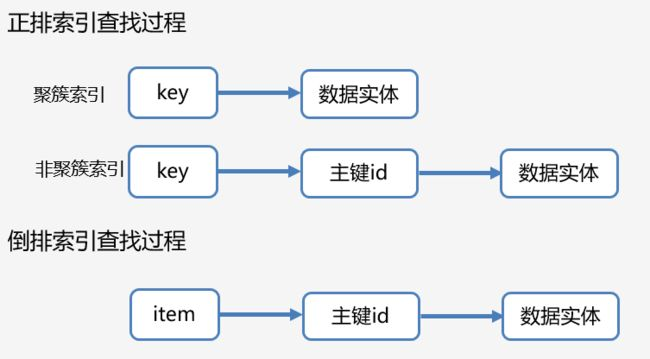
:::tips 聚簇索引和非聚簇索引本质的区别就是B+树的叶子节点上存储的是行数据还是行数据的地址(行号)。 :::
聚集索引(聚簇索引、主键索引)
聚集索引表记录的排列顺序和索引的排列顺序一致,所以查询效率快,只要找到第一个索引值记录,其余就连续性的记录在物理也一样连续存放。聚集索引对应的缺点就是修改慢,因为为了保证表中记录的物理和索引顺序一致,在记录插入的时候,会对数据页重新排序。
InnoDB的主键索引(聚集索引)
- 如果建表时指定了主键,则使用主键作为B+树节点的关键字。
- 如果表中没有主键,但是有唯一索引,则会选取一个唯一索引作为关键字。
如果既没有主键也没有唯一索引,MySQL会自动生成一个6字节的整型唯一标识作为关键字。
非聚集索引(非聚簇索引、二级索引)
非聚集索引指定了表中记录的逻辑顺序,但是记录的物理和索引不一定一致,两种索引都采用B+树结构,非聚集索引的叶子层并不和实际数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针方式。非聚集索引层次多,不会造成数据重排。
InnoDB的二级索引
InnoDB中的二级索引的叶子结点中存的是索引列的值和主键值,所以在使用二级索引查询的时候,首先通过二级索引查找到主键值,然后再根据主键值到主键索引的叶子结点中查到对应的整行数据。

MRR
每次从二级索引中读取到一条记录后,就会根据该记录的主键值执行回表操作。而在某个扫描区间中的二级索引记录的主键值是无序的, 也就是说这些二级索引记录对应的聚簇索引记录所在的页面的页号是无序的。
每次执行回表操作时都相当于要随机读取一个聚簇索引页面,而这些随机 IO 带来的性能开销比较大。MySQL 中提出了一个名为 Disk-Sweep Multi-Range Read (MRR,多范围读取)的优化措施,即先读取一部分二级索引记录,将它们的主键值排好序之后再统一执行回表操作。
相对于每读取一条二级索引记录就立即执行回表操作,这样会节省一些 IO 开销。使用这个 MRR 优化措施的条件比较苛刻,所以我们直接认为每读取一条二级索引记录就立即执行回表操作。MRR 的详细信息,可以查询官方文档。

若有收获,就点个赞吧
0 人点赞
