Union-find算法
Union-find算法,又称并查集算法,主要是解决图论中「动态连通性」问题。
一、问题介绍
简单说,动态连通性其实可以抽象成给一幅图连线。比如下面这幅图,总共有 10 个节点,他们互不相连,分别用 0~9 标记:
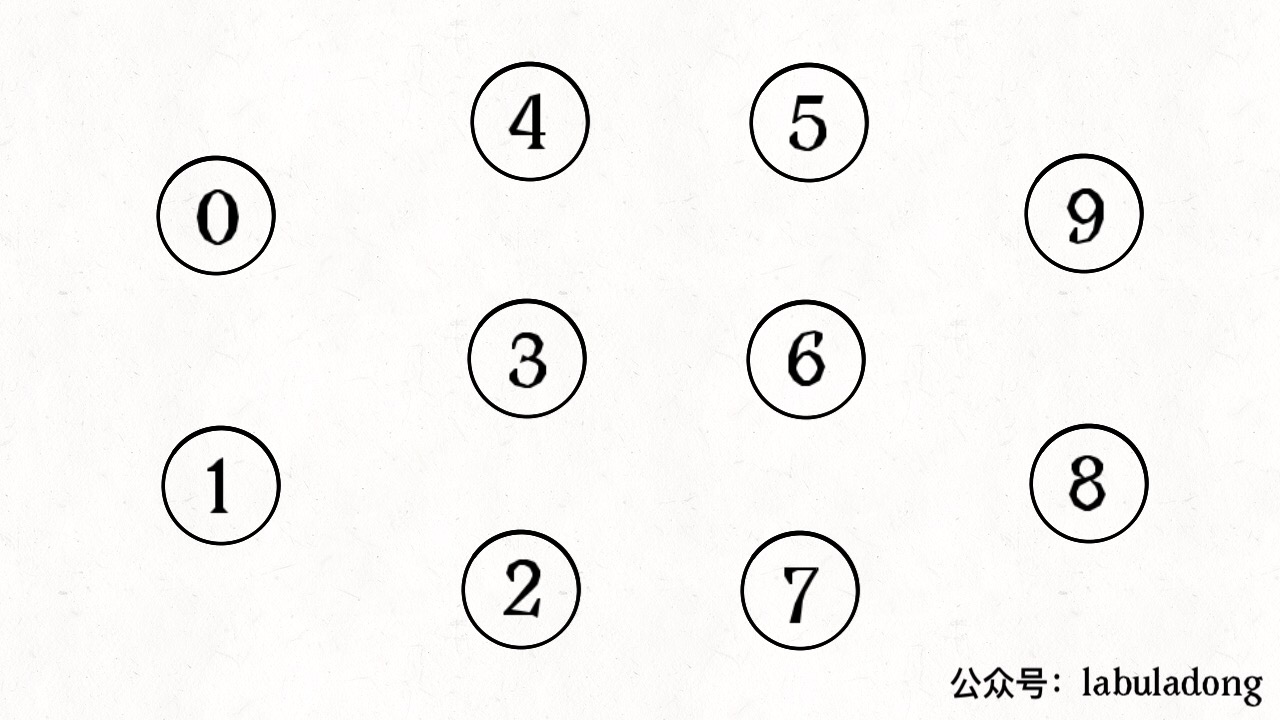
现在我们的 Union-Find 算法主要需要实现这两个 API:
public class UF{private int[] id ;//集合标识private int count; //记录集合数量public UF(int N ){ //初始化count = N;id = new int[N];for(int i = 0 ; i < N;i++){id[i] = i;}}public int count(){return count;}public boolean connected(int p , int q ){return find(p)==find(q);}//find()和union()算法是重点}
这里所说的「连通」是一种等价关系,也就是说具有如下三个性质:
1、自反性:节点p和p是连通的。
2、对称性:如果节点p和q连通,那么q和p也连通。
3、传递性:如果节点p和q连通,q和r连通,那么p和r也连通。
比如说之前那幅图,0~9 任意两个不同的点都不连通,调用connected都会返回 false,连通分量为 10 个。
如果现在调用union(0, 1),那么 0 和 1 被连通,连通分量降为 9 个。
再调用union(1, 2),这时 0,1,2 都被连通,调用connected(0, 2)也会返回 true,连通分量变为 8 个。
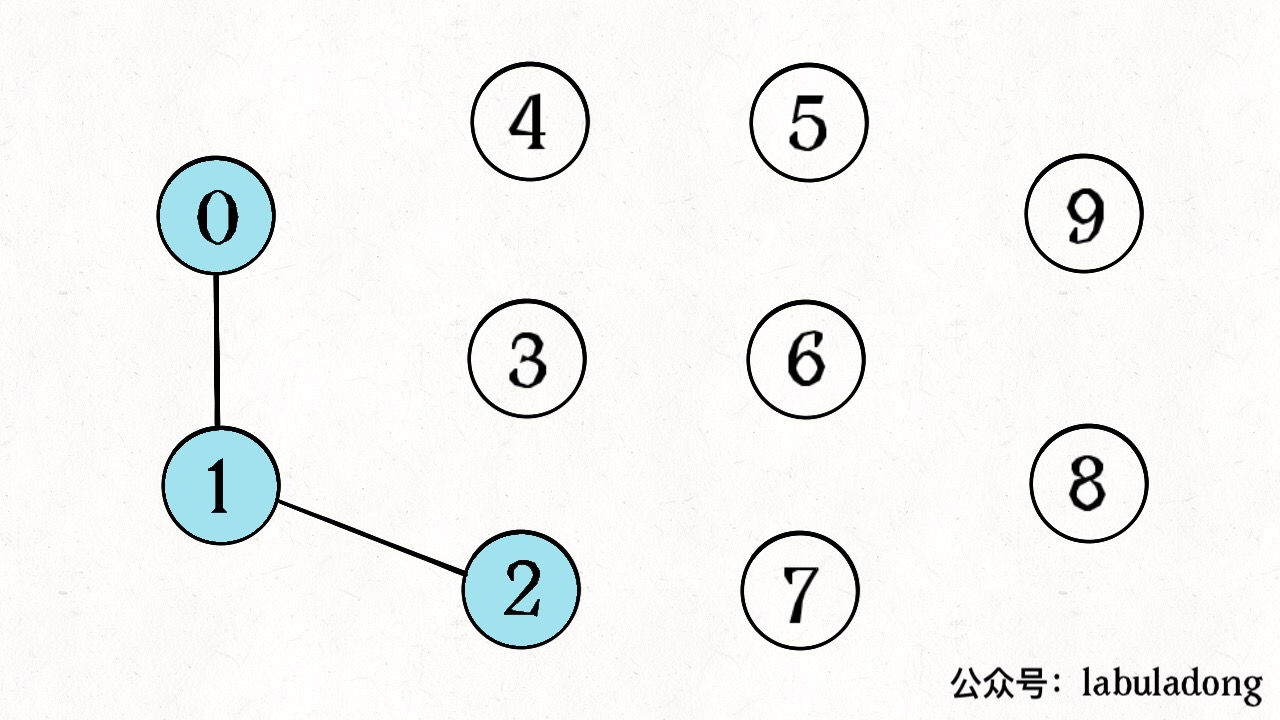
判断这种「等价关系」非常实用,比如说编译器判断同一个变量的不同引用,比如社交网络中的朋友圈计算等等。
这样,你应该大概明白什么是动态连通性了,Union-Find 算法的关键就在于union和connected函数的效率。那么用什么模型来表示这幅图的连通状态呢?用什么数据结构来实现代码呢?
二、基本思路
注意我刚才把「模型」和具体的「数据结构」分开说,这么做是有原因的。因为我们使用森林(若干棵树)来表示图的动态连通性,用数组来具体实现这个森林。
怎么用森林来表示连通性呢?我们设定树的每个节点有一个指针指向其父节点,如果是根节点的话,这个指针指向自己。比如说刚才那幅 10 个节点的图,一开始的时候没有相互连通,就是这样:
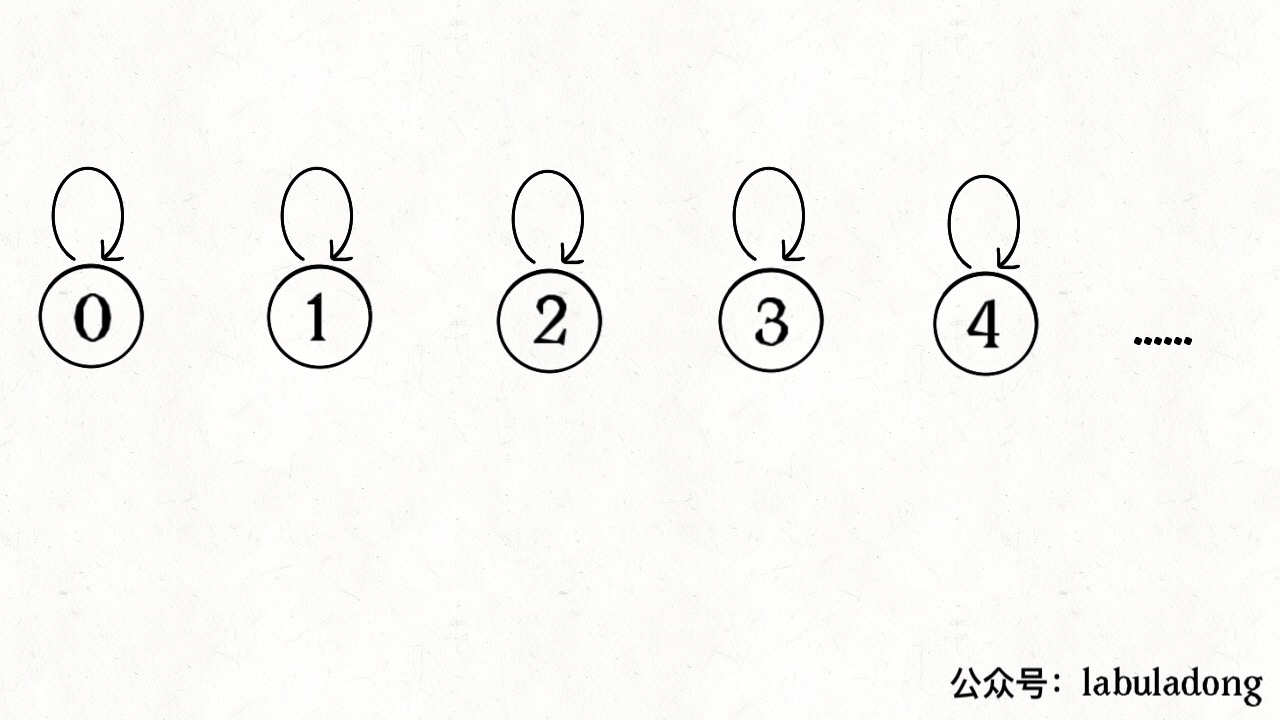
quick-find ——#card=math&code=O%28N%29)
扫描一次数组,这样的union算法需要扫描一次完整序列,此时在同一个集合中的节点的id[p]为同一个值(即集合标识)
public int find(int p ){return id[p];}public void union(int p , int q){int pID = id[p];int qID = id[q];if(qID == pID) return;for(int i = 0 ; i < id.length; i++){if(id[i] == pID){id[i] = qID;}}count--;}
quick-union
id[]的不同定义:
每个节点所对应的 id[] 元素都是同一个分量中的另一个触点的名称(也可能是它自己)——我们将这种联系称为链接。在实现 find() 方法时,我 们从给定的触点开始,由它的链接得到另一个触点,再由这个触点的链接到达第三个触点,如此继 续跟随着链接直到到达一个根触点,即链接指向自己的触点(你将会看到,这样一个触点必然存在)。
如果某两个节点被连通,则让其中的(任意)一个节点的根节点接到另一个节点的根节点上——【quick-union】
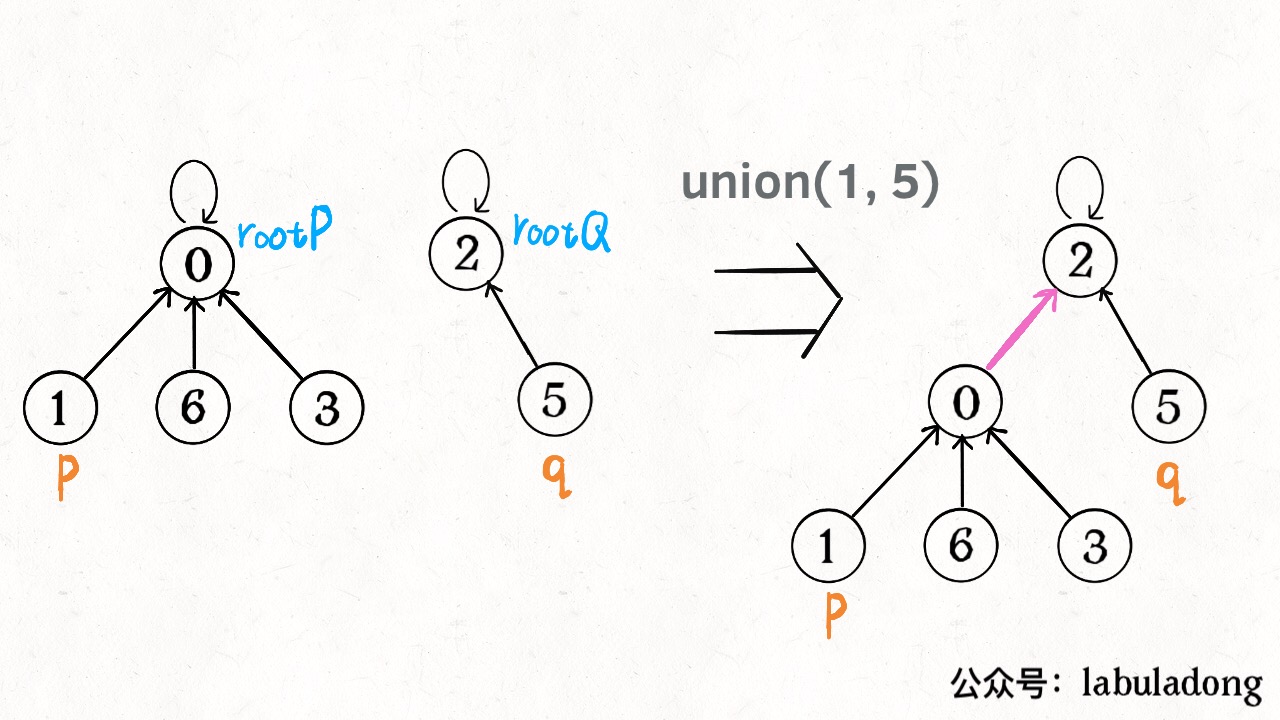
public int find(int p ){while(p!=id[p]) p = id[p];return p;}public void quickunion(int p ,int q){int pRoot = id[p];int qRoot = id[q];if(qRoot == pRoot){return;}id[p] = qRoot;count--;}
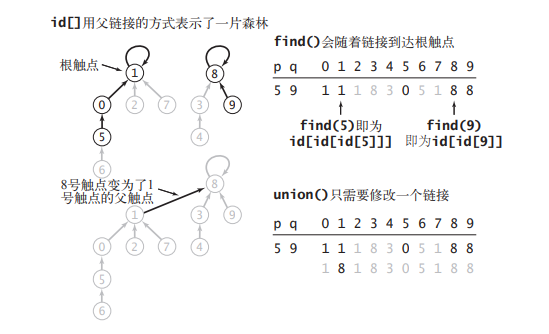
find主要功能就是从某个节点向上遍历到树根,其时间复杂度就是树的高度。我们可能习惯性地认为树的高度就是logN,但这并不一定。logN的高度只存在于平衡二叉树,对于一般的树可能出现极端不平衡的情况,使得「树」几乎退化成「链表」,树的高度最坏情况下可能变成N。
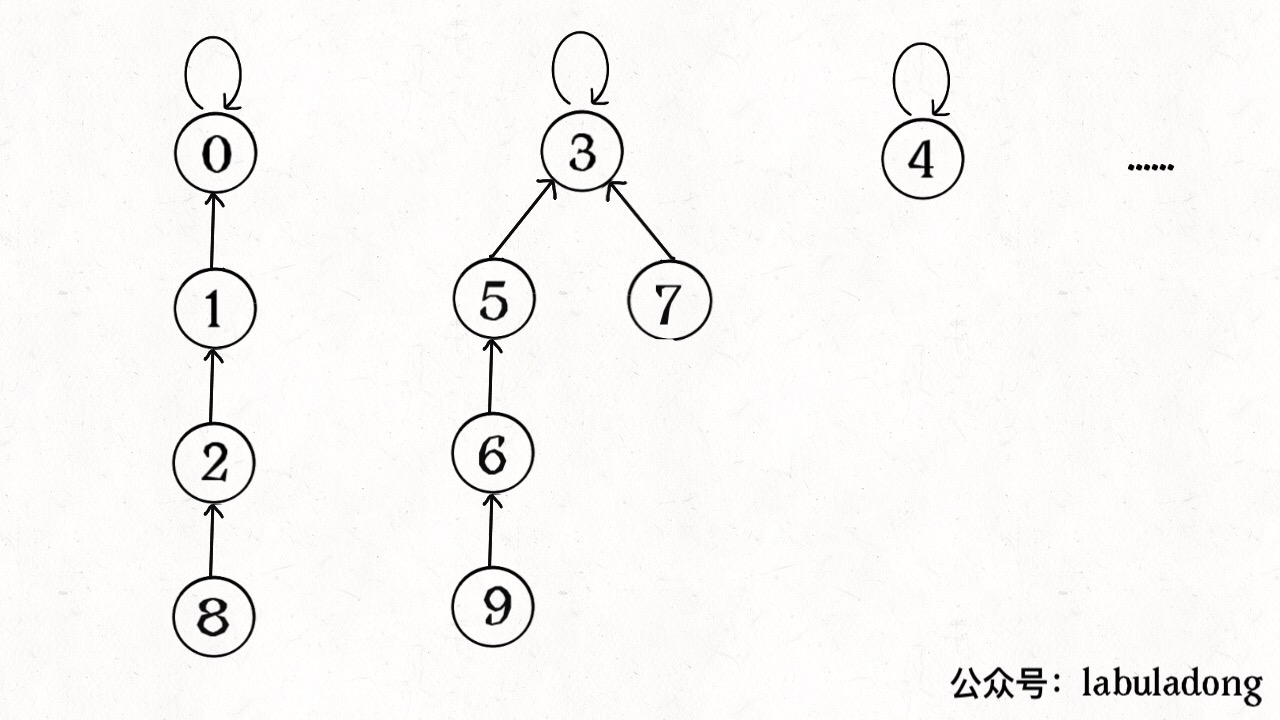
所以说上面这种解法,find,union,connected的时间复杂度都是 O(N)。这个复杂度很不理想的,你想图论解决的都是诸如社交网络这样数据规模巨大的问题,对于union和connected的调用非常频繁,每次调用需要线性时间完全不可忍受。
三、平衡性优化
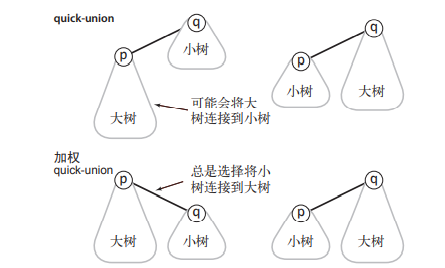
加权quick-union算法——【对数级别】
与其在 union() 中随意将一棵树连接到另一棵树,我们现在会记录每一棵树的大小并总是将较小的树连接 到较大的树上。这项改动需要添加一个数组和一些代码来记录树中的节点数,如算法 1.5 所示,但它能够大大改进算法的效率。我们将它称为加权 quick-union 算法(如图 1.5.7 所示)。该算法构造的树 的高度也远远小于未加权的版本所构造的树的高度。
public class WeightQuickUF{private int[] sz; //各个根节点所对应的分量的大小private int[] id ;//集合标识private int count; //记录集合数量public WeightQuickUF(int N){count = N;id = new int[N];for(int i = 0 ; i < N ;i++) id[i] = i;sz = new int[N];for(int i = 0 ; i < N ; i++) sz[i]=1;}public int find(int p ){while(p!=id[p]) p = id[p];return p;}public void union(int p , int q){int i = find(p);int j = find(q);if(sz[i] < sz[j]){id[i] = j;sz[j] += sz[i];}else{id[j] = i;sz[i] += sz[j];}count--;}}
四、路径压缩
路径压缩
这步优化特别简单,所以非常巧妙。我们能不能进一步压缩每棵树的高度,使树高始终保持为常数?
要实现路径压缩,只需要为 find() 添加一个循环,将在路 径上遇到的所有节点都直接链接到根节点。我们所得到的结果是几乎完全扁平化的树,它和 quick-find 算法理想情况下所得到的树非常接近。
private int find(int p ){while(id[p]!=p){id[p] = id[id[p]];p = id[p];}return p;}
五、参考
- 洗稿labuladong的《UnionFind算法详解》
- 《算法4》

若有收获,就点个赞吧
0 人点赞
