一 背包、队列和栈
集合类数据结构
1.1 概念
1.1.1 数据类型
背包 :只进不出(后进先出),处理顺序不重要,是可以迭代的类型。
队列:先进先出,存在处理顺序;在应用程序中使用队列的主要原因是在用集合保存元素的同时保存它们的相对顺序。
下压栈:先进后出的策略,元素的处理顺序和它们被压入栈的顺序正好相反;在应用程序中使用栈迭代器的 一个典型原因是在用集合保存元素的同时颠倒它们的相对顺序。如使用栈来计算算数表达式%20%20(%204%20%205%20)%20)%20)#card=math&code=%28%201%20%2B%20%28%20%28%202%20%2B%203%20%29%20%2A%20%28%204%20%2A%205%20%29%20%29%20%29&id=EMaBe):
【分析】表达式由括号、运算符和操作数(数字)组成。我们根据以下 4 种情况从左到右逐个将这些实体送入栈处理:
- 将操作数压入操作数栈;
- 将运算符压入运算符栈;
- 忽略左括号;
- 在遇到右括号时,弹出一个运算符,弹出所需数量的操作数,并将运算符和操作数的运算结果压入操作数栈。
1.1.2 集合类数据类型的实现
1、将pop()元素的值设为null——【对象游离】:
Java 的垃圾收集策略是回收所有无法被访问的对象的内存。在对栈 pop() 的实现中,被弹出的元素的引用仍然存在于数组中。这个元素实际上已经是一个孤儿了——它永远也不会再 被访问了,但 Java 的垃圾收集器没法知道这一点,除非该引用被覆盖。即使用例已经不再需要这个元素了,数组中的引用仍然可以让它继续存在。这种情况(保存一个不需要的对象的引用)称为游离。在这里,避免对象游离很容易,只需将被弹出的数组元素的值设为 null 即可,这将覆 盖无用的引用并使系统可以在用例使用完被弹出的元素后回收它的内存。
2、可迭代的集合数据类型必须实现的东西——【Java迭代】
集合数据类型必须实现一个 iterator() 方法并返回一个 Iterator 对象;
Iterator 类必须包含两个方法:hasNext()(返回一个布尔值)和 next()(返回集合中的 一个泛型元素)。
Iterator<String> i = collection.iterator();while (i.hasNext()){String s = i.next();StdOut.println(s);}
3、使用一个size记录栈的大小——【栈】
使用两个变量作为索引,一个变量head指向队列的开头,一个tail指向队列的结尾
4、push()在链表的头部插入节点,pop()删除连接的头部节点——【使用链表实现下压栈】
5、first指向队列的开头,last指向队列的末尾,元素入队移动last,弹出移动first——【使用链表实现队列】
6、背包可用栈实现,删去pop()方法即可——【背包】
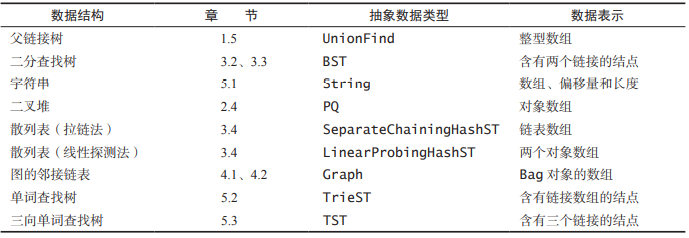
1.2 复杂度分析
1.2.1 时间复杂度
【Knuth】原则上可以构造一个数学模型来描述任意程序的运行时间,一个程序运行的总时间主要和两点有关:
- 执行每条语句的耗时
- 执行每条语句的频率
对于大多数程序,得到其运行时间的数学模型所需的步骤如下:
- 确定输入模型,定义问题的规模
- 识别内循环
- 根据内循环中的操作确定成本模型
- 对于给定的输入,判断这些操作的执行频率。
增长数量级的分类
1、 常数级别
运行时间的增长数量级为常数的程序完成它的任务所需的操作次数一定,因此它的运行时间不 依赖于 N。大多数的 Java 操作所需的时间均为常数。
2、 对数级别
运行时间的增长数量级为对数的程序仅比常数时间的程序稍慢。运行时间和问题规模成对数关 系的程序的经典例子就是二分查找(BinarySearch)。对数的底数和增长的数量级无关(因为不同的底数仅相当于一个常数因子),所以我们在说明对数级别时一般使用 log N。
3、 线性级别
使用常数时间处理输入数据中的所有元素或是基于单个 for 循环的程序是十分常见的。此类程 序的增长数量级是线性的——它的运行时间和 N 成正比。
4、 线性对数级别
我们用线性对数描述运行时间和问题规模 N 的关系为 N log N 的程序。和之前一样,对数的底数和增长的数量级无关。线性对数算法的典型例子是Merge.sort(请见算法2.4)和Quick.sort()(请 见算法 2.5)。
5、 平方级别
一个运行时间的增长数量级为的程序一般都含有两个嵌套的 for 循环,对由 N 个元素得到 的所有元素对进行计算。初级排序算法
Selection.sort()和Insertion.sort()都是这种类型的典型程序。
6、 立方级别
一个运行时间的增长数量级为的程序一般都含有三个嵌套的 for 循环,对由 N 个元素得 到的所有三元组进行计算。本节中的 ThreeSum 就是一个典型的例子。
7、 指数级别
在第 6 章中(也只会在第 6 章)我们将会遇到运行时间和或者更高级别的函数成正比的 程序。一般我们会使用指数级别来描述增长数量级为
的算法,其中 b>1 且为常数,尽管不同的b值得到的运行时间可能完全不同。指数级别的算法非常慢——不可能用它们解决大规模的 问题。但指数级别的算法仍然在算法理论 中有着重要的地位,因为它们看起来仍然 是解决许多问题的最佳方案。
示例
TwoSum:归并排序+二分查找——【单层循环】
ThreeSum:归并排序+二分查找——【双层循环】
1.2.2 空间复杂度
Java基础空间消耗
1、Java中一个对象本身的开销大致是16字节
2、一个指向外部的引用大概需要8字节
3、Java中数组被实现为对象,一般会因为记录长度而需要额外的内存。一个原始数据类型的数组一般需要24字节的头信息(16字节的对象开销,4字节用于保存长度以及4填充字节)
4、String的标准实现含有4个示例变量:一个指向字符数组的引用(8字节)和3个int值(各4字节)。第一个int描述的是字符数组中的偏移量,第二个int是一个计数器(字符串的长度),第三个int是一个散列值。
5、每个String对象会使用40字节(16字节对象,3*4字节,数组因引用8字节,4个填充字节)
6、一个子字符串所需的额外内存是一个常数,构造一个子字符串 所需的时间也是常数
7、栈和堆分配内存(待补充)
1.3 并查集union-find
二、排序
该部分主要的排序算法有:
- 选择排序
- 插入排序
- 希尔排序
- 堆排序
- 快速排序
- 堆排序
具体内容见排序|voidwx
三、查找
该部分主要内容为:二分查找、二叉搜索树、红黑树、散列表

若有收获,就点个赞吧
0 人点赞
