title: KMP算法
tags:
- KMP
- 算法
- Java
categories: [算法,计算机]
declare: true
mathjax: true
copyright: true
toc: true
abbrlink: 2da0528d
date: 2021-02-15 09:54:20
KMP算法
简介
KMP 算法是 D.E.Knuth、J,H,Morris 和 V.R.Pratt 三位神人共同提出的,称之为 Knuth-Morria-Pratt 算法,简称 KMP 算法。该算法相对于 Brute-Force(暴力)算法有比较大的改进,主要是消除了主串指针的回溯,从而使算法效率有了某种程度的提高。
描述
该算法实现的功能是在一个目标串中查找是否存在模式串,若存在,则返回模式串在目标串中第一次出现的位置。
过程
1、朴素的模式匹配
从目标串S中的第一个字符开始和模式串T中的第一个字符比较, 分别用i和j指示S串和T串中正在比较的字符位置。
匹配成功,返回模式串T中第一个字符在目标串S中的位置,否则匹配失败,返回零值。

这样匹配的时间复杂度最坏是O(m*n),最好情况下算法的平均时间复杂度为O(n+m) (该结论来自课程ppt)
2、无回溯的模式匹配——KMP
在朴素的模式匹配中,每当目标串中的字符与模式串中的字符不相等时,都要进行回溯,使得其时间复杂度大。
KMP 算法主要是通过消除主串指针的回溯来提高匹配的效率的,它提取并运用了加速匹配的信息!
示例:
目标串S=aabaabaaf,模式串T=aabaaf
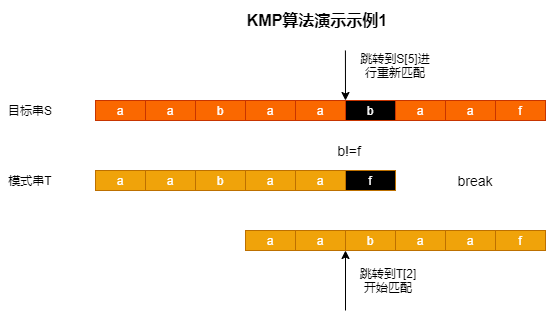
在上图中我们可以看到,当b!=f时,下一次匹配并不是从S[1]和T[0]开始,而是从S[5]和T[2]开始进行字符匹配。在该过程中,当碰到不匹配的字符b!=f时,会现在模式串T找到aabaa中的最大相同的前后缀长度(此处为2)。所以在下一次匹配开始时,对于模式串,会跳过已经与后缀相同的前缀,直接从T[2]开始匹配;对于目标串,由于模式串中的最大相同的前后缀长度对应的后缀已经匹配了目标串中的字符(aa),则接着向后匹配即可。此处自圆其说有点困难
在上述的过程中,提及到了最大相同的前后缀长度,为此我们需要对模式串求前缀表来得到模式串中的各个字符对应的最大相同的前后缀长度。
3、前缀表
模式串T=aabaaf
1. 前后缀概念
前缀:包含首字符,不包含尾字符的所有子串
后缀:包含尾字符,不包含首字符的所有子串
2. 最长相等的前后缀
| 子串 | 最长相等的前后缀 |
|---|---|
| a | 0 |
| aa | 1/a |
| aab | 0 |
| aaba | 1/a |
| aabaa | 2/aa |
| aabaaf | 0 |
则模式串T=aabaaf的前缀表为010120
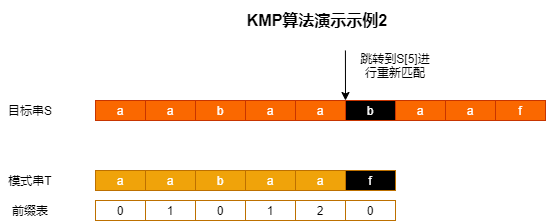
当字符不匹配时b!=f,模式串的子串T[0:4]的最大相等前后缀长度为2,即子串T[0:1]等于子串T[3:4],所以对于模式串下一步吧可以直接从T[2]开始匹配。对于目标串的跳转,怎么解释
求前缀表的目的是为了告诉程序,当发生不匹配时,应该回退到什么位置。前缀表常用next[]数组表示,在代码中,还会将上述的前缀表右移形成next[]数组(首位填-1)
问题
在刚刚求出的前缀表有什么问题呢?如下图
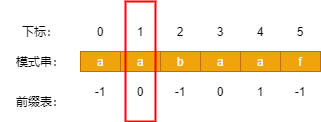
看这个位置红框的位置,如果要找下表1 所对应 前缀表里的数值的时候,前缀表里的数值依然是1,然后就要跳到下表1的位置,如此就「形成了一个死循环」,这样的死循环会让next数组构建失败,类似的还有aaa会在下标2处形成死循环。
1、解法一:数值减一
「如何怎么避免呢,就把前缀表里的数值统一减一, 开始位置设置为-1 。」 这一点对理解后面KMP代码很重要!!
改为如图所示:
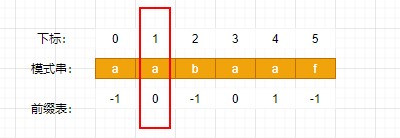
这样就避免的死循环,只不过后续取前缀表里的数值的时候,要记得再+1,才是我们想要的值。
「最后得到的新前缀表在KMP算法里通常用一个next数组来表示。」
注意这个next数组就根据模式串求取的。
2、解法二:前缀表右移得到next数组
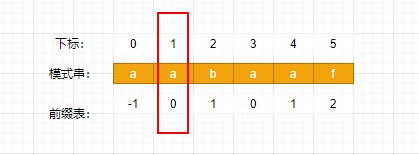
在j处冲突时直接回退next[j]即可
实现KMP算法
1、next数组的求解
- 初始化
- 前后缀不相同
- 前后缀相同
- 更新next数组
i : 后缀末尾位置;j : 前缀末尾位置 ==包括i及之前的子串的最长相同前后缀长度
1. 前缀表统一减1
void getNext(int[] next, String s){int j = -1;next[0] = j;for(int i = 1 ; i < s.length() ; i++){while( j >= 0 && s[i]!=s[j+1]){j = next[j];}if(s[i] == s[j+1]){j++;}next[i] = j;}}
我们需要明白(以下简称最大相同前后缀长度为maxlen,称最大相同前后缀为最大前后缀):
子串s1=aa
子串s2=aab
子串s3=aaba
子串s4=aabaa
…
对于子串s1来说,其maxlen = 1,此时i = 1, j = maxlen-1= 0;
对于子串s2来说,首先应判断在s1的最大相同前后缀的基础上添加s[i]后是否仍有最大相同前后缀。若其满足要求,则可直接通过next[i] = j得到maxlen;若其不满足要求,说明我们需要回退去重新寻找最大前后缀,使用j = next[j]进行回退(此处存在疑问,为什么要按照这样的规律进行回退)。
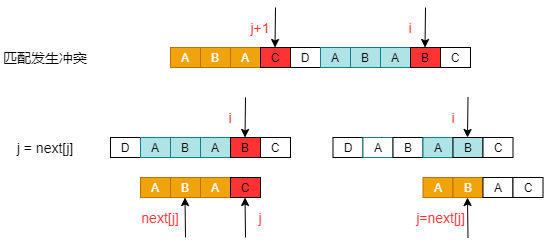
如上图,当发生不匹配时,将j+1前的子串当成模式串,原本的子串当成目标串,此时,按照与之前同样的思路,可以得到j = next[j]。
2. 右移(待完成)
2、匹配过程
见题目部分的实现代码
题目
lc28:实现strStr()函数
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
示例:
输入: haystack = "hello", needle = "ll"输出: 2
示例 2:
输入: haystack = "aaaaa", needle = "bba"
输出: -1
对于本题而言,当 needle 是空字符串时我们应当返回 0 。
class Solution {
public int strStr(String haystack, String needle) {
if(needle.length()==0) return 0;
int[] next = getNext(needle);
int ans = -1;
for(int i = 0 , j = -1 ; i < haystack.length(); i++){
while (haystack.charAt(i) != needle.charAt(j+1) && j>=0){
j = next[j];
}
if (haystack.charAt(i) == needle.charAt(j+1)){
j++;
}
if(j+1 == needle.length()){
ans = i-needle.length()+1;
break;
}
}
return ans;
}
private int[] getNext(String needle){
int j = -1;
int[] next = new int[needle.length()];
next[0]=j;
for(int i = 1; i < needle.length(); i++){
while(j>=0 && needle.charAt(i) != needle.charAt(j+1)){
j = next[j];
}
if(needle.charAt(i) == needle.charAt(j+1)){
j++;
}
next[i] = j;
}
return next;
}
}
参考链接

若有收获,就点个赞吧
0 人点赞
