title: 树
copyright: true
toc: true
tags:
- 数据结构
categories: - 计算机
abbrlink: 7b216a3b
date: 2020-06-17 15:37:57
一、二叉树
1、 二叉树
在二叉树中,每个节点只有一个父节点,且每个节点都只有两个子节点
2、二叉查找树
- 概念
二叉查找树(BST)是特殊的二叉树,其每个节点都含有一个Comparable的键(以及相关理的值),且每个节点的键都大于其左子树中的任意节点的键而小于右子树的任意节点的健。
二、DFS算法解题
其实 DFS 算法就是回溯算法
1、算法框架
三、BFS算法框架
BFS 的核心思想应该不难理解的,就是把一些问题抽象成图,从一个点开始,向四周开始扩散。一般来说,在实现BFS 算法都是用「队列」这种数据结构,每次将一个节点周围的所有节点加入队列。
BFS 相对 DFS 的最主要的区别是:BFS 找到的路径一定是最短的,但代价就是空间复杂度比 DFS 大很多。
1、算法框架
BFS出现的常见场景就是让你在一幅图中找到从start到target的最短距离。在具体的场景中可能有不同的描述,比如走迷宫,有的格子是围墙不能走,从起点到终点的最短距离是多少?如果这个迷宫带「传送门」可以瞬间传送呢?
再比如说两个单词,要求你通过某些替换,把其中一个变成另一个,每次只能替换一个字符,最少要替换几次?
……
对于不同的场景,算法框架基本一致:
//计算start到target的最短距离,图的BFS应用int BFS(Node start , node target){//针对root==null的特殊情况需要做出判断Queue<Node> q;boolean[] visited = new boolean[G.size()]; //G.size是图中的点数量,防止走回头路Arrays.fill(visited,false);int step = 0;q.offer(start); //加入起点visited[index] = true; //index为start对应下标while(!q.isEmpty()){int size = q.size();Node cur = q.poll();for ( int i = 0 ; i < size ;i++){if ( cur==target ) return step;for ( Node n : cur.adjcent){ //cur.adjcent为cur的相邻节点if(!visited[i]){q.offer(n);visited[i] = true;}}}step++ ; //步数更新在此处,但是需要根据不同的情况来改变位置}}//树的层次遍历BFSList<List<Integer>> BFS(TreeNode root){List<List<Integer>> res = new LinkList<>();if(root == null) return res;Queue<TreeNode> q = new LinkedList<>();q.offer(root);while(!q.isEmpty()){int size = q.size();List<Integer> temp = new LinkList<>();for(int i = 0 ; i < size ;i++){TreeNode node = q.poll();if(node.left!=null) q.offer(node.left);if(node.right!=null) q.offer(node.right);temp.add(node.val);}res.add(temp)}return res;}
四、树的示例
1. 题104:二叉树的做大深度
104: 二叉树的最大深度——可使用深度遍历和广度遍历
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
class Solution {public int maxDepth(TreeNode root) {//bfsif(root == null ){return 0;}int ans = 0;Queue<TreeNode> q = new LinkedList<TreeNode>();q.offer(root);while(!q.isEmpty()){int size = q.size();while(size > 0){TreeNode node = q.poll();if(node.left!=null){q.offer(node.left);}if(node.right!=null){q.offer(node.right);}size--;}ans++;}return ans;//dfsif(root == null){return 0 ;}else{int leftLen = maxDepth(root.left);int rightLen = maxDepth(root.right);return Math.max(leftLen,rightLen)+1;//max(左子树的深度,右子树的深度)+1}}}
方法一:深度优先搜索
思路与算法
如果我们知道了左子树和右子树的最大深度l和 r,那么该二叉树的最大深度即为max(l,r) + 1
而左子树和右子树的最大深度又可以以同样的方式进行计算。因此我们可以用「深度优先搜索」的方法来计算二叉树的最大深度。具体而言,在计算当前二叉树的最大深度时,可以先递归计算出其左子树和右子树的最大深度,然后在 O(1)间内计算出当前二叉树的最大深度。递归在访问到空节点时退出。
复杂度分析
时间复杂度:O(n),其中
n 为二叉树节点的个数。每个节点在递归中只被遍历一次。
空间复杂度:O(height),其中height 表示二叉树的高度。递归函数需要栈空间,而栈空间取决于递归的深度,因此空间复杂度等价于二叉树的高度。
方法二:广度优先搜索
思路与算法
我们也可以用「广度优先搜索」的方法来解决这道题目,但我们需要对其进行一些修改,此时我们广度优先搜索的队列里存放的是「当前层的所有节点」。每次拓展下一层的时候,不同于广度优先搜索的每次只从队列里拿出一个节点,我们需要将队列里的所有节点都拿出来进行拓展,这样能保证每次拓展完的时候队列里存放的是当前层的所有节点,即我们是一层一层地进行拓展,最后我们用一个变量 ans 来维护拓展的次数,该二叉树的最大深度即为 ans。
复杂度分析
时间复杂度:O(n),其中 n为二叉树的节点个数。与方法一同样的分析,每个节点只会被访问一次。
空间复杂度:此方法空间的消耗取决于队列存储的元素数量,其在最坏情况下会达到 O(n)。
2. 题111:二叉树的最小深度
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
说明:叶子节点是指没有子节点的节点。
class Solution {public int minDepth(TreeNode root) {//dfsif(root == null){return 0 ;}if(root.left == null && root.right == null) return 1;int min = Integer.MAX_VALUE;if(root.left != null){int minLeft = minDepth(root.left);min = Math.min(min,minLeft);}if(root.right!=null){int minRight = minDepth(root.right);min = Math.min(min,minRight);}return min+1;//bfsif(root == null) return 0;Queue<TreeNode> q = new LinkedList<TreeNode>();int ans = 0 ;q.offer(root);ans = 1;while(!q.isEmpty()){int size = q.size();for(int i = 0 ; i < size ; i++){TreeNode node = q.poll();if(node == null) continue;if(node.left == null && node.right == null){return ans;}q.offer(node.left);q.offer(node.right);}ans++;}return ans;}}
DFS
复杂度分析
时间复杂度:O(N),其中 N 是树的节点数。对每个节点访问一次。
空间复杂度:O(H),其中 H 是树的高度。空间复杂度主要取决于递归时栈空间的开销,最坏情况下,树呈现链状,空间复杂度为O(N)。平均情况下树的高度与节点数的对数正相关,空间复杂度为 O(log N)。
还可以使用另一种方法写DFS
class Solution {public int minDepth(TreeNode root) {if (root == null) {return 0;}// 计算左子树的深度int left = minDepth(root.left);// 计算右子树的深度int right = minDepth(root.right);// 如果左子树或右子树的深度不为 0,即存在一个子树,那么当前子树的最小深度就是该子树的深度+1// 如果左子树和右子树的深度都不为 0,即左右子树都存在,那么当前子树的最小深度就是它们较小值+1return (left == 0 || right == 0) ? left + right + 1 : Math.min(left, right) + 1;}}
3. 题108:将有序数组转换成二叉搜索树
题目描述:
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。
高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。
class Solution {public TreeNode sortedArrayToBST(int[] nums) {return rebuild(nums,0,nums.length-1);}private TreeNode rebuild(int[] nums , int left , int right){if(left > right ){return null;}int mid = (right+left+1)/2;TreeNode root = new TreeNode(nums[mid]);root.left = rebuild(nums,left,mid-1);root.right = rebuild(nums,mid+1,right);return root;}}
前言
二叉搜索树的中序遍历是升序序列,题目给定的数组是按照升序排序的有序数组,因此可以确保数组是二叉搜索树的中序遍历序列。
给定二叉搜索树的中序遍历,是否可以唯一地确定二叉搜索树?答案是否定的。如果没有要求二叉搜索树的高度平衡,则任何一个数字都可以作为二叉搜索树的根节点,因此可能的二叉搜索树有多个。
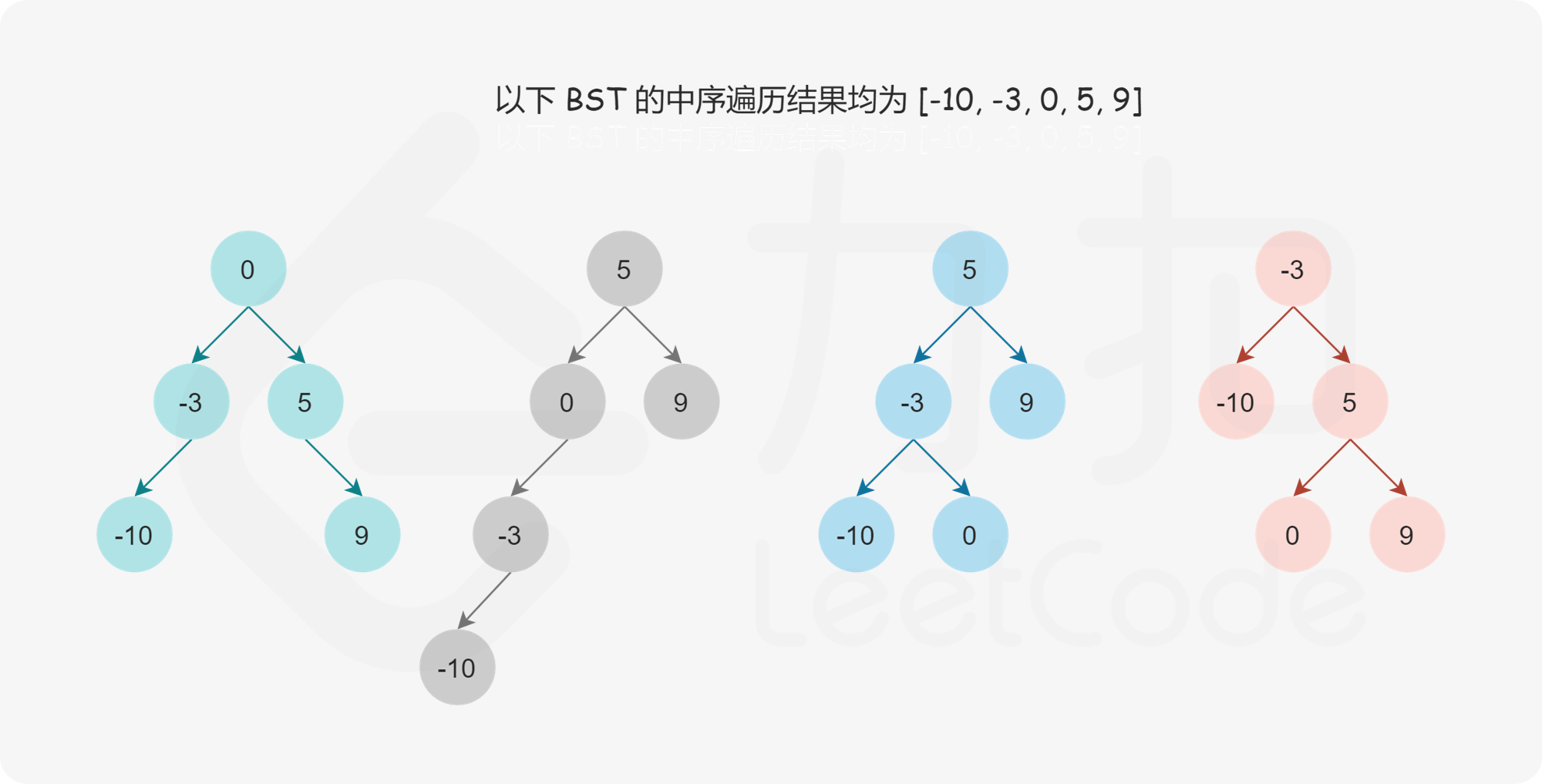
如果增加一个限制条件,即要求二叉搜索树的高度平衡,是否可以唯一地确定二叉搜索树?答案仍然是否定的。
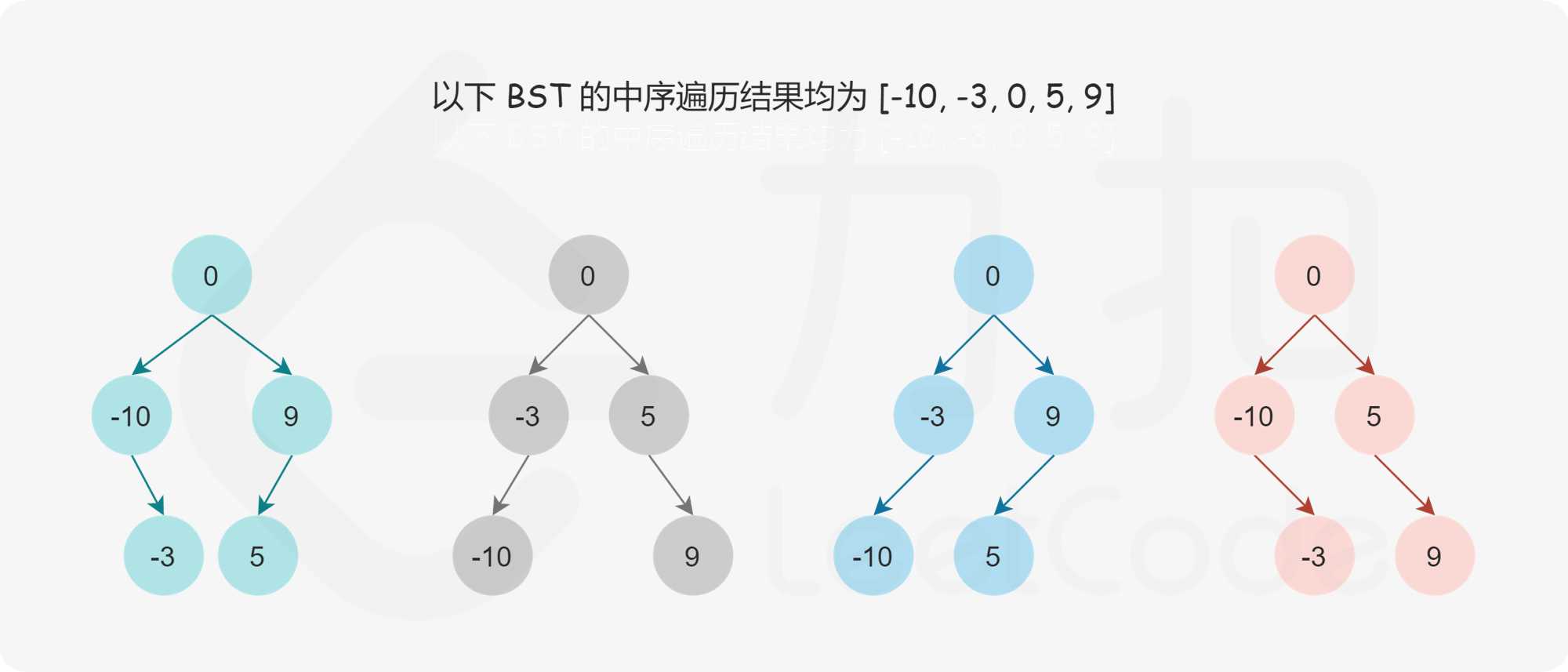
直观地看,我们可以选择中间数字作为二叉搜索树的根节点,这样分给左右子树的数字个数相同或只相差 11,可以使得树保持平衡。如果数组长度是奇数,则根节点的选择是唯一的,如果数组长度是偶数,则可以选择中间位置左边的数字作为根节点或者选择中间位置右边的数字作为根节点,选择不同的数字作为根节点则创建的平衡二叉搜索树也是不同的。
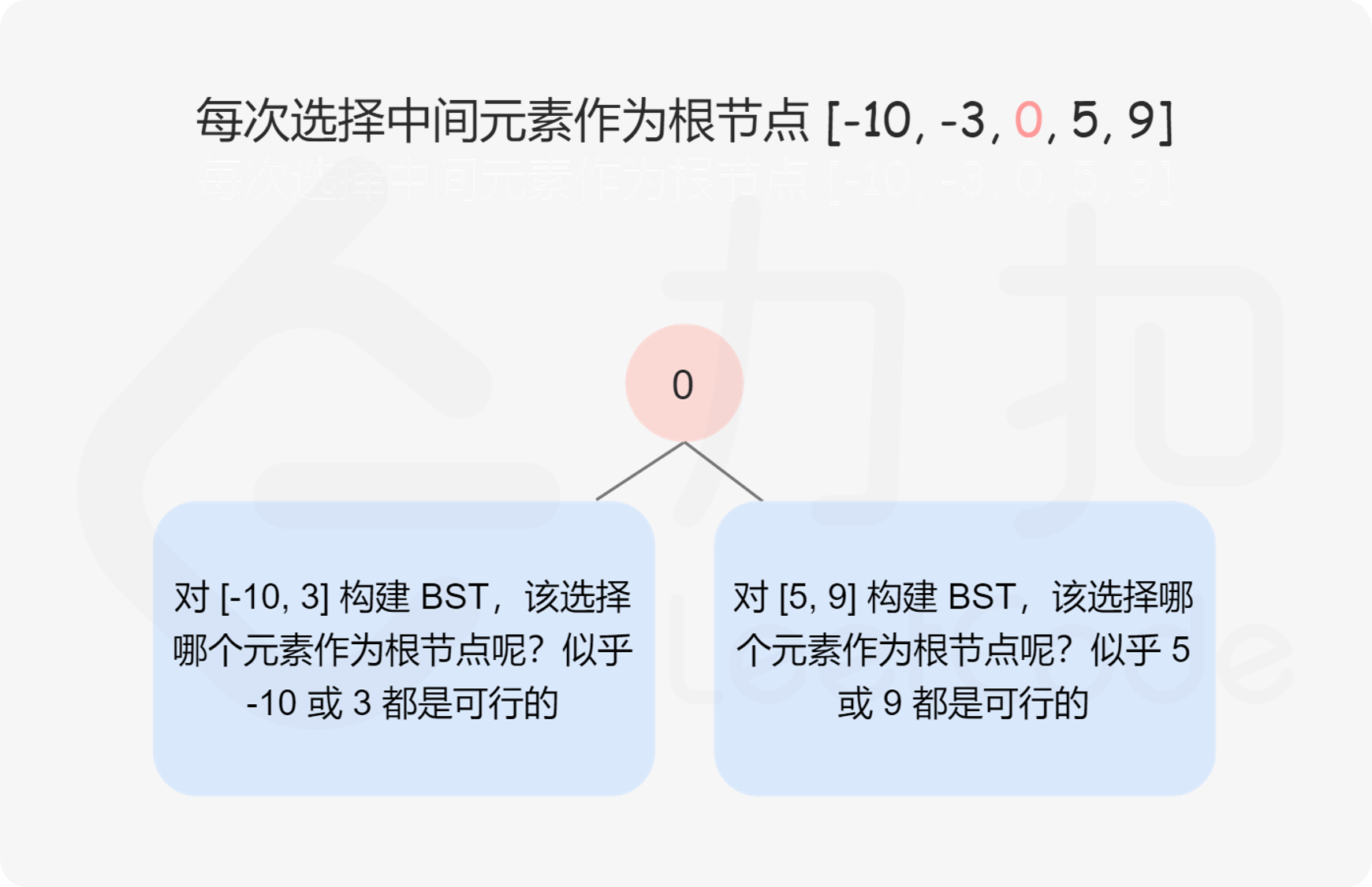
确定平衡二叉搜索树的根节点之后,其余的数字分别位于平衡二叉搜索树的左子树和右子树中,左子树和右子树分别也是平衡二叉搜索树,因此可以通过递归的方式创建平衡二叉搜索树。
当然,这只是我们直观的想法,为什么这么建树一定能保证是「平衡」的呢?这里可以参考「1382. 将二叉搜索树变平衡」,这两道题的构造方法完全相同,这种方法是正确的,1382 题解中给出了这个方法的正确性证明:1382 官方题解,感兴趣的同学可以戳进去参考。
递归的基准情形是平衡二叉搜索树不包含任何数字,此时平衡二叉搜索树为空。
在给定中序遍历序列数组的情况下,每一个子树中的数字在数组中一定是连续的,因此可以通过数组下标范围确定子树包含的数字,下标范围记为[left,right]。对于整个中序遍历序列,下标范围从 left=0 到 right=nums.length−1。当left>right 时,平衡二叉搜索树为空。
以下三种方法中,方法一总是选择中间位置左边的数字作为根节点(mid = (left+right)/2),方法二总是选择中间位置右边的数字作为根节点(mid = (left+right+1)/2),方法三是方法一和方法二的结合,选择任意一个中间位置数字作为根节点。
方法一:中序遍历,总是选择中间位置左边的数字作为根节点
选择中间位置左边的数字作为根节点,则根节点的下标为 mid=(left+right)/2,此处的除法为整数除法。
复杂度分析
时间复杂度:O(n),其中 n 是数组的长度。每个数字只访问一次。
空间复杂度:O(log n),其中 n 是数组的长度。空间复杂度不考虑返回值,因此空间复杂度主要取决于递归栈的深度,递归栈的深度是O(log n)。
参考链接:官方题解
4. 题100:平衡二叉树
题目描述:
给定一个二叉树,判断它是否是高度平衡的二叉树。本题中,一棵高度平衡二叉树定义为:
一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1 。
题解
前言
这道题中的平衡二叉树的定义是:二叉树的每个节点的左右子树的高度差的绝对值不超过 11,则二叉树是平衡二叉树。根据定义,一棵二叉树是平衡二叉树,当且仅当其所有子树也都是平衡二叉树,因此可以使用递归的方式判断二叉树是不是平衡二叉树,递归的顺序可以是自顶向下或者自底向上。
方法一:自顶向下的递归
定义函数 height,用于计算二叉树中的任意一个节点 p 的高度:
%3D%0A%5Cleft%5Clbrace%0A%09%5Cbegin%7Barray%7D%7Bll%7D%0A%20%20%20%20%20%20%20%20%20%20%20%20%200%20%26%20p%E6%98%AF%E7%A9%BA%E8%8A%82%E7%82%B9%20%20%5C%5C%0A%20%20%20%20%20%20%20%20%20%20%20%20%20max(height(p.left)%2Cheight(p.right))%2B1%20%26%20p%E6%98%AF%E9%9D%9E%E7%A9%BA%E8%8A%82%E7%82%B9%5C%5C%20%0A%20%20%20%20%20%5Cend%7Barray%7D%0A%5Cright.%0A#card=math&code=height%28p%29%3D%0A%5Cleft%5Clbrace%0A%09%5Cbegin%7Barray%7D%7Bll%7D%0A%20%20%20%20%20%20%20%20%20%20%20%20%200%20%26%20p%E6%98%AF%E7%A9%BA%E8%8A%82%E7%82%B9%20%20%5C%5C%0A%20%20%20%20%20%20%20%20%20%20%20%20%20max%28height%28p.left%29%2Cheight%28p.right%29%29%2B1%20%26%20p%E6%98%AF%E9%9D%9E%E7%A9%BA%E8%8A%82%E7%82%B9%5C%5C%20%0A%20%20%20%20%20%5Cend%7Barray%7D%0A%5Cright.%0A)
有了计算节点高度的函数,即可判断二叉树是否平衡。具体做法类似于二叉树的前序遍历,即对于当前遍历到的节点,首先计算左右子树的高度,如果左右子树的高度差是否不超过 11,再分别递归地遍历左右子节点,并判断左子树和右子树是否平衡。这是一个自顶向下的递归的过程。
class Solution {public boolean isBalanced(TreeNode root) {if(root == null){return true;}else{return Math.abs(treeLength(root.left) - treeLength(root.right))<=1&& isBalanced(root.left) && isBalanced(root.right);}}private int treeLength(TreeNode root){if(root == null){return 0 ;}int leftLen = treeLength(root.left);int rightLen = treeLength(root.right);return Math.max(rightLen,leftLen)+1;}}
复杂度分析
时间复杂度:#card=math&code=O%28n%5E2%29),其中 n 是二叉树中的节点个数。
最坏情况下,二叉树是满二叉树,需要遍历二叉树中的所有节点,时间复杂度是O(n)。
对于节点 p,如果它的高度是 d,则height(p) 最多会被调用 d 次(即遍历到它的每一个祖先节点时)。对于平均的情况,一棵树的高度 h 满足 O(h)=O(log n),因为 ,所以总时间复杂度为 O(n log n)。对于最坏的情况,二叉树形成链式结构,高度为O(n),此时总时间复杂度为
#card=math&code=O%28n%5E2%29)。
空间复杂度:O(n),其中 n 是二叉树中的节点个数。空间复杂度主要取决于递归调用的层数,递归调用的层数不会超过 n。
方法二:自底向上的递归
方法一由于是自顶向下递归,因此对于同一个节点,函数 height 会被重复调用,导致时间复杂度较高。如果使用自底向上的做法,则对于每个节点,函数 height 只会被调用一次。
自底向上递归的做法类似于后序遍历,对于当前遍历到的节点,先递归地判断其左右子树是否平衡,再判断以当前节点为根的子树是否平衡。如果一棵子树是平衡的,则返回其高度(高度一定是非负整数),否则返回 −1。如果存在一棵子树不平衡,则整个二叉树一定不平衡。
class Solution {public boolean isBalanced(TreeNode root) {return height(root)!=-1;}private int height(TreeNode root){if(root == null){return 0 ;}int leftH, rightH;if((leftH=height(root.left))==-1 || (rightH=height(root.right))==-1|| Math.abs(leftH-rightH)>1){return -1;}return Math.max(leftH,rightH)+1;}}
复杂度分析
时间复杂度:O(n),其中 n 是二叉树中的节点个数。使用自底向上的递归,每个节点的计算高度和判断是否平衡都只需要处理一次,最坏情况下需要遍历二叉树中的所有节点,因此时间复杂度是O(n)。
空间复杂度:O(n),其中 n 是二叉树中的节点个数。空间复杂度主要取决于递归调用的层数,递归调用的层数不会超过 n。
5. 题112:路径总和
题目:
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum ,判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。叶子节点 是指没有子节点的节点。
题解
前言
注意到本题的要求是,询问是否有从「根节点」到某个「叶子节点」经过的路径上的节点之和等于目标和。核心思想是对树进行一次遍历,在遍历时记录从根节点到当前节点的路径和,以防止重复计算。
需要特别注意的是,给定的 root 可能为空。
方法一:广度优先搜索
思路及算法
首先我们可以想到使用广度优先搜索的方式,记录从根节点到当前节点的路径和,以防止重复计算。
这样我们使用两个队列,分别存储将要遍历的节点,以及根节点到这些节点的路径和即可。
class Solution {
public boolean hasPathSum(TreeNode root, int targetSum) {
if(root == null){
return false;
}
Queue<TreeNode> tree = new LinkedList<TreeNode>();
Queue<Integer> treeVal = new LinkedList<Integer>();
tree.offer(root);
treeVal.offer(root.val);
while(!tree.isEmpty()){
TreeNode curnode = tree.poll();
int temp = treeVal.poll();
if(curnode.left==null && curnode.right == null){
if(temp == targetSum){
return true;
}
continue;
}
if(curnode.left!=null){
tree.offer(curnode.left);
treeVal.offer(temp+curnode.left.val);
}
if(curnode.right!=null){
tree.offer(curnode.right);
treeVal.offer(temp+curnode.right.val);
}
}
return false;
}
}
复杂度分析
时间复杂度:O(N),其中 N 是树的节点数。对每个节点访问一次。
空间复杂度:O(N),其中 N 是树的节点数。空间复杂度主要取决于队列的开销,队列中的元素个数不会超过树的节点数。
方法二:递归
思路及算法
观察要求我们完成的函数,我们可以归纳出它的功能:询问是否存在从当前节点 root 到叶子节点的路径,满足其路径和为 sum。
假定从根节点到当前节点的值之和为 val,我们可以将这个大问题转化为一个小问题:是否存在从当前节点的子节点到叶子的路径,满足其路径和为 sum - val。
不难发现这满足递归的性质,若当前节点就是叶子节点,那么我们直接判断 sum 是否等于 val 即可(因为路径和已经确定,就是当前节点的值,我们只需要判断该路径和是否满足条件)。若当前节点不是叶子节点,我们只需要递归地询问它的子节点是否能满足条件即可。
class Solution {
public boolean hasPathSum(TreeNode root, int targetSum) {
dfs
if(root == null){
return false ;
}
if(root.left == null && root.right ==null){
return targetSum == root.val;
}else{
return hasPathSum(root.left,targetSum-root.val) ||
hasPathSum(root.right,targetSum-root.val);
}
}
复杂度分析
时间复杂度:O(N),其中 N 是树的节点数。对每个节点访问一次。
空间复杂度:O(H),其中 H 是树的高度。空间复杂度主要取决于递归时栈空间的开销,最坏情况下,树呈现链状,空间复杂度为 O(N)。平均情况下树的高度与节点数的对数正相关,空间复杂度为 O(log N)。

若有收获,就点个赞吧
0 人点赞
