简单爬虫架构
URL管理器
防止重复抓取、循环抓取
功能:添加、判断已存在
存储:1.内存(set)2.关系数据库(mysql)3.缓存数据库(redis)
网页下载器
下载并存储
urllib2
(注意:python3中将urllib2合并到urllib,并且需要import urllib.request)
urllib2被合并到了urllib中,叫做urllib.request 和 urllib.error
urllib整个模块分为urllib.request, urllib.parse, urllib.error
例:
其中urllib2.urlopen()变成了urllib.request.urlopen()
urllib2.Request()变成了urllib.request.Request()
import urllib.requestresponse=urllib.request.urlopen('www.xxx.com')print response.getcode() #状态码 200则成功response.read() #读取#添加 data http headerimport urllib.request#创建request对象request=urllib.request.Request(url)#添加数据request.add_data('','')#添加headerrequest.add_header('','')response=urllib.request.urlopen(request)'#添加特殊情景的处理器'#登陆才能访问,使用cookie的处理HTTPCookieProcessor#需要代理才能访问ProxyHandler#使用https加密访问HTTPSHandler#URL处于相互的自动的跳转关系HTTPRedirectHandleropener=urllib.request.build_opener(handler) #建立openerurllib.request.install_opener(opener) #将opener添加给urllib2import urllibfrom http import cookiejarcj=cookiejar.CookieJar()#创建cookie容器opener=urllib.build_opener(urllib.HTTPCookieProcessor(cj)) #以cookiejar作为参数生成一个handler,之后生成一个openerurllib.install_opener(opener)#安装给urllib2response=urllib.urlopen('www.xxx.com')
例
import urllib.requestfrom http import cookiejarurl='http://www.baidu.com'cj=cookiejar.CookieJar()opener=urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))urllib.request.install_opener(opener)response=urllib.request.urlopen(url)print(response.getcode())print(response.read())print(cj)
网页解析器
从网页中提取出有价值数据的工具
1.正则表达式 2.parser *3.Beautiful soup 4.lxml
1为模糊匹配 234为结构化解析
结构化解析DOM(document object model)树
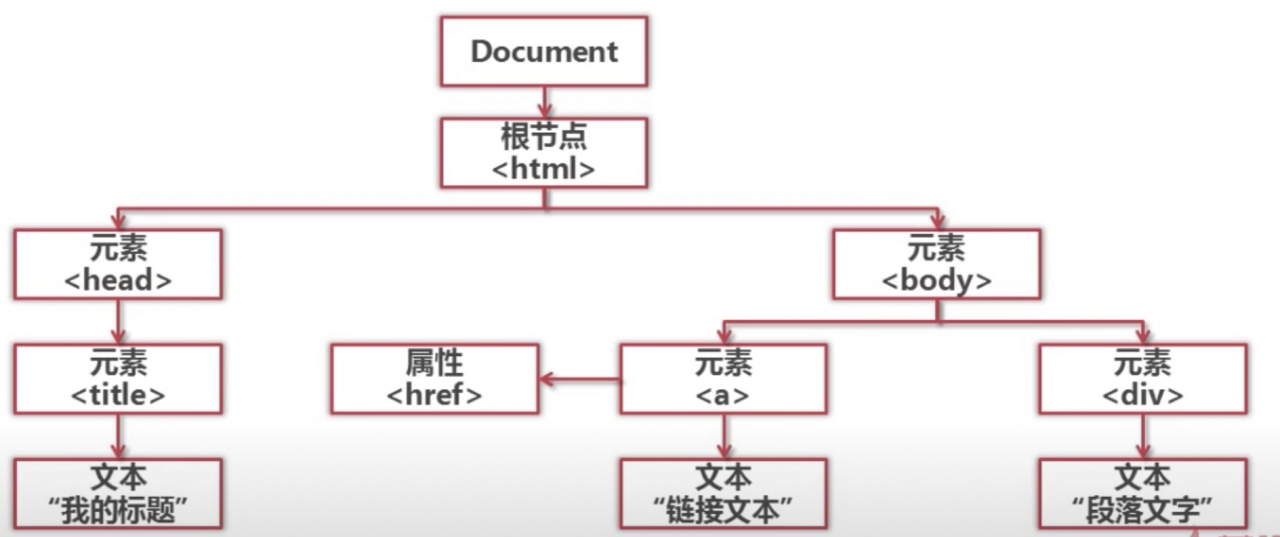
beautifulsoup4
nanaconda prompt conda install beautifulsoup4
conda info —env 查看子环境
#对一个html网页创建beautifulsoup对象,生成一DOM树,搜索节点,访问节点(名称、属性、文字)from bs4 import BeautifulSoupsoup=BeautifulSoup(html_doc, #文档字符串'html.parser' #解析器from_encoding='utf-8' #文档编码)#find_all(name,attrs,string)选择填写nodes=soup.find_all('a',href='/view/123.htm',string='python')from node in nodes:#node.name获取标签名称,node['herf']获取herf属性(字典),node.get_text() 查找链接文字
例:
from bs4 import BeautifulSouphtml_doc="""<a onmousedown="return c({'fm':'tab','tab':'video'})" href="/sf/vsearch?pd=video&tn=vsearch&lid=e4c8f65b00018878&ie=utf-8&wd=VS+code+No+module+named+%27beautifulsoup4%27&rsv_spt=7&rsv_bp=1&f=8&oq=VS+code+No+module+named+%27beautifulsoup4%27&rsv_pq=e4c8f65b00018878&rsv_t=742aR1%2FxH%2F8MCg4mll4MCdK4%2BRscvYOCJEBpeIT4XTGmIJ%2BN6kG5n75oV1BoxJ9HxWYqsQ">瑙嗛</a><a onmousedown="return c({'fm':'tab','tab':'news'})" href="https://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&word=VS+code+No+module+named+%27beautifulsoup4%27" sync="true" wdfield="word">璧勮</a>"""soup=BeautifulSoup(html_doc,'html.parser',from_encoding='utf-8')links=soup.find_all('a')for link in links:print(link.get_text())

若有收获,就点个赞吧
0 人点赞
