通常用于对一段文本进行替换、检索或提取等操作
import re
示例
对输入的邮箱值进行校验
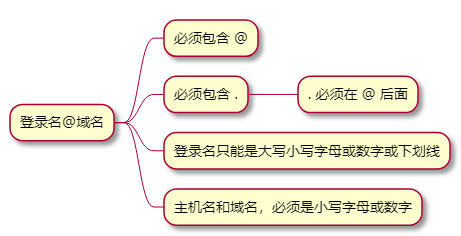
import reregex = r'^[0-9a-z]+\w*@([0-9a-z]+\.)+[0-9a-z]+$'email = 'luBan2019@sina.com'matchObj = re.match(regex, email)if matchObj:print('匹配的内容:' + matchObj.group())else:print("没有匹配的内容")
\s 匹配任何空白字符g \S匹配任何非空白字符
使用字符表达式 regex = r’^+86$’ 校验字符串的开头和结尾
^ 表示字符串的开头 ¥$ 表示字符串的结尾
- 是因为加号也是一个表达式 +表示加号本身
单词字符相关表达式

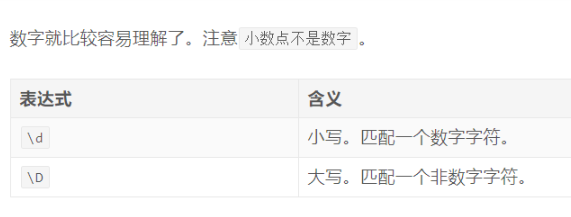
数字相关表达式
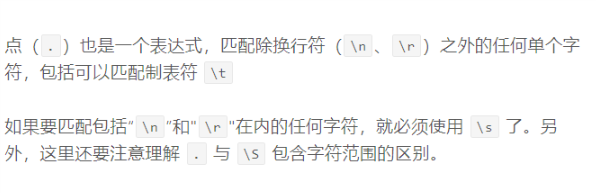
点表达式
逻辑或
regex = r’^13|14|15|16|17|18|19’
子表达式
regex = r’^(13(4|5|6|7|8|9)$)’ 表示有着相同的前缀,不同的只是第三个数字 regex = r’[1]‘ 表示只能是数字 英文字母大小写开头
排除范围
在中括号内,用^来表示排除范围
限定符表达式
可限定出现的次数


非贪婪模式
在一般限定符或范围限定符后面加?
单次检索
re.search(regex, text) '检索全文,返回第一个're.match(regex, text) '检查文本的开头'matchObj.group() '调用结果的对象'
索引
matchObj.start() '调用返回对象的索引 从0开始计算 取第一个结果对象的首字符'matchObj.end() '从1开始计算 取第一个结果的末字符 'matchObj.span() '返回元组 包含两个数据'
全量检索
re.findall(regex, text) 返回列表
迭代器
import reline = 'I love dogs cats and others'regex = r'\w+\s'matchObjs = re.finditer(regex, line)for matchObj in matchObjs :print(matchObj.group() + ' start=' + str(matchObj.start()) + ' end=' + str(matchObj.end()))#所有结果I start=0 end=2love start=2 end=7dogs start=7 end=12cats start=12 end=17and start=17 end=21
替换
re.sub(pattern, repl, sourceText, count) 'count是最大替换次数,可以不写,不写默认全部替换''正则表达式,替换后字符,源文件'
import retext = "2019-11-23"## 替换所有的非数字的字符,兼容性好regex = r'\D'## 全部替换targetText = re.sub(regex, '/', text)print('日期:' + targetText)
预编译
re.compile(regex) 返回值是pattern对象import retext = "2019-11-23"## 替换所有的非数字的字符,兼容性好regex = r'\D'## 编译一次pattern = re.compile(regex)matchObjs = pattern.findall(text)print(matchObjs)targetText = pattern.sub('/', text)print('日期:' + targetText)
分组
对于返回的结果对象调用分组的方法
1.返回整体结果 matchObj.group()
2.指定分组 接受正整数参数 group(1)第一个子表达式
3.全部分组 groups() 返回一个元组 包含所有分组的字符串
实战
网页爬取
提取新闻链接
import reimport requests## 抓取页面response = requests.get('https://news.sina.com.cn/')content = response.textprint(content)## 扫描 <a>xxx</a> 标签,这是新闻链接aTagRegex = r"<a.+?/a>"aTagPattern = re.compile(aTagRegex);matchs = aTagPattern.findall(content)for matchStr in matchs:print(matchStr)
import reimport requests## 抓取页面response = requests.get('https://news.sina.com.cn/')response.encoding = 'utf-8'content = response.text## 扫描 <a>xxx</a> 标签,这是新闻链接aTagRegex = r"<a.+?/a>"aTagPattern = re.compile(aTagRegex);## 网址正则表达式linkRegex = r"href=\"(.+?)\""linkPattern = re.compile(linkRegex);## 标题正则表达式titleRegex = r">(.+)<"titlePattern = re.compile(titleRegex);matchs = aTagPattern.findall(content)for matchStr in matchs:print(matchStr)## 解析网址matchLinkObj = linkPattern.search(matchStr)if matchLinkObj :print(matchLinkObj.groups()[0])## 解析标题matchTitleObj = titlePattern.search(matchStr)if matchTitleObj :print(matchTitleObj.groups()[0])print('')
- a-zA-Z0-9 ↩︎

若有收获,就点个赞吧
0 人点赞
