根据url返回不同的文件
import * as http from "http";import { IncomingMessage, ServerResponse } from "http";import * as fs from "fs";import * as p from "path";// __dirname 表示当前文件所在目录const server = http.createServer();const publicDir = p.resolve(__dirname, "public");// path.resolve() 传入路径或路径片段,解析为绝对路径server.on("request", (request: IncomingMessage, response: ServerResponse) => {const { method, url, headers } = request;switch (url) {case "/index.html":response.setHeader("Content-Type", "text/html; chartset=utf-8");fs.readFile(p.resolve(publicDir, "index.html"), (error, data) => {if (error) throw error;response.end(data.toString());});break;case "/style.css":response.setHeader("Content-Type", "text/css; charset=utf-8");fs.readFile(p.resolve(publicDir, "style.css"), (error, data) => {if (error) throw error;response.end(data.toString());});break;case "/main.js":response.setHeader("Content-Type", "text/javascript; charset=utf-8");fs.readFile(p.resolve(publicDir, "main.js"), (error, data) => {if (error) throw error;response.end(data.toString());});break;}});server.listen(8888);
处理查询参数
使用url.parse
The url.parse() method takes a URL string, parses it, and returns a URL object.
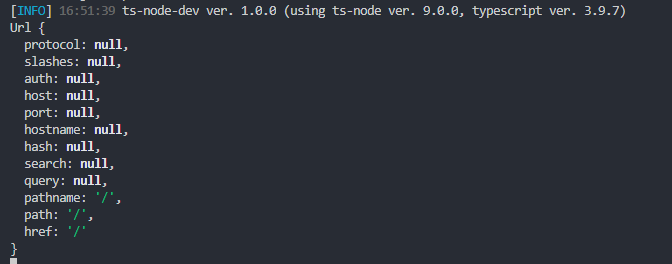
import * as url from "url";server.on("request", (request: IncomingMessage, response: ServerResponse) => {const { method, url: path, headers } = request;const { pathname, search } = url.parse(path);})这样就可以得到path的所有信息可以打印出来看看console.log(url.parse(path))
匹配任意文件
const server = http.createServer();const publicDir = p.resolve(__dirname, "public");// path.resolve() 传入路径或路径片段,解析为绝对路径server.on("request", (request: IncomingMessage, response: ServerResponse) => {const { method, url: path, headers } = request;const { pathname, search } = url.parse(path);console.log(url.parse(path));// response.setHeader("Content-Type", "text/html; chartset=utf-8");// /index.html => index.htmlconst fileName = pathname.substr(1);fs.readFile(p.resolve(publicDir, fileName), (error, data) => {if (error) {response.statusCode = 404;response.end(`你要的文件不存在`);} else {response.end(data.toString());}});});server.listen(8888);
将之前的switch修改,封装成一个方法,在publicDir目录下的文件都能匹配到。
fileName是去掉pathname前面的‘/’得到的
处理非GET请求以及文件缓存
处理非GET请求,因为是静态服务器,所以直接给他返回个405就好
if (method !== "GET") {response.statusCode = 405;response.end();return;}
文件缓存通过设置响应头的Cache-Control属性实现
response.setHeader("Cache-Control", `public, max-age=${catchAge}`);response.end(data.toString());
完整代码
import * as http from "http";import { IncomingMessage, ServerResponse } from "http";import * as fs from "fs";import * as p from "path";import * as url from "url";// __dirname 表示当前文件所在目录const server = http.createServer();const publicDir = p.resolve(__dirname, "public");// path.resolve() 传入路径或路径片段,解析为绝对路径let catchAge = 3600 * 24 * 365;server.on("request", (request: IncomingMessage, response: ServerResponse) => {const { method, url: path, headers } = request;const { pathname, search } = url.parse(path);// 处理非GET请求,因为是静态服务器,直接不允许访问了if (method !== "GET") {response.statusCode = 405;response.end();return;}// response.setHeader("Content-Type", "text/html; chartset=utf-8");// /index.html => index.htmllet fileName = pathname.substr(1);if (fileName === "") {fileName = "index.html";}fs.readFile(p.resolve(publicDir, fileName), (error, data) => {if (error) {if (error.errno === -4058) {response.statusCode = 404;fs.readFile(p.resolve(publicDir, "404.html"), (error, data) => {response.end(data);});response.end(`你要的文件不存在`);} else if (error.errno === -4068) {response.statusCode = 403;response.end("无权查看目录内容");} else {response.statusCode = 500;response.end(`服务器繁忙,请稍后重试`);}} else {// 返回文件内容// 缓存文件内容 + 时长:31536000s// 浏览器是不会帮你缓存首页的,即使你设置了缓存response.setHeader("Cache-Control", `public, max-age=${catchAge}`);response.end(data.toString());}});});server.listen(8888);

若有收获,就点个赞吧
0 人点赞
