缓存字段
如何获取博客的评论数
- 数一下评论的id
- select count(id) from comments where blog_id=8
- 把对应id为8的博客的评论都数一下,返回出来
如果有很多篇博客,很多评论,这样数太慢了
可不可以在blog表上叫一个comment_count字段
每次添加comment则+1,每次删除comment则-1
这样是可以的,可以快速的去获取评论数
这个方法经常用在项目里面,而且我们约定所有这种缓存,都以下划线_count作为结尾
这就涉及到了事务
事务
有些操作必须一次完成
- 用户评论之后,要做两件事
- 第一步,在comments表新增记录
- 第二部,在blogs表将对应的comment_count +1
- 如果第一步执行了,第二步没有执行,数据就乱了
可以使用事务解决上面的问题
语法:
start transaction;语句1; 语句2; 语句3;commit;
以上 只要一句出错,则全都不生效。
所以我们要把 上面的第一步放在语句1,第二步放在语句2,这样的话,要么都成功,要么都失败
菜鸟教程https://www.runoob.com/mysql/mysql-index.html
MySQL存储引擎
- 命令 SHOW ENGINES;
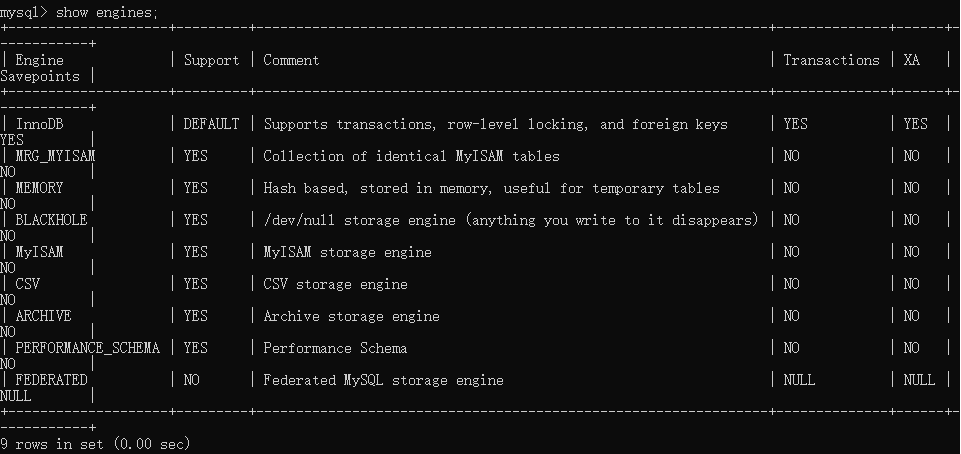
常见的
- InnoDB - 默认,目前版本是新版的InnoDB
- MyISAM - 拥有较高的插入、查询速度,但不支持事务
- Memory - 内存中,快速访问数据 (速度非常快)
- Archive - 只支持insert和select
每种都有不同的特点和优势,一般最常见的就是InnoDB
InnoDB
- InnoDB是事务型数据库的首选,支持事务、遵循ACID、支持行锁和外键
索引
语法
- CREATE UNIQUE INDEX index1 ON users(name(100))
UNIQUE是可以删掉的,如果是唯一性的就加UNIQUE,如果不是就不加
index1 : 索引名称
users:表名
name: 字段名
100 :长度
- show index in users;
显示users表的所有索引
菜鸟教程,挺不错的https://www.runoob.com/mysql/mysql-index.html
用途
提高搜索效率
where xxx>100 那么我们可以创建xxx的索引
下次搜索xxx>100的时候就会非常的快
- where xxx>100 and yyy>200,创建xxx,yyy共同组成的索引

若有收获,就点个赞吧
0 人点赞
