1.前言
条件查询作为es中最核心的功能,可以说是功能最为丰富了。es中为查询提供了丰富的api,接下来开始逐个学习
2.存入测试数据
PUT student/_bulk{ "index":{ "_id": 1 } }{ "name":"王乾雯","age":18,"dec":"she is so sex too","grade":33.8,"tages":[1,2,3]}{ "index":{ "_id": 2 } }{ "name":"宋可心","age":18,"dec":"she is so sex","grade":44.8,"tages":[2,2,3]}{ "index":{} }{ "name":"郭楠","age":22,"dec":"she is good at sex","grade":2.8,"tages":[1,2,6]}{ "index":{} }{ "name":"王可菲","age":17,"dec":"she is so beautiful","grade":4.8,"tages":[6,5,3]}{ "index":{} }{ "name":"冯铁城","age":18,"dec":"he is so cool","grade":100,"tages":[4,4,3]}{ "index":{} }{ "name":"王彦舒","age":17,"dec":"she is so cute","grade":1.22,"tages":[5,8,3]}{ "index":{} }{ "name":"宁娜","age":17,"dec":"her feet is so sex!on my god!!!!","grade":55.22,"tages":[5,7,3]}{ "index":{} }{ "name":"lulu","age":17,"dec":"her feet is so sex!i want fuck her","grade":78.13,"tages":[3,2,3]}
3.无查询条件
GET ${indexName},${indexName}…/_search(PS:可以在一个路由中指定多个索引统一查询返回)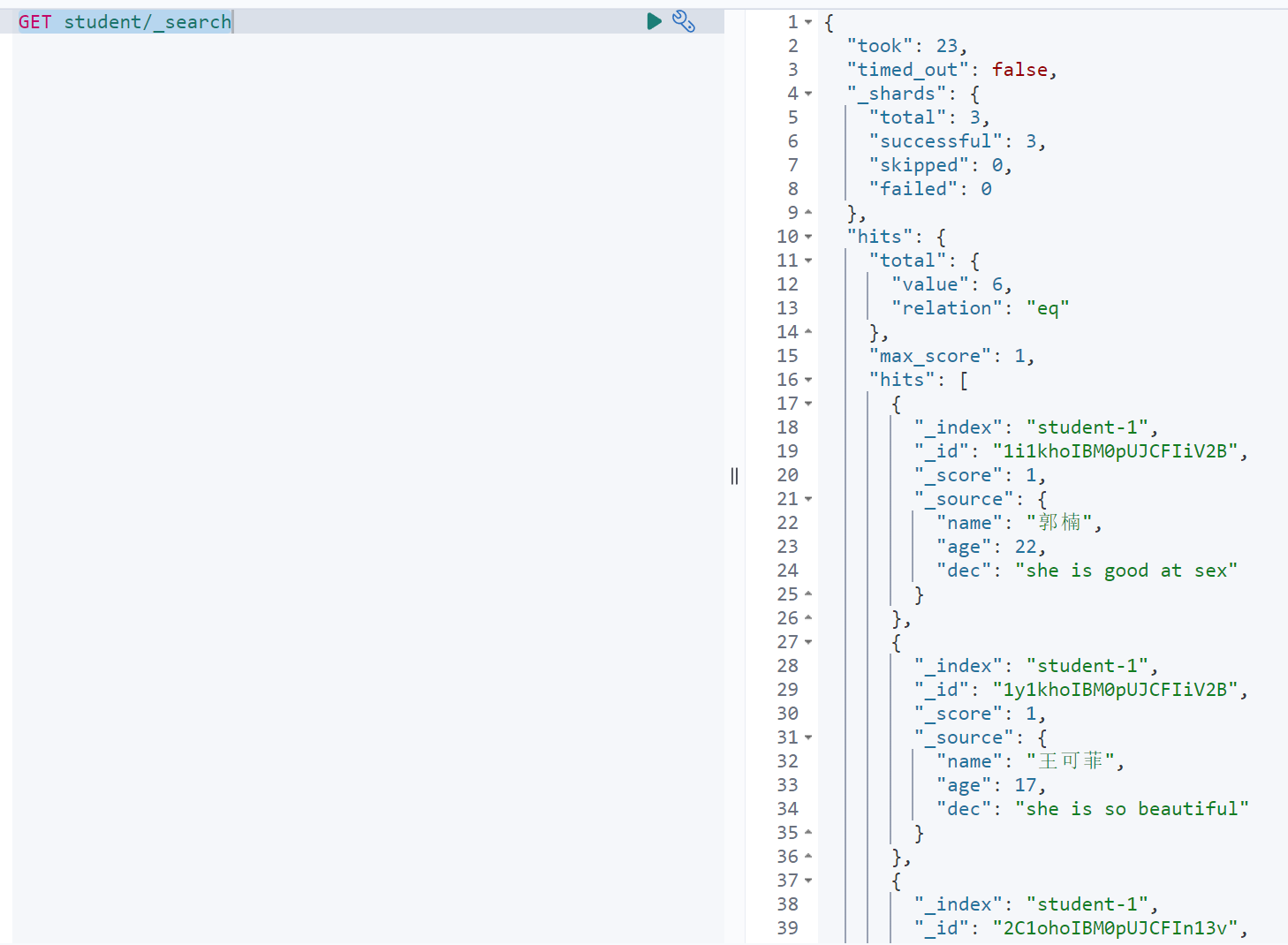
返回字段说明
示例:
{"took":1,"timed_out":false,"_shards":{"total":3,"successful":3,"skipped":0,"failed":0},"hits":{"total":{"value":2,"relation":"eq"},"max_score":1,"hits":[{"_index":"student-1","_id":"2","_score":1,"_source":{"name":"zyl","age":2,"des":"i am a girl"}},{"_index":"student-1","_id":"1","_score":1,"_source":{"name":"冯铁城","age":12,"des":"i am a boy"}}]}}
说明
{"took":"查询花费时间,单位毫秒","timed_out":"是否超时","_shards":{"total":"分片信息.总数","successful":"分片信息.执行成功分片","skipped":"分片信息.执行忽略分片","failed":"分片信息.执行失败分片"},"hits":{"total":{"value":"搜索条件匹配的文档总数.总命中计数的值","relation":"搜索条件匹配的文档总数.计数规则:(eq计数准确/gte计数不准确)"},"max_score":"最大匹配度分值","hits":[{"_index":"命中结果索引","_id":"命中结果ID","_score":"命中结果分数","_source":"命中结果原文档信息"}]}}
4.基础分页查询
命令格式
es中通过参数size和from来进行基础分页的控制
- from:类似于mongo中的skip,指定跳过多少条数据
- size:类似于mongo中的limit,指定返回多少条数据
示例:
- url参数
GET student/_search?from=4&size=2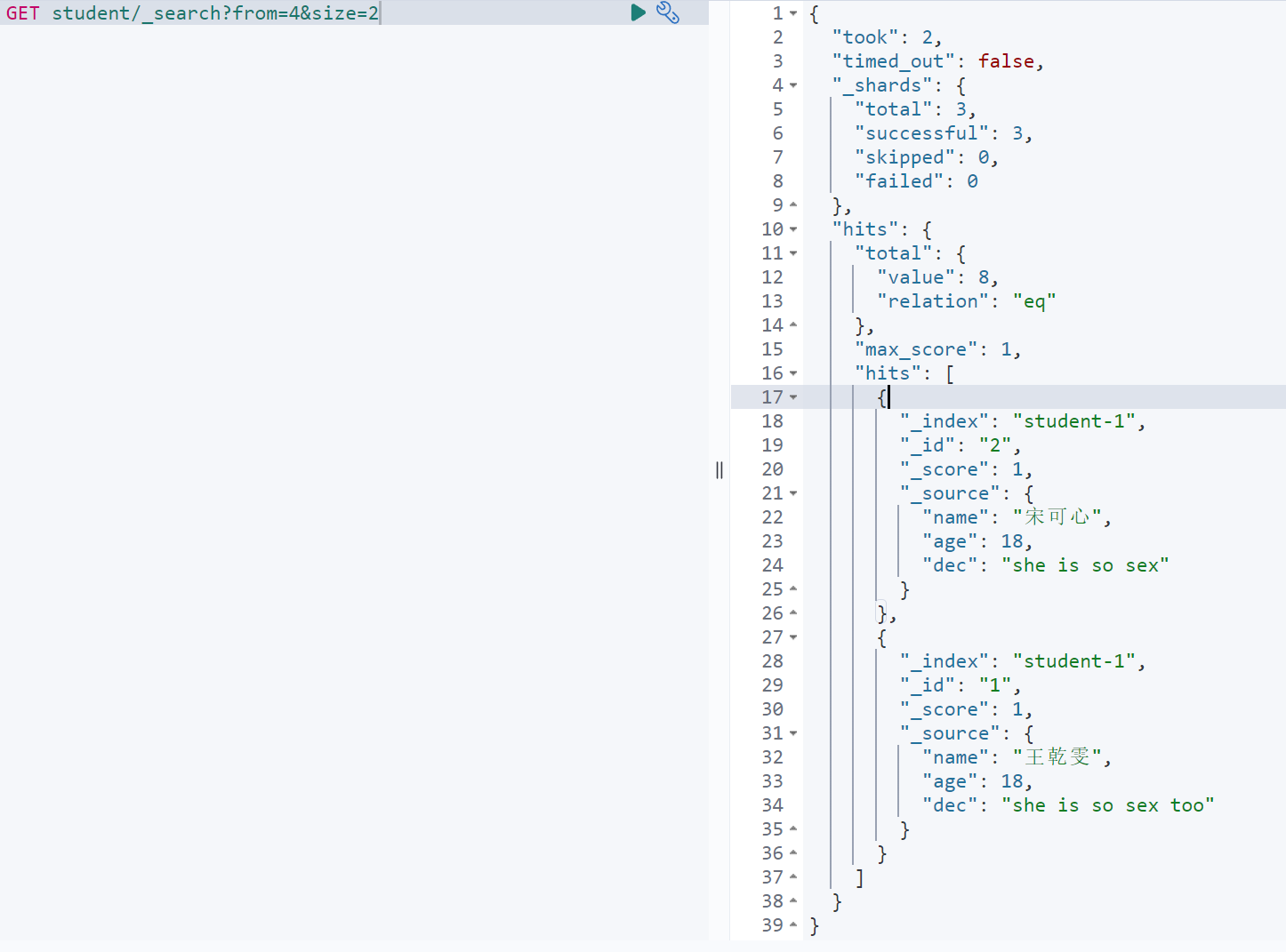
body参数
GET student/_search{"from": 0,"size": 20}
原理
es中的基础分页功能,在数据量较小时,还是可用的。但是一旦数据量递增,那么查询效率将直线下降
因为es中分页查询的步骤是如下步骤假定当前索引包含3个分片,默认size=10,假设查询到第1000页时,那么代表需要获取第10000~10010条数据
- 客户端发送请求到协调节点
- 协调节点将请求转发到所有分片
- 每个分片获查询本地分片的10010条数据,返回给协调节点
- 协调节点收到每个分片的响应,共计30030条数据。然后进行统一排序,最后丢弃掉30020条数据,
- 协调节点返回给客户端最后10条数据
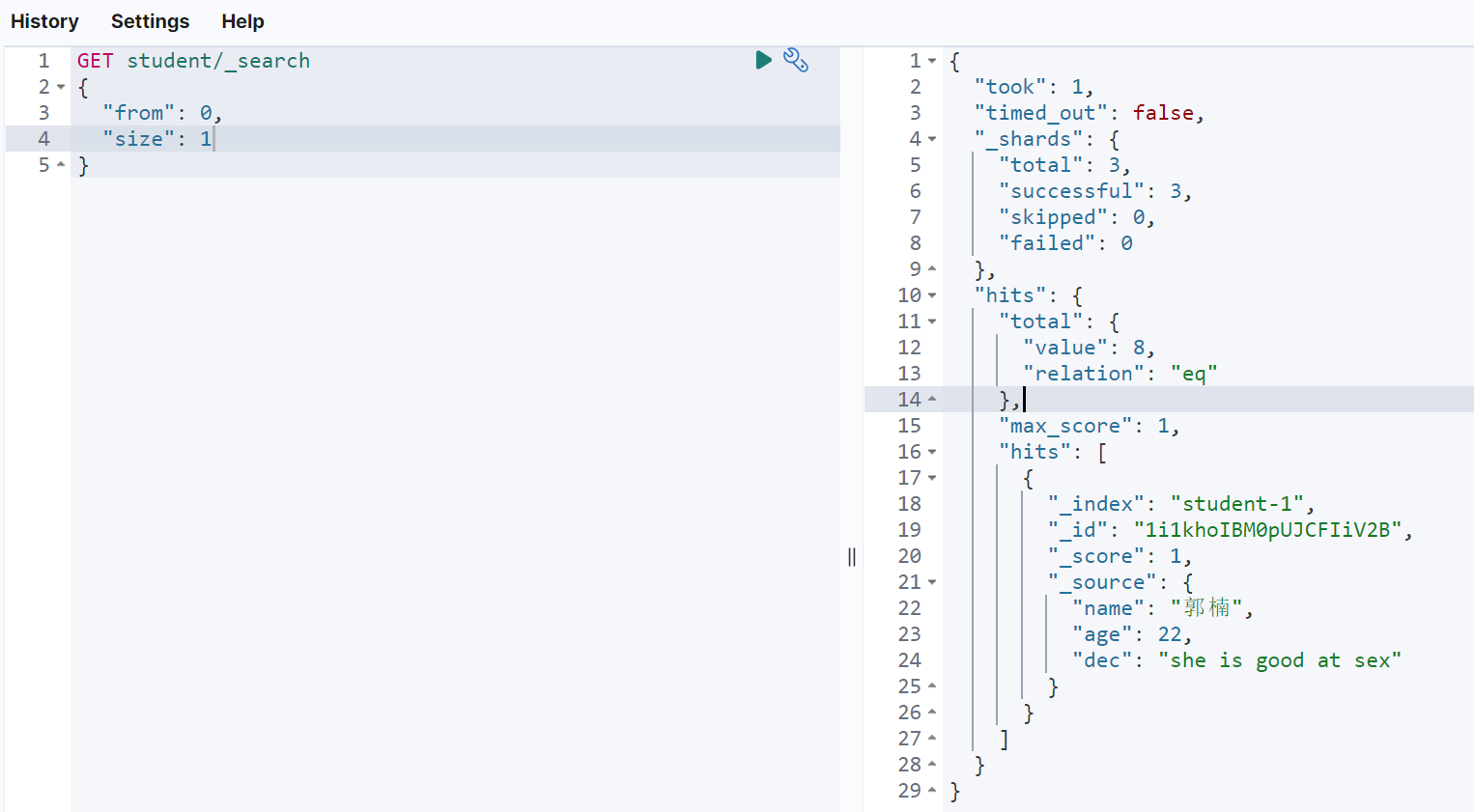
很明显,分片越多,页数越大,协调节点最后进行数据排序返回的工作量越大。因此,基于线性递增情况,不建议使用from和size模式进行大数据量的分页查询。
es中允许fromsize最大分页页数为1000
5.常用的条件查询
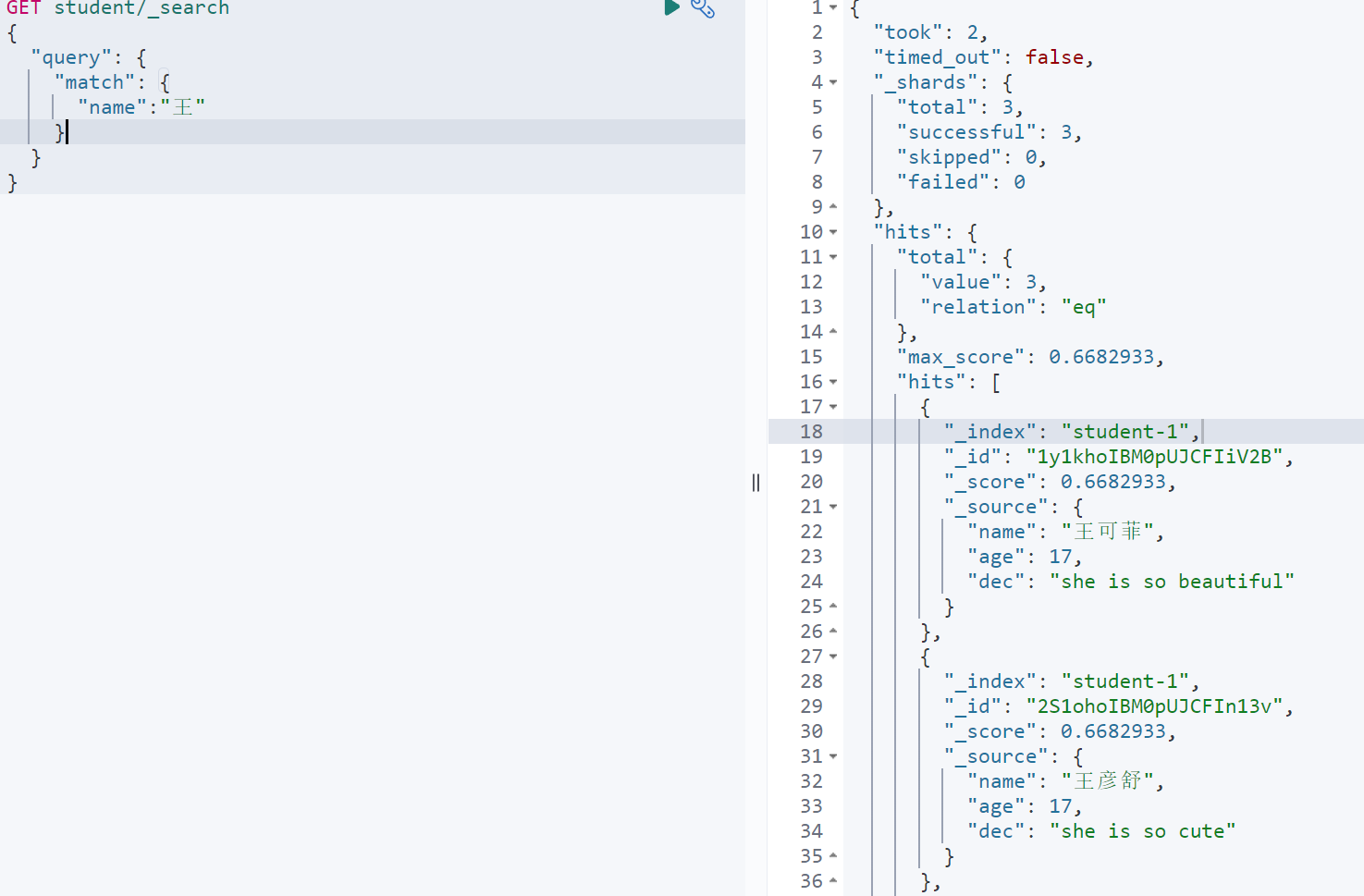
单字段全文索引查询
使用query.match进行查询。match适用与对单个字段基于全文索引进行数据检索。对于全文字段,match使用特定的分词进行全文检索。而对于那些精确值,match同样可以进行精确匹配
GET student/_search{"query": {"match": {"name":"王"}}}
单字段不分词查询
使用query.match_phrase进行查询。
可以类比match进行理解,match查询短语时,会对短语进行分词,再针对每个词条进行全文检索。
GET student/_search{"query": {"match_phrase": {"dec": "so sex"}}}
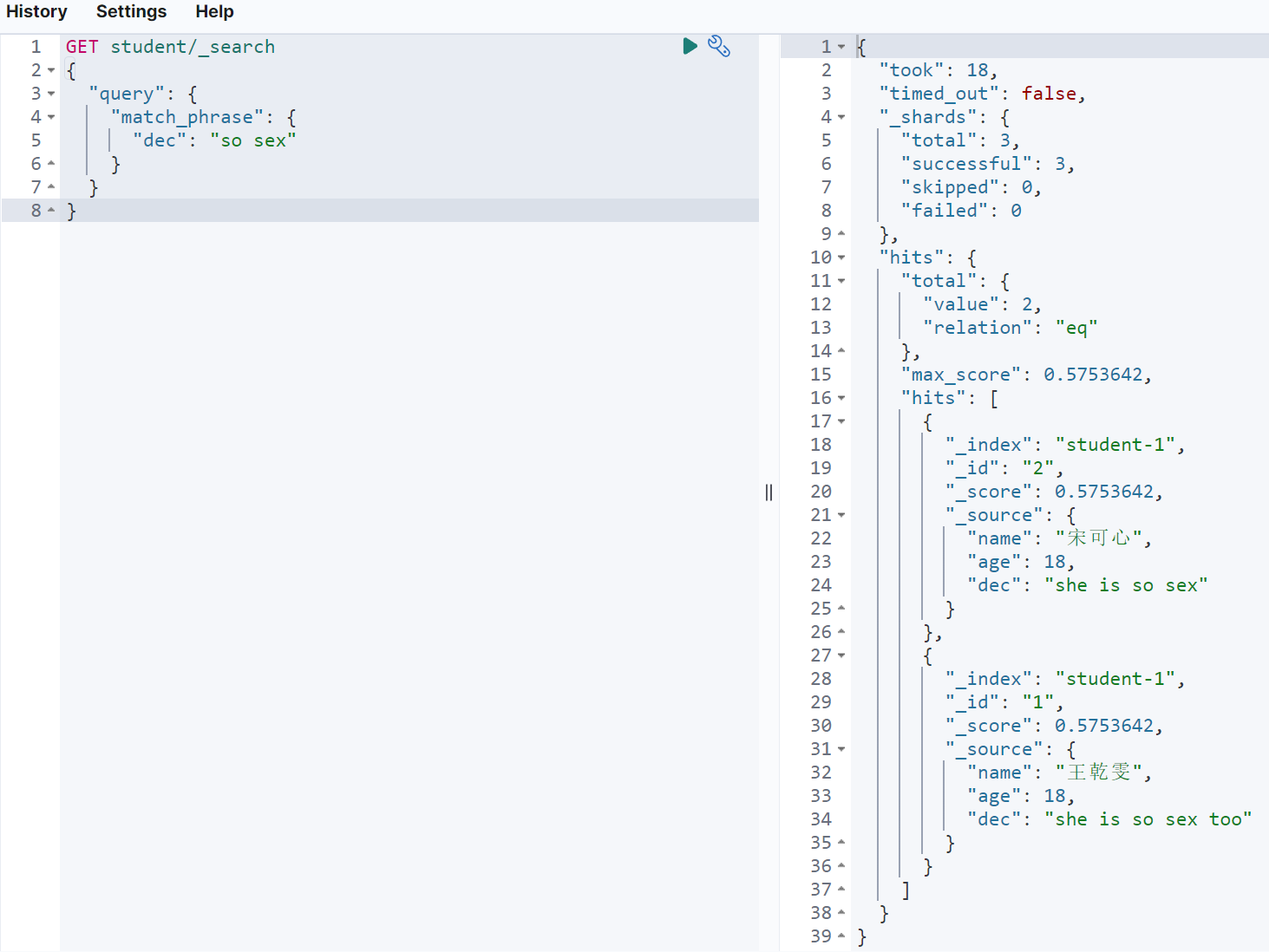
多字段全文索引查询
相当于对多个字段执行了match查询
GET student/_search{"query": {"multi_match": {"query": "so sex too","fields": ["name","dec"]}}}
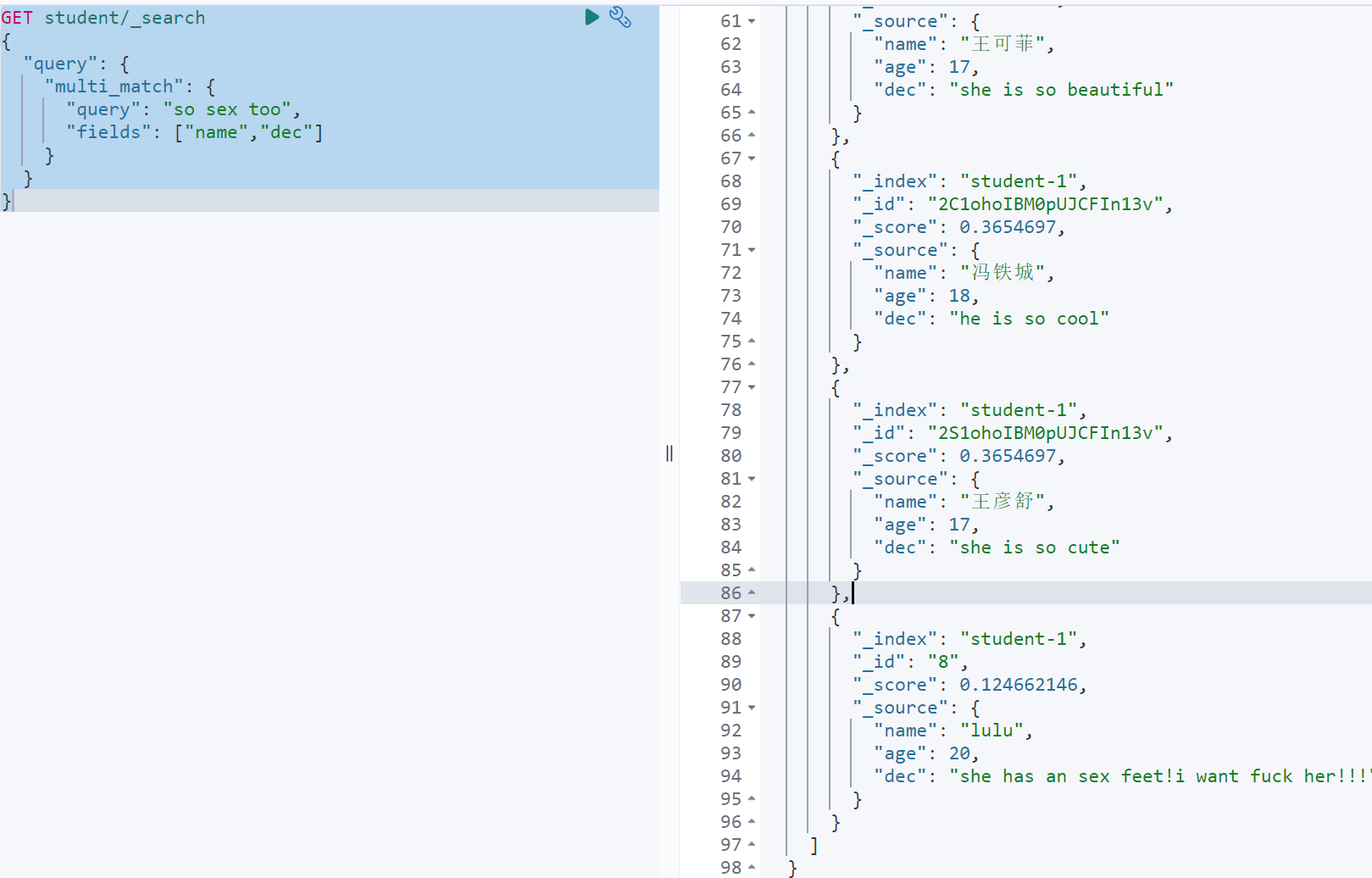
范围查询
使用range来进行范围查询,适用于数组,时间等字段
GET student/_search{"query": {"range": {"age": {"gt": 17,"lt": 19}}}}
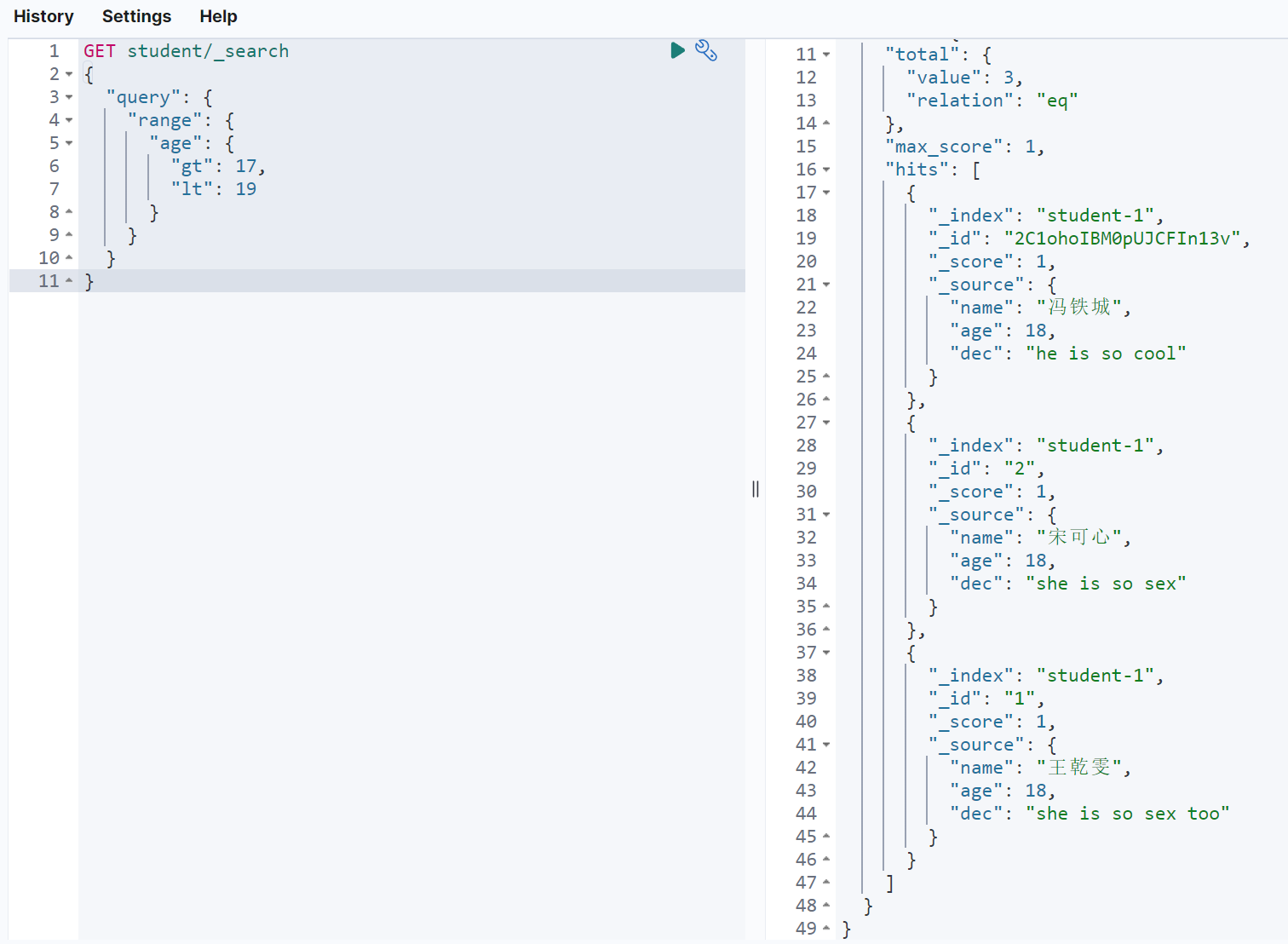
单字段精确查询
使用term进行非分词字段的精确查询。需要注意的是,对于那些分词的字段,即使查询的value是一个完全匹配的短语,也无法完成查询
GET student/_search{"query": {"term": {"age": {"value": "17"}}}}
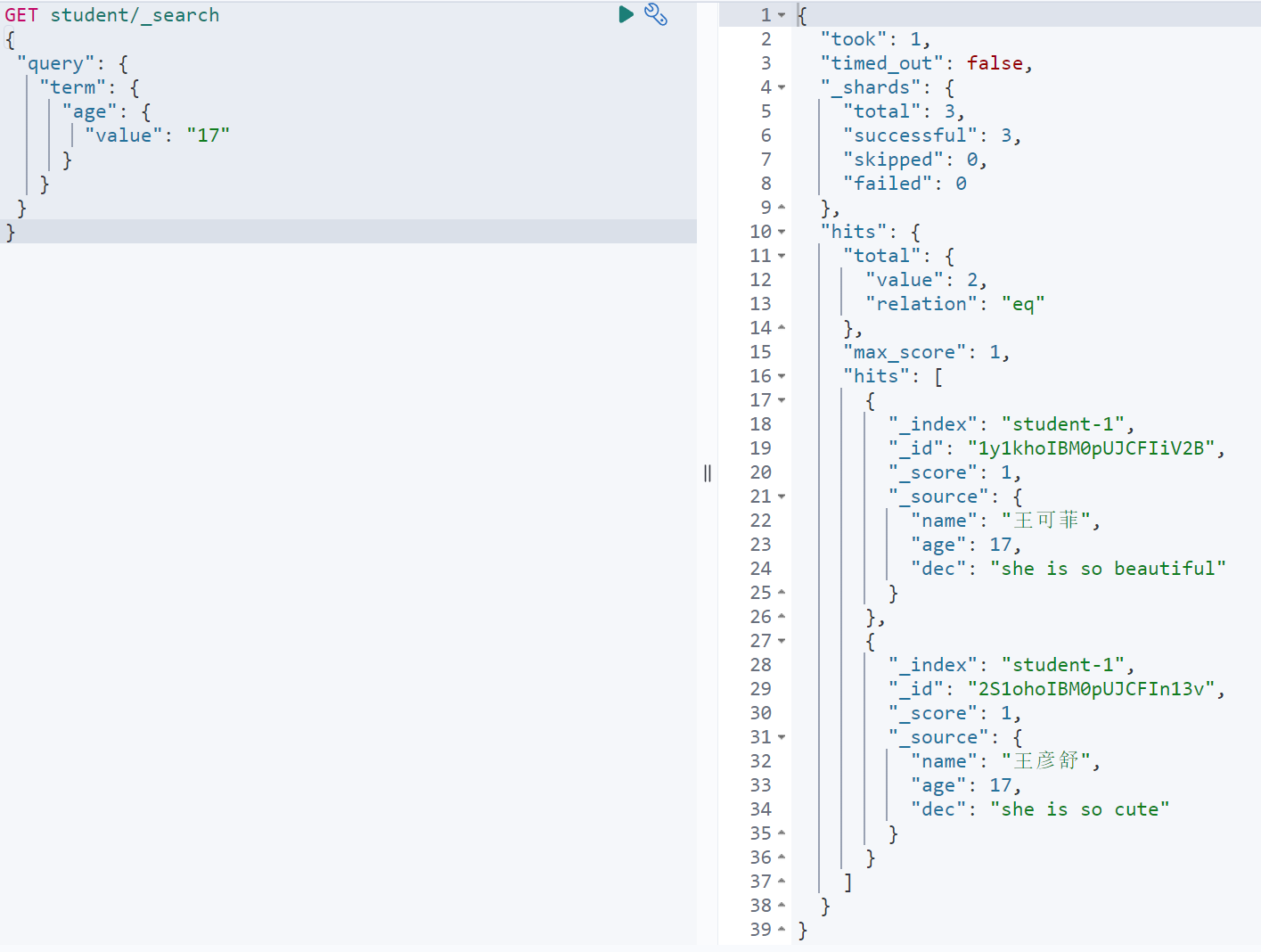
多字段精确查询
与term一样。区别在于可以匹配一个字段的多个值,满足一个即检索成功
GET student/_search{"query": {"terms": {"age": [17,18]}}}
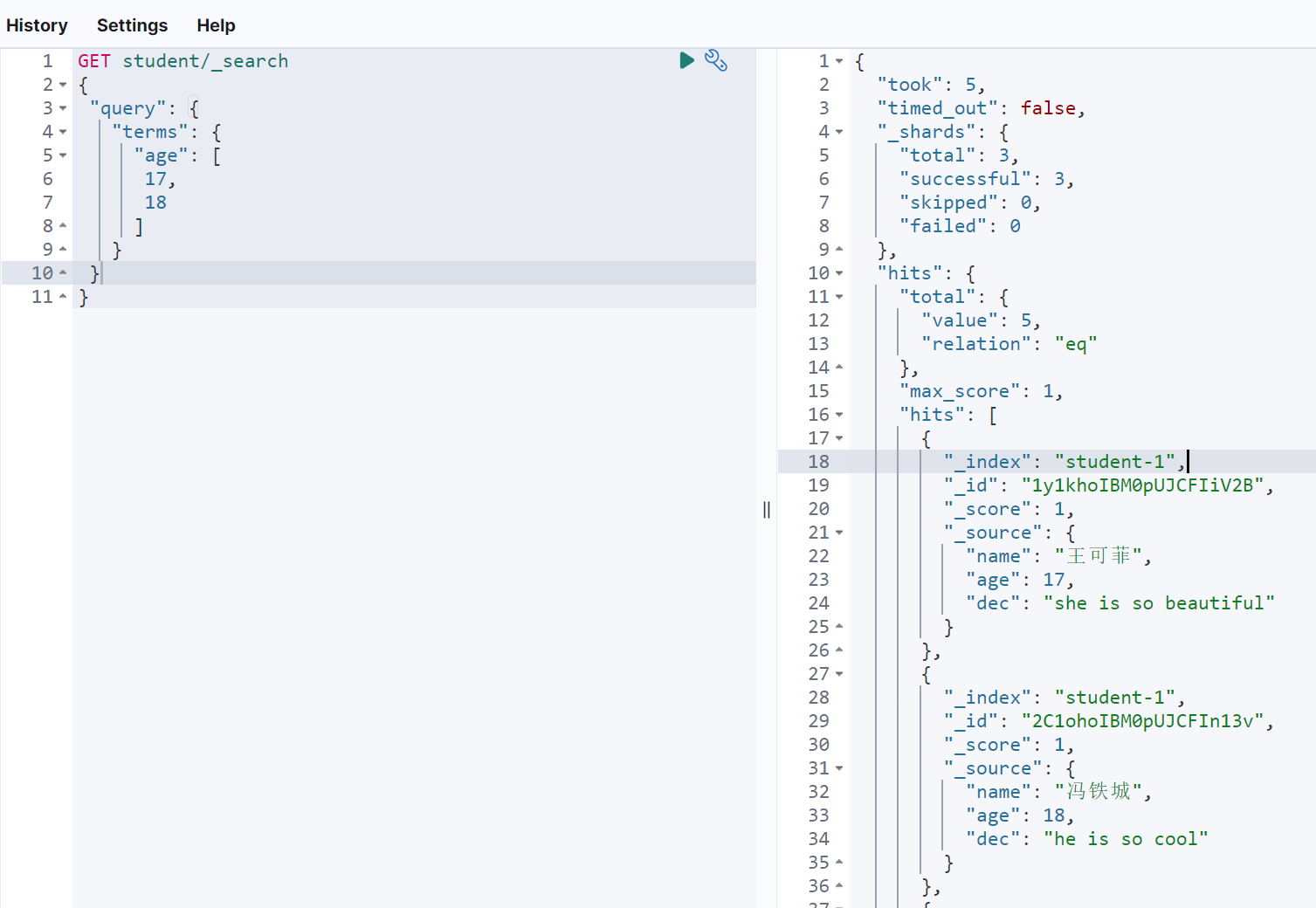
文档包含字段查询
因为es的数据是基于文档存储的,文档的持久化形式为json,json的特点就是灵活且no schema。因此,理论上,一个索引中,文档的字段格式可以完全不同。当然为了提高查询效率,尽可能的避免稀疏索引的出现,还是建议一个索引中的文档格式一致。
为了确定当前索引有哪些文档包含了对应的字段,es中使用exists来实现。(PS:本来还有个missing,但是在8.3版本没有了)
GET student/_search{"query": {"exists": {"field": "name"}}}
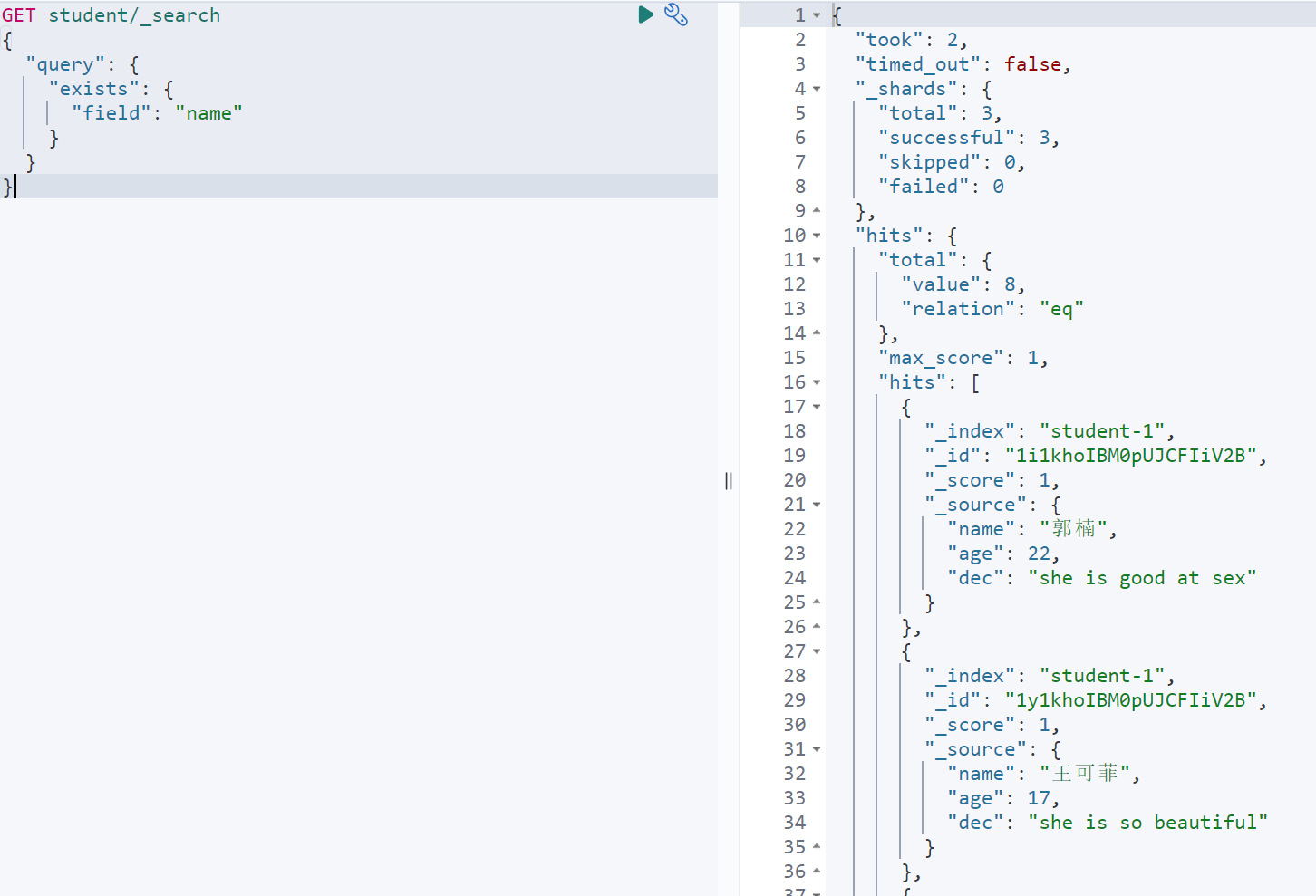
6.多条件组合查询
bool关键字
es中使用bool来控制多条件查询,bool查询支持以下参数
- must:被查询的数据必须满足当前条件
- mush_not:被查询的数据必须不满足当前条件
- should:被查询的数据应该满足当前条件。should查询被用于修正查询结果的评分。需要注意的是,如果组合查询中没有must,那么被查询的数据至少要匹配一条should。如果有mush语句,那么就无须匹配should,should将完全用于修正查询结果的评分
- filter:被查询的数据必须满足当前条件,但是filter操作不涉及查询结果评分。仅用于条件过滤
示例:
GET student/_search{"query": {"bool": {"must": [{"match": {"dec": "she is"}}],"must_not": [{"term": {"age": {"value": "18"}}}],"should": [{"match": {"name": "lu"}}],"filter": [{"range": {"age": {"gte": 18,"lte": 30}}}]}}}
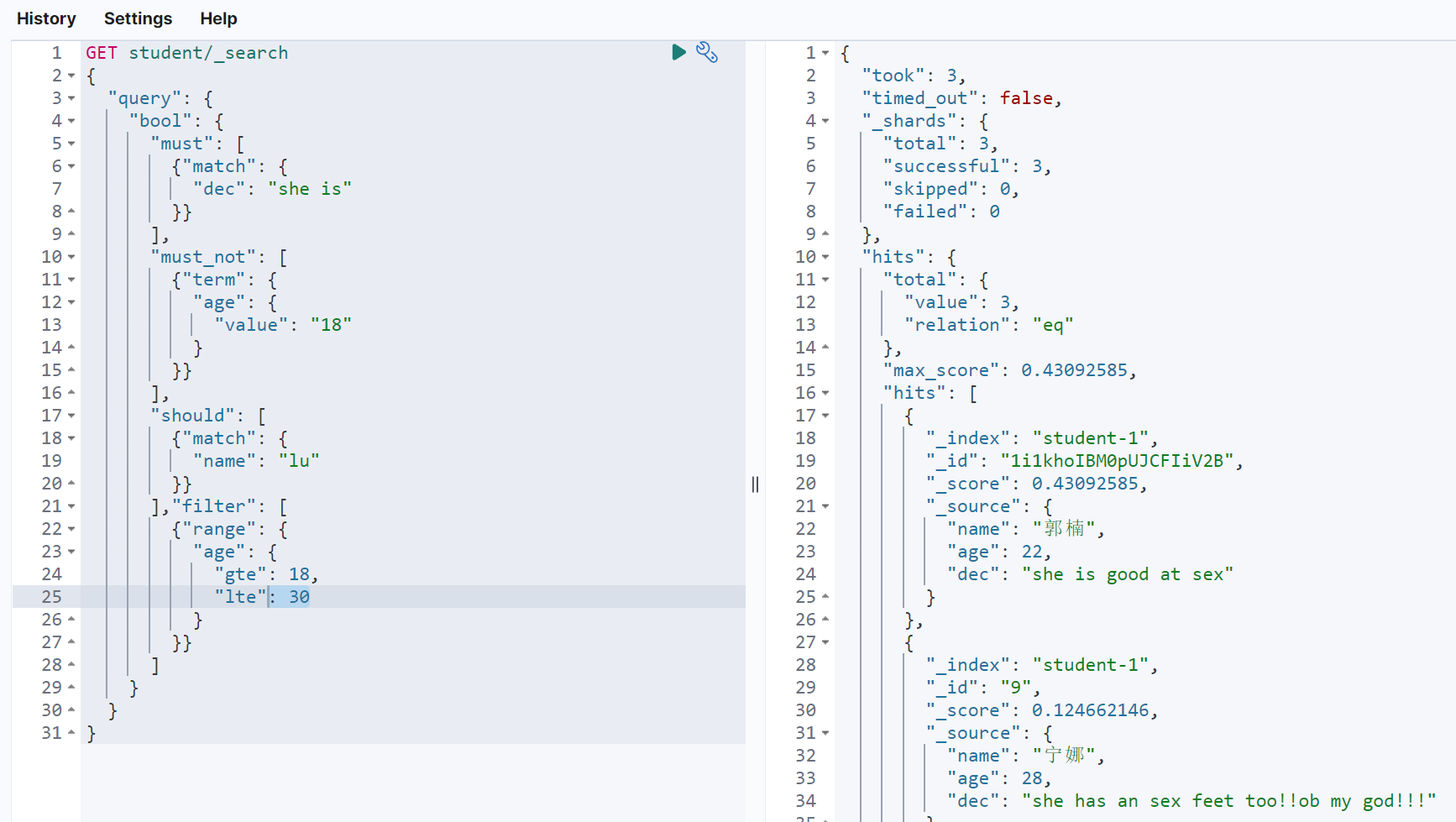
constant_score关键字
constant_score查询可以通过boost指定一个固定的评分,通常来说,constant_score的作用是代替一个只有filter的bool查询
示例:
GET student/_search{"query": {"constant_score": {"filter": {"term": {"age": 18}},"boost": 1.2}}}

7.查询验证与分析
验证
es中通过/_validate/query路由来验证查询条件的正确性
示例:
GET student/_validate/query?explain{"query": {"bool": {"must": [{"match": {"dec": "she is"}}]}}}
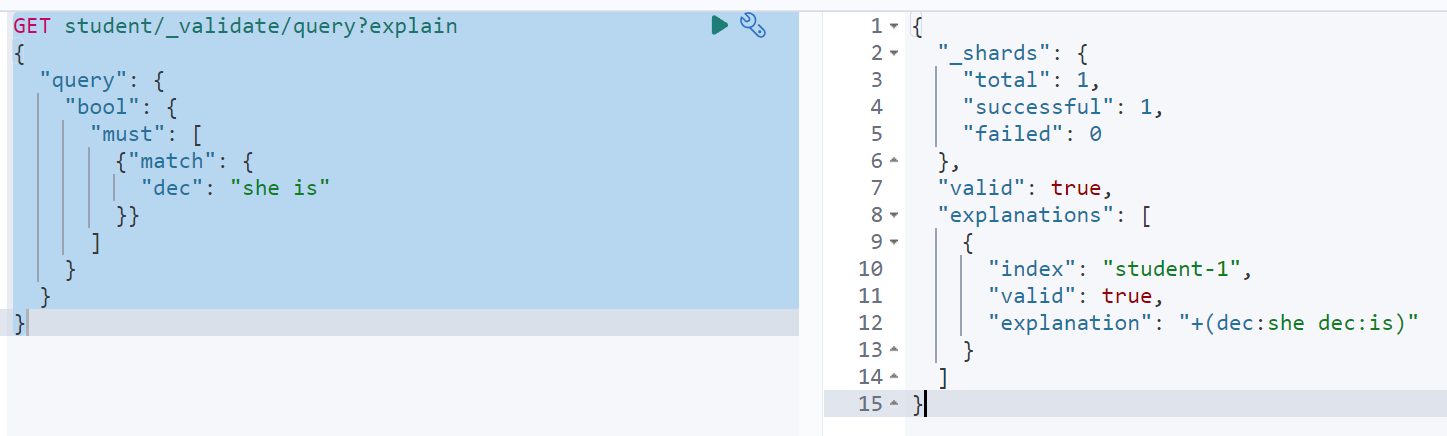

分析
es中通过/_validate/query?explain路由来进行查询分析
GET student/_validate/query?explain{"query": {"bool": {"must": [{"match": {"dec": "she is"}}]}}}
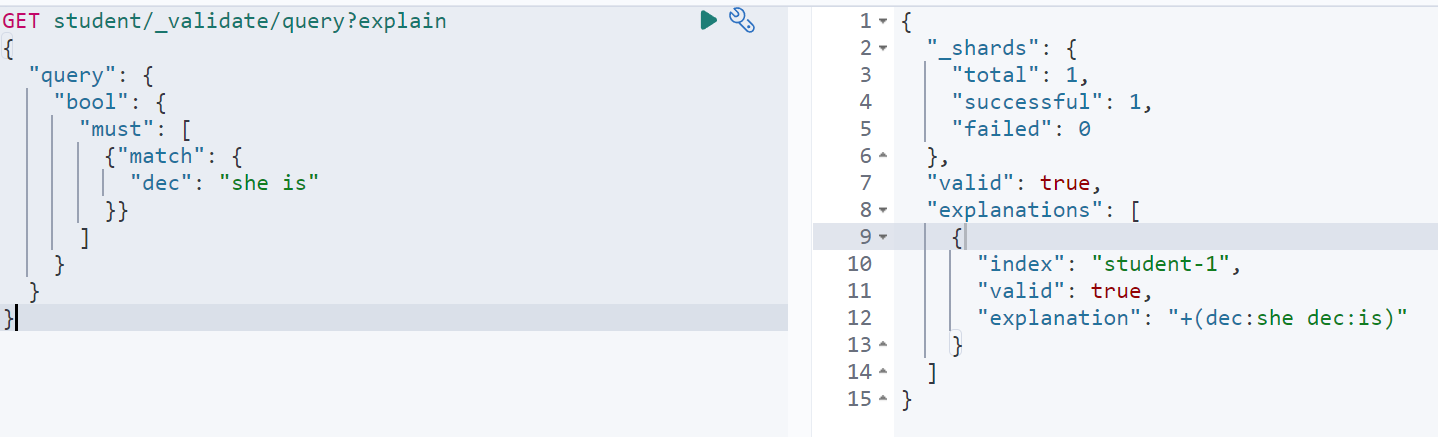
如图:可以看出当前查询只涉及了一个索引,并且查询短语被分成了两个词she/is
8.排序
默认排序
es中默认使用_score降序来进行返回结果的排序,_score越大,代表与查询条件关联性越大。
但是,_socre的计算是很占用查询性能的。有很多时候我们不需要进行分值计算,可以通过filter或constant_score来进行构建查询条件
filter示例:
GET student/_search{"query": {"bool": {"filter": [{"term": {"age": 18}}]}}}
如图可以看到,对应返回的score字段都为0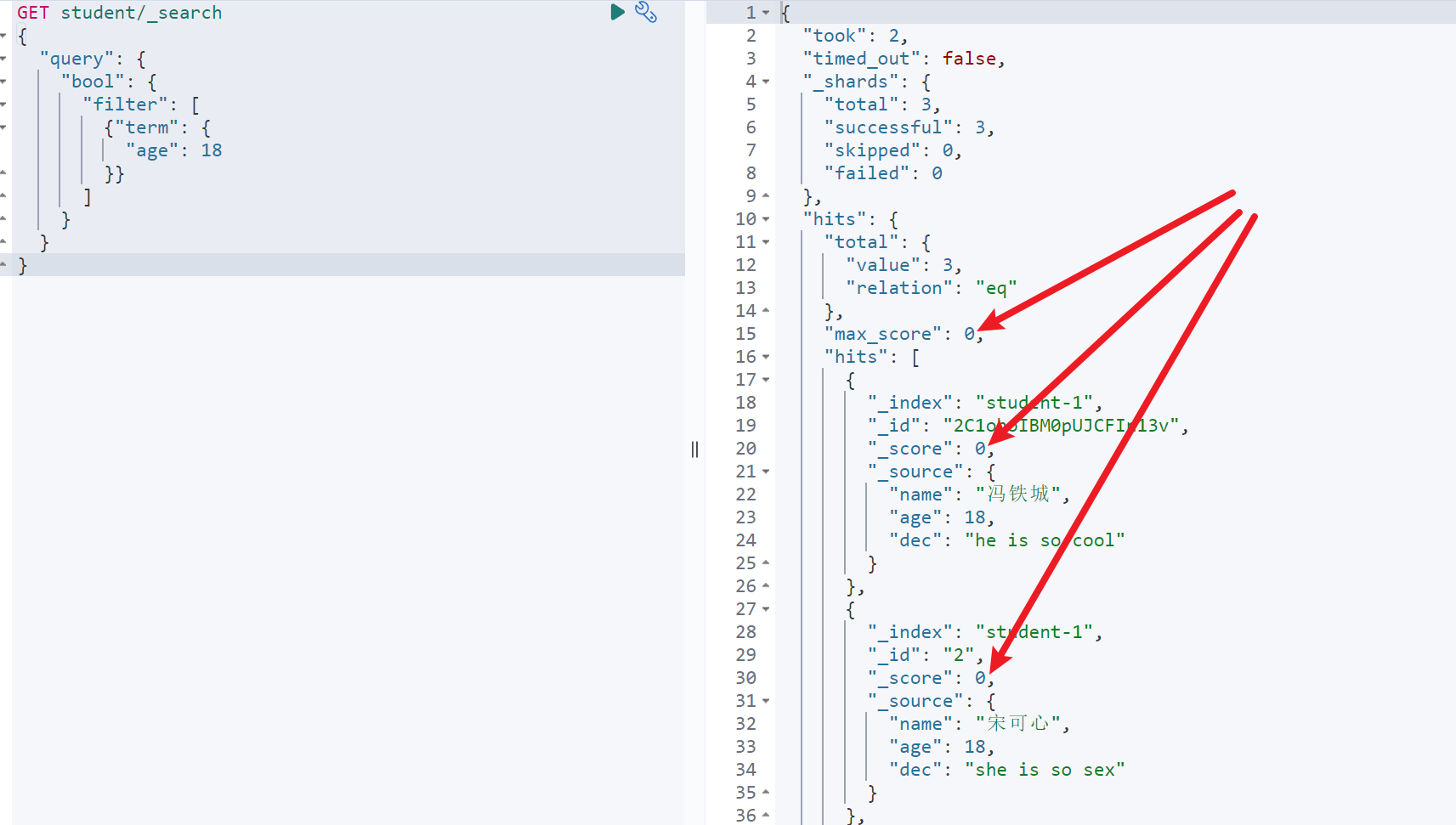
constant_score示例:
GET student/_search{"query": {"constant_score": {"filter": {"term": {"age": 18}},"boost": 1.2}}}
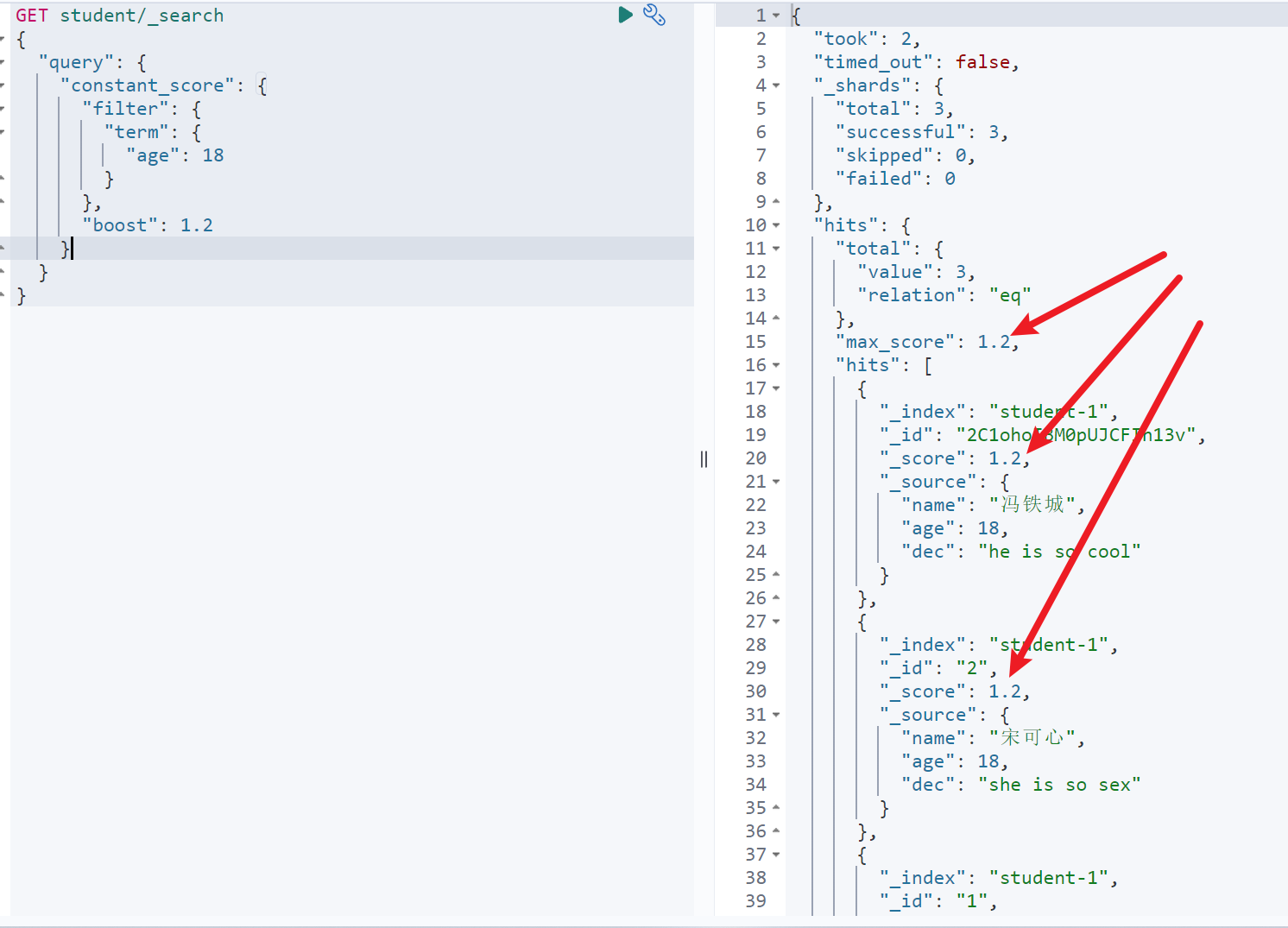
自定义排序
语法
es中使用sort参数来自定义排序顺序,默认为升序。排序示例如下:
- 按照年龄升序:{“sort”:[“age”]}
按照年龄降序:{“sort”:[{“age”:{“order”:”desc”}}]}
注意点
es中使用doc value列式存储来实现字段的排序功能
- text字段默认不创建doc value,因此无法针对text字段进行排序
可以通过设置text字段属性fielddata=true来开启对text字段的排序功能,但是不建议开启,对text字段排序及其消耗查询性能且不符合需求
示例
单字段排序
GET student/_search{"sort": ["age"]}
如图,可以看到自定义排序以后,每个返回文档的score参数都为空,且都多了一个sort的字段声明了其排序依据的值
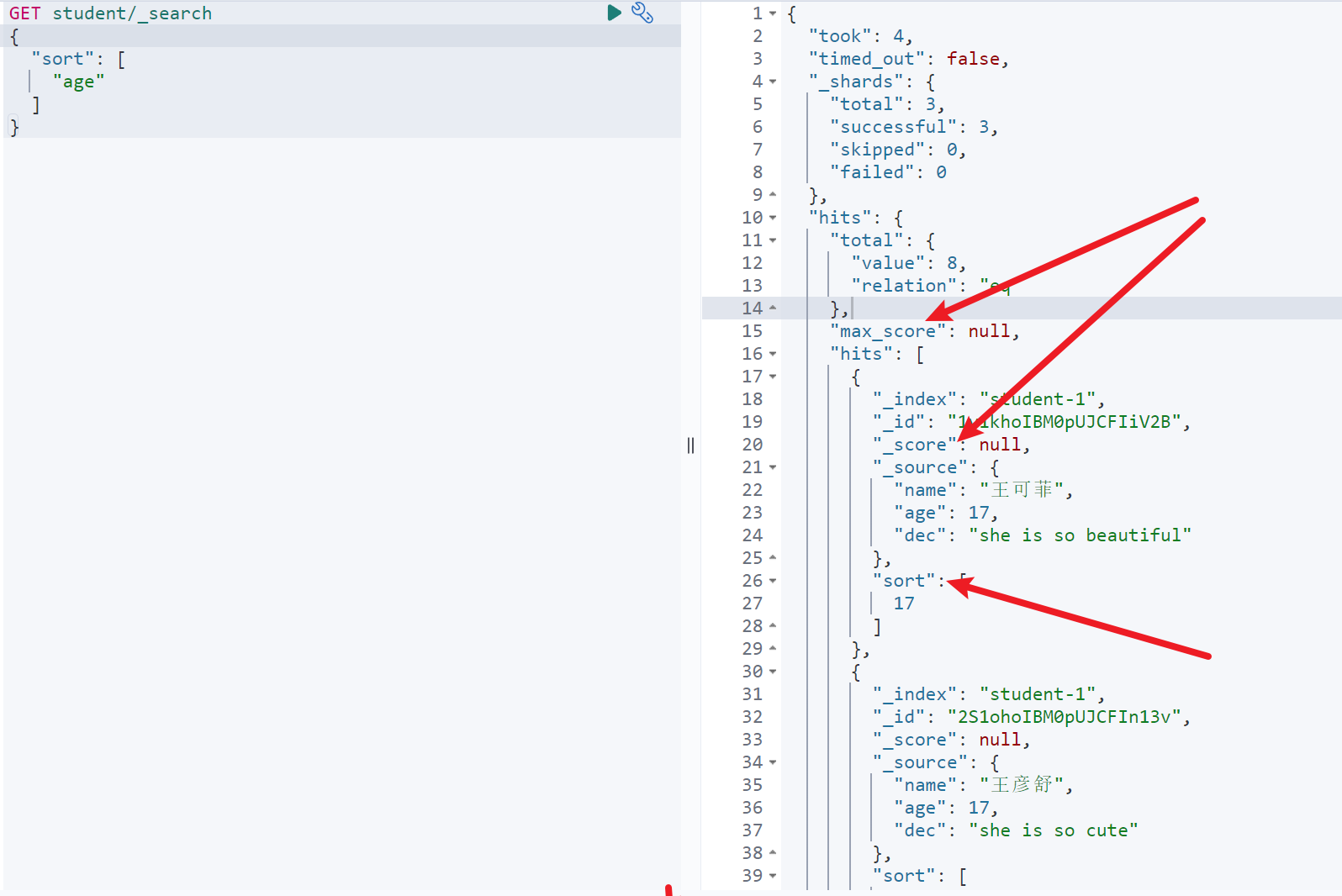
多字段排序
GET student/_search{"sort": [{"age": {"order": "desc"}},{"grade": {"order": "desc"}}]}
数组字段排序
es中同样支持针对数组内的元素进行排序,通过sort时指定mode属性来。mode包含以下属性:
min:依据数组中最小值排序
- max:依据数组中最大值排序
- avg:依据数组的平均值排序
- sum:依据数组的和值排序
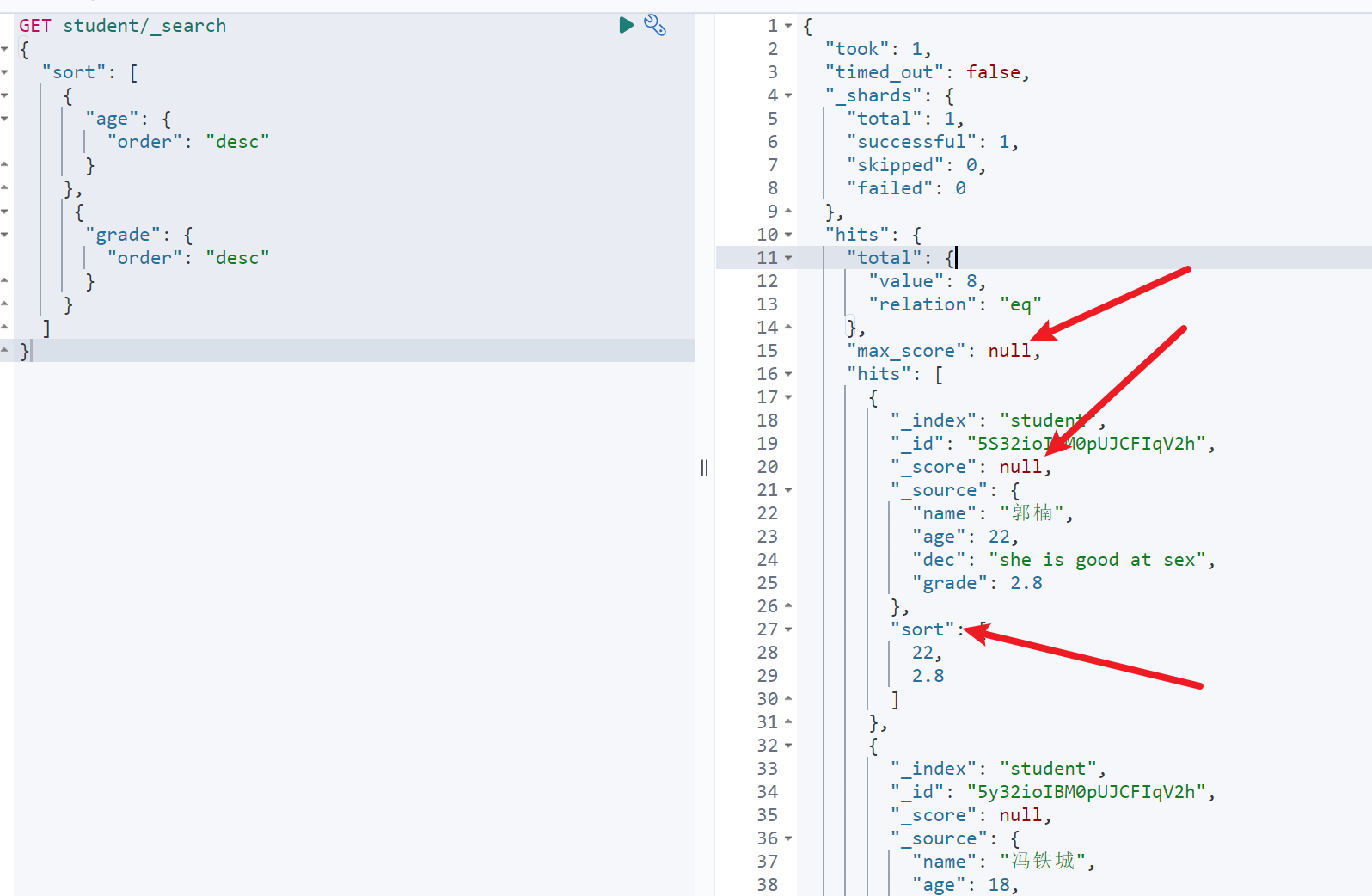
示例:
GET student/_search{"sort": [{"tages": {"order": "desc","mode": "max"}}]}
9.score计算原则
原则
es中进行条件查询时,默认都会返回一个_score字段表述结果文档与查询条件的匹配程度
es官方文档中有如下一段话:
查询语句会为每个文档生成一个 score 字段。评分的计算方式取决于查询类型 不同的查询语句用于不同的目的: fuzzy 查询会计算与关键词的拼写相似程度,terms 查询会计算 找到的内容与关键词组成部分匹配的百分比,但是通常我们说的 relevance_ 是我们用来计算全文本字段的值相对于全文本检索词相似程度的算法。
也就是说,score通常来说,适用于查询短语分词之后,与结果文档对应字段的匹配程度
原理(TF/IDF)
Elasticsearch 的相似度算法被定义为检索词频率/反向文档频率, TF/IDF ,包括以下内容:
- 检索词频率:查询条件词条,在文档对应字段中,出现的频率。频率越高,权重越大。字段中出现过 5 次要比只出现过 1 次的相关性高。
- 反向文档频率:查询条件词条,对应的文档数,对应的文档数越多,权重越低。检索词出现在多数文档中会比出现在少数文档中的权重更低。
- 字段长度准则:查询字段在文档中的长度,长度越长,权重越低。 检索词出现在一个短的 title 要比同样的词出现在一个长的 content 字段权重更大。
上述可能比较绕口,下面举个例子理解下
假设当前查询语句如下:
GET student/_search{"query":{"match":{"des":"like"}}}
那么,查询时,会按照以下标准进行文档关联性评分计算
- 检索词频率:在所有返回结果文档的name字段中,like词条出现的频率越多,对应文档的权重越高
- 反向文档频率:like词条对应倒排表中的文档数越多,返回文档的权重越低
字段长度准则:在所有返回结果文档的name字段中,name字段越大,对应文档的权重越低
验证
es中使用explain属性来开启查询分析,需要注意的是,查询分析十分消耗性能,在线上环境一定不要开启或高频次使用
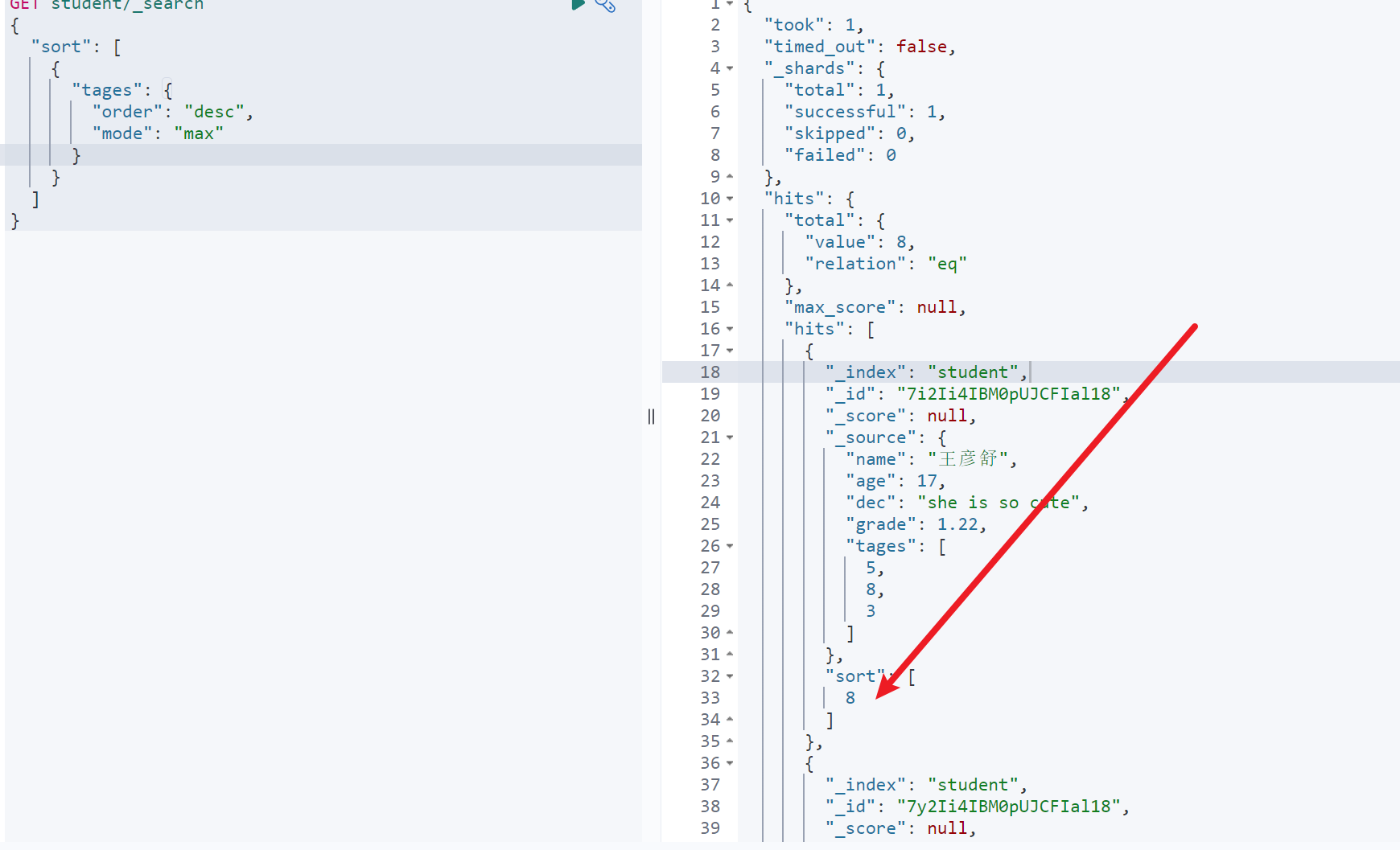
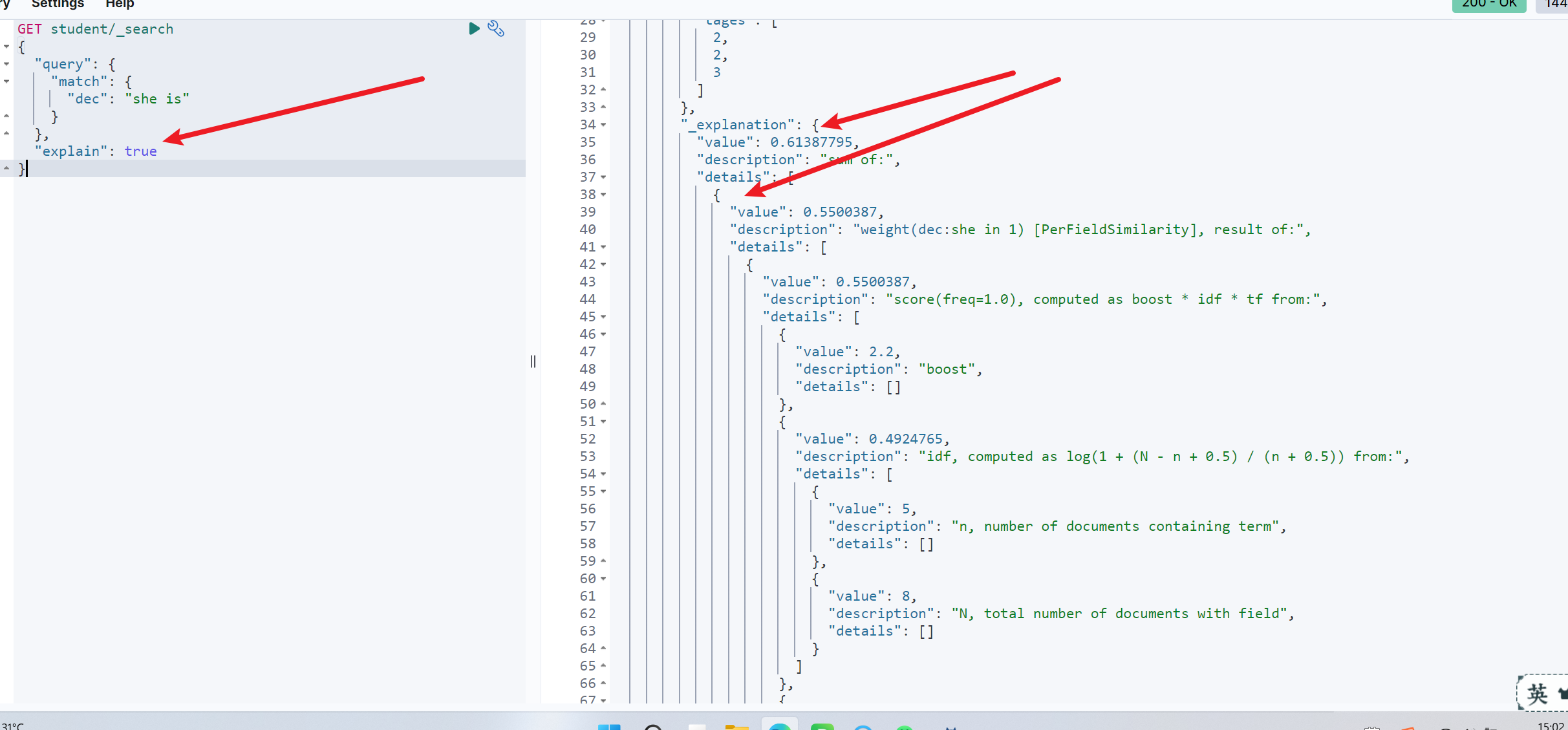
示例:GET student/_search{"query": {"match": {"dec": "she is"}},"explain": true}
如图,查看_explanation字段即可,具体分析参考:链接
10.scroll分页
es中默认允许from+size的分页的最大数据量为10000。当我们想要批量获取更大的数据量时,使用from+size就会十分的耗费性能
es中可以使用/scorll路由来进行滚动分页查询,它类似于在查询初始时间点创建了一个当前服务集群的数据快照(包含每一个分片),并保留它一段时间。在时间超过了设置的过期时间以后,快照将在es空闲时被删除
需要注意的是,因为是进行快照查询,因此在快照创建后数据的变更在本次的滚动查询中,不可见
示例:查询并初始化快照,快照保存时间1分钟
GET student/_search?scroll=1m{"query": {"match_phrase": {"dec": "she is"}},"sort": ["_doc"],"size": 4}
如图,当前共返回4条数据,并且返回了一个快照ID,后续可以根据快照ID进行滚动查询
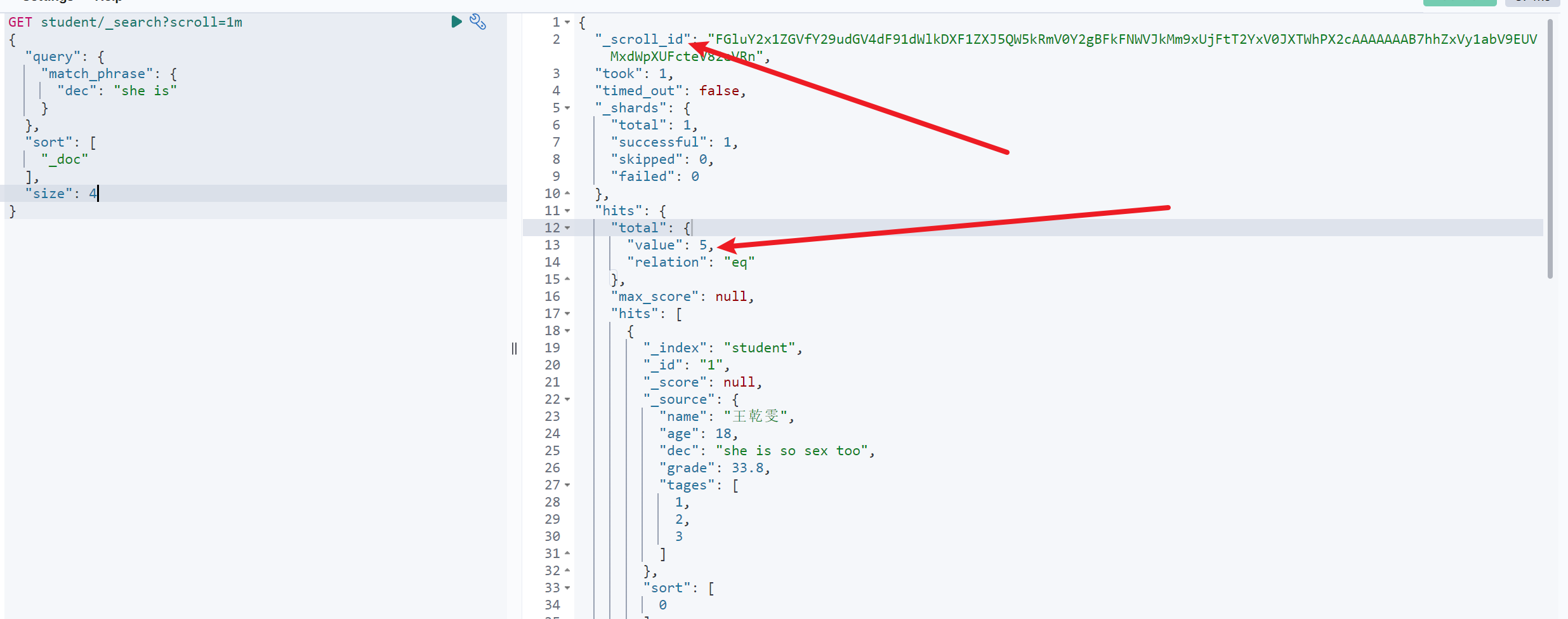
根据快照ID滚动查询
GET /_search/scroll{"scroll": "1m","scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDnF1ZXJ5VGhlbkZldGNoAhZBTVlSZDJvcVIxbU9mMVdCV01oT19nAAAAAAAAe6UWcVctWm1fRFFTMXVqV1BXLXlfNnlUZxYyX2RPS2ctdFNrT0MweWxBcE1ucUR3AAAAAAACufcWWUV4Q1B1OTRSdktrZXVvWU94aU5GQQ=="}
如图,再初始查询后,后续只需根据scorll_id查询即可,但是需要指定快照保存时间,不然很可能滚动查询到一半,快照没了。
同时要注意,在后续的查询时,不需要指定索引了,因为是对数据快照进行滚动查询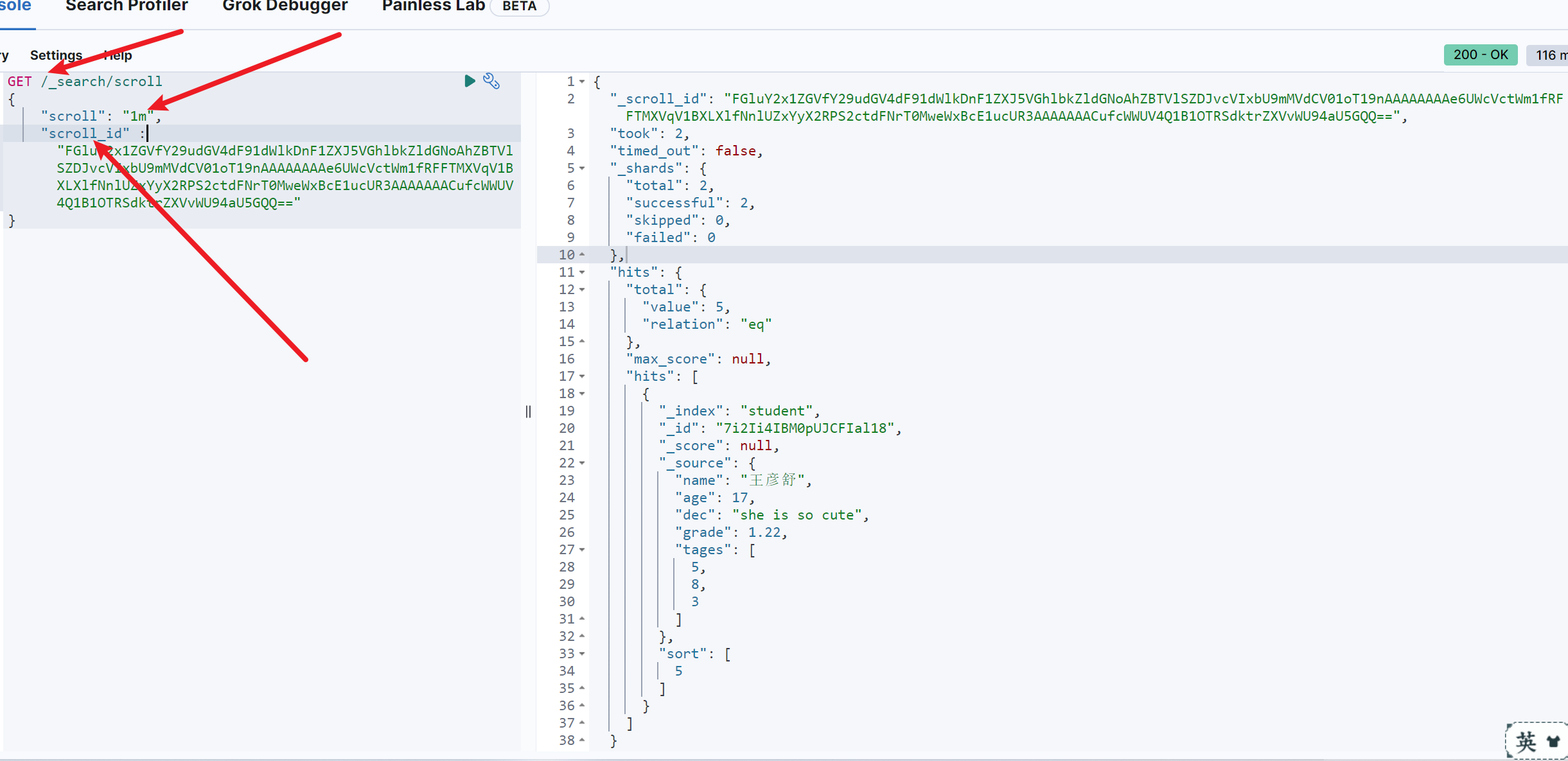

若有收获,就点个赞吧
0 人点赞
