1.什么是分词
对于非结构语言的查询,如果采用全文检索的方式进行查询,需要进行对其进行分词处理
分词,顾名思义,将一句话或一大段话,通过一定的规则,分割成多个词条的过程称为分词
2.ES中分词器的构成
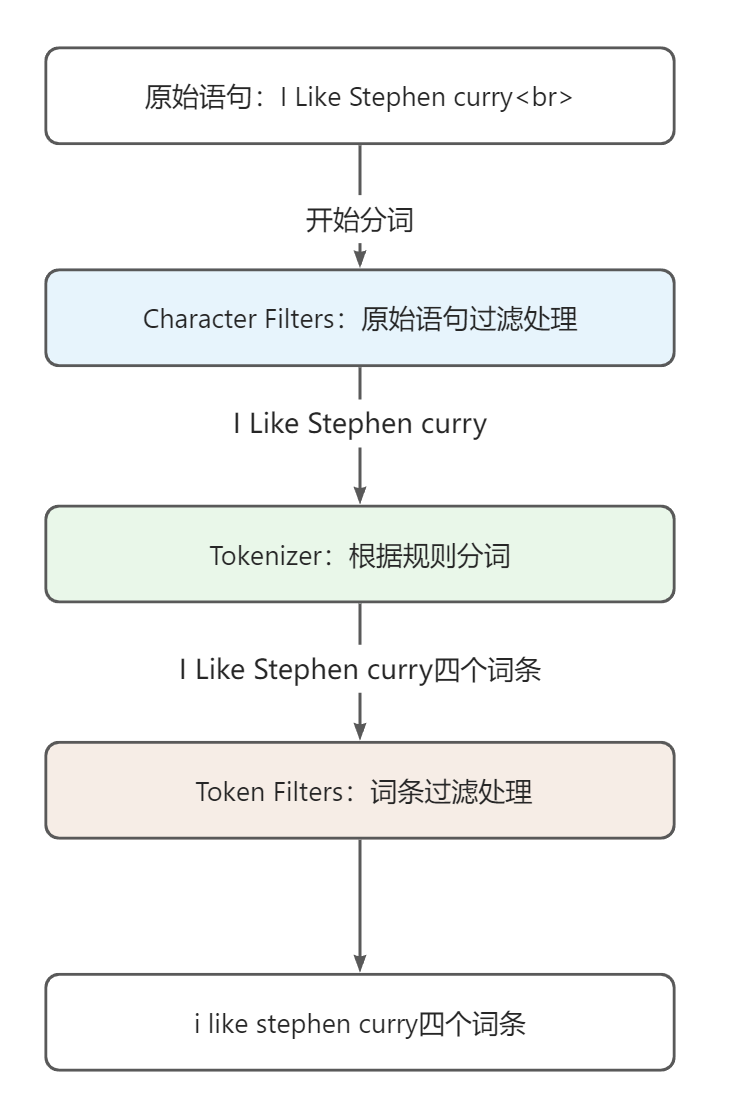
ES中的分词器由以下三部分组成:
- Character Filters:针对原始文本处理,比如去除 html 标签,标点符号,语气词等。一个分词器中可以包含0至多个Character Filters
- Tokenizer:按照规则将原始文本切分为词条,比如按照空格切分。一个分词器中有且只有一个Tokenizer
- Token Filters:将切分的单词进行加工,比如大写转小写,删除结语词,增加同义语。一个分词器中可以包含0至多个Token Filters
3.ES内置分词器
- Standard Analyzer :默认分词器,按词切分,小写处理
- Simple Analyzer:按照非字母切分(符号被过滤),小写处理
- Stop Analyzer:小写处理,停用词过滤(the ,a,is)
- Whitespace Analyzer:按照空格切分,不转小写
- Keyword Analyzer:不分词,直接将输入当做输出
- Pattern Analyzer:正则表达式,默认 \W+
- Language:提供了 30 多种常见语言的分词器
- Customer Analyzer:自定义分词器
4.常用的中文分词器
IK
优势:支持自定义词库,支持热更新分词字典
github地址:https://github.com/medcl/elasti
分类:
- ik_max_word:分词颗粒度小,满足业务场景更丰富
- ik_smart:分词器颗粒度较粗,满足分词场景要求不高的业务
5.如何测试分词器
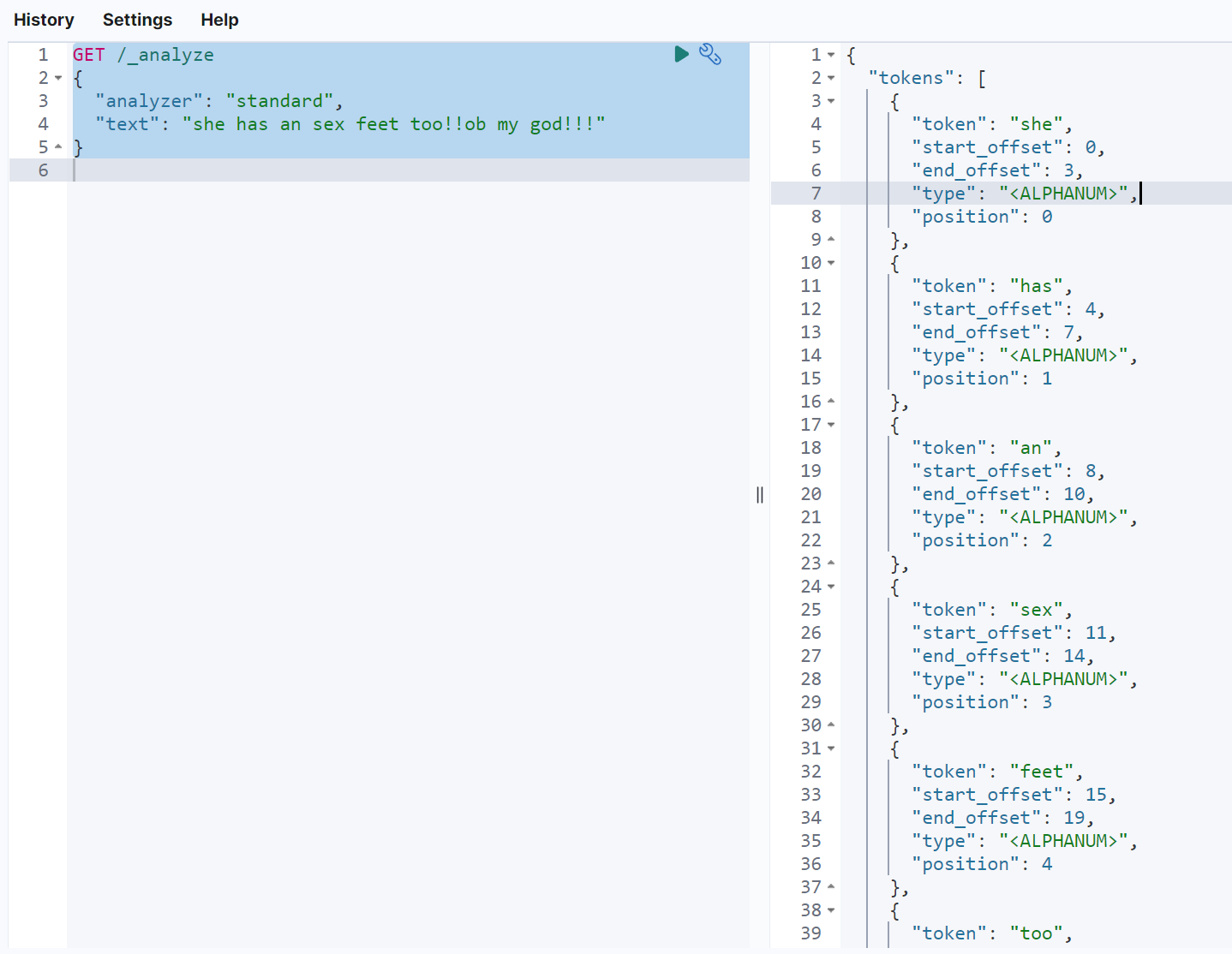
在es中,可以通过_analyze路由指定分词器以及要被分词的短语,来获取到这个短语使用指定分词器后的分词结果。通常来说,我们可以利用这个功能来实现分词器的测试
如下示例,analyzer为指定的分词器,text为要被分词的短语GET /_analyze{"analyzer": "standard","text": "she has an sex feet too!!ob my god!!!"}
6.中文分词器部署
准备
前置条件,已配置好es集群,请参考:ElasticSearch部署
以ik分词器为例进入目录
cd /usr/local查看当前es版本
浏览器输入:http://120.48.107.224:9201/ 查看。如图,版本8.0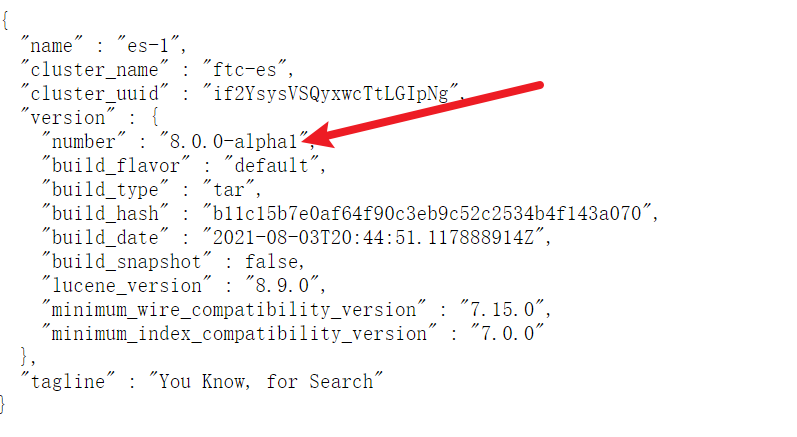
下载
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
下载对应版本的zip压缩包即可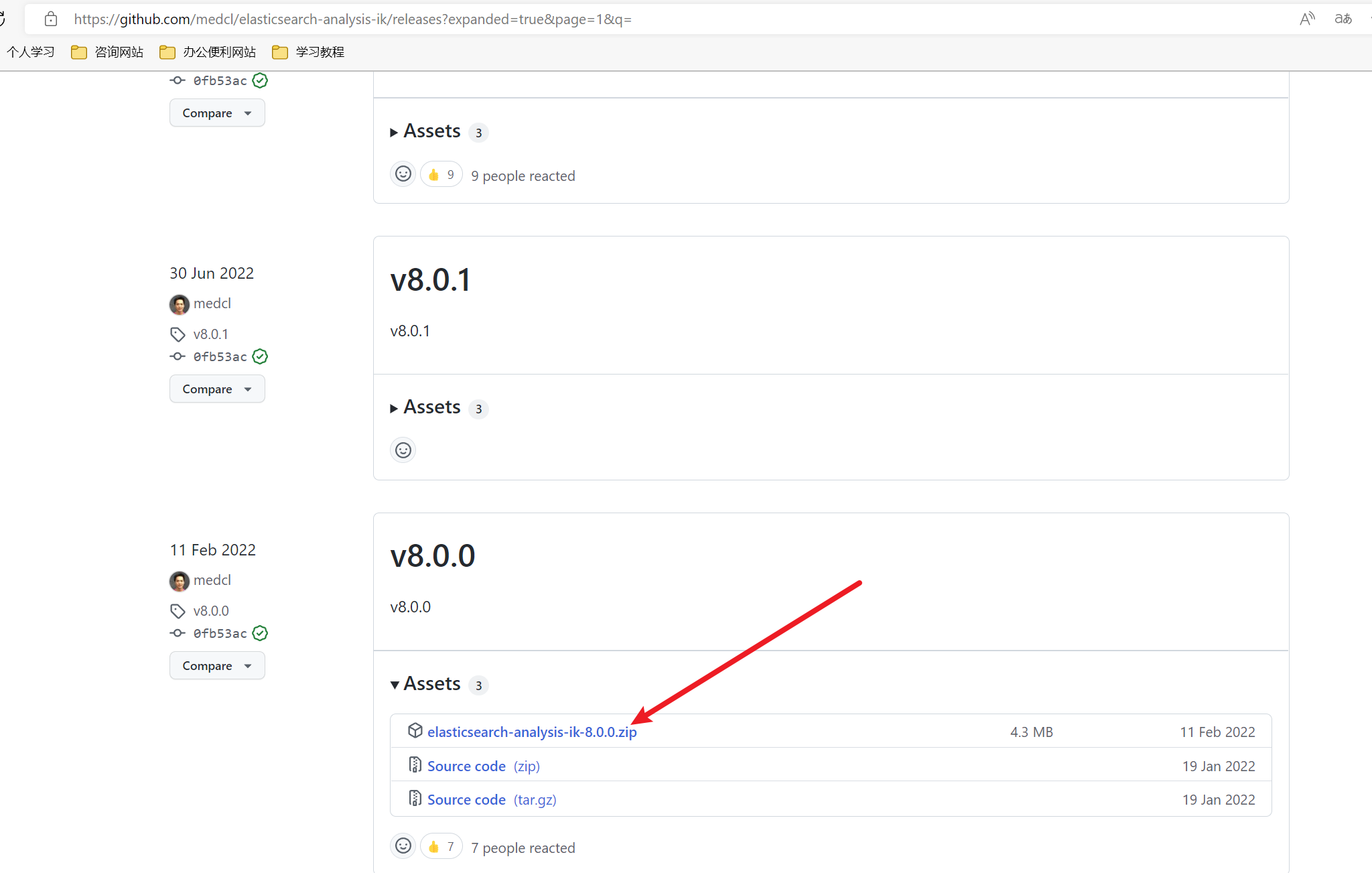
如图,下载完毕
创建ik插件文件夹
- mkdir /usr/local/elasticsearch-set/elasticsearch-1/plugins/ik
- mkdir /usr/local/elasticsearch-set/elasticsearch-2/plugins/ik
mkdir /usr/local/elasticsearch-set/elasticsearch-3/plugins/ik
解压
unzip elasticsearch-analysis-ik-8.0.0.zip -d elasticsearch-set/elasticsearch-1/plugins/ik/
- unzip elasticsearch-analysis-ik-8.0.0.zip -d elasticsearch-set/elasticsearch-2/plugins/ik/
- unzip elasticsearch-analysis-ik-8.0.0.zip -d elasticsearch-set/elasticsearch-3/plugins/ik/
- cd elasticsearch-set/elasticsearch-3/plugins/ik/
- ll
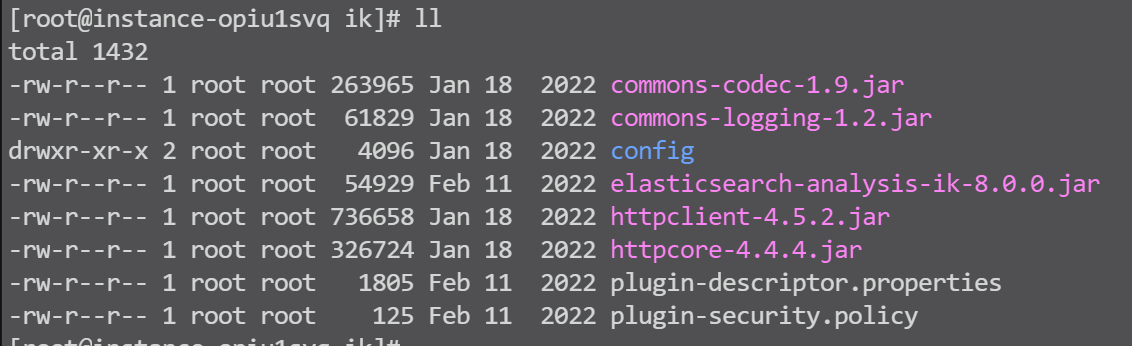
授权
- chgrp -R esuser /usr/local/elasticsearch-set/elasticsearch-1/plugins/ik
- chown -R esuser /usr/local/elasticsearch-set/elasticsearch-1/plugins/ik
- chmod 777 /usr/local/elasticsearch-set/elasticsearch-1/plugins/ik
- chgrp -R esuser /usr/local/elasticsearch-set/elasticsearch-2/plugins/ik
- chown -R esuser /usr/local/elasticsearch-set/elasticsearch-2/plugins/ik
- chmod 777 /usr/local/elasticsearch-set/elasticsearch-2/plugins/ik
- chgrp -R esuser /usr/local/elasticsearch-set/elasticsearch-3/plugins/ik
- chown -R esuser /usr/local/elasticsearch-set/elasticsearch-3/plugins/ik
chmod 777 /usr/local/elasticsearch-set/elasticsearch-3/plugins/ik
重启es服务器
supervisorctl status

- supervisorctl restart elastic-1
- supervisorctl restart elastic-2
supervisorctl restart elastic-3
测试
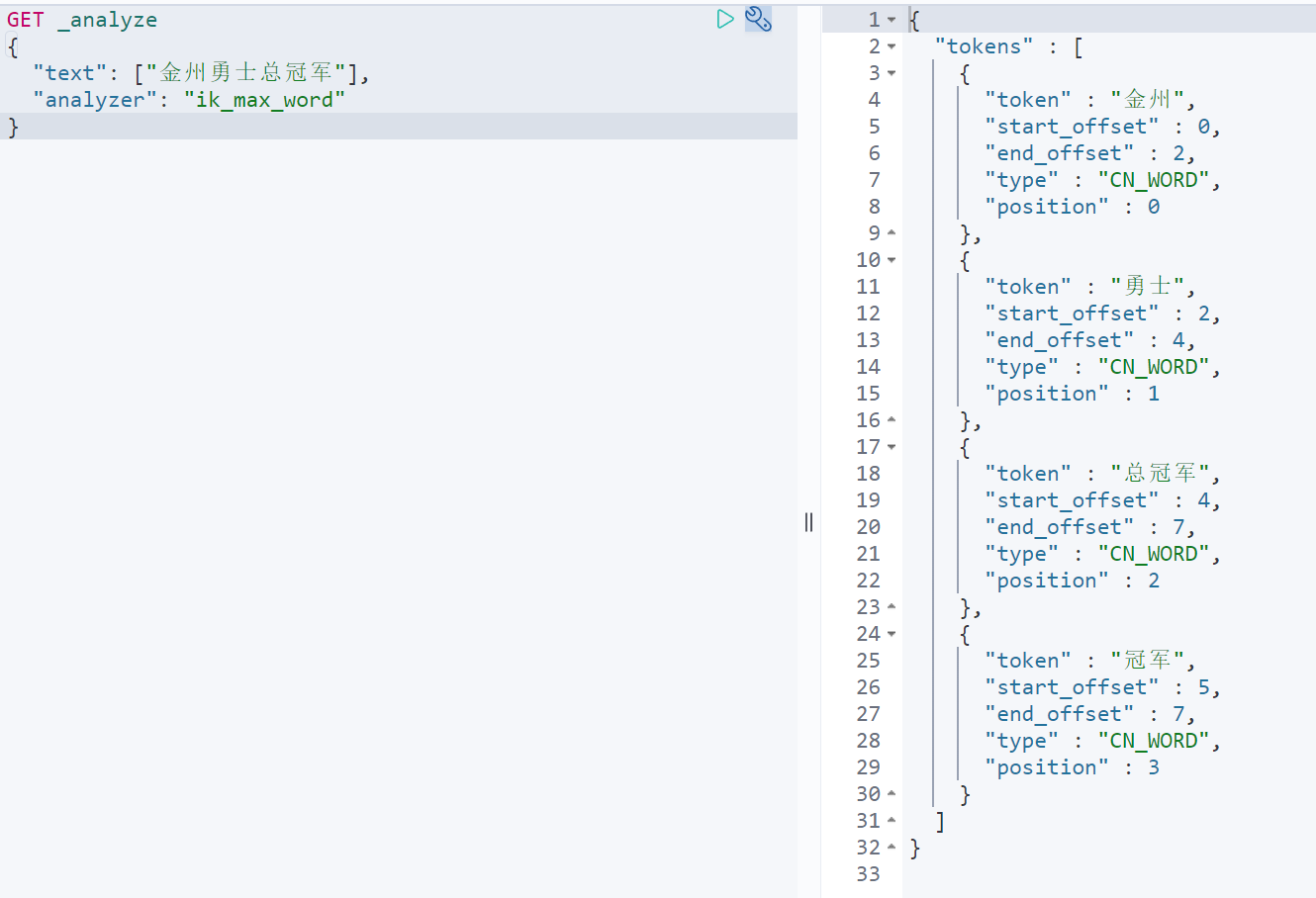
kibana分词输入如下测试
GET _analyze{"text": ["金州勇士总冠军"],"analyzer": "ik_max_word"}
7.中文分词测试
创建索引并指定ik分词器
PUT student{"mappings": {"properties": {"name":{"type": "text","analyzer": "ik_max_word"},"des":{"type": "text","analyzer": "ik_max_word"}}}}
准备数据
PUT student/_bulk{ "create":{} }{"name":"冯铁城","des":"一个帅小伙"}{ "create":{} }{"name":"张钰玲","des":"一个小姑娘"}{ "create":{} }{"name":"马冬梅","des":"你要干什么"}{ "create":{} }{"name":"夏洛","des":"全班排名第二的大傻子,也是个帅小伙"}
测试
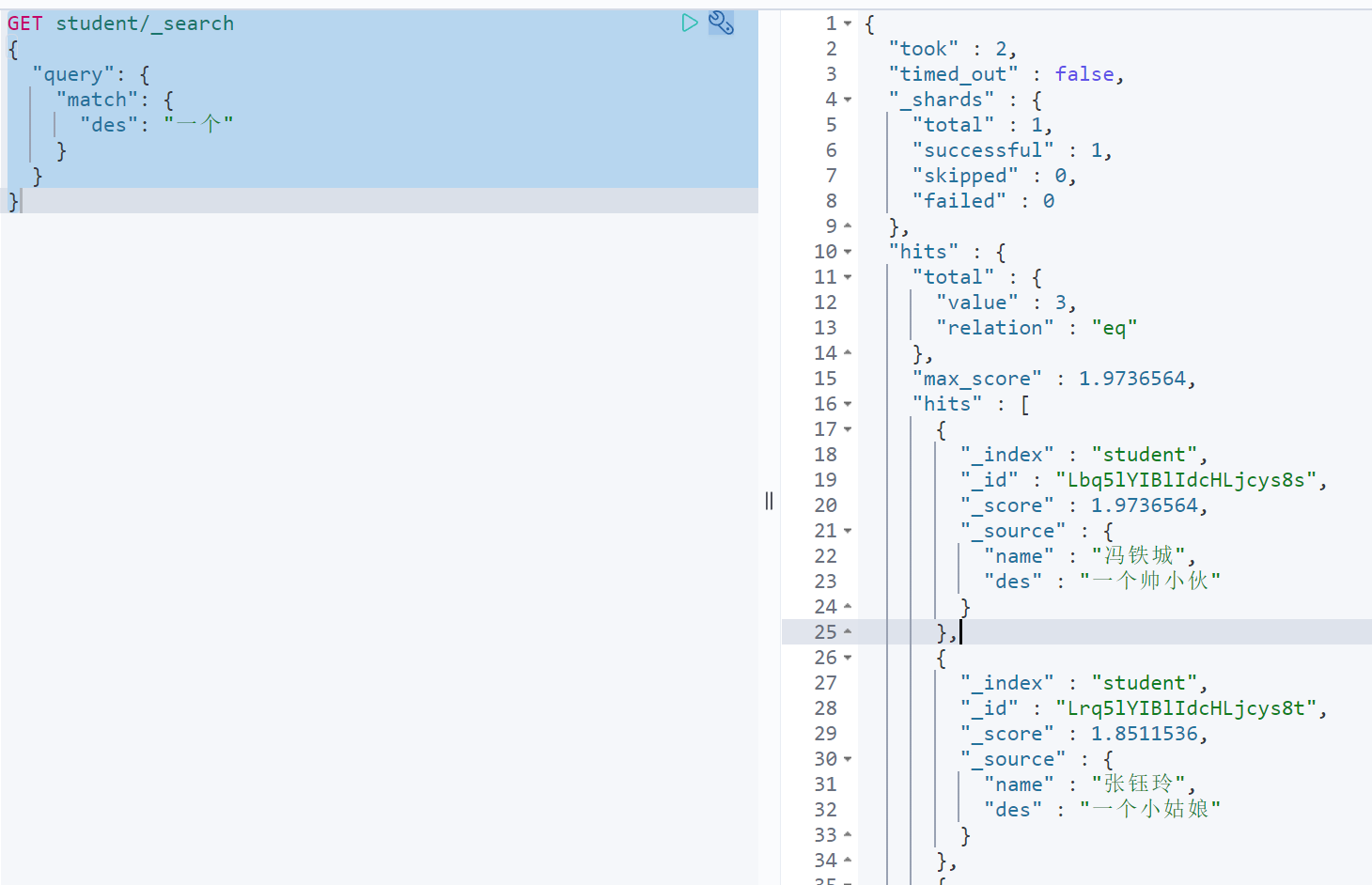
查询描述中带有”一个”的学生
GET student/_search{"query": {"match": {"des": "一个"}}}
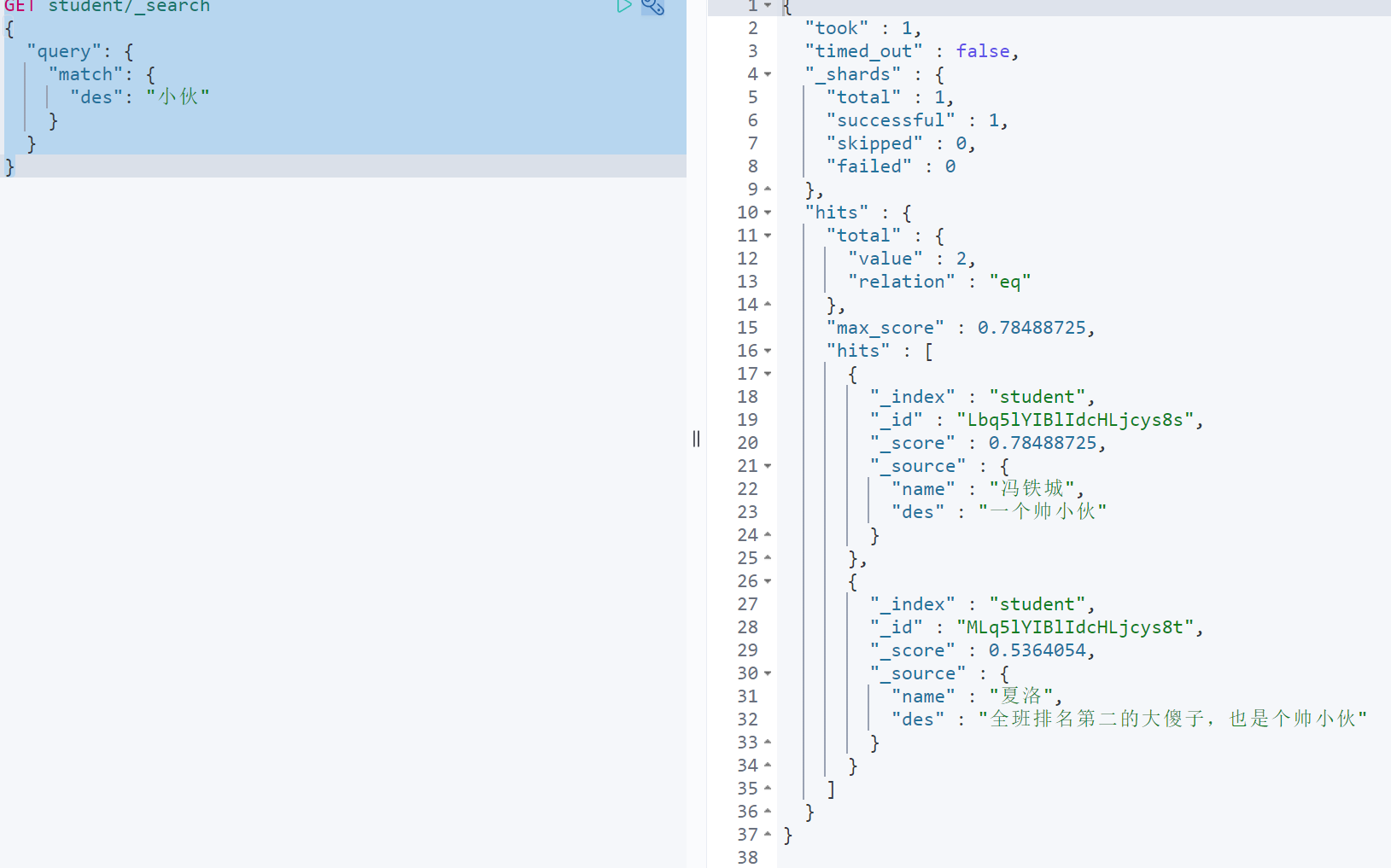
查询描述中带有”小伙”的学生
GET student/_search{"query": {"match": {"des": "小伙"}}}

若有收获,就点个赞吧
0 人点赞
