1.数据准备
索引mapping
PUT student-1{"aliases":{"student":{}},"mappings":{"properties":{"age":{"type":"byte"},"dec":{"type":"text","fields":{"keyword":{"type":"keyword","ignore_above":256}}},"grade":{"type":"half_float"},"name":{"type":"keyword"},"tages":{"type":"keyword"}}},"settings":{"index":{"refresh_interval":"3s","number_of_shards":"3","number_of_replicas":"1"}}}
测试数据
PUT student/_bulk{ "index":{ "_id": 1 } }{ "name":"王乾雯","age":18,"dec":"she is so sex too","grade":33.8,"tages":["sex","cute"]}{ "index":{ "_id": 2 } }{ "name":"宋可心","age":18,"dec":"she is so sex","grade":44.8,"tages":["sex","long leg"]}{ "index":{} }{ "name":"郭楠","age":22,"dec":"she is good at sex","grade":2.8,"tages":["sex"]}{ "index":{} }{ "name":"王可菲","age":17,"dec":"she is so beautiful","grade":4.8,"tages":["beautiful"]}{ "index":{} }{ "name":"冯铁城","age":18,"dec":"he is so cool","grade":100,"tages":["cool","high"]}{ "index":{} }{ "name":"王彦舒","age":17,"dec":"she is so cute","grade":1.22,"tages":["sex","like fuck"]}{ "index":{} }{ "name":"宁娜","age":17,"dec":"her feet is so sex!on my god!!!!","grade":55.22,"tages":["very sex","like fuck"]}{ "index":{} }{ "name":"lulu","age":17,"dec":"her feet is so sex!i want fuck her","grade":78.13,"tages":["very sex","like fuck","beautiful feet"]}
2.term/terms
es中,使用term或terms(一个字段满足多个值)进行字段的精确值查询。并且推荐使用filter和constant_score进行查询封装,来实现不计算分数的查询操作。
- 对于基础数据类型:可以将term/terms理解为=或like
对于基础数据类型的数组:可以将term/terms理解为in
示例
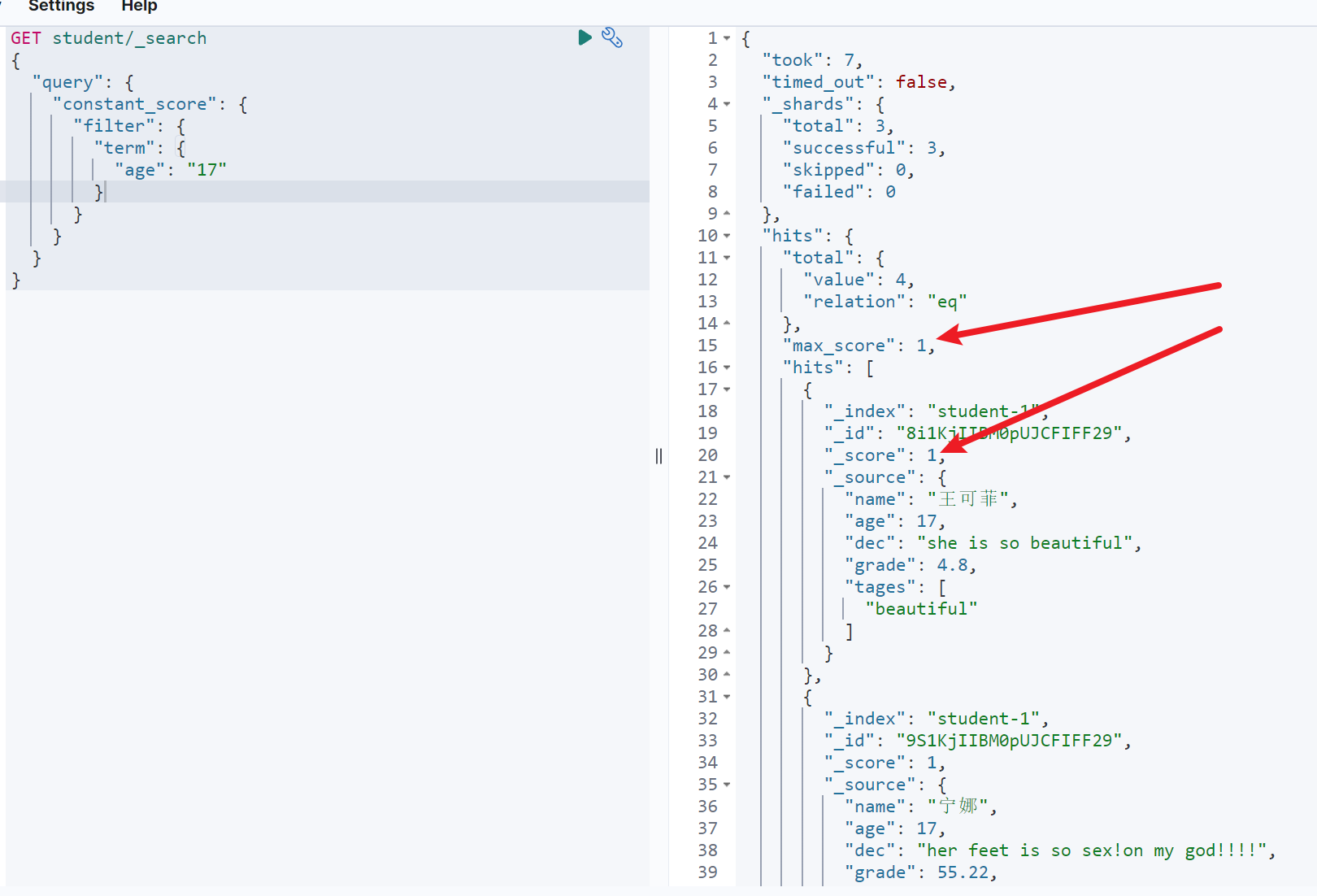
GET student/_search{"query": {"constant_score": {"filter": {"term": {"age": "17"}}}}}
注意事项
term/terms查询不适用于text字段,因为text字段会进行分词处理,当我们使用完全匹配的短语进行查询时,在倒排索引中是获取不到对应的词条的,因此也无法进行数据检索。如果必须要对文本类型字段进行精确查询,可将其设置为keyword类型
term/terms的查询语义,是必须包含(must contain),而不是必须精确相等(must equal exactly)。由于倒排索引表自身的特性,整个字段是否相等会难以计算,因此想要等值查询只能获取到对应的文档后,再取出其字段,然后进行等值对比。很明显这种查询效率及其低下,因此一定要理解terms的语义。
filter原理
查找匹配文档:通过倒排索引获取文档ID
- 创建 bitset:过滤器会创建一个 bitset (一个包含 0 和 1 的数组),它描述了哪个文档会包含该 term 。匹配文档的标志位是 1 。在内部,它表示成一个 “roaring bitmap”,可以同时对稀疏或密集的集合进行高效编码。
- 迭代 bitsets:一旦为每个查询生成了 bitsets ,Elasticsearch 就会循环迭代 bitsets 从而找到满足所有过滤条件的匹配文档的集合。执行顺序是启发式的,但一般来说先迭代稀疏的 bitset (因为它可以排除掉大量的文档)。
增量使用计数:Elasticsearch 能够缓存非评分查询从而获取更快的访问,但是它也会不太聪明地缓存一些使用极少的东西。非评分计算因为倒排索引已经足够快了,所以我们只想缓存那些我们 知道 在将来会被再次使用的查询,以避免资源的浪费。为了实现以上设想,Elasticsearch 会为每个索引跟踪保留查询使用的历史状态。如果查询在最近的 256 次查询中会被用到,那么它就会被缓存到内存中。当 bitset 被缓存后,缓存会在那些低于 10,000 个文档(或少于 3% 的总索引数)的段(segment)中被忽略。这些小的段即将会消失,所以为它们分配缓存是一种浪费。
3.range
es中使用range来进行值得范围查询,每个range条件可以包含1/2个查询条件,条件修饰符如下:
gt:大于
- lt:小于
- gte:大于等于
-
示例
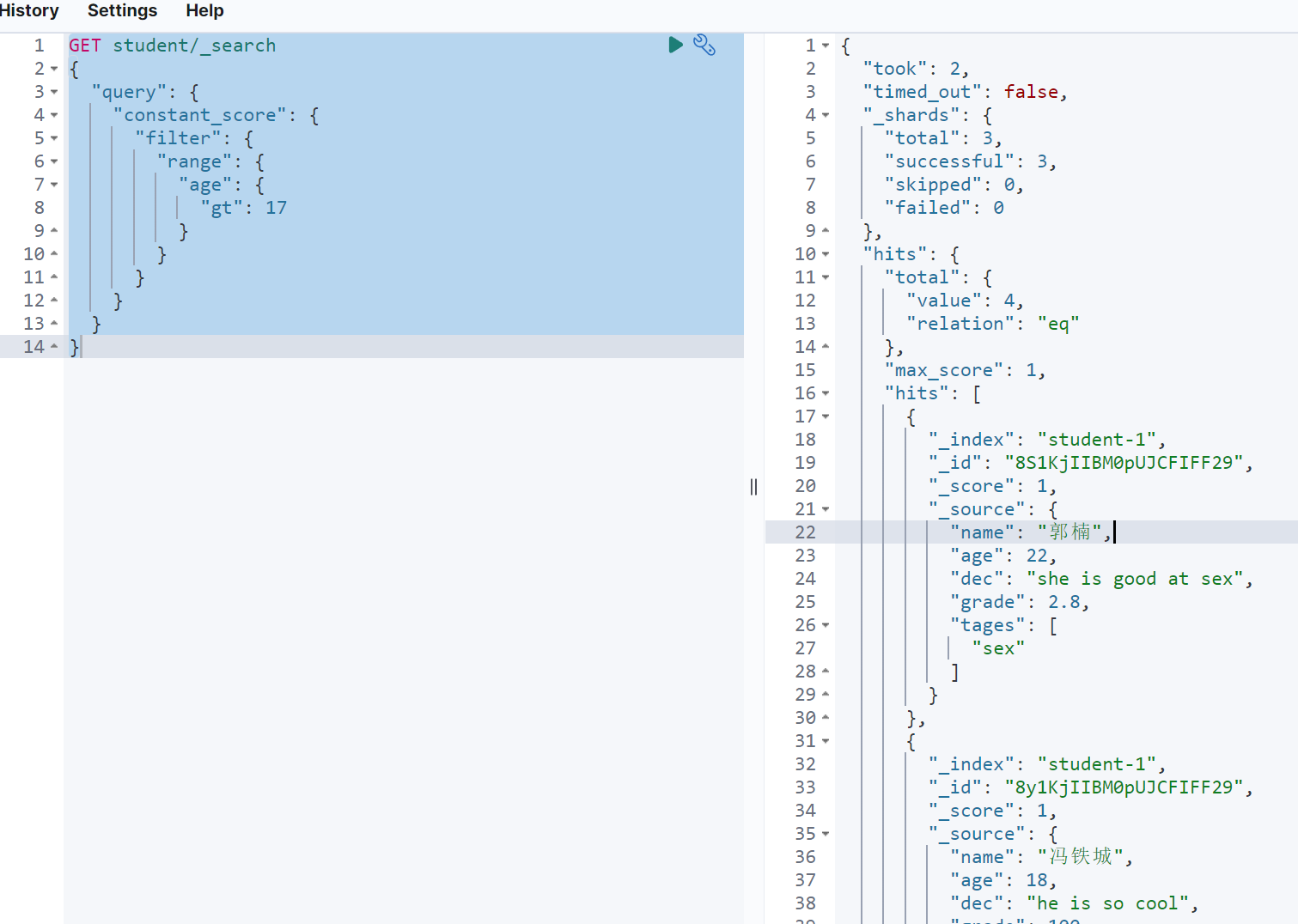
查询年龄大于17的学生
GET student/_search{"query": {"constant_score": {"filter": {"range": {"age": {"gt": 17}}}}}}
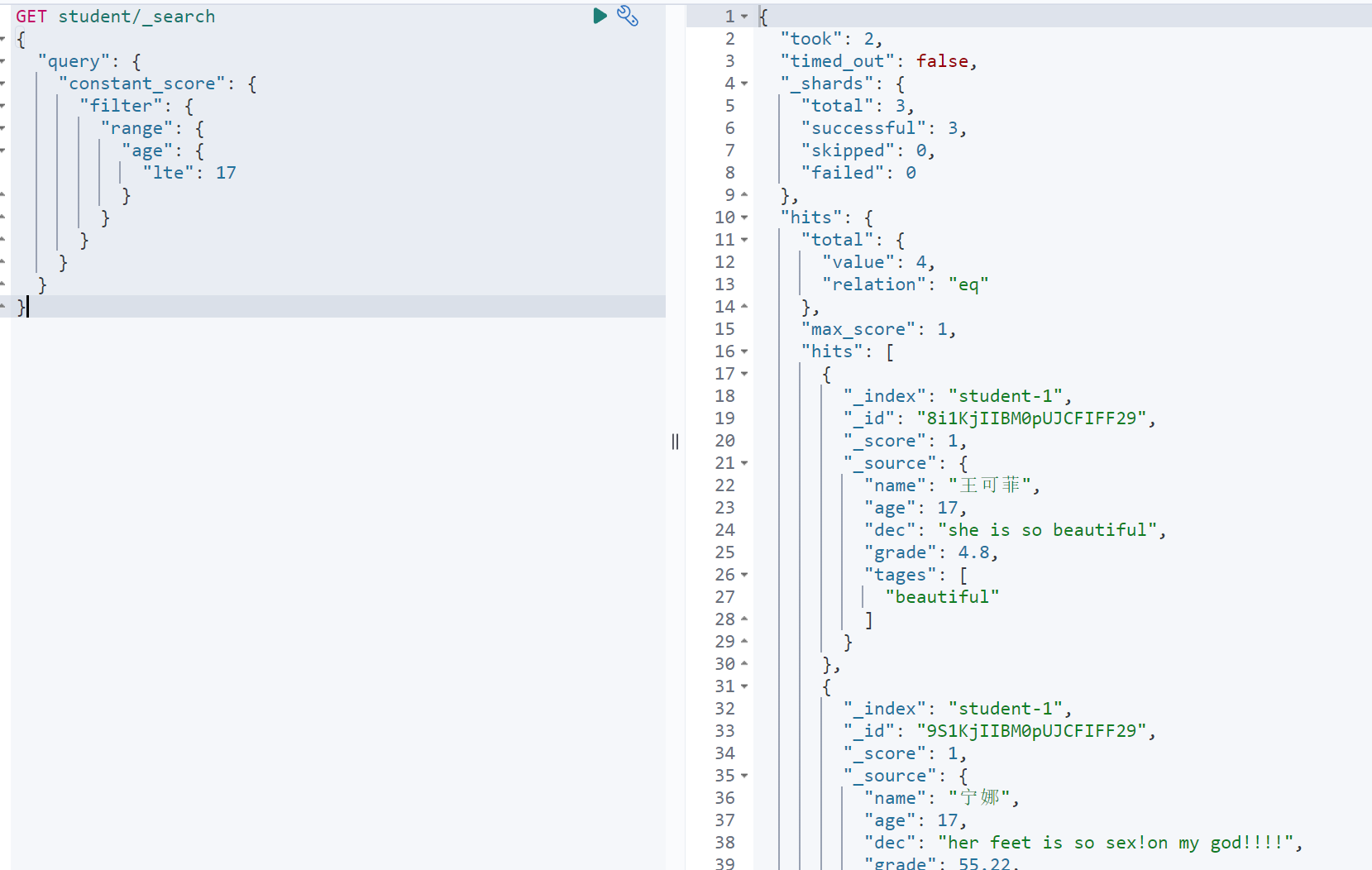
查询年龄小于等于17的学生
GET student/_search{"query": {"constant_score": {"filter": {"range": {"age": {"lte": 17}}}}}}
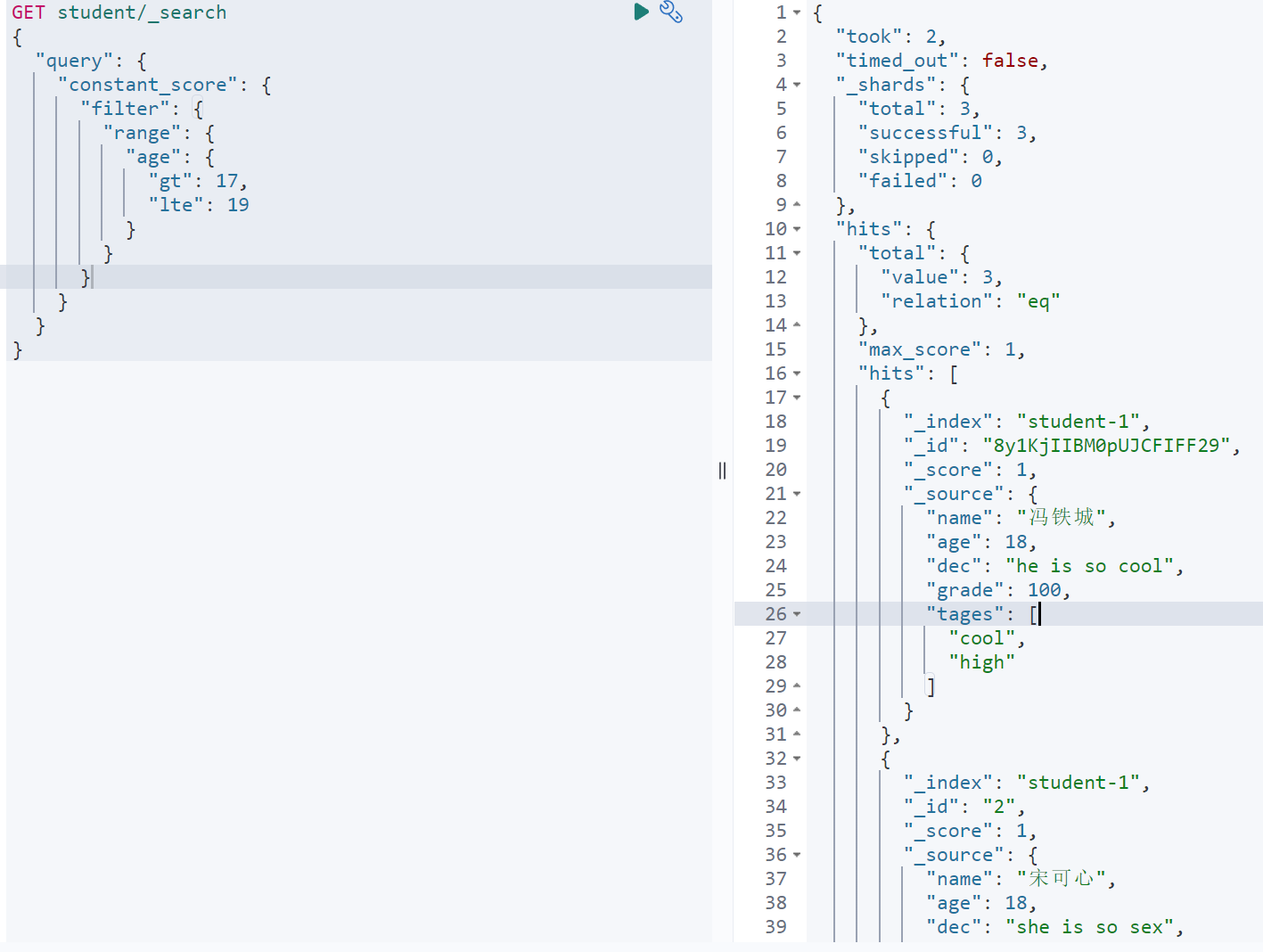
查询年龄大于等于17,但是年龄小于19的学生
GET student/_search{"query": {"constant_score": {"filter": {"range": {"age": {"gt": 17,"lte": 19}}}}}}
4.exist
es中使用exist来判定一个文档中是否包含对应的字段。因为对于空值,es本身是不会为其创建倒排索引的,因此,使用exist来判定是一个比较好的方案
我尝试了使用missing查询,但是基于8.3版本missing查询会报错
示例
查询包含name字段的文档
GET student/_search{"query": {"constant_score": {"filter": {"exists": {"field": "name"}},"boost": 1.2}}}
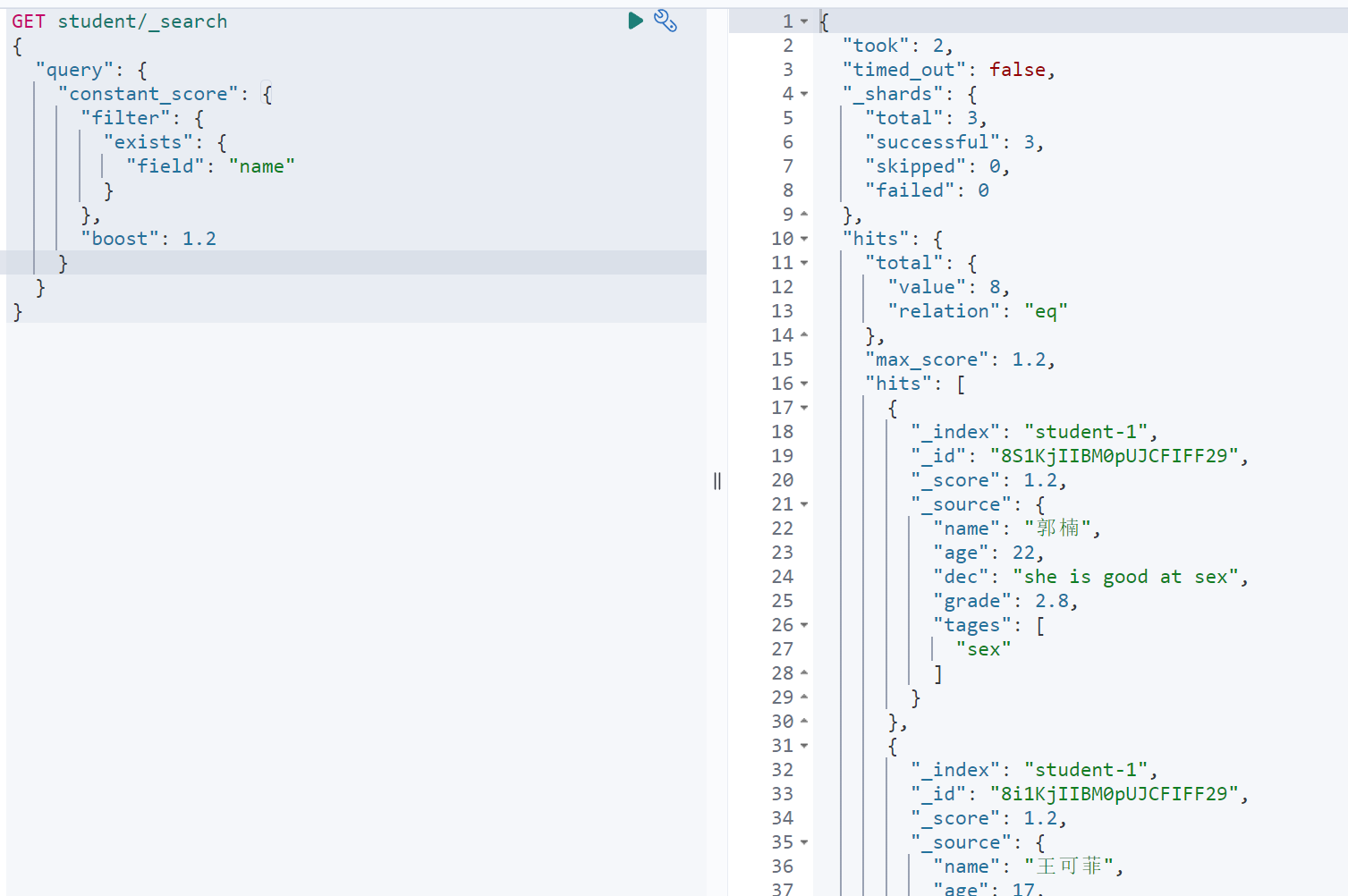
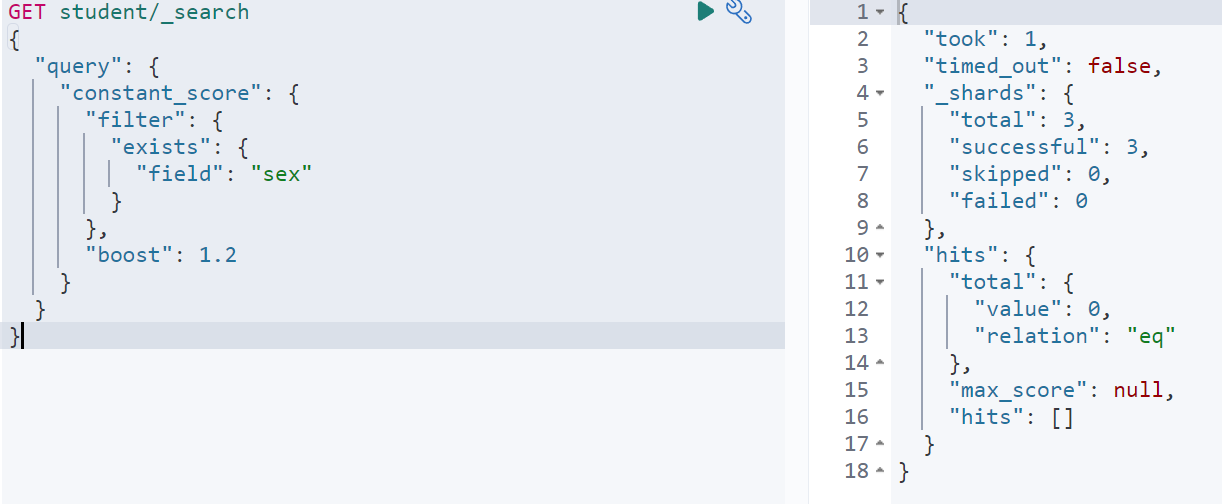
查询包含sex字段的文档
GET student/_search{"query": {"constant_score": {"filter": {"exists": {"field": "sex"}},"boost": 1.2}}}
5.match
es中使用match来进行文本匹配查询。matchh可以作为es中的核心查询语句,无论是对于结构化数据还是非结构化数据,match查询都可以对其进行匹配检索
对于非文本类型数据:可以将match理解为=/in
-
示例
查询年龄=18的学生
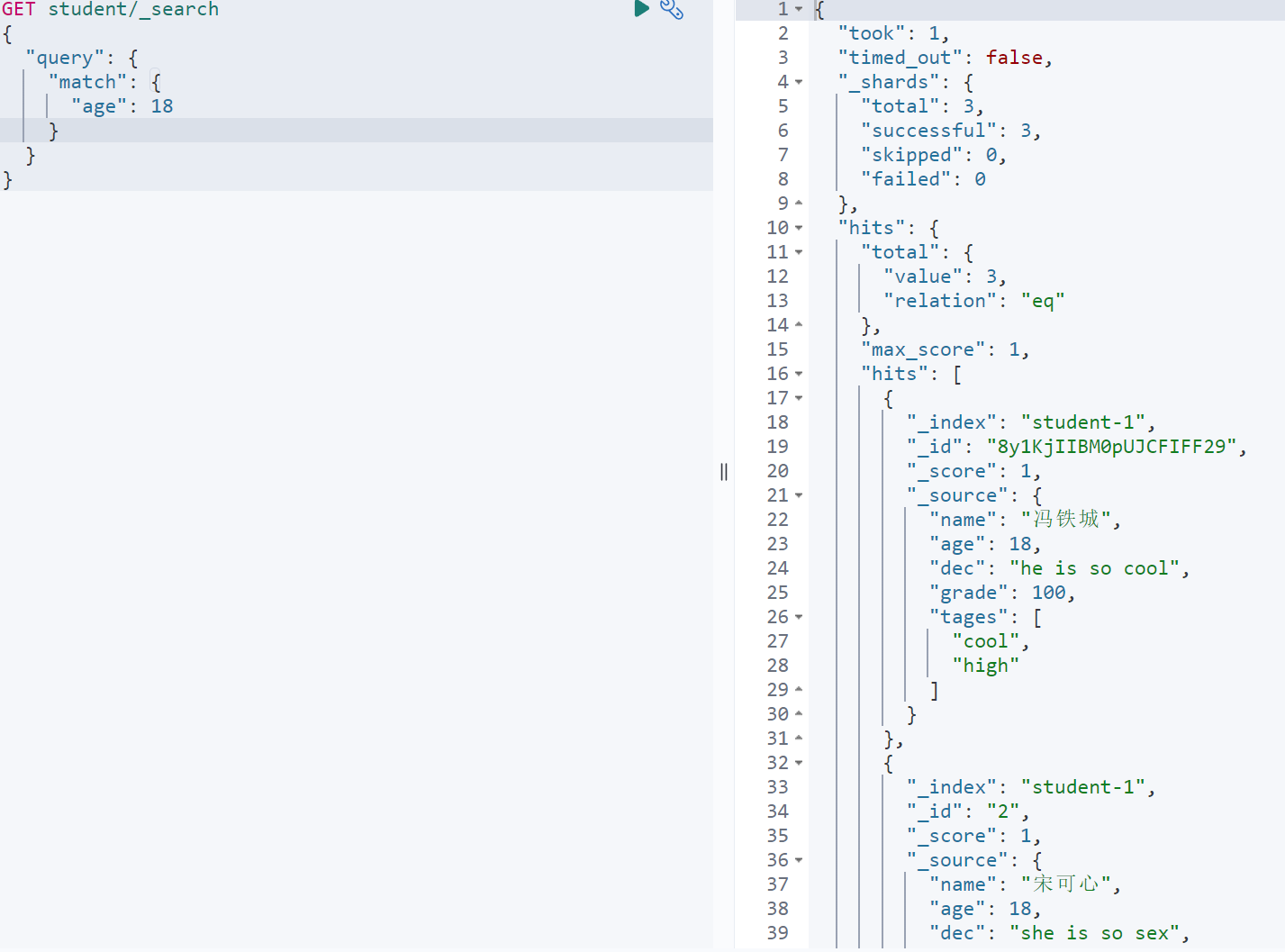
GET student/_search{"query": {"match": {"age": 18}}}
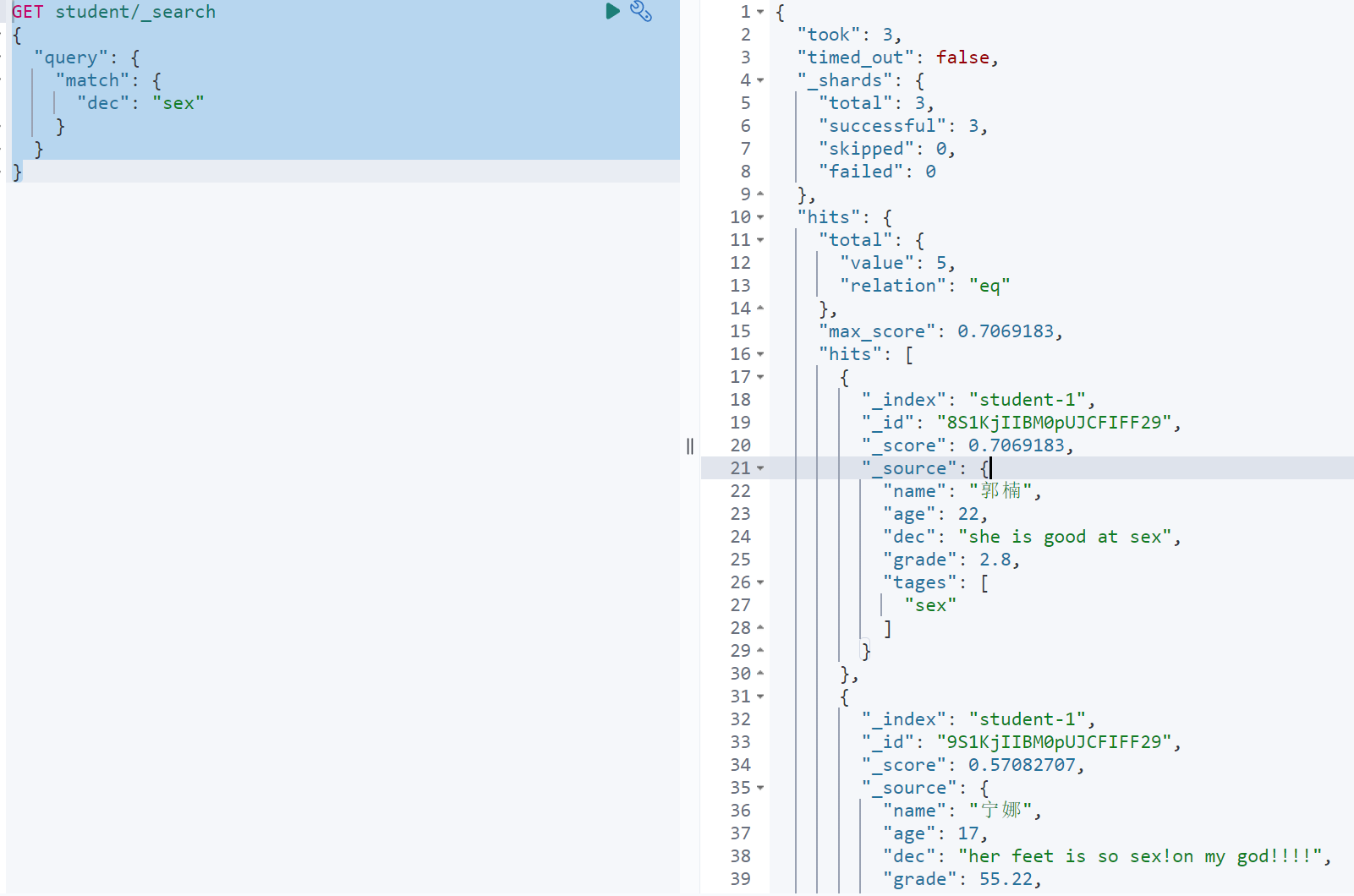
查询描述中有sex词条的学生
GET student/_search{"query": {"match": {"dec": "sex"}}}
原理
match查询本质上是对查询条件执行格式转化和分词之后的term查询,接下来详解其查询原理
非文本字段
将参数进行格式转化,转化为对应的格式。如转为int或bool等
- 如果为一个词条,那么使用term查询,如果为多个词条,那么使用terms查询
- 基于每个term在参数字段的倒排索引中找到对应的倒排表,多个term结果进行交集运算返回
如果使用filter或constant_score查询,无需评分,直接返回。如需要评分操作,进行评分后返回
文本字段
将参数进行分词处理,转化为对应的词条
- 如果为一个词条,那么使用term查询,如果为多个词条,那么使用terms查询
- 基于每个term在参数字段的倒排索引中找到对应的倒排表,多个term结果进行交集运算返回
-
精准度控制
operator
operator的作用在于,假设当前的查询短语是name:i like。
如果operator=or,将返回name中包含like或包含i的文档,默认为or
- 如果operator=and,将返回name中包含like并且包含i的文档
示例:
GET student/_search{"query": {"match": {"dec": {"query": "she sex","operator": "and"}}}}
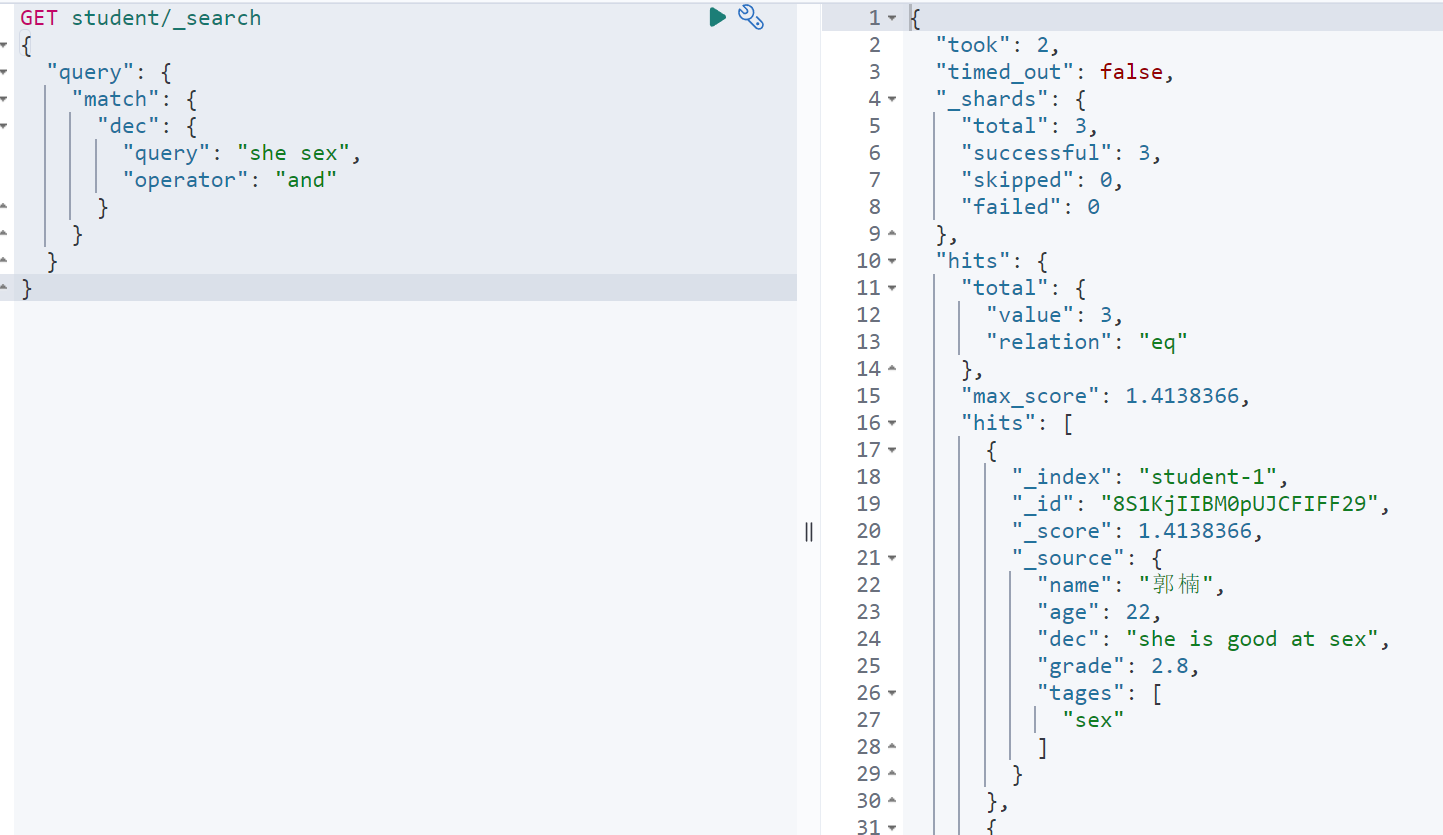
minimum_should_match
minimum_should_match的作用在于,很多时候,需求并没有那么强制性的要求是或否。这时我们可以通过minimum_should_match指定一个百分比,来控制返回文档的匹配度。具体参考文档:链接
示例:
GET student/_search{"query": {"match": {"dec": {"query": "she sex","minimum_should_match": "100%"}}}}
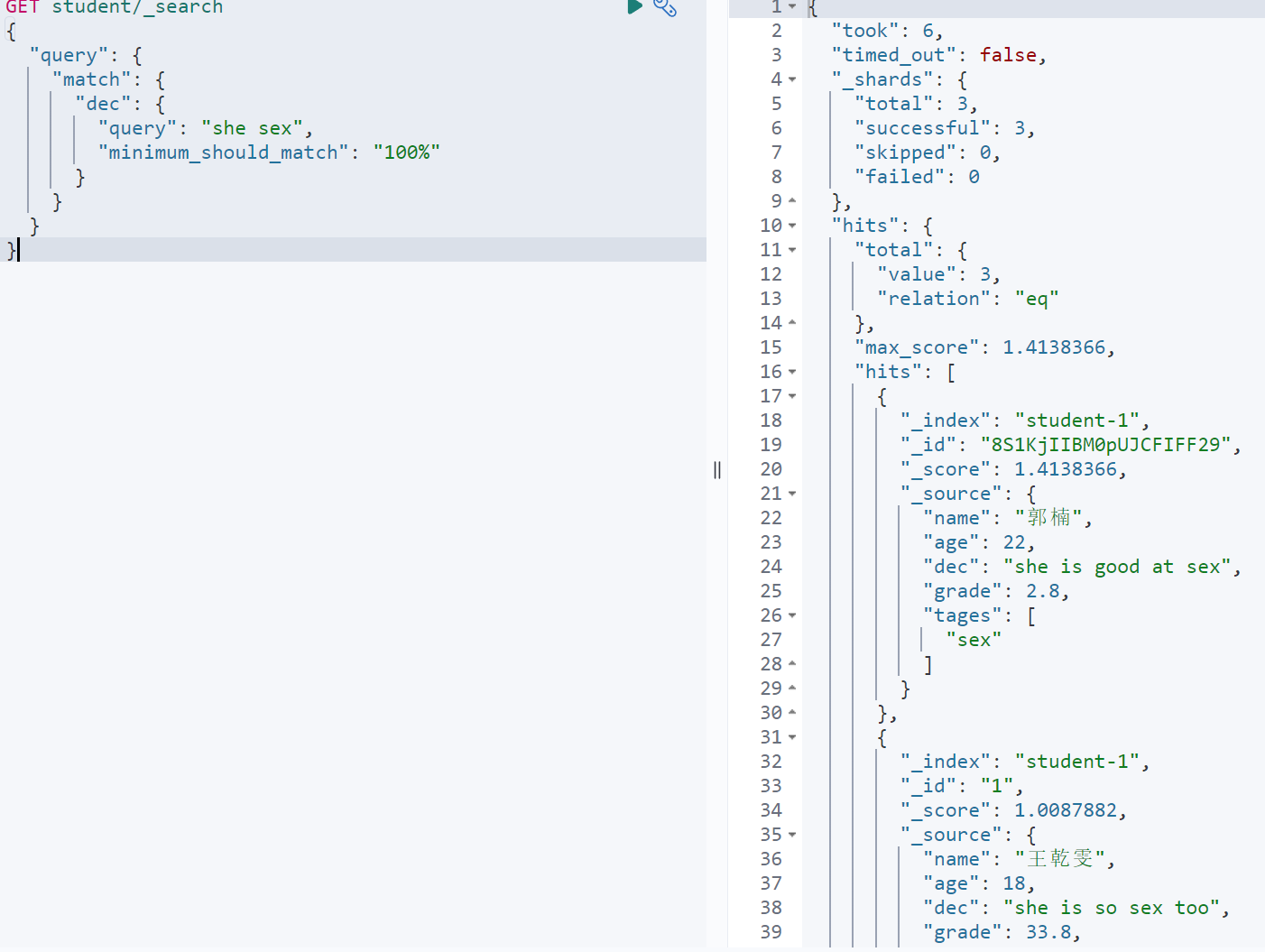
6.muti_match
es中使用muti_match来进行一个值是否匹配多个字段的查询
语法
{"query": {"multi_match": {"query": "","type": "best_fields","fields": []}}}
- query:要查询的短语
- fields:要查询的字段,可以通过_xxx的方式来进行通配符匹配,同时可通过^XXX的方式来指定某个字段的分值计算权重。例如:fields:_name,des^2,代表要查询字段名称格式为*_name的字段,或des字段。同时des字段进行算分时,boost=2,默认boost=1,因此des字段的算分权重大于name
- type:可以理解为算分类型,分为以下几种
- best_fields策略:将某一个字段匹配尽可能多的关键词的文档,优先返回回来
- most_fields策略:将尽可能返回更多字段匹配到某个关键词的文档,优先返回回来
- cross_fields策略:跨字段查询
示例
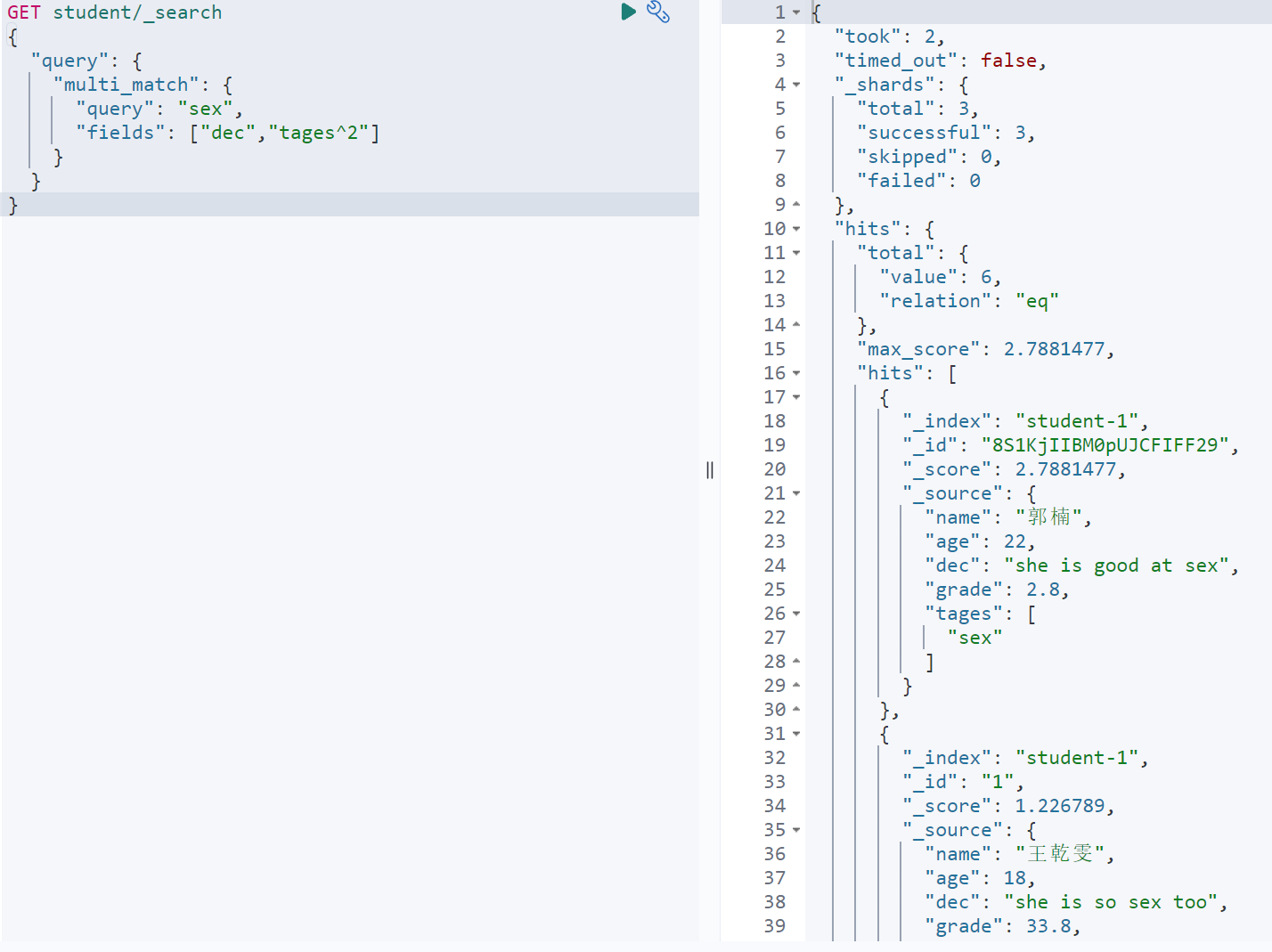
查询描述或标签中包含sex的文档,优先考虑标签字段
GET student/_search{"query": {"multi_match": {"query": "sex","fields": ["dec","tages^2"]}}}
7.match_phrase
es中match会对查询短语进行分词,之后进行全文检索。而有时查询并不需要对短语进行分词,此时就需要用到match_phrase短语查询了
语法
GET student/_search{"query": {"match_phrase": {"field": "value"}}}
或
{"query": {"match_phrase": {"field": {"query": "value","slop": 10}}}}
field:查询字段
- value:查询的值
slop:词条偏移量,slop越大,短语查询的精确匹配度越低。同理,文档字段中被检索词条的slop越小,该文档的评分权重越高
示例
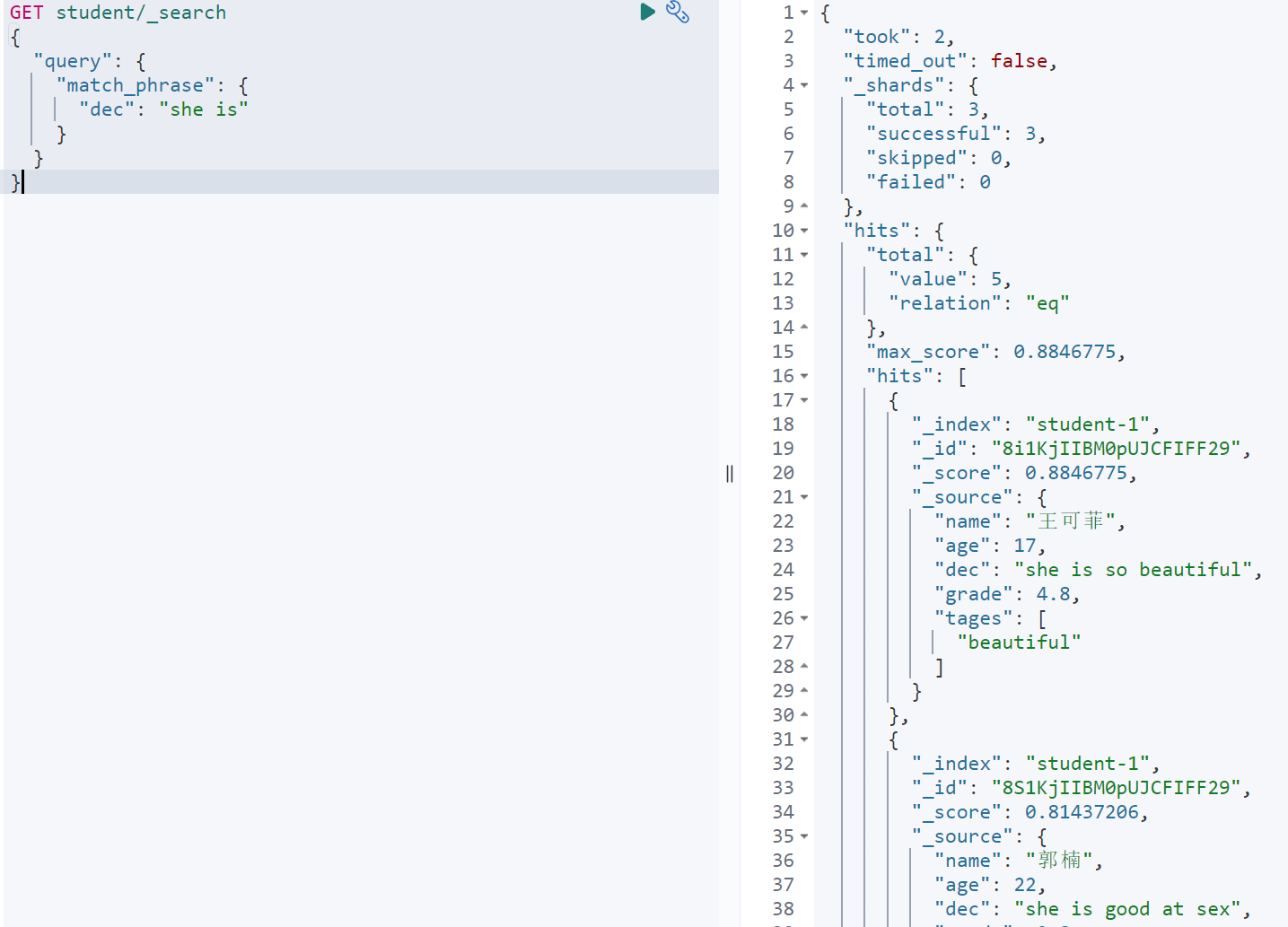
查询dec中包含she is短语的文档
GET student/_search{"query": {"match_phrase": {"dec": "she is"}}}
原理
类似 match 查询, match_phrase 查询首先将查询字符串解析成一个词项列表,然后对这些词项进行搜索,但只保留那些包含全部搜索词项,且位置与搜索词项相同的文档。
可以使用slop扩大词项位置偏移量,slop越大,短语查询精确度越低,查询文档关联性越低,算分权重就越低8.prefix、wildcard、regexp
上述的所有文本查询,其最小单位都是基于词条进行查询。
那么有很多时候,我们想将查询的最小粒度优化到字符级别,比如说,查询姓氏为冯的学生。很明显中文是不会基于空格分词的,这个时候我们就需要用到部分匹配查询prefix、wildcard、regexp语法
假设当前需求为查询姓氏为冯的学生
prefix:{“query”:{“prefix”:{“name”:{“value”:”冯”}}}}
- wildcard:{“query”:{“wildcard”:{“name”:{“value”:”冯*”}}}}
-
示例
GET student/_search{"query": {"prefix": {"name": {"value": "王"}}}}
原理
根据前缀字符在倒排索引中找到对应的词条
- 获取词条对应的文档ID
- 继续查询下一个词条,判定是否以前缀字符开头
- 直到下一个词条不是以前缀字符为止时

很明显,相对于短语查询,常规前缀查询的效率的要低很多。当然这个低是相对于很大的数据量来说的。为了解决这个问题,需要在建立索引时,指定对应字段分词器的token filter类型为 n-gram。通俗点来说,按照字符渐进的方式进行分词,进而将前缀查询优化为了短语查询。详情参考:链接
9.bool
上面说的所有查询方式,都是基于一个查询条件进行的。那么如果一个查询中想要适配多个查询条件,怎么办?es中提供了bool查询来控制多条件查询,bool查询可以嵌套
bool查询中包含了多种属性,接下来一一介绍常用属性
must
must顾名思义,代表必须匹配当前查询条件,可以理解为and关键字。例如,查询姓氏为王,年龄为18的学生:
GET student/_search{"query": {"bool": {"must": [{"prefix": {"name": {"value": "王"}}},{"term": {"age": {"value": "18"}}}]}}}
must_not
也很好理解,代表必须不匹配当前查询条件,可以理解为!。例如,查询年龄不为18且姓氏不为王的学生
GET student/_search{"query": {"bool": {"must_not": [{"prefix": {"name": {"value": "王"}}},{"term": {"age": {"value": "18"}}}]}}}
should
should查询比较复杂,通常来说,should查询的作用仅仅是用于bool查询中的评分影响。但是当一个bool查询时没有must关键字时,should关键字就会影响到查询结果,此时should关键字的作用就可以类比为or关键字
例如:
查询年龄为17或标签包含sex的学生
GET student/_search{"query": {"bool": {"should": [{"term": {"age": {"value": 17}}},{"term": {"tages": {"value": "sex"}}}]}},"sort": [{"age": {"order": "desc"}}]}
查询描述中包含sex的学生,但是优先考虑标签中包含long leg的学生
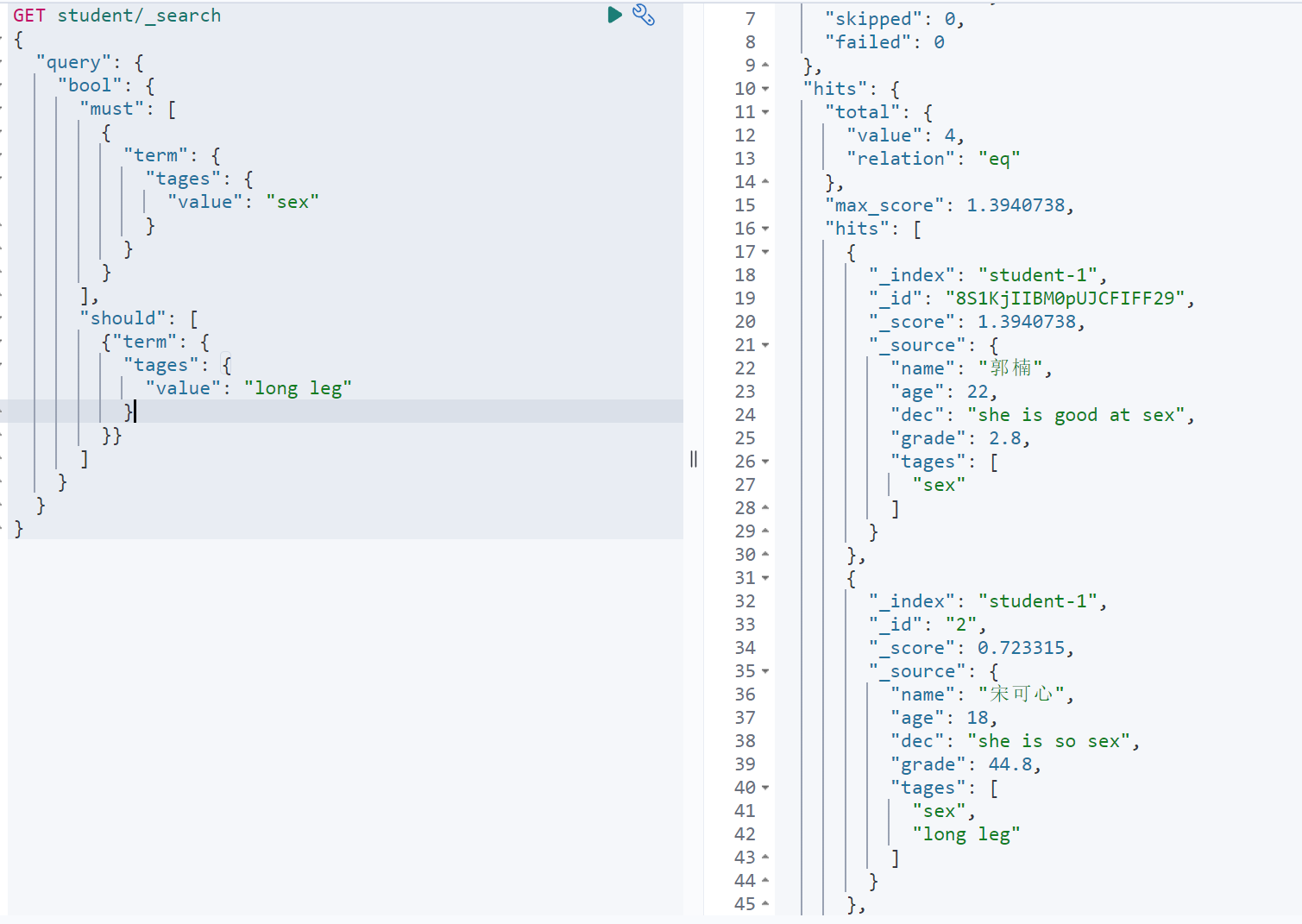
GET student/_search{"query": {"bool": {"must": [{"term": {"tages": {"value": "sex"}}}],"should": [{"term": {"tages": {"value": "long leg"}}}]}}}
混合查询
查询姓氏为王,并且标签中包含cute或like fuck的学生
GET student/_search{"query": {"bool": {"must": [{"prefix": {"name": {"value": "王"}}},{"bool": {"should": [{"term": {"tages": {"value": "cute"}}},{"term": {"tages": {"value": "like fuck"}}}]}}]}}}

查询年龄大于17岁,或者标签中包含sex或like fuck的学生
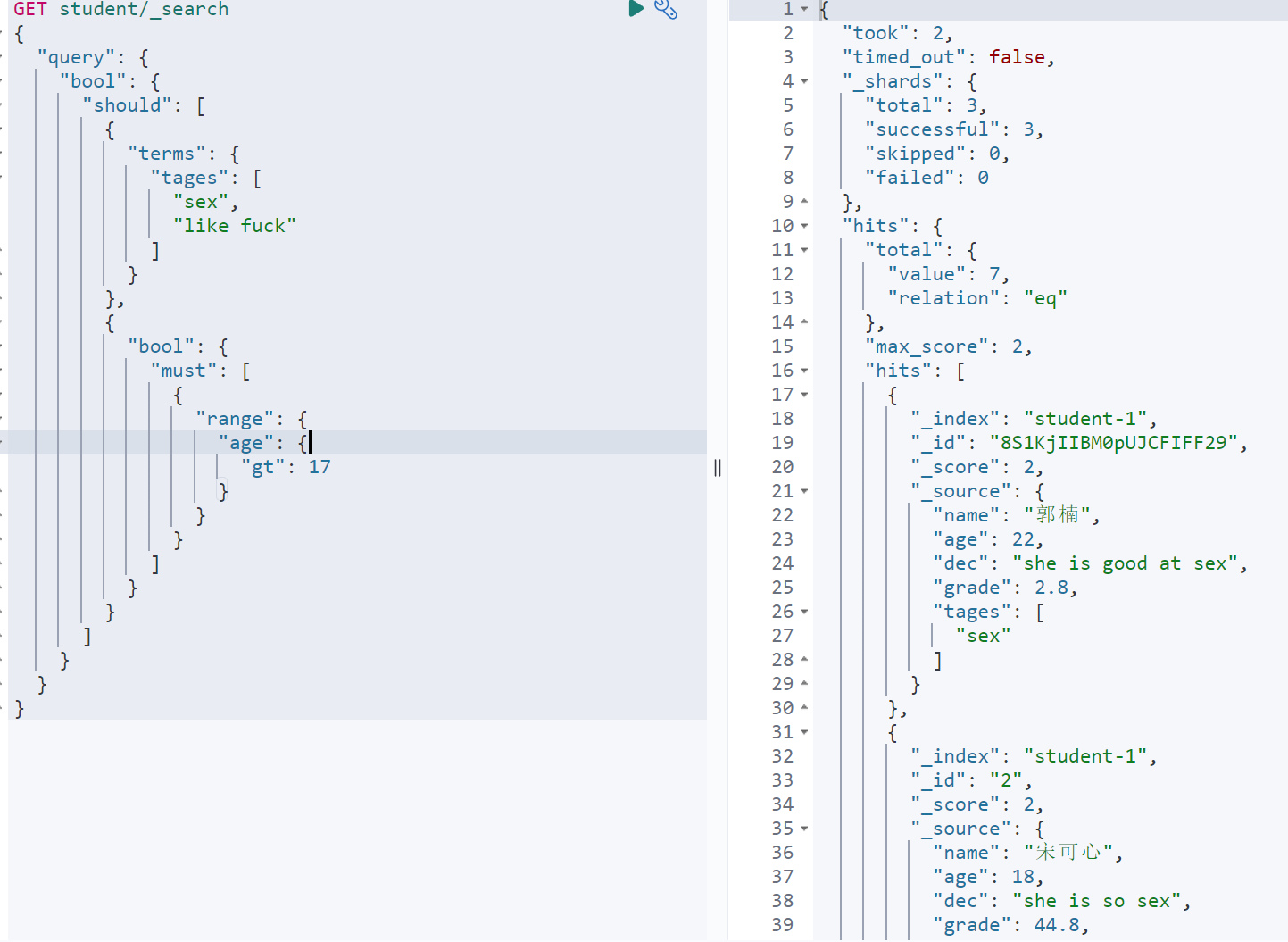
GET student/_search{"query": {"bool": {"should": [{"terms": {"tages": ["sex","like fuck"]}},{"bool": {"must": [{"range": {"age": {"gt": 17}}}]}}]}}}
10.score计算详解
大神们我学不动了,自行阅读:链接

若有收获,就点个赞吧
0 人点赞
