1.核心概念
想要了解es中的聚合,需要先了解桶和指标的概念。es中的聚合就是一个或多个桶和零个或多个指标的组合
例如:select sum(grade) from user where age >13
- age >13即是一个桶,这个桶中存放的,都是年龄大于13的用户
- sum(grade)就是指标,对age>13的桶进行了成绩字段的求和计算
桶(Buckets)
满足特定条件的文档的集合。可以理解为将es中存储的文档,通过一定的条件,整合到了一个虚拟的概念中,这个概念就称为桶。
当聚合开始被执行,每个文档里面的值通过计算来决定符合哪个桶的条件。如果匹配到,文档将放入相应的桶并接着进行聚合操作。
桶也可以被嵌套在其他桶里面,提供层次化的或者有条件的划分方案。
指标(Metrics)
对桶内的文档进行统计计算。大多数 指标 是简单的数学运算(例如最小值、平均值、最大值,还有汇总),这些是通过文档的值来计算。
例如计算nba联盟中,金州勇士队队龄超过10年的nba球员个数
- 通过球队划分桶(金州勇士)
- 然后通过队龄划分桶(超过10年)
- 然后通过职能划分桶(队员)
-
2.准备数据
汽车订单索引
创建索引:包含颜色(color)、制造商(make)、价格(price)、售卖日期(sold)4个字段
PUT cars_order{"mappings": {"properties" : {"color" : {"type" : "keyword"},"make" : {"type" : "keyword"},"price" : {"type" : "long"},"sold" : {"type" : "date"}}}}
批量存储数据
POST /cars_order/_bulk{ "index": {}}{ "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" }{ "index": {}}{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }{ "index": {}}{ "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" }{ "index": {}}{ "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" }{ "index": {}}{ "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" }{ "index": {}}{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }{ "index": {}}{ "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" }{ "index": {}}{ "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2014-02-12" }{ "index": {}}{ "price" : 120000, "color" : "yellow", "make" : "ford", "sold" : "2014-06-11" }{ "index": {}}{ "price" : 90000, "color" : "yellow", "make" : "ford", "sold" : "2014-03-03" }
网站请求索引
创建索引:包含延迟(latency)、请求时间(timestamp)、请求地区(zone)3个参数
PUT website{"mappings": {"properties": {"latency": {"type": "long"},"timestamp": {"type": "date"},"zone": {"type": "keyword"}}}}
批量添加数据
POST /website/_bulk{ "index": {}}{ "latency" : 100, "zone" : "US", "timestamp" : "2014-10-28" }{ "index": {}}{ "latency" : 80, "zone" : "US", "timestamp" : "2014-10-29" }{ "index": {}}{ "latency" : 99, "zone" : "US", "timestamp" : "2014-10-29" }{ "index": {}}{ "latency" : 102, "zone" : "US", "timestamp" : "2014-10-28" }{ "index": {}}{ "latency" : 75, "zone" : "US", "timestamp" : "2014-10-28" }{ "index": {}}{ "latency" : 82, "zone" : "US", "timestamp" : "2014-10-29" }{ "index": {}}{ "latency" : 100, "zone" : "EU", "timestamp" : "2014-10-28" }{ "index": {}}{ "latency" : 280, "zone" : "EU", "timestamp" : "2014-10-29" }{ "index": {}}{ "latency" : 155, "zone" : "EU", "timestamp" : "2014-10-29" }{ "index": {}}{ "latency" : 623, "zone" : "EU", "timestamp" : "2014-10-28" }{ "index": {}}{ "latency" : 380, "zone" : "EU", "timestamp" : "2014-10-28" }{ "index": {}}{ "latency" : 319, "zone" : "EU", "timestamp" : "2014-10-29" }
3.聚合命令
格式
首先要学习下es中聚合命令的格式,如下
GET index_name/_search{"aggs": {"NAME": {"AGG_TYPE": {}}}}
index_name:索引名称
- aggs:聚合修饰符
- NAME:自定义变量名称,用于返回聚合结果时的变量名
- AGG_TYPE:聚合类型,es中包括了多种聚合类型,常用的聚合相关命令包括如下
聚合命令: :::success
- terms:按照匹配条件进行聚合,可以按照条件将文档存入不同的桶中,进行后续操作
- histogram:条形图(折方图),可以指定步长,按照步长递增进行聚合。例如指定步长为100,那么就会聚合出0~100,100~200……等以此类推个桶
- date_histogram:时间条形图(折方图),可以指定时间频率,按照时间频率进行聚合,例如每秒,每分,每月,每年等
- cardinality:去重计算,存在一定的误差值,可以参考HyperLogLog
- percentiles:获取字段不同百分比数对应的值,常用语异常记录获取
percentile_ranks:获取值对应的百分比数,常用语异常记录获取 ::: 结果集过滤命令: :::success
filter:对聚合结果进行过滤,对查询结果不过滤
post_filter:对聚合结果不过滤,对查询结果过滤 ::: 指标计算命令: :::success
avg:计算平均值
- sum:求和
- min:最小值
- max:最大值
:::
示例
获取每个颜色汽车的销量
可以看到GET cars_order/_search{"aggs": {"color_sold_count": {"terms": {"field": "color"}}}}
- 自定义返回的字段名称为color_sold_count
- 聚合类型为terms
- 聚合字段为color,意味着按照color进行桶的划分
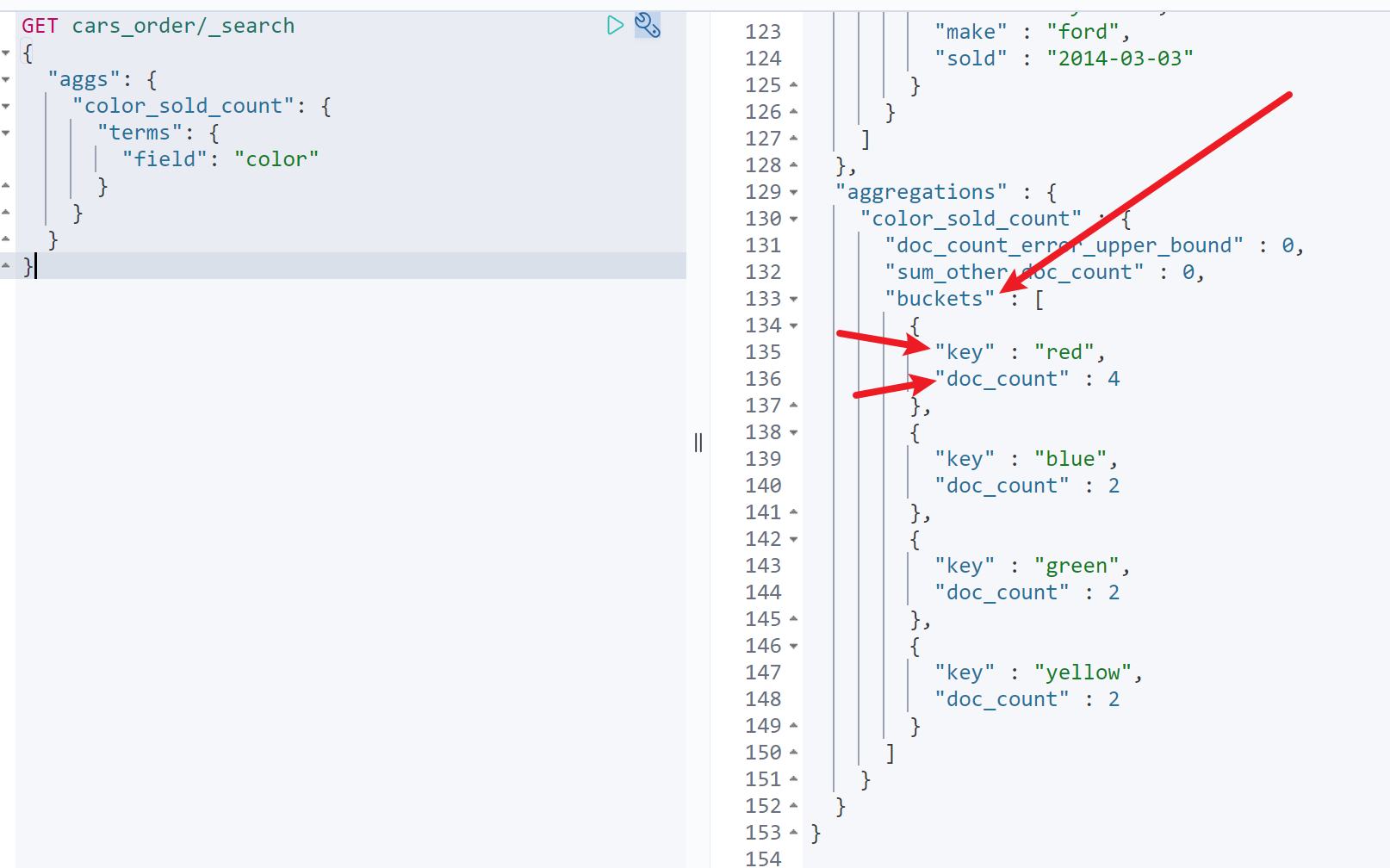
如图,可以看到聚合结果和查询结果一起返回。
- 聚合结果中包含buckets字段,代表根据颜色进行terms聚合,共生成了4个桶。
- 每个桶中包括key和doc_count字段
- key代表当前桶的聚合依据字段
doc_count代表当前桶中文档的数量,默认排序按照doc_count倒序排列
4.嵌套聚合
es中默认支持聚合的嵌套,意味着可以在一个桶中再次进行桶的划分,从而获取不同情况下更为详细的数据,在这之前,先学习一下terms聚合的命令格式
terms
terms命令格式如下,以下包含了部分的常用参数
GET index_name/_search{"aggs": {"NAME": {"terms": {"field": "","size": 10,"collect_mode": "depth_first","order": {"_key": "asc"}}}}}
field:对哪个字段进行聚合
- size:返回桶中的多少个数据,通常可以结合排序模式进行使用,默认值=10
- collect_mode:集合模式,包括深度优先遍历(depth_first)和广度优先遍历(breadth_first)两种。对于数组类型的字段,在使用深度优先遍历的情况下,可能会导致占用内存过多的情况。因为深度优先遍历会将数据全部加载到内存中后再进行剪枝操作
order:排序,默认按照doc_count倒序排列,可以指定默认字段或子聚合字段进行排序
聚合嵌套示例
在了解了如何使用terms进行聚合之后,可以开始学习如何嵌套聚合,嵌套聚合分为同层嵌套的子嵌套
同层嵌套
例如:统计每种颜色和每个厂商的汽车销量
GET cars_order/_search{"aggs": {"color_sold_count": {"terms": {"field": "color"}},"make_sold_count": {"terms": {"field": "make"}}}}
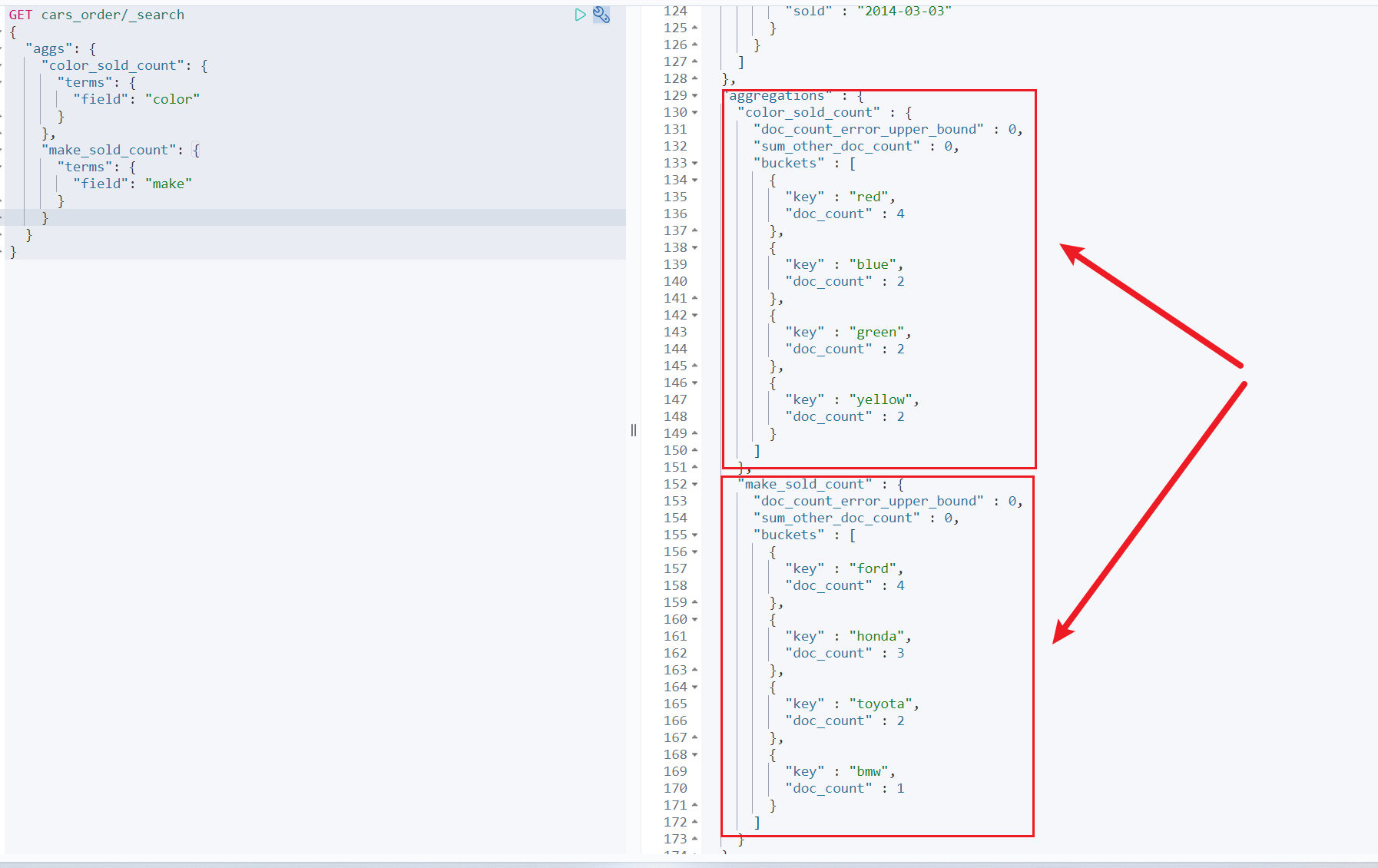
可以看到,从两个纬度进行了桶的聚合,分别是颜色和制造商。可以从中直观的看出,不同颜色以及不同制造商的销量子聚合嵌套
假设当前有这样一个需求:获取不同颜色汽车的销量,同时统计每种颜色汽车中每个制造商的销量以及每个制造商的总销售额
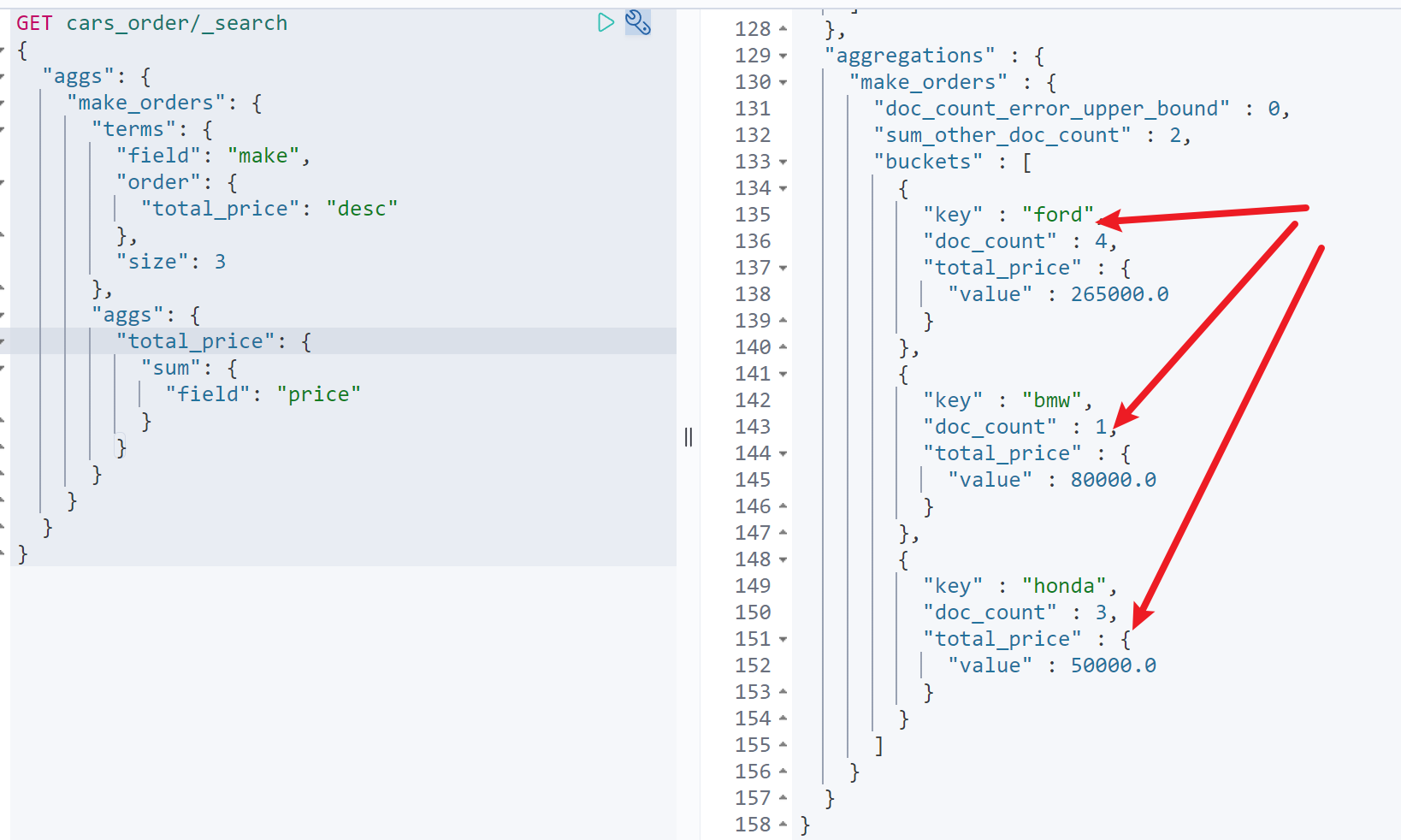
这时候,就需要用到自聚合嵌套。具体命令如下GET cars_order/_search{"aggs": {"color_sold_count": {"terms": {"field": "color"},"aggs": {"make_sold_count": {"terms": {"field": "make"},"aggs": {"make_all_price": {"sum": {"field": "price"}}}}}}}}
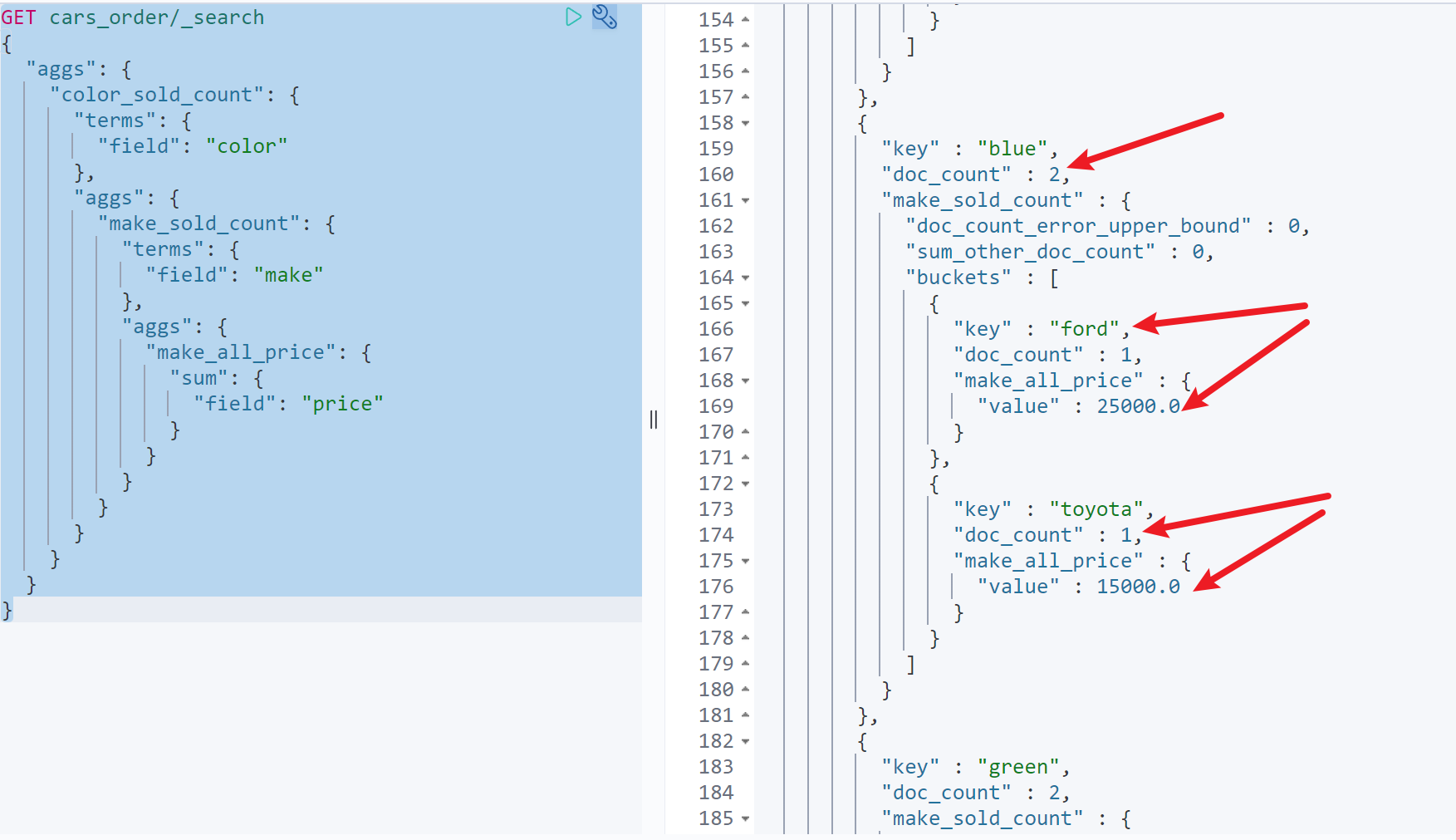
如图,可以看到,蓝色汽车总销售额=2,其中福特汽车销售额=1,Toyota汽车销售额=1,福特汽车总售价25000,toyota总销售额15000。
从上述例子就可以看出,通过嵌套聚合,可以非常方便且直观的对于聚合的结果进行在统计,这在线上应用中将十分的有用5.条形图
terms聚合可以通过文档中的某个字段进行桶的划分并进行相应的指标运算。
但是有的时候,我们想要通过一些范围步长,来进行桶的划分。比如说,统计20000以内,20000到40000,40000到60000……依次递增的不同范围的汽车售价,此时就需要用到条形图聚合了。注意
条形图聚合只适用于数字类型的字段,例如int,long,double,float等,其他类型不适配
格式
GET index_name/_search{"aggs": {"NAME": {"histogram": {"field": "price","interval": 20000,"order": {"_key": "asc"},"min_doc_count": 0,"extended_bounds": {"min": 0,"max": 300000}}}}}
field:聚合字段名称
- interval:步长,可根据场景自行指定
- order:排序,默认按照key升序排列
- min_doc_count:最小文档数,当指定了最小文档数之后,桶中文档数小于该值的,不会出现在聚合结果中
extended_bounds:范围,默认最小值=0,最大值=文档中对应字段的最大值。可以通过extended_bounds指定最大值以及最小值,进而过滤掉一些无意义的值,同时可以搭配min_doc_count进行进一步的过滤
示例
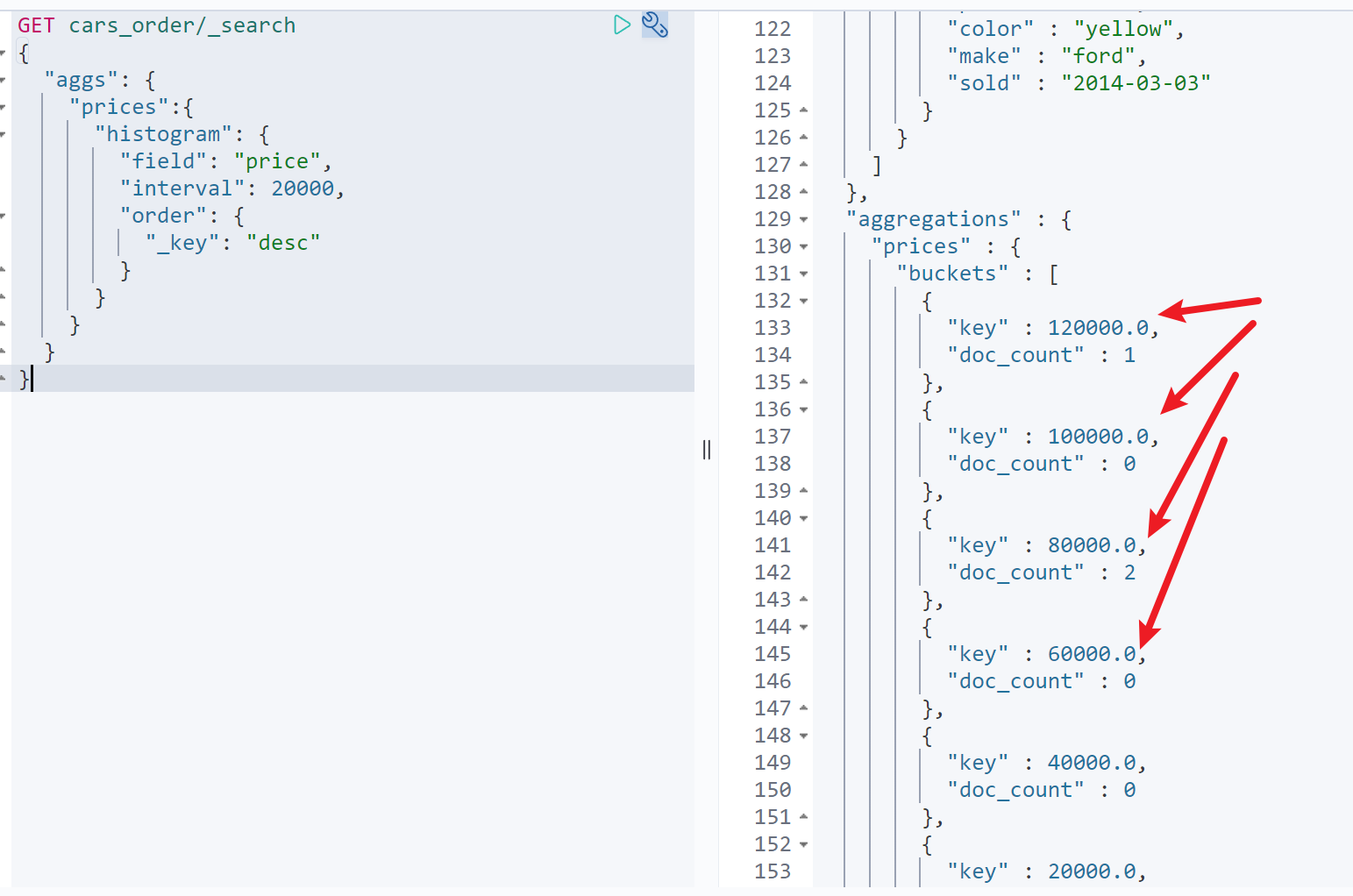
按照销售额步长为20000统计不同颜色汽车的销量
GET cars_order/_search{"aggs": {"price_sold": {"histogram": {"field": "price","interval": 20000},"aggs": {"color_sold_count": {"terms": {"field": "color"}}}}}}
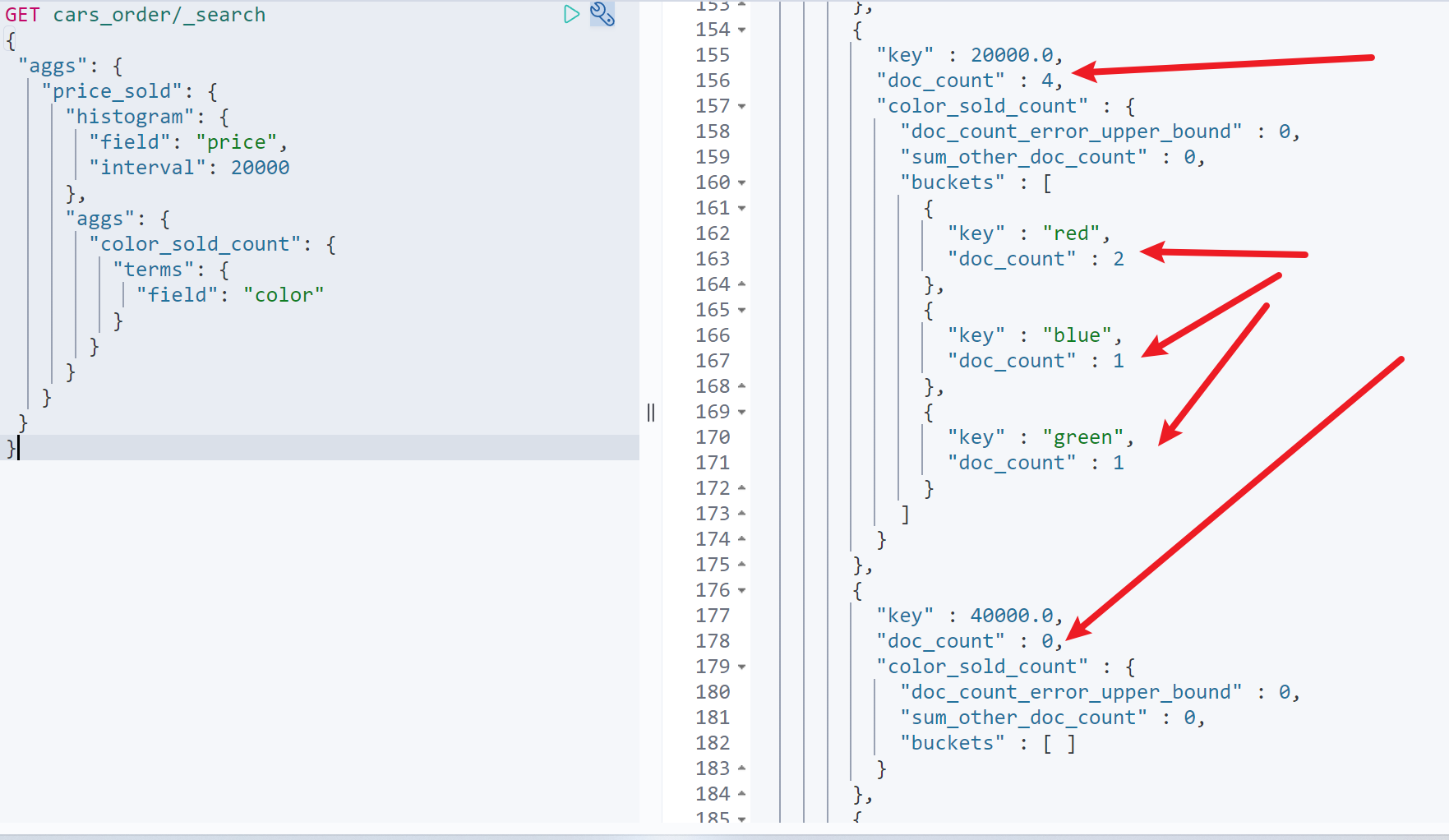
如图:可以看出20000~40000的销量=4,40000~60000的销量=0。同时在20000~40000的区间中,红蓝绿对应的销量分别为2,1,1。6.时间条形图
在很多时候,会存在按照每月,每天等需求进行条形图展示和区分,此时就需要用到时间条形图了
注意
格式
GET index_name/_search{"aggs": {"NAME": {"date_histogram": {"field": "sold","calendar_interval": "1M","format": "yyyy-MM-dd","order": {"_key": "asc"},"min_doc_count": 0,"extended_bounds": {"min": 0,"max": 300000}}}}}
field:执行聚合的字段
- calendar_interval:时间步长,常用的包括如下值 :::success
- 1s:每秒
- 1m:每分
- 1h:每小时
- 1d:每天
- 1M:每月
- 1q:每季度
- 1y:每年 :::
- format:返回的key_as_string字段的日期格式化形式
- min_doc_count:最小文档数,当指定了最小文档数之后,桶中文档数小于该值的,不会出现在聚合结果中
- order:排序,默认按照key升序排列
extended_bounds:范围,默认最小值=0,最大值=文档中对应字段的最大值。可以通过extended_bounds指定最大值以及最小值,进而过滤掉一些无意义的值,同时可以搭配min_doc_count进行进一步的过滤
示例
每个季度,不同汽车品牌的销售总额
GET cars_order/_search{"aggs": {"price_all": {"date_histogram": {"field": "sold","calendar_interval": "1q","format": "yyyy-MM-dd"},"aggs": {"make_all": {"terms": {"field": "make"},"aggs": {"make_price": {"sum": {"field": "price"}}}}}}}}
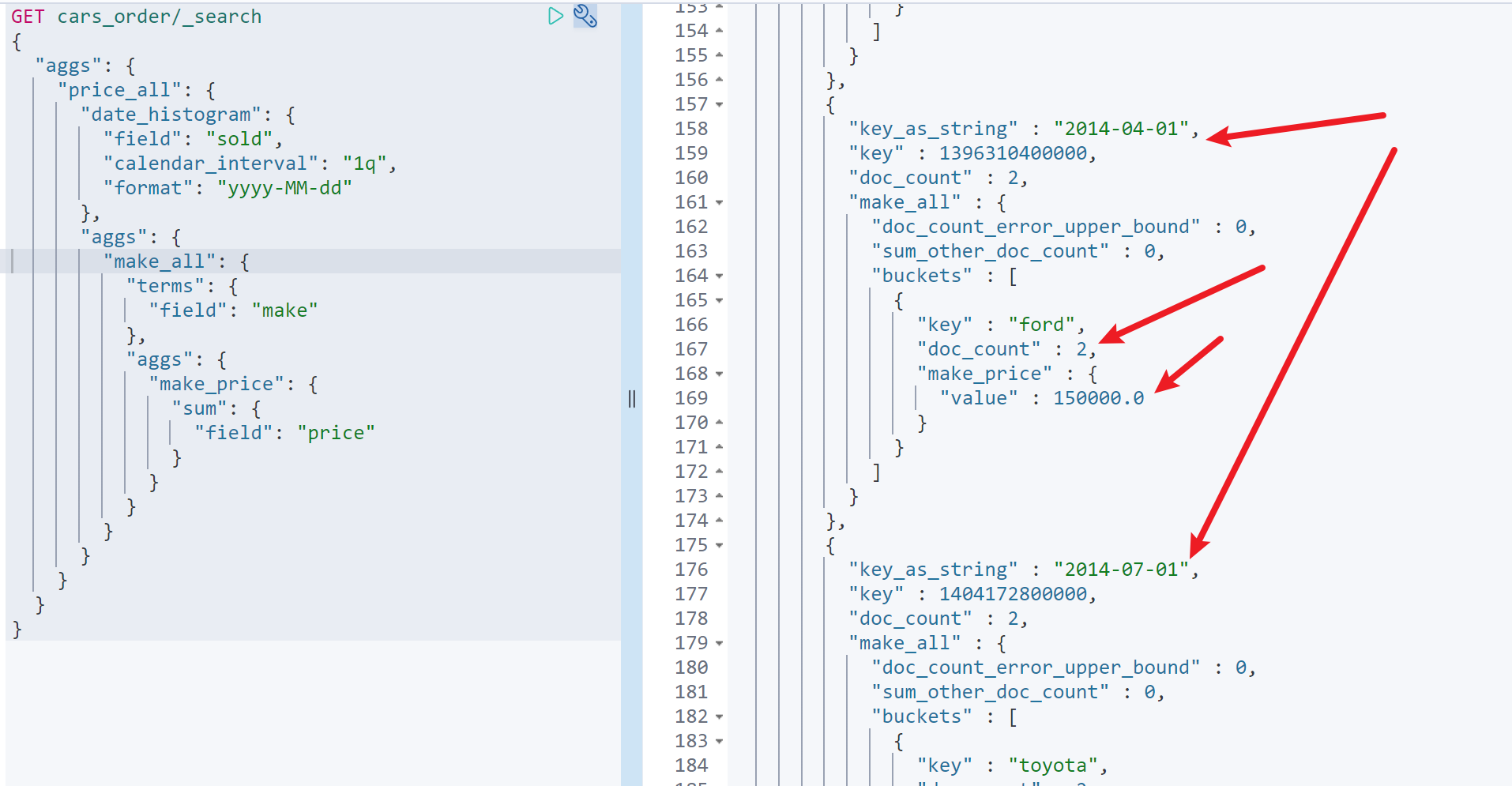
如图,可以看到第二季度共售出2辆车,2辆车都是福特车,总销售额1500007.过滤
经过了上述的聚合学习,目前已经可以对索引中的全部文档进行各种姿势的聚合操作了。但是有时候,我们并不想对全部文档进行聚合,亦或者需要对查询结果或聚合结果进行聚合,此时就需要用到过滤的知识了,过滤包括以下三种,接下来一一进行讲解
查询和聚合都过滤
这是一种最常见的情况,对索引中的部分文档进行聚合,同时对于查询结果和聚合结果都进行过滤。此时在aggs同级使用query即可
示例
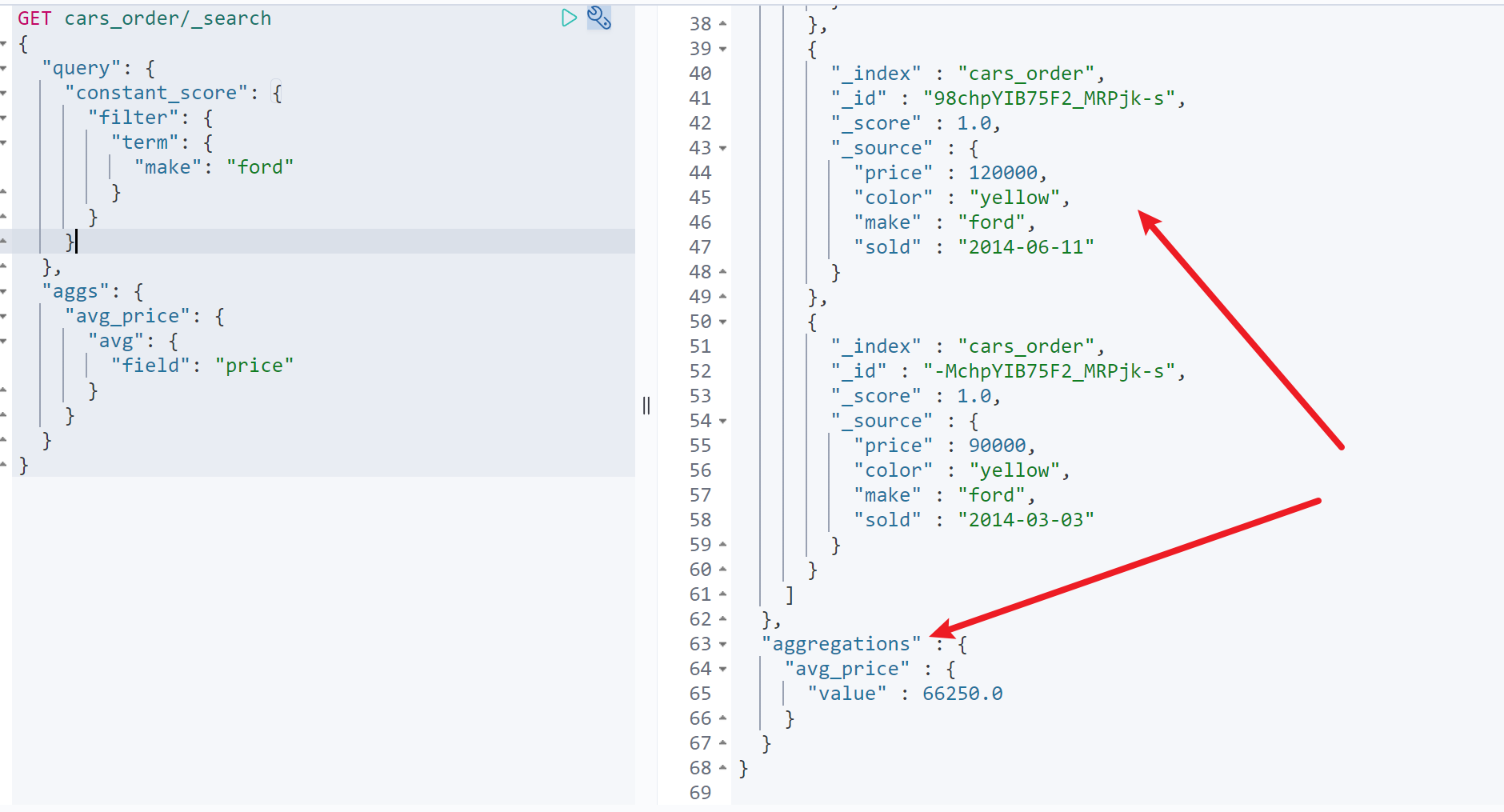
统计福特汽车的售价平均值
GET cars_order/_search{"query": {"constant_score": {"filter": {"term": {"make": "ford"}}}},"aggs": {"avg_price": {"avg": {"field": "price"}}}}
global:{}
global:{}属性,可以是当前层面聚合获取全部文档,又不影响其他层面
例如:获取福特汽车均价以及所有汽车均价,看看福特汽车的价格是否合理GET cars_order/_search{"query": {"constant_score": {"filter": {"term": {"make": "ford"}}}},"aggs": {"ford_avg": {"avg": {"field": "price"}},"all_order":{"global": {},"aggs": {"all_avg": {"avg": {"field": "price"}}}}}}

如图,可以看到福特汽车均价为66250,所有汽车的平均售价为42200聚合过滤
有时候,我们并不需要过滤查询结果,仅仅是想要过滤聚合结果,此时就需要做到嵌套filter到aggs中来实现
示例
查询所有福特汽车订单,统计福特汽车中黄色汽车的销售总额
GET cars_order/_search{"query":{"constant_score":{"filter":{"term":{"make":"ford"}}}},"aggs":{"cars_order":{"aggs":{"color_cars_order":{"terms":{"field":"color"},"aggs":{"total_price":{"sum":{"field":"price"}}}}},"filter":{"term":{"color":"yellow"}}}}}
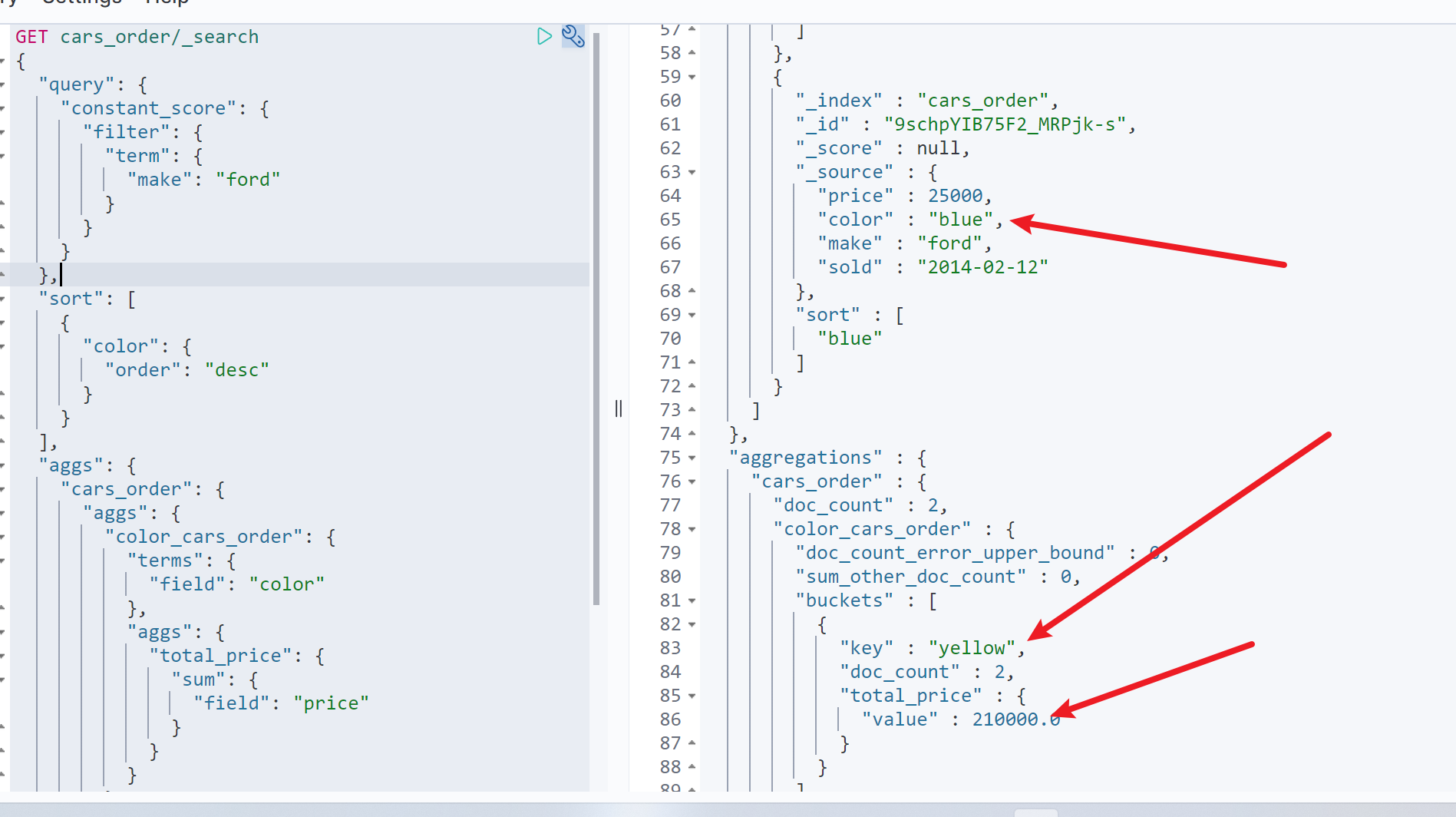
如图可以看到,查询结果中仍然包含蓝色汽车,但是聚合中仅包含黄色汽车的聚合信息查询过滤
同理,有时候,我们需要对查询结果过滤,但是对于聚合结果不过滤。此时就需要使用post_filter来进行查询后的查询结果过滤
示例
查询展示蓝色福特汽车,同时统计不同颜色汽车的销售均价
GET cars_order/_search{"aggs": {"color_cars": {"terms": {"field": "color"},"aggs": {"avg_price": {"avg": {"field": "price"}}}}},"post_filter": {"bool": {"must": [{"term": {"make": {"value": "ford"}}},{"term": {"color": {"value": "blue"}}}]}}}
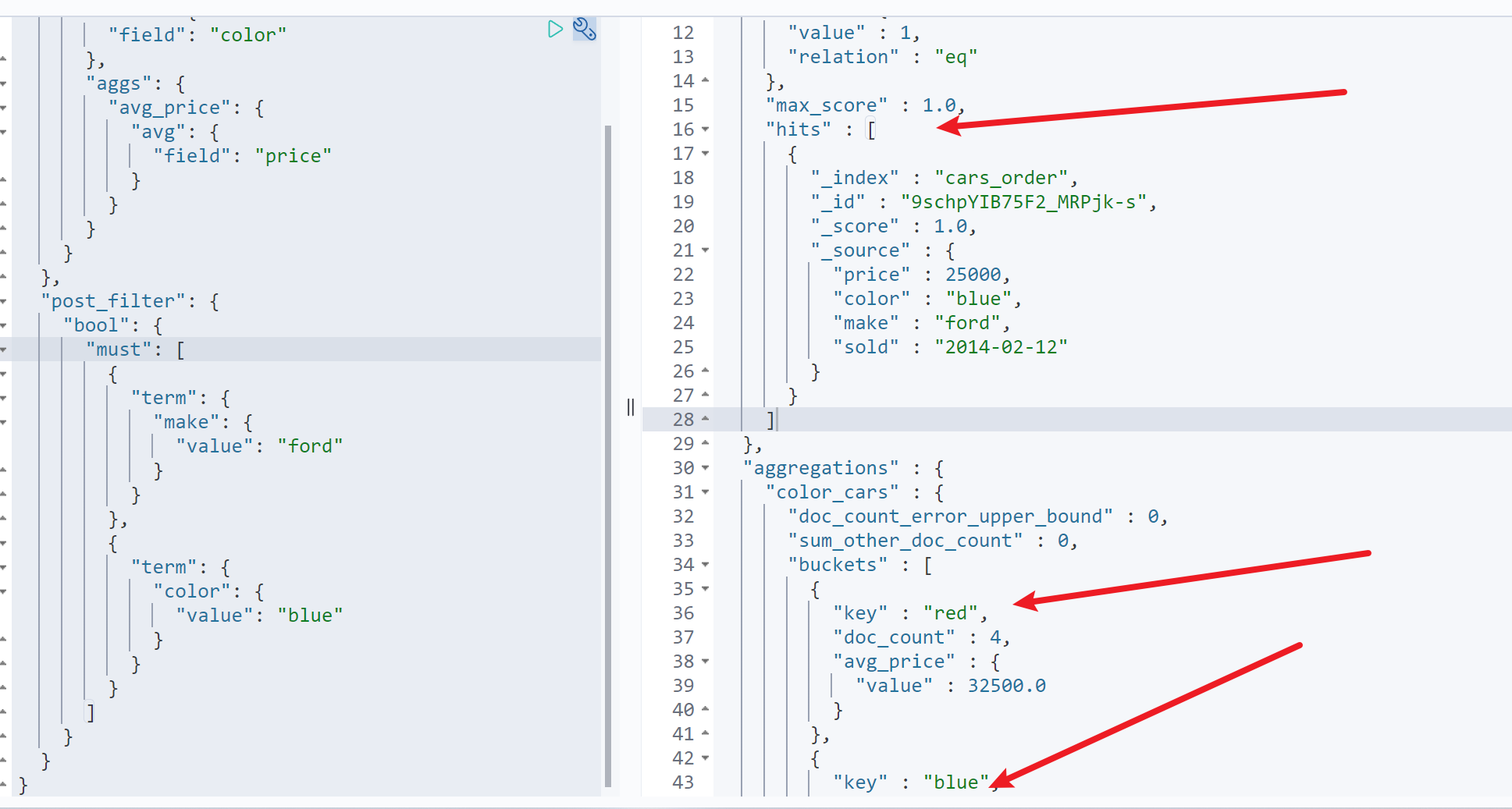
如图,查询结果只返回了蓝色的福特汽车订单,但是聚合结果中,又同时返回了所有订单的聚合结果
需要注意的是postfilter仅适用于聚合中使用 , 不要在普通搜索使用 post_filter 。
post_filter 的特性是在查询 之后_ 执行,这意味着当数据量过大时,会急剧影响查询的性能。8.排序
在聚合结果中,不同的聚合操作默认的排序规律不同。但是都是基于默认字段的排序,很多时候,我们也想要根据自定义的字段排序,接下来详细说明下两种排序使用
默认排序
terms聚合默认使用doc_count倒序排列,也可以使用_count表示doc_count字段
GET cars_order/_search{"aggs": {"make_order": {"terms": {"field": "make","order": {"_count": "asc"}}}}}
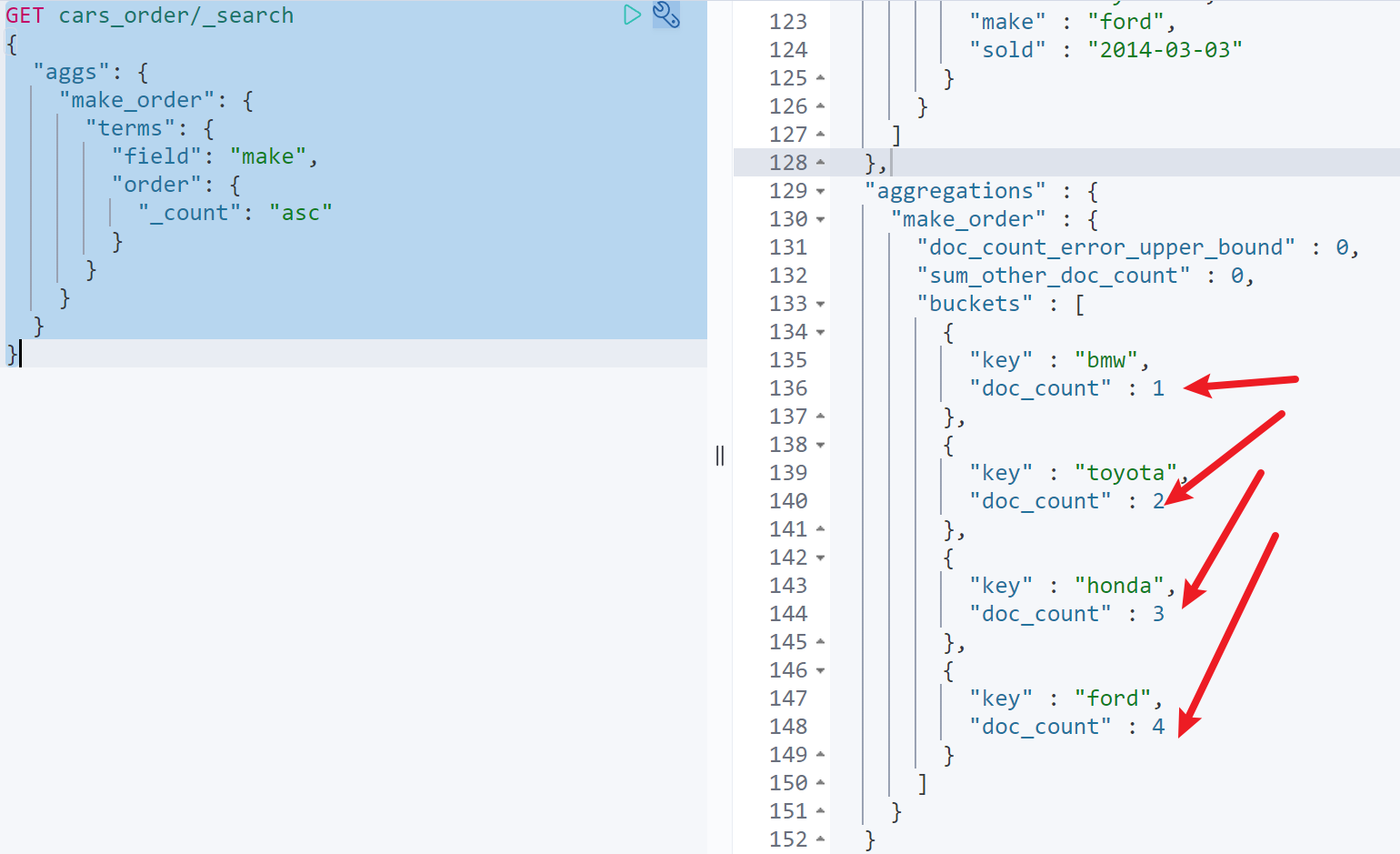
可以看到按照doc_count升序排列histogram、date_histogram默认按照key升序排列,也可以使用_key表示key字段
GET cars_order/_search{"aggs": {"prices":{"histogram": {"field": "price","interval": 20000,"order": {"_key": "desc"}}}}}
自定义排序
同层级
自定义排序同样很简单,只要排序字段在聚合中存在即可
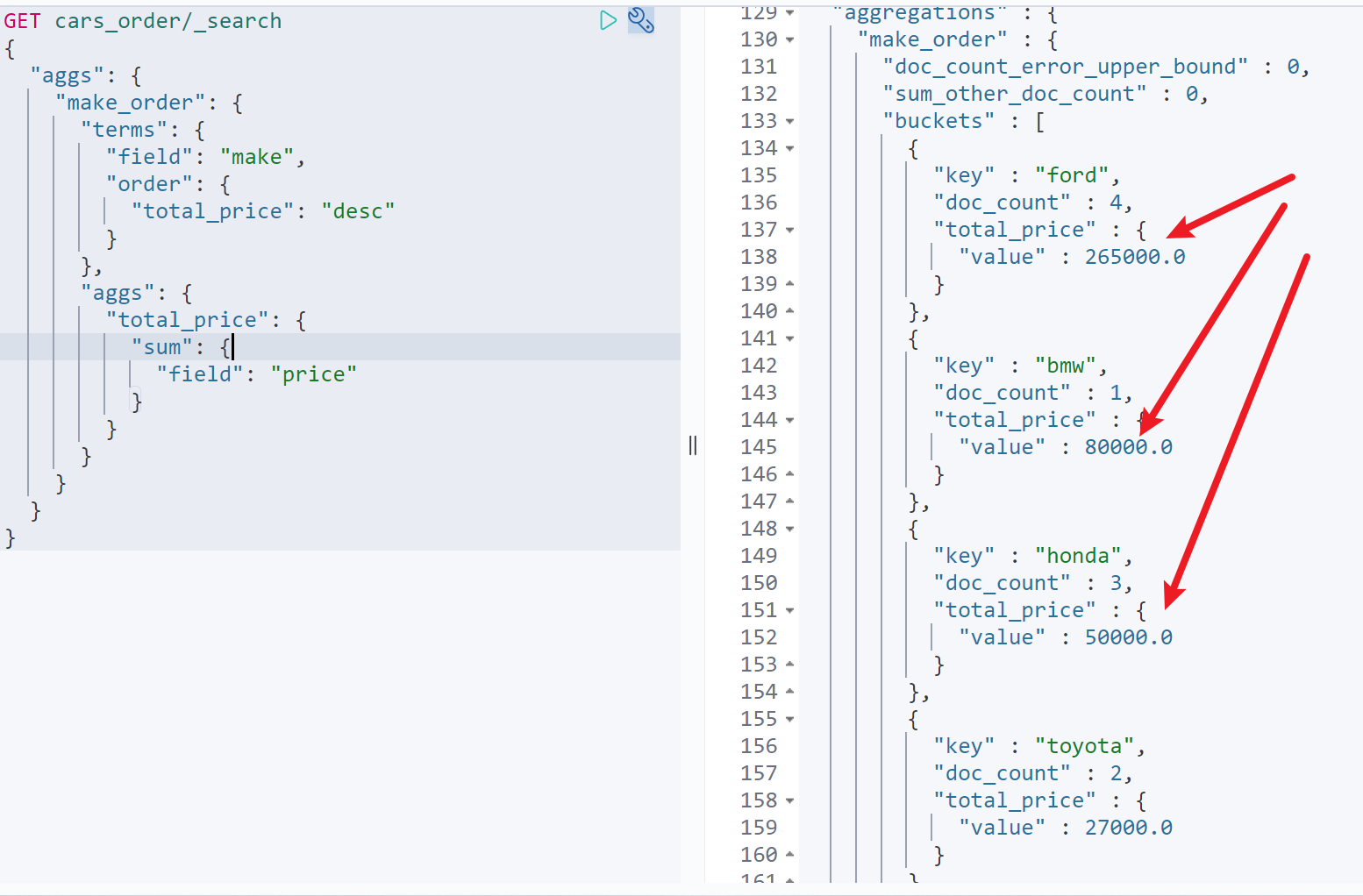
例如统计所有厂商的销售总额,并明确了解谁的销售总额最高GET cars_order/_search{"aggs": {"make_order": {"terms": {"field": "make","order": {"total_price": "desc"}},"aggs": {"total_price": {"sum": {"field": "price"}}}}}}
深层级
有时当聚合层级较深时,我们想要依靠深层及聚合指标进行排序,此时可以通过”>”符号来进行链接
例如:获取每个季度,每个厂商黄色汽车销售总额,并且直观看到黄色汽车销售总额高的厂商GET cars_order/_search{"aggs": {"date_orders": {"date_histogram": {"field": "sold","calendar_interval": "1q","format": "yyyy-MM-dd"},"aggs": {"make_orders": {"terms": {"field": "make","order": {"yellow_orders>total_price": "desc"}},"aggs": {"yellow_orders": {"filter": {"terms": {"color": ["yellow"]}},"aggs": {"total_price": {"sum": {"field": "price"}}}}}}}}}}
与size进行结合
有时候,通过排序与size结合,可以方便的过滤到我们想要的数据
例如:获取汽车销量前三名的厂商GET cars_order/_search{"aggs": {"make_orders": {"terms": {"field": "make","order": {"total_price": "desc"},"size": 3},"aggs": {"total_price": {"sum": {"field": "price"}}}}}}
9.近似聚合
对于聚合来说,不是所有的算法都像获取最大值这样简单。很多时候我们想要获取一个总的值,例如总数和百分比数,而这些操作往往都很复杂,因此需要在算法的性能和内存使用上做出权衡。
Elasticsearch 目前支持两种近似算法( cardinality 和 percentiles )。 它们会提供准确但不是 100% 精确的结果。 以牺牲一点小小的估算错误为代价,这些算法可以为我们换来高速的执行效率和极小的内存消耗。
对于 大多数 应用领域,能够实时返回高度准确的结果要比 100% 精确结果重要得多。cardinality(去重统计)
es聚合中使用cardinality进行去重聚合操作,类似于Hyperloglog,这样的去重结果并不准确,但是可以保证极小的内存消耗的极高的响应效率
命令格式
GET cars_order/_search{"aggs": {"color_count": {"cardinality": {"field": "color","precision_threshold": 100}}}}
field:聚合字段
- precision_threshold:配置精度,定义了在何种基数水平下希望得到一个近乎精确的结果。precision_threshold 接受 0–40,000 之间的数字,更大的值还是被当作 40,000 来处理。
示例
获取总共卖出来多少厂商的订单GET cars_order/_search{"aggs": {"make_count": {"cardinality": {"field": "make","precision_threshold": 100}}}}
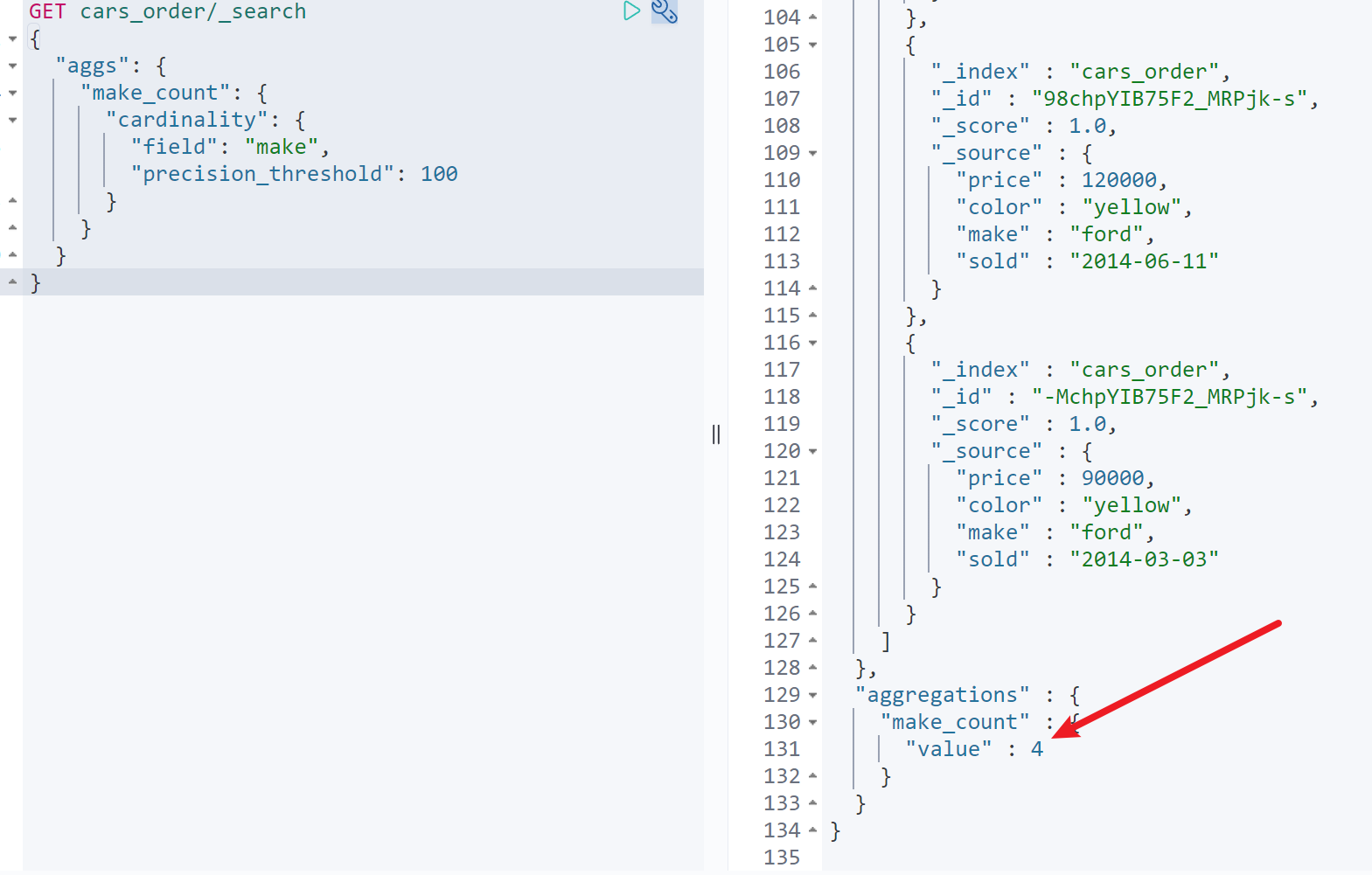
如图,共卖出4个厂商的汽车优化去重速度
速度优化:链接percentiles (计算百分数统计)
什么是百分比数
想要了解percentiles ,必须要了解什么是百分比数。举个例子,我们统计了最近一年内游戏用户的付费总额,列表如下:
| 百分比 | 付费总额 |
|---|---|
| 1 | 100000元 |
| 15 | 80000元 |
| 25 | 70000元 |
| 50 | 30000元 |
| 65 | 10000元 |
| 75 | 8000元 |
| 90 | 4000元 |
| 100 | 1000元 |
通过上述表格,可以看出
- 百分之1的用户,付费达到了100000元
- 百分之15的用户,付费达到了80000元
- 百分之25的用户,付费达到了70000元
- ……依次类推
通过上述信息可以明确得知用户的付费分布。同理反过来,也可以明确知道,有百分之15的用户付费率达到了80000。
上述的数据就是一批百分数,通过百分数可以进行相关指标的分布率分析,以及找出异常指标。下面开始详细讲解相关内容
命令格式
GET website/_search{"aggs": {"latency_percentiles": {"percentiles": {"field": "latency","percents": [1,5,25,50,75,95,99]}}}}
- field:聚合字段
percents:百分比分布,可以自行指定,常用的参考上面的例子即可
示例
统计不同区域网站请求的平均值,通过百分数进行异常值分析,查看哪个区域网络延迟较高
GET website/_search{"aggs": {"zone_latency": {"terms": {"field": "zone"},"aggs": {"avg_latency": {"avg": {"field": "latency"}},"latency_percentiles": {"percentiles": {"field": "latency","percents": [5,25,50,75,95]}}}}}}
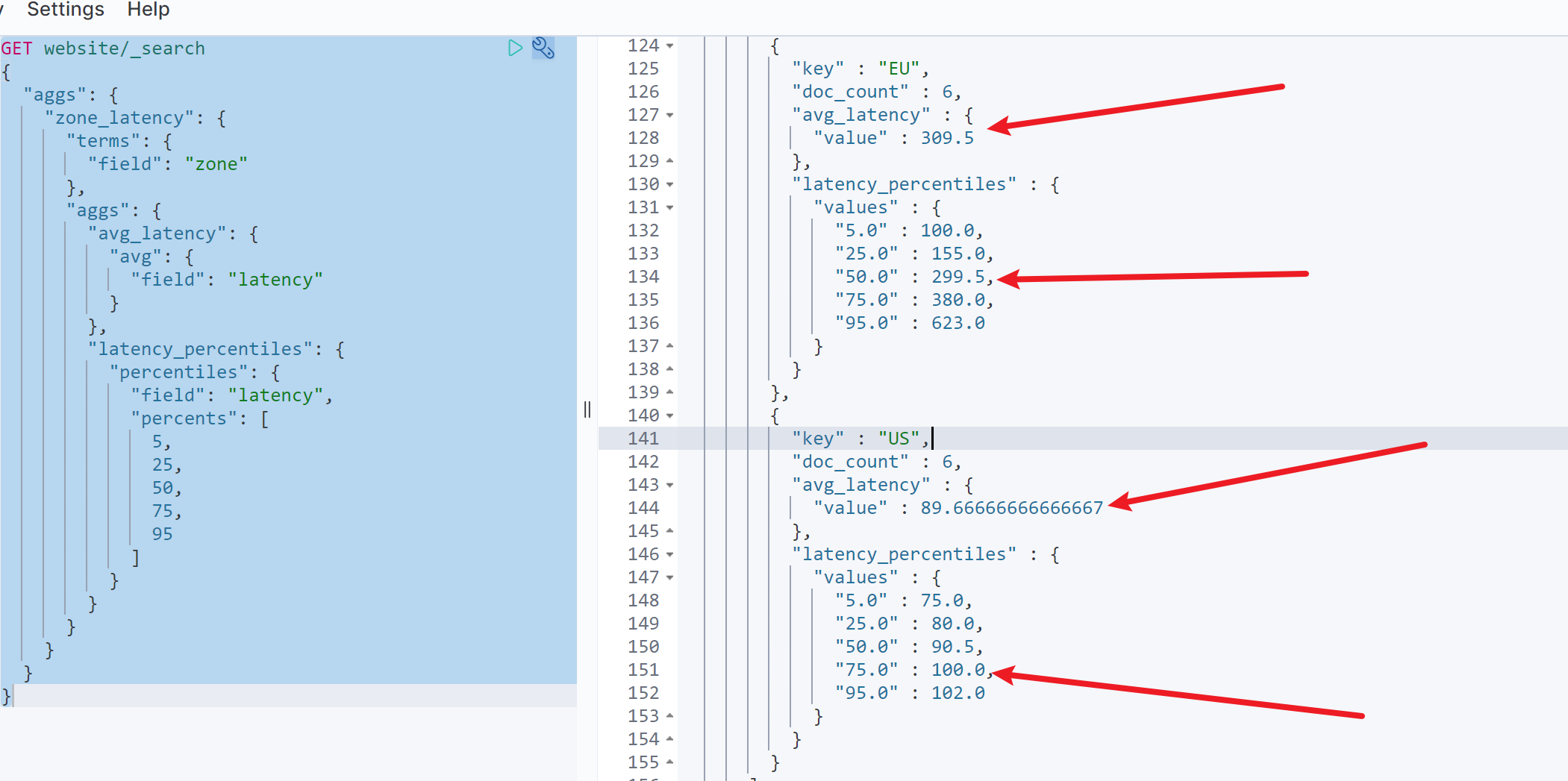
如图,可以的值以下信息欧洲地区平均网络延迟:309.5ms
- 美国地区平均网络延迟:89.67ms
- 欧洲地区大约百分之50的用户达到了平均水准
- 美国地区大约百分之75的用户达到了平均水准
因此可以得知欧洲地区的网络延迟较高,是影响网站慢查询比率高的主要原因
percentile_ranks(反向计算百分数统计)
除了可以获取不同百分比数对应的值,也可以通过值获取其对应的百分比区间。具体就是使用percentile_ranks来操作
命令格式
GET website/_search{"aggs": {"load": {"percentile_ranks": {"field": "latency","values": [100,400,800]}}}}
- field:统计字段
-
示例
获取美国地区,网络延迟达到30、80、 100的用户百分比
GET website/_search{"aggs": {"load": {"aggs": {"US_load": {"terms": {"field": "zone"},"aggs": {"US_load_percentile_ranks": {"percentile_ranks": {"field": "latency","values": [30,80,100]}}}}},"filter": {"term": {"zone": "US"}}}}}
如图,可以看到美国地区
网络延迟达到30ms的用户约为0%
- 网络延迟达到80ms的用户约为29%
- 网络延迟达到100ms的用户约为72%
10.原理
前言
众所周知,es是基于lucene,而lucene对于非结构化数据全文检索的实现是基于倒排索引。对于数据的查询,倒排索引的支持已经非常足够。但是,思考一下,对于聚合操作,倒排索引的支持真的够了吗?
假设当前需要根据年龄字段总和,如果使用倒排索引,我们需要通过正向文件获取全部文档信息,然后获取其年龄字段,进行聚合,之后在返回。很明显,对于专注于查询的es来说,这样做带来的效率影响是不可接受的。
因此es中使用了doc value来实现聚合以及排序等相关操作
Doc value
什么是Doc value
dov value可以简单的将其理解为一个key value形式的键值对,键为文档ID,值为文档对应字段的值。一个segment中这样的键值对组合在一起,就形成了这个字段的doc value
如图,一个segment中包含4个文档,上图为文档age字段的doc value。当然es中会进行相对应的数据压缩等操作。上图只提供一个形象的描述
有了doc value,只需遍历age字段的doc value,获取其值进行求和操作即可
Doc value存储在哪里?
- 当 working set 远小于系统的可用内存,系统会自动将 Doc Values 驻留在内存中,使得其读写十分快速。
- 不过,当其远大于可用内存时,系统会根据需要从磁盘读取 Doc Values,然后选择性放到分页缓存中。很显然,这样性能会比在内存中差很多,但是它的大小就不再局限于服务器的内存了。如果是使用 JVM 的 Heap 来实现那么只能是因为 OutOfMemory 导致程序崩溃了。
Doc value对所有字段都有效吗?
Doc Values 默认对所有字段启用,除了text类型(分词字段)。也就是说所有的数字、地理坐标、日期、IP 和不分析( not_analyzed )字符类型都会默认开启。
Doc values 不支持 analyzed 字符串字段,因为它们不能很有效的表示多值字符串。
Doc values 最有效的场景就是,每个文档对应字段只有一个或几个词条时, 而不是无数个词条,分析字符串(想象一个 PDF ,可能有几兆字节并有数以千计的独特词条)。
出于这个原因,doc values 不生成分析的字符串。可以设置text字段属性fielddata=true开启其聚合功能。11.总结
es中从匹配字段值,范围,日期范围等多个角度提供了数据聚合的功能。同时通过近似精确值去重和百分比计算来实现数据的近似精确统计
但是es关注的并不仅仅是单纯的聚合功能,在实现聚合时,我们还要考虑聚合的性能、聚合对于内存的消耗等因素。
建议在进行es聚合相关功能落地时,要从服务器,硬件,内存,jvm虚拟机,聚合语法等多个角度来考虑。es不仅仅是一个数据搜索引擎,而是一个功能强大的数据分析引擎!!!

若有收获,就点个赞吧
0 人点赞
