91.介绍一下目前的项目数据处理流程
2.kafka 和 spark streaming offset处理方法,如何保证数据精确一次
3.kafka分区消息有序,生产端一条消息失败时,怎么处理的。以及kafka反压
4.spark streaming的怎么做启停,怎么查看日志
5.hdfs 块异常处理,写文件同步的处理
6.es 数据写入流程
7.hive数据倾斜解决办法
8.etl过程怎么处理
9.Java堆栈
10.spark submit 主要参数
2.kafka 和 spark streaming offset处理方法
Checkpoints
偏移量将存储在检查点中。这很容易实现,但是有缺点。如果您的应用程序代码已更改,则无法从检查点恢复。
kafka
Kafka具有偏移量提交API,该API在特殊的Kafka主题中存储偏移量。默认情况下,新消费者将定期自动提交偏移量。这几乎肯定不是您想要的,因为由消费者成功轮询的消息可能尚未导致Spark输出操作,从而导致语义未定义。这就是为什么上面的流示例将“ enable.auto.commit”设置为false的原因。但是,您可以使用commitAsync API 在知道输出已存储之后向Kafka提交偏移量。与检查点相比,其好处是,无论您对应用程序代码进行的更改如何,Kafka都是持久存储。但是,Kafka不是事务性的,因此您的输出必须仍然是幂等的。
stream.foreachRDD { rdd =>val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges// some time later, after outputs have completedstream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)}
与HasOffsetRanges一样,仅当在createDirectStream的结果上调用时,对CanCommitOffsets的强制转换才能成功,而不是在转换后进行。commitAsync调用是线程安全的,但如果需要有意义的语义,则必须在输出之后进行。
自己的数据存储
对于支持事务的数据存储,即使在失败情况下,将偏移与结果保存在同一事务中也可以使两者保持同步。如果您在检测重复或跳过的偏移量范围时很谨慎,则回滚事务可防止重复或丢失的消息影响结果。这相当于一次语义。即使是由于聚合而产生的输出(通常很难使等幂),也可以使用此策略。
// The details depend on your data store, but the general idea looks like this// begin from the offsets committed to the databaseval fromOffsets = selectOffsetsFromYourDatabase.map { resultSet =>new TopicPartition(resultSet.string("topic"), resultSet.int("partition")) -> resultSet.long("offset")}.toMapval stream = KafkaUtils.createDirectStream[String, String](streamingContext,PreferConsistent,Assign[String, String](fromOffsets.keys.toList, kafkaParams, fromOffsets))stream.foreachRDD { rdd =>val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRangesval results = yourCalculation(rdd)// begin your transaction// update results// update offsets where the end of existing offsets matches the beginning of this batch of offsets// assert that offsets were updated correctly// end your transaction}
kafka分区消息有序,生产端一条消息失败时,怎么处理的。以及kafka反压
kafka分区消息有序,生产端一条消息失败时,怎么处理的
消息回调,同步处理,重新发送
kafka 反压
开启反压的缘由:
一个批次的数据应该在一个批次内处理完,即batch process time应该接近于batch Duration,如果batch处理时间总是比batch间隔时间长,就会不断增加调度延迟时间而且数据也会在内存里堆积,进而增加系统不稳定性;另一方面,如果batch处理时间总是远远小于batch间隔时间,则集群资源利用率不高,也是一种资源浪费。
启用反压也比较简单:sparkConf.set("spark.streaming.backpressure.enabled", "true")。spark会在作业执行结束后,调用RateController.onBatchCompleted更新batch的元数据信息:batch处理结束时间、batch处理时间、调度延迟时间、batch接收到的消息量等.
override def onBatchCompleted(batchCompleted: StreamingListenerBatchCompleted){val elements = batchCompleted.batchInfo.streamIdToInputInfofor{processingEnd<- batchCompleted.batchInfo.processingEndTimeworkDelay <- batchCompleted.batchInfo.processingDelaywaitDelay <- batchCompleted.batchInfo.schedulingDelayelems <- elements.get(streamUID).map(_.numRecords)} computeAndPublish(processingEnd, elems, workDelay, waitDelay)}
然后基于上述参数,使用PID估计算法预估速率,具体实现是PIDRateEstimator的compute方法。
spark streaming的怎么做启停,怎么查看日志
启动:一般由shell 提交
停止:
- 设置spark参数 spark.streaming.stopGracefullyOnShutdown = ture 使用 StopGraceFully 所有接收的数据都会被处理完成,才会停止。
使用Spark UI找出驱动程序在哪个节点上运行。在yarn cluster deploy 模式下,驱动程序和AM在同一容器中运行。
登录该节点,然后执行 ps -ef | grep java | grep ApplicationMaster 并找出该pid。请注意,根据您的应用程序/环境等,您的grep字符串可能会有所不同。
kill -SIGTERM to send SIGTERM to the process.
默认情况下, spark.yarn.maxAppAttempts 参数使用 YARN中yarn.resourcemanager.am.max-attempts中的默认值 。默认值为2。因此,在第一个AM被您的kill命令停止后,YARN将自动启动另一个AM /驱动程序。您必须再次杀死第二个。您可以 在spark-submit期间设置 —conf spark.yarn.maxAppAttempts = 1,但是您必须问自己是否真的想让驱动程序没有失败的机会。
程序出现异常后打一个标记,标记存放在可靠的外部系统如hdfs、redis等。
hdfs debug recoverLease -path /blockrecover/ruozedata.md -retries 10
这样做是基于这样的思考:1个block有对应的三个副本,其中一个副本损坏了,但是有另外两个副本存在,是可以利用另外两个副本进行修复的,因此我们可以使用debug命令进行修复
在HDFS中实际上也可以配置块的自动修复的
当数据块损坏后,DataNode节点在执行directoryscan操作之前,都不会发现损坏
directoryscan操作是间隔6h进行的dfs.datanode.directoryscan.interval : 21600
在DataNode向NameNode进行blockreport之前,都不会恢复数据块;
blockreport操作是间隔6h进行的dfs.blockreport.intervalMsec : 21600000
当NameNode收到blockreport才会进行恢复操作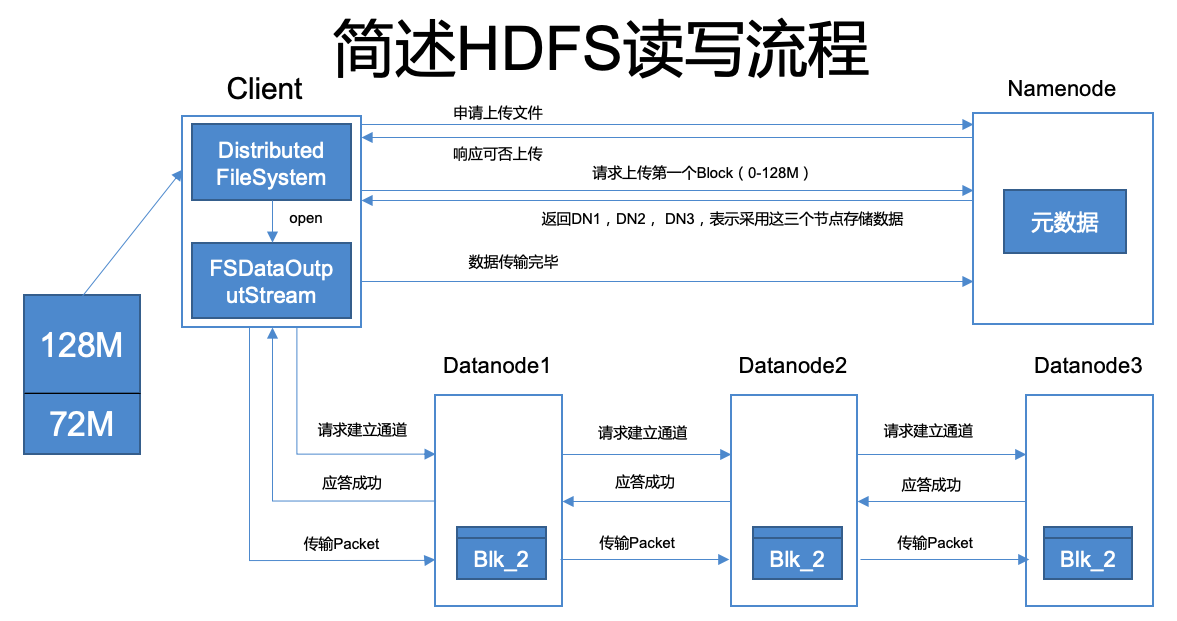
```scala package com.smothclose
import org.apache.log4j.{Level, Logger} import org.apache.spark.SparkConf import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext}`
object SparkTest {
def createSSC(): root.org.apache.spark.streaming.StreamingContext = { val update: (Seq[Int], Option[Int]) => Some[Int] = (values: Seq[Int], status: Option[Int]) => { //当前批次内容的计算 val sum: Int = values.sum
//取出状态信息中上一次状态val lastStatu: Int = status.getOrElse(0)Some(sum + lastStatu)}val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("SparkTest")// 如果为true,Spark会StreamingContext在JVM关闭时正常关闭,而不是立即关闭。sparkConf.set("spark.streaming.stopGracefullyOnShutdown", "true")val ssc = new StreamingContext(sparkConf, Seconds(5))ssc.checkpoint("./ck1111")val line: ReceiverInputDStream[String] = ssc.socketTextStream("node01", 9999)val word: DStream[String] = line.flatMap(_.split(" "))val wordAndOne: DStream[(String, Int)] = word.map((_, 1))val wordAndCount: DStream[(String, Int)] = wordAndOne.updateStateByKey(update)wordAndCount.print()ssc
}
def main(args: Array[String]): Unit = { val ssc: StreamingContext = StreamingContext.getActiveOrCreate(“./ck”, () => createSSC())
new Thread(new MonitorStop(ssc)).start()ssc.start()ssc.awaitTermination()
hdfs 块异常处理,写文件同步的处理
块异常处理
debug方式优雅处理
配置参数自动修复
写文件同步
[Spark RDD的弹性到底指什么]

若有收获,就点个赞吧
0 人点赞
