广播变量
广播变量类似于 MapReduce 中的 DistributeFile,通常来说是一份不大的数据集,一旦广播变量在 Driver 中被创建,整个数据集就会在集群中进行广播,能让所有正在运行的计算任务以只读方式访问。广播变量支持一些简单的数据类型,如整型、集合类型等,也支持很多复杂数据类型,如一些自定义的数据类型。
广播变量为了保证数据被广播到所有节点,使用了很多办法。这其实是一个很重要的问题,我们不能期望 100 个或者 1000 个 Executor 去连接 Driver,并拉取数据,这会让 Driver 不堪重负。Executor 采用的是通过 HTTP 连接去拉取数据,类似于 BitTorrent 点对点传输。这样的方式更具扩展性,避免了所有 Executor 都去向 Driver 请求数据而造成 Driver 故障。
Spark 广播机制运作方式是这样的:Driver 将已序列化的数据切分成小块,然后将其存储在自己的块管理器 BlockManager 中,当 Executor 开始运行时,每个 Executor 首先从自己的内部块管理器中试图获取广播变量,如果以前广播过,那么直接使用;如果没有,Executor 就会从 Driver 或者其他可用的 Executor 去拉取数据块。一旦拿到数据块,就会放到自己的块管理器中。供自己和其他需要拉取的 Executor 使用。这就很好地防止了 Driver 单点的性能瓶颈,如下图所示。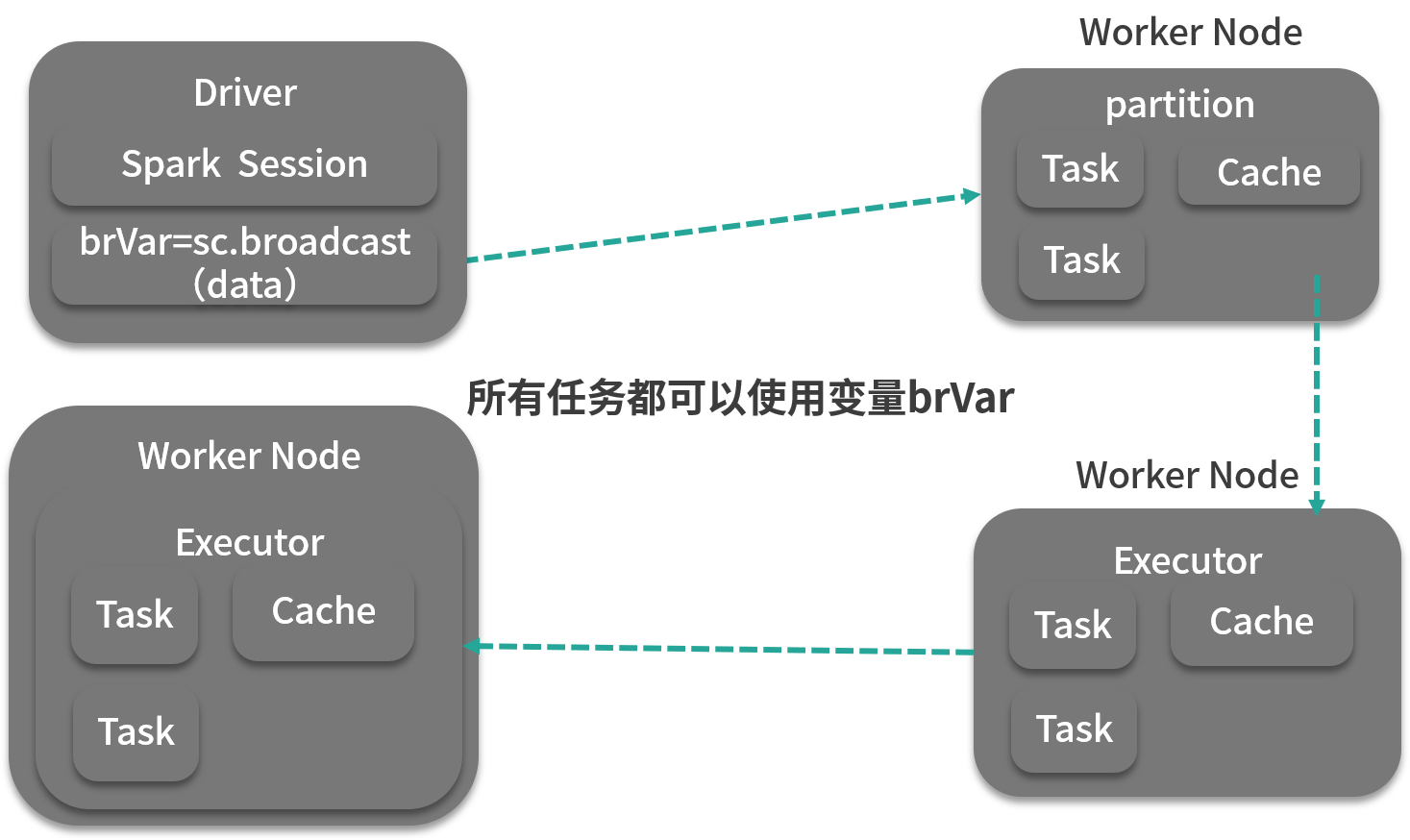
广播变量会持续占用内存,当我们不需要的时候,可以用 unpersist 算子将其移除,这时,如果计算任务又用到广播变量,那么就会重新拉取数据。
scala> val rdd_one = sc.parallelize(Seq(1,2,3))rdd_one: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[101] atparallelize at
你还可以使用 destroy 方法彻底销毁广播变量,调用该方法后,如果计算任务中又用到广播变量,则会抛出异常:
17/05/27 14:07:28 ERROR Utils: Exception encounteredorg.apache.spark.SparkException: Attempted to use Broadcast(163) after itwas destroyed (destroy at
广播变量在一定数据量范围内可以有效地使作业避免 Shuffle,使计算尽可能本地运行,Spark 的 Map 端连接操作就是用广播变量实现的。

若有收获,就点个赞吧
0 人点赞
