消息送达保证
数据(消息)在计算节点随着处理过程在不停流动,计算节点从它的上游收到数据,经过处理又发向下游计算节点,在这个过程中,如何保证当前节点一定能收到上游计算节点发送的处理结果是一个非常重要的问题,因为它直接影响了流处理结果的正确性。我们也称其为消息送达保证(delivery guarantee)问题,对于消息送达保证,业界一般有以下 3 种语义。
- 至少送达一次(at least once),下游节点一定会收到一次上游节点发过来的消息,但也可能会接收到重复的消息。
- 至多送达一次(at most once),下游节点不一定会收到上游节点发来的消息。这意味着,有可能上游节点发送的消息,下游节点丢失了,但上游节点不会重发。
- 恰好送达一次(exact once),下游节点一定会且只会收到一次上游节点发来的消息。这当然是所有用户最希望的,但对于某些用户来说可能不是必需的。
对于这 3 种解决方案,当然流处理技术应该以恰好送达一次为目标进行设计,因为如果没有这种消息送达保证,那么对于支付场景、计算广告场景(点击计费)等来说就无法保证结果的正确性,这对于业务方来说是不可接受的。但也有很多时候,业务场景可能只需要至少送达一次的保证,那么这个时候就需要进行取舍。
在谈论消息送达保证这个话题时,其实不能孤立地看待它,我们可以将其看成两个问题:即发送消息的可靠性保障和消费消息的可靠性保障。前者指的其实是可靠发送,而后者指的是可靠接收并处理。想要达到“恰好送达一次”的效果,需要这两者同时满足。很多系统声称自己提供“恰好一次”的解决方案,但当我们仔细研究其原理时,会发现并不准确,因为它们没有解释消费者(下游计算节点,消息接收者)或者生产者(上游计算节点,消息发送者)在发送或接收失败时,还如何能保证消息“恰好一次”地传递。
Kafka 的数据流如下图所示: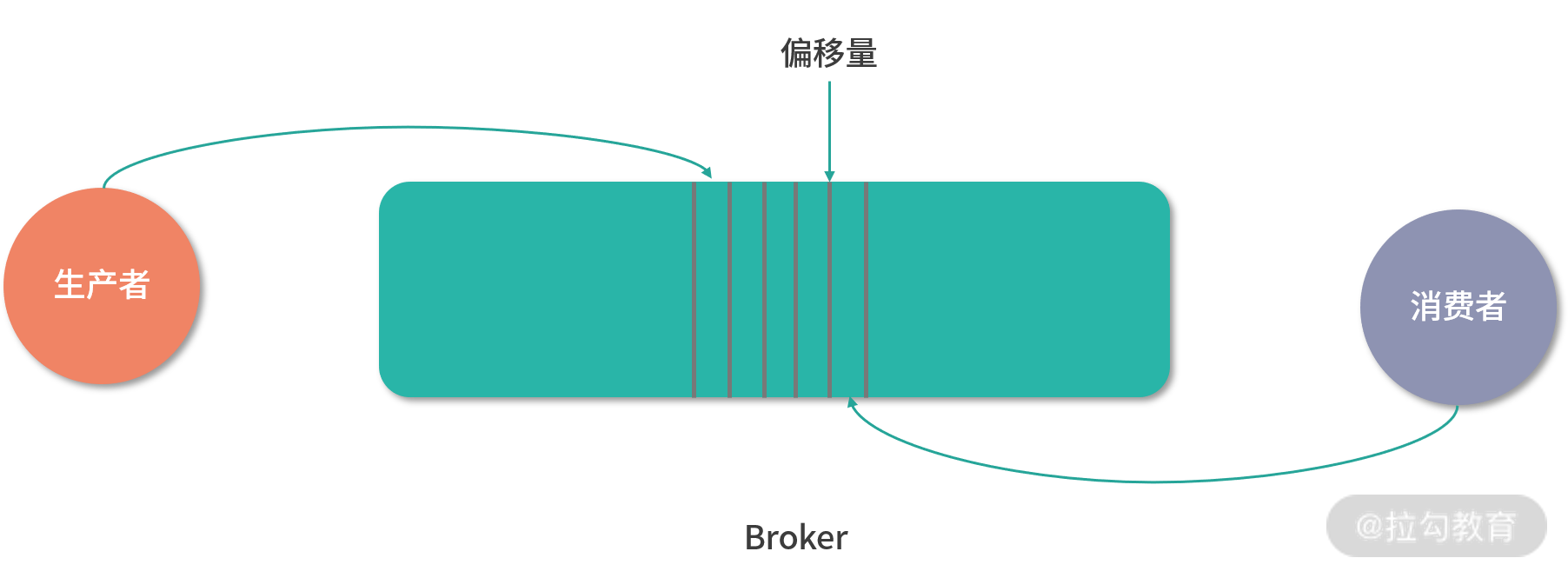
如前所述,我们将其分为两个阶段:生产者生产消息,消费者消费消息。只有这两个阶段都满足了“恰好一次”的语义,整个过程才能满足“恰好一次”的语义。我们先从生产者的角度来看,目前的 Kafka 采用异步方式发送消息,当消息被提交后,Kafka 会异步将其发送给 Broker,发送成功后会回调发送 ACK,如果没有则重试,直到收到 ACK 为止,消息会有一个主键,在Broker 端会做幂等处理,不会导致数据出现重复,这样就算在提交过程中,出现了网络故障,导致消息不能及时发送,最终还是能保证发送消息“恰好一次”的语义效果。我们现在再从消费者的角度来看,所有副本都保存有相同的日志以及偏移量(offset),假设由消费者控制偏移量在日志中的位置。当消费者读取了几条数据时,有下面两种情况:
- 读取消息,然后在日志中保存偏移量位置,最后处理消息。但有可能消费者保存了偏移量位置之后,在处理消息输出之前崩溃了。在这种情况下,接管处理的进程会在已保存的位置开始,即使该位置之前有几个消息尚未处理。这就达到了“至多一次”的效果,在消费者处理失败消息的情况下,不进行处理。
- 读取消息,处理消息,最后保存消息的位置。在这种情况下,可能消费进程处理消息之后,在保存偏移位置之前崩溃了。当新的进程重新接管时,将接收已经被处理的前几个消息。这就达到了“至少一次”的效果。
如果想实现“恰好一次”的语义,那么需要做的其实是将输出处理消费数据的结果和修改偏移量这两个操作放在一个事务里,就可以保证“恰好一次”语义,最完美的解决方案是采取经典的两段式提交,但很多消费者不支持两段式提交,并且两段式提交会影响性能表现。有一个变通的办法就是将消费者的输出与消费者的偏移量存储在一个地方,这就避免了分布式事务,当然这会引起一些不必要的麻烦,更常见的会使用幂等输出,来实现“恰好一次”的效果。
关键抽象与架构
Spark Streaming 的关键抽象 DStream,DStream 意指 Discretized Stream(离散化流),它大体上来说是一个 RDD 流(序列),其元素(RDD)可以理解为从输入流生成的批。在流处理的过程中,用户其实就是在对 DStream 进行各种变换,最后再输出。如下图所示,可以看出 Spark Streaming 的输入是连续的,经过 Spark Streaming 接收后,会变成一个 RDD 序列,之后的处理逻辑是基于 DStream 来操作的。
DStream 的生成依据是按照时间间隔切分,该时间间隔的数据会生成一个微批(mini-batch),即一个 RDD,所以该间隔也被称为批次间隔,DStream 里面持有对所有产生的 RDD 的引用,虽然 RDD 和 DStream 非常像,在种类上基本都是一一对应的,如 UnionDStream 与 UnionRDD,但是 DStream 还是和 RDD 有本质不同,如下图所示:
RDD 是 DStream 中某个批次的数据,而 DStream 代表了一段时间所产生的 RDD。所以通过这种方式,Spark Streaming 把对连续流的处理,变成了对批序列 DStream 的处理。我们会在 StreamingContext 设置批次间隔大小,一般大于 200ms。最准确的说法是某段时间内的 RDD。
最后,可以看到 Spark Streaming 对流的抽象本质上还是流,只是处理是基于批来处理的。这与 Structured Streaming 来说是不同的,我们在后面会讲到。
Spark Streaming 在架构上与 Spark 离线计算架构非常相似,主要分为 Driver 与 Executor,同样可以运行在 Yarn、Mesos 上,也能够以 standalone 和 local 模式运行。它们之间的关系仍旧是 Driver 负责调度,Executor 执行任务。如下图所示。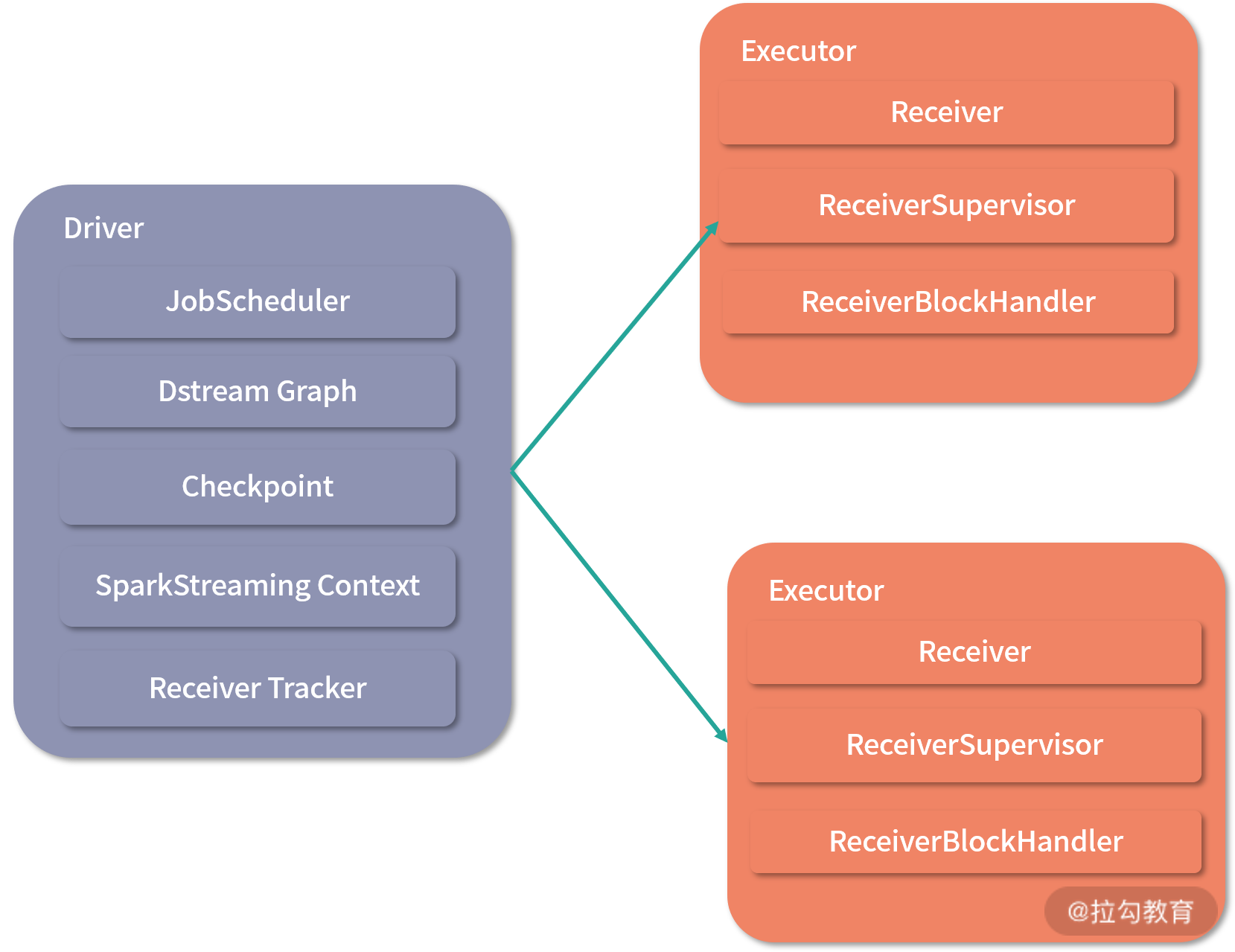
Driver
在 Driver 中,有几个关键模块,SparkStreamingContext 、DStreamGraph、JobScheduler、Checkpoint、ReceiverTracker
- SparkStreamingContext:SparkStreamingContext是一开始在用户代码中初始化完成的。它主要的工作是对作业进行一些配置,例如 DStream 切分的批次间隔(Duration),以及与其他模块进行交互,如 DStreamGraph 和 JobScheduler 等。
- DStreamGraph:既然 Spark Streaming 最后还是对批的处理,那么批处理中根据计算逻辑生成的 RDD DAG 也是存在的,它由 DStreamGraph 生成。DStreamGraph 维护了输入 DStream 与输出 DStream 的实例,还会通过 generateJobs 方法生成一个作业集合(RDD DAG),它会由 JobScheduler 调度启动执行任务。
- JobScheduler:JobScheduler 顾名思义是 Spark Streaming 的作业调度器,在创建 SparkStreamingContext 的同时,JobScheduler 也会作为它的一部分被创建,所有的任务都是最后由它调度 Executor 来执行。
- Checkpoint:在 Spark 中,任何一个 RDD 丢失,都可以通过依赖关系重新计算得到, Checkpoint 是 Spark Streaming 容错机制的核心,会定时对已算好的中间结果以及其他中间状态进行存储,避免了依赖链过长的问题。这样就算某个 DStream 丢失了,也不用从头开始计算,只需从最近的依赖关系开始计算即可。
- ReceiverTracker:ReceiverTracker 通过 Executor 上的 ReceiverSupvisor 来管理所有的 Receiver。主要功能是把需要计算的数据发送给 Executor。当 Executor 接收完毕后,也会将数据块的元数据上报给 ReceiverTracker。
SparkStreamingContext 负责与其他组件交互,DStreamGraph 与 JobScheduler 负责调度,Checkpoint 负责容错,ReceiverTracker 负责与 Executor 进行数据交互。
Executor
Executor 是具体的任务执行者,其中重要的组件有 Receiver、ReceiverSupvisor、ReceiveredBlockHandler
ReceiverTracker 会和 Executor 通信,启动 ReceiverSupvisor 实例,ReceiverSupvisor 会马上启动 Receiver 开始接收数据。Receiver 接收到数据后,用 ReceiverdBlockHandler 以块的方式写到 Executor 的磁盘或者内存,对应的实现是 BlockManagerBasedBlockHandler 和 WriteAheadLogBasedBlockHandler,前者是根据 Executor 的 StorageLevel 写到相应的存储层,后者会先进行预写日志(Write Ahead Log),其中,后者能对流式数据源提供更好的容错性。数据接收完毕后,会根据调度开始计算任务。
Spark Streaming 的作业初始化与提交和 Spark SQL 作业有些不同,我们还是通过初始化 SparkSession 的方式得到 StreamingContext 的引用,再对其设置一个关键参数:批次间隔后,就可以进行数据接收和数据处理的动作。
无状态的转换算子
基于上面的抽象,对流进行处理与批处理就没什么不同了,我们只着眼于此刻正在处理的这个时间范围内的 RDD,所以数据处理方式与批处理并没有什么不同,算子也与批处理没多大区别,算子作用与数据流中的每个 RDD,这类算子我们称之为无状态算子,如下图所示: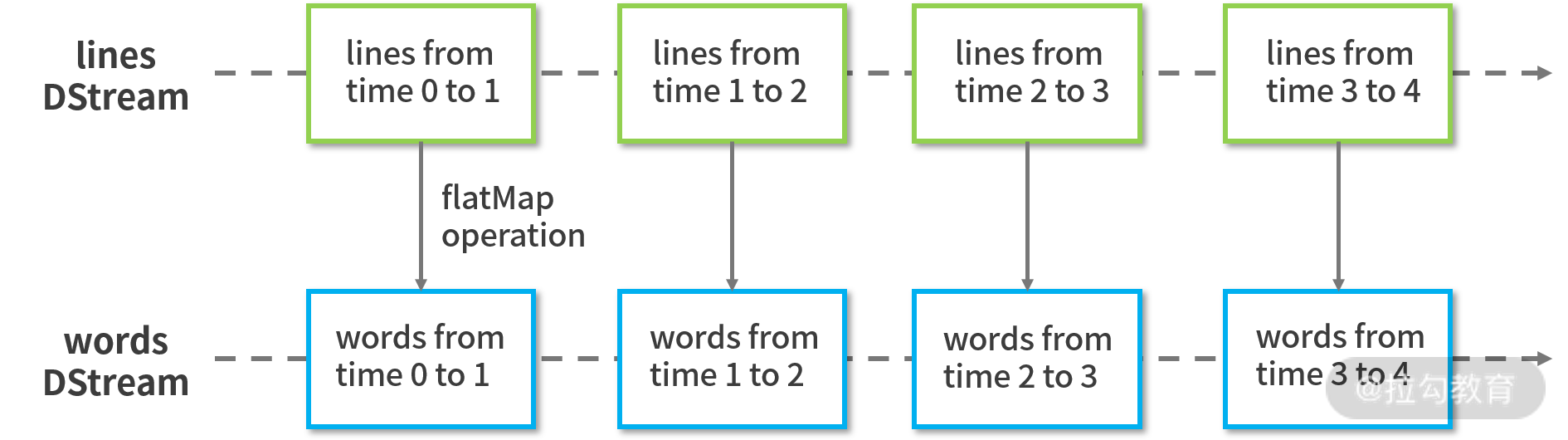
转换算子如 map、mapPartitions、reduceByKey、reduce、flatmap、glom、filter、repartition、union
有状态的转换算子
在实际工作场景中,默认的时间间隔很难满足流处理的业务需要,比如想对 DStream 中的某几个 RDD 进行操作,或者是想保存一些中间结果做增量计算,就需要运用到另一类转换算子:有状态的转换算子。
有状态的转换算子主要分为两种,一种是基于时间窗口,另一种是基于整个时间跨度。
基于时间窗口
基于时间窗口的概念其实早就深植于 Spark Streaming 中,我们在设置批次间隔时间(如 1 s)时,本质上就是设置了一个时间窗口,在用户代码中的计算逻辑其实是作用在每一个在该批次间隔中形成的 RDD 上,上一个 RDD 和这一个 RDD 的计算结果不会互相影响。当我们需要对若干批次的数据处理结果进行聚合的时候,就需要设置一个更大的时间窗口,如下图所示: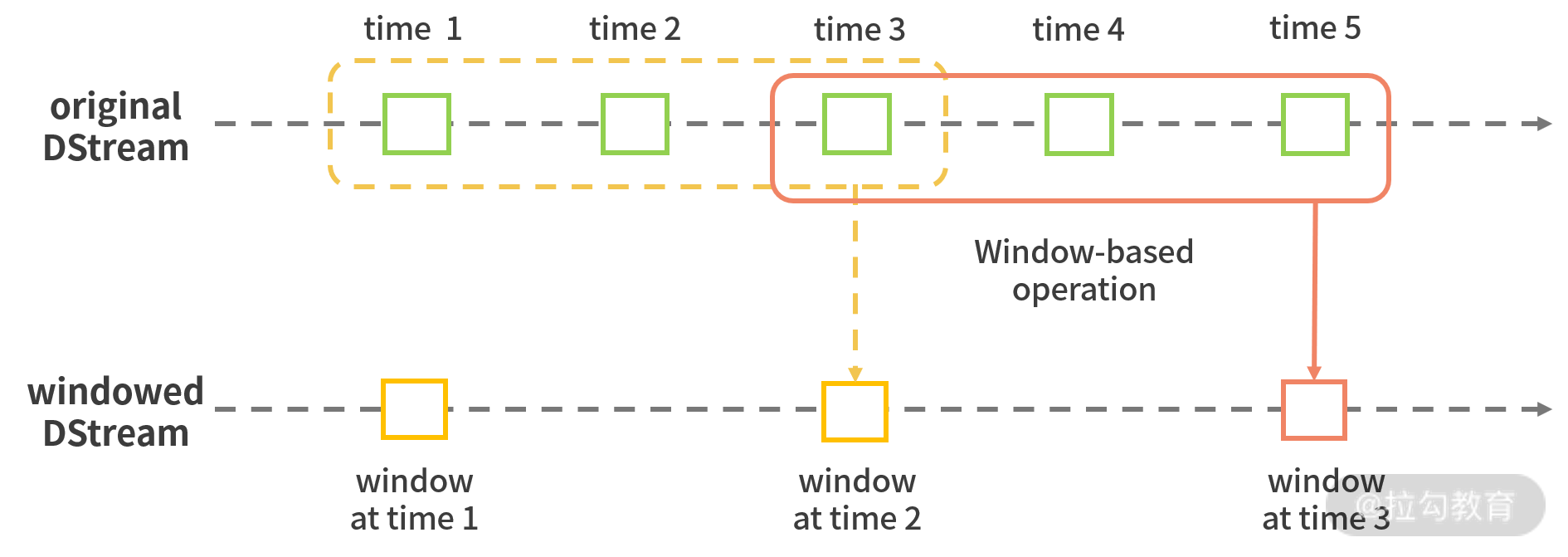
时间窗口是由批次间隔组成的有限时间跨度,基于窗口的操作对窗口中所有数据进行处理。此外,窗口是一个逻辑的概念,它可以进行滑动,图中所示的窗口跨度为 3,滑动步长为 2,滑动意味着每隔多少时间,窗口会被触发一次,每批次数据与窗口的对应关系为一对多,意味着某个批次的数据可以存在于多个窗口中。这里注意窗口间隔与滑动步长都必须是 DStream 批次间隔的整数倍。
基于窗口的转换算子
slice
def slice(interval: Interval): Seq[RDD[T]]
def slice(fromTime: Time, toTime: Time): Seq[RDD[T]]
slice 算子返回该时间跨度内的 RDD 集合,批次间隔可以用 Interval 进行定义,也可以用起始时间与结束时间来定义,注意,开始时间与结束时间需要是批次间隔的倍数,否则系统会自动进行取整。该算子相当于在整个 DStream 流中截取了一段。
window
window(windowDuration: Duration): DStream[T]
window(windowDuration: Duration, slideDuration: Duration): DStream[T]
window 算子定义了窗口的属性,如跨度(windowDuration)和滑动步长(slideDuration),并返回一个新的 DStream,默认的滑动步长为批次间隔。当我们通过 window 算子定义了滑动窗口以后,可以用使用 join 算子进行连接操作( join 要求两个窗口的滑动步长必须一致),例:
import org.apache.spark.streaming.StreamingContextimport org.apache.spark.streaming.Secondsimport org.apache.spark.streaming.dstream.ConstantInputDStreamimport org.apache.spark.sql.SparkSessionimport org.apache.spark.streaming.dstream.DStream.toPairDStreamFunctionsobject SparkStreamingJoin {def main(args: Array[String]): Unit = {val spark = SparkSession.builder.master("local[2]").appName("SparkStreamingJoin").getOrCreate()val sc = spark.sparkContextval ssc = new StreamingContext(sc, batchDuration = Seconds(2))val leftData = sc.parallelize(0 to 3)val leftStream = new ConstantInputDStream(ssc, leftData)val rightData = sc.parallelize(0 to 2)val rightStream = new ConstantInputDStream(ssc, rightData)// 连接的DStream窗口需要有相同的Duration或者其中一个DStream的Duration是另一个的整数倍val rightWindow = rightStream.map(f => (f,f)).window(Seconds(2),Seconds(4))val leftWindow = leftStream.map(f => (f,f)).window(Seconds(6),Seconds(4))leftWindow.join(rightWindow).print()ssc.start()ssc.awaitTermination()}}
window 算子很重要的用法是与无状态算子配合使用,使其结果满足需要的时间跨度限制。
reduceByWindow
def reduceByWindow(reduceFunc: (T, T) => T,windowDuration: Duration,slideDuration: Duration): DStream[T]
def reduceByWindow(reduceFunc: (T, T) => T,invReduceFunc: (T, T) => T,windowDuration: Duration,slideDuration: Duration): DStream[T]
按照 reduceFunc 的逻辑对滑动窗口中的数据进行聚合。后一个 reduceByWindow 是前一个的重载版本,不同之处在于增加了反函数(invReduceFunc)作为参数。反函数存在的作用在于优化那些增量计算的逻辑
检查点
流应用程序必须24/7全天候运行,因此必须对与应用程序逻辑无关的故障(例如,系统故障,JVM崩溃等)具有弹性。为此,Spark Streaming需要将足够的信息检查点指向容错存储系统,以便可以从故障中恢复。检查点有两种类型的数据。
- 元数据检查点 -将定义流计算的信息保存到HDFS等容错存储中。这用于从运行流应用程序的驱动程序的节点的故障中恢复(稍后详细讨论)。元数据包括:
- 配置 -用于创建流应用程序的配置。
- DStream操作 -定义流应用程序的DStream操作集。
- 不完整的批次 -作业排队但尚未完成的批次。
- 数据检查点 -将生成的RDD保存到可靠的存储中。在一些有状态转换中,这需要合并多个批次中的数据,这是必需的。在此类转换中,生成的RDD依赖于先前批次的RDD,这导致依赖项链的长度随时间不断增加。为了避免恢复时间的这种无限制的增加(与依存关系链成比例),有状态转换的中间RDD定期 检查点到可靠的存储(例如HDFS)以切断依存关系链。
总而言之,从驱动程序故障中恢复时,主要需要元数据检查点,而如果使用有状态转换,则即使是基本功能,也需要数据或RDD检查点。
何时启用检查点
必须为具有以下任一要求的应用程序启用检查点:
- 有状态转换的用法 -如果在应用程序中使用updateStateByKey或reduceByKeyAndWindow(带有反函数),则必须提供检查点目录以允许定期进行RDD检查点。
- 从运行应用程序的驱动程序故障中恢复 -元数据检查点用于恢复进度信息。
注意,没有前述状态转换的简单流应用程序可以在不启用检查点的情况下运行。在这种情况下,从驱动程序故障中恢复也将是部分的(某些丢失但未处理的数据可能会丢失)。这通常是可以接受的,并且许多都以这种方式运行Spark Streaming应用程序。预计将来会改善对非Hadoop环境的支持。
如何配置检查点
可以通过在容错,可靠的文件系统(例如HDFS,S3等)中设置目录来启用检查点,将检查点信息保存到该目录中。这是通过使用完成的streamingContext.checkpoint(checkpointDirectory)。这将允许您使用上述有状态转换。此外,如果要使应用程序从驱动程序故障中恢复,则应重写流应用程序以具有以下行为。
- 程序首次启动时,它将创建一个新的StreamingContext,设置所有流,然后调用start()。
- 失败后重新启动程序时,它将根据检查点目录中的检查点数据重新创建StreamingContext。 ``` // Function to create and setup a new StreamingContext def functionToCreateContext(): StreamingContext = { val ssc = new StreamingContext(…) // new context val lines = ssc.socketTextStream(…) // create DStreams … //process DStream in here ssc.checkpoint(checkpointDirectory) // set checkpoint directory ssc }
// Get StreamingContext from checkpoint data or create a new one val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)
// Do additional setup on context that needs to be done, // irrespective of whether it is being started or restarted context. …
// Start the context
context.start()
context.awaitTermination()
```
如果checkpointDirectory存在,则将根据检查点数据重新创建上下文。如果该目录不存在(即第一次运行),则将functionToCreateContext调用该函数以创建新上下文并设置DStreams。
请注意,RDD的检查点会导致保存到可靠存储的成本。这可能会导致RDD获得检查点的那些批次的处理时间增加。因此,需要仔细设置检查点的间隔。在小批量(例如1秒)时,每批检查点可能会大大降低操作吞吐量。相反,检查点太不频繁会导致沿袭和任务规模增加,这可能会产生不利影响。对于需要RDD检查点的有状态转换,默认间隔为批处理间隔的倍数,至少应为10秒。可以使用设置 dstream.checkpoint(checkpointInterval)。通常,DStream的5-10个滑动间隔的检查点间隔是一个很好的尝试设置。

若有收获,就点个赞吧
0 人点赞
