逻辑层
RDD 血统(lineage)与 Spark 容错
在 DAG 中,最初的 RDD 被称为基础 RDD,后续生成的 RDD 都是由算子以及依赖关系生成的,也就是说,无论哪个 RDD 出现问题,都可以由这种依赖关系重新计算而成。血统的表现形式主要分为宽依赖(wide dependency)与窄依赖(narrow dependency),如下图所示:
- 窄依赖:子 RDD 中的分区与父 RDD 中的分区只存在一对一的映射关系
- 宽依赖: 子 RDD 中的分区与父 RDD 中的分区存在一对多的映射关系
宽依赖还有个名字,叫 Shuffle 依赖,也就是说宽依赖必然会发生 Shuffle 操作,在前面也提到过 Shuffle 也是划分 Stage 的依据。而窄依赖由于不需要发生 Shuffle,所有计算都是在分区所在节点完成,它类似于 MapReduce 中的 ChainMapper。所以说,在你自己的 DAG 中,如果你选取的算子形成了宽依赖,那么就一定会触发 Shuffle。
物理层
很多算子都会引起 RDD 中的数据进行重分区,新的分区被创建,旧的分区被合并或者被打碎,在重分区的过程中,如果数据发生了跨节点移动,就被称为 Shuffle,在 Spark 中, Shuffle 负责将 Map 端(这里的 Map 端可以理解为宽依赖的左侧)的处理的中间结果传输到 Reduce 端供 Reduce 端聚合(这里的 Reduce 端可以理解为宽依赖的右侧)它是 MapReduce 类型计算框架中最重要的概念,同时也是很消耗性能的步骤。Spark 对 Shuffle 的实现方式有两种:Hash Shuffle 与 Sort-based Shuffle,这其实是一个优化的过程。在较老的版本中,Spark Shuffle 的方式可以通过 spark.shuffle.manager 配置项进行配置,而在最新的 Spark 版本中,已经去掉了该配置,统一称为 Sort-based Shuffle。
Hash Shuffle
在 Spark 1.6.3 之前, Hash Shuffle 都是 Spark Shuffle 的解决方案之一。 Shuffle 的过程一般分为两个部分:Shuffle Write 和 Shuffle Fetch,前者是 Map 任务划分分区、输出中间结果,而后者则是 Reduce 任务获取到的这些中间结果。Hash Shuffle 的过程如下图所示: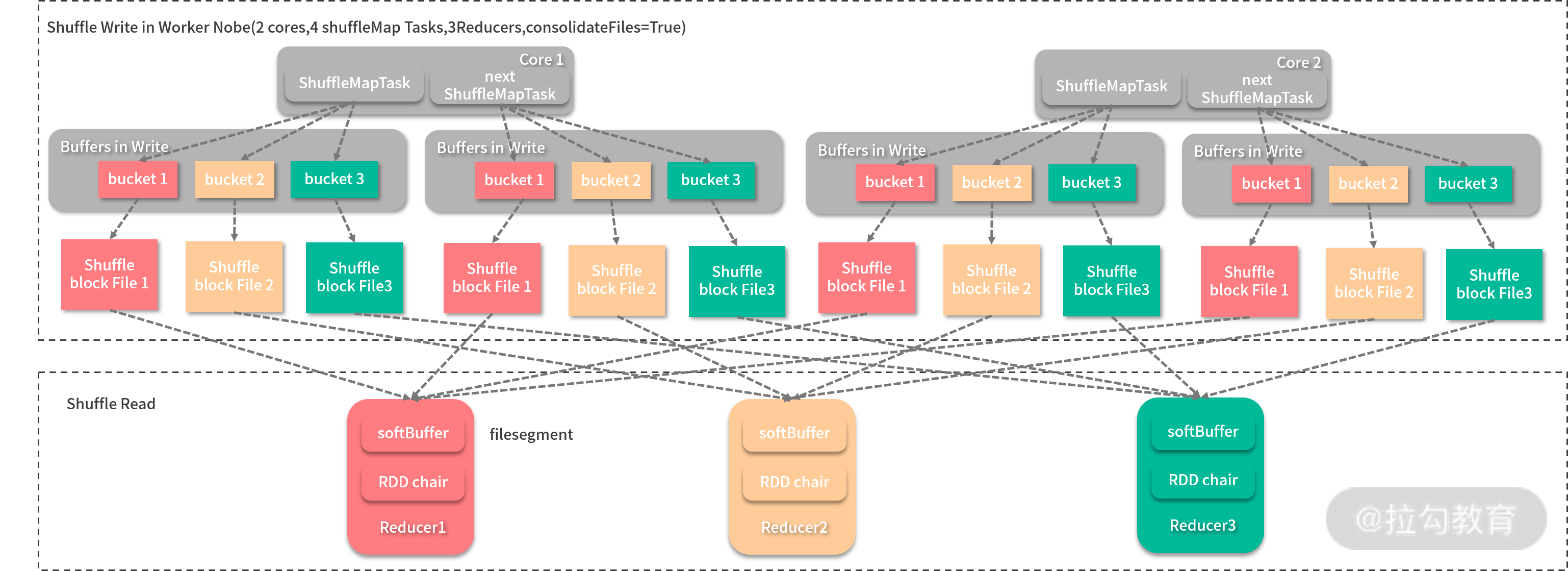
在图中,Shuffle Write 发生在一个节点上,该节点用来执行 Shuffle 任务的 CPU 核数为 2,每个核可以同时执行两个任务,每个任务输出的分区数与 Reducer(这里的 Reducer 指的是 Reduce 端的 Executor)数相同,即为 3,每个分区都有一个缓冲区(bucket)用来接收结果,每个缓冲区的大小由配置 spark.shuffle.file.buffer.kb 决定。这样每个缓冲区写满后,就会输出到一个文件段(filesegment),而 Reducer 就会去相应的节点拉取文件。这样的实现很简单,但是问题也很明显。主要有两个:
- 生成的中间结果文件数太大。理论上,每个 Shuffle 任务输出会产生 R 个文件( R为Reducer 的个数),而 Shuffle 任务的个数往往由 Map 任务个数 M 决定,所以总共会生成 M * R 个中间结果文件,而往往在一个作业中 M 和 R 都是很大的数字,在大型作业中,经常会出现文件句柄数突破操作系统限制。
- 缓冲区占用内存空间过大。单节点在执行 Shuffle 任务时缓存区大小消耗为 m R spark.shuffle.file.buffer.kb,m 为该节点运行的 Shuffle 任务数,如果一个核可以执行一个任务,m 就与 CPU 核数相等。这对于动辄有 32、64 物理核的服务器来说,是比不小的内存开销。为了解决第一个问题, Spark 推出过 File Consolidation 机制,旨在通过共用输出文件以降低文件数,如下图所示:
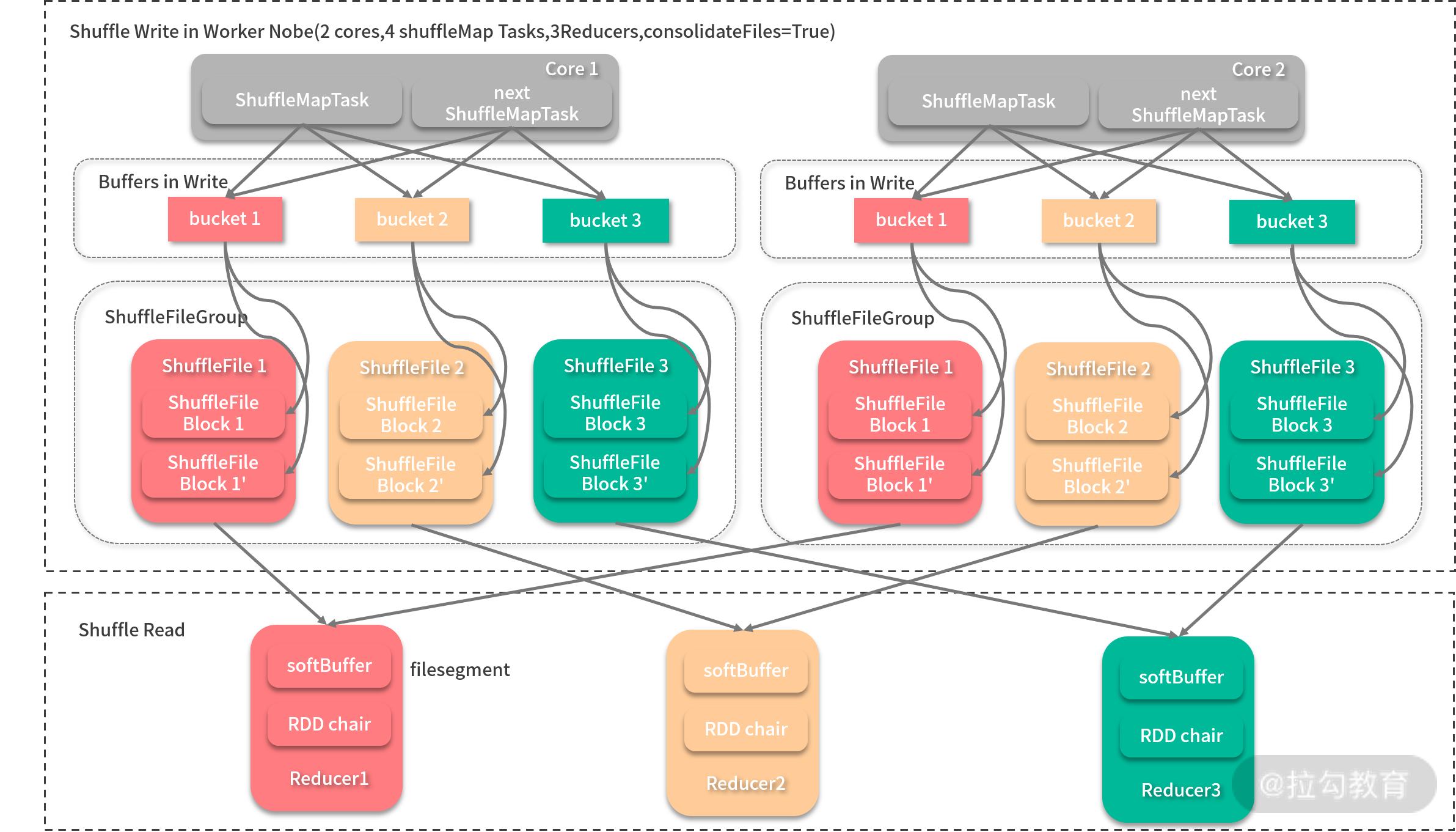
每当 Shuffle 任务输出时,同一个 CPU 核心处理的 Map 任务的中间结果会输出到同分区的一个文件中,然后 Reducer 只需一次性将整个文件拿到即可。这样,Shuffle 产生的文件数为 C(CPU 核数)* R。 Spark 的 FileConsolidation 机制默认开启,可以通过 spark.shuffle.consolidateFiles 配置项进行配置。
Sort-based Shuffle
在 Spark 先后引入了 Hash Shuffle 与 FileConsolidation 后,还是无法根本解决中间文件数太大的问题,所以 Spark 在 1.2 之后又推出了与 MapReduce 一样(你可以参照《Hadoop 海量数据处理》(第 2 版)的 Shuffle 相关章节)的 Shuffle 机制: Sort-based Shuffle,才真正解决了 Shuffle 的问题,再加上 Tungsten 计划的优化, Spark 的 Sort-based Shuffle 比 MapReduce 的 Sort-based Shuffle 青出于蓝。如下图所示: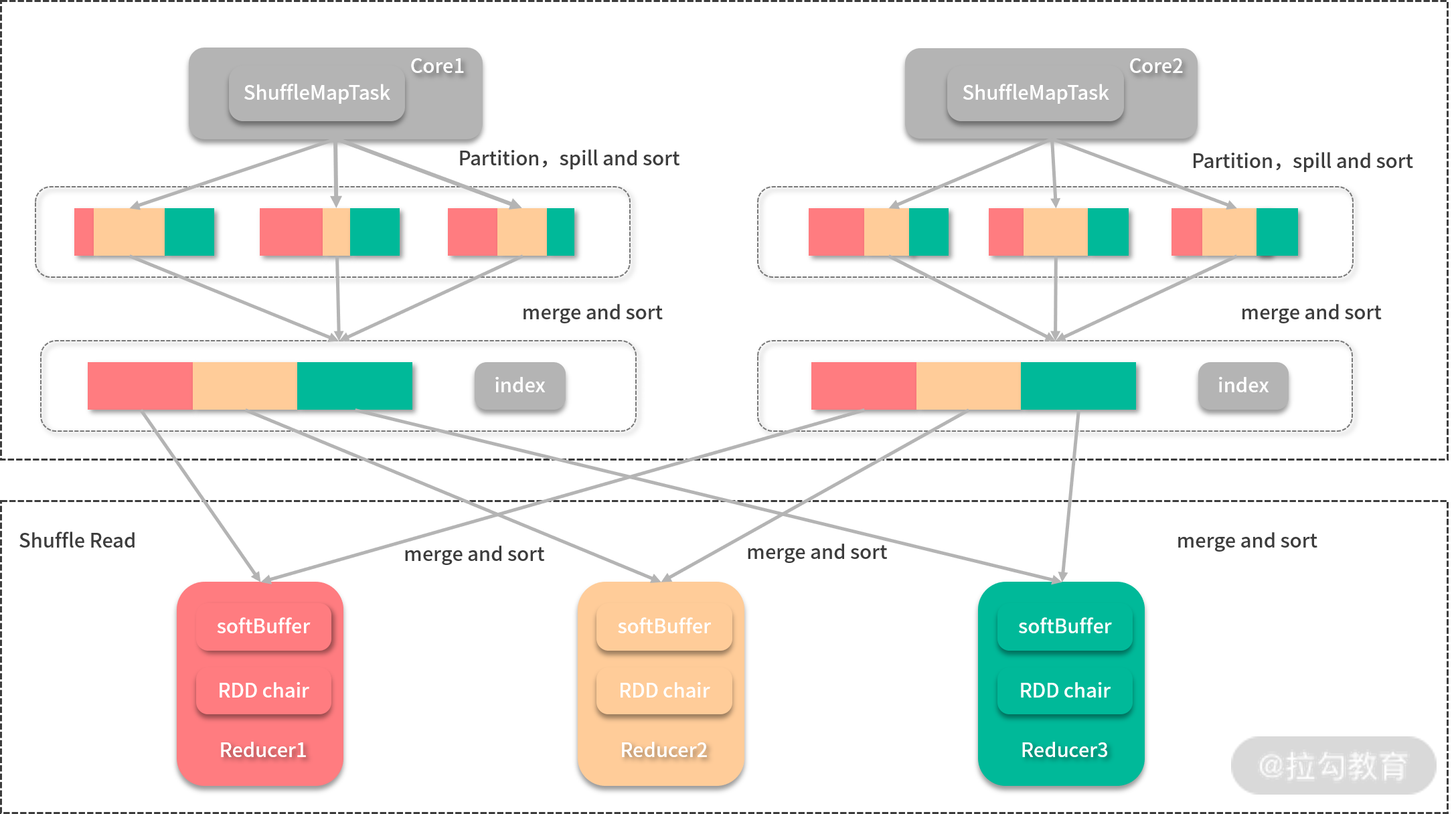
每个 Map 任务会最后只会输出两个文件(其中一个是索引文件),其中间过程采用的是与 MapReduce 一样的归并排序,但是会用索引文件记录每个分区的偏移量,输出完成后,Reducer 会根据索引文件得到属于自己的分区,在这种情况下,Shuffle 产生的中间结果文件数为 2 * M(M 为 Map 任务数)。在基于排序的 Shuffle 中, Spark 还提供了一种折中方案——Bypass Sort-based Shuffle,当 Reduce 任务小于 spark.shuffle.sort.bypassMergeThreshold 配置(默认 200)时,Spark Shuffle 开始按照 Hash Shuffle 的方式处理数据,而不用进行归并排序,只是在 Shuffle Write 步骤的最后,将其合并为 1 个文件,并生成索引文件。这样实际上还是会生成大量的中间文件,只是最后合并为 1 个文件并省去排序所带来的开销,该方案的准确说法是 Hash Shuffle 的Shuffle Fetch 优化版。
Spark 在1.5 版本时开始了 Tungsten 计划,也在 1.5.0、 1.5.1、 1.5.2 的时候推出了一种 tungsten-sort 的选项,这是一种成果应用,类似于一种实验,该类型 Shuffle 本质上还是给予排序的 Shuffle,只是用 UnsafeShuffleWriter 进行 Map 任务输出,并采用了要在后面介绍的 BytesToBytesMap 相似的数据结构,把对数据的排序转化为对指针数组的排序,能够基于二进制数据进行操作,对 GC 有了很大提升。但是该方案对数据量有一些限制,随着 Tungsten 计划的逐渐成熟,该方案在 1.6 就消失不见了。
从上面整个过程的变化来看, Spark Shuffle 也是经过了一段时间才趋于成熟和稳定,这也正像学习的过程,不用一蹴而就,贵在坚持。
习题及解析
用 Spark 算子实现对 1TB 的数据进行排序?
关于这道题的解法,你可能很自然地想到了归并排序的原理,首先每个分区对自己分区进行排序,最后汇总到一个分区内进行全排序,如下图所示: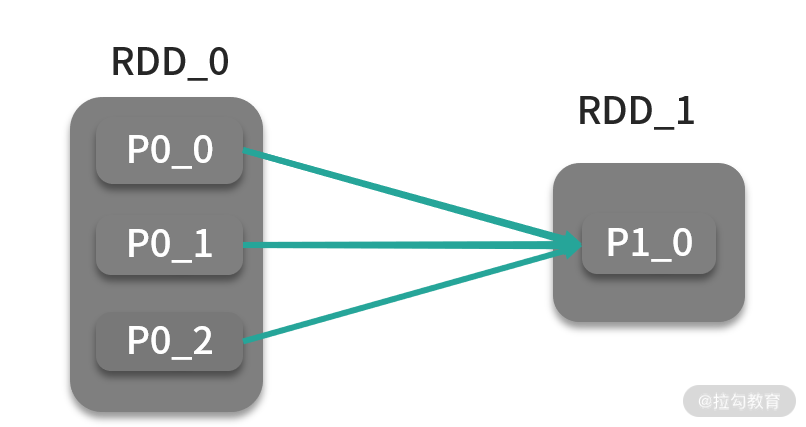
可想而知,最后 1TB 的数据都会汇总到 1 个 Executor,就算这个 Executor 分配到的资源再充足,面对这种情况,无疑也是以失败告终。
这道题的解法应该是另一种方案,首先数据会按照键的区间进行分发,也就是 Shuffle,如 [0,100000]、 [100000,200000)和 [200000,300000],每个分区没有交集。照此规则分发后,分区内再进行排序,就可以在满足性能要求的前提下完成全排序,如下图: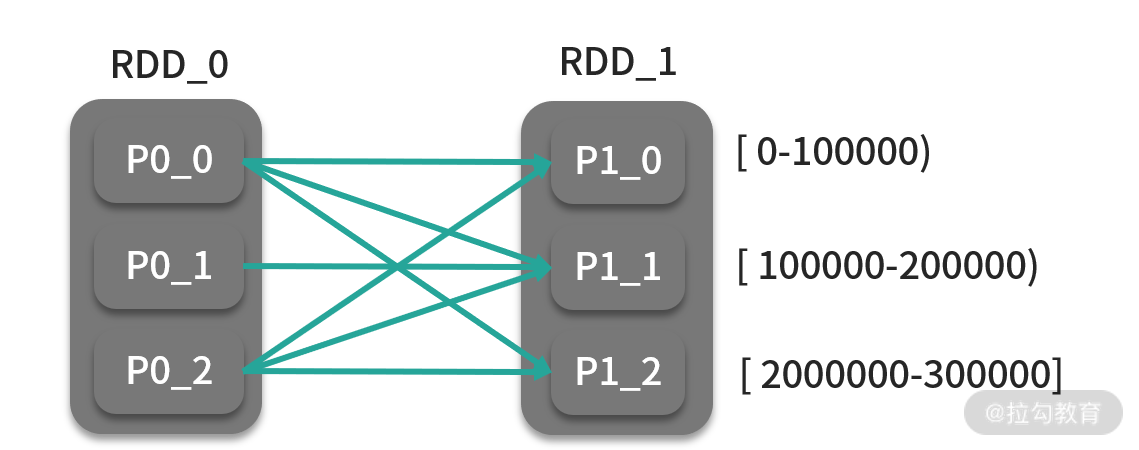
这种方式的全排序无疑实现了计算的并行化。
于这种排序方式,Spark 也将其封装为 sortByKey 算子,它采用的分区器则是 RangePartitioner。

若有收获,就点个赞吧
0 人点赞
