窗口函数可以使用户针对某个范围的数据进行聚合操作,如:
- 累积和
- 差值
- 加权移动平均
可以想象一个窗口在全量数据集上进行滑动,用户可以自定义在窗口中的操作,如下图所示。
使用窗口函数,首先需要定义窗口,DataFrame 提供了 API 定义窗口,以及窗口中的计算逻辑,还是以学生成绩为例,现在需要得出每个学生单科最佳成绩以及成绩所在的年份,这个需求就要用到窗口中的 row_number 函数,row_number 函数可以根据窗口中的数据生成行号,首先来定义窗口:
import org.apache.spark.sql.expressions.Windowimport org.apache.spark.sql.functions._val window = Window.partitionBy("name","subject").orderBy(desc("grade"))
上面的代码定义了窗口的范围:按照每个人的姓名与科目的组合进行开窗,并控制了数据在窗口中的顺序:按照 grade 降序进行排序,row_number 函数就可以作用在这个窗口上,对每个人每个科目成绩赋予行号,代码如下:
dfSG.select(col("name"), col("subject"), col("year"), col("grade"), row_number().over(window)).show()
结果如图:
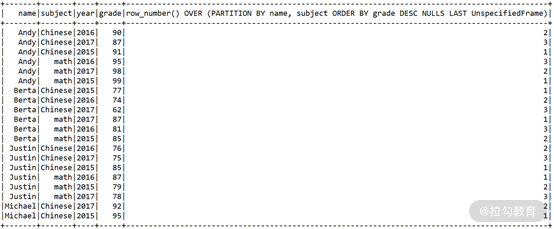
最后只需要从这张表中过滤出 row_number 等于 1 的数据即可。
此外,DataFrame 还提供了 rowsBetween 和 rangeBetween 来进一步定义窗口范围,其中 rowsBetween 是通过物理行号进行控制,rangeBetween 是通过逻辑条件来对窗口进行控制。
// rangeBetween 窗口是当前行的 num 值 +2 到当前行的 num 值 +20 这个区间中的数据val windowSlide = Window.partitionBy("key").orderBy("num").rangeBetween(Window.currentRow + 2,Window.currentRow + 20)val dfWin = spark.read.json("json/window.json")dfWin.select(col("key"),sum("num").over(windowSlide)).sort("key").show()// rowsBetween 通过行号来指定参与计算的物理窗口,窗口由当前行、当前行的前一行、当前行的后一行组成,窗口大小为 3val windowSlide = Window.partitionBy("key").orderBy("num").rowsBetween(Window.currentRow - 1,Window.currentRow + 1)dfWin.select(col("key"),sum("num").over(windowSlide)).sort("key").show()
在实际开发过程中,大量的需求都可以直接通过函数以及函数的组合完成,一般来说,函数的丰富程度往往超乎你的想象,所以在面临新需求时,建议首先查阅文档,看看有没有函数可以利用,如果实在不行,我们才会使用用户自定义函数(User Defined Function)。
Spark SQL 的函数文档目前我没有发现特别全面的,所以我通常就会直接阅读源码,源码列出了所有的函数,如下:

若有收获,就点个赞吧
0 人点赞
