1.String的基本特性
- String: 字符串 , 使用一对””引起来表示
- String s1 = “Anda”; // 字面量的定义方式
- String s2 = new String(“moxi”);
- string申明为final , 不可被继承
- String实现了Serializable接口: 表示字符串是支持序列化的, 实现了Comparable接口: 表示string可以比较大小
- string在jdk8及以前内部定义的final char[] value用于存储字符串数据, JDK9时改成了byte[]
1.为什么JDK9改变了结构
String类的当前实现将字符存储在char数组中,每个字符使用两个字节(16位),从许多不同的应用程序收集的数据表明, 字符串是堆使用的主要组成部分, 而且, 大部分数字字符串对象只包含拉丁字符,这些字符只需要一个字节的存储空间, 因此这些字符串对象的内部char数组中有一半的空间将不会使用
我们建议改变字符串的内部表示clasš从utf-16字符数组到字节数组+一个encoding-flag字段, 新的String类将根据字符串的内容存储编码为ISO-8859-1/Latin-1(每个字符一个字节)或者UTF-16(每个字符两个字节)的字符, 编码标志将指示使用那种编码.
结论: String再也不用char[]来存储了, 改成了byte[] 加上编码标记, 节约了一些空间
// 之前private final char value[]// 之后private final byte[] value;
同时基于String的数据结构,列如StringBuffer 和 StringBuilder也同样做了修改
2.String的不可变性
String: 代表不可变的字符序列. 简称: 不可变性.
当对字符串重新赋值时, 需要重写指定内存区域赋值 , 不能使用原有的value进行赋值. 当对现有的字符串进行连接操作时 , 也需要重新指定内存区域赋值, 不能使用原有的value进行赋值, 当调用string的replace()方法修改指定字符或者字符串时, 也需要重新指定内存区域赋值, 不能使用原有的value进行赋值, 通过字面量的方式(区别于new)给一个字符串赋值, 此时的字符串值声明在字符串常量池中.
3.面试题
/*** @author anda* @since 1.0*/public class StringExer {static String str = new String("good");char[] ch = {'1', 'b', 'c', 'e'};public void change(String str, char[] ch) {str = "234";ch[0] = 's';}public static void main(String[] args) {StringExer stringExer = new StringExer();stringExer.change(stringExer.str, stringExer.ch);System.out.println("stringExer.str = " + stringExer.str);System.out.println("stringExer.ch = " + Arrays.toString(stringExer.ch));}}
输出结果
good[s,b,c,e]
4.注意:
字符串常量池是不会存储相同的内容的字符串的
String的string pool是一个固定的大小的Hashtable, 默认大小长度是1009, 如果放进string pool的string非常多, 就会造成hash冲突严重, 从而导致链表会很长,而链表长了后直接造成的影响就是调用string.intern时性能大幅下降.
使用-XX:StringTableSize可以设置stringtable的长度
在JDK6中的Stringtable是固定的,就是1009长度, 如果常量池中的字符串过多就会造成效率下降的很快,stringtablesize设置没有要求
在jdk7中,stringtable的长度默认值是60013
在jdk8中,StringTable可以设置的最小值为1009
2.String的内存分配
在Java基础中有8种基本类型数据和一种比较特殊的类型string,这些类型为了使它们运行过程中速度更加快,更节省内存,都提供了一种常量池的概念
常量池就是类似于Java系统级别提供的缓存,8中基本数据类型的常量池都是系统协调的,string类型常量池比较特殊, 它的主要使用方法有两种
直接使用双引号声明出来的String对象会直接存储在常量池中.
- 比如: String info = “atguigu.com”;
如果不是用双引号声明的string对象,可以使用string提供的intern()方法.
Java6及以前 , 字符串常量池存放在永久代
Java7中的常量池的逻辑做了很大的改变, 即将字符串常量池的位置调整到Java堆区
所有的字符串都保存在堆中,和其他普通对象一样, 这样可以让你在进行调优应用时仅需要调整堆大小就可以了. 字符串常量池概念原本使用的比较多,但是这个改动使得我们有足够的理由重新考虑在Java7中使用string.intern()
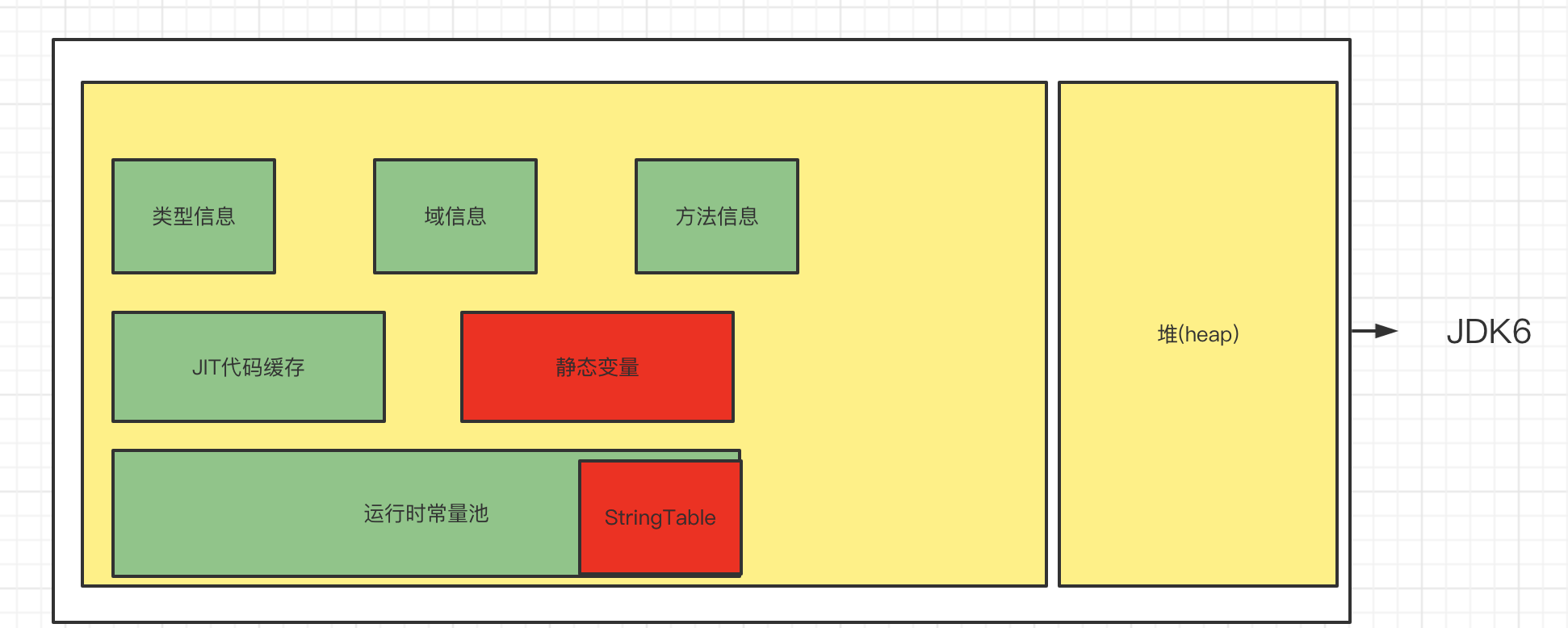
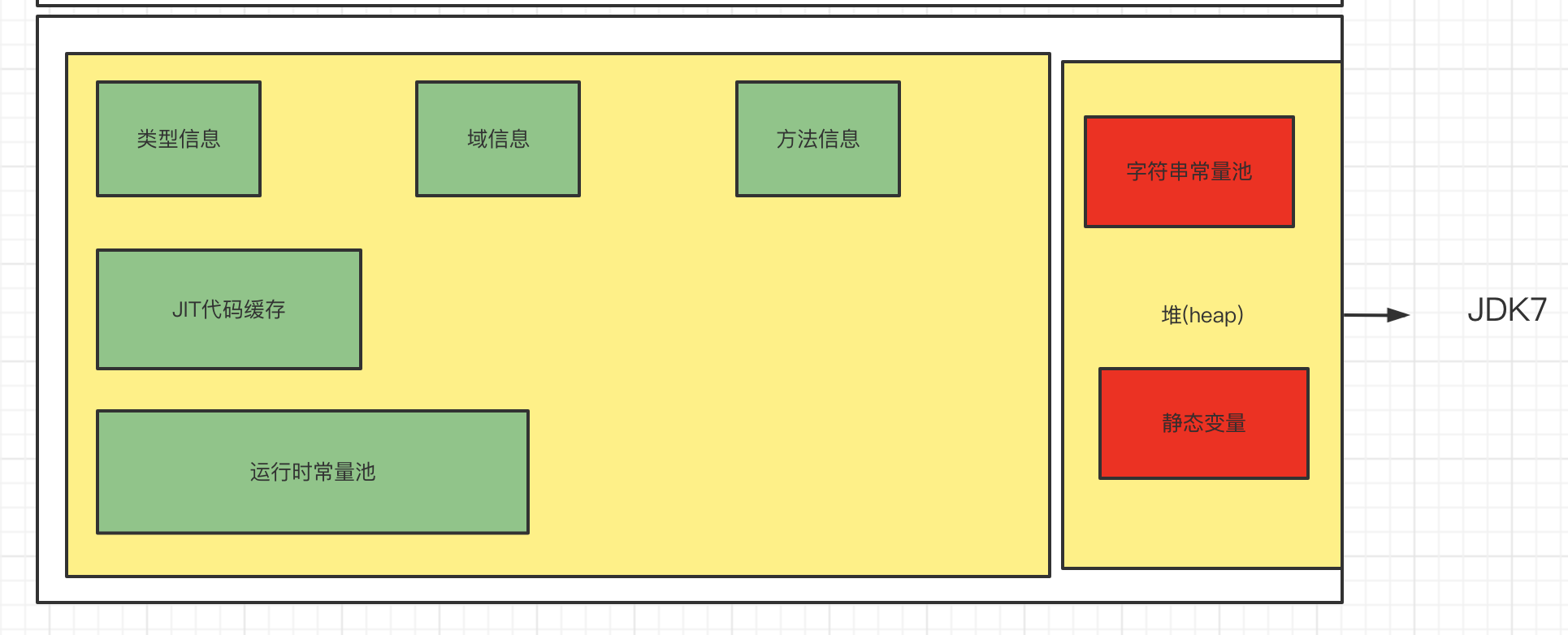
1.为什么StringTable从永久代调整到堆中
在JDK7中, interned字符串不再Java堆的永久生成中分配, 而是在Java堆的主要部分(Ole Gen 和 Yong Gen) 中分配的 , 与应用程序创建的其他对象一起分配,因此更改将导致驻留在主Java堆中的数据更多, 驻留在永久生成中的数据更加少, 因此可能需要调整堆大小,由于这一变化,大多数应用程序在堆使用方面就会比较少, 但加载许多类或大量字符串的较大应用程序会出现这种差异,intern()方法会更显著的差异
- 永久代默认比较小
- 永久代垃圾回收频率低
3.String的基本操作
Java语言贵方要求相完全相同的字符串字面量,应该包含同样的Unicode字符序列(包含同一份码点序列的常量,)并且必须是指向同一个String类实例
4.字符串拼接操作
- 常量与常量的拼接结果在常量池,原理是编译器优化
- 常量池中不会存在相同内容的变量
- 只要其中有一个变量,结果就是在堆中, 变量拼接的原理是StringBuilder
如果拼接的结果调佣intern()方法,则主动将常量池中还没有的字符串对象放入池中,并返回此对象地址 ```java /**
- @author anda
@since 1.0 */ public class StringAppendTest {
public static void test1() {
String s1 = "a" + "b" + "c"; // 得到abc的常量池String s2 = "abc";// abc存放在常量池,直接将常量池的地址返回System.out.println(s1 == s2); // trueSystem.out.println(s1.equals(s2)); // true
}
public static void test2() {
String s1 = "javaEE";String s2 = "hadoop";String s3 = "javaEEhadoop";String s4 = "javaEE" + "hadoop";String s5 = s1 + "hadoop";String s6 = "javaEE" + s2;String s7 = s1 + s2;System.out.println(s3 == s4); // trueSystem.out.println(s3 == s5); // falseSystem.out.println(s3 == s6); // falseSystem.out.println(s3 == s7); // falseSystem.out.println(s5 == s6); // falseSystem.out.println(s5 == s7); // falseSystem.out.println(s6 == s7); // falseString s8 = s6.intern();System.out.println(s3 == s8); // true
}
public static void main(String[] args) {
//test1();test2();
} }
从上述的结果我们可以知道:<br />如果拼接符号的前后出现了变量, 则相当于在堆空间中new String(), 具体的内容为拼接的结果<br />从而调用intern方法, 则会判断字符串常量池中是否存在JavaEEhadoop值, 如果存在则返回常量池中的值, 否则就在常量池中创建<a name="ED1tW"></a>## 1.底层原理拼接操作的底层其实使用了StringBuilder<br /><br />s1+s2的执行细节- StringBuilder s = new StringBuilder;- s.append(s1);- s.append(s2);- s.toString --> 类似new String('ab');在JDK5之后,使用的是StringBuilder,在JDK5之前使用的是StringBuffer| String | StringBuffer | StringBuilder || --- | --- | --- || String的值是不可变的, 这就导致了每次对String的操作都会生成新的String对象 , 不仅效率低下, 而且浪费空间大量的优先空间. | StringBuffer是可变类,和线程安全的字符串操作类, 任何堆它指向的字符串的操作都不会产生新的对象, 每个StringBuffer对象都有一定的缓冲区容量,当字符串大小没有超过容量是, 不会分配新的容量,当字符串大小超过容量时, 会自动增加容量 | 可变类,速度快 || 不可变 | 可变 | 可变 || | 线程安全 | 线程不安全 || | 多线程操作字符串 | 单线程操作字符串 |**注意: **如果左右两边任何一个都是变量的话, 底层就会使用new StringBuilder 进行拼接, 但是如果使用的是final修饰, 则是从常量池中获取 , 所以拼接符号左右两边都是字符串常量或常量引用, 则仍然使用编译器优化 , 也就是呗final修饰的变量, 将会变成常量, 类和方法将不能被继承- 在实际开发中,能够使用final的时候,建议使用上```javapublic static void test3(){final String a = "a";final String b = "b";String s3 = "ab";String s4 = a + b;System.out.println(s3==s4); // true}
2.拼接操作和append性能比对
/*** 6686ms*/public static void method1() {long start = System.currentTimeMillis();String source = "";for (int i = 0; i < 100000; i++) {source += "a"; //每次都会创建一个新的StringBuilder对象, 当然, 这是在1,5之后(1.5之前都是StringBuffer)}long end = System.currentTimeMillis();System.out.println(end - start);}/*** 7ms*/private static void method2() {long start = System.currentTimeMillis();StringBuilder source = new StringBuilder();for (int i = 0; i < 100000; i++) {source.append("a");}long end = System.currentTimeMillis();System.out.println(end - start);}
方法1 耗时的时间: 6686ms , 方法2耗时时间: 7ms
结论:
- 通过StringBuilder的append()方式添加字符串的效率, 要远高于String的字符串拼接方法
好处:
- StringBuilder的append的方式 , 自始至终只创建一个StringBuilder的对象
- 对于字符串拼接方式, 还需要创建很多StringBuilder对象和调用toString时候, 创建的String对象
- 内存中由于创建了比较多的StringBuilder和String对象, 内存占用过大, 如果进行GC那么将会耗时更多的时间
改进的空间
- 我们使用的是StringBuilder的空参数构造器, 默认的字符串容量是16 , 然后将原来的字符串拷贝到新的字符串中, 我们也可以默认初始化更大的长度, 减少扩容的次数.
- 因此在实际开发中 , 我们能够确定, 前前后后需要添加字符串不高于某个限定值, 那么建议使用构造器创建一个阈值的长度.
5.intern()的使用
如果不是用双引号申明的String对象,可以使用string提供的intern方法: intern方法会从字符串常量池中查询当前字符串是否存在, 如若不存在就会将当前字符串放入常量池中.
- 比如: String myInfo = new String(“Test intern()”).intern();
也就是说 , 如果在任意字符串上调用String.intern方法, 那么其返回结果所指向的那个类实例, 必须和直接以常量形式出现的字符串实例完全相同, 因此, 下列表达式的值必定是true:
(“a”+”b”+”c”).intern() == “abc”
Interned String就是确保字符串在内存里只有一份拷贝 , 这样可以节约内存空间 , 加快字符串操作任务的执行速度. 注意 , 这个值会被存放在字符串内部池(String Intern Pool).
/***如何保证变量指向的是字符串常量池中的数据呢?有两种方式:1. String str = "shkstart"; // 字面量定义的方式2.1. String str = new String("shkstart").intern();2. String str = new StringBuilder("shkstart").toString().intern();**/public class StringIntern(){public static void main(String args[]){}}
1.new String(); 创建了几个对象
- new String(): 只会创建一个对象
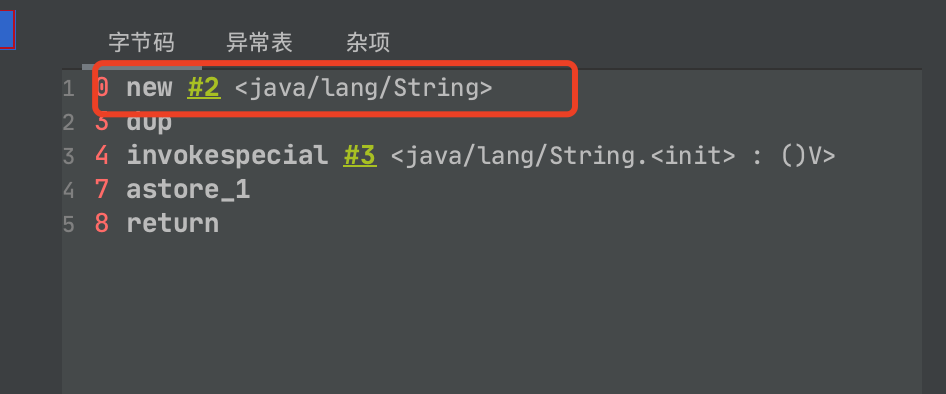
- new String(“abc”); 至少创建一个对象,最多创建两个对象
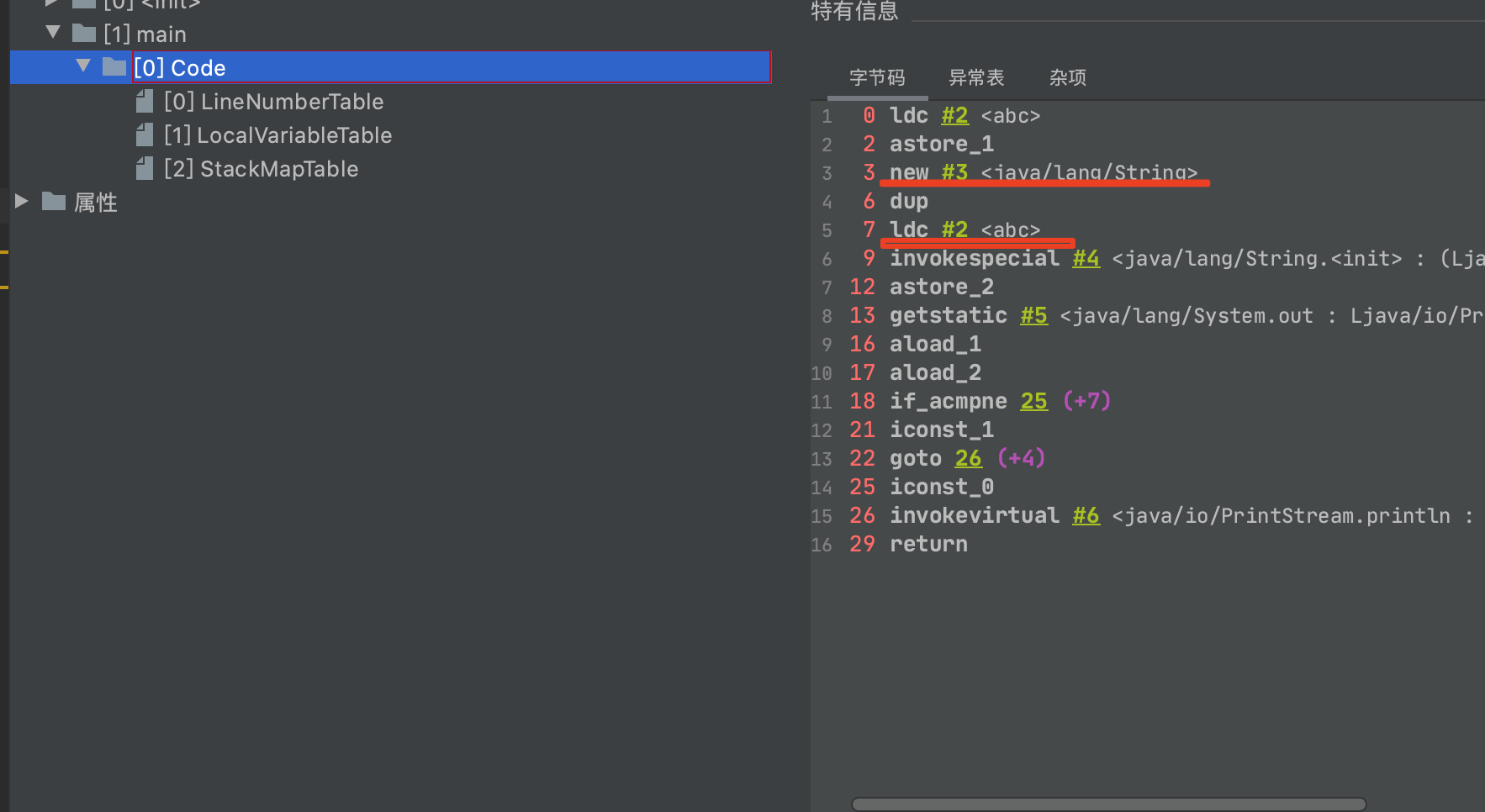
- String str = new String(“a”)+new String(“b”); 是创建六次 , 可是字节码上面的只有5次
- 第一次是new StringBuilder()
- 第二次是 new String(“a”)
- 第三次是ldc “a”变量
- 第四次是 new String(“b”);
- 第五次是ldc “b”变量
- 第六次是toString()是底层一次new String()
�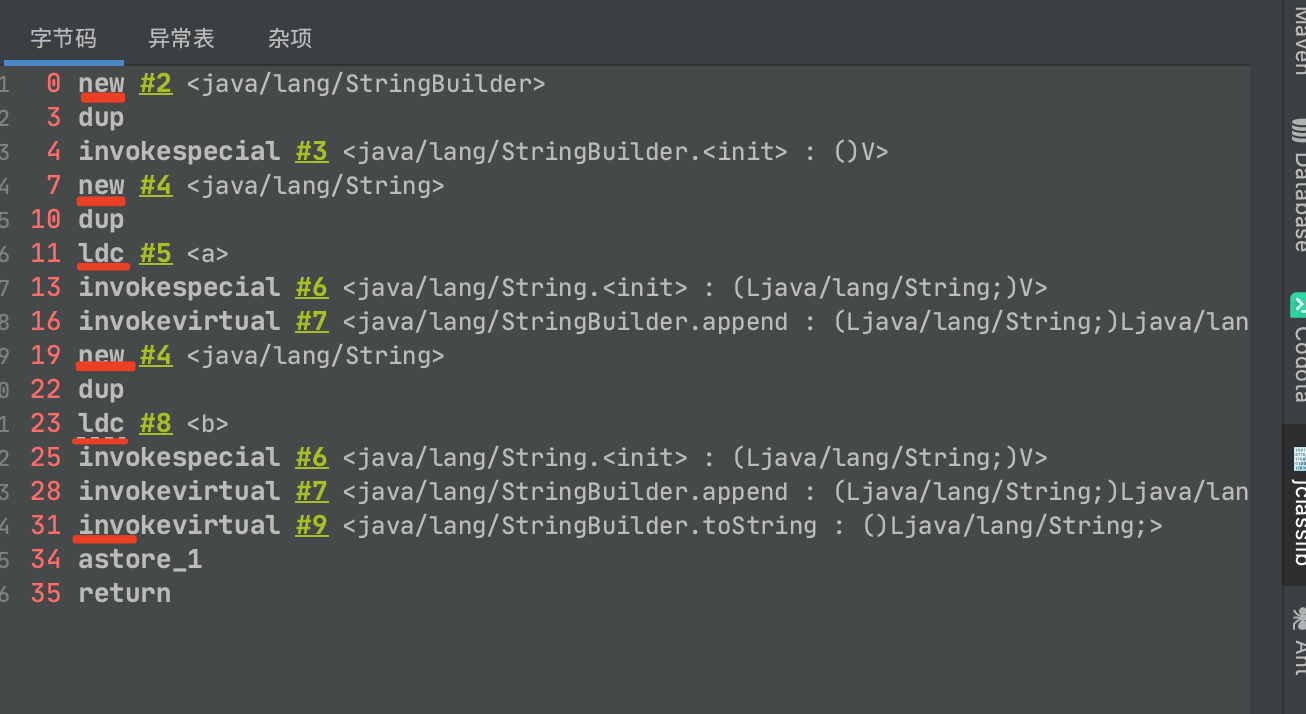

/*** 题目:* new String("ab") 会创建几个对象? 看字节码 , 就知道是两个.* 一个对象是: new 关键字在堆空间创建的* 另一个对象是: 字符串常量池中的对象 , 字节码指令: ldc** 扩展:* new String("a") + new String("b") 呢?* 对象1: new StringBuilder()* 对象2: new String("a")* 对象3: 常量池中的"a"* 对象4: new String("b")* 对象5: 常量池中的"b"** 深入剖析: StringBuilder的toString()* 对象6: new String("ab")* 强调一下: toString的调用, 在字符串常量池中, 没有生成"ab"*** @author anda* @since 1.0*/public class StringNewTest {public static void main(String[] args) {// String str1 = "abc";// String str = new String("abc");// System.out.println(str1 == str);String str = new String("a")+new String("b");}}
2.关于intern()
public class StringIntern {public static void main(String[] args) {String s = new String("1");s.intern(); // 调用此方法以前 , 字符串常量池中已经存在"1"String s2 = "1";System.out.println(s == s2); // jdk6:false jdk8/jdk7: falseString s3 = new String("1") + new String("1");// 执行完上一行代码以后, 字符串常量池中, 是不存在11的s3.intern(); // 在字符串常量池中生成"11", 在jdk6之中 , 创建了一个新的对象"11" , 也就有了新的地址 , jdk7String s4 = "11";System.out.println(s3 == s4); // jdk6 false jdk7/jdk8 true}}
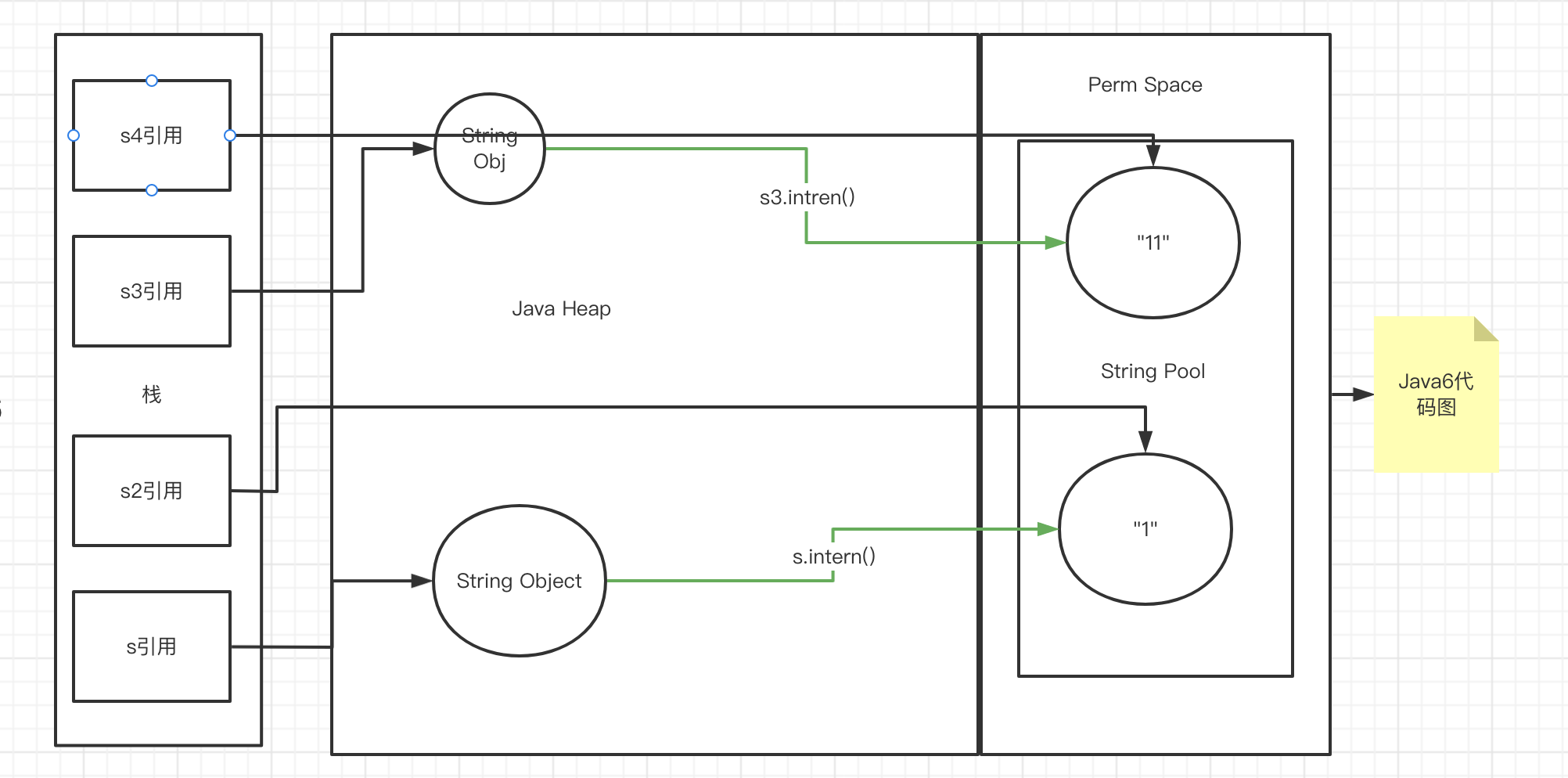
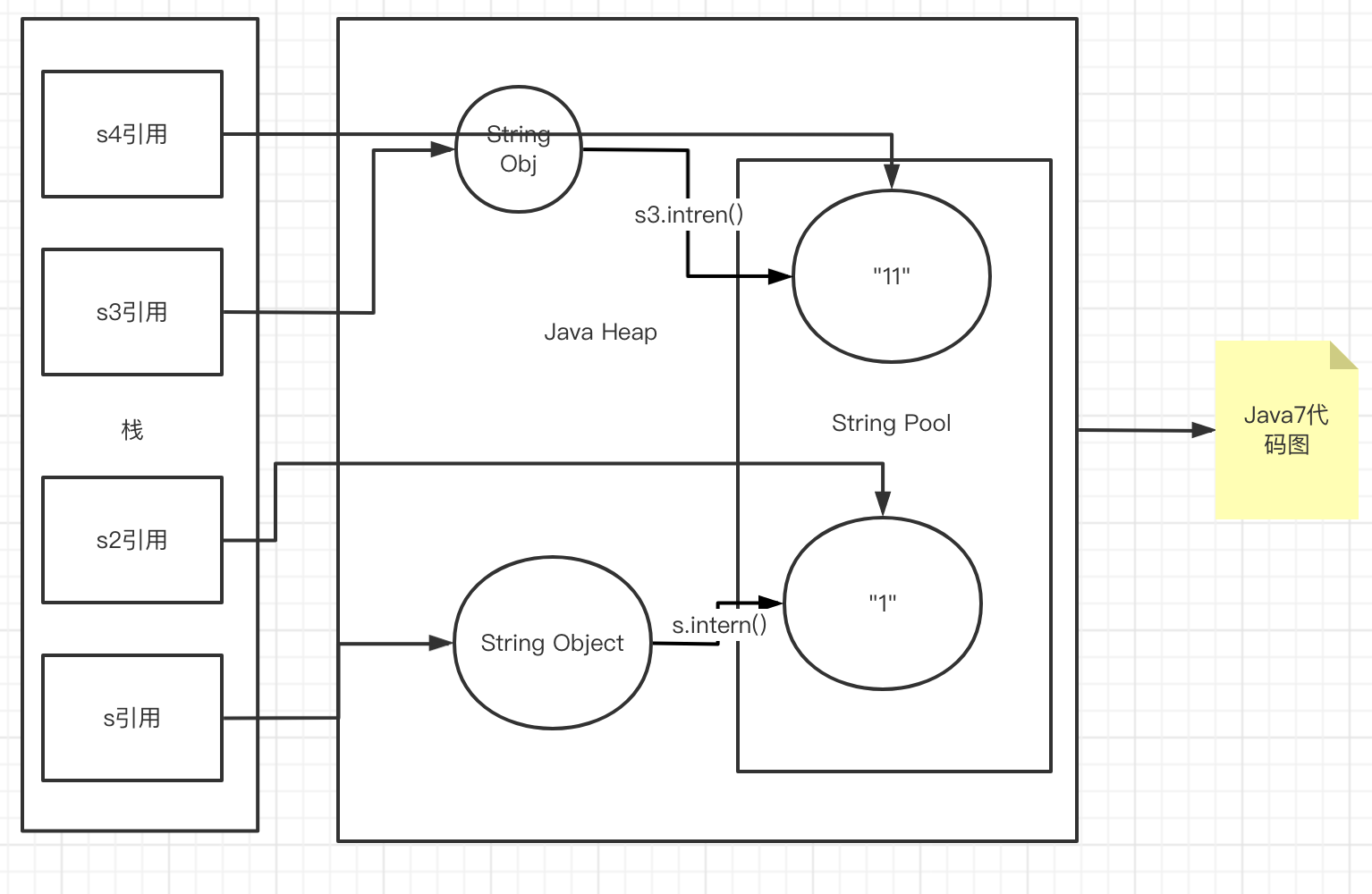
总结String的intern()的使用;
- jdk1.6中, 将这个字符串对象尝试放入串池.
- 如果串池中 , 则不会放入,返回已有的串池中的对象的地址
- 如果没有 , 会把此对象复制一份, 放入串池,并返回串池中的对象地址
- jdk1.7起,将这个字符串对象尝试放入串池.
- 如果串池中有, 则不会放入, 返回已有的串池中的对象的地址
- 如果没有 , 则会把对象的引用地址复制一份, 放入串池 , 并返回串池中的引用地址
3.intern()其他面试题
String s = new String("1");s.intern();String s1 = "1";System.out.println(s1 == s);/*** jdk1.6 true* 1. String s = new String("1"); 先生成一个对象,此时对象地址就是0x1111* 2. 之后将"1" 放入常量池中 0x2222* 3. s.intern() , 判断常量池是否有此变量, 刚好发现有,就直接返回地址0x2222* 4. String s1 = "1"; 此时就会去常量池里面找,此时就会返回0x2222* 所以最后0x1111!=0x2222** jdk1.7/1.8 false* 1. String s = new String("1"); 先生成一个对象,此时对象地址就是0x1111* 2. 之后将"1" 放入常量池中 0x2222* 3. s.intern() , 判断常量池是否有此变量, 刚好发现有,就直接返回地址0x2222* 4. String s1 = "1"; 此时就会去常量池里面找,此时就会返回0x2222* 所以最后0x1111!=0x2222*/
String s = new String("1") + new String("1");s.intern();String s1 = "11";System.out.println(s1 == s);/*** jdk1.6 false* 1. String s = new String("1") + new String("1");此时对象地址就是0x1111,* 2.并不会将0x1111放入常量池里面* 3.s.intern()就会判断当前字符串是否存在常量池中,这里是不存在的情况, 就将堆中的对象复制到常量池中(jdk6的做法),并且生成新的地址返回0x2222* 4.String s1 = "11"; 判断常量池是否有此变量 , 刚好找到有此对象,返回0x2222* 所以最后0x2222!=0x1111** jdk1.7/jdk1.8 true* 1. String s = new String("1") + new String("1"); 此时对象地址就是0x1111,* 2. 这个时候并不会将常量放入常量池* 3. s.intern(); 判断常量池是否有此对象. 这个时候常量池是没有"11"常量的, 此时就需要生成一个常量池 , jdk7/8中的做法是将堆中的地址复制到常量池中,然后返回就是0x1111.* 4. String s1 = "11"; 先判断常量池是否有常量, 这个时候刚好发现有这个常量, 所以直接引用,就是0x1111* 最后0x1111==0x11111**/
String s1 = "11";String s = new String("1") + new String("1");String intern = s.intern();System.out.println(s1 == s);System.out.println(s1 == intern);/*** jdk1.6 false* 1.String s1 = "11"; 先创建对象,s1地址就是0x2222 , 这个时候在jdk1.6中, 这个常量池对象不存在, 就需要向堆中拷贝一份对象,并且生成新的地址 地址就会0x1111* 2 String s = new String("1") + new String("1"); 此时就只会生成对象, 比如 0x3333* 3.s.intern();判断对象池中是否有此对象,这个时候已经存在 , 就直接返回0x1111* 所以0x2222!=0x3333** jdk1.7/jdk1.8* 1. String s1 = "11"; 先创建对象,s1地址就是0x2222 , 这个时候在jdk1.7中, 如果常量池不存在, 就直接拷贝对象中的引用地址 地址就会0x2222* 2. String s = new String("1") + new String("1"); 此时对象地址就是0x1111* 3 s.intern();判断对象池中是否有此对象,这个时候已经存在 , 就直接返回0x2222* 最后 0x2222!=0x1111**/
4.intern的空间效率测试
public class StringIntern3 {static final int MAX_COUNT = 1000 * 10000;static final String[] arr = new String[MAX_COUNT];public static void main(String[] args) {Integer [] data = new Integer[]{1,2,3,4,5,6,7,8,9,10};long start = System.currentTimeMillis();for (int i = 0; i < MAX_COUNT; i++) {arr[i] = new String(String.valueOf(data[i%data.length])).intern();}long end = System.currentTimeMillis();System.out.println("花费的时间为:" + (end - start));try {Thread.sleep(1000000);} catch (Exception e) {e.getStackTrace();}}}
结论:
对于程序中有大量使用存在的字符串时, 尤其是存在很多已经重复的字符串时, 使用intern方法能够节省内存空间.
6.StringTable的垃圾回收
7.G1的String去重操作
注意这里说的是重复, 指的是在堆中的数据, 而不是常量池中的, 因为常量池中的本身就不会重复
1.描述
背景: 对许多Java应用(有大也有小的)做的测试得出以下结果:
- 堆存活数据集合里面的string对象占用25%
- 堆存活数据集合里面重复的string对象有13.5%
- string对象的平均长度是45
许多大规模的Java的应用的瓶颈在于内存, 测试表明,在这些类型的应用里面, Java堆中存活的数据集合差不多25%是string对象, 更进一步, 这里里面差不多一半string对象是重复的,重复的意思是说, stringl.equals(string2)==true,堆上存在重复的string对象必然是一种内存的浪费, 这个项目将在G1的垃圾收集器中实现自动持续堆重复的string对象进行去重, 这样就能避免浪费内存
2.实现
- 如果垃圾收集器工作的时候,会访问堆上存活的对象, 对每一个访问的对象都会检查是否是候选的要去重的string对象
- 如果是, 把这个对象的一个引用插入到队列中等待后续的处理,一个去重的线程在后台运行, 处理这个队列, 处理队列的元素意味着从队列中删除这个元素,然后尝试去重新引用string对象
- 使用一个hashtable来记录所有的被string对象使用的不重复的char数组, 当去重的时候,会查这个hashtable, 来看堆上是否已经存在一个一模一样的char数组
- 如果存在,string对象会被调整引用那个数组, 释放堆原来的数组的引用, 最终会被垃圾收集器回收掉
- 如果查找失败, char数组会被插入到hashtable, 这样以后的时候可以共享这个数组
3.开启
命令行选项:UsestringDeduplication(bool):开启string去重,默认是不开启的,需要手动开启。 PrintStringDeduplicationStatistics(bool):打印详细的去重统计信息 StringDeduplicationAgeThreshold(uintx):达到这个年龄的string对象被认为是去重的候选对象

若有收获,就点个赞吧
0 人点赞
