1.MapReduce思想
MapReduce思想在生活中处处可见, 我们或多或少都曾接触过这种思想.MapReduce的思想核心是分而治之
充分利用了并行处理的优势
MapReduce任务过程是分为两个处理阶段:
- Map阶段: Map阶段的主要作用是”分” , 即把复杂的任务分解为若干个”简单的任务”来并行处理. Map阶段的这些任务可以并行计算, 彼此没有依赖关系
- Reduce阶段: Reduce阶段的主要作用是”合”, 即堆Map阶段的结果进行全局汇总

2.官方WordCount案例源码解析
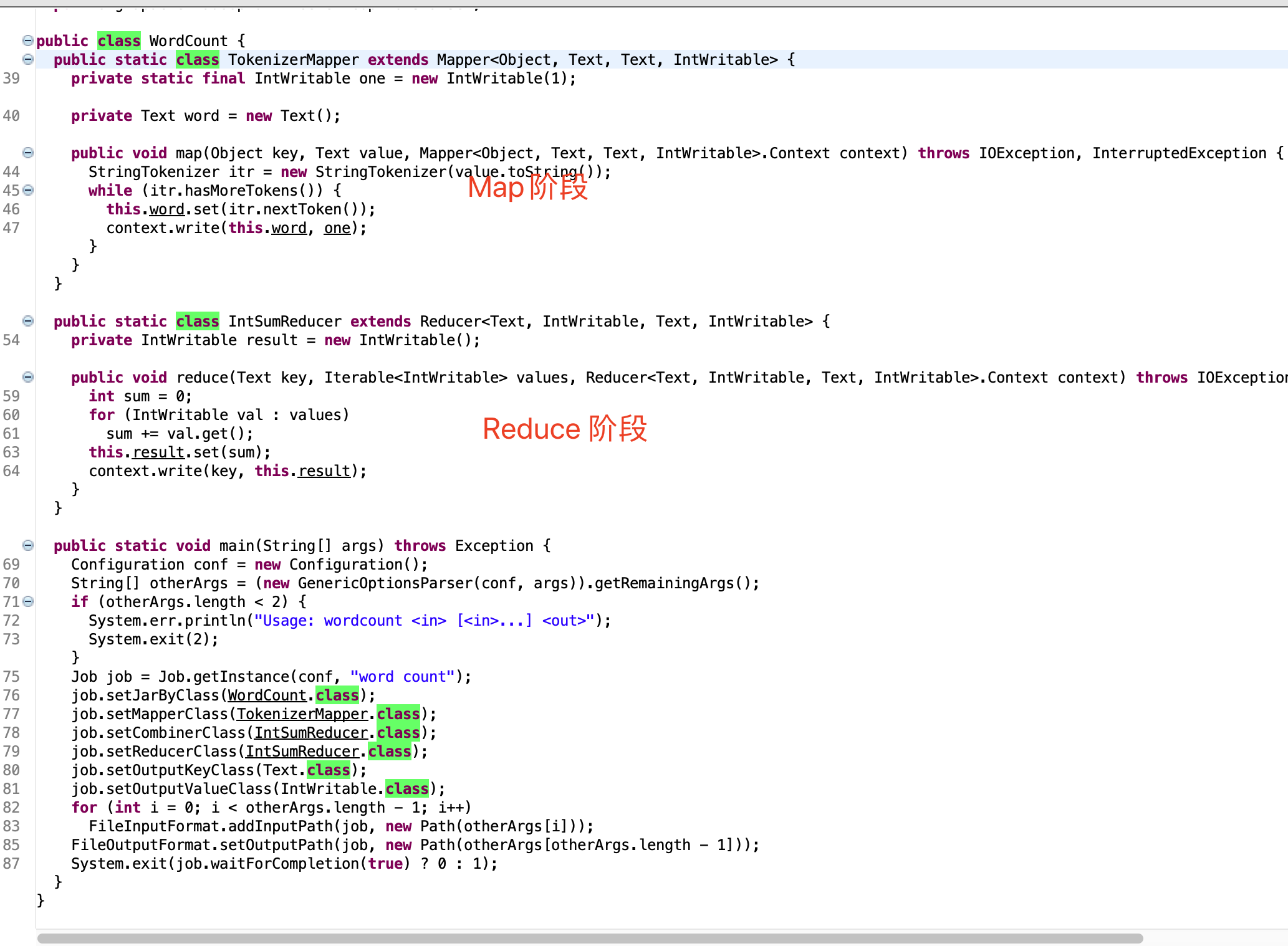
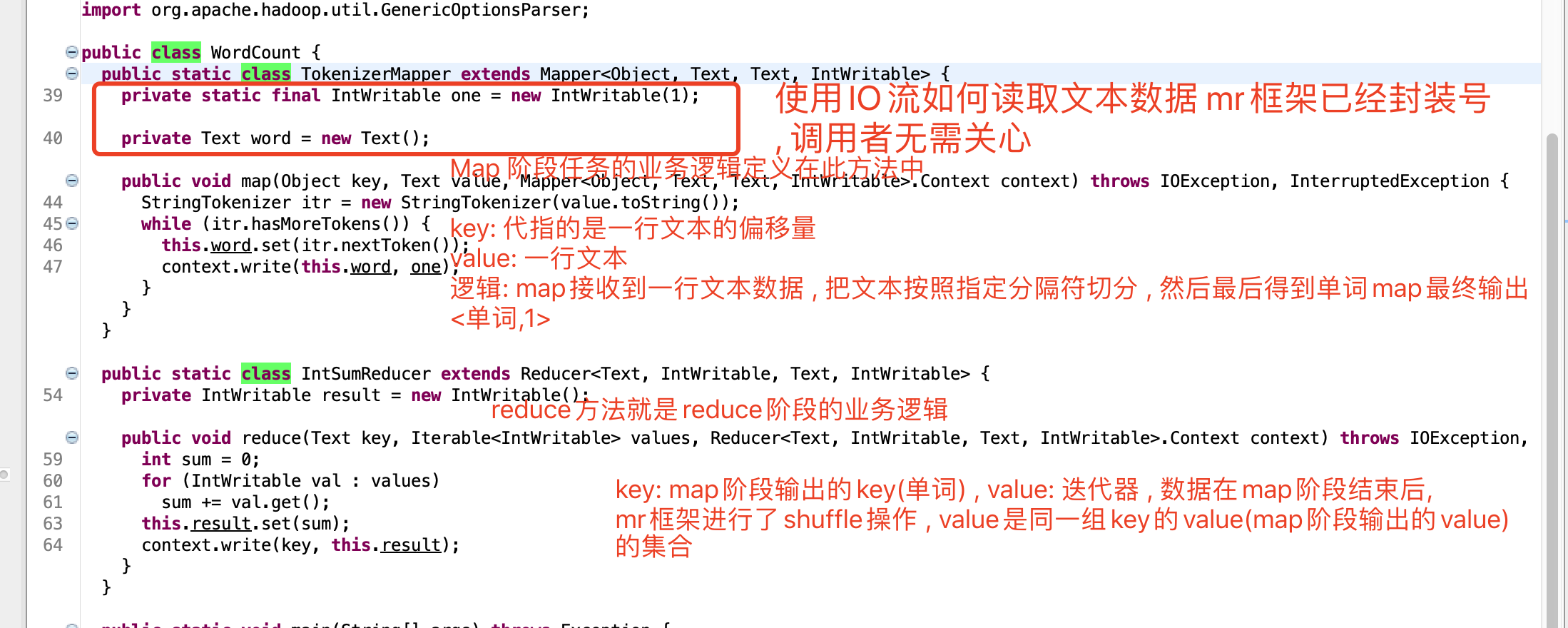

经过查看分析官方WordCount案例源码我们发现一个统计单词数量的MapReduce程序的代码由三个部分组成.
- Mapper类
- Reducer类
- 运行作业的代码(Driver)
Mapper类继承了org.apache.hadoop.mapreduce.Mapper类重写了其中的map方法, Reducer类继承了org.apache.hadoop.mapreduce.Reducer类重写了其中的reduce方法
重写的Map方法作用: map方法其中的逻辑就是用户希望mr程序map阶段如何处理的逻辑;
重写的Reduce方法作用: reduce方法其中的逻辑是用户希望mr程序reduce阶段如何处理的逻辑
1.Hadoop序列化
为什么进行序列化?
序列化主要是我们网络通信传输数据时,或者把对象持久化到文件 , 需要把对象序列化二进制的结构
观察源码时发现自定义Mapper类与自定义Reducer类都有泛型类型约束 , 比如自定义Mapper有四个形参, 但是形参类型不是常见的Java基本类型.
为什么Hadoop要选择建立自己的序列化格式而使用Java自带的serializable?
- 序列化分布式程序中非常重要,在hadoop中,集群中多个节点的进程间的通信是通过RPC(远程过程调用 Renote Procedurce Call)实现; RPC将消息序列化成二进制流发送到远程节点, 远程过程节点再将接收到的二进制数据反序列化为原始的消息 , 因此RPC往往追求一下特点:
- 紧凑: 数据更加紧凑 , 能充分利用网络带宽资源
- 快速: 序列化和反序列化的性能开销更低
- Hadoop使用的是自己的序列化格式Writable. 它比Java的序列化Serialzation更加紧凑速度快, 一个对象使用Serialzation序列化之后 , 会携带很多额外信息比如校验信息 , Header, 继承体系等等
Java包装类型与Hadoop常用序列化类型
| Java包装类型 | Hadoop Writable 类型 |
|---|---|
| Boolean | BooleanWritable |
| Byte | ByteWritable |
| Integer | IntWritable |
| Long | LongWritable |
| Double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
| Float | FloatWritable |
3.MapReduce编程规范以及示例编写
1.MapReduce 编程规范以及示例编写
- 用户自定义一个Mapper类继承Hadoop的Mapper类
- Mapper的输入数据是KV对的形式(类型可以自定义)
- Map阶段的业务逻辑定义在map()方法中
- Mapper的输出数据是KV对的形式(类型可以自定义)
2.Reducer类
- 用户自定义Reducer类要继承Hadoop的Reducer类
- Reducer的输入数据类型对应Mapper的输出数据类型(KV对)
- Reducer的业务逻辑写在reduce()方法中
- Reduce()方法是对相同K的一组KV对调用执行一次
3.Driver阶段
创建提交YARN集群运行的Job对象 , 其中封装了MapReduce程序运行所需要的相关参数输入数据路径,输出数据路径等, 也相当于是一个YARN集群的客户端 , 主要作用就是提交我们的MapReduce程序运行
4.代码实现
1.需求
在给定的文本文件中统计输出每一个单词出现的总次数
输入数据: wc.txt
输出:
apache 2clickhouse 2mapreduce 1spark 2xiaoming 1
2.实现方案
1.整体思路梳理
Map阶段:
- map()方法中把传入的数据转成String类型
- 根据空格切分出单词
- 输出<单词,1>
Reduce阶段:
- 汇总各个key(单词)的个数, 遍历value数据进行累加
- 输出key的总数
Driver
- 获取配置文件对象, 获取job对象实例
- 指定程序jar的本地路径
- 指定mapper/reducer类
- 指定Mapper终输出的kv数据类型
- 指定最终输出的kv数据类型
- 指定Job处理的原始数据路径
- 指定Job输出结果路径
- 提交作业
2.编写Mapper类
```java package com.anda.hadoop.mapper;
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
- @author anda
@since 1.0 */ public class WordCountMapper extends Mapper
Text k = new Text(); IntWritable v = new IntWritable(1);
@Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1. 获取第一行String line = value.toString();// 2. 切割String[] words = line.split(" ");// 3. 输出for (String word : words) {k.set(word);context.write(k, v);}}
}
<a name="lSfyu"></a>#### 3.编写Reducer```javapackage com.anda.hadoop.mapper;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** @author anda* @since 1.0*/public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {int sum;IntWritable v = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {// 1. 累加求和sum = 0;for (IntWritable count : values) {sum += count.get();}// 2. 输出v.set(sum);context.write(key, v);}}
4.Driver 驱动类
package com.anda.hadoop.mapper;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;/*** @author anda* @since 1.0*/public class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {// 1. 获取配置信息以及封装任务Configuration configuration = new Configuration();Job job = Job.getInstance(configuration);// 2. 设置jar加载路径job.setJarByClass(WordCountDriver.class);// 3. 设置map和reduce类job.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);// 4. 设置map输出job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// 5. 设置最终输出kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));// 7. 提交boolean b = job.waitForCompletion(true);System.exit(b ? 0 : 1);}}
5.运行任务
- 本地模式
- 直接IDEA中运行驱动类集合
- idea中需要传入参数即可

运行结束 , 到输出路径查看结果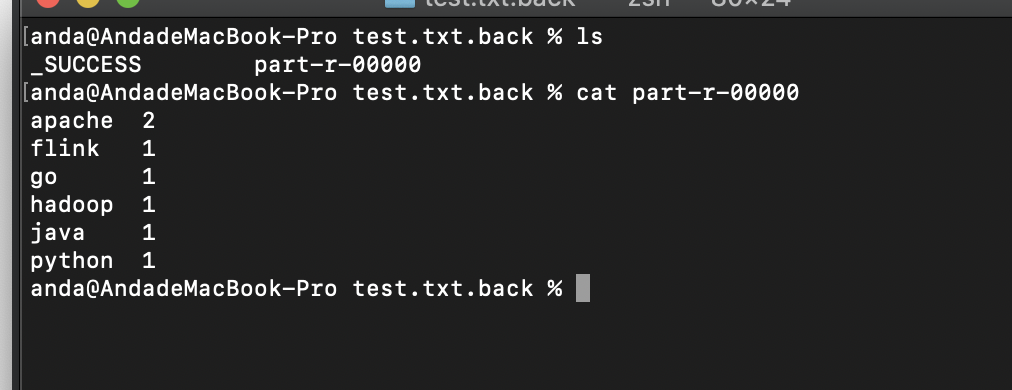
注意本地idea运行mr任务与集群没有任何关系, 没有提交任务到yarn集群 , 是在本地使用多线程方式模拟的mr的运行
- Yarn集群模式
- 把程序打成jar包 , 上传到Hadoop集群 , 选择合适的jar包
准备原始数据文件上传到HDFS的路径 , 不能是本地路径 , 因为跨节点运行无法获取数据!!
- 启动Hadoop集群(Hdfs, Yarn)
- 使用haddoop命令提交任务
$ hadoop jar anda-hadoop-1.0.0.jar com.anda.hadoop.mapper.WordCountDriver /user/anda/test/input /user/anda/test/back
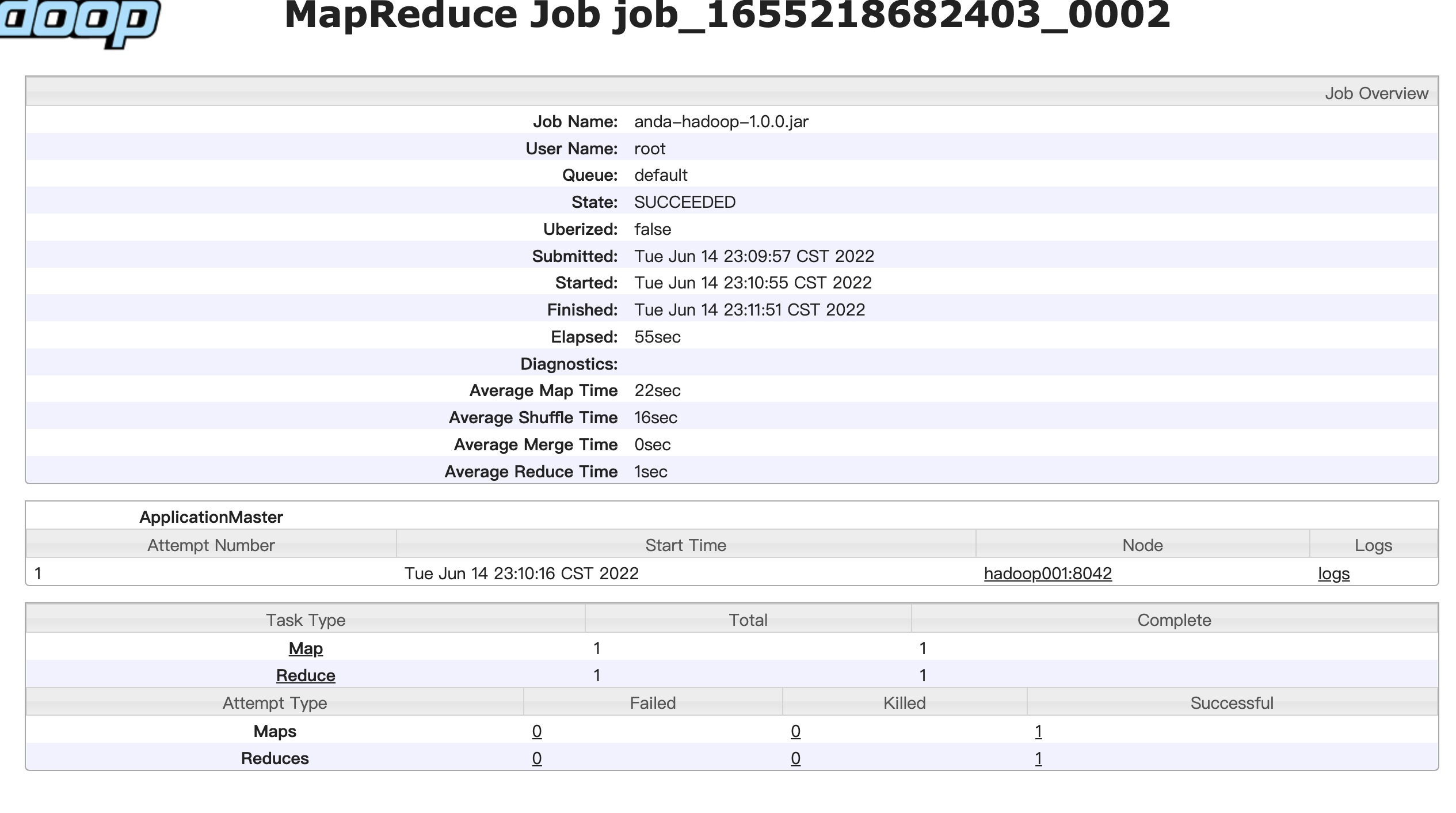
执行成功4.序列化Writable接口
基本序列化类型往往不能满足所有需求 , 比如在Hadoop框架内部传递一个自定义bean对象 , 那么该对象需要实现Writable序列化接口.1.实现Writable序列化步骤如下
- 必须实现Writable接口
反序列化时, 需要反射调用空参构造函数 , 所以必须有空参构造
public CostomBean(){}
重写序列化方法
@Overridepublic void write(DataOutput out)throws Exception{}
重写反序列化方法
@Overridepublic void readFields(DataInput in)throws IOException{}
反序列化的字段顺序和序列化字段必须完全一致
- 方便展示结果数据 , 需要重写bean对象 的toString()方法, 可以自定义分隔符
- 如果自定义Bean对象需要放在mapper输出KV中的K,则该对象还需要实现Comparable接口, 因为MapReduce框中的Suffle 过程要求对key必须能排序
2.Writable接口案例
需求 统计每台智能音箱设备内容播放时长 , 原始日志格式
001 001577c3 kar_890809 120.192.100.99 1116 954 200日志Id 设备Id appkey 网络IP 自有内容时长 第三方内容时长 网络状态码
1.编写MapReduce程序
创建SpeakBean对象 ```java package com.anda.hadoop.writable;
import org.apache.hadoop.io.Writable;
import java.io.DataInput; import java.io.DataOutput; import java.io.IOException;
/**
- @author anda
@since 1.0 */ // 1. 实现writable接口 public class SpeakBean implements Writable {
private Long selfDuration; private Long thirdPartDuration; private Long sumDuration;
// 2.反序列化时 , 需要反射调用空参构造函数 , 所以必须有 public SpeakBean() {
}
public SpeakBean(Long selfDuration, Long thirdPartDuration) {
this.selfDuration = selfDuration;this.thirdPartDuration = thirdPartDuration;this.sumDuration = this.selfDuration + this.thirdPartDuration;
}
// 3.写序列化方法 @Override public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(selfDuration);dataOutput.writeLong(thirdPartDuration);dataOutput.writeLong(sumDuration);
}
// 4. 反序列化方法 // 5. 反序列化方法读顺序必须和写序列化方法的写顺序必须一致 @Override public void readFields(DataInput dataInput) throws IOException {
this.selfDuration = dataInput.readLong();this.thirdPartDuration = dataInput.readLong();this.sumDuration = dataInput.readLong();
}
public Long getSelfDuration() {
return selfDuration;
}
public void setSelfDuration(Long selfDuration) {
this.selfDuration = selfDuration;
}
public Long getThirdPartDuration() {
return thirdPartDuration;
}
public void setThirdPartDuration(Long thirdPartDuration) {
this.thirdPartDuration = thirdPartDuration;
}
public Long getSumDuration() {
return sumDuration;
}
public void setSumDuration(Long sumDuration) {
this.sumDuration = sumDuration;
}
public void set(Long selfDuration, Long thirdPartDuration) {
this.selfDuration = selfDuration;this.thirdPartDuration = thirdPartDuration;this.sumDuration = this.selfDuration + this.thirdPartDuration;
}
// 6. 编写toString方法, 方便后续打印 @Override public String toString() {
return "SpeakBean{" +"selfDuration=" + selfDuration +", thirdPartDuration=" + thirdPartDuration +", sumDuration=" + sumDuration +'}';
} }
2. 编写Mapper类```javapackage com.anda.hadoop.writable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** @author anda* @since 1.0*/public class SpeakDurationMapper extends Mapper<LongWritable, Text, Text, SpeakBean> {SpeakBean v = new SpeakBean();Text text = new Text();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 1. 获取一行String line = value.toString();// 2. 切割字段String[] files = line.split(" ");// 3.封装对象 取出设备IdString deviceId = files[1];long selfDuration = Long.parseLong(files[files.length - 3]);long thirdPartDuration = Long.parseLong(files[files.length - 2]);text.set(deviceId);v.set(selfDuration, thirdPartDuration);// 4.写出context.write(text, v);}}
- 编写Reducer ```java package com.anda.hadoop.writable;
import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
- @author anda
@since 1.0 */ public class SpeakDurationReducer extends Reducer
@Override protected void reduce(Text key, Iterable
values, Context context) throws IOException, InterruptedException { long selfDuration = 0;long thirdPartDuration = 0;// 1. 遍历所有bean, 将其中的自有 , 第三方时长分别累加for (SpeakBean value : values) {selfDuration += value.getSelfDuration();thirdPartDuration += value.getThirdPartDuration();}SpeakBean speakBean = new SpeakBean(selfDuration, thirdPartDuration);context.write(key, speakBean);
} }
4. 编写驱动```javapackage com.anda.hadoop.writable;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;/*** @author anda* @since 1.0*/public class SpeakerDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {args = new String[]{"/Users/anda/Desktop/test.txt.bak", "/Users/anda/Desktop/test.txt.dir"};// 1.获取配置信息 , 或者job对象实例Configuration configuration = new Configuration();Job job = Job.getInstance(configuration);// 2. 指定本程序的jar包所在的本地路径job.setJarByClass(SpeakerDriver.class);// 3. 指定本业务job要使用的mapper/reducer业务类job.setMapperClass(SpeakDurationMapper.class);job.setReducerClass(SpeakDurationReducer.class);// 4. 指定mapper输出数据的kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(SpeakBean.class);// 5.指定最终输出的数据的kv类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(SpeakBean.class);// 6.指定job的输出原始文件所在目录FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));// 7.boolean b = job.waitForCompletion(true);System.exit(b ? 0 : 1);}}
mr 编程技巧总结
- 结合业务设计map输出的key和value, 尽量用key相同则取往同一个reduce的特点
- map()方法中获取到只是一行文本数据 , 尽量不做聚合运算
- reduce()方法的参数要清楚含义
5.MapReduce原理分析
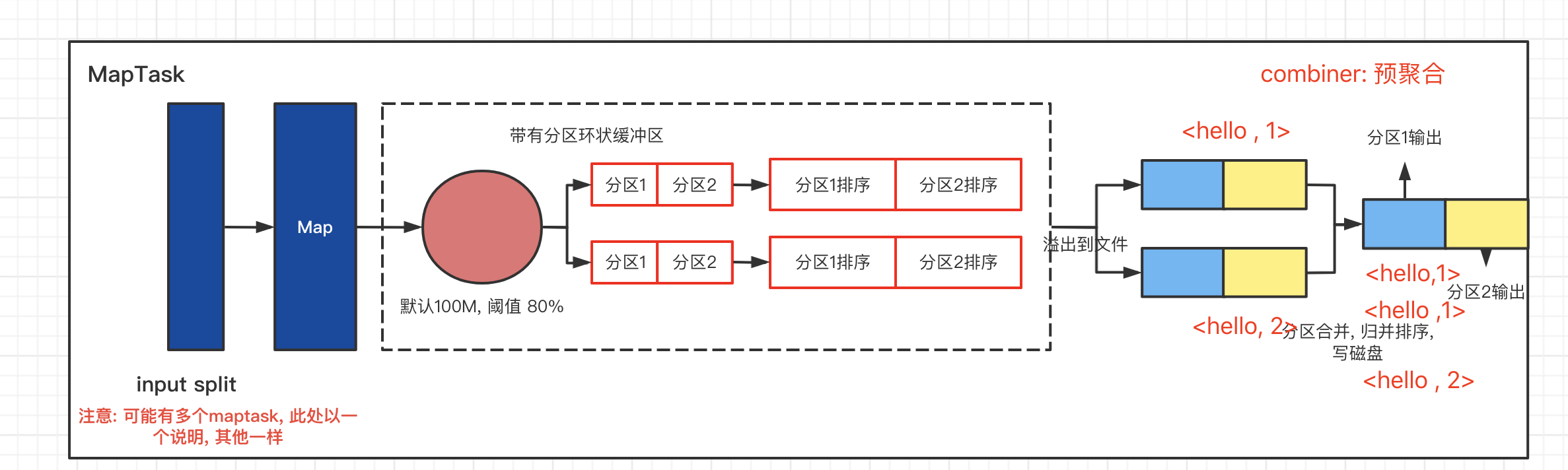
1.MapTask运行机制详解
MapTask流程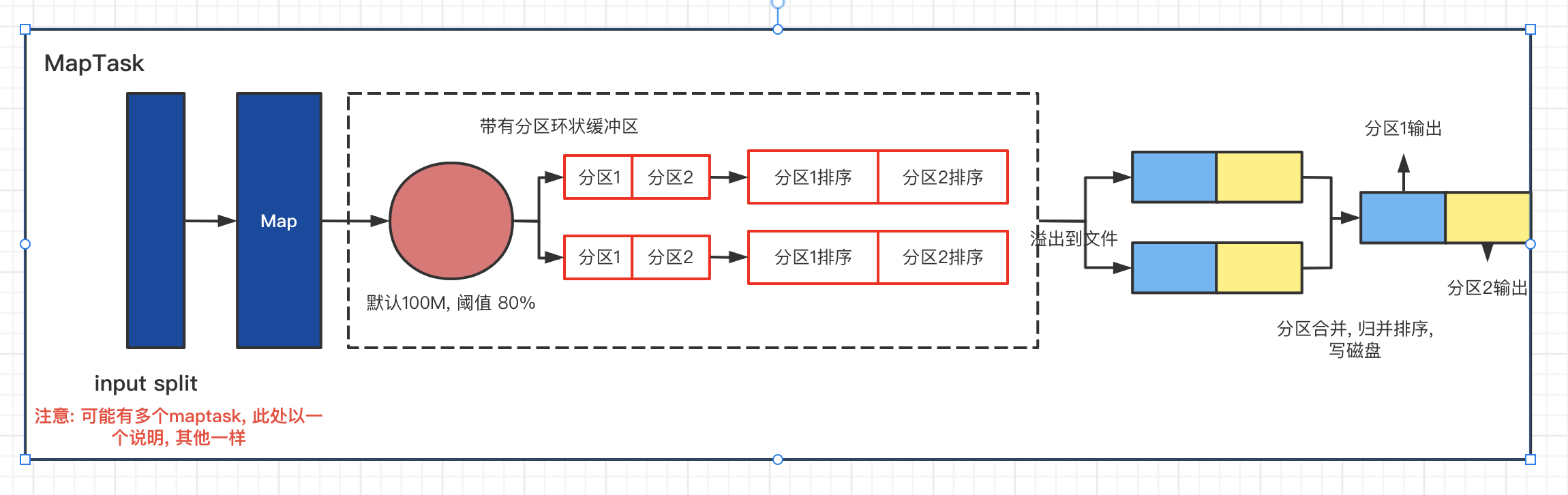
详细步骤:
- 首先 , 读取数据组件InputFormat(默认 TextInputFormat)会通过gitSplit方法对输入目录中文件进行逻辑切分规划得到splits,有多少个split就对应启用多少个MapTask, split与block的对应关系默认是1对1.
- 将输入文件切分为splits之后 , 由RecordReader对象(默认LineRecordReader), 进行读取 , 以\n作为分隔符 , 读取一行数据 , 返回
- 读取split返回
- map逻辑完之后 , 将map的每条结果通过context.write进行collect数据收集 , 在collect中, 会先对其进行分区处理 , 默认使用HashPartitioner
MapReduce提供Partitioner接口 , 他的作用就是根据key或value以及reduce的数量来决定当前的这对输出数据最终应该交给由那个reduce task处理 , 默认对key hash后再以reduce数量取模, 默认的取模方式只是为了平均reduce的处理能力 , 如果用户对自己的Partitioner有需求 , 可以定制并设置到job上.
- 接下来, 会将数据写入内存 , 内存中这片区域叫做环形缓冲区, 缓冲区的作用是批量收集map结果 , 减少磁盘IO的影响, 我们的key/value对以及Partition结果都会被写入缓冲区 , 当然吸入之前 , key与value值都会被序列化字节数组
- 环形缓冲区其实是一个数组 , 数组中存放着key, value的序列化数据和key,value的元数据信息, 包括partition , key的起始位置 , value的起始位置 , 以及value的长度 , 环形结构是一个抽象概念.
- 缓冲区是有大小限制 , 默认是100MB, 当map task的输出结果很多时, 就可能撑爆内存, 所以需要在一定条件下缓冲区中的数据临时写入磁盘 , 然后重新利用这一块缓冲区 , 这个内存往磁盘写数据的过程中称为Spill , 中文可译为溢写 , 这个溢出是由单独线程来完成, 不影响往缓冲区写map结果的线程. 溢写线程启动时不应该阻止map的结果输出 , 所以整个缓冲区有个溢写的比例spill.percent, 这个比例默认是0.8. 溢写线程启动 , 锁定这80MB的内存 , 执行溢写过程. MapTask的输出结果还可以以往剩下的20MB内存中写, 互不影响.
- 当溢写线程启动后 , 需要对这80MB空间内的key做排序(sort),排序是MapReduce 模型默认的行为!
- 如果job设置过Combiner, 那么现在就是使用Combiner的时候了 , 将有相同key的key/value对的value加起来, 减少溢写到磁盘的数据量.Combiner会优化MapReduce的中间结果 , 所以它在整个模型中会多次使用
- 哪些场景才能使用Combiner呢? 从这里分析,Combiner的输出是Reducer的输出 , Combiner决不能改变最终的计算结果场景, 比如,最大值,Combiner的使用一定得慎重, 如果用好, 它对job执行效率有帮助 , 反之会影响reduce的最终结果
- 合并溢写文件: 每次溢写在磁盘上生成一个临时文件(写之前判断是否有combiner), 如果map的输出结果很大, 很多次这样的溢写发生, 磁盘上相应的就会有多个临时文件存在, 当整个数据处理结束之后开始对磁盘中的临时文件进行merge合并, 因为最终的文件只有一个, 写入磁盘 , 并且为这个文件提供了索引文件, 以记录每个reduce对应数据的偏移量
MapTask的一些配置
| mapreduce.task.io.sort.factor | 10 |
|---|---|
| mapreduce.task.io.sort.mb | 100 |
| mapreduce.map.sort.spill.percent | 0.80 |
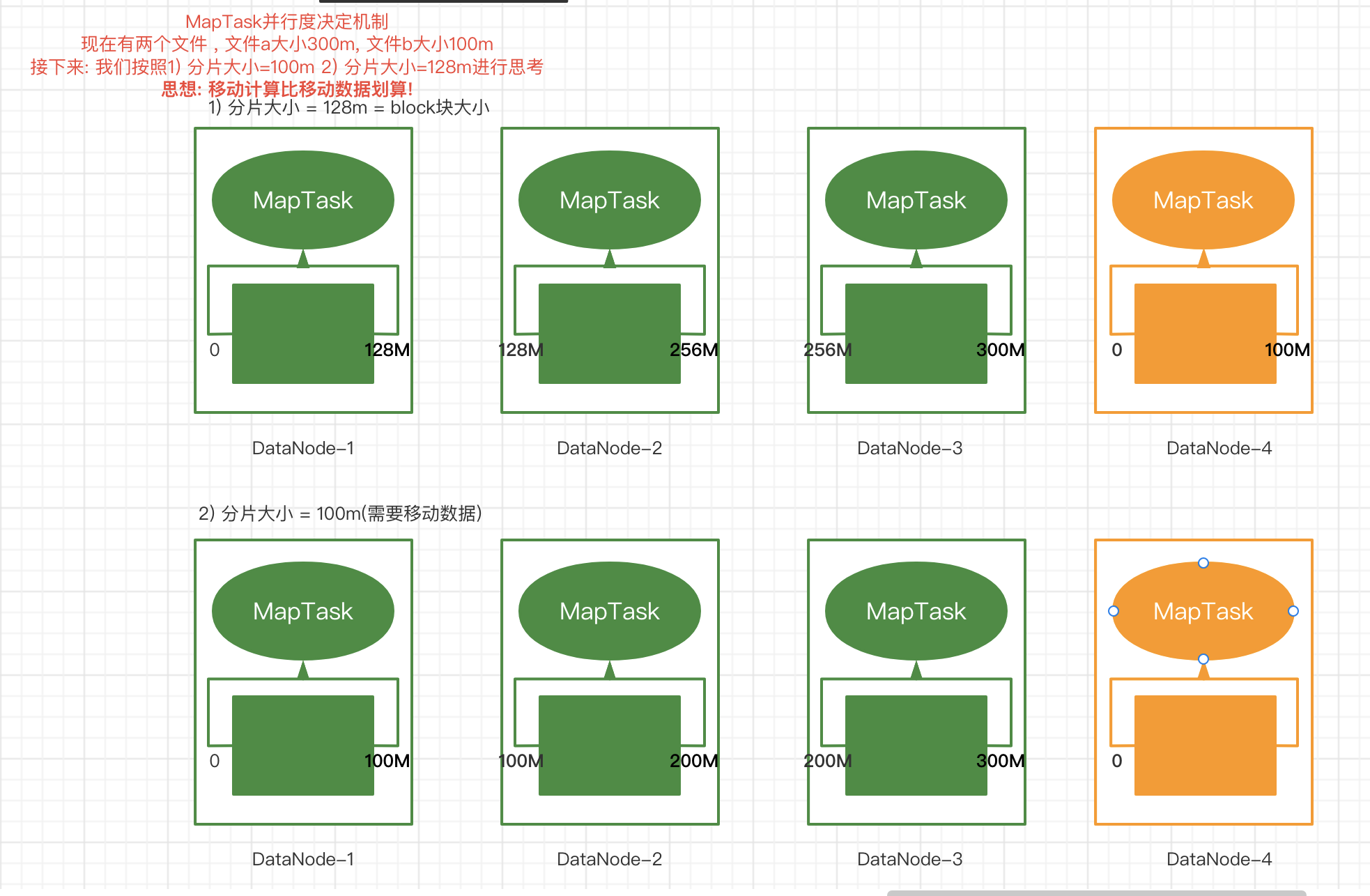
2.MapTask的并行度
- MapTask并行度思考
- MapTask并行度决定机制
数据块: Block是HDFS物理上把数据分成一块一块.
切分: 数据切分只是逻辑上对输入进行分片 , 并不会在磁盘上将其切分成片存储
1.切片机制源码阅读
3.ReduceTask工作机制
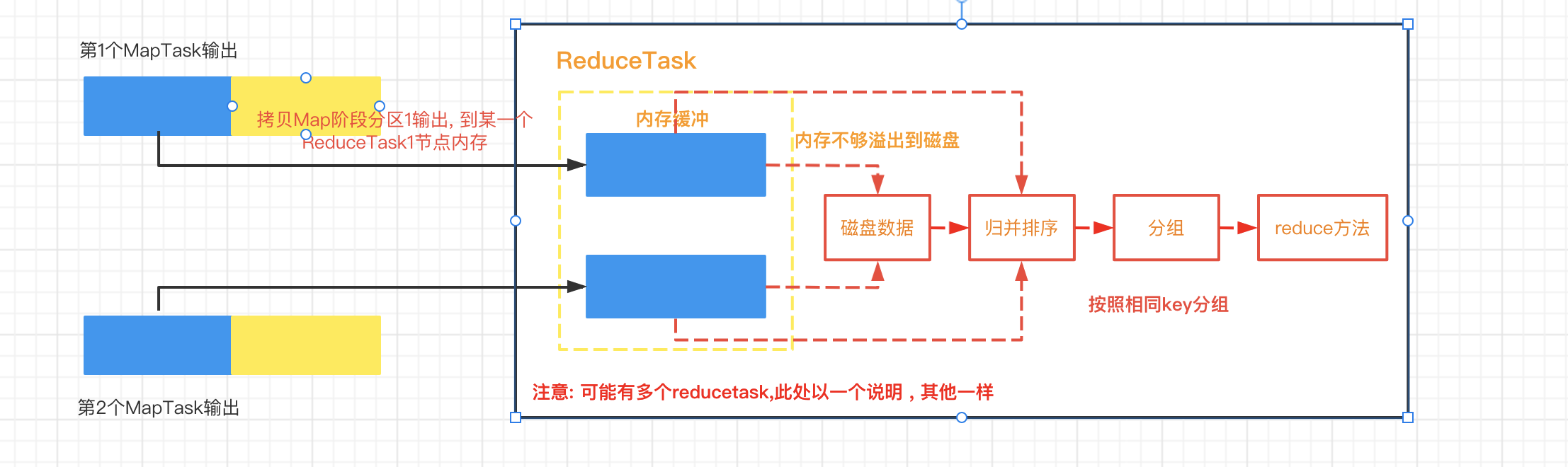
Reduce 大致分为copy , sort , reduce 三个阶段,重点在前两个阶段, copy阶段会包含一个eventFetcher来获取已完成的map列表, 由Fetcher线程去copy数据. 在此过程中会启动两个merge线程, 分别是inMemoryMerger和onDiskMerger , 分别将内存中的数据 merge到磁盘和将磁盘中的数据进行merge, 待数据copy完成之后 , copy阶段就开发完成了 , 开始进行sort阶段,sort阶段主要是执行finalMerge , 纯粹的sort阶段 , 完成之后就是reduce阶段 , 调用用户定义的reduce函数进行处理.
详细步骤:
- Copy阶段, 简单地拉取数据 , Reduce进程启动一些数据copy线程Fetcher , 通过Http方式请求maptask获取自己的文件 ,
- merge阶段如map端的merge动作 , 只是数组中存放的是不同的map端copy来的数值 , copy过来的数据会先放入内存缓存区中, 这里的缓冲区大小要比map端的更为灵活, merge有三种形式: 内存到内存 ; 内存到磁盘 , 磁盘到磁盘. 默认情况下第一种形式不启用, 当内存中的数据量到达一定阈值 , 就启动内存到磁盘的merge, 与map端类似 , 这也是溢写的过程 , 这个过程中如果你设置有combiner, 也是会启动的, 然后启动第三种磁盘到磁盘merge方式生成最终的文件.
- 合并排序,把分散的数据合并成一个大的数据后 , 还会对合并后的数据排序.
- 对排序后的键值对调用reduce方法 , 键相等的键值对调用一次reduce方法, 每次调用会产生零个或者多个键值对 , 最后把这些输出的键值对写入的HDFS文件中.
4.Reduce Task并行度
ReduceTask的并行度同样影响整个job的执行并发度和执行效率 , 但与Maptask的并发数由切片数决定不同, ReduceTask数量的决定是可以直接动手设置:
注意事项// 默认值是1 , 手动设置值为4job.setNumReduceTasks(4)
- ReduceTask=0 , 表示没有Reduce阶段 , 输出文件数和MapTask数量保持一致;
- ReduceTask数量不设置默认就是一个 , 输出文件数量为1个
-
5.Suffle机制
map阶段处理的数据如何传递给reduce阶段 , 是MapReduce框架中最关键的一个流程 , 这个流程就叫shuffle.
shuffle: 洗牌, 发牌—(核心机制 , 数据分区, 排序 , 分组 , combine , 合并等过程)
MapReduce Shuffle机制
MapTask的map方法之后 , ReduceTask的redcue方法之前的数据处理过程称之为Shuffle
会按照key进行分区, 默认分区规则是key的hashcode值%numreducetasks1.MapReduce的分区与reduceTask的数量
在MapReduce中, 通过我们指定分区 , 会将同一个分区的数据发送到同一个reduce当中进行处理(默认是key相同去往同一个分区), 列如我们为了数据的统计 , 我们可以把一批类似的数据发送到同一个reduce当中去,在同一个reduce当中统计相同类型的数据
如果保证相同的key的数据去往同一个reduce呢?只需要保证相同key的数据分发到同一个分区即可 , 结合以上原理分析我们知道MR程序shuffle机制默认就是这种规则1.分区源码
MR程序默认使用的HashPartitioner, 保证了相同的key去往同一个分区!!!

2.自定义分区
实际生产中需求变化多端 , 默认分区规则往往不能满足需求 , 需要结合业务逻辑来灵活控制分区规则以及分区数量!!!
如何定制自己需要的分区规则
具体步骤 自定义类继承Partitioner , 重写getPartition方法
- 在Driver驱动中 , 指定使用自定义Partitioner
- 在Driver驱动中 , 要根据自定义Partitioner的逻辑设置相应数量的ReduceTask数量
需求 , 按照不同的appkey把记录输出到不同的分区中
原始日志格式
0001 A a_001 192.168.10.101 11 11 2000002 B a_001 192.168.10.102 11 11 2000003 C a_001 192.168.10.103 11 11 2000004 D a_001 192.168.10.104 11 11 2000004 E a_001 192.168.10.105 11 11 2000005 F b_002 192.168.10.106 11 11 2000006 G b_002 192.168.10.107 11 11 2000007 H b_002 192.168.10.108 11 11 2000008 I b_002 192.168.10.109 11 11 2000009 M b_002 192.168.10.100 11 11 200
输出结果
根据appKey把不同厂商的日志数据分别输出到不同的文件中
需求分析
面对业务需求 , 结合mr的特点 , 来设计map输出的kv, 以及reduce的kv数据
一个ReduceTask对应一个输出的文件 , 因为在shuffle机制 , 中每个reduceTask拉取的都是某个分区的数据, 分区对应一个输出文件 ,
结合appkey的前缀相同的特点 , 同时不能使用默认分区规则 , 而是使用自定义分区器, 只要appkey前缀同则数据进入同一个分区
整体思路:
Mapper
- 读取一行文本, 按照制表符切分
- 解析出appkey字段, 其余数据封装为PartitionBean对象 , (实现序列化Writable接口)
- 设计map()输出的kv, key—->appkey(依靠该字段完成分区),PartitionBean对象作为Value输出
Partition
自定义分区器, 实现按照appkey字段前缀来区分所属分区
Reduce
- reduce()正常输出即可 , 无需进行聚合操作
Driver
- 在原先设置job属性的同时增加设置使用自定义分区器
- 注意设置reducetask的数量(与分区数量保持一致)
PartitionBean
package com.anda.hadoop.shuffie;import org.apache.hadoop.io.Writable;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;/*** 0001 A a_001 192.168.10.101 11 11 200** @author anda* @since 1.0*/public class PartitionBean implements Writable {private String code;private String codeName;private String appKey;private String addressIp;private String timeDuration;private String thirdPartDuration;private String status;@Overridepublic void write(DataOutput dataOutput) throws IOException {dataOutput.writeUTF(code);dataOutput.writeUTF(codeName);dataOutput.writeUTF(appKey);dataOutput.writeUTF(addressIp);dataOutput.writeUTF(timeDuration);dataOutput.writeUTF(thirdPartDuration);dataOutput.writeUTF(status);}@Overridepublic void readFields(DataInput dataInput) throws IOException {this.code = dataInput.readUTF();this.codeName = dataInput.readUTF();this.appKey = dataInput.readUTF();this.addressIp = dataInput.readUTF();this.timeDuration = dataInput.readUTF();this.thirdPartDuration = dataInput.readUTF();this.status = dataInput.readUTF();}public PartitionBean() {}public PartitionBean(String code, String codeName, String appKey, String addressIp, String timeDuration, String thirdPartDuration, String status) {this.code = code;this.codeName = codeName;this.appKey = appKey;this.addressIp = addressIp;this.timeDuration = timeDuration;this.thirdPartDuration = thirdPartDuration;this.status = status;}@Overridepublic String toString() {return "PartitionBean{" +"code='" + code + '\'' +", codeName='" + codeName + '\'' +", appKey='" + appKey + '\'' +", addressIp='" + addressIp + '\'' +", timeDuration='" + timeDuration + '\'' +", thirdPartDuration='" + thirdPartDuration + '\'' +", status='" + status + '\'' +'}';}public String getCode() {return code;}public void setCode(String code) {this.code = code;}public String getCodeName() {return codeName;}public void setCodeName(String codeName) {this.codeName = codeName;}public String getAppKey() {return appKey;}public void setAppKey(String appKey) {this.appKey = appKey;}public String getAddressIp() {return addressIp;}public void setAddressIp(String addressIp) {this.addressIp = addressIp;}public String getTimeDuration() {return timeDuration;}public void setTimeDuration(String timeDuration) {this.timeDuration = timeDuration;}public String getThirdPartDuration() {return thirdPartDuration;}public void setThirdPartDuration(String thirdPartDuration) {this.thirdPartDuration = thirdPartDuration;}public String getStatus() {return status;}public void setStatus(String status) {this.status = status;}}
Mapper
package com.anda.hadoop.shuffie;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** @author anda* @since 1.0*/public class PartitionMapper extends Mapper<LongWritable, Text, Text, PartitionBean> {final PartitionBean partitionBean = new PartitionBean();final Text text = new Text();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {final String[] fields = value.toString().split(" ");final String appKey = fields[2];partitionBean.setCode(fields[0]);partitionBean.setCodeName(fields[1]);partitionBean.setAppKey(appKey);partitionBean.setAddressIp(fields[3]);partitionBean.setTimeDuration(fields[4]);partitionBean.setThirdPartDuration(fields[5]);partitionBean.setStatus(fields[6]);text.set(appKey);context.write(text, partitionBean);}}
CustomPartitioner
package com.anda.hadoop.shuffie;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Partitioner;/*** @author anda* @since 1.0*/public class CustomPartitioner extends Partitioner<Text, PartitionBean> {@Overridepublic int getPartition(Text text, PartitionBean partitionBean, int i) {final String keyApp = text.toString();if (keyApp.equals("a_001")) {return 1;}if (keyApp.equals("b_002")) {return 2;}return 0;}}
PartitionReducer
package com.anda.hadoop.shuffie;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** @author anda* @since 1.0*/public class PartitionReducer extends Reducer<Text, PartitionBean, NullWritable, PartitionBean> {@Overrideprotected void reduce(Text key, Iterable<PartitionBean> values, Context context) throws IOException, InterruptedException {for (PartitionBean value : values) {context.write(NullWritable.get(), value);}}}
PartitionDriver
�
package com.anda.hadoop.shuffie;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;/*** @author anda* @since 1.0*/public class PartitionDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {final Configuration configuration = new Configuration();final Job job = Job.getInstance(configuration);job.setJarByClass(PartitionDriver.class);job.setMapperClass(PartitionMapper.class);job.setReducerClass(PartitionReducer.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(PartitionBean.class);job.setOutputKeyClass(NullWritable.class);job.setOutputValueClass(PartitionBean.class);job.setPartitionerClass(CustomPartitioner.class);job.setNumReduceTasks(3);FileInputFormat.setInputPaths(job, new Path("/Users/anda/Desktop/text_dir/shuffle.txt"));//FileOutputFormat//FileOutputFormatFileOutputFormat.setOutputPath(job, new Path("/Users/anda/Desktop/text_dir/out_data"));final boolean flag = job.waitForCompletion(true);System.exit(flag ? 0 : 1);}}
总结:
- 自定义分区器最好保证分区数量与ReduceTask数量保持一致;
- 如果分区数量不止1 , 但是ReduceTask数量1 , 此时只会输出一个文件.
- 如果ReduceTask数量大于分区数量, 但是输出多个空文件
- 如果ReduceTask数量小于分区数量 , 有可能会报错
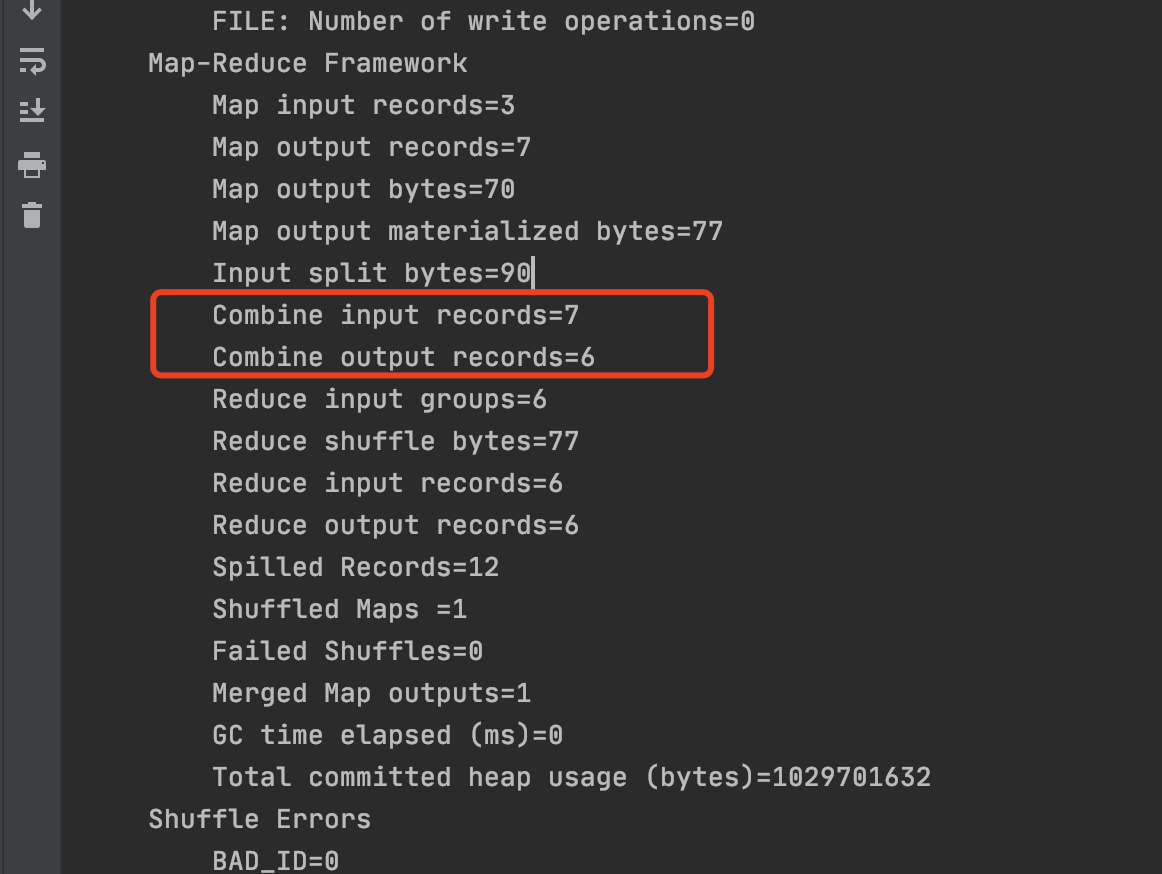
3.MapReduce 中的Combiner
- Combiner是MR程序中的mapper 和Reducer之外的一种组件
- Combiner组件的父类就是Reducer
- Combiner和Reducer的区别在于运行的位置
- Combiner是在每一个maptask所在的节点运行;
- Combiner的意义就是对每个maptask的输出进行局部汇总,以减少网络传输量
- Combiner能够应用的前提是不能影响最终的业务逻辑 , 此外 , Combiner的输出kv, 应该跟reducer的输入kv类型要对应起来.
举列说明
假设一个计算平均值的MR任务
Map阶段
2个MapTask
MapTask1输出数据: 10 / 5 / 15, 如果使用Combiner:(10+5+15)/3 = 10
MapTask2输出数据: 2 / 6 , 如果使用Combiner( 2 + 6 ) / 2 = 4
Reduce阶段汇总
(10+4)/2=7
而正确结果
(10+5+15+2+6)/5=7.6
- 自定义Combiner实现步骤
- 自定义一个Combiner继承Reducer, 重写Reduce方法
- 在驱动(Driver)设置使用Combiner(默认是不适用Combiner组件)
1.改造WordCount程序
package com.anda.hadoop.mapper;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** @author anda* @since 1.0*/public class WordCountCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {IntWritable total = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable value : values) {int i = value.get();sum += i;}total.set(sum);context.write(key, total);}}
<br />在驱动(Driver)设置使用Combiner
job.setCombinerClass(WordCountCombiner.class);

如果直接私用WordCountReducer作为Combiner使用是否可以 直接使用Reducer作为Combiner组件使用时可以的
6.MapReduce中的排序
排序是MapReduce框架中最重要的操作之一.
MapTask和ReduceTask均会堆数据按照key进行排序, 该操作属于Hadoop的默认行为, 任何应用程序中的数据均会被排序 , 不管逻辑上, 是否需要, 默认排序是按照字典顺序排序 , 且实现该排序的方法是快速排序
- MapTask
- 它会处理的结果暂时放到环形缓冲区中, 当环形缓冲区使用率达到一定阈值后 , 再对缓冲区中的数据进行一次快速排序 , 并将这些有序数据溢写到磁盘上
- ReduceTask当所有的数据拷贝完毕后 , ReduceTask统一堆内存上磁盘上的所有数据进行一次归并排序.
- 部分排序. MapReduce根据输入记录的键对数据集排序, 保证输出的每个文件内部有序
- 全排序. 最终输出结果只有一个文件, 且文件内部有序 , 实现方式是只设置一个ReduceTask . 但该方法在处理大型文件时效率极低, 因为一台机器处理所有文件 , 完全丧失MapReduce所提供的并行架构
- 辅助排序:(GroupingComparator分组): 在Reduce端堆key进行分组. 应用于: 接收的key为bean对象时 , 想让一个或几个字段相同(全部字段比较不相同)的key进入到同一个reduce方法时, 采用分组排序.
1.WritableComparable
Bean对象如果作为Map输出的key时, 需要实现WritableComparable接口并重写compareTo方法指定排序规则
全排序
基于统计的播放时长案例的输出结果对总时长进行排序
实现全局排序只能设置一个ReduceTask!!!
播放时长案例输出结果
需求分析00fdaf3 33180 33420 00fdaf3 6660000wersa4 30689 35191 00wersa4 658800a0fe2 43085 44254 0a0fe2 873390ad0s7 31702 29183 0ad0s7 608850sfs01 31883 29101 0sfs01 60984a00df6s 33239 36882 a00df6s 70121adfd00fd5 30727 31491 adfd00fd5 62218
如何设计map()方法输出的key,value
MR框架中shuffle阶段的排序是默认行为, 不管你是否都会进行排序.
key: 把所有字段封装成一个bean对象 , 并且指定bean对象作为key输出 , 如果作为key输出, 需要实现排序接口, 指定自己的排序规则;
具体步骤
Mapper
- 读取结果文件, 按照制表符进行切分
- 解析出相应字段封装为SpeakBean
- SpeakBean实现WritableComparable接口重写compareTo方法
- map()方法输出k,v; key—>SpeakBean, value—>NullWritable.get()
Reducer
- 循环遍历输出
Mapper代码
package com.anda.hadoop.sort;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** @author anda* @since 1.0*/public class SortMapper extends Mapper<LongWritable, Text, SpeakBeanSort, NullWritable> {Text k = new Text();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String[] fields = value.toString().split(" ");SpeakBeanSort speakBeanSort = new SpeakBeanSort(Long.parseLong(fields[1]),Long.parseLong(fields[2]),fields[0]);context.write(speakBeanSort, NullWritable.get());}}
Reducer 代码
package com.anda.hadoop.sort;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** @author anda* @since 1.0*/public class SortReducer extends Reducer<SpeakBeanSort, NullWritable, NullWritable, SpeakBeanSort> {@Overrideprotected void reduce(SpeakBeanSort key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {for (NullWritable value : values) {context.write(value, key);}}}
```javapackage com.anda.hadoop.sort;import org.apache.hadoop.io.WritableComparable;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;/*** @author anda* @since 1.0*/public class SpeakBeanSort implements WritableComparable<SpeakBeanSort> {// 定义属性private Long selfDuration; // 自有内容时长private Long thirdPartDuration; // 第三方内容时长private String deviceId; // 设备Idprivate Long sumDuration; // 总时长// 准备一个空参构造public SpeakBeanSort() {}public SpeakBeanSort(Long selfDuration, Long thirdPartDuration, String deviceId) {this.selfDuration = selfDuration;this.thirdPartDuration = thirdPartDuration;this.deviceId = deviceId;this.sumDuration = this.selfDuration + this.thirdPartDuration;}@Overridepublic void write(DataOutput dataOutput) throws IOException {dataOutput.writeLong(selfDuration);dataOutput.writeLong(thirdPartDuration);dataOutput.writeUTF(deviceId);dataOutput.writeLong(sumDuration);}@Overridepublic void readFields(DataInput dataInput) throws IOException {this.selfDuration = dataInput.readLong();this.thirdPartDuration = dataInput.readLong();this.deviceId = dataInput.readUTF();this.sumDuration = dataInput.readLong();}@Overridepublic String toString() {return "SpeakBeanSort{" +"selfDuration=" + selfDuration +", thirdPartDuration=" + thirdPartDuration +", deviceId='" + deviceId + '\'' +", sumDuration=" + sumDuration +'}';}public Long getSelfDuration() {return selfDuration;}public void setSelfDuration(Long selfDuration) {this.selfDuration = selfDuration;}public Long getThirdPartDuration() {return thirdPartDuration;}public void setThirdPartDuration(Long thirdPartDuration) {this.thirdPartDuration = thirdPartDuration;}public String getDeviceId() {return deviceId;}public void setDeviceId(String deviceId) {this.deviceId = deviceId;}public Long getSumDuration() {return sumDuration;}public void setSumDuration(Long sumDuration) {this.sumDuration = sumDuration;}@Overridepublic int compareTo(SpeakBeanSort o) {if (this.sumDuration > o.getSumDuration()) {return 1;} else if (this.sumDuration < o.getSumDuration()) {return -1;}return 0;}}
Driver代码
package com.anda.hadoop.sort;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;/*** @author anda* @since 1.0*/public class SortDriver {public static void main(String[] args) throws Exception {Configuration configuration = new Configuration();Job job = Job.getInstance(configuration);// 指定本程序的jar包所在的本地路径job.setJarByClass(SortDriver.class);// 指定本业务job要使用的mapper/reducer业务类job.setMapperClass(SortMapper.class);job.setReducerClass(SortReducer.class);// 指定mapper输出的数据kv类型job.setMapOutputKeyClass(SpeakBeanSort.class);job.setMapOutputValueClass(NullWritable.class);// 指定最终输出类型job.setOutputKeyClass(NullWritable.class);job.setOutputValueClass(SpeakBeanSort.class);job.setNumReduceTasks(1);// 指定job的输出原始文件位置所在目录FileInputFormat.setInputPaths(job, new Path("/Users/anda/Desktop/text_dir/sort.txt"));FileOutputFormat.setOutputPath(job, new Path("/Users/anda/Desktop/text_dir/sort_data"));boolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}}
2.GroupingComparator
GroupingComparator是mapreduce当中reduce端的一个功能组件 , 主要的作用是决定哪些数据作为一组, 调用一次reduce的逻辑 , 默认是每个不同的key, 作为多个不同的组 , 每个组调用一次reduce逻辑 , 我们可以自定义GroupingComparator实现不同的key作为同一个组 , 调用一次reduce逻辑.
- 需求
原始需求
Order_0000001 Pdt_01 222.8Order_0000001 Pdt_05 25.8Order_0000002 Pdt_03 522.8Order_0000002 Pdt_04 122.4Order_0000002 Pdt_05 722.4Order_0000003 Pdt_01 232.8
需要求出每一个订单中成交金额最大的一笔交易
- 实现思路
Mapper
- 读取一行文本数据 , 切分出每个字段;
- 订单Id和金额封装成一个Bean对象, Bean对象的排序规则指定为先按照订单Id排序 , 订单Id相等再按照金额降序排;
- map()方法输出kv,key—>bean对象 , value->NullWritable.get();
Shuffle
- 指定分区器 , 保证相同订单Id的数据去往同个分区(自定义分区器)
- 指定GroupingComparator, 分组规则指定只要订单Id相同则认为属于同一组;
Reduce
- 每个reduce()方法写出一组key的第一个
参考代码
- OrderBean
OrderBean定义两个字段 , 一个字段是orderId,第二个字段是金额(注意金额一定要使用Double或者DoubleWritable类型 , 否则没法按照金额顺序排序)
排序规则指定先按照订单Id排序 , 订单Id相等再按照金额降序排序!!
package com.anda.hadoop.group;import org.apache.hadoop.io.WritableComparable;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;/*** @author anda* @since 1.0*/public class OrderBean implements WritableComparable<OrderBean> {private String orderId;private Double price;public OrderBean(){}@Overridepublic int compareTo(OrderBean o) {int i = this.orderId.compareTo(o.orderId);if (i == 0) {return -this.price.compareTo(o.price);}return i;}@Overridepublic void write(DataOutput dataOutput) throws IOException {dataOutput.writeUTF(this.orderId);dataOutput.writeDouble(this.price);}@Overridepublic void readFields(DataInput dataInput) throws IOException {this.orderId = dataInput.readUTF();this.price = dataInput.readDouble();}public String getOrderId() {return orderId;}public void setOrderId(String orderId) {this.orderId = orderId;}public Double getPrice() {return price;}public void setPrice(Double price) {this.price = price;}@Overridepublic String toString() {return "OrderBean{" +"orderId='" + orderId + '\'' +", price=" + price +'}';}}
- 自定义分区器
保证ID相同的订单去往同个分区最终去往同一个Reduce中
package com.anda.hadoop.group;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.mapreduce.Partitioner;/*** @author anda* @since 1.0*/public class CustomPartitioner extends Partitioner<OrderBean, NullWritable> {@Overridepublic int getPartition(OrderBean orderBean, NullWritable nullWritable, int i) {// 自定义分区 , 将相同订单Id的数据发送到同一个reduce里面去return (orderBean.getOrderId().hashCode() & Integer.MAX_VALUE) % i;}}
- 自定义GroupingComparator
保证id相同的订单进入一个分组中, 进入分组的数据已经按照金额降序排序 , reduce()方法取出第一个即是金额最高的交易
package com.anda.hadoop.group;import org.apache.hadoop.io.WritableComparable;import org.apache.hadoop.io.WritableComparator;/*** @author anda* @since 1.0*/public class CustomGroupingComparator extends WritableComparator {public CustomGroupingComparator() {super(OrderBean.class, true);}@Overridepublic int compare(WritableComparable a, WritableComparable b) {OrderBean first = (OrderBean) a;OrderBean second = (OrderBean) b;final int i = first.getOrderId().compareTo(second.getOrderId());if (i == 0) {System.out.println(first.getOrderId() + "-----" + second.getOrderId());}return i;}}
- Mapper ```java package com.anda.hadoop.group;
import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
- @author anda
@since 1.0 */ public class GroupMapper extends Mapper
@Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 读取一行文本 , 然后切分final String[] fields = value.toString().split(" ");OrderBean orderBean = new OrderBean();orderBean.setOrderId(fields[0]);orderBean.setPrice(Double.parseDouble(fields[2]));context.write(orderBean, NullWritable.get());
} }
- Reducer```javapackage com.anda.hadoop.group;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** @author anda* @since 1.0*/public class GroupReducer extends Reducer<OrderBean, NullWritable, OrderBean, NullWritable> {@Overrideprotected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {context.write(key, NullWritable.get());}}
- Driver ```java package com.anda.hadoop.group;
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
- @author anda
@since 1.0 */ public class GroupDriver {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();Job job = Job.getInstance(configuration);job.setJarByClass(GroupDriver.class);job.setMapperClass(GroupMapper.class);job.setReducerClass(GroupReducer.class);job.setOutputKeyClass(OrderBean.class);job.setOutputValueClass(NullWritable.class);job.setMapOutputKeyClass(OrderBean.class);job.setMapOutputValueClass(NullWritable.class);FileInputFormat.setInputPaths(job, new Path("/Users/anda/Desktop/text_dir/group.txt"));FileOutputFormat.setOutputPath(job, new Path("/Users/anda/Desktop/text_dir/group_data"));job.setPartitionerClass(CustomPartitioner.class);//job.setGroupingComparatorClass(CustomGroupingComparator.class);job.setNumReduceTasks(3);boolean result = job.waitForCompletion(true);System.out.println(result ? 0 : 1);boolean b = job.waitForCompletion(true);System.out.println(b ? 0 : 1);
} }
<a name="dyr6l"></a>## 7. MapReduce Join实战<a name="Rxb1Q"></a>## 1.MR Reduce 端join<a name="rWeov"></a>### 1.需求分析- 需求投递行为数据表deliver_info:```latex1001 177725422 2020-01-031002 177725422 2020-01-041003 177725433 2020-01-03
职位表position:
177725422 产品经理 177725433 大数据开发工程师
假如数据量巨大 , 两表的数据是以文件的形式存储在HDFS中,需要用mapreduce程序来实现一下SQL查询运算
2.代码实现
通过将关联的条件作为map输出的key, 将两表满足join条件的数据并携带数据来源的文件信息 , 发往同一个reduce task , 在reduce中进行数据的串联.
Driver
package com.anda.hadoop.join_reduce;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;/*** @author anda* @since 1.0*/public class ReduceJoinDriver {public static void main(String[] args) throws Exception {// 1.获取配置文件对象, 获取job对象实例final Configuration configuration = new Configuration();final Job job = Job.getInstance(configuration);// 2.指定程序jar的本地路径job.setJarByClass(ReduceJoinDriver.class);// 3.指定mapper输出的kv数据类型job.setMapperClass(ReduceJoinMapper.class);job.setReducerClass(ReduceJoinReducer.class);// 4.指定Mapper输出的kv数据类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(DeliverBean.class);// 5.指定最终输出的kv数据类型job.setOutputKeyClass(DeliverBean.class);job.setOutputValueClass(NullWritable.class);// 6.指定job输入结果路径FileInputFormat.setInputPaths(job, new Path("/Users/anda/Desktop/text_dir/join_mapper_reduce"));// 7.指定job输出结果路径FileOutputFormat.setOutputPath(job, new Path("/Users/anda/Desktop/text_dir/join_mapper_reduce/out_join"));// 8.提交作业boolean flag = job.waitForCompletion(true);System.exit(flag ? 0 : 1);}}
Mapper
package com.anda.hadoop.join_reduce;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.lib.input.FileSplit;import java.io.IOException;/*** @author anda* @since 1.0*/public class ReduceJoinMapper extends Mapper<LongWritable, Text, Text, DeliverBean> {String fileName;DeliverBean deliverBean = new DeliverBean();Text text = new Text();@Overrideprotected void setup(Context context) throws IOException, InterruptedException {// 1.获取输入文件切片FileSplit fileSplit = (FileSplit) context.getInputSplit();// 2.获取输入文件名称fileName = fileSplit.getPath().getName();}@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 1.获取输入数据String line = value.toString();// 2.不同文件分别处理if (fileName.startsWith("deliver_info")) {// 2.1切割String[] fields = line.split(" ");// 2.2封装了bean对象deliverBean.setUserId(fields[0]);deliverBean.setPositionId(fields[1]);deliverBean.setDate(fields[2]);deliverBean.setPositionName("");deliverBean.setFlag("deliver");text.set(fields[1]);} else {// 2.3.切割String[] fields = line.split(" ");// 2.4封装bean对象deliverBean.setPositionId(fields[0]);deliverBean.setPositionName(fields[1]);deliverBean.setUserId("");deliverBean.setDate("");deliverBean.setFlag("position");text.set(fields[0]);}context.write(text, deliverBean);}}
Reducer
package com.anda.hadoop.join_reduce;import org.apache.commons.beanutils.BeanUtils;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;import java.util.ArrayList;/*** @author anda* @since 1.0*/public class ReduceJoinReducer extends Reducer<Text, DeliverBean, DeliverBean, NullWritable> {@Overrideprotected void reduce(Text key, Iterable<DeliverBean> values, Context context) throws IOException, InterruptedException {// 1.准备投递行为数据的集合ArrayList<DeliverBean> doBeans = new ArrayList<>();values.forEach(System.out::println);// 2.准备bean对象DeliverBean pBean = new DeliverBean();for (DeliverBean bean : values) {if ("deliver".equals(bean.getFlag())) {DeliverBean dBean = new DeliverBean();try {BeanUtils.copyProperties(dBean, bean);} catch (Exception e) {e.printStackTrace();}doBeans.add(dBean);} else {try {BeanUtils.copyProperties(pBean, bean);} catch (Exception e) {e.printStackTrace();}}}for (DeliverBean bean : doBeans) {bean.setPositionName(pBean.getPositionName());context.write(bean, NullWritable.get());}}}
Bean
package com.anda.hadoop.join_reduce;import com.google.common.base.Objects;import org.apache.hadoop.io.Writable;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;/*** @author anda* @since 1.0*/public class DeliverBean implements Writable {private String userId;private String positionId;private String date;private String positionName;private String flag;public DeliverBean() {}public DeliverBean(String userId, String positionId, String date, String positionName, String flag) {this.userId = userId;this.positionId = positionId;this.date = date;this.positionName = positionName;this.flag = flag;}@Overridepublic void write(DataOutput dataOutput) throws IOException {dataOutput.writeUTF(this.userId);dataOutput.writeUTF(this.positionId);dataOutput.writeUTF(this.date);dataOutput.writeUTF(this.positionName);dataOutput.writeUTF(this.flag);}@Overridepublic void readFields(DataInput dataInput) throws IOException {this.userId = dataInput.readUTF();this.positionId = dataInput.readUTF();this.date = dataInput.readUTF();this.positionName = dataInput.readUTF();this.flag = dataInput.readUTF();}@Overridepublic String toString() {return Objects.toStringHelper(this).add("userId", userId).add("positionId", positionId).add("date", date).add("positionName", positionName).add("flag", flag).toString();}public String getUserId() {return userId;}public void setUserId(String userId) {this.userId = userId;}public String getPositionId() {return positionId;}public void setPositionId(String positionId) {this.positionId = positionId;}public String getDate() {return date;}public void setDate(String date) {this.date = date;}public String getPositionName() {return positionName;}public void setPositionName(String positionName) {this.positionName = positionName;}public String getFlag() {return flag;}public void setFlag(String flag) {this.flag = flag;}}
2.MR Map端join
1.需求分析
使用与关联表有小表的情形;
可以将小表分发到所有的map节点, 这样map节点可以在本地对自己所读到的达表数据进行join并输出最终结果, 可以大大提高join操作的并发度 , 加快处理速度
2.代码实现
- 在Mapper的setup阶段, 将文件读取到缓存集合中
- 在驱动函数中加载缓存
// 缓存普通文件到Task运行节点
job.addCacheFile(new URI(“file:///Users/…”))
Dirver
package com.anda.hadoop.join_map;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.net.URI;/*** @author anda* @since 1.0*/public class MapDeliverBeanJoinDriver {public static void main(String[] args) throws Exception {Configuration configuration = new Configuration();Job job = Job.getInstance(configuration);job.setJarByClass(MapDeliverBeanJoinDriver.class);job.setMapperClass(MapDeliverBeanJoinMap.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);FileInputFormat.setInputPaths(job, new Path("/Users/anda/Desktop/text_dir/join_mapper_reduce/deliver_info.txt"));FileOutputFormat.setOutputPath(job, new Path("/Users/anda/Desktop/text_dir/join_mapper_reduce/map_join_out"));job.addCacheFile(new URI("file:///Users/anda/Desktop/text_dir/join_mapper_reduce/position_info.txt"));job.setNumReduceTasks(0);boolean flag = job.waitForCompletion(true);System.exit(flag ? 0 : 1);}}
Bean
package com.anda.hadoop.join_map;import com.google.common.base.Objects;import org.apache.hadoop.io.Writable;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;/*** @author anda* @since 1.0*/public class MapDeliverBean implements Writable {private String userId;private String positionId;private String date;private String positionName;private String flag;public MapDeliverBean() {}public MapDeliverBean(String userId, String positionId, String date, String positionName, String flag) {this.userId = userId;this.positionId = positionId;this.date = date;this.positionName = positionName;this.flag = flag;}@Overridepublic void write(DataOutput dataOutput) throws IOException {dataOutput.writeUTF(this.userId);dataOutput.writeUTF(this.positionId);dataOutput.writeUTF(this.date);dataOutput.writeUTF(this.positionName);dataOutput.writeUTF(this.flag);}@Overridepublic void readFields(DataInput dataInput) throws IOException {this.userId = dataInput.readUTF();this.positionId = dataInput.readUTF();this.date = dataInput.readUTF();this.positionName = dataInput.readUTF();this.flag = dataInput.readUTF();}@Overridepublic String toString() {return Objects.toStringHelper(this).add("userId", userId).add("positionId", positionId).add("date", date).add("positionName", positionName).add("flag", flag).toString();}}
Mapper
package com.anda.hadoop.join_map;import org.apache.commons.lang.StringUtils;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.BufferedReader;import java.io.FileInputStream;import java.io.IOException;import java.io.InputStreamReader;import java.nio.charset.StandardCharsets;import java.util.HashMap;import java.util.Map;/*** @author anda* @since 1.0*/public class MapDeliverBeanJoinMap extends Mapper<LongWritable, Text, Text, NullWritable> {Map<String, String> pMap = new HashMap();Text text = new Text();@Overrideprotected void setup(Context context) throws IOException, InterruptedException {// 1. 获取缓存文件BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("position_info.txt"), StandardCharsets.UTF_8));String line;while (StringUtils.isNotBlank(line = reader.readLine())) {// 2.切割String[] fields = line.split(" ");// 3.缓存数据pMap.put(fields[0], fields[1]);}// 4 关流reader.close();}@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 1.获取一行String line = value.toString();// 2.截取String[] fields = line.split(" ");// 3.获取职位idString pId = fields[1];// 4.获取职位名称String pName = pMap.get(pId);// 4.拼接text.set(line + " " + pName);// 5.写出context.write(text, NullWritable.get());}}
3.数据倾斜解决方案
什么是数据倾斜
- 数据倾斜无非就是大量的key被partition分配到同一个分区里,
- 绝大多数task执行都非常快 , 但个别task执行慢, 甚至慢
1.InputFormat
运行MapReduce程序时 , 输入的文件格式包括: 基于行的日志文件, 二进制格式文件 , 数据库表等, 那么正对于不同的数据类型 , MapReduce是如何读取这些数据的呢?
InputFormat是MapReduce框架用来读取数据的类.
InputFormat常见子类包括:
- TextInputFormat(普通文本文件, MR框架默认的读取实现类型)
- KeyValueTextInputFormat(读取一行文本数据按照指定分隔符 , 把数据封装为kv类型)
- NLineInputFormat(读取数据按照行数进行划分分片)
- CombineTextInputFormat(合并小文件,避免启动过多MapTask任务)
- 自定义InputFormat
- CombineTextInputFormat案例
MR框架默认的TextInputFormat切片机制按文件划分片 , 文件无论多小 , 都是一个单独的切片, 然后由一个MapTask处理 , 如果有大量小文件 , 就对应的会生成并启动大量的MapTask, 而每个MapTask处理的数据量很小大量时间浪费在初始化资源启动回收等阶段, 这种方式导致资源利用率不高.
CombineTextInputFormat用于小文件过多的场景, 他可以将多个小文件从逻辑上划分成一个切面, 这样多个小文件就可以交给MapTask处理, 提高资源利用率.
需求
将输入数据中的多个小文件合并为一个切片处理
- 运行WordCount案例 , 准备多个小文件
具体使用方式
// 设置mapreduce读取数据的类型 , 如果不设置InputFormat 它默认用的是TextInputFormat.classjob.setInputFormatClass(CombineTextInputFormat.class);// 设置虚拟存储切片的最大值设置4MCombineTextInputFormat.setMaxInputSplitSize(job, 1024 * 6 * 1024);
验证切片数量的变化
- CombineTextInputFormat切片原理
切片生成过程分为两部分, 虚拟存储过程和切片过程
假设设置setMaxInputSplitSize的值为6M
17个小文件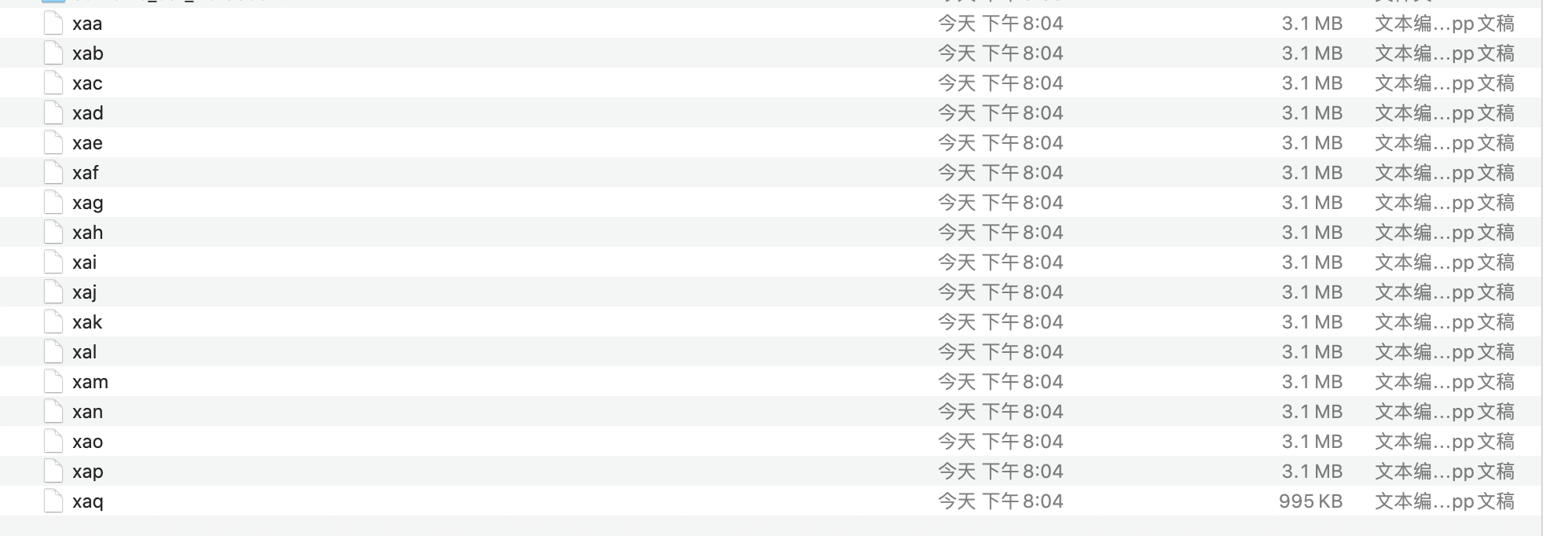
- 虚拟存储过程: 把输入目录下所有的文件大小 , 依次和设置的setMaxInputSplitSize值进行比较 , 如果不大于设置的最大值 , 逻辑上划分一个块. 如果输入文件大于设置的最大值且大于两倍,此时文件将均分为2个虚拟存储块(防止出现太小切片)
比如setMaxInputSplitSize值为4M , 输入文件大小为8.02M,则逻辑上分出一个4M的块, 剩余的大小为4.02M,如果按照4M逻辑划分, 就会出现0.02M的非常小的虚拟存储文件,所以将剩余的4.02M切割成(2.01M和2.01M)两个文件.
- 切片的过程中
- 判断虚拟存储的文件大小是否大于setMaxInputSplitSize值 , 大于等于则单独形成一个切片
- 如果不大于则跟下一个虚拟存储文件进行合并 , 共同形成一个切片
- 按照输入的文件, 3.1M 995KB 这十七个小文件
最终会形成9个切片
前面十六个都会是(3.1M+3.1M) 共有8分 , 最后一个995KB单独是一份
注意: 虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值
1.自定义InputFormat
2.OutputFormat
1.自定义OutputFormat

若有收获,就点个赞吧
0 人点赞
