1. HDFS 简介
HDFS (全程为 Hadoop Distribute File System, Hadoop分布式文件系统) 是Hadoop核心组件 . 是分布式存储服务.
分布式文件系统横跨多台计算机, 在大数据时代有着广泛的应用前景,他们为存储和处理大规模数据提供所需的扩展能力
HDFS是分布式文件中一种
2.HDFS 的重要概念
HDFS通过统一的命名空间目录树来定位文件; 另外, 它是分布式的, 由很多服务器联合起来实现其功能, 集群中的服务器有各自的角色
- 典型的Master/Slave架构
HDFS 的架构师经典的Master/Slave结构
HDFS集群往往是一个NameNode(HA架构会有两个NameNode,联邦机制)+多个DataNode组成
NameNode是集群的住节点 , DataNode是集群从节点
- 分块存储(black块机制)
HDFS支持传统的层次文件结构组织, 用户或者应用程序可以创建目录, 然后将文件保存这些目录里面, 文件系统名字空间的层次结构和大多数现有的文件系统类似: 用户可以创建 , 删除 , 移动或者重命名文件.
NameNode负责维护文件系统的名字空间 , 任何对文件名字空间或属性的修改都将被NameNode记录下来
HDFS提供给客户单一个抽象目录树 , 访问形式:hdfs//namenode的hostname:port/test/input
hdfs://hadoop001:9000/test/input
- NameNode元数据管理
我们把目录结构及文件分块位置信息叫做元数据
NameNode的元数据记录每个文件对应的black信息(block的id 以及所在的DataNode节点信息)
- DataNode数据存储
文件的各个block的具体存储管理由DataNode节点承担, 一个block会有多个DataNode来存储 , DataNode会定时想NameNode来汇报自己持有的block信息
- 副本机制
为了容错 , 文件的所有block都会有副本 , 每个文件的block大小和副本系数都是可配置的, 应用程序可以指定某个文件的副本数目 , 副本系数可以在文件创建的时候指定 , 也可以在之后改变 , 副本数量默认是3个
- 一次写入 , 多次读出
HDFS是设计成适应一次写入 , 多次读的场景 , 而且不支持文件的随机修改(支持追加写入, 不支持随机更新)
正因为如此 , HDFS适合用来做大数据分析的底层存储服务 , 并不适合用来做网盘等等应用(修改不方便 ,延迟大 , 网络开销大 , 成本高)
3.HDFS 架构
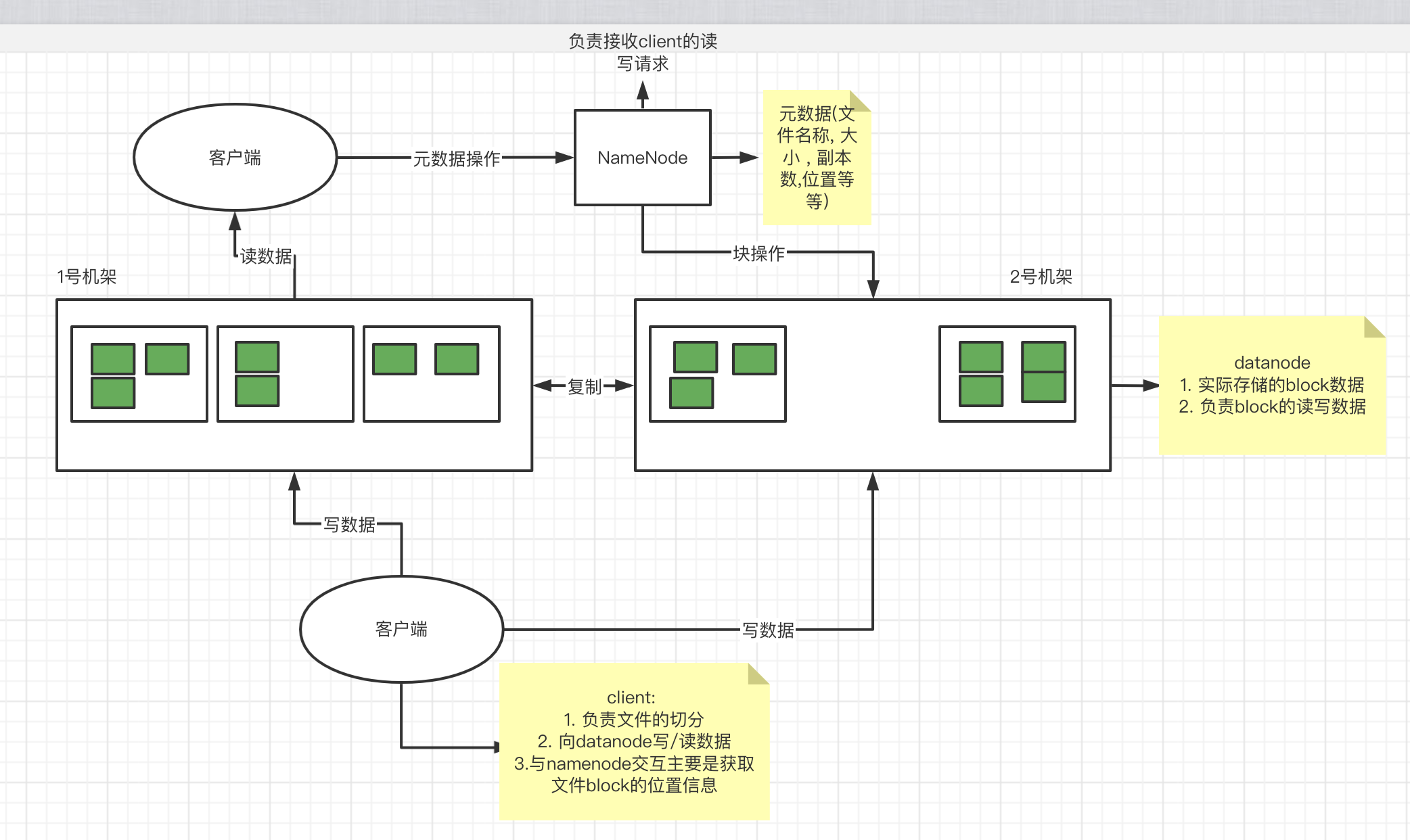
- NameNode(NN): HDFS集群的管理者, Master
- 维护管理HDFS的名称空间(NameSpace)
- 维护管理HDFS的名称空间(NameSpace)
- 维护副本策略
- 记录文件块(Block)的映射信息
- DataNode: NameNode 下达命令 , DataNode执行实际操作 , Slave节点.
- 保存实际的数据块
- 负责数据块的读写
- Client: 客户端
基本语法
$ bin/hadoop fs 具体命令$ bin/hdfs dfs 具体命令
HDFS命令演示
启动Hadoop集群(方便后续测试)
$ sbin/start-dfs.sh$ sbin/start-yarn.sh# 注意这两个命令不能再同一台机器上启动
-help: 输出这个命令参数
$ hadoop fs -help rm
-ls: 显示目录信息
$ hadoop fs -ls /
-mkdir: 在HDFS上创建目录
$ hadoop fs -mkdir -p /test/anda
-moveFromLocal: 从本地剪切粘贴到HDFS ```shell $ hdfs dfs -moveFromLocal [local_file_path] [hadoop_path]
$ hdfs dfs -moveFromLocal ./test.txt.back /test/anda
6. -appendToFile追加一个文件到已经存在的文件末尾```shell$ vim test.txt.back# 输入 111111111111111111111111111111111$ hdfs dfs -appendToFile test.txt.back /test/anda/test.txt.back
-cat 显示文件内容
$ hdfs dfs -cat /test/anda/test.txt.back
-chgrp -chmod -chown: Linux文件系统中的用法一样 , 修改文件所属权限
$ hdfs dfs -chmod 666 /test/anda/test.txt.back$ hdfs dfs -chown root:root /test/anda/test.txt.back
-copyFromLocal 从本地文件系统中拷贝文件到HDFS路劲去
$ hdfs dfs -copyFromLocal READMD.md /test/anda
-copyToLocal
$ hdfs dfs -copyToLocal /test/anda/READMD.md .
-cp 从HDFS的一个路径拷贝到另外一个路径
$ hdfs dfs -cp /test/anda/README.md /test/anda_cp/
-mv 在HDFS目录中移动文件
$ hdfs dfs -mv /test/anda/test.txt.back /
-get 等同于copyToLocal , 就是从HDFS下载文件到本地
$ hdfs dfs -get /test.txt.back .
-put等同于copyFromLocal
$ hdfs dfs -put wc.txt /test/anda/
-tail 显示一个文件的末尾
$ hdfs dfs -tail -f /test/anda/test.txt.back
-rm 删除文件或文件夹
$ hdfs dfs -rm -rf /READMD.md
-rmdir 删除空目录
$ hdfs dfs -mkdir /coco$ hdfs dfs -rmdir /coco
-du 统计文件夹的大小信息
$ hdfs hdfs -du /test/anda/
-setrep 设置HDFS文件的副本数量
$ hdfs dfs -setrep 10 /test/anda/READMD.md
这里设置的副本数只是记录在NameNode的元数据中, 是否真的这么多副本 , 还得看DataNode的数量 , 因为目前只有3台设备, 最多也就是三个副本, 只有节点数的增加到10台时, 副本数才能达到10.
2.Java客户端
1.客户端环境准备
- 将Hadoop-2.9.2安装包解压到非中文的路径

- 配置HADOOP_HOME和HADOOP_PATH环境变量

- 创建一个Maven工程
导入相应的依赖坐标+日志配置文件
<dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13.2</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.8.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.9.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.9.2</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>2.9.2</version></dependency></dependencies>
为了便于控制程序运行打印日志的数量 , 需要在项目的src/main/resources 目录下, 新建一个文件 , 命名为”logs4j.properties”, 文件内容
log4j.rootLogger=INFO, stdoutlog4j.appender.stdout=org.apache.log4j.ConsoleAppenderlog4j.appender.stdout.layout=org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%nlog4j.appender.logfile=org.apache.log4j.FileAppenderlog4j.appender.logfile.File=target/spring.loglog4j.appender.logfile.layout=org.apache.log4j.PatternLayoutlog4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
新建HdfsClient类
/*** @author anda* @since 1.0*/public class HDFSClient {static FileSystem fileSystem = null;static Configuration configuration = null;static {// 1. 获取文件系统配置configuration = new Configuration();configuration.set("fs.defaultFS", "hdfs://hadoop001:9000");try {// 如果出现权限问题 , 我们要给定上传的用户权限//fileSystem = FileSystem.get(new URI("hdfs://hadoop001:9000"), configuration, "root");fileSystem = FileSystem.get(configuration); // 使用此段代码时, 会出现无权限的操作, 如下图} catch (Exception e) {e.printStackTrace();}}/*** 创建目录** @throws Exception*/@Testpublic void testMkdir() throws Exception {fileSystem.mkdirs(new Path("/coco/monika"));fileSystem.close();}}
遇到问题:
如果不指定操作HDFS集群的用户信息, 默认是获取当前操作系统的用户信息, 出现权限被拒绝的问题 , 报错如下:
- HDFS 文件系统权限问题
hdfs文件系统权限问题与linux的文件权限机制类似
r:read w:write x:execute 权限x对于文件标识忽略 , 对于文件夹标识是否有权限访问其内容
如果liunx系统用户zhangsan使用hadoop命令创建一个文件, 那么这个文件在HDFS当中的owner就是zhangsan
解决方案
- 指定用户信息获取FileSystem对象
关闭HDFS权限校验
$ vim hdfs-site.xml
<property><name>dfs.permissions</name><value>true</value></property>
修改完成之后要分发到其他节点 , 同时要启动HDFS集群
基于HDFS权限本身比较鸡肋的特点 , 我们可以彻底放弃HDFS权限校验 , 如果生产环境中我们可以考虑借助kerberos以及sentry等安全框架来管理大数据集群安全 , 所以我们直接修改HDFS的根目录权限为777
$ hadoop fs -chmod -R 777 /
2.HDFS的API操作
1.上传文件
/*** 从本地将文件拷贝到HDFS** @throws IOException*/@Testpublic void testCopyFromLocalFile() throws IOException {fileSystem.copyFromLocalFile(new Path("/Users/anda/Desktop/JUC.html"), new Path("/coco/ll"));fileSystem.close();}
如果需要将hdfs.site.xml拷贝到项目的根目录(src/main/resources)下
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xls"?><configuration><property><name>dfs.replication</name><value>1</value></property></configuration>
参数的优先级: 代码中设置的值 > 用户自定义配置文件 > 服务器的默认配置
2.下载配置
/*** 从HDFS拷贝文件到本地** @throws Exception*/@Testpublic void testCopyToLocal() throws Exception {fileSystem.copyToLocalFile(new Path("/READMD.md"), new Path("/Users/anda/Desktop"));fileSystem.close();}
3.删除文件
/*** 删除文件** @throws Exception*/@Testpublic void testDelete() throws Exception {fileSystem.delete(new Path("/coco/ll/Redis.html"), Boolean.TRUE);fileSystem.close();}
4.查看文件名称 , 权限 , 长度 , 块信息
/*** 查看文件名称 , 权限 , 长度 , 块信息* @throws IOException*/@Testpublic void testListFiles() throws IOException {RemoteIterator<LocatedFileStatus> listFiles = fileSystem.listFiles(new Path("/"), true);while (listFiles.hasNext()) {LocatedFileStatus status = listFiles.next();// 输出详情// 文件名称System.err.println(status.getPath().getName());// 长度System.err.println(status.getLen());// 权限System.out.println(status.getPermission());// 分组System.out.println(status.getGroup());// 获取存储的块信息BlockLocation[] blockLocations = status.getBlockLocations();for (BlockLocation blockLocation : blockLocations) {// 获取块存储的主机节点String[] hosts = blockLocation.getHosts();for (String host : hosts) {System.out.println("host = " + host);}}System.err.println("=================");}fileSystem.close();}
5.文件夹判断
/*** 测试是文件还是目录** @throws Exception*/@Testpublic void testListStatus() throws Exception {FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/"));for (FileStatus fileStatus : fileStatuses) {if (fileStatus.isFile()) {System.out.println(fileStatus.getPath().getName());} else {System.err.println(fileStatus.getPath().getName());}}fileSystem.close();}
6.IO流操作
1.文件上传
/*** 文件上传** @throws Exception*/@Testpublic void putFileToHDFS() throws Exception {// 1. 创建输入流FileInputStream fis = new FileInputStream(new File("/Users/anda/Desktop/jd-gui-1.6.6.jar"));// 2. 获取输出流FSDataOutputStream fos = fileSystem.create(new Path("/test.jar"));// 3.流对拷IOUtils.copyBytes(fis, fos, configuration);// 4.关闭资源IOUtils.closeStream(fos);IOUtils.closeStream(fis);fileSystem.close();}
2.文件下载
/*** 文件下载*/@Testpublic void getFileFromHDFS() throws Exception {// 2. 获取输入流FSDataInputStream fis = fileSystem.open(new Path("/READMD.md"));// 3. 获取输出流FileOutputStream fos = new FileOutputStream(new File("/Users/anda/Desktop/README.md.back"));// 4. 流的对拷IOUtils.copyBytes(fis, fos, configuration);// 5. 关闭资源IOUtils.closeStream(fos);IOUtils.closeStream(fis);fileSystem.close();}
3.seek定位读取
/*** 重新读取文件 ,从头开始读取* @throws Exception*/@Testpublic void readFileSeek2() throws Exception {// 2 打开李输入流 , 读取数据输出到控制台.FSDataInputStream in = null;try {in = fileSystem.open(new Path("/READMD.md"));IOUtils.copyBytes(in, System.err, 4096, false);in.seek(0);System.out.println("=================");IOUtils.copyBytes(in, System.err, 4096, false);} finally {if (in != null) {IOUtils.closeStream(in);}}}
5.HDFS读写解析
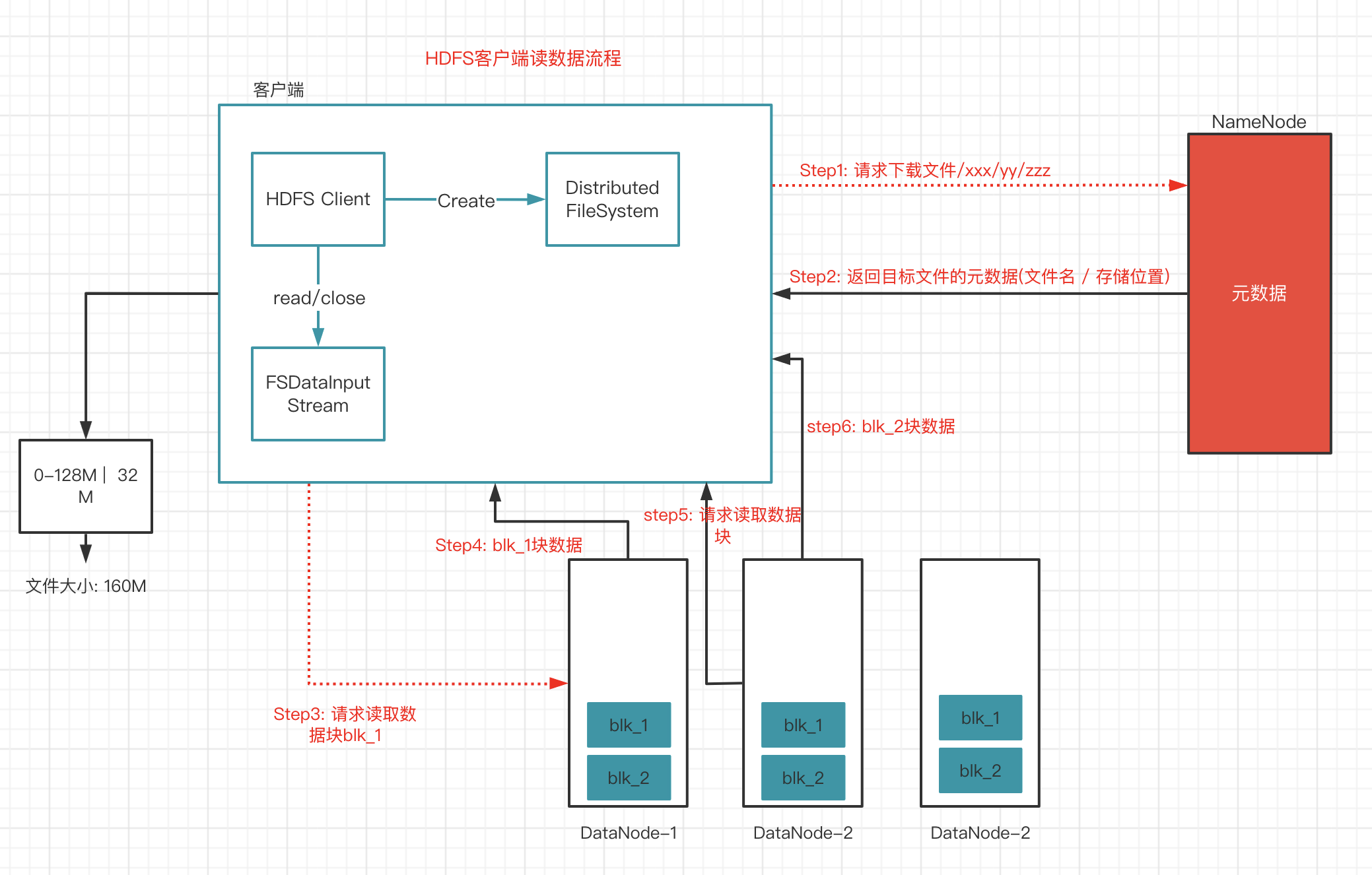
1.HDFS读数据流程
- 客户端通过Distributed FileSystem向NameNode请求下载文件 , NameNode通过查询元数据 , 找到文件块所在的DataNode地址
- 挑选一台DataNode(就近原则, 然后随机) 服务器, 请求读取数据
- DataNode开始传输数据给客户端(从磁盘里面读取数据输入流 , 以Packet为单位来做校验)
- 客户端以Packet为单位 , 现在本地缓存, 然后写入目标文件
2. HDFS写数据流程
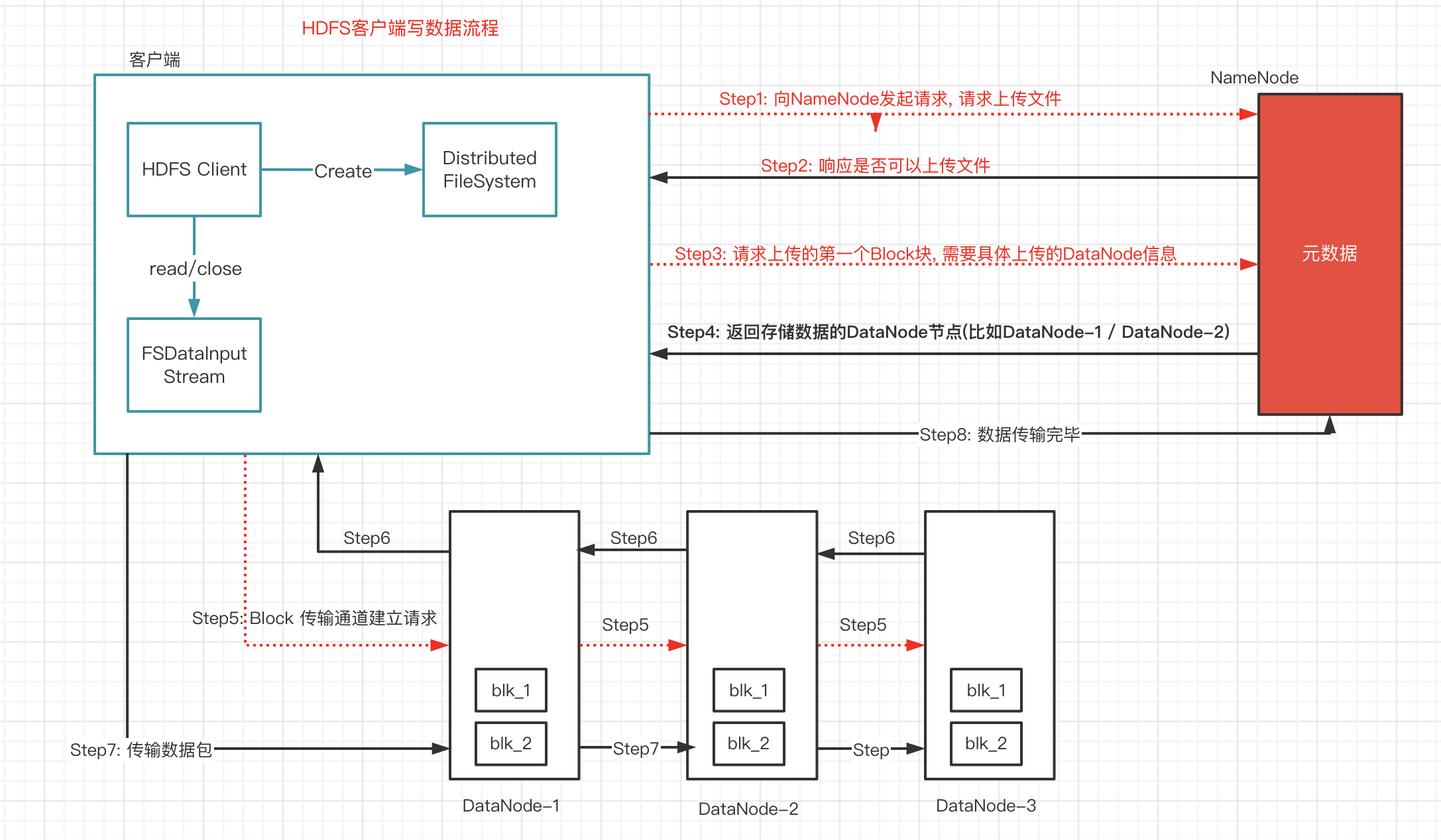
- 客户端通过Distributed FileSystem 模块向NameNode请求上传文件 , NameNode检查目标文件是否已存在 , 父目录是否存在
- NameNode返回是否可以上传
- 客户端请求第一个Block上传到哪几个DataNode服务器上
- NameNode返回3个DataNode节点 , dn1 dn2 dn3
- 客户端通过FSDataOutputStream模块请求dn1上传数据, dn1收到请求会继续调用dn2 . 然后dn2调用dn3 , 将这个通信管道建立完成
- 客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存)以Packet为单位 , dn1收到一个Packet就会传给dn2 , dn2传给dn3; dn1每传一个packet会放入一个确定队列等待确认
- 当一个Block传输完成之后 , 客户端再次请求NameNode上传第二个Block的服务器(重复执行3-7步)
验证Packet代码
@Testpublic void testUploadPacket() throws Exception {// 1.准备读取本地文件的输出流FileInputStream fin = new FileInputStream(new File("/Users/anda/Desktop/jd-gui-1.6.6.jar"));// 2.准备好写出数据到hdfs的输出流FSDataOutputStream fout = fileSystem.create(new Path("/coco/ll/jd-gui-1.6.6.jar"), () -> {// 这个progress方法就是每传输64KB(packet)就会执行一次System.out.println("------");});// 3.实现拷贝流IOUtils.copyBytes(fin, fout, configuration);}
6.NN与2NN
1.HDFS元数据管理机制
问题1: NameNode如何管理和存储元数据?
计算机中存储数据两种: 内存或者是磁盘
元数据存储磁盘: 存储磁盘无法面对客户对元数据信息的任意的快速低延迟的响应,但是安全性高 , 元数据存储内存 , 如果断点 , 内存中的数据全部丢失
解决方案: 内存+磁盘; NameNode内存+FsImage的文件(磁盘)
新问题: 磁盘和内存中元数据如何划分
两个数据一模一样 , 还是两个数据合并到一起才是一份完整的数据呢?
一模一样: client 如果对元数据进行增删改查操作 , 需要保证两个数据的一致性 , FsImage文件操作起来效率也不高
两个合并=完整数据: NameNode引入一个edits文件(日志文件: edits文件记录的是client的增删改操作)
不再选择让NameNode把数据dump出来形成FsImage文件(这种操作是比较消耗资源)
元数据管理流程
NameNode & SecondayNamenode & CheckPoint 工作机制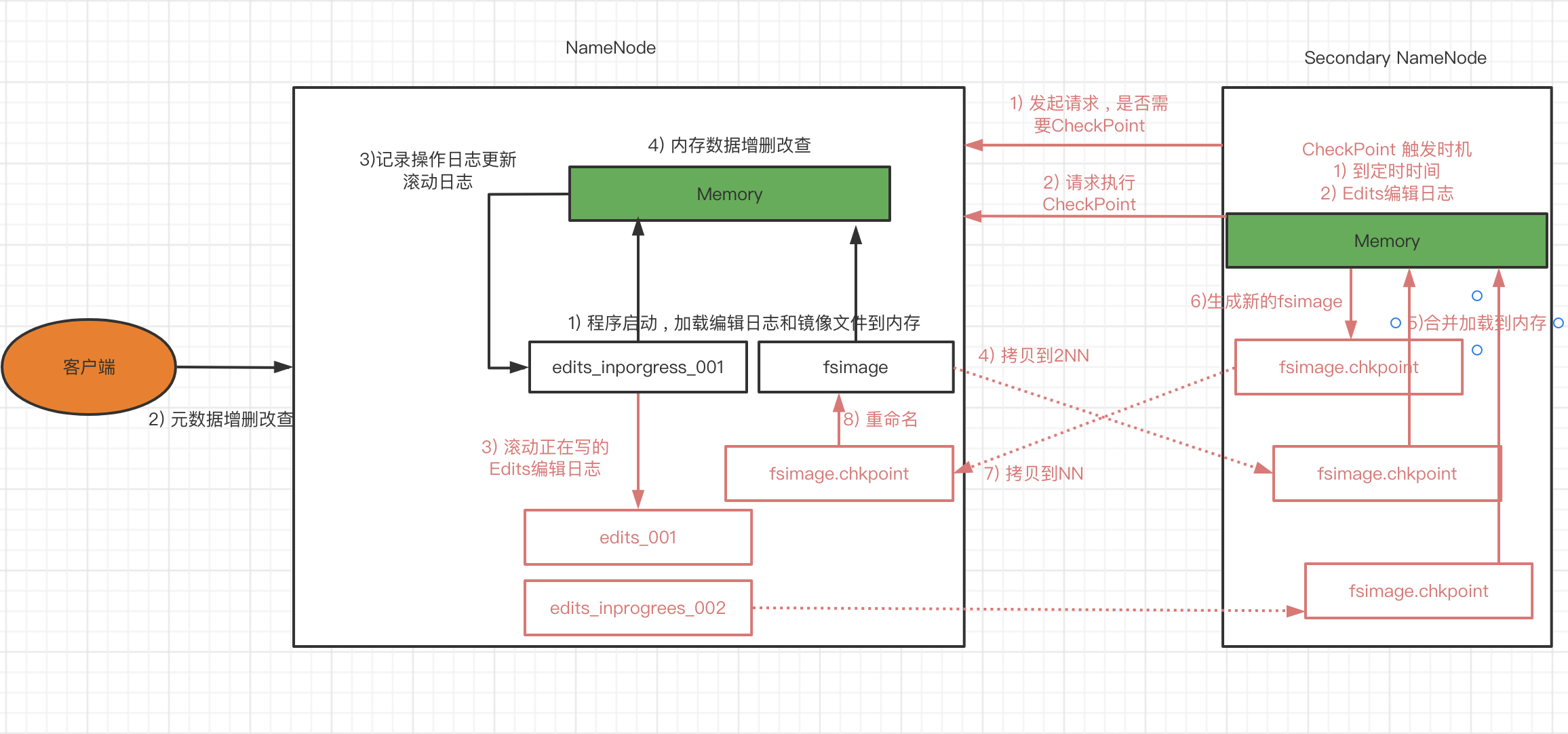
- 第一阶段: NameNode启动
- 第一次启动NameNode格式化之后 , 创建Fsimage和Edits文件 , 如果不是第一次启动 , 直接加载编辑日志和镜像文件到内存.
- 客户端对元数据进行增删改查的请求
- NameNode记录操作日志 , 更新滚动日志.
- NameNode在内存中对数据进行增删改
第二阶段: Secondary NameNode工作
- Secondary NameNode询问NameNode是否需要CheckPoint , 直接带回NameNode是否执行检查点操作结果.
- Secondary NameNode请求执行CheckPoint.
- NameNode滚动正在写的Edits日志.
- 将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode.
- Secondary NameNode加载编辑日志和镜像文件到内存 , 并合并.
- 生成新的镜像文件fsimage.chkpoint
- 拷贝fsimage.chkpoint到NameNode.
- NameNode将fsimage.chkpoint重新命名成fsimage.
2. Fsimage 与Edits文件解析
NameNode 在执行格式化之后,会在/opt/hadoop-2.9.2/data/tmp/dfs/name/current 目录下产生如下文件:
Fsimage文件: 是namenode中关于元数据的镜像, 一般成为检查点, 这里包含了HDFS文件系统所有目录以及文件相关信息(Block 数量 , 副本数量 , 权限等信息)
- Edits文件: 存储了客户端堆HDFS文件系统所有的更新操作记录 , Client 对 HDFS文件系统所有的更新操作都会被记录到Edits文件中 , (不包括查询操作)
- see_txid: 该文件是保存了一个数字 , 数字对应着最后一个Edits文件名的数字
- VERSION: 该文件记录namenode的一些版本号信息, 比如: CusterId, namespaceID等
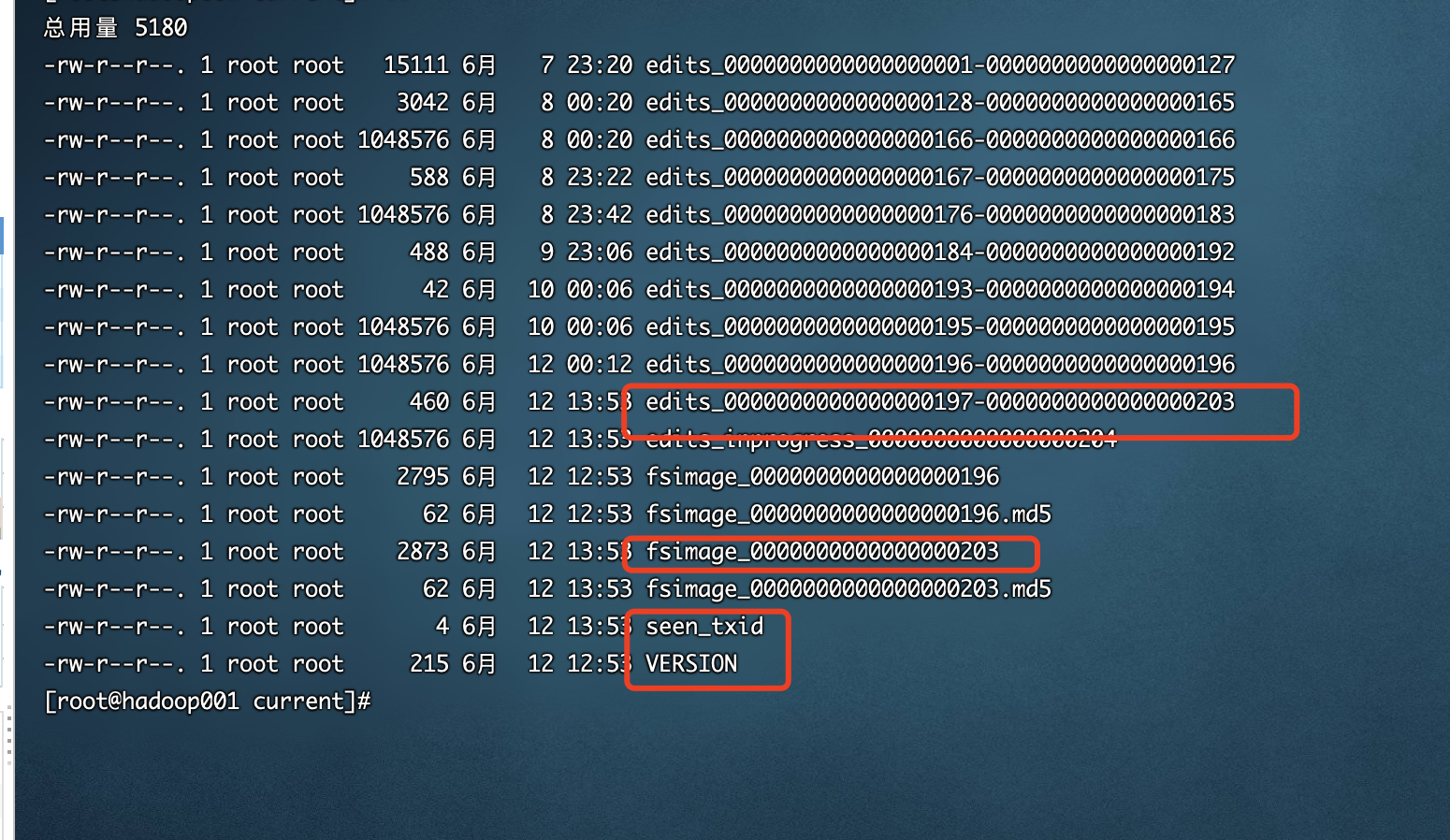
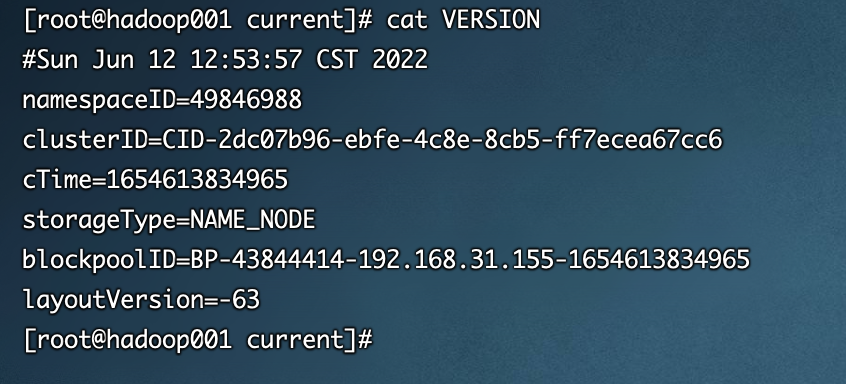
namespace 命令空间ID clusterID 当前集群的唯一标识 blockpoolID 块池ID
1.Fsimage 文件内容
官方地址
查看oiv和oev命令
$ hdfs

基本语法
$ hdfs oiv -p 文件类型(xml) -i 镜像文件 -o 转换后文件输出路径
案例实操
$ cd /opt/hadoop-2.9.2/data/tmp/dfs/name/current$ mkdir -p /opt/hadoop-2.9.2/server_info$ hdfs oiv -p XML -i fsimage_0000000000000000205 -o /opt/hadoop-2.9.2/server_info/fsimage_0000000000000000205.xml
```xml <?xml version=”1.0”?>
-63 1 826afbeae31ca687bc2f8471dc841b66ed2c6704 49846988 1000 1021 0 1073741845 205 16438 37 16385 DIRECTORY 1654785634613 root:supergroup:0755 9223372036854775807 -1 16386 DIRECTORY tmp 1654614776586 root:supergroup:0770 -1 -1 16387 DIRECTORY hadoop-yarn 1654614318900 root:supergroup:0770 -1 -1 16388 DIRECTORY staging 1654614745942 root:supergroup:0770 -1 -1 16389 DIRECTORY history 1654614320811 root:supergroup:0770 -1 -1 16390 DIRECTORY done 1654614926637 root:supergroup:0770 -1 -1 16391 DIRECTORY done_intermediate 1654614804579 root:supergroup:1777 -1 -1 16392 FILE wcinput 3 1654614633337 1654614628837 134217728 root:supergroup:0644 1073741825 1001 28 0 16393 DIRECTORY root 1654614745943 root:supergroup:0700 -1 -1 16394 DIRECTORY .staging 1654614918293 root:supergroup:0700 -1 -1 16400 DIRECTORY logs 1654614777430 root:root:1777 -1 -1 16401 DIRECTORY root 1654614777480 root:root:0770 -1 -1 16402 DIRECTORY logs 1654614777540 root:root:0770 -1 -1 16403 DIRECTORY application_1654614262516_0001 1654614928345 root:root:0770 -1 -1 16404 DIRECTORY root 1654614927042 root:supergroup:0770 -1 -1 16406 DIRECTORY wcoutput 1654614914482 root:supergroup:0755 -1 -1 16412 FILE part-r-00000 3 1654614911942 1654614910335 134217728 root:supergroup:0644 1073741832 1008 36 0 16414 FILE _SUCCESS 3 1654614914491 1654614914482 134217728 root:supergroup:0644 0 16417 FILE job_1654614262516_0001-1654614762502-root-word+count-1654614914554-1-1-SUCCEEDED-default-1654614825702.jhist 3 1654614915987 1654614915689 134217728 root:supergroup:0770 1073741834 1010 33638 0 16418 FILE job_1654614262516_0001_conf.xml 3 1654614916633 1654614916145 134217728 root:supergroup:0770 1073741835 1011 196196 0 16419 FILE hadoop003_44430 3 1654614927495 1654614926185 134217728 root:root:0640 1073741836 1012 22684 0 16420 FILE hadoop002_41790 3 1654614928284 1654614926545 134217728 root:root:0640 1073741837 1013 75944 0 16421 DIRECTORY 2022 1654614926637 root:supergroup:0770 -1 -1 16422 DIRECTORY 06 1654614926637 root:supergroup:0770 -1 -1 16423 DIRECTORY 07 1654614926637 root:supergroup:0770 -1 -1 16424 DIRECTORY 000000 1654614927042 root:supergroup:0770 -1 -1 16425 DIRECTORY test 1654617764844 root:supergroup:0755 -1 -1 16426 DIRECTORY anda 1654618513269 root:supergroup:0755 -1 -1 16427 FILE test.txt.back 3 1654616670910 1654616257517 134217728 root:root:0777 1073741838 1014 80 0 16428 FILE READMD.md 10 1654617345347 1654617343799 134217728 root:supergroup:0644 1073741839 1015 125 0 16429 DIRECTORY anda_cp 1654617974186 root:supergroup:0755 -1 -1 16431 FILE READMD.md 3 1654618266033 1654785962503 134217728 root:supergroup:0777 1073741841 1017 125 0 16433 DIRECTORY coco 1654700685557 root:supergroup:0755 -1 -1 16434 DIRECTORY ll 1655010121825 root:supergroup:0755 -1 -1 16436 FILE JUC.html 1 1654701889974 1654701886726 134217728 root:supergroup:0644 1073741843 1019 45777461 0 16437 FILE test.jar 1 1654785636323 1654785634613 134217728 root:supergroup:0644 1073741844 1020 3238491 0 16438 FILE jd-gui-1.6.6.jar 1 1655010123087 1655010121825 134217728 root:supergroup:0644 1073741845 1021 3238491 0 0 0 16385 16431 16433 16425 16437 16386 16392 16406 16386 16387 16400 16387 16388 16388 16389 16393 16389 16390 16391 16390 16421 16391 16404 16393 16394 16400 16401 16401 16402 16402 16403 16403 16420 16419 16406 16414 16412 16421 16422 16422 16423 16423 16424 16424 16417 16418 16425 16426 16429 16426 16428 16429 16427 16433 16434 16434 16436 16438 0 0 0 0 1 0 0
问题: Fsimage中为什么没有记录块所对应DataNode?<br />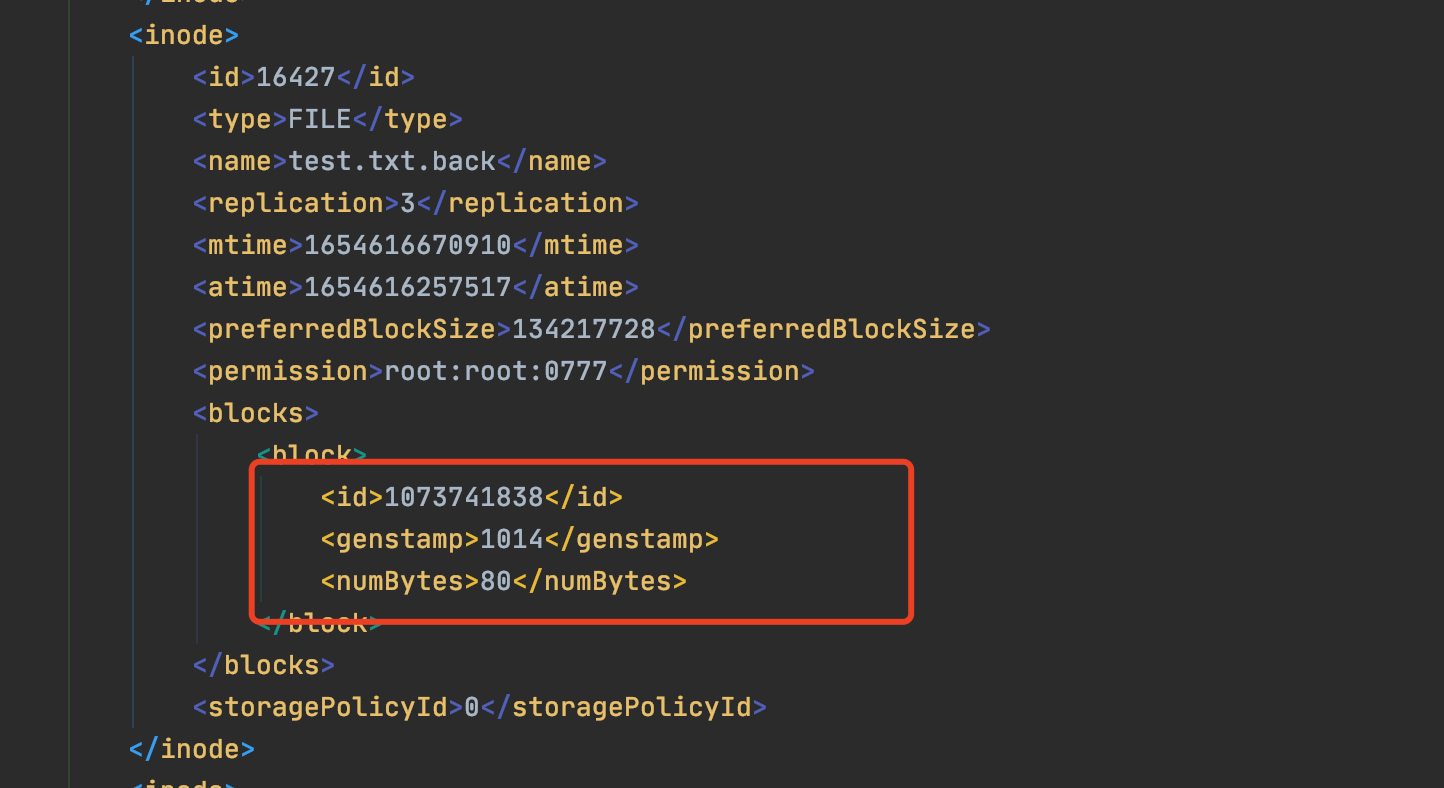<br />在内存元数据中是有记录块所对应的dn信息 , 但是fsimage中就剔除了这个信息 , HDFS集群在启动的时候会加载image以及edits文件 , block对应的dn信息都没有记录 , 集群启动的时会有一个安全模式<br />(safemode) , 安全模式就是为了让dn汇报自己当前所持有的block信息给nn来补全元数据 , 后续每隔一段时间dn都要汇报自己持有的block信息.<a name="lvUfy"></a>### 2.Edits文件内容1. 基本语法```shell$ hdfs oev -p 文件类型 -i 编辑日志 -o 转换后文件输出路径$ hdfs oev -p XML -i edits_0000000000000000204-0000000000000000205 -o /opt/hadoop-2.9.2/server_info/edits_0000000000000000204-0000000000000000205.xml$ cat /opt/hadoop-2.9.2/server_info/edits_0000000000000000204-0000000000000000205.xml
<?xml version="1.0" encoding="UTF-8"?><EDITS><EDITS_VERSION>-63</EDITS_VERSION><RECORD><OPCODE>OP_START_LOG_SEGMENT</OPCODE><DATA><TXID>204</TXID></DATA></RECORD><RECORD><OPCODE>OP_END_LOG_SEGMENT</OPCODE><DATA><TXID>205</TXID></DATA></RECORD></EDITS>
备注: Edits中只记录更新相关的操作 , 查询或者下载文件并不会记录在内
NameNode启动时如何确定加载那些Edits文件?
NN启动时需要加载fsimage文件以及那些没有被2nn进行合并的edit文件 , nn如何判断哪些edits已经已经被合并了呢?
可以通过fsimage文件自身的编号来确定哪些已经被合并了.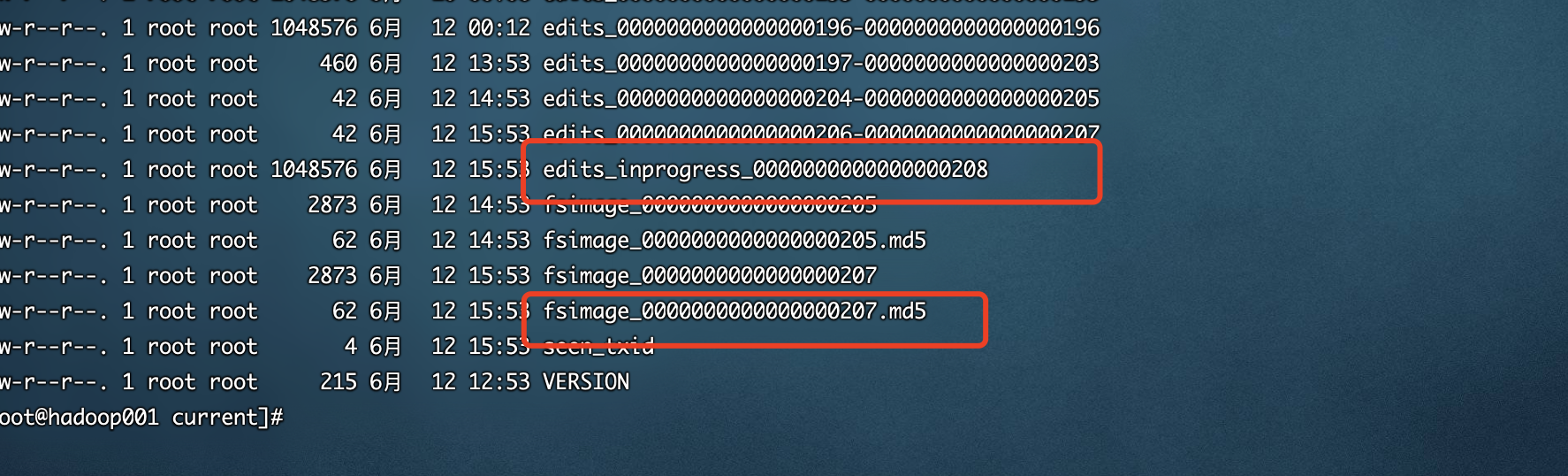
这个编号可以确定那些edits没有被合并
3.checkpoint 周期
$ vim hdfs-site.xml
<!-- 定时一小时 --><property><name>dfs.namenode.checkpoint.period</name><value>3600</value></property><!-- 一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次 --><property><name>dfs.namenode.checkpoint.txns</name><value>1000000</value> <description>操作动作次数</description></property><property><name>dfs.namenode.checkpoint.check.period</name><value>60</value><description> 1分钟检查一次操作次数</description></property>
7.NN故障处理
NameNode故障后, HDFS集群就无法正常工作 , 因为HDFS文件系统的元数据需要由NameNode来管理维护并与Client交互, 如果元数据出现损坏和丢失同样会导致NameNode无法正常工作进而HDFS文件系统无法正常的对外提供服务
如果元数据出现丢失如何恢复呢?
- 将2NN的元数据拷贝到NN的节点下, 此方式会存在元数据丢失的情况
- 搭建HDFS的HA(高可用)集群 , 解决NN的单点故障问题 ,(借助Zookeeper实现HA, 一个Active的NameNode, 一个是standy的NameNode)
8.Hadoop的限额与归档以及集群安全模式
高级命令
- HDFS文件限额配置
HDFS文件的限额配置允许我们以文件大小或者文件个数来限制我们在某个目录下上传的文件数量或者文件内容总量 , 以便达到我们类似百度网盘等限制每个用户允许上传的最大的文件的量
数量限额
$ hdfs dfs -mkdir /user/root/anda # 创建hdfs文件夹$ hdfs dfsadmin -setQuota 2 /user/root/anda # 给该文件夹下面设置最多上传两个文件 , 上传文件时却只能上传一个$ hdfs dfsadmin -clrQuota /user/root/anda # 清除文件数量限制
空间大小限额
$ hdfs dfsadmin -setSpaceQuota 4k /user/root/anda # 限制空间大小4KB$ hdfs dfs -copyFormLocal README.md /user/root/anda$ hdfs dfsadmin -clrSpaceQuota /user/root/anda #清除空间限额# 查看hdfs文件限额数量$ hdfs dfs -count -q -h /user/root/anda
- HDFS的安全模式
安全模式是HDFS所处的一种特殊状态, 在这种状态下, 文件系统只接受读数据请求 , 而不接受删除 , 修改等变更请求. 在NameNode主节点启动时 , HDFS首先进入安全模式,DataNode在启动的时候会向NameNode汇报可用的block等状态 , 当整个系统达到安全标准时, HDFS自动离开安全模式 , 如果HDFS处于安全模式下, 则文件block不能进行任何副本操作复制操作 , 因此达到最小的副本数量要求 , 是基于DataNode启动时 的状态来判定的,启动时不会再做任何复制(从而达到最小副本数量要求),HDFS刚刚启动的时候 , 默认是30s钟的时间是出于安全期的 , 只有过了30s之后,集群脱离安全期 , 然后才可以对进群进行操作
$ hdfs dfsadmin -safemode
- Hadoop归档技术
主要解决HDFS集群存在大量小文件的问题
由于大量小文件会占用Namenode的内存 , 因此对于HDFS来说 , 存储大量小文件造成的NameNode内存资源的浪费
Hadoop归档文件HAR文件,是一个更加高效的文件存档工具 , HAR文件是由一组文件通过ARCHIVE工具创建而来, 在减少了NameNode的内存使用的同时 , 可以对文件进行头透明的访问, 通俗来说就是HAR文件对NameNode来说就是一个文件减少内存浪费, 对于实际操作处理文件依然是一个一个独立的文件
案例
归档文件
# 把/user/root/anda目录下面所有的文件归档成一个叫input.har的归档文件 , 并把归档后文件存储到/user/root/input路径下$ hadoop archive -archiveName input.har -p /user/root/anda /user/root/input
查看归档
$ hadoop fs -lsr /user/root/input/input.har$ hadoop fs -lsr har:///user/root/input/input.har
解压归档文件
$ hadoop fc -cp har:///user/root/input/input.har/* /user/root
9.日志采集综合案例
1.需求分析
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path;
import java.io.File; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; import java.text.SimpleDateFormat; import java.util.Date; import java.util.Timer; import java.util.TimerTask;
/**
- @author anda
@since 1.0 */ public class LogCollector {
static class LogCollectorTask extends TimerTask {
@Overridepublic void run() {// 采集的业务逻辑SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");String todayName = sdf.format(new Date());// 1.扫描指定的路径 , 找到待上传的文件File file = new File("/Users/anda/Desktop/logs/");File[] files = file.listFiles((dir, name) -> name.endsWith(".txt"));// 2.把待上传文件转移到临时目录File tempFile = new File("/Users/anda/Desktop/logs_tmp/");if (!tempFile.exists()) {tempFile.mkdirs();}for (File file1 : files) {file1.renameTo(new File(tempFile + "/" + file1.getName()));}// 3.使用hdfs api上传日志文件到指定目录Configuration configuration = new Configuration();configuration.set("fs.defaultFS", "hdfs://hadoop001:9000");try {FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop001:9000"), configuration, "root");Path path = new Path("/user/local/logs/target/");if (!fileSystem.exists(path)) {fileSystem.mkdirs(path);}File[] temp = tempFile.listFiles();for (File file1 : temp) {String path1 = file1.getPath();if (!path1.contains(".txt")) {continue;}fileSystem.copyFromLocalFile(new Path(file1.getPath()), new Path("/user/local/logs/target/" + todayName + "/" + file1.getName()));}} catch (IOException | URISyntaxException | InterruptedException e) {e.printStackTrace();}///Users/anda/Desktop/logs_tmp}
}
public static void main(String[] args) {
Timer timer = new Timer();timer.schedule(new LogCollectorTask(), 0, 3600 * 10000);
} }
```

若有收获,就点个赞吧
0 人点赞
