适用题型
堆结构适用于求TopK相关的问题,
求前K个大的数采用固定堆大小为K的小根堆,每次移除堆顶的最小元素,到最后剩下的就是该组数列中最大的K的数字。
同理,求TopK小的的问题,采用大根堆,每次堆顶元素大的出堆,剩下的就是最小的K个数字。
堆结构-完全二叉树
这里是大根堆结构
heapInsert(int[] arr, int index) 时间复杂度O(logN) 上移过程:将指定位置index的数向上调整,添加节点时使用 时间复杂度O(logN)
// 新加进来的数,现在停在了index位置,向上调整,使其最后保持堆的结构特性// 移动到0位置,或者干不掉自己的父亲了,停!private void heapInsert(int[] arr, int index) {// [index] < [index-1]/2 当前节点小于父节点,或者到了堆顶结束// index == 0// 这个条件包含以上两种终止情况,当index=0时,条件是不成立的。while (arr[index] > arr[(index - 1) / 2]) {swap(arr, index, (index - 1) / 2);index = (index - 1) / 2;}}
heapify(int[] arr, int index, int heapSize) 时间复杂度O(logN) 下沉过程:将指定位置index的数向下调整,删除节点时,使用,从堆顶开始向下调整
// 从index位置,开始向下调整,最后保持堆的结构特性// 停:较大的孩子都不再比index位置的数大或者已经没孩子时终止,到了heapsize。private void heapify(int[] arr, int index, int heapSize) {int left = index * 2 + 1; // 计算出左孩子小标while (left < heapSize) { // 如果有左孩子,继续向下执行/// 获取较大孩子的下标int largest = ( left + 1 < heapSize && arr[left + 1] ) > arr[left] ? left + 1 : left; // 如果有右孩子,且右孩子的值大于左孩子的值,将右孩子下表个largest,否则左孩子下标给largestint maxChildIndex = arr[largest] > arr[index] ? largest : index; // 比较之后较大的下标// 如果父节点》=子节点大,不需要调整,跳出。if (maxIndex == index) {break;} else {// index位置的数和较大孩子要互换swap(arr, largest, index);index = maxChildIndex;left = index * 2 + 1;}}}
例题1:假设在一个正常的大根堆中,突然由于某种原因,某个位置i上的数字X突然发生了改变->X^,但是不知道是变大了还是变小了,如何快速的调整X^,使其仍然保持为大根堆的结构。
对i位置的数,顺序执行heapInsert以及heapify两个过程,即可完成调整,时间复杂度为O(logN)
堆结构(大根堆)的相关操作代码如下:
public class Code_Heap {// 手写大堆根结构,如果需要小根堆,只需要更改比较器即可,定义小的在上边,大的在下面。public static class MyMaxHeap {private int[] heap;private final int limit;private int heapSize;public MyMaxHeap(int limit) {heap = new int[limit];this.limit = limit;heapSize = 0;}public boolean isEmpty() {return heapSize == 0;}public boolean isFull() {return heapSize == limit;}public void push(int value) {if (heapSize == limit) {throw new RuntimeException("heap is full");}heap[heapSize] = value;// value heapSizeheapInsert(heap, heapSize++);}// 用户此时,让你返回最大值,并且在大根堆中,把最大值删掉// 剩下的数,依然保持大根堆结构public int pop() {int ans = heap[0];swap(heap, 0, --heapSize);heapify(heap, 0, heapSize);return ans;}// 新加进来的数,现在停在了index位置,向上调整,使其最后保持堆的结构特性// 移动到0位置,或者干不掉自己的父亲了,停!private void heapInsert(int[] arr, int index) {// [index] [index-1]/2// index == 0while (arr[index] > arr[(index - 1) / 2]) { // 这个条件包含以上两种终止情况,当index=0时,条件是不成立的。swap(arr, index, (index - 1) / 2);index = (index - 1) / 2;}}// 从index位置,开始向下调整,最后保持堆的结构特性// 停:较大的孩子都不再比index位置的数大或者已经没孩子时终止private void heapify(int[] arr, int index, int heapSize) {int left = index * 2 + 1; // 计算出左孩子小标while (left < heapSize) { // 如果有左孩子,继续向下执行/// 获取较大孩子的下标int largest = ( left + 1 < heapSize && arr[left + 1] ) > arr[left] ? left + 1 : left; // 如果有右孩子,且右孩子的值大于左孩子的值,将右孩子下表个largest,否则左孩子下标给largestint maxIndex = arr[largest] > arr[index] ? largest : index; // 比较之后较大的下标// 如果父节点》=子节点大,不需要调整,跳出。if (maxIndex == index) {break;} else {// index位置的数和较大孩子要互换swap(arr, largest, index);index = maxIndex;left = index * 2 + 1;}}}private void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;}}public static class MyComparator implements Comparator<Integer>{@Overridepublic int compare(Integer o1, Integer o2) { // compare(o1,o2) 返回值 为正 o1>o2 为负 o1<o2 0 相等return o2 - o1; //这种定义实现的是小根堆 小的优先,举例参数具体值带入即可明白}}public static void main(String[] args) {// 小根堆PriorityQueue<Integer> heap = new PriorityQueue<>(new MyComparator());heap.add(5);heap.add(5);heap.add(5);heap.add(3);// 5 , 3System.out.println(heap.peek());heap.add(7);heap.add(0);heap.add(7);heap.add(0);heap.add(7);heap.add(0);System.out.println(heap.peek());while(!heap.isEmpty()) {System.out.println(heap.poll());}}}
堆排序代码实现
堆排序步骤:
(1)先让整个数组变成大根堆的结构,建大根堆有两种形式。
- 自上向下建堆, O(N*logN)
- 自下向上建堆, O(N)
(2)依次进行heapify,逻辑删除堆顶元素(也就是每次的全局最大值),得出一个有序序列。O(N*logN)

// 堆排序额外空间复杂度O(1)
public static void heapSort(int[] arr) {
if (arr == null || arr.length < 2) {
return;
}
//建大根堆方式1: O(N*logN) 从数组小下标开始建根 自上而下 heapinseart
// for (int i = 0; i < arr.length; i++) { // O(N)
// heapInsert(arr, i); // O(logN)
// }
//建大根堆方式2: O(N) 从数组大头开始建根 自下而上 heapify
for (int i = arr.length - 1; i >= 0; i--) {
heapify(arr, i, arr.length);
}
int heapSize = arr.length; // 大根堆构建完成之后,开始进行排序
swap(arr, 0, --heapSize); // 堆顶元素(最大值)和最后一个值交换,并且堆大小减一,全局最大值和堆断连。 相当于逻辑删除堆中的堆顶元素。
// O(N*logN)
while (heapSize > 0) { // O(N)
heapify(arr, 0, heapSize); // O(logN) 将去除全局最大值后的堆结构重新进行heapify,确定剩下的全局最大值
swap(arr, 0, --heapSize); // O(1) 依次断连,堆顶最大值元素,然后再heapify,维持大根堆结构
}
// 最后数组中剩下的就是拍好序的数组序列了。
}
public static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
加强堆(优化)
提出问题:
对于现在有一个需求,对于一个大根堆,堆元素存放在数组中。现在要删除堆中一个指定元素的位置,普通的堆结构是先遍历一遍堆数组,找到这个元素的位置,这个过程是O(N)的复杂度,然后再进行heapify,O(logN),整个过程的时间复杂度是O(N)。
能否做到删除堆中的任意元素为log(N)的复杂度呢?
在JavaApi中提供的堆操作中,是无法实现O(logN)的复杂度的。因为在PriorityQueue源码中只有一个数组来存放堆元素,也就是给定一个数组下标索引,我们能够立刻找到该位置的数,这就是所谓的正向索引。但是,给定一个元素,能立刻找到该元素所在的位置吗,在当前情况下显然是不能的,因为没有存反向索引,也就是不能通过一个具体值来立刻确定其所在的位置,反向索引的具体实现是具体值作为索引值,具体值的位置作为value值。这样就可以在O(1)的时间复杂度内确定给定元素所在的位置。那么删除堆中元素的时间复杂度就变成了O(logN)
即重构堆的实现,自己添加反向索引表,能够将时间代价由 O(N) —-> O(logN)
加强堆 代码实现如下:
/*
* T一定要是非基础类型,有基础类型需求包一层
*/
public class HeapGreater<T> {
private ArrayList<T> heap; // 正向索引,动态数组存储堆元素
private HashMap<T, Integer> indexMap; // 反向索引表,key存元素值,value存放元素所在的位置 get(key)的时间复杂度为O(1)
private int heapSize;
private Comparator<? super T> comp;
public HeapGreater(Comparator<T> c) {
heap = new ArrayList<>();
indexMap = new HashMap<>();
heapSize = 0;
comp = c;
}
public void remove(T obj) {
T replace = heap.get(heapSize - 1);
int index = indexMap.get(obj);
indexMap.remove(obj);
heap.remove(--heapSize);
if (obj != replace) {
heap.set(index, replace);
indexMap.put(replace, index);
resign(replace);
}
}
// 堆元素值发生变化进行调整
public void resign(T obj) {
heapInsert(indexMap.get(obj));
heapify(indexMap.get(obj));
}
// 请返回堆上的所有元素
public List<T> getAllElements() {
List<T> ans = new ArrayList<>();
for (T c : heap) {
ans.add(c);
}
return ans;
}
private void heapInsert(int index) {
while (comp.compare(heap.get(index), heap.get((index - 1) / 2)) < 0) {
swap(index, (index - 1) / 2);
index = (index - 1) / 2;
}
}
private void heapify(int index) {
int left = index * 2 + 1;
while (left < heapSize) {
int best = left + 1 < heapSize && comp.compare(heap.get(left + 1), heap.get(left)) < 0 ? (left + 1) : left;
best = comp.compare(heap.get(best), heap.get(index)) < 0 ? best : index;
if (best == index) {
break;
}
swap(best, index);
index = best;
left = index * 2 + 1;
}
}
public boolean isEmpty() {
return heapSize == 0;
}
public int size() {
return heapSize;
}
public boolean contains(T obj) {
return indexMap.containsKey(obj);
}
public T peek() {
return heap.get(0);
}
public void push(T obj) {
heap.add(obj);
indexMap.put(obj, heapSize);
heapInsert(heapSize++);
}
public T pop() {
T ans = heap.get(0);
swap(0, heapSize - 1);
indexMap.remove(ans);
heap.remove(--heapSize);
heapify(0);
return ans;
}
private void swap(int i, int j) {
T o1 = heap.get(i);
T o2 = heap.get(j);
heap.set(i, o2);
heap.set(j, o1);
indexMap.put(o2, i);
indexMap.put(o1, j);
}
}
题目1. 最大线段重合问题
给定很多线段,每个线段都有两个数[start, end],表示线段开始位置和结束位置,左右都是闭区间,规定如下 1)线段的开始和结束位置都是整数值 2)线段重合区域的长度必须>=1 返回线段最多重合区域中,包含了几条线段。
解题思路:
- 线段的最大重合区域的左边界,一定是某条线段的左边界
- 对每个线段的开始位置进行排序
- 求每个开始位置的最大贯穿数就是最大重合的线段数
- 用小根堆来保存线段的结尾位置数
- 按线段的头排序然后依次和小根堆堆顶元素进行比较,如果 当前线段的头>小根堆堆顶,弹出,直到堆顶元素>当前线段开始元素,将当前线段尾部加入到堆中,堆中元素的个数就是该位置向右贯穿的线段的个数。
Eg: 线段如下 【1,3】【2,4】【2,6】【3,4】 【5,8】【7,9】
最大重合区域为:3-4和2-3,包含线段数为3条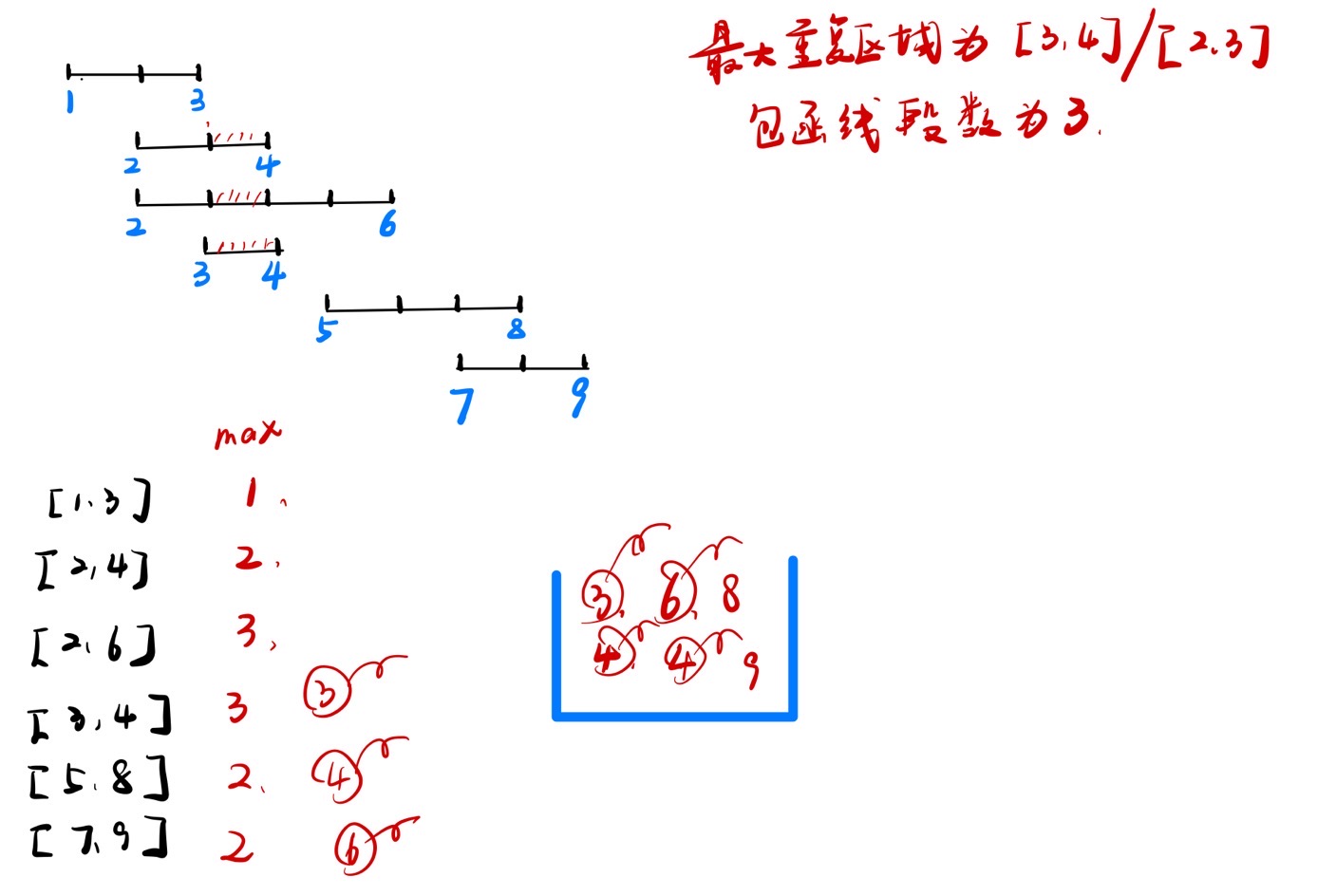 -=
-=
暴力笨蛋方法:
1、从所有线段中找到开始位置的最小值min 和结束位置的最大值max。所有的线段将坐落在【min,max】这个区域。设min = 1 max = 10
2、重合区域必定包含某个 x.5 因此可以在【1,10】上设点 1.5 、 2.5、3.5、4.5、5.5、6.5、7.5、8.5、9.5。
然后统计每个点所属的线段个数,统计结果的最大值即是答案。
时间复杂度 : O((max - min) * N) N 表示线段数量
小根堆方法:
每个线段根据开始位置,从小到大排个序。
准备一个小根堆
eg: 【1,3】【2,4】【2,6】【3,4】 【5,8】【7,9】
任何一个重合区域的左边界,必定是某个线段的左边界。
求每一个线段的左边界向右贯穿线段的最大数量。
如上几个线段的例子:
以1开始向右的最大贯穿数为 1
以2开始向右的最大贯穿数为 3
以3开始向右的最大贯穿数为 3
代码实现:
/**
* 实现方式1:暴力笨蛋方法
*/
public static int maxCover1(int[][] lines) {
int min = Integer.MAX_VALUE;
int max = Integer.MIN_VALUE;
for (int i = 0; i < lines.length; i++) {
min = Math.min(min, lines[i][0]);// 所有线段的开始位置求最小值
max = Math.max(max, lines[i][1]);// 所有线段的结束位置求最大值
}
int cover = 0;
// 遍历每一个点5被多少个线段包含
for (double p = min + 0.5; p < max; p += 1) {
int cur = 0;
for (int i = 0; i < lines.length; i++) {
if (lines[i][0] < p && lines[i][1] > p) {
cur++;
}
}
cover = Math.max(cover, cur);
}
return cover;
}
/**
* 实现方式2: 小根堆 实现
* 时间复杂度 O(N * logN) 最差情况:每个线段的结尾进一次小根堆,出一次小根堆。
*/
public static int maxCover2(int[][] m) {
Line[] lines = new Line[m.length];
for (int i = 0; i < m.length; i++) {
lines[i] = new Line(m[i][0], m[i][1]);
}
Arrays.sort(lines, new StartComparator()); // 按照线段开始位置排序
// 小根堆,每一条线段的结尾数值,使用默认的
PriorityQueue<Integer> heap = new PriorityQueue<>();
int max = 0;
for (int i = 0; i < lines.length; i++) {
// lines[i] -> cur 在黑盒中,把<=cur.start 东西都弹出
while (!heap.isEmpty() && heap.peek() <= lines[i].start) {
heap.poll();
}
// 将线段的结尾位置加到小根堆中
heap.add(lines[i].end);
// 更新max
max = Math.max(max, heap.size());
}
return max;
}
// 定义线段类
public static class Line {
public int start;
public int end;
public Line(int s, int e) {
start = s;
end = e;
}
}
// 定义比较器
public static class EndComparator implements Comparator<Line> {
@Override
public int compare(Line o1, Line o2) {
return o1.end - o2.end;
}
}
题目2:手动改写堆相关题目(重要)加强堆
Java中提供的堆相关的API,PriorityQueue提供的操作是有限的,相对使用者来说就相当于一个黑盒,给指定的序列构建堆,返回堆顶元素等操作。
当一组对象数据通过PriorityQueue建立起堆以后,如果对象的内部比较属性突然改变,正常操作我们需要一个heapInseart或者heapipy过程,但是ProorityQueue却不支持这种操作,此时这个堆就成了一个无效堆。
原因:PriorityQueue没有提供反向索引表。
堆的存储采用数组结构
假设内存对象a(5)表示对象a,内部比较属性为5,存在数组0位置,如上,b(7)在数组1位置,c(8)在数组2位置。
数组中只能通过数组下表(可以认为是索引)找到具体的对象,但是如果a()对象中的比较属性发生变化,只能通过遍历整个数组来找到a()的位置,来确定是否来调整堆结构,这个过程是O(N)的,但是通过heapInseart和heapify两个过程来调整堆结构是O(logN)级别的。
题目:电商用户抽奖策略
给定一个整型数组int[] arr;和一个布尔类型数组boolean[] op
两个数组一定等长,假设长度为N,arr[i]表示客户编号,op[i]表示客户操作
arr = [3, 3, 1, 2, 1, 2, 5 …]
op = [T, T, T, T, F, T, F …]
依次表示:3用户购买了一件商品,3用户购买了一件商品,1用户购买了一件商品,2用户购买了一件商品,
1用户退货了一件商品,2用户购买了一件商品,5用户退货了一件商品…
一对arr[i]和po[i]就代表一个事件:
用户号为arr[i],op[i] == T代表这个用户购买了一件商品,op[i]==F代表这个用户退货了一件商品,现在作为一名电商平台负责人,想在每一个事件到来的时候,都给购买次数最多的前K名用户颁奖。所以,每个事件发生后,都需要一个得奖名单(得奖区)。
得奖系统的规则如下:
- 如果某个用户购买的商品数为0,但是又发生了退货事件,则认为该事件无效,得奖名单和之前事件时保持一致,如例子中的5用户
- 某用户发生购买商品事件,购买商品数+1;发生退货事件,购买商品数-1
- 每次都是最多K个用户获奖,K也为传入的参数,如果根据全部规则,得奖人数确实不够K个,那就以不够的情况为输出结果。
- 得奖系统分为得奖区和候选区,任何用户只要购买数>0,一定在这两个区域中的一个
- 购买数量最大的前K名用户进入得奖区,在最初时如果得奖区没有达到K个用户,那么新来的用户直接进入到得奖区
- 如果购买数量不足以进入得奖区的用户,直接进入到候选区
- 如果候选区购买数最多的用户,已经足以进入到得奖区,该用户就会替换得奖区中购买数量最少的用户(大于才能替换);
如果得奖区中购买数最多的用户有多个,就替换最早进入到得奖区的用户
如果候选区中购买数最多的用户有多个,机会给最早进入到候选区的用户
候选区和得奖区是两套时间,
因用户只会在其中一个区域,所以只会有一个区域的时间,另一个区域没有;<br />从得奖区出来进入候选区的用户,得奖区时间删除,进入候选区的时间就是当前事件的时间;<br />从候选区出来进入得奖区的用户,候选区时间删除,进入得奖区的时间就是当前时间的时间;如果某用户购买数为0,不管在哪个区域都离开,区域时间删除,离开是指彻底离开,任何区域也找不到该用户
如果下次该用户又发生购买行为,产生>0的购买数,会再次根据之前规则回到某个区域中,进入区域的时间重新计算
package class07;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.HashMap;
import java.util.List;
public class Code02_EveryStepShowBoss {
// 用户类
public static class Customer {
public int id; // 用户编号
public int buy; // 购买商品数量
public int enterTime; // 进入区域的时间
public Customer(int v, int b, int o) {
id = v;
buy = b;
enterTime = 0;
}
}
// 候选区比较器: 候选区购买数量相同,最早进入候选区的用户排在前面(优先进入得奖区)
public static class CandidateComparator implements Comparator<Customer> {
@Override
public int compare(Customer o1, Customer o2) {
return o1.buy != o2.buy ? (o2.buy - o1.buy) : (o1.enterTime - o2.enterTime);
}
}
// 得奖区比较器:得奖区购买数量相同,最早进入候选区的用户排在前面(优先被替换)
public static class DaddyComparator implements Comparator<Customer> {
@Override
public int compare(Customer o1, Customer o2) {
return o1.buy != o2.buy ? (o1.buy - o2.buy) : (o1.enterTime - o2.enterTime);
}
}
/**
* 得奖区结构
*/
public static class WhosYourDaddy {
private HashMap<Integer, Customer> customers; // 用户编号
private HeapGreater<Customer> candHeap; // 候选区的堆
private HeapGreater<Customer> daddyHeap; //得奖区的堆
private final int daddyLimit;
public WhosYourDaddy(int limit) {
customers = new HashMap<Integer, Customer>();
candHeap = new HeapGreater<>(new CandidateComparator());
daddyHeap = new HeapGreater<>(new DaddyComparator());
daddyLimit = limit;
}
// 当前 处理i号事件,arr[i] -> id, buyOrRefund
/**
* 处理当前事件
* @param time 时间点
* @param id 用户编号
* @param buyOrRefund 用户操作行为
*/
public void operate(int time, int id, boolean buyOrRefund) {
if (!buyOrRefund && !customers.containsKey(id)) {
return;
}
if (!customers.containsKey(id)) {
customers.put(id, new Customer(id, 0, 0));
}
Customer c = customers.get(id);
if (buyOrRefund) {
c.buy++;
} else {
c.buy--;
}
if (c.buy == 0) {
customers.remove(id);
}
if (!candHeap.contains(c) && !daddyHeap.contains(c)) { // 新用户
if (daddyHeap.size() < daddyLimit) {
c.enterTime = time;
daddyHeap.push(c);
} else {
c.enterTime = time;
candHeap.push(c);
}
} else if (candHeap.contains(c)) { // 老用户,且在候选区
if (c.buy == 0) { // 购买数为0 删掉
candHeap.remove(c);
} else { // 购买数不是零,则必定发生变化。调用候选区小根堆的元素内容改变的方法,进行调整
candHeap.resign(c);
}
} else { // 老用户,且在得奖区
if (c.buy == 0) { // 购买数为 0
daddyHeap.remove(c);
} else { // 购买数不是零,则必定发生变化。调用得奖区小根堆的元素内容改变的方法
daddyHeap.resign(c);
}
}
// 候选区和得奖区交换 交换之前 候选区和得奖区一定要进行排序
daddyMove(time);
}
/**
* 返回得奖区的用户id列表
* @return
*/
public List<Integer> getDaddies() {
List<Customer> customers = daddyHeap.getAllElements();
List<Integer> ans = new ArrayList<>();
for (Customer c : customers) {
ans.add(c.id);
}
return ans;
}
// 候选区移动
private void daddyMove(int time) {
// 候选区为空
if (candHeap.isEmpty()) {
return;
}
// 候选区非空
if (daddyHeap.size() < daddyLimit) {
Customer p = candHeap.pop();
p.enterTime = time;
daddyHeap.push(p);
} else {
if (candHeap.peek().buy > daddyHeap.peek().buy) {
Customer oldDaddy = daddyHeap.pop();
Customer newDaddy = candHeap.pop();
oldDaddy.enterTime = time;
newDaddy.enterTime = time;
daddyHeap.push(newDaddy);
candHeap.push(oldDaddy);
}
}
}
}
/**
* 实现方式二:采用加强堆的形式 时间复杂度为 O(N * lgN)
* @param arr
* @param op
* @param k
* @return
*/
public static List<List<Integer>> topK(int[] arr, boolean[] op, int k) {
List<List<Integer>> ans = new ArrayList<>();
WhosYourDaddy whoDaddies = new WhosYourDaddy(k); // 得奖系统的结构
for (int i = 0; i < arr.length; i++) {
whoDaddies.operate(i, arr[i], op[i]); // 结构调整
ans.add(whoDaddies.getDaddies()); // 返回得奖区
}
return ans;
}
/**
* 实现方式一: 暴力方式解决 时间复杂度至少为为 O(N * N * lgN)
*
* @param arr 客户编号列表
* @param op 客户操作列表
* @param k 前K个用户获奖
*/
public static List<List<Integer>> compare(int[] arr, boolean[] op, int k) {
HashMap<Integer, Customer> map = new HashMap<>(); // 用户编号
ArrayList<Customer> cands = new ArrayList<>(); // 候选区
ArrayList<Customer> daddy = new ArrayList<>(); // 得奖区
List<List<Integer>> ans = new ArrayList<>(); // 返回得奖结果{{客户编号1,购买数量1,发生时间1},{客户编号2,购买数量2,发生时间2}...}
for (int i = 0; i < arr.length; i++) {
int id = arr[i];
boolean buyOrRefund = op[i];
if (!buyOrRefund && !map.containsKey(id)) { // 规则1.用户购买的商品数为0,但是又发生了退货事件
ans.add(getCurAns(daddy));
continue;
}
// 没有发生:用户购买数为0并且又退货了这个事件
// 用户之前购买数是0,此时买货事件。新进来的用户
// 用户之前购买数>0, 此时买货
// 用户之前购买数>0, 此时退货
if (!map.containsKey(id)) {
map.put(id, new Customer(id, 0, 0)); // 购买数量 和 进入时间 暂时设置为0, 在后续操作中再进行调整赋值
}
//
Customer c = map.get(id);
if (buyOrRefund) {
c.buy++;
} else {
c.buy--;
}
if (c.buy == 0) {
map.remove(id);
}
// c
// 如果是 新用户发生购买行为
if (!cands.contains(c) && !daddy.contains(c)) {
if (daddy.size() < k) { // 得奖区未满,直接进入到得奖区,否则进入到候选区
c.enterTime = i;
daddy.add(c);
} else {
c.enterTime = i;
cands.add(c);
}
}
// 遍历处理购买数为0的数据
cleanZeroBuy(cands);
cleanZeroBuy(daddy);
// 事件发生后排序
cands.sort(new CandidateComparator()); // 排序时间复杂度: O(N * lnN)
daddy.sort(new DaddyComparator()); // 排序时间复杂度: O(K * lnK)
// 移动更新区域 排序后候选区的第一个和得奖区的第一个进行比较,看是否发生移动
move(cands, daddy, k, i);
ans.add(getCurAns(daddy));
}
return ans;
}
/**
* 候选区和得奖区数据交换
* @param cands
* @param daddy
* @param k
* @param time
*/
public static void move(ArrayList<Customer> cands, ArrayList<Customer> daddy, int k, int time) {
// 候选区为空,不发生替换
if (cands.isEmpty()) {
return;
}
// 候选区不为空
if (daddy.size() < k) { // 得奖区没满
Customer c = cands.get(0);
c.enterTime = time;
daddy.add(c);
cands.remove(0);
} else { // 得奖区满了,候选区有东西
if (cands.get(0).buy > daddy.get(0).buy) {
Customer oldDaddy = daddy.get(0);
daddy.remove(0);
Customer newDaddy = cands.get(0);
cands.remove(0);
newDaddy.enterTime = time;
oldDaddy.enterTime = time;
daddy.add(newDaddy);
cands.add(oldDaddy);
}
}
}
public static void cleanZeroBuy(ArrayList<Customer> arr) {
List<Customer> noZero = new ArrayList<Customer>();
for (Customer c : arr) {
if (c.buy != 0) {
noZero.add(c);
}
}
arr.clear();
for (Customer c : noZero) {
arr.add(c);
}
}
public static List<Integer> getCurAns(ArrayList<Customer> daddy) {
List<Integer> ans = new ArrayList<>();
for (Customer c : daddy) {
ans.add(c.id);
}
return ans;
}
// 为了测试
public static class Data {
public int[] arr;
public boolean[] op;
public Data(int[] a, boolean[] o) {
arr = a;
op = o;
}
}
// 为了测试
public static Data randomData(int maxValue, int maxLen) {
int len = (int) (Math.random() * maxLen) + 1;
int[] arr = new int[len];
boolean[] op = new boolean[len];
for (int i = 0; i < len; i++) {
arr[i] = (int) (Math.random() * maxValue);
op[i] = Math.random() < 0.5 ? true : false;
}
return new Data(arr, op);
}
// 为了测试
public static boolean sameAnswer(List<List<Integer>> ans1, List<List<Integer>> ans2) {
if (ans1.size() != ans2.size()) {
return false;
}
for (int i = 0; i < ans1.size(); i++) {
List<Integer> cur1 = ans1.get(i);
List<Integer> cur2 = ans2.get(i);
if (cur1.size() != cur2.size()) {
return false;
}
cur1.sort((a, b) -> a - b);
cur2.sort((a, b) -> a - b);
for (int j = 0; j < cur1.size(); j++) {
if (!cur1.get(j).equals(cur2.get(j))) {
return false;
}
}
}
return true;
}
public static void main(String[] args) {
int maxValue = 10;
int maxLen = 100;
int maxK = 6;
int testTimes = 100000;
System.out.println("测试开始");
for (int i = 0; i < testTimes; i++) {
Data testData = randomData(maxValue, maxLen);
int k = (int) (Math.random() * maxK) + 1;
int[] arr = testData.arr;
boolean[] op = testData.op;
List<List<Integer>> ans1 = topK(arr, op, k);
List<List<Integer>> ans2 = compare(arr, op, k);
if (!sameAnswer(ans1, ans2)) {
for (int j = 0; j < arr.length; j++) {
System.out.println(arr[j] + " , " + op[j]);
}
System.out.println(k);
System.out.println(ans1);
System.out.println(ans2);
System.out.println("出错了!");
break;
}
}
System.out.println("测试结束");
}
}

若有收获,就点个赞吧
0 人点赞
