- 3.0、Flink Vs SparkStreaming
- 3.1、Architectural principles
- 3.2、Deploy
- https://flink.apache.org/downloads.html">1.下载flink安装包,下载地址:https://flink.apache.org/downloads.html
- 2.上传flink安装包到Linux服务器上
- 3.解压flink安装包
- 4.修改conf目录下的flink-conf.yaml配置文件
- 5.指定jobmanager的地址
- 6.指定taskmanager的可用槽位的数量
- 7.修改conf目录下的workers配置文件,指定taskmanager的所在节点
- 8.执行启动脚本
- 9.执行jps查看进程
- 10.访问JobManager的web管理界面,端口8081
- 3.4.2、Flink自定义Source操作
- 3.4.3、总结
- 3.5、Transformation
- 3.6、Window & Watermark
- 3.9、Probleam List
3.0、Flink Vs SparkStreaming
3.0.1、Concept
Spark围绕着速度、易用性、和复杂分析而生。
Flink围绕着高性能、稳定性和准确性,快速处理数据
3.0.2、Flink VS Spark
Flink
1、Flink计算模型是基于算子的流模型,实时处理流数据;在Flink中批处理被认为是特殊的一种流处理。
2、没有最小数据的延迟、带有一个独立于实际编程接口的优化器
3、基于流水线执行,处理速度比Spark要快;通过原生闭环算子,flink中的机器学习和图处理速度更快。
4、API比spark要少
5、编程语言提供了Java和Scala
6、Flink数据流运行的时候配置最少,可以实现低延迟和高吞吐;可以在批流两种处理模式下使用相同的算法
7、内部有自己的内存管理器,不同于GC;可以通过显式管理内存和消除内存峰值。
8、Flink基于Chandy-Lamport分布式快照的容错机制,而且是轻量级的、有助于保持高吞吐提供强大一致性保证
9、窗口标准基于记录或者用户自定义的。一般只处理一次记录来消除重复
Spark:
1、Spark计算模型基于微批处理模型,使用三方集群管理器操作;通过RDD抽象集来完成批数据处理。
2、和Flink相比,Spark有更高的延迟
3、在Spark中,作业需要手动优化,处理时间长
4、API层面很容易使用。高阶API提供了多种编程语言,如R,Scala,Python,Java
5、Spark中的迭代处理并不是基于原生的,在系统外实现为普通的for循环。
6、数据流在Spark中表示为DAG
7、Spark具有自动内存管理,提供了可配置的内存管理。
8、Spark中的窗口标准是基于时间的。
3.1、Architectural principles
3.1.1、特点
- 批流统一
- 支持高吞吐、低延迟‘高性能的流处理
- 支持有状态计算的Exactly-Once语义
- 支持高度灵活的窗口操作,如基于事件时间,基于会话时间,基于处理时间等。
- 支持Backpressure功能的持续流模型
- 支持基于轻量级Snapshot实现的容错
- 支持迭代计算
- 支持程序自动优化:即避免特定情况下的shuffle、排序等操作,中间结果有必要缓存
3.1.2、组件栈
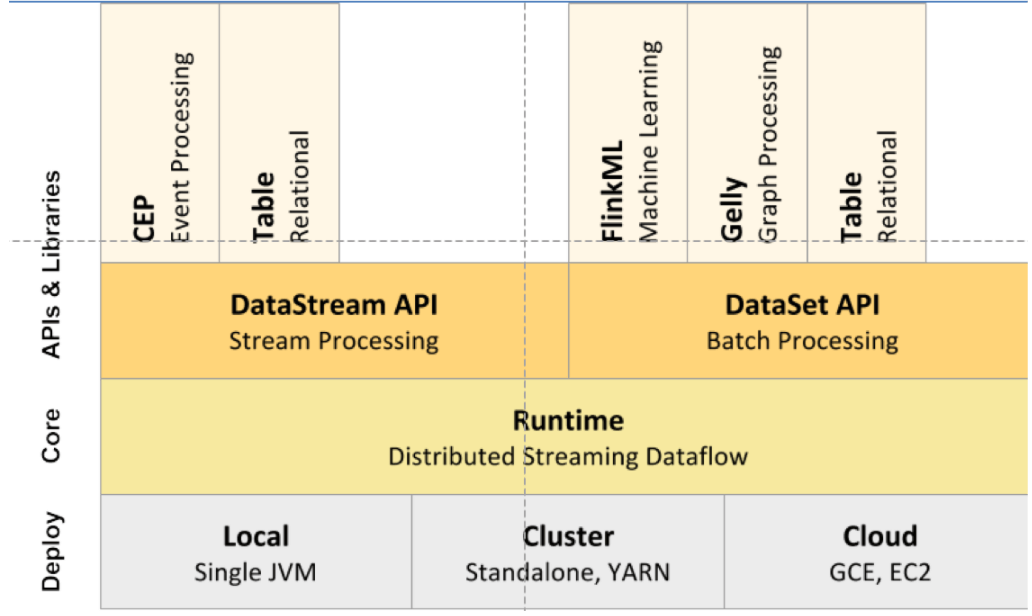
| 分层 | 功能 |
|---|---|
| Runtime层 | 支持Flink计算的全部核心实现,比如说:支持分布式Stream处理、JobGraph到ExecutionGraph的映射、调度等等,为上层API提供基础服务 |
| API层 | 主要实现了面向无界Stream的流处理和面向Batch的批处理API,其中面向流处理对应的DataStream API,面向批处理对应的DataSet API |
| Libaries层 | 面向流处理支持:CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作);面向批处理的支持:FlinkML(机器学习库)、Gelly(图处理) |
| Deploy层 | 主要涉及了Flink的部署模式,Flink支持多种部署模式:本地、集群(Standalone/YARN)、云(GCE/EC2) |

3.1.4、架构体系
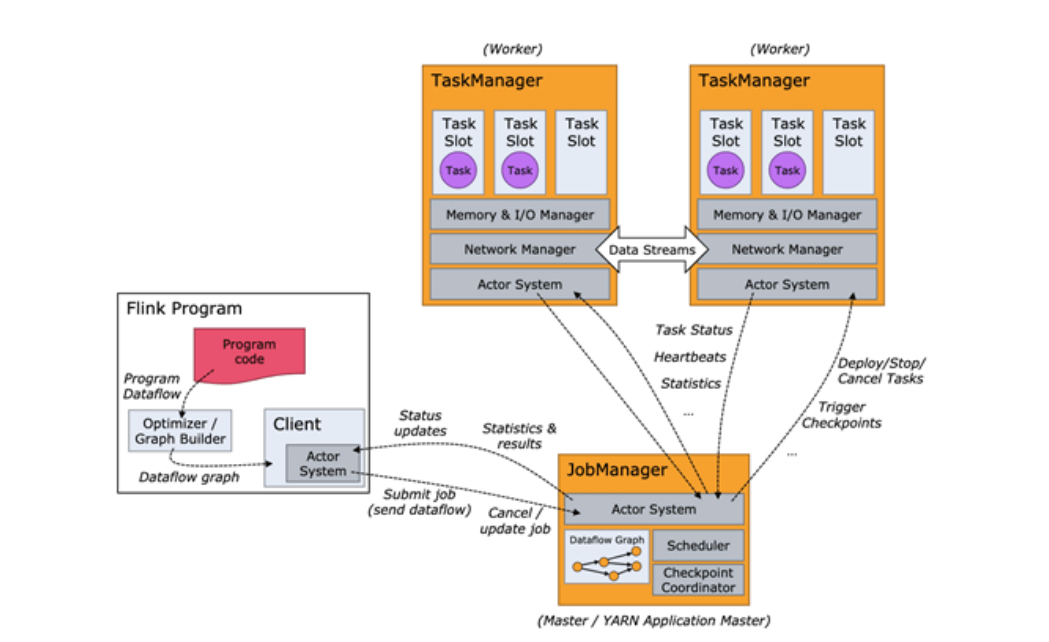
| 概念 | 功能 |
|---|---|
| JobManager | 也称为Master,主要用来调度task,协调checkpoit,失败时恢复等。Flink在运行时至少要有一个master运行,当配置HA模式时,有一个是leader,而其他的都是standby |
| TaskManager | 也称为Worker,用来执行一个DataFlow的task,数据缓冲和Data Streams的数据交换.Flink在运行时至少要有一个TaskManager.TaskManager通过RPC通信连接到JobManager,告知自身可用性从而获得任务分配 |
| Task | 一个阶段多个功能相同subTask的稽核,类似于Spark的TaskSet |
| subTask | Flink最小的执行单元,是一个java类的实例,有自身的属性和方法 |
| Slot | 计算资源隔离单元,一个Slot中可以运行多个subTask,但这些subTask必须来自同一个job的不同Task的subTask |
| State | Flink任务在运行过程中计算的中间结果 |
| CheckPoint | 将中间计算结果持久化的指定存储系统的一种定期执行的机制 |
| StateBackend | 用来存储中间计算结果的存储系统,Flink支持三种StateBackend,分别是Memory,FsBackend,RocksDB |
| Operator Chain | 没有shuffle的多个算子合并在一个subTask中就形成了Operator Chain,类似于Spark中的pipeline |
3.1.5、编程模型
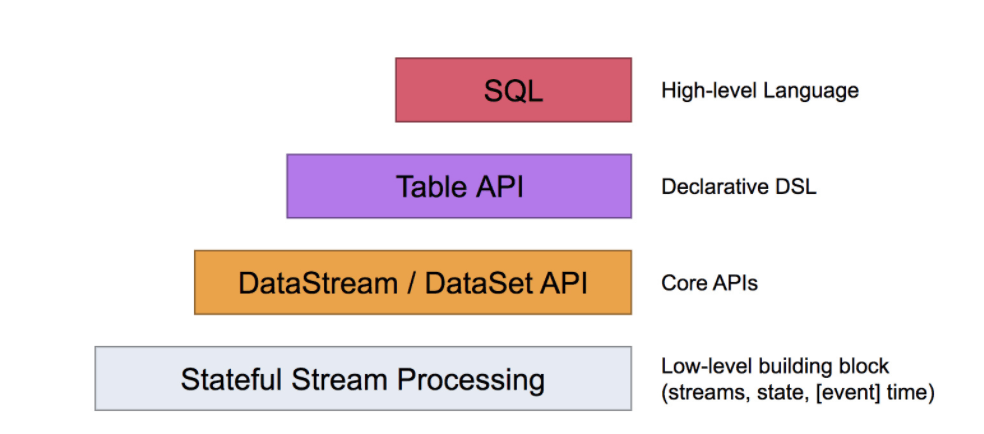
Flink提供了不同的抽象级别以开发流式或批处理应用:
- 最底层提供了有状态流。它将通过过程函数(Process Function)嵌入到DataStream API中。它允许用户可以自由处理来自一个或多个流数据的事件,并使用一致、容错的状态。除此之外,用户可以注册事件时间和处理事件回调,从而程序可以实现复杂的计算。
- DataStream/DataSet API 是Flink提供的核心API。DataSet处理有界的数据集,DataStream处理有界或无界的数据流。用户可以通过各种方法(map/flatmap/window/keyBy/sum/max/min/avg/join)等将数据进行转换/计算
- Table API:是以表为中心的声明式SQL,其中表可能会动态变化(在表达流数据时)。Table API提供了例如select、project、join、group-by、aggregate等操作,使用起来更加简洁。
- Flink提供了最高层级的抽象是SQL.这一层抽象在语法与表达能力上与Table API类似,但是以SQL查询表达式的形式表现程序。SQL抽象与Table API交互密切,同时SQL查询可以直接在Table API定义的表上执行
3.2、Deploy
3.2.1、Flink原生安装
```shell1.下载flink安装包,下载地址:https://flink.apache.org/downloads.html
2.上传flink安装包到Linux服务器上
3.解压flink安装包
tar -xvf flink-1.11.1-bin-scala_2.12.tgz -C /bigdata/
4.修改conf目录下的flink-conf.yaml配置文件
5.指定jobmanager的地址
jobmanager.rpc.address: localhost
6.指定taskmanager的可用槽位的数量
taskmanager.numberOfTaskSlots: 2
7.修改conf目录下的workers配置文件,指定taskmanager的所在节点
localhost
8.执行启动脚本
bin/start-cluster.sh
9.执行jps查看进程
jps
10.访问JobManager的web管理界面,端口8081
<a name="UY936"></a>### 3.2.2 Ambari集成Flink1、下载Flink二进制包<br />wget [http://www.us.apache.org/dist/flink/flink-1.7.2/flink-1.7.2-bin-hadoop27-scala_2.11.tgz](http://www.us.apache.org/dist/flink/flink-1.7.2/flink-1.7.2-bin-hadoop27-scala_2.11.tgz)<br />2、解压缩```shelltar -zxvf flink-1.7.2-bin-hadoop27-scala_2.11.tgzmv flink-1.7.2-bin-hadoop27-scala_2.11 /opt/flinkchown -R hdfs:hdfs /opt/flink
3、环境变量配置
vi /etc/profileexport FLINK_HOME=/opt/flinkexport PATH=$FLINK_HOME/bin:$PATH:wqsource /etc/profile
4、下载安装Ambari-Flink软件包
git clone https://github.com/abajwa-hw/ambari-flink-service.gitmv ambari-flink-server /var/lib/ambari-server/resources/stacks/HDP/$VERSION/services/FLINK
5、重启ambari-server
ambari-server restart
6、安装flink

7、修改yarn参数
<property><name>yarn.client.failover-proxy-provider</name><value>org.apache.hadoop.yarn.client.RequestHedgingRMFailoverProxyProvider</value></property>
8、重启yarn
9、测试
flink run --jobmanager yarn-cluster \-yn 1 \-ytm 768 \-yjm 768 \/opt/flink/examples/batch/WordCount.jar \--input hdfs://hdp1:8020/user/hdfs/demo/input/word \--output hdfs://hdp3:8020/user/hdfs/demo/output/wc/
10、flink sql client
sql-client.sh embedded

11、错误解决
java.lang.NoClassDefFoundError: com/sun/jersey/core/util/FeaturesAndProperties
解决方案:在flink的lib包里面添加如下的两个jar包
12、wordcount
/****从一个Socket端口中实时的读取数据,然后实时统计相同单词出现的次数,该程序会一直运行*启动程序前先使用nc -l 8888启动一个socket用来发送数据*/public class StreamingWordCount {public static void main(String[] args) throws Exception {//创建流式计算的ExecutionEnvironmentStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//调用Source,指定Socket地址和端口DataStream<String> lines = env.socketTextStream("localhost", 10088);DataStream<Tuple2<String, Integer>> words = lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic void flatMap(String line, Collector<Tuple2<String, Integer>> collector)throws Exception {String[] words = line.split(" ");for (String word : words) {collector.collect(Tuple2.of(word, 1));}}});//按照key分组并聚合DataStream<Tuple2<String, Integer>> result = words.keyBy(0).sum(1);//将结果打印到控制台result.print();//执行env.execute("StreamingWordCount");}}
3.3、Submit mode
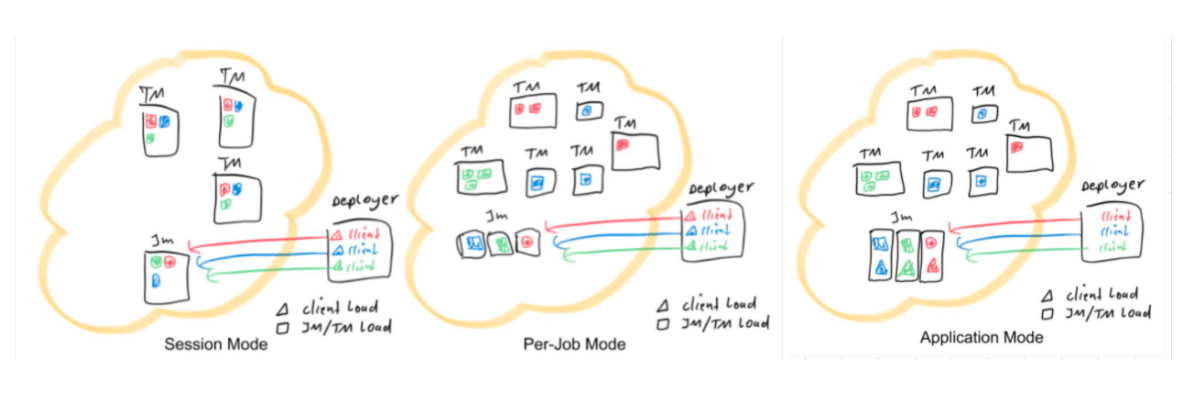
3.3.1、Session mode
流程:
1、该模式首先会预分配资源,根据指定的资源参数提前初始化一个Flink集群,常驻于Yarn中(本文中都是基于Yarn的资源管理器),并启动一个JobManager和固定数量的TaskManager。
2、这个时候可以直接提交作业运行,节省了申请资源分配的开销。
总结:
1、这种模式下所有的作业共享这些固定的资源,而且作业之间不能隔离,会出现资源竞争的情况。
2、当一个TM发生故障宕机后,那么所有在这个节点上的作业都会失败。
3、当提交运行越来越多的Job后,JM的负载压力也会越高。
场景:
因此该模式通常用于部署一些运行时间短,对延迟要求性不高的任务。
3.3.2、Per-Job mode
该模式见名知意,即每个作业Job提交到Yarn上形成自己独立的Flink集群,即拥有作业自己的JobManager和TaskManager。
1、因此在提交作业的时候,由于需要单独的申请资源,因此启动延迟会相对比较高;
2、但是作业之间的资源是隔离的,也就是说作业之间是相互独立的,不会相互造成影响,一个Job的TaskManager失败不会影响到其他的作业运行;
3、另外JobManager也是相互独立的,负载不会相当那么高;
4、当job完成后,分配的资源就会得到释放回收。不像Session模式资源属于常占的。
场景:
基于以上几点特性,Per-Job模式一般用于提交长时间运行的作业。通常生产环境使用该种模式
3.3.3、Per-Job Vs Session Mode
通常来讲,无论是Per-job模式还是Session模式,都需要一个客户端入口向Yarn发起提交请求,用来提交作业。那么在main方法执行之前,直到env.execute()方法,客户端还需要做一些工作:
1、需要获取作业相关依赖
2、分析执行环境并获取逻辑计划,通常来讲就是从StreamGraph到JobGraph的生成。
3、将依赖和JobGraph上传到集群
当以上工作做完之后,Flink Runtime将会被触发,并通过env.execute方法执行job。
那么这个时候思考一下,如果在初始化分析并获取依赖阶段,如果依赖东西非常多且很大,那么就会占用更多的带宽;如果业务执行逻辑非常复杂,那么在解析转换逻辑计划生成JobGraph的时候就需要更多的内存和CPU。因此基于这种场景下,客户端资源将会成为一个瓶颈。
当然上述描述的场景问题在两种提交模式中都会存在。因此出现了第三种提交模式,即Application mode
3.3.4、Application mode(Flink1.11+)
1、针对客户端做大量的前期工作的问题:client所做的一些事情都被转移到JM上来做了,也就是说程序主方法在集群中进行执行,入口点在ApplicationClusterEntryPoint。那么开发者只需要负责发起提交请求。
另外如果在主方法内在多个env.execute()/executeAsync()被调用,那么在Application 模式下,这些作业都被看作是同一个应用程序(如果是以per-job模式提交,那么会启动多个应用程序)。这么看来的话,application模式其实是per-job模式和session模式的折中方案。
2、针对依赖传输造成的带宽占用问题:flink作业需要依赖的包有flink-dist.jar(发布用的)、扩展包(位于{FLINK_HOME}/lib)、插件库(${FLINK_HOME/plugin})、用户jar包。那么针对这些依赖包,我们可以提前上传到HDFS上,然后通过yarn.provided.lib.dirs参数来指定存储路径。
通过这种方式,所有的flink作业不用重复上传依赖包,这样就可以直接从hdfs上拉取,而且NodeManager也会缓存这些依赖包进一步加速作业提交。
使用application模式提交demo
bin/flink run-application -t yarn-application \-Djobmanager.memory.process.size=2048m \-Dtaskmanager.memory.process.size=4096m \-Dtaskmanager.numberOfTaskSlots=2 \-Dparallelism.default=10 \-Dyarn.application.name="MyFlinkApp" \-Dyarn.provided.lib.dirs="hdfs://myhdfs/flink-common-deps/lib;hdfs://myhdfs/flink-common-deps/plugins"
3.3.5、 Session mode Vs Per-Job mode Vs Application mode
3.4、Source
3.4.1、Flink预定义Source操作
在flink中,source主要负责数据的读取。
flink预定义的source中又分为并行source(主要实现ParallelSourceFunction接口)和非并行source(主要实现了SourceFunction接口)
附上官网相关的说明:
you can always write your own custom sources by implementing the SourceFunction for non-parallel sources, or by implementing the ParallelSourceFunction interface or extending the RichParallelSourceFunction for parallel sources
3.4.1.1、基于File的数据源
1.1底层原理
Flink在进行文件读取的时候会启动两个subTask,一个subTask用来监听,另外一个subTask用来数据读取。且监听的subTask是属于非并行的,即并行度为1,而数据读取的subTask是属于并行的 ,通常并行度和job的并行度是一致的
readTextFile(path):逐行读取文本文件,将符合TextInputFormat规范的文件,作为字符串返回readFile(fileInputFormat, path):根据指定的文件输入格式读取readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo):上面两个方法底层其实调用的就是该方法
1.2 代码
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());DataStreamSource<String> textSource = env.readTextFile("/data/GitCode/flink/src/main/resources/word.txt");//如果不设置并行度的话,这里会跟机器的核数一致int parallelism = textSource.getParallelism();System.out.println("textFile并行度:" + parallelism);textSource.print();env.execute("TextFileSourceDemo");}
3.4.1.2、基于Socket的数据源(一般用于学习,测试)
2.1、底层原理
通常调用socketTextStream方法来接收socket数据,元素可以用分隔符分开,该方法底层实现了SourceFunction接口,是属于非并行source
2.2、代码
public static void main(String[] args) throws Exception {//并行度和系统核数一致StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//非并行的source,只有1个并行度DataStreamSource<String> lines = env.socketTextStream(args[0], Integer.parseInt(args[1]));int parallelism = lines.getParallelism();System.out.println("socketTextStream并行度:"+parallelism);SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = lines.flatMap((String line, Collector<Tuple2<String, Integer>> out) -> Arrays.stream(line.split(" ")).forEach(word -> out.collect(Tuple2.of(word, 1)))).returns(Types.TUPLE(Types.STRING, Types.INT));SingleOutputStreamOperator<Tuple2<String, Integer>> summed = wordAndOne.keyBy(t -> t.f0).sum(1);summed.print();env.execute("WordCount");}
3.4.1.3、基于集合的数据源(学习,测试)
从集合中创建一个数据流,集合中所有的元素类型都是一致的.其底层调用了SourceFunction接口,属于非并行source。注意:fromParallelCollection方法是属于并行的,底层调用了RichParallelSourceFunction接口
fromCollection(Collection)
val list=List(1,2,3,4,5,6,7,8,9)val inputStream=env.fromCollection(list)
fromCollection(Iterator, Class)
val iterator=Iterator(1,2,3,4)val inputStream=env.fromCollection(iterator)
fromElements(T …)
从一个给定的对象序列中创建一个数据流,所有的对象必须是相同类型的。DataStreamSource<Integer> fromSource = env.fromElements(1, 2, 3, 4);int parallelism = fromSource.getParallelism();System.out.println("fromElements并行度:" + parallelism);
generateSequence(from, to)
从给定的间隔中并行地产生一个数字序列。
val inputStream = env.generateSequence(1,10)
3.4.1.4、基于Kafka的数据源(重点)
这里给出简单的入门示例,实际工作场景中需要考虑到容错、数据一致性、分区发现、结合水印实现一些窗口操作等功能
public class kafkaSource {private static Properties properties = new Properties();private static final String BOOTSTRAPLIST = "hdp1:6667,hdp2:6667";private static final String GROUPID = "metric-group";private static final String TOPIC = "metric";static {properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAPLIST);properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");properties.put(ConsumerConfig.GROUP_ID_CONFIG, GROUPID);properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");}public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());DataStreamSource<String> kafkaSource = env.addSource(new FlinkKafkaConsumer<String>(TOPIC, new SimpleStringSchema(), properties));kafkaSource.print();env.execute();}}
3.4.2、Flink自定义Source操作
3.4.2.1、非并行Source
即实现SourceFunction接口
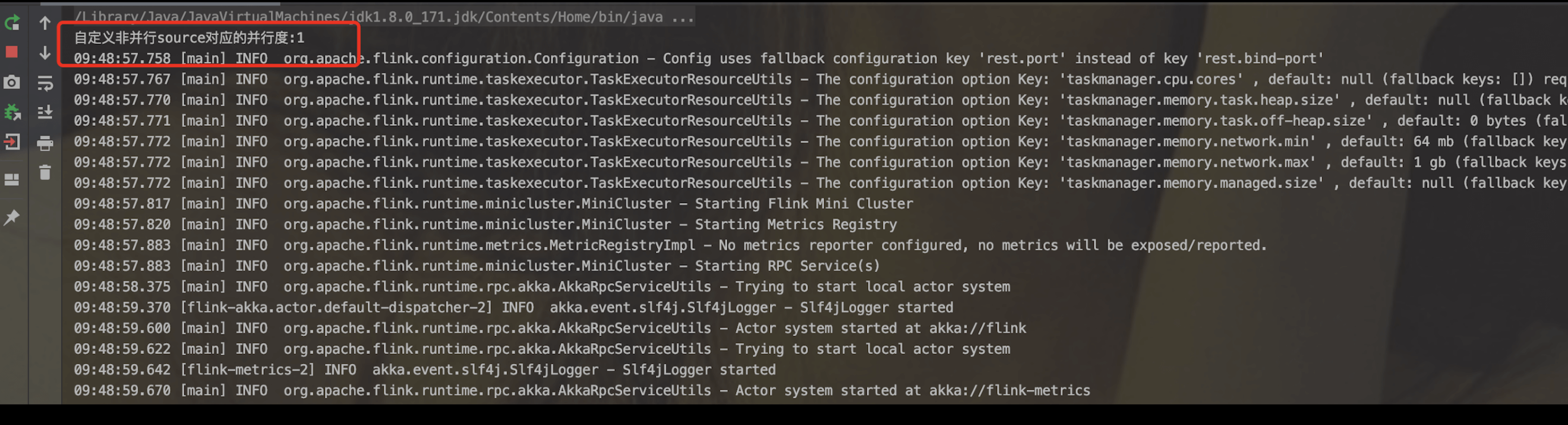
public class CustomNonParallelSource {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());List<String> list = new ArrayList<>();list.add("Spark");list.add("Hadoop");list.add("Flink");list.add("HBase");list.add("Es");SingleOutputStreamOperator<String> singleOutputStreamOperator = env.addSource(new MyWordSource(list)).returns(String.class);System.out.println("自定义非并行source对应的并行度:" + singleOutputStreamOperator.getParallelism());singleOutputStreamOperator.print();env.execute();}static class MyWordSource implements SourceFunction<String> {private List<String> words;private boolean isStop = false;public MyWordSource() {}public MyWordSource(List<String> words) {this.words = words;}@Overridepublic void run(SourceContext<String> ctx) throws Exception {if (words != null && words.size() > 0) {while (!isStop) {words.forEach(word -> ctx.collect(word));}}}@Overridepublic void cancel() {isStop = true;}}}
3.4.2.2、并行Source
通过实现ParallelSourceFunction接口或者继承RichParallelSourceFunction来定义并行source。
其中RichParallelSourceFunction功能更加丰富些,可以获取上下文信息,提供open和close方法等更加强大的功能
简单的实时流
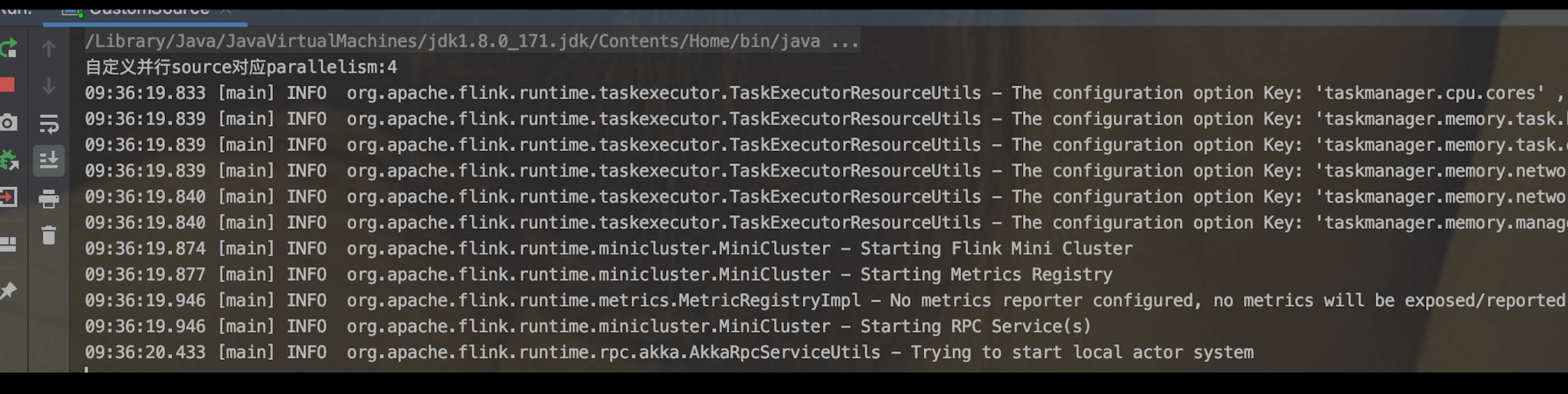
public class CustomSource {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();List<String> words = new ArrayList<>();words.add("spark");words.add("hadoop");words.add("flink");// DataStreamSource<String> wordsSource = env.addSource(new MyWordSource(words));SingleOutputStreamOperator singleOutputStreamOperator = env.addSource(new MyWordParallelSource(words)).returns(String.class);// 如果不设置并行度,则和系统核数一致System.out.println("自定义并行source对应parallelism:" + singleOutputStreamOperator.getParallelism());singleOutputStreamOperator.print();env.execute("CustomSource");}static class MyWordParallelSource extends RichParallelSourceFunction {private boolean isStop = false;private List<String> words;public MyWordParallelSource() {}/*** 通常在该方法做一些初始化的工作,如创建数据库连接等* @param parameters* @throws Exception*/@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);}/*** 释放资源* @throws Exception*/@Overridepublic void close() throws Exception {super.close();}public MyWordParallelSource(List<String> word) {this.words = word;}@Overridepublic void run(SourceContext ctx) throws Exception {int numberOfParallelSubtasks = getRuntimeContext().getNumberOfParallelSubtasks();while (!isStop) {if (words != null && words.size() > 0) {words.forEach(word -> ctx.collect(numberOfParallelSubtasks + "--->" + word));}Thread.sleep(2000);}}/*** 该方法对无界数据流有作用*/@Overridepublic void cancel() {isStop = true;}}static class MyWordSource extends RichSourceFunction<String> {private List<String> words;private boolean flag = true;public MyWordSource(List<String> words) {this.words = words;}/*** 产生数据,用sourceContext将数据发生出去** @param sourceContext* @throws Exception*/@Overridepublic void run(SourceContext sourceContext) throws Exception {//获取当前subTask的运行上下文RuntimeContext runtimeContext = getRuntimeContext();int indexOfThisSubtask = runtimeContext.getIndexOfThisSubtask();while (flag) {if (words != null && words.size() > 0) {words.forEach(word -> sourceContext.collect(indexOfThisSubtask + "--->" + word));}Thread.sleep(2000);}}/*** 停止source,对于无界数据流有用*/@Overridepublic void cancel() {flag = false;}}}
3.4.2.3、自定义source读取mysql
public class MysqlSource extends RichSourceFunction<Student> {private static Logger logger = LoggerFactory.getLogger(MysqlSource.class);private static final String URL ="jdbc:mysql://localhost:3306/hibernate?useUnicode=true&characterEncoding=UTF-8";private static final String USERNAME="root";private static final String PASSWORD="123456";PreparedStatement preparedStatement;private Connection connection;private static Connection getConnection() {Connection connection = null;try {Class.forName("com.mysql.jdbc.Driver");connection = DriverManager.getConnection(URL, USERNAME, PASSWORD);} catch (Exception e) {logger.error("创建Mysql连接异常,信息:[{}]",e);e.printStackTrace();}return connection;}/*** open()方法中建立连接,这样不用每次invoke的时候建立和释放连接** @param parameters* @throws Exception*/@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);connection = getConnection();String sql = "select * from student";preparedStatement = this.connection.prepareStatement(sql);}/*** DataStream调用一次run方法用来获取数据* @param ctx* @throws Exception*/@Overridepublic void run(SourceContext<Student> ctx) throws Exception {ResultSet resultSet =preparedStatement.executeQuery();while (resultSet.next()){Student student = new Student(resultSet.getInt("id"),resultSet.getString("name").trim(),resultSet.getString("password").trim(),resultSet.getInt("age"));ctx.collect(student);}}@Overridepublic void cancel() {}/*** 关闭时释放连接* @throws Exception*/@Overridepublic void close() throws Exception {super.close();if(connection!=null){connection.close();}if(preparedStatement!=null){preparedStatement.close();}}}
3.4.3、总结

3.5、Transformation
一个流的转换操作将会应用在一个或者多个流上面,这些转换操作将流转换成一个或者多个输出流,将这些转换算子组合在一起来构建一个数据流图。大部分的数据流转换操作都是基于用户自定义函数udf。udf函数打包了一些业务逻辑并定义了输入流的元素如何转换成输出流的元素。像MapFunction这样的函数,将会被定义为类,这个类实现了Flink针对特定的转换操作暴露出来的接口。
DataStream API针对大多数数据转换操作提供了转换算子,这里将转换算子分为四类:
- 基本转换算子:将会作用在数据流中的每一条单独的数据上
- KeyedStream转换算子:在数据有key的情况下,对数据应用转换算子。
- 多流转换算子:合并多条流为一条流或者将一条流分割为多条流
- 分布式转换算子:将重新组织流里面的事件。
3.5.1、基本转换算子
基本转换算子会针对流中的每一个单独的事件做处理,也就是说每一个输入数据会产生一个输出数据。单值转换,数据分割,数据过滤,都是基本转换操作的典型例子.
3.5.1.1、map
类型转换:DataStream → DataStream
作用:map算子将每一个输入的事件传送到用户自定义的一个mapper,这个mapper只返回一个输出事件
实现原理:底层调用的是transform方法,真正实现逻辑封装在StreamMap类中,该类底层实现了OneInputStreamOperator接口,在processElement方法中实现具体的功能
public <R> SingleOutputStreamOperator<R> map(MapFunction<T, R> mapper, TypeInformation<R> outputType) {return transform("Map", outputType, new StreamMap<>(clean(mapper)));}
操作案例:
功能:将字符串转为大写
方式一:直接调用原生的map算子
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);//方式一:调用原生自带的map算子SingleOutputStreamOperator<String> wordSource = socketTextStream.map(word -> word.toUpperCase());wordSource.print();env.execute();
方式二:调用底层的transform算子重定义实现
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);//方式二:SingleOutputStreamOperator<String> wordSource = socketTextStream.transform("MyMap", TypeInformation.of(String.class), new StreamMap<>(String::toUpperCase));wordSource.print();env.execute();
方式三:继承实现类自定义实现
/*** 类似于StreamMap操作*/static class MyStreamMap extends AbstractStreamOperator<String> implements OneInputStreamOperator<String, String> {@Overridepublic void processElement(StreamRecord<String> element) throws Exception {String elementValue = element.getValue();output.collect(element.replace(elementValue.toUpperCase()));}}StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);SingleOutputStreamOperator<String> wordSource = socketTextStream.transform("MyStreamMap", TypeInformation.of(String.class), new MyStreamMap());wordSource.print();env.execute();
方式四:实现RichMapFunction类
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);SingleOutputStreamOperator<String> wordSource = socketTextStream.map(new RichMapFunction<String, String>() {/*** 在构造对象之后,执行map方法之前执行一次* 通常用于初始化工作,例如连接创建等* @param parameters* @throws Exception*/@Overridepublic void open(Configuration parameters) throws Exception {super.open(parameters);}/*** 在关闭subtask之前执行一次,例如做一些释放资源的工作* @throws Exception*/@Overridepublic void close() throws Exception {super.close();}@Overridepublic String map(String s) throws Exception {int indexOfThisSubtask = getRuntimeContext().getIndexOfThisSubtask();return indexOfThisSubtask + ":" + s.toUpperCase();}});wordSource.print();env.execute();
3.5.1.2、flatmap
类型转换:DataStream → DataStream
作用:和map算子比较类似,不同之处在于针对每一个输入事件flatMap会生成0个、1个或多个输出元素。
实现原理:同map实现原理一样,底层调用的是transform方法,真正实现逻辑封装在StreamMap类中,该类底层实现了OneInputStreamOperator接口,在processElement方法中实现具体的功能
操作案例:
功能:将一行记录按照空格分割,并转换为大写
方式一:直接调用原生算子,其他方式同map算子
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);SingleOutputStreamOperator<String> flatMap = socketTextStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String s, Collector<String> collector) throws Exception {Arrays.stream(s.split(" ")).forEach(word -> collector.collect(word.toUpperCase()));}});flatMap.print();env.execute("FlatMapDemo");//如输入 a b c//最后输出ABC
3.5.1.3、filter
类型转换:DataStream → DataStream
作用:通过在每个输入事件上对一个布尔条件进行求值来过滤掉一些元素,然后将剩下的元素继续发送。一个true的求值结果会把输入事件保留下来并发送到输出,而如果求值结果为false,则输入事件会被抛弃掉
实现原理:底层调用的是transform方法,真正实现逻辑封装在StreamFilter类中,该类底层实现了OneInputStreamOperator接口,在processElement方法中实现具体的功能
操作案例:
功能:仅保留以A开头的字符串
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);socketTextStream.filter(word->word.startsWith("A")).print();env.execute("FilterDemo");//如输入bcaadAbAc//最后得到的结果为AbAc
3.5.2、KeyedStream转换算子(通常和window配合使用)
3.5.2.1、KeyBy
类型转换:DataStream → KeyedStream
作用:其实就是按照key进行分组,根据不同的key分配到不同的分区中,所有具有相同key的事件会在同一个slot中进行处理
实现原理:
- 根据key进行hash运算得到hash值,即变量keyHash
- 使用murmurHash公式进行计算,即调用murmurHash(keyHash)
- 对murmurHash和最大并行度进行求余运算得到变量keyGroupId = murmurHash%maxParallelism
- 计算并行度索引Index = (keyGroupId*parallelism)/maxParallelism
操作案例:public static int assignKeyToParallelOperator(Object key, int maxParallelism, int parallelism) {Preconditions.checkNotNull(key, "Assigned key must not be null!");return computeOperatorIndexForKeyGroup(maxParallelism, parallelism, assignToKeyGroup(key, maxParallelism));}//1.计算key的hashCode值public static int assignToKeyGroup(Object key, int maxParallelism) {Preconditions.checkNotNull(key, "Assigned key must not be null!");return computeKeyGroupForKeyHash(key.hashCode(), maxParallelism);}//2.使用murmurHash进行计算,并和最大并行度进行求余运算public static int computeKeyGroupForKeyHash(int keyHash, int maxParallelism) {return MathUtils.murmurHash(keyHash) % maxParallelism;}//3.计算获取索引public static int computeOperatorIndexForKeyGroup(int maxParallelism, int parallelism, int keyGroupId) {return keyGroupId * parallelism / maxParallelism;}
功能:基于key进行求和统计
方式一:针对Tuple类型,使用下标进行分组 ```java StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSourcesocketTextStream = env.socketTextStream(“localhost”, 8888);
socketTextStream.map(word-> Tuple3.of(word.split(“ “)[0],word.split(“ “)[1],Double.valueOf(word.split(“ “)[2]))) .returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class,String.class,Double.class)) .keyBy(t->t.f0+t.f1 ) //这里不支持 In many cases lambda methods don’t provide enough information for automatic type extraction .sum(2) .print();
env.execute(“KeyByDemo”);
方式二:针对Bean,使用字段名称进行分<br />注意:该种方式下,Bean中的字段不能私有化,且必须要有无参构造器<br />WordCount Bean```javapublic class WordCount {public String word;public Integer count;public WordCount() {}public WordCount(String word, Integer count) {this.word = word;this.count = count;}public static WordCount of(String word, Integer count) {return new WordCount(word, count);}public String getWord() {return word;}public void setWord(String word) {this.word = word;}public Integer getCount() {return count;}public void setCount(Integer count) {this.count = count;}@Overridepublic String toString() {return "WordCount{" +"word='" + word + '\'' +", count=" + count +'}';}}StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);socketTextStream.map(words->WordCount.of(words,1)).returns(WordCount.class).keyBy(WordCount::getWord).sum("count").print();
方式三:实现KeySelector类
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);socketTextStream.map(word -> Tuple3.of(word.split(" ")[0], word.split(" ")[1], Double.valueOf(word.split(" ")[2]))).returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class, String.class, Double.class)).keyBy(new KeySelector<Tuple3<String, String, Double>, String>() {@Overridepublic String getKey(Tuple3<String, String, Double> value) throws Exception {return value.f0 + value.f1;}}).sum(2).print();env.execute("KeyByDemo");
3.5.2.2、fold(已过时)
类型转换:KeyedStream → DataStream
作用:合并当前元素和前一次折叠操作的结果,并产生一个新的值,返回的流中包含每一次折叠的结果,而不是只返回最后一次折叠的结果
实现原理:还是调用transform方法,逻辑封装在StreamGroupedFold类中,该类实现了OneInputStreamOperator和OutputTypeConfigurable接口,其中有一个value的判断逻辑
OUT value = values.value();//如果前一次折叠的结果不为空,则和当前结果进行合并,并更新,否则取当前结果(即初始化)if (value != null) {OUT folded = userFunction.fold(outTypeSerializer.copy(value), element.getValue());values.update(folded);output.collect(element.replace(folded));} else {OUT first = userFunction.fold(outTypeSerializer.copy(initialValue), element.getValue());values.update(first);output.collect(element.replace(first));}
操作案例:
功能:按照key进行sum求和
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);socketTextStream.flatMap((String words, Collector<Tuple2<String,Integer>> out)-> Arrays.stream(words.split(" ")).forEach(word-> out.collect(Tuple2.of(word,1)) )).returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class,Integer.class)).keyBy(t->t.f0).fold(Tuple2.of("", 0), new FoldFunction<Tuple2<String, Integer>, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> fold(Tuple2<String, Integer> tuple2, Tuple2<String, Integer> o) throws Exception {//tuple2为中间存储的结果或初始化值o.f1 = o.f1 + tuple2.f1;return o;}}).print();env.execute("FoldDemo");//如输入a 10a 20a 30//最后得到a 60
3.5.2.3、sum/min/minBy/max/maxBy
类型转换:KeyedStream → DataStream
作用:分组数据流上的滚动聚合操作,即按照key进行求最大值/最小值/求和等操作。这里只给出min和minBy的区别,其他都类似。
其中min和minBy的区别是min返回的是一个最小值,而minBy返回的是其字段中包含最小值的元素,返回的流中包含每一次聚合的结果,而不是只返回最后一次聚合的最终结果。
通俗来讲当有多个字段时,min的作用是对其中指定字段进行分组取最小值,而不关心其他字段,结果中只会取第一次出现的字段;而minBy按照指定字段返回最小值所在的记录,其中有一个布尔值参数,当为false时,则取最小值的最新记录
实现原理:底层调用的还是transform方法,具体的实现逻辑封装在StreamGroupedReduce类中,该类也是实现了OneInputStreamOperator接口
IN value = element.getValue();IN currentValue = values.value();//可以看到最底层调用的其实是用户自定义函数if (currentValue != null) {IN reduced = userFunction.reduce(currentValue, value);values.update(reduced);output.collect(element.replace(reduced));} else {values.update(value);output.collect(element.replace(value));}
操作案例:
功能:一条记录中包含3个字符,用逗号分隔,最后一个字符为整数类型,按照切分后的第一个字段为key取最小值
方式一:调用minBy算子,first参数为false
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);socketTextStream.map(word -> Tuple3.of(word.split(",")[0], word.split(",")[1], Integer.valueOf(word.split(",")[2]))).returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class, String.class, Integer.class)).keyBy(t -> t.f0).minBy(2,false).print();env.execute("MinMinByDemo");//如输入hadoop,spark,1hadoop,hadoop,2hadoop,spark,10 -->根据hadoop为key,取最小值spark,hadoop,50spark,test,40spark,teste,100spark,hadoop,200 -->根据spark为key,取最小值//结果输出4> (hadoop,spark,1)4> (hadoop,spark,1)4> (hadoop,spark,1)1> (spark,hadoop,50)1> (spark,test,40)1> (spark,test,40)1> (spark,test,40)
方式二:调用minBy算子,first参数为true
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);socketTextStream.map(word -> Tuple3.of(word.split(",")[0], word.split(",")[1], Integer.valueOf(word.split(",")[2]))).returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class, String.class, Integer.class)).keyBy(t -> t.f0).minBy(2,false).print();//如输入spark,hadoop,50spark,test,40spark,teste,100spark,hadoop,200flink,hadoop,400spark,Hadoop,400flink,spark,300flink,java,500flink,spark,400flink,es,100spark,java,300spark,flink,300flink,java,50//最终输入1> (spark,hadoop,50)1> (spark,test,40)1> (spark,test,40)1> (spark,test,40)4> (flink,hadoop,400)1> (spark,test,40)4> (flink,spark,300)4> (flink,spark,300)4> (flink,spark,300)4> (flink,es,100)1> (spark,test,40)1> (spark,test,40)4> (flink,java,50) --即获取最小值所在的记录
方式三:调用min算子
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);socketTextStream.map(t -> Tuple2.of(t.split(",")[0], Integer.valueOf(t.split(",")[1]))).returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class, Integer.class)).keyBy(t -> t.f0).min(1).print();env.execute();
3.5.2.4、reduce
类型转换:KeyedStream → DataStream
作用:合并当前元素和上次聚合的结果,产生一个新值,和fold算子比较类似
实现原理:和fold算子一致
操作案例:
功能:简单的单词统计
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);socketTextStream.flatMap((String words, Collector<Tuple2<String,Integer>> out)-> Arrays.stream(words.split(" ")).forEach(word->out.collect(Tuple2.of(word,1)))).returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class,Integer.class)).keyBy(t->t.f0).reduce(new ReduceFunction<Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> reduce(Tuple2<String, Integer> stringIntegerTuple2, Tuple2<String, Integer> t1) throws Exception {stringIntegerTuple2.f1 = stringIntegerTuple2.f1 + t1.f1;return stringIntegerTuple2;}}).print();env.execute("ReduceByDemo");//如输入abcdeafdadc//最终结果为3> (a,1)1> (b,1)2> (c,1)3> (d,1)1> (e,1)3> (a,2)1> (f,1)3> (d,2)3> (a,3)3> (d,3)2> (c,2)
3.5.3、多流转换算子
3.5.3.1、union
类型:多个DataStream→ DataStream
作用:对两个或两个以上的DataStream进行union操作,产生一个包含所有DataStream元素的新DataStream
实现原理:底层会重新创建一个DataStream对象,并把原来老的多个DataStream对象放到一个list表中,进行校验类型是否一致,其中DataStream构造器参数有一个UnionTransformation类,底层继承了Transformation类
List<Transformation<T>> unionedTransforms = new ArrayList<>();unionedTransforms.add(this.transformation);for (DataStream<T> newStream : streams) {if (!getType().equals(newStream.getType())) {throw new IllegalArgumentException("Cannot union streams of different types: "+ getType() + " and " + newStream.getType());}unionedTransforms.add(newStream.getTransformation());}return new DataStream<>(this.environment, new UnionTransformation<>(unionedTransforms));
操作案例:
功能:合并元素
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<Integer> source1 = env.fromElements(1, 2, 3, 4, 5);DataStreamSource<Integer> source2 = env.fromElements(11, 22, 33, 44, 55);DataStream<Integer> unionSource = source1.union(source2);unionSource.print();env.execute();
3.5.3.2、connect
类型:DataStream,DataStream → ConnectedStreams
作用:连接两个保持各自类型的数据流,两个流被connect之后,只是被放在了同一个流中,但是内部仍然是保持着各自的数据类型和形式,并且相互独立
实现原理:内部重新创建了一个ConnectedStreams对象,且该对象内部重写了大部分常用算子,包含上面总结的算子,但是算子名称和基本算子不太一致,如map算子称为Co-Map,flatMap算子成为Co-Flat Map
操作案例:
功能:字符串和int类型DataStream进行关联,并增加不同的前缀
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<Integer> stream1 = env.fromElements(1, 2, 3, 4, 5);DataStreamSource<String> streamStr = env.fromElements("hello", "str", "good");ConnectedStreams<Integer, String> connect = stream1.connect(streamStr);connect.map(new CoMapFunction<Integer, String, String>() {@Overridepublic String map1(Integer value) throws Exception {return "hhhh1"+value;}@Overridepublic String map2(String value) throws Exception {return "11111"+value;}}).print();env.execute("ConnectDemo");}//最后结果为2> hhhh133> 11111hello4> hhhh111> hhhh121> 11111good4> 11111str4> hhhh153> hhhh14
3.5.4、分布式转换算子
针对于flink的分区,有五种类型:shuffle,轮询,global,广播和自定义;8种分区器(这里只给出6种,剩下的两种比较简单,有兴趣的读者可以自行阅读)
3.5.4.1、8种分区器

3.5.4.2、五种分区类型
1、shuffle
Random
类型转换:DataStream → DataStream
作用:将数据随机的分配到下游算子的并行任务中去。
实现原理:底层创建ShufflePartitioner对象,该对象继承了StreamPartitioner。具体逻辑如下:
//根据并行度个数随机分配public int selectChannel(SerializationDelegate<StreamRecord<T>> record) {return random.nextInt(numberOfChannels);}
操作案例:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//非并行sourceDataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);//获取读取source时的并行度为1int sourceParallelism = socketTextStream.getParallelism();System.out.println("读取socket source并行度:" + sourceParallelism);SingleOutputStreamOperator<String> mapped = socketTextStream.map(new RichMapFunction<String, String>() {@Overridepublic String map(String value) throws Exception {int index = getRuntimeContext().getIndexOfThisSubtask();return index + "-->" + value;}}).setParallelism(2);//获取map之后的并行度,这里得到手动设置的2int mappedParallelism = mapped.getParallelism();System.out.println("经过map之后的并行度:" + mappedParallelism);DataStream<String> shuffle = mapped.shuffle();//获取shuffle之后的并行度,这里的值和系统核数保持一致int shuffleParallelism = shuffle.getParallelism();System.out.println("经过shuffle之后的并行度:" + shuffleParallelism);shuffle.addSink(new RichSinkFunction<String>() {@Overridepublic void invoke(String value, Context context) throws Exception {System.out.println(getRuntimeContext().getIndexOfThisSubtask() + "--->" + value);}});env.execute();
2、轮询
Round-Robin
类型转换:DataStream → DataStream
作用:使用Round-Robin负载均衡算法将输入流平均分配到随后的并行运行的任务中去
实现原理:即调用rebalance算子,该算子底层由RebalancePartitioner类实现具体的分配逻辑,该类同样继承自StreamPartitioner,具体逻辑如下:
//这里真正实现轮询@Overridepublic int selectChannel(SerializationDelegate<StreamRecord<T>> record) {nextChannelToSendTo = (nextChannelToSendTo + 1) % numberOfChannels;return nextChannelToSendTo;}
操作案例:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);socketTextStream.map(new RichMapFunction<String, String>() {@Overridepublic String map(String value) throws Exception {int indexOfThisSubtask = getRuntimeContext().getIndexOfThisSubtask();return indexOfThisSubtask + "-->map后-->" + value;}}).rebalance().addSink(new RichSinkFunction<String>() {@Overridepublic void invoke(String value, Context context) throws Exception {int index = getRuntimeContext().getIndexOfThisSubtask();System.out.println(value + "--->rebalance--->" + index);}});env.execute();//最后结果3-->map后-->spark--->rebalance--->10-->map后-->hadoop--->rebalance--->21-->map后-->flink--->rebalance--->32-->map后-->java--->rebalance--->03-->map后-->es--->rebalance--->20-->map后-->good--->rebalance--->31-->map后-->yes--->rebalance--->02-->map后-->are--->rebalance--->1
3、Rescale
类型转换:DataStream → DataStream
作用:使用的也是round-robin算法,但只会将数据发送到接下来的并行运行的任务中的一部分任务中。本质上,当发送者任务数量和接收者任务数量不一样时,rescale分区策略提供了一种轻量级的负载均衡策略。如果接收者任务的数量是发送者任务的数量的倍数时,rescale操作将会效率更高
实现原理:调用rescale算子,底层由RescalePartitioner分区器实现,该分区器继承自StreamPartitioner,具体处理逻辑如下:
@Overridepublic int selectChannel(SerializationDelegate<StreamRecord<T>> record) {if (++nextChannelToSendTo >= numberOfChannels) {nextChannelToSendTo = 0;}return nextChannelToSendTo;}
操作案例:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);socketTextStream.map(new RichMapFunction<String, String>() {@Overridepublic String map(String value) throws Exception {int indexOfThisSubtask = getRuntimeContext().getIndexOfThisSubtask();return indexOfThisSubtask + "-->map后-->" + value;}}).rescale().addSink(new RichSinkFunction<String>() {@Overridepublic void invoke(String value, Context context) throws Exception {int index = getRuntimeContext().getIndexOfThisSubtask();System.out.println(value + "--->rescale--->" + index);}});env.execute();
rebalance()和rescale()的根本区别在于任务之间连接的机制不同。 rebalance()将会针对所有发送者任务和所有接收者任务之间建立通信通道,而rescale()仅仅针对每一个任务和下游算子的一部分子并行任务之间建立通信通道。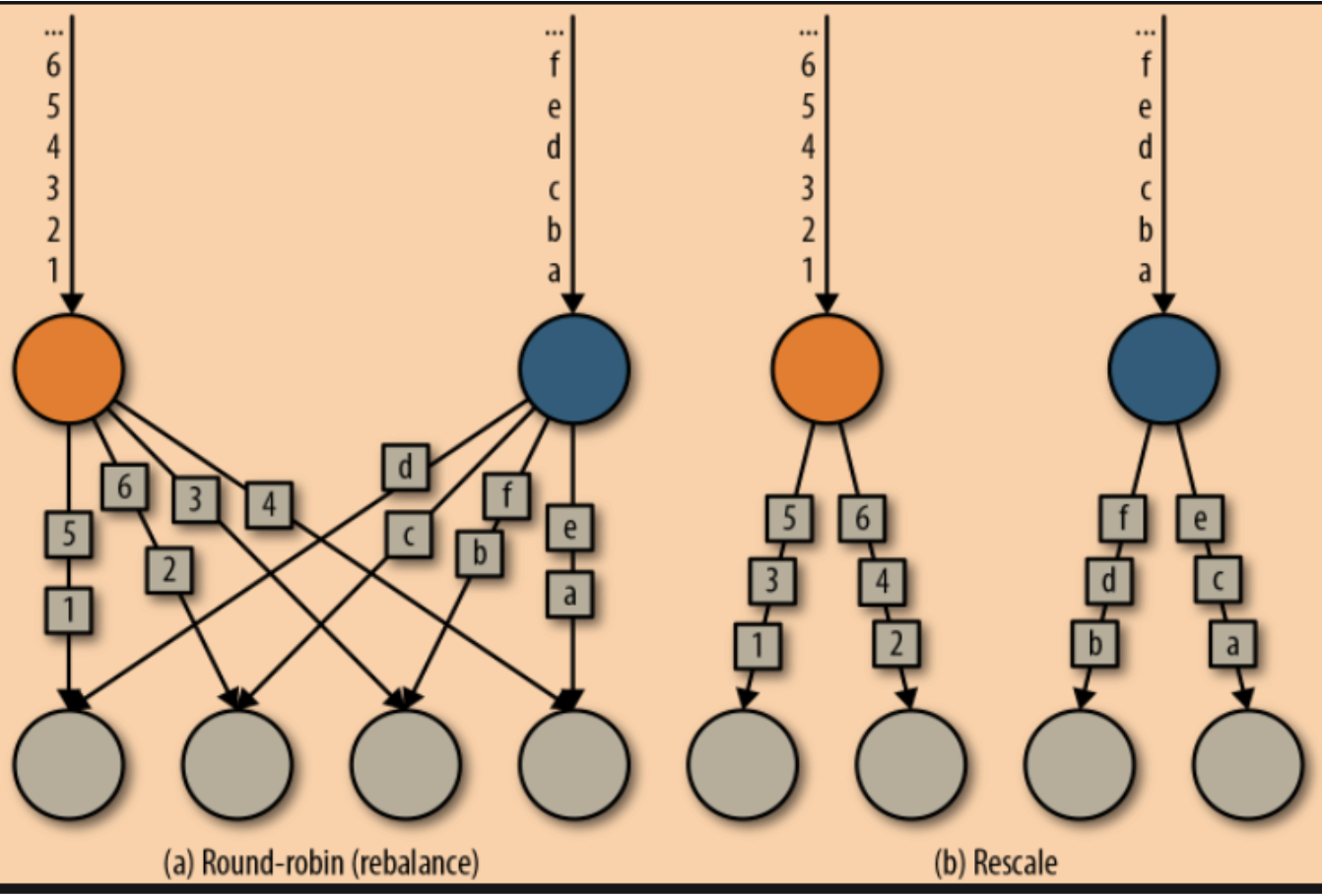
如上图所示,对于round-robin分区方式来说,上游两个分区可以分配的范围是下游的4个所有分区,属于真正的轮询方式,但是会有很大的网络开销。对于Rescale分区方式来说,上下游的分配方式和并行度有关,即上游的每个分区对应下游的两个分区,这种方式减少了网络IO,可以直接从本地的上游算子获取所需的数据。
4、广播Broadcast
类型转换:DataStream → DataStream
作用:将输入流的所有数据复制并发送到下游算子的所有并行任务中去
实现原理:调用broadcast算子,底层由BroadcastPartitioner分区器实现,同样继承自StreamPartitioner,具体实现逻辑:
//直接被所有的channel进行处理了,所以不需要在该方法中实现分区逻辑
@Overridepublic int selectChannel(SerializationDelegate<StreamRecord<T>> record) {throw new UnsupportedOperationException("Broadcast partitioner does not support select channels.");}
操作案例:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);socketTextStream.map(new RichMapFunction<String, String>() {@Overridepublic String map(String value) throws Exception {int index = getRuntimeContext().getIndexOfThisSubtask();return index+"-->"+value;}}).setParallelism(2).broadcast().addSink(new RichSinkFunction<String>() {@Overridepublic void invoke(String value, Context context) throws Exception {System.out.println(value+"-->"+getRuntimeContext().getIndexOfThisSubtask());}});env.execute();//输入javasparkhadoop//最终结果1-->java-->11-->java-->31-->java-->21-->java-->00-->spark-->00-->spark-->20-->spark-->10-->spark-->31-->hadoop-->21-->hadoop-->01-->hadoop-->31-->hadoop-->1
5、Global
类型转换:DataStream → DataStream
作用:将所有的输入流数据都发送到下游算子的第一个并行任务中去。这个操作需要很谨慎,因为将所有数据发送到同一个task,将会对应用程序造成很大的压力
实现原理:调用global算子,由GlobalPartitioner分区器实现,同样继承自StreamPartitioner类,具体分区逻辑如下:
//即直接分到第一个task中
@Overridepublic int selectChannel(SerializationDelegate<StreamRecord<T>> record) {return 0;}
操作案例:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);socketTextStream.map(new RichMapFunction<String, String>() {@Overridepublic String map(String value) throws Exception {int index = getRuntimeContext().getIndexOfThisSubtask();return index+"-->"+value;}}).global().addSink(new RichSinkFunction<String>() {@Overridepublic void invoke(String value, Context context) throws Exception {System.out.println(value+"-->"+getRuntimeContext().getIndexOfThisSubtask());}});env.execute();//输入flinksparkhadoopjavaeskylin//最终结果0-->flink-->01-->spark-->02-->hadoop-->03-->java-->00-->es-->01-->kylin-->0
6、自定义Custom
类型转换:DataStream → DataStream
作用:使用自定义分区策略实现分区逻辑以及定义针对流的哪个字段或者key进行分区
实现原理:调用partitionCustom方法,由CustomPartitionerWrapper类进行封装自定义分区逻辑,同样也是继承自StreamPartitioner类,具体实现方式如下:
//这里的partitioner对象是由用户自定义实现的@Overridepublic int selectChannel(SerializationDelegate<StreamRecord<T>> record) {K key;try {key = keySelector.getKey(record.getInstance().getValue());} catch (Exception e) {throw new RuntimeException("Could not extract key from " + record.getInstance(), e);}return partitioner.partition(key, numberOfChannels);}
操作案例:
功能:如果key为spark,则分配到第一个分区,如果key为hadoop,则分配到第二个分区,如果key为flink,则分配到第三个分区,其他则默认分配到分区0
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> socketTextStream = env.socketTextStream("localhost", 8888);socketTextStream.map(new RichMapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {int indexOfThisSubtask = getRuntimeContext().getIndexOfThisSubtask();return Tuple2.of(value, indexOfThisSubtask);}}).returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class,Integer.class)).setParallelism(2).partitionCustom(new Partitioner<String>() {@Overridepublic int partition(String key, int numPartitions) {System.out.println("下游并行度为:" + numPartitions);int res = 0;if (key.equalsIgnoreCase("spark")) {res = 1;} else if ("hadoop".equalsIgnoreCase(key)) {res = 2;} else if ("flink".equalsIgnoreCase(key)) {res = 3;}return res;}}, t -> t.f0) //按照t.f0为key进行分组.addSink(new RichSinkFunction<Tuple2<String, Integer>>() {@Overridepublic void invoke(Tuple2<String, Integer> value, Context context) throws Exception {System.out.println(value.f0 + "--->" + getRuntimeContext().getIndexOfThisSubtask());}});env.execute();//输入hadoopflinkjavaessparkkylinhbase//最终结果下游并行度为:4hadoop--->2下游并行度为:4flink--->3下游并行度为:4java--->0下游并行度为:4es--->0下游并行度为:4spark--->1下游并行度为:4kylin--->0下游并行度为:4hbase--->0
3.6、Window & Watermark
3.6.1、Window
3.6.1.1、应用场景
Apache Flink可以说是目前大数据实时流处理最流行的技术,功能非常强大,支持开发和运行多种不同类型的应用程序。主要特性包括:批流一体化、状态管理、事件时间支持以及精准一次的状态一致性保障等。目前Flink的应用场景整体概括下来包含以下几点:
- 事件驱动型应用
- 数据分析(OLAP)型应用
- 数据管道/ETL类型应用
接下来将针对这三类应用做一个简单的概述,希望读者能有一个大概的了解。
3.6.1.1.1 事件驱动型应用
概念:事件驱动是在计算存储分离的传统应用基础上进化而来的,它是一类具有状态的应用,从一个或多个事件中提取数据,并根据事件来触发计算、状态更新或者其他的动作。事件驱动型应用在设计上,将数据和计算进行分离,应用只需要访问本地(内存/磁盘)来获取数据,容错性的实现依赖于定期持久化存储写入checkpoint,关于传统型应用和事件驱动型应用的区别可见下图:
优势:事件驱动型应用通过本地访问数据来实现更高的吞吐和更低的延迟,并异步增量来完成远程持久化存储的checkpoint。而传统型的应用需要共享同一个数据库,因此任何对数据库自身的修改都需要谨慎协调。
实际案例:典型的事件驱动应用如:基于规则的监控告警;反欺诈;异常检测等业务监控场景
3.6.1.1.2 OLAP型应用
概念:其实这块的应用场景应该是比较常见的,对于传统的分析方式大多是以批查询处理的,如通过hive/spark等离线技术进行处理的,而Flink是可以支持批流一体的分析应用
优势:相对于批查询,flink流处理分析可以使得结果产出延迟更低。flink流分析简化了应用抽象,通常实现批查询需要由多个独立的组件组成,需要定时调度完成ETL,一旦某个环节出现问题将会影响后续的步骤。而flink流分析涵盖了从数据接入到数据结果产出的所有步骤,同时可以依赖底层引擎提供的故障恢复机制。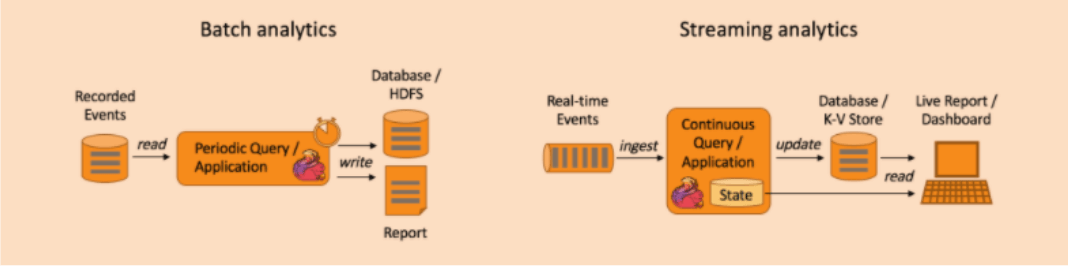
3.6.1.1.3 数据管道/ETL应用
概念:同上面的OLAP类型应用,一般用于构建实时数仓中的步骤,将一系列ETL步骤组成一个pipeline形式
优势:优势同OLAP应用

3.6.2、窗口概念
在引入窗口概念之前,我们需要知道Flink中的数据主要分为两类:有界数据流和无界数据流。
无界数据流:指的是一旦开始生成后就会持续不断的产生新的数据,即数据没有时间边界,这种类型的数据一般适用于做ETL
有界数据流:指的是输入的数据有始有终,一般这种类型的数据用于批处理,如统计过去一分钟的pv或者uv等类似聚合类操作。
而flink又是实时流技术,那么如何支持有界数据流的聚合操作呢?这个时候就有了窗口的概念。
窗口的作用就是为了周期性的获取数据,即把传入的无界数据流在逻辑上划分多个buckets,所以可以把窗口看作是从流到批的一个桥梁。

如上图所示,在一个无界的数据流上,我们通过指定窗口各种属性来实现有界流的处理。因为有了窗口,使得flink成为流批一体的潮流大数据技术。
3.6.3、窗口生命周期
通过以上的内容,我们应该知道了窗口的作用(主要是为了解决什么样的问题)。那么这个时候需要思考四个问题
- 数据元素是如何分配到对应窗口中的(也就是窗口的分配器)?
- 元素分配到对应窗口之后什么时候会触发计算(也就是窗口的触发器)?
- 在窗口内我们能够进行什么样的操作(也就是窗口内的操作)?
- 当窗口过期后是如何处理的(也就是窗口的销毁关闭)?
其实这四个问题从大体上可以理解为窗口的整个生命周期过程。接下来我们对每个环节进行讲解
3.6.4、窗口分配器WindowAssigner
在开始梳理窗口分配过程之前,我们应该先知道Flink中的窗口从大体上划分有2种类型:
- 根据时间划分窗口,也就是TimeWindow,按照时间来生成窗口。每个时间窗口都有一个开始时间和结束时间,表示一个左闭右开的时间段。根据时间窗口再进一步进行划分,有以下几种窗口分配类型:
- 滚动窗口(Tumbling Window)
- 滑动窗口(Sliding Window)
- 会话窗口(Session Window)
- 根据数据划分窗口,也就是GlobalWindow(CountWindow),根据数据条数来生成一个窗口,和时间无关。
由于基于数据条数来划分窗口是比较简单的,这里不再细说。接下来将针对时间窗口(实际生产中也是常用的)来进行讲述。
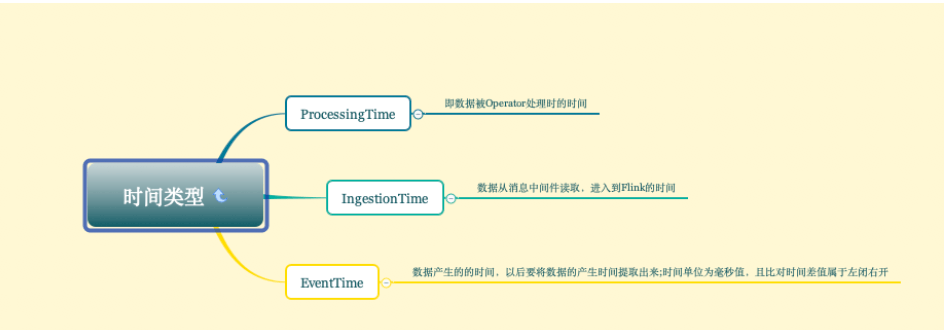
在讲述时间窗口之前,需要先了解一下在Flink中,关于时间又分为三种:
- Event Time:即事件产生的时间
- IngestionTime:即进入系统的时间,也就是数据进行flink的时间
- Processing Time:即数据被Operator算子处理的时间
滚动窗口Tumbling Window
滚动窗口分配器会把每个元素分配到一个指定窗口大小的窗口中,且每个窗口之间没有重叠。例如当指定大小为5分钟的窗口,那么就会每5分钟启动一个新的窗口,如下图所示:

该类窗口的特点:
- 时间对齐,默认情况下时间窗口会做一个对齐,比如设置一个一小时的窗口,那么窗口的起止时间是[0:00:00.000 - 0:59:59.999)
- 窗口长度固定
- 窗口没有重叠
适用场景:适合做每个时间段的聚合计算,BI分析。例如统计某页面每分钟点击的pv。
滑动窗口 Sliding Window
滑动窗口分配器将元素分配到固定长度的窗口中,与滚动窗口类似,窗口的大小由窗口大小参数(size)来配置,另一个窗口滑动参数(slide)控制滑动窗口开始的频率。滑动窗口如果滑动参数小于窗口大小的话,窗口是可以重叠的,在这种情况下,元素会被分配到多个窗口下。例如,可以设置一个大小为10分钟的窗口,每5分钟滑动一次,那么每隔5分钟就会得到一个窗口,其中包含过去10分钟内到达的事件,如下图所示。
该类窗口的特点:
- 时间可以对齐
- 窗口长度固定
- 有重叠
适用场景:对最近一段时间段内进行统计(如某接口近几分钟的失败调用率)
会话窗口Session Window
会话窗口由一系列事件组合一个指定时间长度的timeout间隙组成,类似于web应用的session,也就是一段时间没有接收到新数据就会生成新的窗口。
session窗口分配器通过session活动来对元素进行分组,session窗口和滑动窗口和滚动窗口相比,不会有重叠和固定的开始时间和结束时间的情况。
当它在一个固定的时间周期内不再接收元素,即非活动间隔产生,那个窗口就会关闭。
一个session窗口通过一个session间隔来配置,这个session间隔定义了非活跃周期的长度,当这个非活跃周期产生,那么当前的session关闭并且后续的元素将被分配到新的session窗口中去

会话窗口就是根据上图中的session gap来切分不同的窗口,当一个窗口在大于session gap时间内没有接收到数据,窗口就会关闭,所以在这种模式下,窗口的长度是可变的,开始和结束时间也是不确定的,唯独可以设置定长的session gap.
该类窗口的特点:
触发器(Trigger)决定了何时启动Window Function来处理窗口中的数据以及何时将窗口内的数据清理。
增量计算窗口函数对每个新流入的数据直接进行聚合,Trigger决定了在窗口结束时将聚合结果发送出去;全量计算窗口函数需要将窗口内的元素缓存,Trigger决定了在窗口结束时对所有元素进行计算然后将结果发送出去。
每一个窗口都有一个默认的Trigger,当到达窗口的结束时间时,Trigger和对应的计算就会被触发。目前flink内置的触发器有以下几种:
- EventTimeTrigger:基于event time来触发计算
- ProcessingTimeTrigger:基于processing time来触发计算,通过对比ProcessingTime和窗口EndTime来确定是否触发窗口
- ContinuousProcessingTimeTrigger:根据间隔时间周期性触发窗口或者Window的结束时间小于当前ProcessTime触发窗口计算
- ContinuousEventTimeTrigger:根据间隔时间周期性触发窗口或者Window的结束时间小于当前EndTime触发窗口计算。
- CountTrigger:基于窗口内元素数量来触发计算,当超过设定的阈值来触发窗口计算
- PurgingTrigger:对其他触发器做一个转换,即支持清理窗口数据功能
- DeltaTrigger:根据接入数据计算出来的Delta指标是否超过指定的Threshold去判断是否触发窗口计算
这里需要注意的是GlobalWindow的默认触发器是NeverTrigger,它从不触发。因此,在使用GlobalWindow时,必须定义一个自定义触发器。如果我们有一些个性化的触发条件,比如窗口内遇到某个特定的元素、元素总数达到一定数量或窗口中的元素到达时满足某种特定的模式时,我们可以自定义一个Trigger。那么接下来需要了解一下Trigger接口的五种方法:
- onElement()方法:当某个窗口增加一个元素时,会调用该方法,返回一个TriggerResult
- onEventTime()方法:当一个基于Event Time的Timer触发了FIRE时调用onEventTime方法
- onProcessingTime()方法:当一个基于Processing Time的Timer触发了FIRE时调用onProcessTime方法
- onMerge()方法:和有状态的触发器有关,当多个窗口被合并时调用onMerge,并会合并触发器的状态,例如使用会话窗口时。
- clear()方法:当窗口数据被清理时,调用clear方法来清理所有的Trigger状态数据,否则随着窗口越来越多,状态数据也会越来越多
当满足某个条件,Trigger会返回一个TriggerResult封装的结果,根据返回结果进行下一步的操作:
- CONTINUE:什么都不做
- FIRE:启动计算并将结果发送给下游,不清理窗口数据
- PURGE:清理窗口数据但是不执行计算
- FIRE_AND_PURGE:启动计算,发送结果然后清理窗口数据
示例1:按照event_time来划分窗口,窗口长度为4s,同时每2s触发一次计算,并将中间状态结果清除掉

如上图所示,输入1000,flink,1 具体含义如下:
- 1000是event_time可以理解成为1s
- flink作为分组的key
- 1代表key对应的value
具体代码见simple.window.trigger.PurgingTriggerDemo
示例2:自定义Trigger
实现功能:在EventTimeTrigger基础上增加一个元素个数统计,当窗口内的元素个数达到阈值后则触发计算,并清除状态;当达到窗口结束时间时再次触发计算,同时也清除状态。具体代码见simple.window.trigger.CustomCountEventTimeTrigger
private static int count = 1;@Overridepublic TriggerResult onElement(Object element, long timestamp, TimeWindow window, TriggerContext ctx) throws Exception {long nextEndTime = window.getEnd() - 1;System.out.println("当前事件时间:" + timestamp + " 窗口截止时间:" + nextEndTime + " 当前窗口内元素个数为:" + count);if (nextEndTime <= ctx.getCurrentWatermark()) {return TriggerResult.FIRE_AND_PURGE;} else {ctx.registerEventTimeTimer(nextEndTime);}//判断元素个数是否达到阈值if (count < MAX_VALUE) {count++;} else {count = 1;System.out.println("元素个数达到阈值,开始触发计算:" + element);return TriggerResult.FIRE_AND_PURGE;}return TriggerResult.CONTINUE;}//这里设置窗口长度为3s,元素个数阈值为2//输入://1000,flink,1//2000,flink,2//3000,flink,3//4000,flink,4

3.6.6、窗口函数windowFunction
当我们对无限流完成了窗口划分,并在一定时间下触发了窗口,那么这个时候就需要对窗口内的元素进行一定的操作,也就是所谓的窗口函数。窗口函数主要分为两种:一种是增量计算,如reduce和aggregate,在处理时会保存一个中间状态结果,新进来的元素会和这个状态中间数据进行一些操作;一种是全量计算,如process,指的是先缓存窗口内所有的元素,等触发之后对窗口内所有元素执行计算。
在讲述窗口函数具体实现之前,先来了解一下Flink窗口的大致骨架结构:
对于Keyed Windows:按照key分组的骨架结构如下
stream.keyBy(...) <- keyed versus non-keyed windows.window(...) <- required: "assigner"[.trigger(...)] <- optional: "trigger" (else default trigger)[.evictor(...)] <- optional: "evictor" (else no evictor)[.allowedLateness(...)] <- optional: "lateness" (else zero)[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data).reduce/aggregate/fold/apply() <- required: "function"[.getSideOutput(...)] <- optional: "output tag"
对于Non-Keyed Windows:即不分组模式对应的骨架结构如下
stream.windowAll(...) <- required: "assigner"[.trigger(...)] <- optional: "trigger" (else default trigger)[.evictor(...)] <- optional: "evictor" (else no evictor)[.allowedLateness(...)] <- optional: "lateness" (else zero)[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data).reduce/aggregate/fold/apply() <- required: "function"[.getSideOutput(...)] <- optional: "output tag"
关于trigger触发器,第五小节已经大致介绍了。evictor销毁将在下一小节讲述,allowedLateness和sideOutputLateData这块涉及到WaterMark,读者可以先略过后面会有单独的文章进行讲解。
通过窗口函数可以实现对数据类型的转换并对窗口内的数据进行一些必要的操作,如下图一个DataStream通过调用keyBy转换成KedyedStream,再经过window转换成WindowedStream,然后再基于WindowedStream进行reduce、aggregate或者process等窗口函数进行操作
窗口函数大致可以分为ReduceFunction、AggregateFunction、FoldFunction和ProcessWindowFunction。接下来分别进行介绍其具体作用。
ReduceFunction
ReduceFunction指定如何将输入中的两个元素组合在一起以产生相同类型的输出元素。 Flink使用ReduceFunction来逐步聚合窗口的元素。如下面的示例汇总了窗口中所有元素的元组的第二个字段
DataStream<Tuple2<String, Long>> input = ...;input.keyBy(<key selector>).window(<window assigner>).reduce(new ReduceFunction<Tuple2<String, Long>> {public Tuple2<String, Long> reduce(Tuple2<String, Long> v1, Tuple2<String, Long> v2) {return new Tuple2<>(v1.f0, v1.f1 + v2.f1);}});
AggregateFunction
AggregateFunctio是ReduceFunction的通用版本,也是一种增量计算窗口函数,保存了一个中间状态数据,但是使用比较复杂。先来看一下源码
@PublicEvolvingpublic interface AggregateFunction<IN, ACC, OUT> extends Function, Serializable {//创建一个新的Accumulator,也就是中间状态数据,在发起一次aggregate时会调用ACC createAccumulator();//当窗口内进入一个新元素时会把该元素和ACC进行合并,然后返回新的状态数据ACCACC add(IN value, ACC accumulator);//将中间结果转换为结果数据OUT getResult(ACC accumulator);//合并两个ACCACC merge(ACC a, ACC b);}
源码中定义了三个类型,IN,ACC,OUT。输入类型是IN,输出类型是OUT,中间状态数据是ACC。这种复杂的设计是为了解决输入类型、中间状态和输出类型不一致的问题。下面将通过一个例子来讲解一下这几个函数的工作流程
示例:计算一个窗口的平均值,那么ACC就要保存总和以及个数
class MyAggregateFunction implements AggregateFunction<Tuple3<String, String, Integer>, Tuple2<Integer, Integer>, Double> {@Overridepublic Tuple2<Integer, Integer> createAccumulator() {return Tuple2.of(0, 0);}@Overridepublic Tuple2<Integer, Integer> add(Tuple3<String, String, Integer> value, Tuple2<Integer, Integer> accumulator) {accumulator.f0 = accumulator.f0 + 1;accumulator.f1 = accumulator.f1 + value.f2;System.out.println("新增元素,当前中间状态结果:" + accumulator + " 当前事件元素:" + value);return accumulator;}@Overridepublic Double getResult(Tuple2<Integer, Integer> accumulator) {System.out.println("调用结果值..分子为:" + accumulator.f1 + " 分母为:" + accumulator.f0);return Double.valueOf(accumulator.f1 / accumulator.f0);}@Overridepublic Tuple2<Integer, Integer> merge(Tuple2<Integer, Integer> a, Tuple2<Integer, Integer> b) {System.out.println("合并值:" + a);return Tuple2.of(a.f0 + b.f0, a.f1 + b.f1);}}

如上图所示,当程序刚启动时,还没有数据进入,这个时候会创建一个新的ACC。当有数据流入后,会调用add函数更新ACC,如果有跨节点的ACC的话,flink会调用merge进行合并直到窗口结束后会调用getResult生成结果。
注意:如果你未设置并行度,则默认按照机器的核数,那么这个时候就会出现应该窗口触发的时候但未触发的情况。笔者开发的demo见simple.window.function.AggregateFunctionDemo。

在笔者的例子中,如果未设置并行度为1,那么只有当窗口3的数据到来时才会触发窗口0。如果读者的机器核数比较多,那么有可能会调试多次不能触发窗口0的计算。具体原因见源码:
private void findAndOutputNewMinWatermarkAcrossAlignedChannels() throws Exception {long newMinWatermark = Long.MAX_VALUE;boolean hasAlignedChannels = false;// determine new overall watermark by considering only watermark-aligned channels across all channelsfor (InputChannelStatus channelStatus : channelStatuses) {if (channelStatus.isWatermarkAligned) {hasAlignedChannels = true;newMinWatermark = Math.min(channelStatus.watermark, newMinWatermark);}}// we acknowledge and output the new overall watermark if it really is aggregated// from some remaining aligned channel, and is also larger than the last output watermarkif (hasAlignedChannels && newMinWatermark > lastOutputWatermark) {lastOutputWatermark = newMinWatermark;output.emitWatermark(new Watermark(lastOutputWatermark));}}
也就是说当同一个窗口内的元素所在task都满足窗口触发条件时,那么该窗口才会真正被触发。
FoldFunction
FoldFunction指定如何将窗口的输入元素与输出类型的元素组合。每当窗口内有数据流入就会和当前输出值进行一些合并操作。该函数作用其实跟ReduceFunction一样,唯一不同的是该函数可以设置一个初始值。具体使用可以参考下面官网的示例:即将所有输入的long类型值追加到初始值为空上。
DataStream<Tuple2<String, Long>> input = ...;input.keyBy(<key selector>).window(<window assigner>).fold("", new FoldFunction<Tuple2<String, Long>, String>> {public String fold(String acc, Tuple2<String, Long> value) {return acc + value.f1;}});
ProcessWindowFunction
ProcessWindowFunction是属于全量计算的函数,需要把窗口内的全量数据进行缓存,因此是非常耗费性能和资源的。该函数会返回一个包含全部数据的可迭代对象Iterable,提供了可访问时间和一些状态信息,可以直接操作状态,所以该函数比其他窗口函数更加丰富灵活。源码定义如下:
/*** IN :输入类型* OUT:输出类型* KEY: keyBy算子中按照key分组,Key的类型* W:窗口类型***/public abstract class ProcessWindowFunction<IN, OUT, KEY, W extends Window> extends AbstractRichFunction {private static final long serialVersionUID = 1L;//对一个窗口内的元素进行处理,元素会缓存在Iterable中,处理后输出到Collector中public abstract void process(KEY key, Context context, Iterable<IN> elements, Collector<OUT> out) throws Exception;//窗口执行完毕后会进行清理,删除各类状态数据public void clear(Context context) throws Exception {}//窗口上下文状态,包括窗口元数据、状态数据、WaterMark等public abstract class Context implements java.io.Serializable {//返回当前正在处理的Windowpublic abstract W window();//返回当前ProcessingTimepublic abstract long currentProcessingTime();//返回当前EventTime对应的Watermarkpublic abstract long currentWatermark();//返回某个key下的某个window状态,单窗口下的状态,当使用单个窗口状态时,需要在clear函数中清理状态public abstract KeyedStateStore windowState();//返回某个key下的全局状态,跨多个窗口,也就是说多个窗口都能访问public abstract KeyedStateStore globalState();//迟到的数据发送到其他位置public abstract <X> void output(OutputTag<X> outputTag, X value);}}
示例:统计窗口下的元素个数
DataStream<Tuple2<String, Long>> input = ...;input.keyBy(t -> t.f0).timeWindow(Time.minutes(5)).process(new MyProcessWindowFunction());public class MyProcessWindowFunctionextends ProcessWindowFunction<Tuple2<String, Long>, String, String, TimeWindow> {@Overridepublic void process(String key, Context context, Iterable<Tuple2<String, Long>> input, Collector<String> out) {long count = 0;for (Tuple2<String, Long> in: input) {count++;}out.collect("Window: " + context.window() + "count: " + count);}}
注意:ProcessWindowFunction需要把一个窗口内的所有元素都缓存起来,这种操作将占用大量的存储资源,虽然应用场景很广,能够解决比较复杂的场景问题,但是稍有使用不慎就会造成严重后果
ProcessWindowFunction With Incremental Aggreation:即ProcessWindowFunction和增量计算结合
为了解决ProcessWindowFunction将整个窗口元素缓存起来占用大量资源的情况,flink提供了可以将ProcessWindowFunction和reduce和aggregate组合的操作。即当元素到达窗口时进行增量计算,当窗口结束的时候,ProcessWindowFunction将会出增量结果进行处理输出结果。该组合操作即可以增量计算窗口,同时也可以访问窗口的一些元数据、状态信息等。
示例:ProcessWindowFunction和ReduceFunction结合使用来获取窗口中最小的元素和窗口的开始时间
DataStream<SensorReading> input = ...;input.keyBy(<key selector>).timeWindow(<duration>).reduce(new MyReduceFunction(), new MyProcessWindowFunction());// Function definitionsprivate static class MyReduceFunction implements ReduceFunction<SensorReading> {public SensorReading reduce(SensorReading r1, SensorReading r2) {return r1.value() > r2.value() ? r2 : r1;}}private static class MyProcessWindowFunctionextends ProcessWindowFunction<SensorReading, Tuple2<Long, SensorReading>, String, TimeWindow> {public void process(String key,Context context,Iterable<SensorReading> minReadings,Collector<Tuple2<Long, SensorReading>> out) {SensorReading min = minReadings.iterator().next();out.collect(new Tuple2<Long, SensorReading>(context.window().getStart(), min));}}
3.6.7、窗口销毁WindowEvictor
Flink的窗口模型允许除了WindowAssigner和Trigger之外还指定一个可选的Evictor,可以在Window Function执行前或者执行后调用Evictor.具体源码定义如下:
/**** T为元素类型* W为窗口*/public interface Evictor<T, W extends Window> extends Serializable {//在Window Function之前调用,即可以在窗口处理之前剔除数据void evictBefore(Iterable<TimestampedValue<T>> var1, int var2, W var3, Evictor.EvictorContext var4);//在Window Function之后调用void evictAfter(Iterable<TimestampedValue<T>> var1, int var2, W var3, Evictor.EvictorContext var4);//Evictor上下文public interface EvictorContext {long getCurrentProcessingTime();MetricGroup getMetricGroup();long getCurrentWatermark();}}
窗口中所有的元素被放在Iterable
Flink提供了三种已实现的Evictor:
- CountEvictor:保存指定数量的元素,多余的元素按照从前往后的顺序剔除
- DeltaEvictor:计算Window中最后一个元素与其余每个元素之间的增量,丢弃增量大于或等于阈值的元素
- TimeEvictor:对于给定的窗口,提供一个以毫秒为单位间隔的参数interval,找到最大的时间戳max_ts,然后删除所有时间戳小于max_ts-interval。
这里有以下几个注意点:
- 如果指定Evictor,那么可以防止预聚合操作,因为在计算之前会把所有的元素先传递给Evictor
- 由于Flink不保证元素顺序,因此Evictor当从窗口的开头删除元素时,那么该元素不一定是第一个或者最后一个到达的元素。
- 默认情况下,在窗口函数调用之前执行Evictor逻辑
3.6.8、总结
3.6.2、Watermark
3.6.2.1、引入
通过对上篇窗口的讲解,我们对flink窗口的整个生命周期有了一个大致的了解,并掌握了窗口的作用。这里给出一个常见的生产案例,如统计每分钟的点击用户数,技术实现上一般是flink对接kafka(假设这里我们保证全局有序的),窗口长度为1分钟。如下图示例: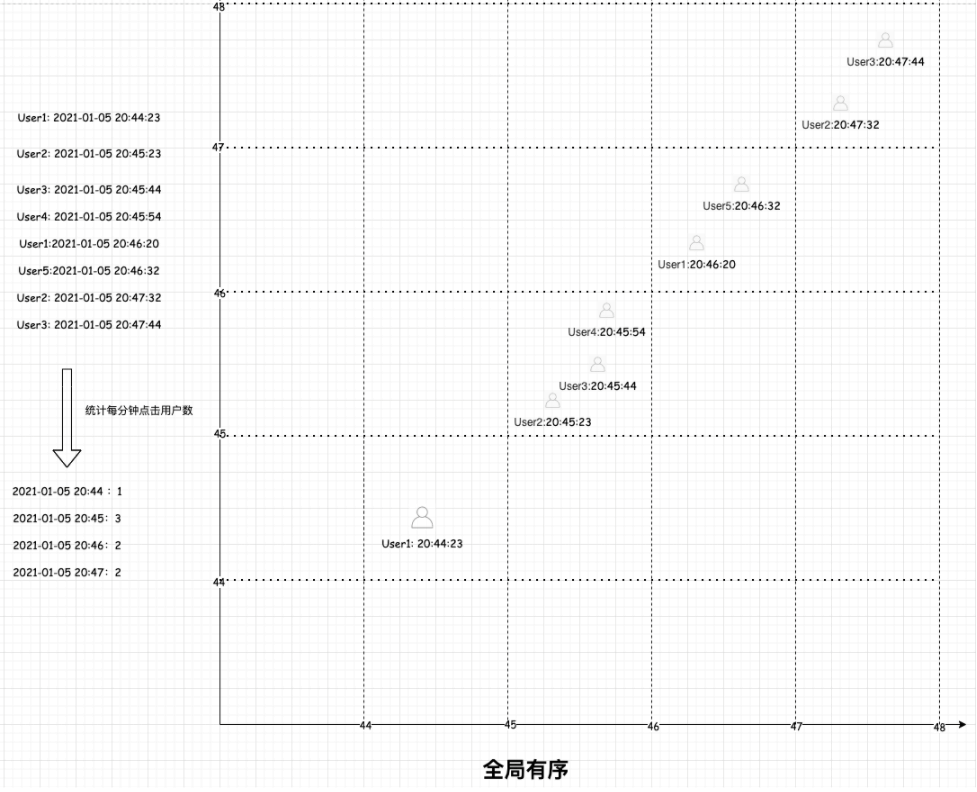
图中的结果可以说是精准的,不过这里有一个前提条件就是消费kafka时消息是全局有序的。但是一般实际环境下很难保证全局有序,那么就会出现下图的情况:可能由于网络延迟或者系统故障等一些因素导致20:45的消息在20:46分才开始消费,部分20:46的消息在20:47分开始消费,那么最后的统计结果如下图所示,可见此时统计的结果是不正确的。

因此对于乱序消费的情况,我们应该如何处理呢?很明显,flink提供了一种称之为水印(Watermark)的机制来解决。接下来分以下几个方面来介绍:
- Watermark如何定义的?其本质是什么?
- Watermark生成方式策略
- Watermark内部接口是如何实现的?
- 如何计算得出Watermark,何时会再次触发计算?
- Watermark API使用以及源码改造
- 多流下Watermark的一些问题
- 实际场景下的问题引出
3.6.2.2、WaterMark定义
Watermark是Apache Flink提出的一种用来解决乱序、延迟数据等情况的解决方案,通常和窗口结合使用。例如在一个窗口内,对于延迟数据,我们不能一直无限期等待所有延迟数据到来后才触发窗口计算,因此提出了Watermark机制,由用户来决定等待延迟数据多久后触发计算。本质上来说Watermark就是单调递增的时间戳,来控制等待延迟数据的最大时长。对于watermark,可以在flink应用程序中两个地方使用:
- 直接在数据源上使用;该方式相对会比较好,因为数据源可以利用 watermark 生成逻辑中有关分片/分区(shards/partitions/splits)的信息。使用这种方式,数据源通常可以更精准地跟踪 watermark,整体 watermark 生成将更精确
- 在操作算子上使用;当无法在数据源上使用时,则可以在算子操作上进行使用
3.6.2.3、WaterMark生成方式
基于上面的概念定义,我们知道watermark要和窗口结合使用。为了使用EventTime语义,flink需要知道事件时间戳对应的字段,那么也就是说数据流中的每个元素都需要有一个可以分配的事件时间戳。通过上篇窗口的讲解,使用TimestampAssigner API从元素中的某个字段来提取时间戳,而且时间戳的分配和watermark的生成齐头并进的,这样就可以告诉flink应用程序处理的进度。可以通过指定WatermarkGenerator来配置watermark的生成方式,Flink内置提供了两种Watermark生成方式:
- 周期性生成(Periodic Watermark)
周期性(即达到一定的时间间隔或指定的记录数)后会触发watermark的生成 - 标记生成(Punctuated Watermark)
通过数据流中某些特殊标记事件来触发watermark的生成。这种方式下窗口的触发与时间无关,而是决定于何时收到标记事件;在某些TPS很高场景下,会生成大量的watermark,会对下游算子造成压力,因此只有当实时性要求非常高的时候才会使用该种方式
3.6.2.4、接口定义
看到这里,相信大家对watermark的作用有了一定的了解,那么我们可能会好奇底层是如何生成watermark的。这里会从watermark的定义,到watermark的生成以及时间的分配和watermark使用策略循序渐进的进行介绍。主要涉及到以下几个类:
- Watermark:watermark定义类
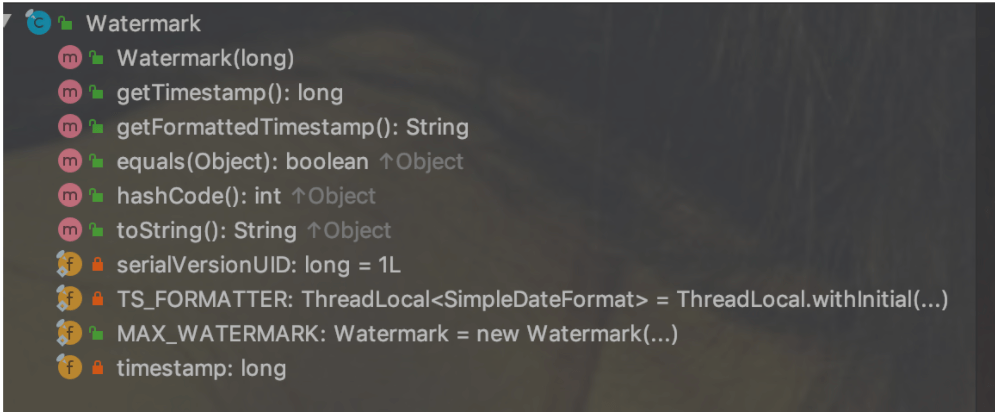
从该类中的方法和属性就可以看出watermark其底层本质就是一个时间戳
- WatermarkGenerator:watermark生成接口,该接口定义了两个方法 ```java /* 每来一个元素事件就会调用一次该方法 *eventTimestamp:从事件中提取出的时间戳
- 允许水印生成器检查并记住事件时间戳,或者根据事件本身发出水印 */ void onEvent(T event, long eventTimestamp, WatermarkOutput output);
/* 定期调用,可能会发出或不会发出新的水印 */ void onPeriodicEmit(WatermarkOutput output);
1. BoundedOutOfOrdernessWatermarks:WatermarkGenerator接口的实现类,实际生产中比较常用```javapublic BoundedOutOfOrdernessWatermarks(Duration maxOutOfOrderness) {this.outOfOrdernessMillis = maxOutOfOrderness.toMillis();// start so that our lowest watermark would be Long.MIN_VALUE.this.maxTimestamp = Long.MIN_VALUE + outOfOrdernessMillis + 1;}@Overridepublic void onEvent(T event, long eventTimestamp, WatermarkOutput output) {maxTimestamp = Math.max(maxTimestamp, eventTimestamp);}@Overridepublic void onPeriodicEmit(WatermarkOutput output) {output.emitWatermark(new Watermark(maxTimestamp - outOfOrdernessMillis - 1));}
- 从该类的实现可以看出水印的计算公式是:maxTimestamp - outOfOrdernessMillis - 1
- maxTimestamp:该参数值指的是窗口内最大的事件时间戳
- outOfOrdernessMillis:由用户指定的允许延迟时长。例如指定outOfOrdernessMillis=1000(1s),也就是说允许数据最多延迟1s的时间。
- TimestampAssigner:从字面意思可以看出是时间分配器,即给每个事件分配一个时间,既可以是从事件中解析出事件时间或者是系统时间
long extractTimestamp(T element, long recordTimestamp);
WatermarkStrategy:Flink为用户提供了一个工具类,可以同时设置TimestampAssigner和WatermarkGenerator。WatermarkGenerator类提供了很多常用的watermark策略,当然用户也可以自定义策略。
public interface WatermarkStrategy<T> extends TimestampAssignerSupplier<T>, WatermarkGeneratorSupplier<T>{/*** 根据策略实例化一个可分配时间戳的 {@link TimestampAssigner}。*/@OverrideTimestampAssigner<T> createTimestampAssigner(TimestampAssignerSupplier.Context context);/*** 根据策略实例化一个 watermark 生成器。*/@OverrideWatermarkGenerator<T> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context);}
当然,通常是不需要实现该接口的,可以调用内部静态方法来获取一个策略;或者可以使用该工具类将自定义的TimestampAssigner和WatermarkGenerator进行绑定。
3.6.2.5、如何计算得出Watermark
在接口定义部分中的讲解中,已经得知WatermarkGenerator接口的实现类中在创建Watermark实例时,传入了一个构造器参数,而该参数值就是maxTimestamp - outOfOrdernessMillis - 1;由此就可知Watermark的值,那么仍然以文章开头的例子来讲解watermark是如何计算的。
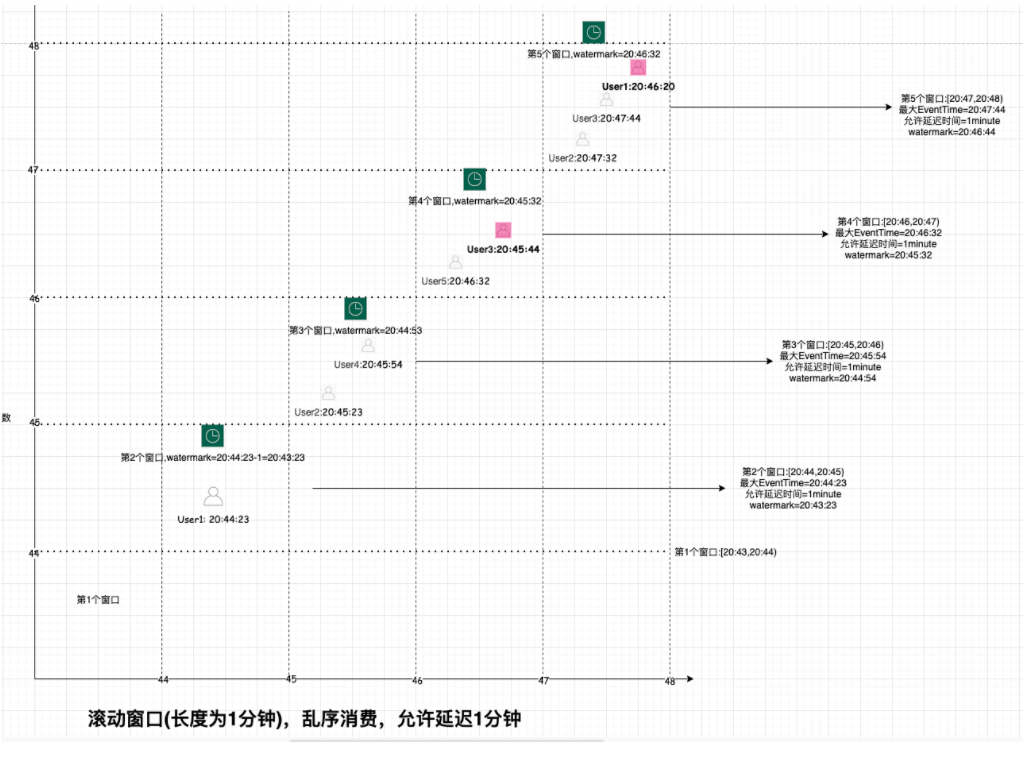
我们这里设置outOfOrdernessMills的值为1分钟,也就是说我们允许数据延迟1分钟,否则的话则丢弃或者进行其他的处理。在上篇文章中介绍到了窗口的触发机制(以滚动窗口+事件时间触发机制来说明):当流元素的最大事件时间大于当前窗口的结束时间,就会触发窗口计算。如开头所讲,如果出现数据延迟,那么就会造成延迟的数据无法被计算的情况;既然有了水印机制可以解决这一问题,当有数据延迟时,窗口又是如何被触发的呢?这里我们结合上图来梳理一下:
| 用户ID | 点击时间 | 到达窗口 | 实际落入窗口 | 当前窗口结束时间 | 水印时间 | 触发计算 | 计算结果 |
|---|---|---|---|---|---|---|---|
| User1 | 20:44:23 | 第2个窗口 | 第2个窗口 | [20:44,20:45) | 20:43:23 | 否 | 否 |
| User2 | 20:45:23 | 第3个窗口 | 第3个窗口 | [20:45,20:46) | 20:44:23 | 否 | 否 |
| User4 | 20:45:54 | 第3个窗口 | 第3个窗口 | [20:45,20:46) | 20:44:54 | 否 | 否 |
| User5 | 20:46:32 | 第4个窗口 | 第4个窗口 | [20:46,20:47) | 20:45:32 | 触发第二个窗口 | 窗口2:[User1] |
| User3 | 20:45:44 | 第4个窗口 | 第3个窗口 | [20:46,20:47) | 20:45:32 | 否 | 窗口2:[User1] |
| User2 | 20:47:32 | 第5个窗口 | 第5个窗口 | [20:47,20:48) | 20:46:32 | 触发第三个窗口 | 窗口2:[User1] 窗口3:[User2,User4,User3] |
| User3 | 20:47:44 | 第5个窗口 | 第5个窗口 | [20:47,20:48) | 20:46:44 | 否 | 窗口2:[User1] 窗口3:[User2,User4,User3] |
| User1 | 20:46:20 | 第5个窗口 | 第4个窗口 | [20:47,20:48) | 20:46:44 | 否 | 窗口2:[User1] 窗口3:[User2,User4,User3] |
| User5 | 20:44:54 | 第5个窗口 | 第2个窗口 | [20:44,20:45) | 直接丢弃 | 直接丢弃 |
从该执行表格中可以发现以下规律:
- 水印生成时间是单调递增的
- 当水印时间大于窗口结束时间则会触发窗口计算
- 如果延迟数据大于指定延迟时间后,则不会被计算到窗口内
3.6.2.6、Watermark使用
简单API(结合源码改造)
这里主要给出watermark的简单api使用demo,以及内置的两种watermark生成策略和自定义生成策略。
关于watermark简单的API使用,结合文章中给出的样例,笔者结合源码进行了部分重构。这里给出主要的代码(TumblingWatermarkMain.java) ```java StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); env.setParallelism(1);
DataStreamSource
socketTextStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor
env.execute();
**最终结果:**其中截图中的水印值结果是笔者在自定义触发器中结合watermark生成机制来改造实现的。主要是为了方便读者理解水印的机制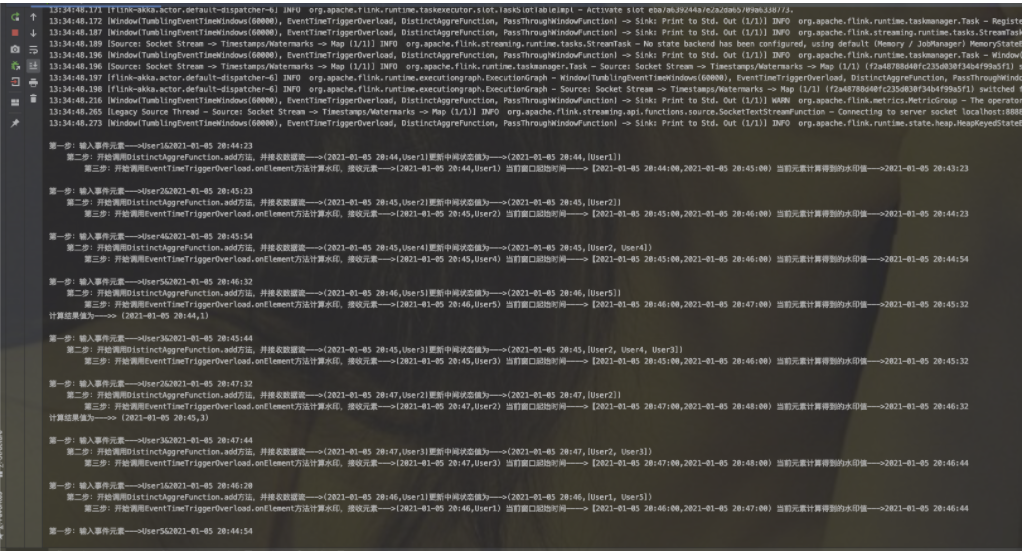<a name="b58QX"></a>##### 自定义生成策略刚才简单的API案例中已经涉及到Period生成策略,标记策略比较简单,笔者这里不再给出。接下来使用自定义生成策略(同样以上述例子来实现)。具体代码地址:[TumblingWatermarkMain.java](https://github.com/lcp5674/learn-flink-demo/blob/main/flink/src/main/java/simple/window/watermark/TumblingWatermarkCustomMain.java" \t "_blank)```java//这里给出核心代码WatermarkStrategy<String> ws = ((ctx) -> new CustomWatermarkGenerator());socketTextStream.assignTimestampsAndWatermarks(ws.withTimestampAssigner(new CustomTimestampAssignerWithSource())).map((MapFunction<String, Tuple2<Long, String>>) value -> getLongStringTuple2(value, simpleDateFormat, SEPATOR)).returns(TupleTypeInfo.getBasicTupleTypeInfo(Long.class, String.class)).keyBy(t -> {return targetFormat.format(new Date(t.f0));}).window(TumblingEventTimeWindows.of(Time.minutes(1L))).trigger(EventTimeTriggerOverload.create()).aggregate(new DistinctAggreFunctionStrategy()).print("计算结果值为--->");
最后的结果和简单API下的结果一致。

3.6.2.7、多流下的Watermark处理
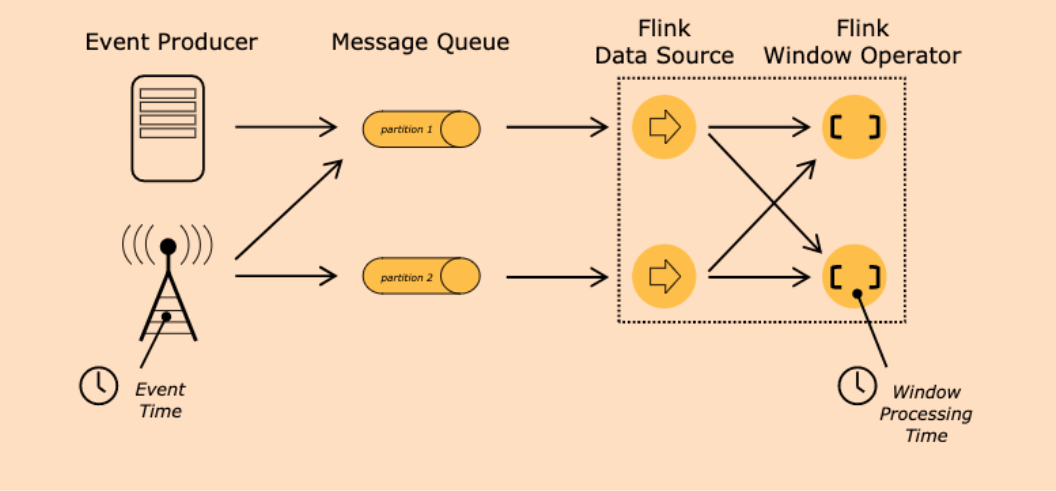
细心的读者会发现在示例代码中总会有一个并行度的设置env.setParallelism(1),增加该设置主要是为了方便理解watermark的机制。当然在实际场景中,特别是对接kafka的时候,大部分情况下是不会设置并行度为1的,否则会出现大量的延迟。我们仍然以开头的案例来讲解并行度对watermark的影响(注意:在demo代码里使用的是socketStream来模拟KafkaSourceStream。假设kafka topic有2个分区,接下来分别对比一下并行度=1和并行度=2的区别
第一种情况:当并行度=1时,见下图

可以发现2个分区的数据全部被一个source消费,那么这个时候也只会生成一个watermark,同时其他的算子也将会以一个并行度来计算。(这种情况也就是我们开头所讲的例子)
第二种情况:当并行度=2时,见下图:

可以发现每个source都分别消费一个partition,而且每个source都会生成一个watermark。这个时候就产生了一个问题:kafka topic的分区只能保证分区有序,但不能保证全局有序,如果说每个source都产生了一个watermark,那么统计出的结果就会有问题,而且也违背了我们发现的规律(即watermark单调递增)。
当然,如何让watermark单调递增的问题很好解决,只要保证全局有序就可以,这样就和单流下的watermark处理机制一样了。对应的在Flink中的抽象实现封装在org.apache.flink.streaming.api.operators.AbstractStreamOperator中。这里以TwoInputStreamOperator为例,即有两个Input Source
public void processWatermark(Watermark mark) throws Exception {if (timeServiceManager != null) {timeServiceManager.advanceWatermark(mark);}output.emitWatermark(mark);}//将source1计算生成的watermark和全局最小的watermark进行比较public void processWatermark1(Watermark mark) throws Exception {input1Watermark = mark.getTimestamp();long newMin = Math.min(input1Watermark, input2Watermark);if (newMin > combinedWatermark) {combinedWatermark = newMin;processWatermark(new Watermark(combinedWatermark));}}//将source2计算生成的watermark和全局最小的watermark进行比较public void processWatermark2(Watermark mark) throws Exception {input2Watermark = mark.getTimestamp();long newMin = Math.min(input1Watermark, input2Watermark);if (newMin > combinedWatermark) {combinedWatermark = newMin;processWatermark(new Watermark(combinedWatermark));}}
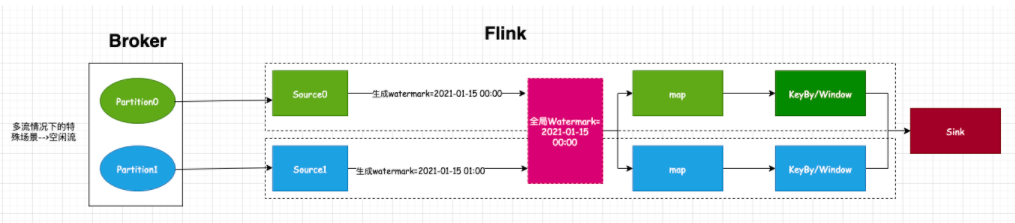
从源码中可以看出,Flink是取多个流中最小的watermark作为全局的watermark。虽然这样能够保证全局有序且单调递增,但也会有一个实际的问题,比如下图特殊的场景:当source0消费partition0得到的watermark为2021-01-15 00:00,source1消费partition1得到的watermark为2021-01-15 01:00,那么最终得到的全局watermark为2021-01-15 00:00,此时数据流正常计算触发。但当业务数据出现异常时或者key分区不均匀时,出现了partition0分区不再接收数据的情况,而partition1一直接收最新的数据(即事件时间都是大于2021-01-15 01:00)。试想:之后计算得到的watermark值会一直为2021-01-15 00:00,那么就无法触发窗口计算,随着时间推移,Flink处理的数据越来越多,而窗口资源一直未被释放,最后可能会导致程序down掉。
对于这种特殊的场景,也就是所谓的多流处理中的空闲流问题。对于此类问题,Flink提供了一个使用很简单的方案:即用户可以设置一定的超时时间,当全局watermark所在的source流在一定时间内没有数据的话,那么flink则会丢弃该watermark。应用到本文的例子中,也就是说当source0超过一定时间没有消费到数据的话,那么全局watermark对应2021-01-15 00:00这个值就无效了,之后就会按照正常的计算流程进行处理,也就不会影响水印的处理进度。具体使用方式如下:
//在watermark策略上设置空闲超时时间即可WatermarkStrategy.<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofMinutes(1L)).withTimestampAssigner(new CustomSerializableTimestampAssignerWithNoSource()).withIdleness(Duration.ofMinutes(1L))
3.6.2.8、思考(TODO)?
到这里已经基本上把Flink Watermark的核心知识点介绍完了,那么接下来有两个问题需要读者们一起来思考:
1.对于超出延迟范围的内的数据如何处理?(默认情况下是直接丢弃掉)
2.Watermark容错处理(实际场景中消费kafka的案例比较多,那么当程序挂掉重启之后watermark会恢复吗?如果不能恢复应该如何解决?)
3.7、State&State Backend
3.7.1、State
3.7.1.1、回顾
经过前面几篇文章的整理,我们已经学习到了Flink框架的特性以及数据流处理模型中的前两个环节(source、transformation)。在transformation环节中,基于无界流的场景下,我们引入了窗口的概念,并从完整的生命周期全貌进行了剖析,随之又引出了乱序数据场景下的解决方案,即watermark的定义和计算规则以及一些高级的问题抛出。前几篇的文章是从数据接入和数据计算的角度来学习flink,那么这里我们可能需要思考一个常问到的问题:对于Flink来说,是如何做到数据一致性(Exactly-Once)的?接下来几篇文章我们将针对这个高频面试题问题来详细展开讲解。首先在第一篇Flink框架介绍中,提到了Flink支持状态计算的概念。这个词汇对于老手们来讲再熟悉不过了,那么本篇将从以下几个方面来展开:
- 怎么理解状态?状态的作用是什么?
- 在Flink中状态类型有哪几种?
- 在实际的场景中如何使用状态?
3.7.1.2、状态介绍
What is State?
While many operations in a dataflow simply look at one individual event at a time (for example an event parser), some operations remember information across multiple events (for example window operators). These operations are called stateful。
这段英文来自于官网对状态的介绍。以上的英文直译的大概意思就是说:状态在Flink中叫做State,通常很多operator仅此一次对事件处理,但是有些operator会记录下多个事件的信息,那么这些operator就是有状态的。大白话来讲在应用程序中代表某个时刻某个task或者operator的状态,就是用来保存中间计算结果或者用来缓存数据的。
那么根据是否需要保存中间结果,又分为有状态计算和无状态计算。
- 对于流计算而言,如果每次计算都是相互独立的,不依赖上下游的事件,则是无状态计算
- 如果计算需要依赖之前或者后续的事件,那么就是有状态的计算
那么在这里举两个案例来解释下State的应用场景:
- 数据流中有重复数据,我们需要做去重处理,那么就需要知道之前接收到哪些数据并保存下来,这样每收到一条新的数据,都要与已经收到的数据比较是否重复
- 基于前面讲到的窗口统计求和场景,一般思路是将事件缓存起来,然后窗口触发计算进行求和,但是这种效率比较低,需要占用大量的内存。如果使用增量计算,每次只需要保s存当前所有值的总和,这样当新的事件到来时,只需要在中间结果基础上进行求和即可
3.7.1.3、状态类型
在算子层面,State根据是否在DataStream上指定Key划分为Keyed State和Operator State两大类型。
在流层面,State提供了BroadcastState在广播模式下使用,即将一个流的数据广播到所有的下游任务。它是Operator State的一种特殊类型。
在开发层面,State分为原生(Raw)和托管(Managed)。那托管的意思就是说由Flink来管理State,并对其进行优化、存储和恢复;而原生由用户进行管理、自行序列化,底层以字节数组的形式存储。
按照数据结构的不同,又可以将KeyedState和OperatorState进一步细分:
| 按是否有Key划分 | 支持的State | 作用 |
|---|---|---|
| KeyedState | ValueState |
保存一个可以更新和检索的值,这个值和对应的Key绑定,是最简单的状态。可以通过update()方法更新状态值,通过value()方法获取状态值 |
| KeyedState | ListState |
保存一个元素的列表,即key上的状态值为一个列表。可以通过add()方法进行增加,通过get()方法返回一个Iterable |
| KeyedState | ReducingState |
保存一个单值,通过用户传递的ReduceFunction,每次调用add方法增加值,会调用reduceFunction,最后合并到一个单一的状态值 |
| KeyedState | AggregatingState |
保留一个单值,和ReducingState |
| KeyedState | MapState |
使用Map存储Key-Value时,通过put |
| OperatorState | ListState |
同KeyedState的ListState |
以上所有类型的State都会有一个clear()方法,用于清除当前key下的状态数据,也就是当前输入元素的key.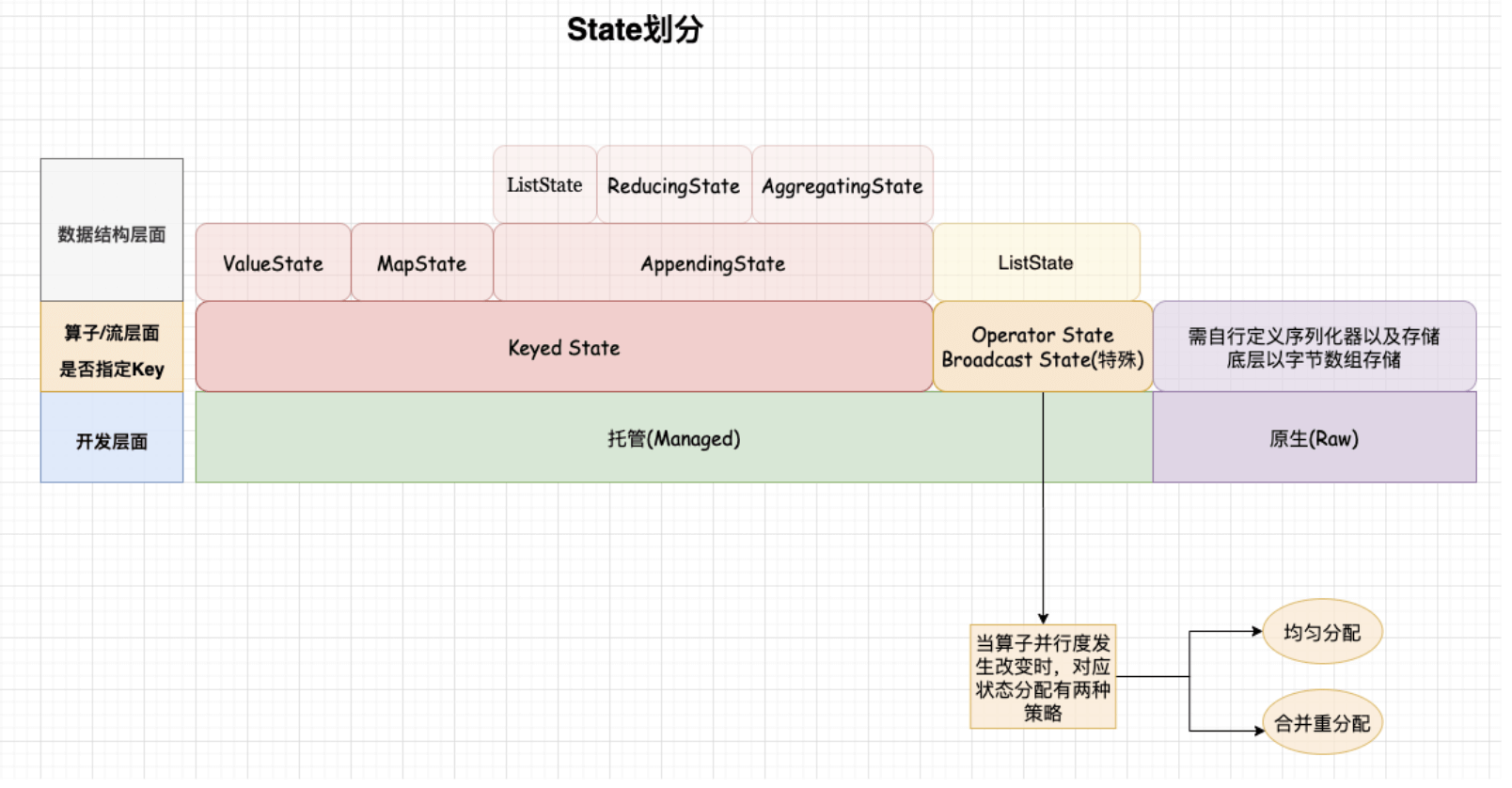
3.7.1.4、状态使用
实际开发中,对状态的使用总结有以下几个步骤:
- 先定义一个StateDescriptor,指定State名称和值类型
- 通过RuntimeContext获取State
- 对数据进行处理后进行更新
接下来将分别针对三种类型的State提供开发Demo:
| State类型 | State结构 | 需求实现 |
|---|---|---|
| KeyedState | ValueState |
实现简单的单词统计,且支持容错 |
| KeyedState | ListState |
实现去重功能 |
| KeyedState | ReducingState |
统计某网站每日总PV |
| KeyedState | MapState |
统计某网站每日UV以及每个用户的访问频次 |
| OperatorState | ListState |
可容错的source/sink实现 |
| BroadcastState | BroadcastState |
双流关联,实现简单拼接 |
3.7.1.4.1、Keyed State
1、ValueState
需求:使用ValueState来实现简单的单词统计,且支持容错;即当任务停止重启之后,计算值不丢失;具体代码见:ValueStateDemo.java
socketTextStream.map(t -> Tuple2.of(t.split(",")[0], Integer.parseInt(t.split(",")[1]))).returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class, Integer.class)).keyBy(t -> t.f0).map(new RichMapFunction<Tuple2<String, Integer>, Tuple2<String, Integer>>() {private transient ValueState<Integer> state;@Overridepublic void open(Configuration parameters) throws Exception {//1.定义状态描述器ValueStateDescriptor<Integer> valueStateDescriptor = new ValueStateDescriptor<>("wc-count", Integer.class);//2.获取状态state = getRuntimeContext().getState(valueStateDescriptor);super.open(parameters);}@Overridepublic Tuple2<String, Integer> map(Tuple2<String, Integer> value) throws Exception {if ("error".equalsIgnoreCase(value.f0)) {return Tuple2.of(value.f0, 1 / 0);}if (state.value() != null) {state.update(state.value() + value.f1);} else {state.update(value.f1);}return Tuple2.of(value.f0, state.value());}}).print()
2、ListState
需求:实现去重功能;具体代码见:ListStateDemo.java
socketTextStream.keyBy(t -> t.split("&")[0]).flatMap(new RichFlatMapFunction<String, String>() {private transient ListState<String> state;@Overridepublic void open(Configuration parameters) throws Exception {state = getRuntimeContext().getListState(new ListStateDescriptor<String>("distinct", String.class));super.open(parameters);}@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String str = value.split("&")[1];StringBuilder stringBuilder = new StringBuilder();Iterator<String> iterator = state.get().iterator();while (iterator.hasNext()) {String stateValue = iterator.next();stringBuilder.append(stateValue).append("\t");}String stateStr = stringBuilder.toString().trim();if ((stateStr.length() > 0 && !stateStr.contains(str)) || stateStr.length() == 0) {state.add(str);stateStr += "\t" + str;}out.collect("当前Key为:" + value.split("&")[0] + " 中间状态值为--->" + stateStr);}}).print();
3、ReducingState
需求:统计某网站每日总PV;具体代码见ReducingStateDemo.java
socketTextStream.keyBy(t -> t.split("&")[0]).process(new KeyedProcessFunction<String, String, Tuple2<String, Integer>>() {private transient ReducingState<Integer> reducingState;@Overridepublic void open(Configuration parameters) throws Exception {reducingState = getRuntimeContext().getReducingState(new ReducingStateDescriptor<Integer>("reduce", new ReduceFunction<Integer>() {@Overridepublic Integer reduce(Integer value1, Integer value2) throws Exception {return value1 + value2;}}, Integer.class));super.open(parameters);}@Overridepublic void processElement(String value, Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {Integer cnt = Integer.valueOf(value.split("&")[1].split("\\|\\|")[1]);reducingState.add(cnt);out.collect(Tuple2.of(value.split("&")[0], reducingState.get()));}}).print();
4、MapState
需求:统计某网站每日UV以及每个用户的访问频次;具体代码见MapStateDemo.java
socketTextStream.keyBy(t -> t.split("&")[0]).process(new KeyedProcessFunction<String, String, Tuple2<String, Integer>>() {private static final long serialVersionUID = 6805407325918189102L;//MapState用来统计UK出现的次数private transient MapState<String, Integer> mapState;//ValueState用来统计去重后的UK个数private transient ValueState<Integer> valueState;@Overridepublic void open(Configuration parameters) throws Exception {mapState = getRuntimeContext().getMapState(new MapStateDescriptor<String, Integer>("mapState", String.class, Integer.class));valueState = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("distinctState", Integer.class));super.open(parameters);}@Overridepublic void processElement(String value, Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {String str = value.split("&")[1];String uK = str.split("\\|\\|")[0];if (mapState.contains(uK)){mapState.put(uK,mapState.get(uK)+1);}else{mapState.put(uK,1);}List list = IteratorUtils.toList(mapState.keys().iterator());valueState.update(list.size());System.out.println("当前key:" + ctx.getCurrentKey() + " 去重UK统计个数为-->" + valueState.value() + " 当前UK出现的次数--->" + mapState.get(uK));out.collect(Tuple2.of(ctx.getCurrentKey(), valueState.value()));}}).print();
3.7.1.4.2、Operator State
Operator State从逻辑上理解,相当于一个并行度算子实例保存一份状态数据,没有key的概念,跟key无关。也就是说流中的元素会根据分区策略分配到不同的算子实例上,那么考虑到当应用重启时,不能保证流中元素和上一次的一样,还能经过该算子,所以在使用Operator State的时候需要实现 CheckpointedFunction接口,重构以下两个方法来设计snapshot和restore的逻辑,以此来保证容错:
//当执行checkpoint的时候,该方法会被调用;至于checkpoint相关知识点下篇文章讲解void snapshotState(FunctionSnapshotContext context) throws Exception;//当用户自定义函数初始化时,该方法会被调用;该方法不仅包含第一次初始化函数也包含从checkpoint中恢复时的一些逻辑void initializeState(FunctionInitializationContext context) throws Exception;
Operator State都是以List形式存储,算子和算子之间的状态数据相互独立。和Keyed State不同的是,Operator State支持当算子并行度发生变化时自动重新分配状态数据。目前有两种分配策略:
- 均匀再分配(Even-split redistribution)
每一个算子返回一个List形式的状态数据。从逻辑上讲,所有算子对应的List形式State数据合并后为整个作业的状态数据。也就是说每个算子都只是包含部分状态数据,当进行恢复或者重分区的时候,就会把整个状态均匀划分多个List。例如:当并行度为1时,状态数据包含元素1和元素2。当把并行度调整为2时,那么元素1就会被分配到算子1上,元素2分配到算子2上。
- 合并重新分配(Union redistribution)
即每个算子实例都会包含整个状态数据,当发生恢复或者重分区时,每个Operator都会获取状态元素的完整数据。当作业存储的状态数据非常大时,不要使用该种策略,否则会出现OOM的情况

具体代码见OperatorStateMain.java:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.enableCheckpointing(3000L);SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");Calendar calendar = Calendar.getInstance();env.addSource(new CounterSource()).map(t -> Tuple2.of(simpleDateFormat.format(calendar.getTime()), Integer.valueOf(Math.toIntExact(t)))).returns(TupleTypeInfo.getBasicTupleTypeInfo(String.class, Integer.class)).addSink(new BufferingSink(10));env.execute();
3.7.1.4.3、Broadcast State
Broadcast State是一种特殊的Operator State。
引入它是为了支持将一个流的记录广播到所有下游任务,而且这些记录在所有的sub task之间都会保持相同的状态,同时也可以被第二个流进行访问。那么和Operator State的区别在于:
- 它内部通过一个Map来维护
- 只适用于有广播流,而且可以有多个不同的broadcast state,通过名称来区分。这也就是说明为什么内部通过map来维护
另需要注意的是:
- 在Flink中,task之间不能通信,为了保证多并行度下算子获取broadcast state的一致性,只有广播流才能对broadcast state进行读写,而普通流只能读broadcast state。
- 在Flink中,所有的task都会对broadcast state进行checkpoint,尽管这么设计会将checkpoint的存储大小扩大了p倍(p代表了并行度),但这样可以保证在还原任务的时候可以快速从同一个文件中读取,避免热点问题
- 在Flink中,broadcast state通常存储在内存中(当然所有的Operator State都是存储于内存中的),所以尽量避免广播状态数据过大,导致OOM
需求:双流关联,实现拼接;具体代码见:BroadCastStateDemo.java
env.addSource(new MyWordSource(demoList)).connect(broadcast).process(new BroadcastProcessFunction<String, String, String>() {@Overridepublic void processElement(String value, ReadOnlyContext ctx, Collector<String> out) throws Exception {out.collect(value + "---->" + ctx.getBroadcastState(BROADCAST).get("broadcastKey"));}@Overridepublic void processBroadcastElement(String value, Context ctx, Collector<String> out) throws Exception {ctx.getBroadcastState(BROADCAST).put("broadcastKey", "广播变量:" + value + " 附加随机数:" + Math.random());}}).map(new RichMapFunction<String, String>() {@Overridepublic String map(String value) throws Exception {int indexOfThisSubtask = getRuntimeContext().getIndexOfThisSubtask();return indexOfThisSubtask + "---->" + value;}}).print();
3.7.2、State Backend(该小节为草稿:待更新)
上篇文章中简单介绍了Flink State的类型和使用场景,由此可知Flink State主要作用就是用来缓存中间结果数据,那么缓存起来的中间数据被Flink存储到什么地方了呢?本文将围绕这一问题展开介绍Flink State存储相关知识点。具体如下:
- Flink支持的State存储介质
- 如何配置支持的State Backend
- 当缓存数据量过大或者缓存周期较长时,Flink是如何管理的?
- State Backend优化点
- State Backend相关参数配置
3.7.2.1、状态存储
3.7.2.2、状态管理
增量存储、过期清理等
3.7.2.3、TTL启用
TTL(过期时间)可以配置到任意类型的State上,当State Value过期时,那么存储的状态数据就会被清理。当然对于List和Map类型的State,可以针对某个Key设置过期时间。在使用TTL时,首先一定要通过StateTtlConfig进行配置,具体语法如下:
StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(1)).setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite) //仅在创建和写入的时候刷新TTL,默认条件下使用OnCreateAndWrite策略;OnReadAndWrite代表在读取和写入的时候刷新TTL.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired) //设置状态可见性策略;默认为不返回过期状态数据;ReturnExpiredIfNotCleanedUp:可以返回过期但未被清除的状态数据.build();
在设置TTL过期时间的同时也可以针对TTL刷新间隔和状态数据可见性进行设置。
对于刷新TTL设置,有以下几种策略:
- OnCreateAndWrite(默认策略)
在进行创建和写入更新的时候可以刷新TTL - OnReadAndWrite
在读取和写入的时候可以刷新TTL - Disabled
禁止刷新
对于数据可见性,有以下几种策略:
- ReturnExpiredIfNotCleanedUp
可以返回已过期但还未删除的状态数据。这里有几点需要注意:- State Backend会存储数据的最近一次更新时间,这也就是说使用该策略会增加State Backend的消耗。对于Heap State Backend类型会在内存中额外存储一个Java对象的引用和一个私有的long类型数值。对于RocksDB State Backend为每个存储值、List或者Map额外添加8个字节
- 目前TTL的设置只支持processing time类型
- 当使用启用TTL的程序来恢复未启用TTL的状态时,会出现兼容性问题,可能会抛出StateMigrationException
- TTL不是Checkpoint或Savepoint的一部分,而是Flink对于当前作业的一种处理方式
- 对于Map State类型,如果用户设置的Value Serializer支持NULL Value的话,那么TTL也会作用于NULL值上;如果不支持NULL,那么可以使用NullableSerializer进行包装
- NeverReturnExpired(默认策略)
不返回已过期的状态数据,对于一些针对数据严格的场景可以使用该种策略(例如对于一些敏感数据的可见性设置)。
清理过期State
默认情况下,当State值过期后,会在读取时显示进行清除。例如当调用ValueState#value时,如果对应的状态值过期了,那么就会立即进行清除。如果State Backend支持清理功能的话,那么会定期在GC时进行清理,当然也可以禁用该功能。
StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(1)).disableCleanupInBackground() //禁用后台清理,该参数不适用于RocksDB StateBackend增量模式.build();
注意:如果是已存在的job,那么从SavePoint重启的时候可以通过StateTtlConfig再次进行启用或禁用
增量清理
对于State的清理,还有另外一种选择就是逐步触发清理删除,触发方式可以通过在状态访问或者event处理时进行回调。如果对于某些State开启了清除策略,那么State Backend就会生成一个全局惰性的迭代器,每次触发清除时,该迭代器就会遍历检测过期的State进行清除。具体设置代码如下:
StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(1)).cleanupIncrementally(10, true) //每次访问State时都会触发一次清除,第一个参数表示要检测的条数,第二个参数表示是否在每个record处理时触发清理;默认是在Heap State Backend上每次检测5条,且不在每个record处理时进行触发.build();
注意:
- 如果没有状态访问发生或者事件处理时,那么过期状态就会持久化,也就是说无法触发清除动作
- 增量清理动作将会增加事件处理的延迟
- 目前增量清除不支持RocksDB,仅支持Heap State Backend
- 如果Heap State Backend使用synchronous snapshot的话,因为全局迭代器不支持并发修改,那么全局的迭代器在迭代遍历的时候会把所有的key拷贝一份,所以这会加重内存消耗。当然对于asynchronous snapshot不会出现这种问题
- 对于已经存在的job,可以在从savepoint中恢复时启用或者禁用该清理策略。
RocksDB 压缩清理
当使用RocksDB State Backend时,后台会定期异步调用特定的压缩过滤器进行合并状态更新来减少存储,同时该过滤器会使用TTL检查状态是否过期来清除过期State。具体使用代码如下:
StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(1)).cleanupInRocksdbCompactFilter(1000) //当处理了1000条记录后,RocksDB压缩过滤器就会查询当前时间戳来检查状态是否过期.build();
如上面代码设置,可以通过减少处理条数来加快清理速度,但因为底层使用了JNI调用,因此会降低压缩性能。这里需要用户在压缩和清除之间平衡好。默认设置是每1000条,就会查询当前时间戳进行更新。另外可以通过设置log4j.logger.org.rocksdb.FlinkCompactionFilter=DEBUG参数开启debug模式。
注意:
- 由于TTL过滤器必须解析上次访问的时间戳来检查每个存储状态对应的key是否到达了过期时间,特别是list或者map类型的state,还会内部每个元素进行检查。因此在压缩期间调用TTL过滤器会降低压缩速度。
- 如果此功能与列表状态(List State)一起使用的话,由于列表状态的元素具有不固定的字节长度,则TTL过滤器必须至少在每个第一个状态项都过期的每个状态条目上,通过JNI额外调用该元素的Flink Java类型序列化器来确定下一个未过期元素的偏移量。
- 对于已经存在的job,可以在从savepoint中恢复时启用或者禁用该清理策略
3.8、CDC
3.8.0、准备工作
在开始研究Flink CDC原理之前(本篇先以CDC1.0版本介绍,后续会延伸介绍2.0的功能),需要做以下几个工作(本篇以Flink1.12环境开始着手)
1、打开Flink官网(查看Connector模块介绍)
2、打开Github,下载源码
apache-flink
flink-cdc-connectors
debezium
3、开始入坑
3.8.1、设计提议
参考资料:FLIP-105
3.8.1.1、设计动机
CDC(Change data Capture,捕捉变更数据)在企业中是一种比较流行的模式,主要用于数据同步、搜索索引、缓存更新等场景;社区早期需要支持能够将变更日志直接提取及解释为Table API和SQL的功能以此来扩宽Flink的使用场景。
从另一方面来讲早期提出了“动态表”的概念,并定义了在流上的两种模式:append模式和update模式。Flink已经支持将流转换为动态表的append模式,但还不支持update模式,所以对changelog的解释是为了填补缺失的一块拼图,以此来获得完整的动态表概念。当然现在不仅仅支持update,还支持retract模式,后面会单独讲解。
3.8.1.2、CDC工具选型
常见的CDC方案比较如下图:
一、功能完善
对于CDC工具,目前有很多选型,如Debezium、Canal等流行解决方案;目前Debezium支持Mysql,PG,SQL Server,Oracle,Cassandra和Mongo,如果Flink支持Debezium,那么也就意味着可以Flink可以连接下面截图中所有数据库的变更日志,对于完善整个生态系统是有利的。其中Debezium支持全量+增量同步,非常灵活,使得Exactly-Once成为可能。
Debezium支持的数据库类型如下图:
二、拥抱社区,便于扩展
如果选择Debezium作为Flink的嵌入式引擎,可以作为一个依赖包嵌入到代码库,而不用通过kafka connector运行,同样也可以不再需要直接与 MySQL 服务器通信,不需要处理复杂快照、GTID、锁等等优点。同时可以拥抱Debezium社区并与之合作
三、内部数据结构相似
对于Flink SQL内部的数据结构RowData类型都有一个元数据RowKind,有4种类型,即插入(Insert)、更新(更新前UPDATE_BEFORE,更新后UPDATE_AFTER)、删除(DELETE),可以发现这四种数据类型和Binlog的结构基本保持一致。
这里解释下Debezium的数据结构中各个元数据字段的含义:
- before字段:是一个可选字段,代表事件发生前行的状态,如果是一个create操作,那么该字段值为null。
- after字段:是一个可选字段,代表事件发生后行的状态,如果是一个delete操作,那么该字段值为null。
- source:是一个必选字段,包括事件的元信息,如offset,binlog文件,数据库和表。
- ts_ms:代表的是Debezium处理事件的时间戳
- OP字段:该字段也有4种取值,分别是C(create)、U(Update)、D(Delete)、Read(R)。对于U操作,其数据部分同时包含了Before和After。
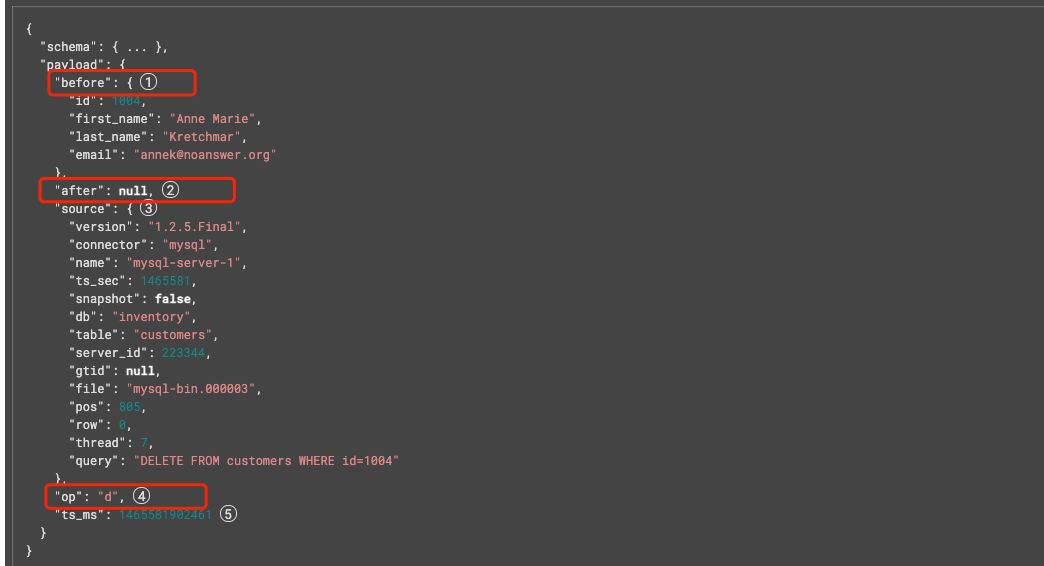
3.8.2、Concepts
这里会涉及到很多的概念,大家先有一个认知,后面会单独拆分进行讲解。
3.8.2.1、Stream
流的概念其实很好理解,Stream具有两个特性:有界性和变化模式。那么接下来分别介绍这两个特性:
1、变化模式

如上图所示:动态表模式有两种,append模式和replace模式(upsert和retract)。接下来简单介绍下两者之间的区别
对于append模式,很容易理解。如果表定义中未指定主键,那么就通过将流记录作为新的一行附加到表中,一旦将记录添加到表中,那么就永远不会更新或者删除。
对于Replace模式,如果表中定义了主键key,那么当不存在具有相同键属性的记录,就会插入到表中,否则就会进行替换。那么针对replace模式,又细分为upsert和retract两者模式:
对于Upsert模式,包含Upsert(insert 和 update)和DELETE两种消息,该模式和retract模式的主要区别在于UPDATE更改会使用单个消息进行编码,效率会更高些。
对于Retract模式,一个update流包含ADD和RETRACT消息,对于一个Insert更改会编码成ADD消息,对于DELETE更改会编码成RETRACT消息,对于UPDATE变更,会编码为Updated-Before作为retract消息和ADD消息。该种模式对于update事件需要拆解为两个消息,效率会相对低些。 这里简单介绍下什么是回撤流,如下图所示:
| Operation | User | Count(url) | Mark |
|---|---|---|---|
| I(Insert) | Mary | 1 | |
| I(Insert) | Bob | 1 | |
| 会删除该记录 | |||
| +U(Update-After) | Mary | 2 | |
| I(Insert) | Liz | 1 | |
| 会删除该记录 | |||
| +U(Update-After) | Bob | 2 |

2、有界性
有界流:由大小有界限的事件组成,作业查询处理当前可用的数据并将在此之后结束。
无界流:由无限的事件组成,如果输入是无界流,则查询会在所有数据到来时连续处理。
总结:
| Boundedness \ Change Mode | Append | Update |
|---|---|---|
| Unbounded | Append Unbounded Stream e.g. Kafka logs |
Update Unbounded Stream e.g. continuously capture changes of MySQL table |
| Bounded | Append Bounded Stream e.g. a parquet file in HDFS, a MySQL table |
Update Bounded Stream e.g. capture changes of MySQL table until a point of time |
3.8.2.2、动态表Dynamic Table
动态表是随时间变化的表,可以像传统的常规表一样进行查询。动态表可以转换为流,流可以转换为动态表(需要具有相同模式,转换方式取决于表模式是否包含主键的定义)。注意:在 Flink SQL 中创建的所有表都是动态表,对动态表的查询会生成一个新的动态表(根据输入进行更新),查询是否终止取决于输入的有界性。
DynamicTable 是一个概念对象,stream 是一个物理表示。
3.8.2.3、Changelog
Changelog(变更日志)是一个附加流(append stream),由包含变更操作列(用于插入/删除标志或将来更多)的行和实际的元数据列组成。对于Flink CDC的设计其目标就是提取变更日志的事件,并将它们转换为变更操作(如insert,update,delete事件)。
从一个append stream转换为update stream(即解释变更日志 Interpret Changelog)。
从一个update stream转换为append stream(发出变更日志 Emit Changelog)。
在Flink SQL中,数据从一个算子流向另外一个算子时都是以一种Changelog Stream的方式,任意时刻的Changelog Stream都可以翻译成一个表或者一个流,如下图所示:
下图将完整的展示Stream类型和Table之间的转换:
不同的CDC工具对于Changelog可能有不同的编码方式,那么对于flink来说也是一个很大的挑战。这里以目前两个比较流行的解决方案:Debezium和Canal为例分别介绍一下:
拿Debezium来说,Debezium是一个构建在Kafka Connector之上的CDC工具,它可以将实时更改流传输到Kafka中 ,Debezium为Kafka的变更日志生成了统一的格式,以更新操作为例:
{"before": {"id": 1004,"first_name": "Anne","last_name": "Kretchmar","email": "annek@noanswer.org"}, //before作为可选字段,如果是create操作,则该字段为null"after": {"id": 1004,"first_name": "Anne Marie","last_name": "Kretchmar","email": "annek@noanswer.org"}, //after作为可选字段,如果是delete操作,则该字段为null"source": { ... },//强制字段,标识事件元信息,如offset,binlog file,database,table 等等。"op": "u", //强制字段,用来描述操作类型,如C(create),U(update),D(delete)"ts_ms": 1465581029523}
默认情况下,Debezium 会为删除操作输出两个事件:DELETE 事件和Tombstone(墓碑)事件(具有空值/有效负载),该 tombstone事件用于Kafka压缩机制。需要注意的是:Debezium并不是一个存储系统,而是代表了一个存储格式,该格式基于JSON格式,可以将反序列化结果行转换为ChangeRow或者Tuple2
Canal是国内流行的CDC工具,用来捕获Mysql到其他系统的变更,支持JSON格式和protobuf格式的Kafka和RocketMQ流变化,这里以update操作为例:
{"data": [{//表示真实的数据,如果是更新操作,则是更新后的状态,如果是删除操作,则是删除之前的状态。"id": "13","username": "13","password": "6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9","name": "Canal Manager V2"}],"old": [ //可选字段,如果不是update操作,那么该字段为null{"id": "13","username": "13","password": "6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9","name": "Canal Manager"}],"database": "canal_manager","es": 1568972368000,"id": 11,"isDdl": false,"mysqlType": {...},"pkNames": ["id"],"sql": "","sqlType": {...},"table": "canal_user","ts": 1568972369005,"type": "UPDATE"}
Flink针对这两个主流的CDC工具编码格式都进行了支持,可以通过format=”canal-json”或者format=”debezium-json”。
3.8.3、源码追溯
从上面的小节中提到Flink选用Debezium作为嵌入式引擎实现CDC,目前Flink CDC已经支持的连接器如下表格:
注意:对于Mongo的连接器支持需要在Flink CDC2.0版本中使用
| Database | Version |
|---|---|
| MySQL | Database: 5.7, 8.0.x JDBC Driver: 8.0.16 |
| PostgreSQL | Database: 9.6, 10, 11, 12 JDBC Driver: 42.2.12 |
| MongoDB | Database: 4.0, 4.2, 5.0 MongoDB Driver: 4.3.1 |
Flink CDC Connectors连接器对应的Flink版本如下表格:
| Flink CDC Connector Version | Flink Version |
|---|---|
| 1.0.0 | 1.11.* |
| 1.1.0 | 1.11.* |
| 1.2.0 | 1.12.* |
| 1.3.0 | 1.12.* |
| 1.4.0 | 1.13.* |
| 2.0.0 | 1.13.* |
3.8.3.1、Debezium-Mysql
在深入了解下Flink是如何结合Debezium,以及具体的交互流程之前先来简单看下Debezium是如何实现事件变更捕获的。下图是Debezium(以Debezium1.2版本为例)在整个CDC链路中的角色: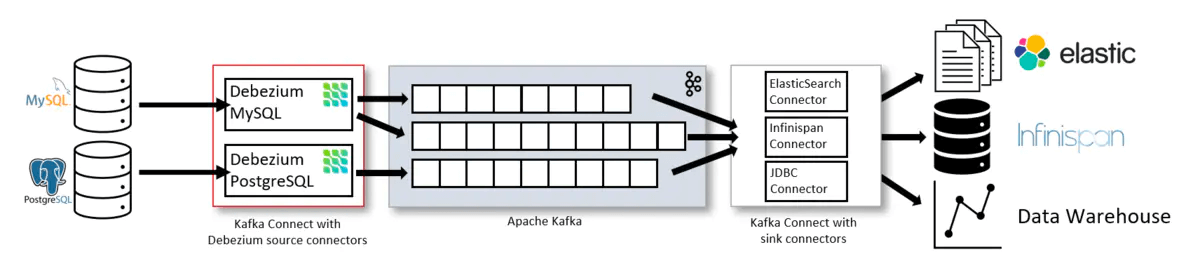
以Mysql例,在使用Debezium前,需要准备以下几点工作:
3.8.3.1.1.0、准备工作
1、需要对mysql账户进行授权
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user' IDENTIFIED BY 'password';
2、开启Mysql binlog
-- 1、检查是否已经开启SELECT variable_value as "BINARY LOGGING STATUS (log-bin) ::"FROM information_schema.global_variables WHERE variable_name='log_bin';--2、配置服务文件,开启binlogserver-id = 223344log_bin = mysql-binbinlog_format = ROWbinlog_row_image = FULLexpire_logs_days = 10
3、开启GTID
全局事务标识符(GTIDs)可以唯一地识别集群内服务器上发生的事务。虽然Debezium MySQL Connector不需要,但使用GTIDs可以简化复制,更容易确认主服务器和从服务器是否一致,GTIDS只在Mysql5.6+之后才能使用
-- 1、开启gtid_modegtid_mode=ON--2、开启enforce_gtid_consistencyenforce_gtid_consistency=ON--3、检测是否生效show global variables like '%GTID%';
3.8.3.1.1.1、Performs Database Snapshots(全量读取)
当Mysql Connector第一次启动的时候会先对数据库执行初始化一致性快照,其主要是因为通常Mysql会被设置为在一定时间段后清除binlog,所以为了保证exactly-once,先做快照。默认快照模式为inital,可以通过snapshot.mode参数调整。接下来看具体快照的细节:
- 先获取一个全局读锁来阻塞其他客户端写入(如果Debezium检测到不允许使用全局锁的时候就会改换为表级别的锁),需要注意的是:快照本身并不能阻止其他客户执行DDL,因为这可能会干扰Connector试图读取binlog位置和表 Schema。全局读锁在读取binlog位置时被保留,然后在后面的步骤中释放。
- 开启一个可重复读的事务以此来确保后续所有的读取都是针对一致的快照进行的。
- 读取当前binlog位置。
- 读取Connecto配置所允许库表对应的Schema。
- 释放全局读锁/表级别锁,这个时候其他客户端可以写入。
- 将DDL变更语句写入对应的topic中(这里也是为了保证一致性来保存所有的DDL语句,当connector在崩溃或者被优雅停止后重新启动的时候就可以从这个topic中读取所有的DDL语句来重建特定时间点下的表结构直到崩溃前binlog的那个点以此防止schema不一致出现异常)。
- 扫描库表,并在特定表的topic上为每一行生成一个事件。
- 提交事务,在Connector偏移量中记录已完成的快照。
如果Connector在制作快照的时候发生了失败,那么在重新启动的时候会创建一个新的快照,一旦快照完成,就会从binlog相同位置开始读取,这样不会丢失任何变更事件。如果Connector停止时间过长,MySQL服务器会清除较早的binlog文件,Connector的最后位置可能会丢失。当Connector重新启动时,MySQL服务器不再有起点,Connector会执行另一个初始快照。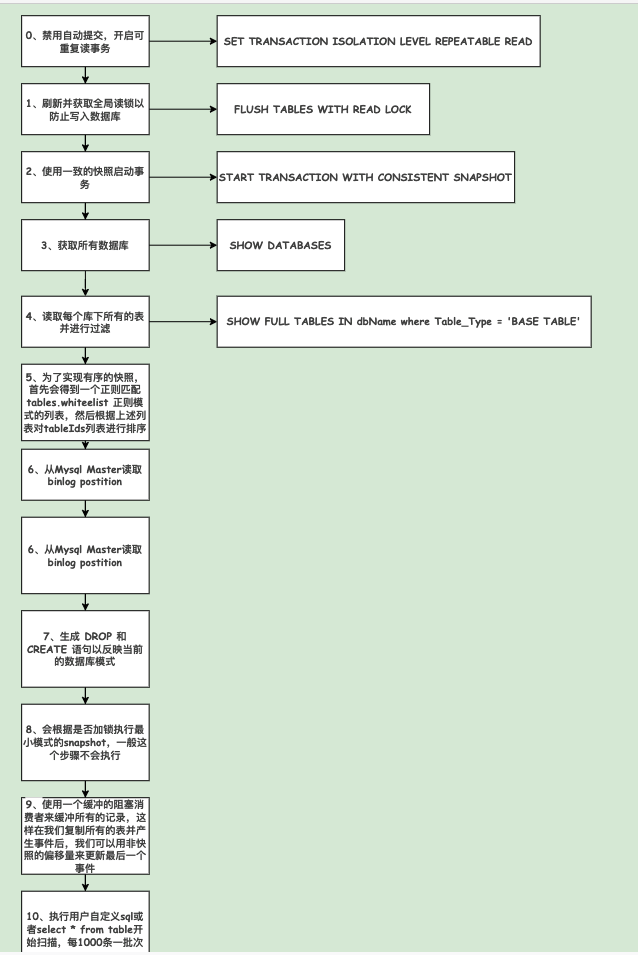
3.8.3.1.1.2、增量读取
- 初始化一个Binlog客户端,并将会开启一个线程名为binlog-client
- client会注册事件监听器,这里面会调用一个handleEvent方法,主要进行offset更新、转发事件处理、心跳通知等逻辑,例如当mysqld写入切换到一个新的binlog时候或执行flush logs或当前binlog文件大小大于max_binlog_size的时候,会重新设置binlog position。
- 配置一系列反序列化器根据事件类型不同进行解析,比如事件的delete、update、insert。然后会分别调用handleDelete、handleUpdate、handleInsert等事件处理器进行处理。
- 监听到一个事件到来的时候会根据具体的事件类型分别调用具体的处理器,这里不作为重点讲解。本篇主要讲解flink如何接收到这部分数据并转换自身所支持的数据结构。
3.8.3.2、Flink-cdc-mysql
关于Flink是如何调用Debezium引擎的,会有单独的篇文来介绍。这里先给出一个调用关系图,读者后续有时间可以自行阅读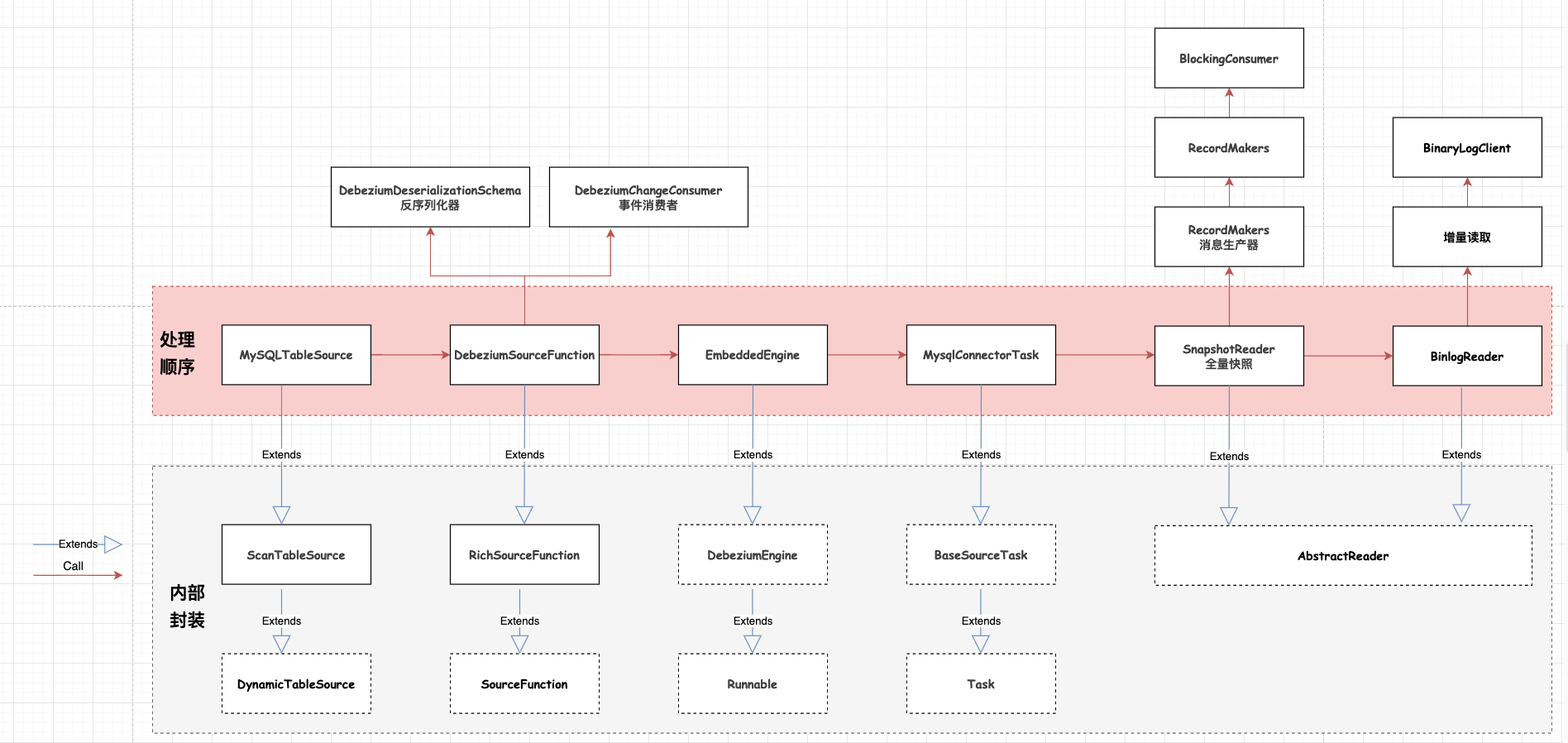
3.8.3.3、Debezium-Mysql Properties
以下表格是debezium自带的配置文件,在flink cdc中依然是可以复用的,只需要在使用之前加上“debezium.”前缀即可生效。
| Property | Default | Description |
|---|---|---|
| name | Connector的唯一名称,如果名字相同会失败报错 | |
| connector.class | Connector连接器的加载类,对于Mysql连接器使用io.debezium.connector.mysql.MySqlConnector | |
| tasks.max | 1 | Connector创建的最大任务数,对于mysql来说只使用一个任务。 |
| database.hostname | Mysql数据库地址 | |
| database.port | 3306 | Mysql数据库端口 |
| database.user | Mysql数据库认证用户名 | |
| database.password | Mysql数据库认证密码 | |
| database.server.name | Mysql服务名称 | |
| database.server.id | random | Mysql服务ID |
| database.history.kafka.topic | 存放库表历史Schema的Topic | |
| database.history.kafka.bootstrap.servers | 存放库表历史Schema的kafka地址 | |
| database.whitelist | empty string | 一个可选的逗号分隔的正则表达式列表,与要监控的数据库名称相匹配;任何不包括在白名单中的数据库名称将被排除在监控之外。默认情况下,所有数据库都将被监控。不能与database.blacklist一起使用 |
| database.blacklist | empty string | 一个可选的逗号分隔的正则表达式列表,与数据库名称相匹配,以排除在监控之外;任何不包括在黑名单中的数据库名称将被监控。不能与database.whitelist一起使用 |
| table.whitelist | empty string | 一个可选的逗号分隔的正则表达式列表,用于匹配要监控的表的全称表标识符;任何不包括在白名单中的表将被排除在监控之外。每个标识符的形式是databaseName.tableName。默认情况下,连接器将监控每个被监控数据库中的每个非系统表。不能与table.blacklist一起使用 |
| table.blacklist | empty string | 一个可选的逗号分隔的正则表达式列表,用于匹配要从监控中排除的表的全称表标识符;任何不包括在黑名单中的表都将被监控。每个标识符的形式是databaseName.tableName。不能与table.whitelist一起使用 |
| column.blacklist | empty string | 一个可选的逗号分隔的正则表达式列表,该列表与应从更改事件消息值中排除的列的全称名称相匹配。列的全称是数据库名.表名.列名,或者数据库名.模式名.表名.列名 |
| column.truncate.to.length.chars | n/a | 一个可选的逗号分隔的正则表达式列表,它与基于字符的列的完全限定名称相匹配,如果字段值长于指定的字符数,其值应在变更事件消息值中被截断。在一个配置中可以使用具有不同长度的多个属性,尽管在每个属性中长度必须是一个正整数。列的全称是数据库名.表名.列名的形式 |
| column.mask.with.length.chars | n/a | 当列长度超过指定长度,那么多余的值由*来替换 |
| column.mask.hash.hashAlgorithm.with.salt.salt | n/a | 列加盐操作 |
| time.precision.mode | adaptive_time_microseconds | 时间、日期和时间戳可以用不同种类的精度表示,包括。adaptive_time_microseconds(默认)根据数据库列的类型,使用毫秒、微秒或纳秒的精度值,准确捕获日期、数据时间和时间戳的值,但TIME类型的字段除外,它总是被捕获为微秒。adaptive(已弃用)根据数据库列的类型,使用毫秒、微秒或纳秒的精度,完全按照数据库中的时间和时间戳值来捕捉;或者connector总是使用Kafka Connector内置的时间、日期和时间戳的表示法来表示时间和时间戳值,它使用毫秒精度,而不管数据库列的精度 |
| decimal.handling.mode | precise | 指定连接器应该如何处理DECIMAL和NUMERIC列的值:precision(默认)使用java.math.BigDecimal值精确表示它们,在变化事件中以二进制形式表示;或者使用double值表示它们,这可能会导致精度的损失,但会更容易使用。 string选项将值编码为格式化的字符串,这很容易使用,但会失去关于真正类型的语义信息 |
| bigint.unsigned.handling.mode | long | 指定BIGINT UNSIGNED列在变化事件中的表示方式,包括:precision使用java.math.BigDecimal表示数值,在变化事件中使用二进制表示法和Kafka Connect的org.apache.kafka.connect.data.Decimal类型进行编码; long(默认)使用Java的long表示数值,它可能不提供精度,但在消费者中使用起来会容易得多。只有在处理大于2^63的值时,才应该使用精确设置,因为这些值不能用long来表达。 |
| include.schema.changes | true | 指定是否要将数据库schema变更事件推送到Topic中 |
| include.query | false | 指定连接器是否应包括产生变化事件的原始SQL查询。 注意:这个选项要求MySQL在配置时将binlog_rows_query_log_events选项设置为ON。查询将不会出现在从快照过程中产生的事件中。 启用该选项可能会暴露出被明确列入黑名单的表或字段,或通过在变更事件中包括原始SQL语句而被掩盖。出于这个原因,这个选项默认为 “false” |
| event.processing.failure.handling.mode | fail | 指定connector在反序列化binlog事件过程中对异常的反应。 fail表示将传播异常,停止Connector Warn将记录有问题的事件及binlog偏移量,然后跳过 skip:直接跳过有问题的事件 |
| inconsistent.schema.handling.mode | fail | 指定连接器应该如何应对与内部Schema表示中不存在的表有关的binlog事件(即内部表示与数据库不一致)。 fail将抛出一个异常(指出有问题的事件及其binlog偏移),并停止连接器。 warn将跳过有问题的事件,并把有问题事件和它的binlog偏移量记录下来。 skip将跳过有问题的事件。 |
| max.queue.size | 8192 | 指定阻塞队列的最大长度,从数据库日志中读取的变更事件在写入Kafka之前会被放入该队列。这个队列可以为binlog reader提供反向压力,例如,当写到Kafka的速度较慢或Kafka不可用时。出现在队列中的事件不包括在这个连接器定期记录的偏移量中。默认为8192,并且应该总是大于max.batch.size属性中指定的最大批次大小。 |
| max.batch.size | 2048 | 指定在该连接器的每次迭代中应处理的每批事件的最大长度。默认值为2048 |
| poll.interval.ms | 1000 | 指定连接器在每次迭代过程中等待新的变化事件出现的毫秒数。默认为1000毫秒,或1秒 |
| connect.timeout.ms | 30000 | 指定该连接器在尝试连接到MySQL数据库服务器后,在超时前应等待的最大时间(毫秒)。默认值为30秒 |
| tombstones.on.delete | true | 控制是否应在删除事件后生成墓碑事件。 当为真时,删除操作由一个删除事件和一个后续的墓碑事件表示。当false时,只有一个删除事件被发送。 发出墓碑事件(默认行为)允许Kafka在源记录被删除后完全删除所有与给定键有关的事件。 |
| message.key.columns | empty string | 一个分号的正则表达式列表,匹配完全限定的表和列,以映射一个主键。 每一项(正则表达式)必须与代表自定义键的<完全限定的表>:<列的逗号分隔列表>相匹配。 完全限定的表可以定义为databaseName.tableName。 |
| binary.handling.mode | bytes | 指定二进制(blob、binary、varbinary等)列在变化事件中的表示方式,包括:bytes表示二进制数据为字节数组(默认),base64表示二进制数据为base64编码的String,hex表示二进制数据为hex编码的(base16)String |
| connect.keep.alive | true | 指定是否应使用单独的线程来确保与MySQL服务器/集群保持连接 |
|---|---|---|
| table.ignore.builtin | true | 指定是否应该忽略内置系统表。无论表的白名单或黑名单如何,这都适用。默认情况下,系统表被排除在监控之外,当对任何系统表进行更改时,不会产生任何事件。 |
| database.history.kafka.recovery.poll.interval.ms | 100 | 用于指定连接器在启动/恢复期间轮询持久数据时应等待的最大毫秒数。默认值是100ms |
| database.history.kafka.recovery.attempts | 4 | 在连接器恢复之前,连接器尝试读取持久化历史数据的最大次数。没有收到数据后的最大等待时间是recovery.attempts x recovery.poll.interval.ms |
| database.history.skip.unparseable.ddl | false | 指定连接器是否应该忽略畸形或未知的数据库语句,或停止处理并让操作者修复问题。安全的默认值是false。跳过应该谨慎使用,因为在处理binlog时,它可能导致数据丢失或混乱 |
| database.history.store.only.monitored.tables.ddl | false | 指定连接器是否应该记录所有的DDL语句或(当为true时)只记录那些与Debezium监控的表有关的语句(通过过滤器配置)。安全的默认值是false。这个功能应该谨慎使用,因为当过滤器被改变时,可能需要缺失的数据。 |
| database.ssl.mode | disabled | 指定是否使用加密的连接。默认是disabled,并指定使用未加密的连接。 如果服务器支持安全连接,preferred选项会建立一个加密连接,否则会退回到未加密连接。 required选项建立一个加密连接,但如果由于任何原因不能建立加密连接,则会失败。 verify_ca选项的行为类似于required,但是它还会根据配置的证书颁发机构(CA)证书来验证服务器的TLS证书,如果它不匹配任何有效的CA证书,则会失败。 verify_identity选项的行为与verify_ca类似,但另外验证服务器证书与远程连接的主机是否匹配。 |
| binlog.buffer.size | 0 | Binlog Reader使用的缓冲区的大小。 在特定条件下,MySQL Binlog可能包含Roldback语句完成的未提交的数据。典型示例正在使用SavePoints或混合单个事务中的临时和常规表更改。 当检测到事务的开始时,Debezium尝试向前滚动Binlog位置并找到提交或回滚,以便决定事务的更改是否会流流。缓冲区的大小定义了Debezium可以在搜索事务边界的同时的交易中的最大变化次数。如果事务的大小大于缓冲区,则Debezium需要重新卷起并重新读取流式传输时不适合缓冲区的事件。0代表禁用缓冲。默认情况下禁用。 注意:此功能还在测试 |
| snapshot.mode | initial | 指定连接器在启动允许快照时的模式。默认为inital,并指定仅在没有为逻辑服务器名称记录偏移时才能运行快照。 when_needed选项指定在启动时运行快照,只要它认为它需要(当没有可用偏移时,或者以前记录的偏移量在指定服务器中不可用的Binlog位置或GTID)。 never选项指定不运行快照。 schema_only选项只获取启动以来的更改。 schema_only_recovery选项是现有连接器的恢复选项,用来恢复损坏或者丢失的数据库历史topic |
| snapshot.locking.mode | minimal | 控制连接器是否持续获取全局MySQL读取锁(防止数据库的任何更新)执行快照。有三种可能的值minimal,extended,none。 minimal仅在连接器读取数据库模式和其他元数据时保持全局读取锁定仅适用于快照的初始部分。快照中的剩余工作涉及从每个表中选择所有行,即使在不再保持全局读取锁定状态时,也可以使用可重复读取事务以一致的方式完成。虽然其他MySQL客户端正在更新数据库。 extended指在某些情况下客户端提交MySQL从可重复读取语义中排除的操作,可能需要阻止所有写入的全部持续时间。 None将阻止连接器在快照过程中获取任何表锁。此值可以与所有快照模式一起使用,但仅在快照时不发生Schema更改时,才能使用。注意:对于使用MyISAM引擎定义的表,表仍将被锁定,只要该属性设置为MyISAM获取表锁定。InnoDB引擎获取的是行级锁 |
| snapshot.select.statement.overrides | 控制哪些表的行将被包含在快照中。此属性包含一个以逗号分隔的完全限定的表(DB_NAME.TABLE_NAME)的列表。单个表的选择语句在进一步的配置属性中指定,每个表由 id snapshot.select.statement.overrides.[DB_NAME].[TABLE_NAME] 识别。这些属性的值是在快照期间从特定表检索数据时要使用的 SELECT 语句。对于大型的仅有附录的表来说,一个可能的用例是设置一个特定的点来开始(恢复)快照,以防止之前的快照被打断。 注意:这个设置只对快照有影响。从binlog捕获的事件完全不受其影响。 |
|
| min.row.count.to.stream.results | 1000 | 在快照操作中,连接器将查询每个包含的表,为该表的所有行产生一个读取事件。这个参数决定了MySQL连接是否会将表的所有结果拉入内存,或者是否会将结果流化(可能会慢一些,但对于非常大的表来说是可行的)。该值指定了在连接器将结果流化之前,表必须包含的最小行数,默认为1000。将此参数设置为’0’,可以跳过所有的表大小检查,并在快照期间始终流式处理所有结果 |
| database.initial.statements | 建立到数据库的 JDBC 连接(不是事务日志读取连接)时要执行的 SQL 语句的分号分隔列表。使用双分号 (‘;;’) 将分号用作字符而不是分隔符。注意:连接器可以自行决定建立 JDBC 连接,因此这通常仅用于配置会话参数,而不用于执行 DML 语句 | |
| snapshot.delay.ms | 连接器在启动后,进行快照之前需要等待的时间间隔;当在集群中启动多个连接器时可以避免快照中断 | |
| snapshot.fetch.size | 指定在快照时应该从表中一次性读取的最大行数 | |
| snapshot.lock.timeout.ms | 10000 | 指定在快照时等待获取表锁的最长时间,如果在指定时间间隔内未获取到表锁的时候,则快照失败 |
| enable.time.adjuster | MySQL 允许用户将年份值插入为 2 位或 4 位。在两位数字的情况下,该值会自动映射到 1970 - 2069 范围。这通常由数据库完成。当 Debezium 进行转换时设置为 true(默认值)。 当转换完全委托给数据库时设置为 false |
|
| sanitize.field.names | true when connector configuration explicitly specifies the key.converter or value.converter parameters to use Avro, otherwise defaults to false. | 是否对字段名称进行清理以符合 Avro 命名要求 |
| skipped.operations | 跳过的 op操作的逗号分隔列表。操作包括:c 表示插入,u 表示更新,d 表示删除。默认情况下,不跳过任何操作 |
3.9、Probleam List
3.9.1、【数据处理】org.apache.flink.table.api.TableException: Sort on a non-time-attribute field is not supported.table.exec.non-temporal-sort.enabled
解决方案:FLINK-18401
enable table.exec.non-temporal-sort.enabled=true which is false by default.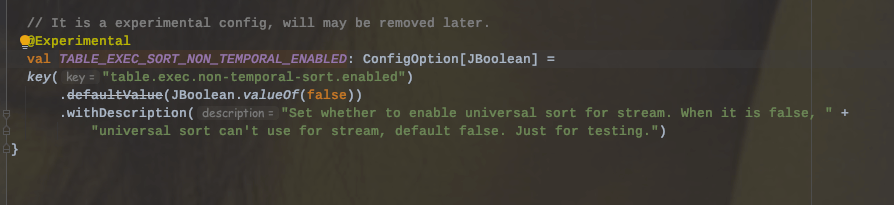
3.9.2、【数据读取】mysql-cdc 指定剔除不需要监听的字段信息时抛出异常
即指定“’debezium.column.blacklist”配置信息时抛出
org.apache.kafka.connect.errors.DataException: order_sales is not a valid field nameat org.apache.kafka.connect.data.Struct.lookupField(Struct.java:254)at org.apache.kafka.connect.data.Struct.get(Struct.java:74)at com.alibaba.ververica.cdc.debezium.table.RowDataDebeziumDeserializeSchema.lambda$createRowConverter$508c5858$1(RowDataDebeziumDeserializeSchema.java:364)at com.alibaba.ververica.cdc.debezium.table.RowDataDebeziumDeserializeSchema.lambda$wrapIntoNullableConverter$7b91dc26$1(RowDataDebeziumDeserializeSchema.java:390)at com.alibaba.ververica.cdc.debezium.table.RowDataDebeziumDeserializeSchema.extractAfterRow(RowDataDebeziumDeserializeSchema.java:126)at com.alibaba.ververica.cdc.debezium.table.RowDataDebeziumDeserializeSchema.deserialize(RowDataDebeziumDeserializeSchema.java:101)at com.alibaba.ververica.cdc.debezium.internal.DebeziumChangeConsumer.handleBatch(DebeziumChangeConsumer.java:97)at io.debezium.embedded.ConvertingEngineBuilder.lambda$notifying$2(ConvertingEngineBuilder.java:81)at io.debezium.embedded.EmbeddedEngine.run(EmbeddedEngine.java:812)at io.debezium.embedded.ConvertingEngineBuilder$2.run(ConvertingEngineBuilder.java:170)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)at java.lang.Thread.run(Thread.java:745)
分析:指定debezium.column.blacklist该参数的意思是指在debezium监听到事件后会把记录中的指定字段删除,然后flink在解析转换的时候找不到字段。
3.9.3、【数据写入】Flink Sql Sink To HBase
解决方案:创建hdfs目录
java.io.FileNotFoundException: File hdfs://cluster/data/hbase/lib does not exist.at org.apache.hadoop.hdfs.DistributedFileSystem.listStatusInternal(DistributedFileSystem.java:705) ~[hadoop-hdfs-2.6.0-cdh5.8.2.jar:?]at org.apache.hadoop.hdfs.DistributedFileSystem.access$600(DistributedFileSystem.java:106) ~[hadoop-hdfs-2.6.0-cdh5.8.2.jar:?]at org.apache.hadoop.hdfs.DistributedFileSystem$15.doCall(DistributedFileSystem.java:763) ~[hadoop-hdfs-2.6.0-cdh5.8.2.jar:?]at org.apache.hadoop.hdfs.DistributedFileSystem$15.doCall(DistributedFileSystem.java:759) ~[hadoop-hdfs-2.6.0-cdh5.8.2.jar:?]at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) ~[hadoop-common-2.6.0-cdh5.8.2.jar:?]at org.apache.hadoop.hdfs.DistributedFileSystem.listStatus(DistributedFileSystem.java:759) ~[hadoop-hdfs-2.6.0-cdh5.8.2.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.util.DynamicClassLoader.loadNewJars(DynamicClassLoader.java:206) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.util.DynamicClassLoader.tryRefreshClass(DynamicClassLoader.java:168) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.util.DynamicClassLoader.loadClass(DynamicClassLoader.java:140) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at java.lang.Class.forName0(Native Method) ~[?:1.8.0_121]at java.lang.Class.forName(Class.java:348) [?:1.8.0_121]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.protobuf.ProtobufUtil.toException(ProtobufUtil.java:1753) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.protobuf.ResponseConverter.getResults(ResponseConverter.java:157) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.MultiServerCallable.call(MultiServerCallable.java:180) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.MultiServerCallable.call(MultiServerCallable.java:53) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.RpcRetryingCaller.callWithoutRetries(RpcRetryingCaller.java:219) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl$SingleServerRequestRunnable.run(AsyncProcess.java:806) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.sendMultiAction(AsyncProcess.java:1102) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.groupAndSendMultiAction(AsyncProcess.java:1009) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.resubmit(AsyncProcess.java:1342) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.receiveGlobalFailure(AsyncProcess.java:1296) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.access$1500(AsyncProcess.java:667) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl$SingleServerRequestRunnable.run(AsyncProcess.java:814) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.sendMultiAction(AsyncProcess.java:1102) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.groupAndSendMultiAction(AsyncProcess.java:1009) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.resubmit(AsyncProcess.java:1342) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.receiveGlobalFailure(AsyncProcess.java:1296) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.access$1500(AsyncProcess.java:667) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl$SingleServerRequestRunnable.run(AsyncProcess.java:814) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.sendMultiAction(AsyncProcess.java:1102) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.groupAndSendMultiAction(AsyncProcess.java:1009) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.resubmit(AsyncProcess.java:1342) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.receiveGlobalFailure(AsyncProcess.java:1296) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.access$1500(AsyncProcess.java:667) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl$SingleServerRequestRunnable.run(AsyncProcess.java:814) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.sendMultiAction(AsyncProcess.java:1102) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.groupAndSendMultiAction(AsyncProcess.java:1009) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.resubmit(AsyncProcess.java:1342) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.receiveGlobalFailure(AsyncProcess.java:1296) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.access$1500(AsyncProcess.java:667) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl$SingleServerRequestRunnable.run(AsyncProcess.java:814) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.sendMultiAction(AsyncProcess.java:1102) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.groupAndSendMultiAction(AsyncProcess.java:1009) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.resubmit(AsyncProcess.java:1342) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.receiveGlobalFailure(AsyncProcess.java:1296) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.access$1500(AsyncProcess.java:667) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl$SingleServerRequestRunnable.run(AsyncProcess.java:814) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.sendMultiAction(AsyncProcess.java:1102) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.groupAndSendMultiAction(AsyncProcess.java:1009) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.resubmit(AsyncProcess.java:1342) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.receiveGlobalFailure(AsyncProcess.java:1296) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.access$1500(AsyncProcess.java:667) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl$SingleServerRequestRunnable.run(AsyncProcess.java:814) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.sendMultiAction(AsyncProcess.java:1102) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.groupAndSendMultiAction(AsyncProcess.java:1009) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.resubmit(AsyncProcess.java:1342) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.receiveGlobalFailure(AsyncProcess.java:1296) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.access$1500(AsyncProcess.java:667) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl$SingleServerRequestRunnable.run(AsyncProcess.java:814) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.sendMultiAction(AsyncProcess.java:1102) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.groupAndSendMultiAction(AsyncProcess.java:1009) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.resubmit(AsyncProcess.java:1342) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.receiveGlobalFailure(AsyncProcess.java:1296) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl.access$1500(AsyncProcess.java:667) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at org.apache.flink.hbase.shaded.org.apache.hadoop.hbase.client.AsyncProcess$AsyncRequestFutureImpl$SingleServerRequestRunnable.run(AsyncProcess.java:814) [flink-sql-connector-hbase-1.4-1.0-SNAPSHOT.jar:?]at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) [?:1.8.0_121]at java.util.concurrent.FutureTask.run(FutureTask.java:266) [?:1.8.0_121]at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) [?:1.8.0_121]at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) [?:1.8.0_121]at java.lang.Thread.run(Thread.java:745) [?:1.8.0_121]
3.9.4、【数据读取】CDC source 扫描 MySQL 表期间,进行加锁操作
debezium-mysql
解决方案:给使用的 MySQL 用户授予 RELOAD 权限即可。
使用’debezium.snapshot.locking.mode’ = ‘none’参数
3.9.5、【数据读取】com.mysql.cj.exceptions.UnableToConnectException: CLIENT_PLUGIN_AUTH is required
解决方案:提供的ip地址是否为物理地址,或者mysql driver版本过高
3.9.6、【数据处理】Java Heap Out Of Memory
# 修改flink-conf.yaml 增加Heap Sizetaskmanager.memory.process.size: 10240mtaskmanager.memory.jvm-metaspace.size: 512mtaskmanager.memory.network.min: 512mbtaskmanager.memory.network.max: 2gbtaskmanager.memory.task.heap.size: 2gbtaskmanager.memory.task.off-heap.size: 1gb
3.9.7、【元数据】进入 SQL Client 创建 table 后,在另外一个节点进入 SQL Client 查询不到 table
解决方案:因为 SQL Client 默认的 Catalog 是在 in-memory 的,不是持久化 Catalog,所以这属于正常现象,每次启动 Catalog 里面都是空的。后续可以使用Hive Catalog,共用元数据
3.9.8、【数据读取】Flink 作业在扫描 MySQL 全量数据时,checkpoint 超时,出现作业 failover
Flink CDC 在 scan 全表数据需要小时级的时间(受下游聚合反压影响),而在 scan 全表过程中是没有 offset 可以记录的(意味着没法做 checkpoint),但是 Flink 框架任何时候都会按照固定间隔时间做 checkpoint,
所以此处 mysql-cdc source 做了比较取巧的方式,即在 scan 全表的过程中,会让执行中的 checkpoint 一直等待甚至超时。超时的 checkpoint 会被仍未认为是 failed checkpoint,默认配置下,这会触发 Flink 的 failover 机制,而默认的 failover 机制是不重启。
所以会造成上面的现象。
解决方案:
# 在 flink-conf.yaml 配置 failed checkpoint 容忍次数,以及失败重启策略execution.checkpointing.interval: 10min # checkpoint间隔时间execution.checkpointing.tolerable-failed-checkpoints: 100 # checkpoint 失败容忍次数restart-strategy: fixed-delay # 重试策略restart-strategy.fixed-delay.attempts: 2147483647 # 重试次数
目前 Flink 社区也有一个 issue(https://issues.apache.org/jira/browse/FLINK-18578)来支持 source 主动拒绝 checkpoint 的机制,将来基于该机制,能比较优雅地解决这个问题
3.9.10、【依赖包】[ERROR] Could not execute SQL statement. Reason: org.apache.calcite.runtime.CalciteException: Non-query expression encountered in illegal context
解决方案:checkpoint存储到hdfs文件系统时,缺少hadoop依赖 包,将https://flink.apache.org/downloads.html对应的jar包放到FLINK_HOME/lib目录下重启即可
3.9.11、【组件通信】Task ‘Source: Custom Source -> Map -> Map -> to: Row -> Map -> Sink: Unnamed (1/3)’ did not react to cancelling signal for 30 seconds Task did not exit gracefully within 180 + seconds
有两种可能:
1.是程序30秒内没有做出反应导致taskmanager挂掉,查看是否资源不足
解决方案:在flink-conf.yaml中配置task.cancellation.timeout: 0
2.是任务被阻塞在某个方法里
解决方案:看日志找到被阻塞的方法进行解决
3.9.12、【数据写入】sink to es 并发时会出现reason=[_doc][pay-gops]: version conflict, current version [46] is different than the one provided [45]]版本冲突问题
解决方案:
技术层面:
1.配置’failure-handler’ = ‘org.apache.flink.streaming.connectors.elasticsearch.util.RetryRejectedExecutionFailureHandler’(未生效)
2.如果使用Stream API的话有提供retryOnConflict,但是SQL目前没有对应的参数
3.降低并行度,ES层将translog调整为异步方式,refresh interval降低
业务层面:保证主键的唯一性
3.9.13、【数据读取】Encountered change event for table xxx.xxxx whose schema isn’t known to this connector
解决方案:inconsistent.schema.handling.mode = ‘warn’
3.9.14、【组件通信】Flink Job运行一段时间后,会重新启动TM,抛出异常java.util.concurrent.TimeoutException: Heartbeat of TaskManager with id container_1607443808899_21627_01_000004(wecloud-test-137:57276) timed out.
解决方案:设置调大以下两个参数
heartbeat.interval:心跳检测间隔(默认10s)
heartbeat.timeout:心跳超时(50s)
3.9.15、【数据写入】Sink To Hdfs
1、需引入hadoop jar
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.6.0-cdh5.8.0</version></dependency>
2、设置HADOOP_HOME变量
3 、由于hadoop version<2.7 使用OnCheckpointRollingPolicy滚动策略,该策略会在每次checkpoint的时候进行文件滚动。这样做的原因是如果部分文件的生命周期跨多个检查点,当 FileSink 从之前的检查点进行恢复时会调用文件系统的 truncate() 方法清理 in-progress 文件中未提交的数据。 Hadoop 2.7 之前的版本不支持这个方法,因此 Flink 会报异常。同时可以重构自定义基于文件大小和时间来滚动
4、 Flink 的 sink 以及 UDF 通常不会区分作业的正常结束(比如有限流)和异常终止,因此正常结束作业的最后一批 in-progress 文件不会被转换到 “完成” 状态 (经测试,Hive可以读取in-progress文件,但会存在小文件问题;这里需要平衡cp时间和小文件)
3.9.16、【数据写入】CDC Sink Mysql Cause binlog disk full
注意:当使用cdc sink to mysql的时候,需要注意binlog占用磁盘容量的问题。
3.9.17、【时区】Flink CDC mysql Timestamp时差问题
source:CREATE TABLE student (id INT,name STRING,create_time TIMESTAMP(0),update_time TIMESTAMP(0),time_ds STRING,ret INT) WITH ('connector' = 'mysql-cdc','hostname' = '127.0.0.1','port' = '3306','username' = 'dev','password' = '**','database-name' = 'wms','table-name' = 'student','source-offset-file' = 'mysql-bin.000007','source-offset-pos' = '1574112','server-time-zone' = 'Asia/Shanghai');sink:CREATE TABLE student_02 (id INT,name STRING,create_time TIMESTAMP(0),PRIMARY KEY (id) NOT ENFORCED) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://127.0.0.1:3306/wms','table-name' = 'student_02','username' = 'dev','password' = '***');
source 中有调节时区的参数。所以读取到的是正确的。但是sink 中没有调节时区的参数。时间就有了时差
解决方案:
sink表的 url后面加上 &serverTimezone=Asia/Shanghai
3.9.18、【数据处理】TopN场景出现Can not retract a non-existent record. This should never happen
java.lang.RuntimeException: Can not retract a non-existent record. This should never happen.at org.apache.flink.table.runtime.operators.rank.RetractableTopNFunction.processElement(RetractableTopNFunction.java:189)at org.apache.flink.table.runtime.operators.rank.RetractableTopNFunction.processElement(RetractableTopNFunction.java:53)at org.apache.flink.streaming.api.operators.KeyedProcessOperator.processElement(KeyedProcessOperator.java:85)at org.apache.flink.streaming.runtime.tasks.OneInputStreamTask$StreamTaskNetworkOutput.emitRecord(OneInputStreamTask.java:193)at org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.processElement(StreamTaskNetworkInput.java:179)at org.apache.flink.streaming.runtime.io.StreamTaskNetworkInput.emitNext(StreamTaskNetworkInput.java:152)at org.apache.flink.streaming.runtime.io.StreamOneInputProcessor.processInput(StreamOneInputProcessor.java:67)at org.apache.flink.streaming.runtime.tasks.StreamTask.processInput(StreamTask.java:372)at org.apache.flink.streaming.runtime.tasks.mailbox.MailboxProcessor.runMailboxLoop(MailboxProcessor.java:186)at org.apache.flink.streaming.runtime.tasks.StreamTask.runMailboxLoop(StreamTask.java:575)at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:539)at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:722)at org.apache.flink.runtime.taskmanager.Task.run(Task.java:547)at java.lang.Thread.run(Thread.java:745)
解决方案:
- 设置参数table.exec.source.cdc-events-duplicate=true,且在配置cdc source时需要指定主键
- Row_number排序中的时间字段最好使用系统时间ProcessTime或者事件时间
3.9.19、【组件通信】CDC模式TM和JM心跳超时
java.util.concurrent.TimeoutException: The heartbeat of TaskManager with id container_1606994889512_969844_01_000002(xy180-wecloud-86:5071) timed out.at org.apache.flink.runtime.resourcemanager.ResourceManager$TaskManagerHeartbeatListener.notifyHeartbeatTimeout(ResourceManager.java:1264)at org.apache.flink.runtime.heartbeat.HeartbeatMonitorImpl.run(HeartbeatMonitorImpl.java:109)at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)at java.util.concurrent.FutureTask.run(FutureTask.java:266)at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:404)at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:197)at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74)at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:154)at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:26)at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:21)at scala.PartialFunction$class.applyOrElse(PartialFunction.scala:123)at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:21)at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:170)at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)at akka.actor.Actor$class.aroundReceive(Actor.scala:517)at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:225)at akka.actor.ActorCell.receiveMessage(ActorCell.scala:592)at akka.actor.ActorCell.invoke(ActorCell.scala:561)at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:258)at akka.dispatch.Mailbox.run(Mailbox.scala:225)at akka.dispatch.Mailbox.exec(Mailbox.scala:235)at akka.dispatch.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)at akka.dispatch.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)at akka.dispatch.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)at akka.dispatch.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
解决方案:
- 可能是资源不足
- 需要定位是否代码问题导致的超时
3.9.20、【组件通信】Message of type [org.apache.flink.runtime.rpc.messages.RemoteRpcInvocation]. A typical reason for AskTimeoutException is that the recipient actor didn’t send a reply.
x Caused by: java.util.concurrent.TimeoutException: Invocation of public abstract java.util.concurrent.CompletableFuture org.apache.flink.runtime.taskexecutor.TaskExecutorGateway.submitTask(org.apache.flink.runtime.deployment.TaskDeploymentDescriptor,org.apache.flink.runtime.jobmaster.JobMasterId,org.apache.flink.api.common.time.Time) timed out. at org.apache.flink.runtime.jobmaster.RpcTaskManagerGateway.submitTask(RpcTaskManagerGateway.java:72) at org.apache.flink.runtime.executiongraph.Execution.lambda$deploy$10(Execution.java:756) at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1590) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) ... 1 more
原因:由于JM分配task到TM时roc超时
解决方案:akka.ask.timeout=120s web.timeout=120000
3.9.21、【类型转换】Flink 使用JDBC查询维度表时字段类型会抛出java.lang.ClassCastException: java.math.BigInteger cannot be cast to java.lang.Long
原因:mysql jdbc connector版本的问题,需要改动源码pom文件并做测试
暂时解决方案:lookup mode改成cdc模式
3.9.22、【类型转换】Flink sql 使用Case when 语句抛出Unable to find common type of GeneratedExpression(field$24,isNull$23,,STRING,None) and ArrayBuffer(GeneratedExpression(((int) 1),false,,INT NOT NULL,Some(1))).
该问题在也有其他用户在Flink邮件中提到过,见https://www.mail-archive.com/user@flink.apache.org/msg42494.html
--原sqlcount(distinct case when server_level=3 and node_type=0 and order_status=1 and pay_status in (1,2) and treat_status in (0,1) then order_id end)--更改后的sqlcount(distinct case when server_level=3 and node_type=0 and order_status=1 and cast(pay_status as string) in ('1','2') and cast(treat_status as string) in ('0','1') then order_id end)
解决方案:主要原因在于calcite在编译表达式生成code时,左右两边的类型不一致导致异常抛出,只需更改字段类型即可
3.9.23、【类型转换】时间戳字段写入HBase时抛出The precision 6 of TIMESTAMP type is out of the range [0, 3] supported by HBase connector
解决方案:类型转换即可
3.9.24、【数据写入】Flink Sink To HBase抛出Unable to load exception received from server:org.apache.hadoop.hbase.CallQueueTooBigException: 17 times, servers with issues
原因:写入过快,超出了rs配置的hbase.ipc.server.max.callqueue.length参数
解决方案:调小并行度,或者调大hbase.ipc.server.max.callqueue.length参数
3.9.25、【数据读取】Flink CDC读取mysql大表的时候抛出以下异常
Streaming result set com.mysql.cj.protocol.a.result.ResultsetRowsStreaming@3bb05d2f is still active.No statements may be issued when any streaming result sets are open and in use on a given connection. Ensure that you have called .close() on any active streaming result sets before attempting more queries.org.apache.kafka.connect.errors.ConnectException: Streaming result set com.mysql.cj.protocol.a.result.ResultsetRowsStreaming@3bb05d2f is still active.No statements may be issued when any streaming result sets are open and in use on a given connection.Ensure that you have called .close() on any active streaming result sets before attempting more queries.Error code: 0; SQLSTATE: S1000.
目前已经提Issus-57,暂时还未得到解决。在mail中也有提及到该问题https://www.mail-archive.com/search?l=user-zh@flink.apache.org&q=subject:%22Flink+cdc+connector%EF%BC%9A%E6%95%B0%E6%8D%AE%E9%87%8F%E8%BE%83%E5%A4%A7%E6%97%B6%EF%BC%8Csnapshot%E9%98%B6%E6%AE%B5%E6%8A%A5%E9%94%99%22&o=newest&f=1
3.9.26、【类型转换】Flink Sql Lookup Join With Primary key type is bigint UnSigned Casuse java.math.BigInteger cannot be cast to java.lang.Long
Issues-330已经解决
3.9.27、【数据一致性】Flink Sql From Mysql-cdc Sink To HBase Cause Miss Data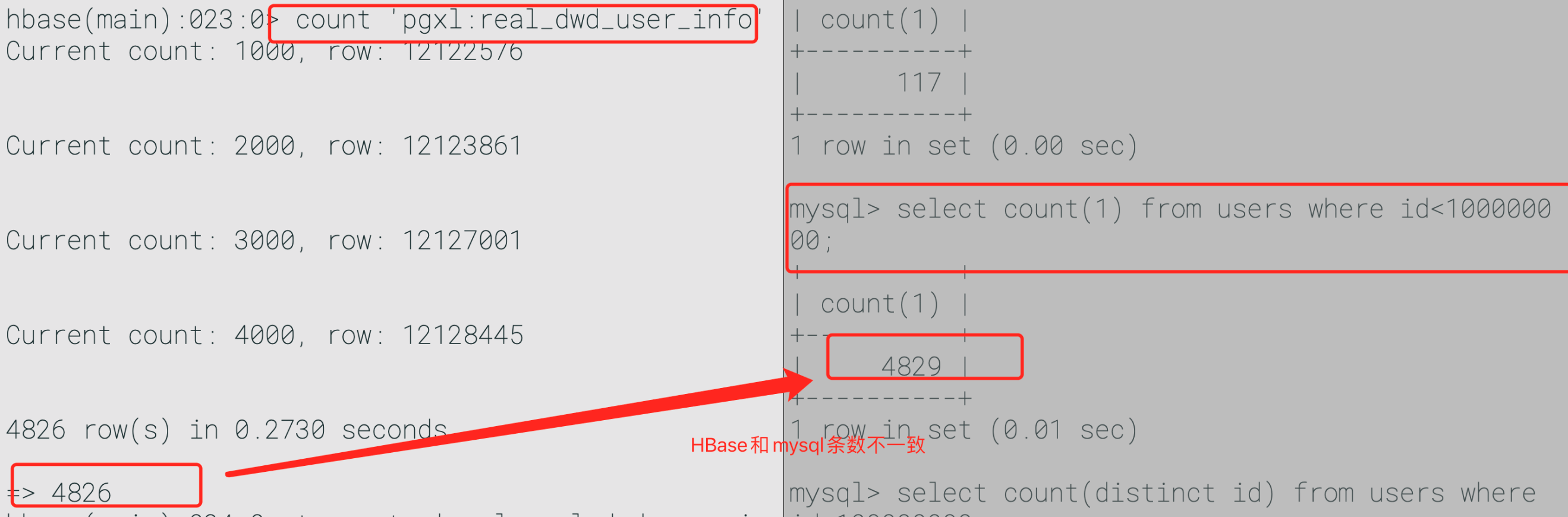
定位:
1、改写源码,增加Log。
2、查看写入逻辑:
#open逻辑,有个定时任务刷新if (bufferFlushIntervalMillis > 0 && bufferFlushMaxMutations != 1) {this.executor = Executors.newScheduledThreadPool(1, new ExecutorThreadFactory("hbase-upsert-sink-flusher"));this.scheduledFuture = this.executor.scheduleWithFixedDelay(() -> {if (closed) {return;}try {flush();} catch (Exception e) {// fail the sink and skip the rest of the items// if the failure handler decides to throw an exceptionfailureThrowable.compareAndSet(null, e);}}, bufferFlushIntervalMillis, bufferFlushIntervalMillis, TimeUnit.MILLISECONDS);}# invoke逻辑if (bufferFlushMaxMutations > 0 && numPendingRequests.incrementAndGet() >= bufferFlushMaxMutations) {flush();}# snapshot逻辑,当队列中还有数据请求未刷新时才满足while (numPendingRequests.get() != 0) {flush();}
以Rowkey=0为例发现操作已经被封装到Mutation中,且已经被刷新了,但在HBase中并未找到该key。猜测可能在mutator处理数据乱序了。
搜索资料查证:
1、https://www.jianshu.com/p/1a753ffcbe2a
2、https://issues.apache.org/jira/browse/HBASE-8626?focusedCommentId=13669455&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel#comment-13669455
解决方案:
1、短期方案:设置’sink.buffer-flush.max-rows’ = ‘2’暂时规避该问题,但对rs会有比较大的压力
2、彻底解决:基于issue改造源码
3.9.28、【事件驱动型】-实时计算等待时长耗时场景
例如要计算用户从下单到接单的过程中实时耗时,比如下单之后提示等待1秒、2秒、3秒。。。,那么这个等待时间需要一直实时累加,直至被处理为止。
对于这种场景实现,结合Flink基于事件驱动的特性,这里采用循环队列缓冲的思想来实现:
这里需要注意两点:
1、队列的大小资源控制,需要结合TTL
2、结果队列输出和其他数据队列对齐时的资源控制,否则会影响其他队列的阻塞,可按照实际场景实现定时器的功能
3.9.29、【事件驱动型】-当日指标值统计重置默认值处理场景
例如:运营想要分析每个渠道的每天流量情况(即pv,uv),假设这个时候新接入一个渠道A,而且这个渠道A并没有什么流量。甚至可能当天都不会有流量进入的情况,但对于运营来说,该渠道A也需要进行展示,即便为0的情况下。
对于FLink基于事件驱动的特性来说,如果渠道A没有流量进入,那么就不会计算该渠道,那么当天的数据就会缺失渠道A,直至有流量进入才会计算。那么这个时候就需要人为触发计算。
设计思路:
将维度数据通过离线的方式同步到数仓中,然后凌晨更新一次数据库,这样就会通过CDC触发一次计算。
3.9.30、【数据处理】Caused by: org.codehaus.janino.InternalCompilerException: Code of method \”split$3064$(LStreamExecCalc$3090;)V\” of class \”StreamExecCalc$3090\” grows beyond 64 KB
该问题主要由于SQL处理逻辑过于复杂,超出JVM对某个方法的字节编码长度限制64KB,这个时候可以用UDF处理。或者优化处理逻辑

若有收获,就点个赞吧
0 人点赞
