一、元数据概述
1.1、定义
元数据定义:描述数据的数据,对数据及信息资源的描述性信息。小编认为元数据不仅仅是关于数据的数据,它还是一种上下文,赋予信息更加丰富的身份。
以图片为例,其图片本身是一种数据,那么图片的名称、属性、尺寸、使用什么设备生成的、生成的时间、责任人等等这些信息其实都属于元数据。
1.2、类型
1.2.1、业务元数据
描述数据系统中业务领域相关概念、关系和规则的数据,包括业务术语、信息分类、指标、统计口径等。
例如:针对机场基础信息数据,其标识信息、数据质量与精度信息、空间参照信息、发布与更新信息、负责单位与联系信息等均构成描述该机场基本数据(如机场代码、坐标等)的业务元数据。
业务元数据也可以大致分为逻辑元数据和物理元数据。
1.2.1.1、逻辑元数据
有关逻辑结构(例如表)的业务元数据被视为逻辑元数据;我们使用元数据进行数据分类和标准化我们的 ETL 处理。表所有者可以在业务元数据中提供有关表的审计信息。它们还可以提供用于写入表的列默认值和验证规则。
1.2.1.2、物理元数据
有关存储在表或分区中的实际数据的元数据被视为物理元数据。
我们的 ETL 处理在作业完成时存储有关数据的指标,稍后用于验证。相同的指标可用于分析数据的成本 + 空间。鉴于两个表可以指向相同的位置(如在 Hive 中),区分逻辑元数据和物理元数据很重要,因为两个表可以具有相同的物理元数据但具有不同的逻辑元数据
1.2.2、技术元数据
描述数据系统中技术领域相关概念、关系和规则的数据,包括物理模型的表与字段、ETL规则、集成关系等。
例如:针对图像数据,其基本数字对象(对象标识符、文件大小、字节序列、压缩类别等)、基本图像信息、图像捕捉元数据、图像评估元数据(空间度量、图像色彩编码等)等构成描述该数据的技术元数据。
1.2.3、操作元数据
操作元数据:描述数据处理日志及运营情况的数据,包括系统执行日志、访问记录等。
1.3、目的及意义
小编认为通过元数据可以帮助企业更好的维护管理数据,沉淀数据资产,且在整个数据生态系统起到承上启下的作用,对于用户来说可以快速、准确获取到完整的上下文数据信息,并完全理解信任数据,对于团队来说可以提升协作效率,减少重复工作,对于企业来说可以充分挖掘数据价值,做出正确的执行决策。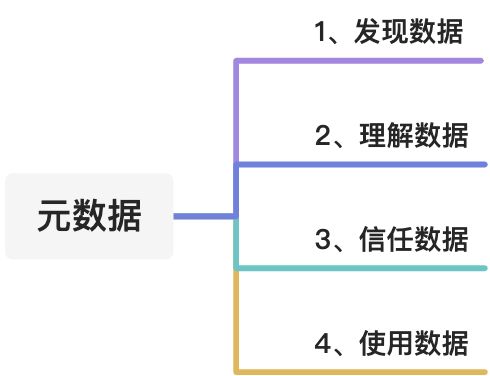
1.4、元数据管理
在对元数据进行管理时需要制定元数据标准、管理规范、管理平台与管控机制,
通过全流程的元数据管理(元数据的生产、采集、注册、维护),实现元数据应用。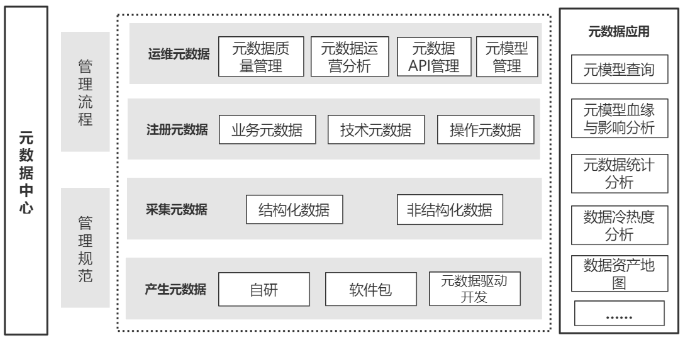
二、元数据管理解决方案
大多数企业中通常会出现一种情况:用户经常不得不问其他人在哪里可以找到合适的数据,因为很难在数据环境中导航。此外,元数据和上下文的缺乏使得难以信任数据。这种缺乏信任使员工无法使用其知识领域之外的资源,他们害怕不小心使用过时或不正确的信息。因此为了解决这类问题,元数据管理至关重要。关于元数据管理解决方案大致分为四类:
1、早期传统解决方案
2、Saas/内部解决方案
3、开源解决方案
4、Lake Discovery
1、早期传统解决方案
2.1、Metaphor
地址:https://metaphor.io/Metaphor的宗旨是”Numerous sources.One truth.”,从字面翻译上理解为众多来源,一个真理。而且提供了多种产品:
1、Data Catalog:数据目录
其实是一种元数据管理工具,公司用来在其系统内清点和组织数据。典型的好处包括改进数据发现、治理和访问;
2、Data Context:获取完整的数据信息
通过授权整个组织的专家根据业务背景丰富数据,使数据具有可操作性。包括示例查询、关键指标的定义、标记数据事件等等。集成到用户的自然工作流程中,使目录永远不会过时。
3、Data Discovery:快速得到想要的数据
通过建立对数据的信任的直观、上下文丰富的发现体验,缩短获取数据的时间。对于每项数据资产,查看依赖它的人、他们使用的查询、指标如何定义以及是否存在任何问题——所有这些都通过用户的自然表现而浮出水面
4、Data Insights:数据洞察
通过深入了解数据的利用方式,优化您的数据团队花费时间和金钱的方式。将投资从未充分利用的数据集、仪表板和工作转移到更高价值的数据资产
2.2、Stemma
地址:https://www.stemma.ai/
功能:一站式元数据管理解决方案
2.2.1、可以通过简单/高级搜索来查看具体的表或者看板等等
2.2.2、可以根据比较常见的数据标签快速查看
2.2.3、系统会推荐比较常用的数据,也就是我们经常看到的热度分析
2.2.4、通过我们搜索得到的结果查看具体的信息
有该表或者数据集的描述信息、责任人、最近更新时间、所属标签、数据范围、最近查询人员、问题反馈交流、关于该目标数据最近的一系列行为以及可以查看上下游血缘等等。
2.2.5、查看搜索目标数据任务上下游血缘信息
2.2.6、同样可以看到该数据集所涉及到的列、看板(可以看到该看板的具体信息以及协作者相关的信息)
2.3、Acryl
地址:https://www.acryl.io/
Acryl Data是一个元数据管理服务提供商,将LinkedIn的元数据工具DataHub进行了商业化。
愿景:通过下一代多云元数据管理平台为您的数据带来更好的清晰度
特点:数据发现,数据质量和联邦治理的一站式数据协作平台,可实现跨数据集,流,模型,仪表板体验整个数据生态系统,从而让数据更加清晰。
1、轻松集成并搜索整个多云数据生态系统,可以快速揭示隐藏的洞察力并建立数据产品
2、基于自动立即触发策略来确保高质量数据
3、基于API-First可扩展的元数据平台,可以实现对分析的安全性,且可复用。
2.4、Select Star
地址:https://selectstar.com/
愿景:Data discovery made easy。
特点:
1、组织并管理您的数据:通过标记和向数据添加文档,以便每个人都可以找到其正确数据集
2、及时监听列变化:Star会自动检测并显示列级别数据血缘,并且可以信任它来自哪里
3、捕获数据的使用:即无需寻找负责人,就能知道数据的用途、是否属于热度数据
4、维护数据安全和治理:Star会把数据基于AICPA SOC 2安全、机密性和可用性进行标准化处理,确保数据安全
2.5、Secoda
地址:https://www.secoda.co/
愿景:快速查找、定位、修复数据,提高协作效率。
定位:Secoda是一个用于管理和搜索所有数据知识的单一个工具,可以和用户使用的其他工具进行配合。
功能:
1、Data Catalog:数据目录
2、Data Analysis:数据分析
3、Data Dictionary:数据字典
4、Data Requests:数据请求使用
特点:
1、通过一个按钮就可以把所有的数据源进行集成,并且可以秒级访问搜索。
2、自动管理并记录元数据,包括表、字段、指标等等。
3、知识库的沉淀,Secoda会记录用户创建的查询、看板以及其他操作。
4、协作分享,可以将查询、分析、元数据和指标等数据资源根据权限控制进行分享协作。
5、代替在JIRA,Slack和Google表单之间跳跃,团队可以使用Secoda管理整个数据请求过程。避免重复回答同样的问题
2、Saas/内部解决方案
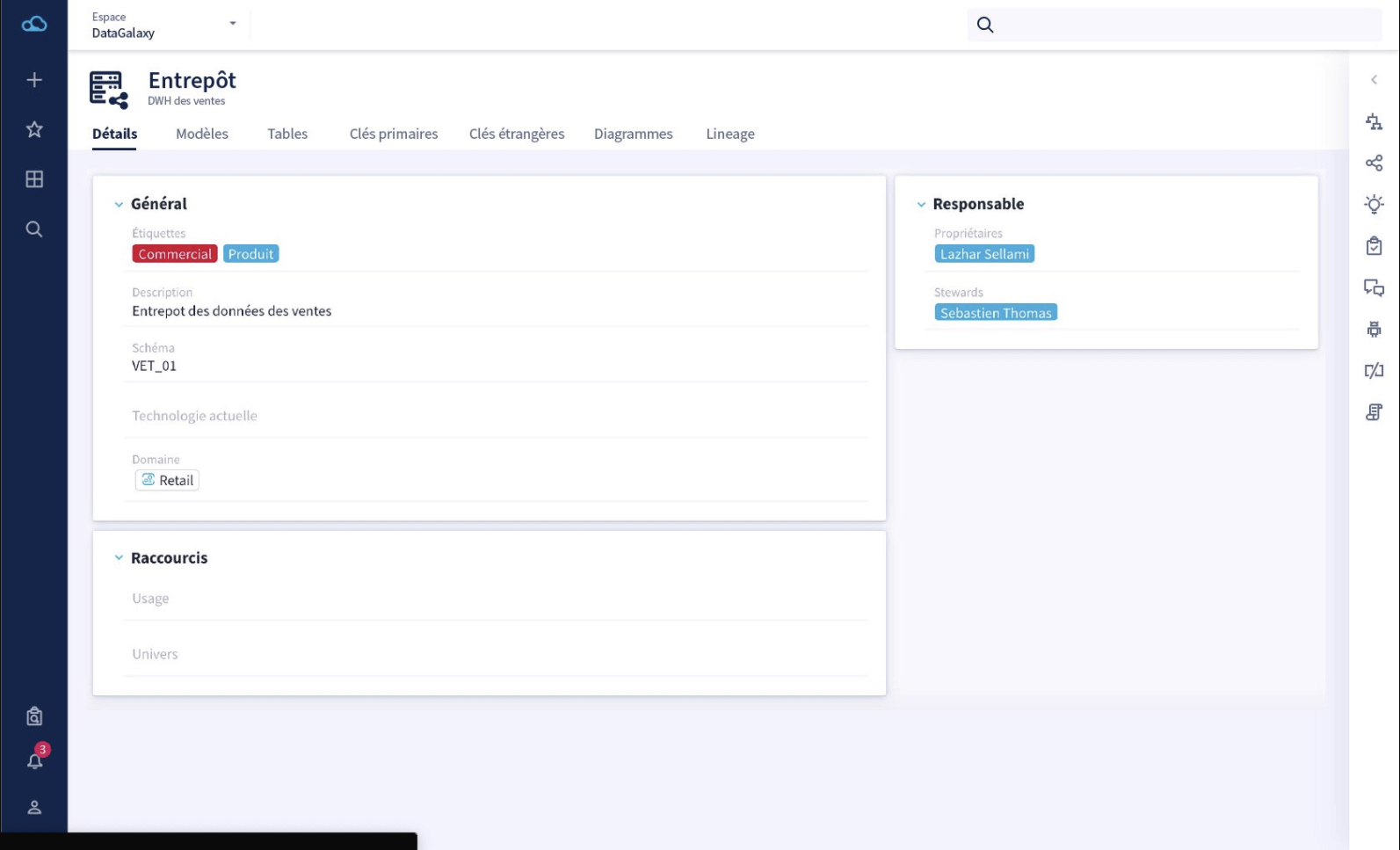
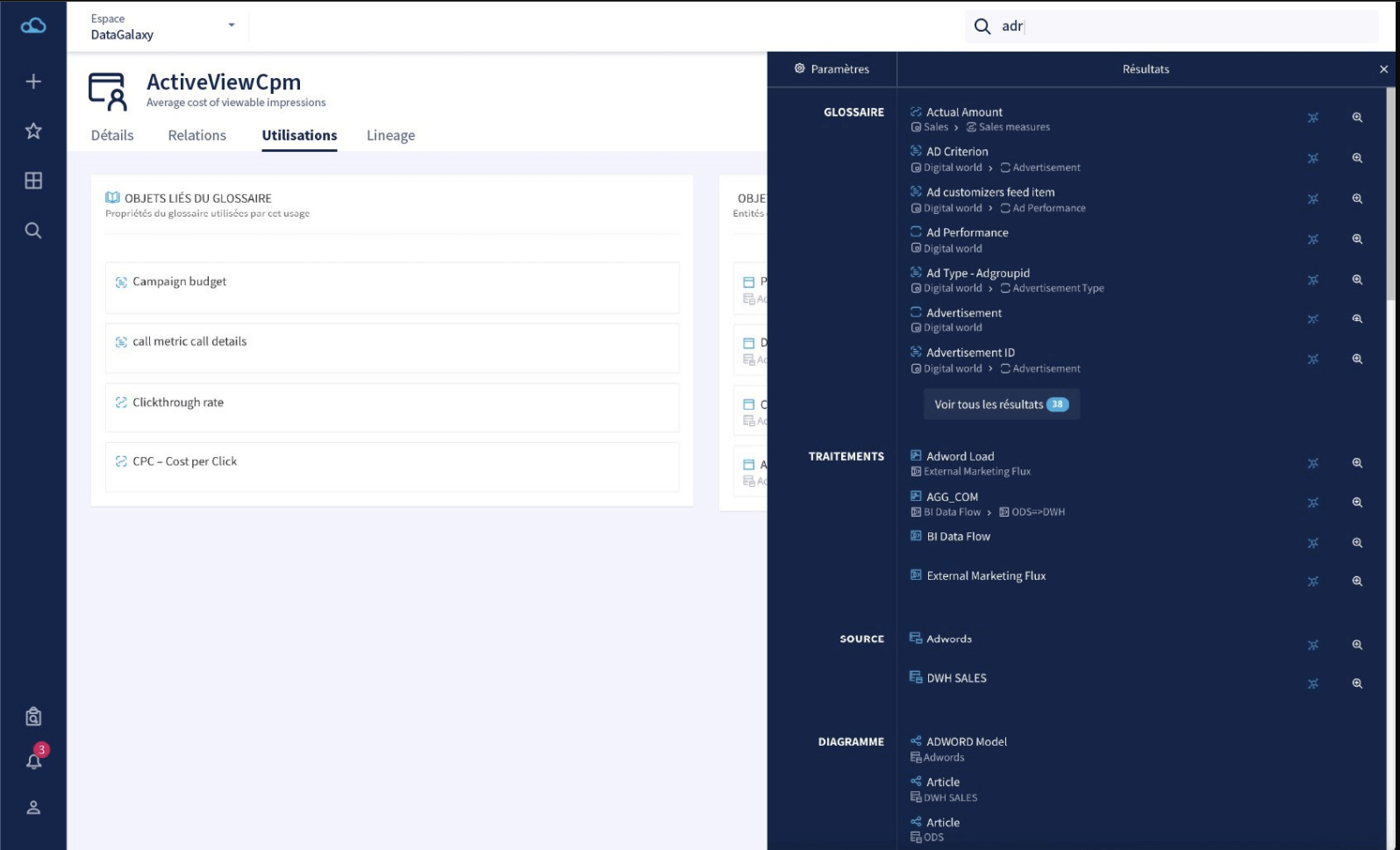
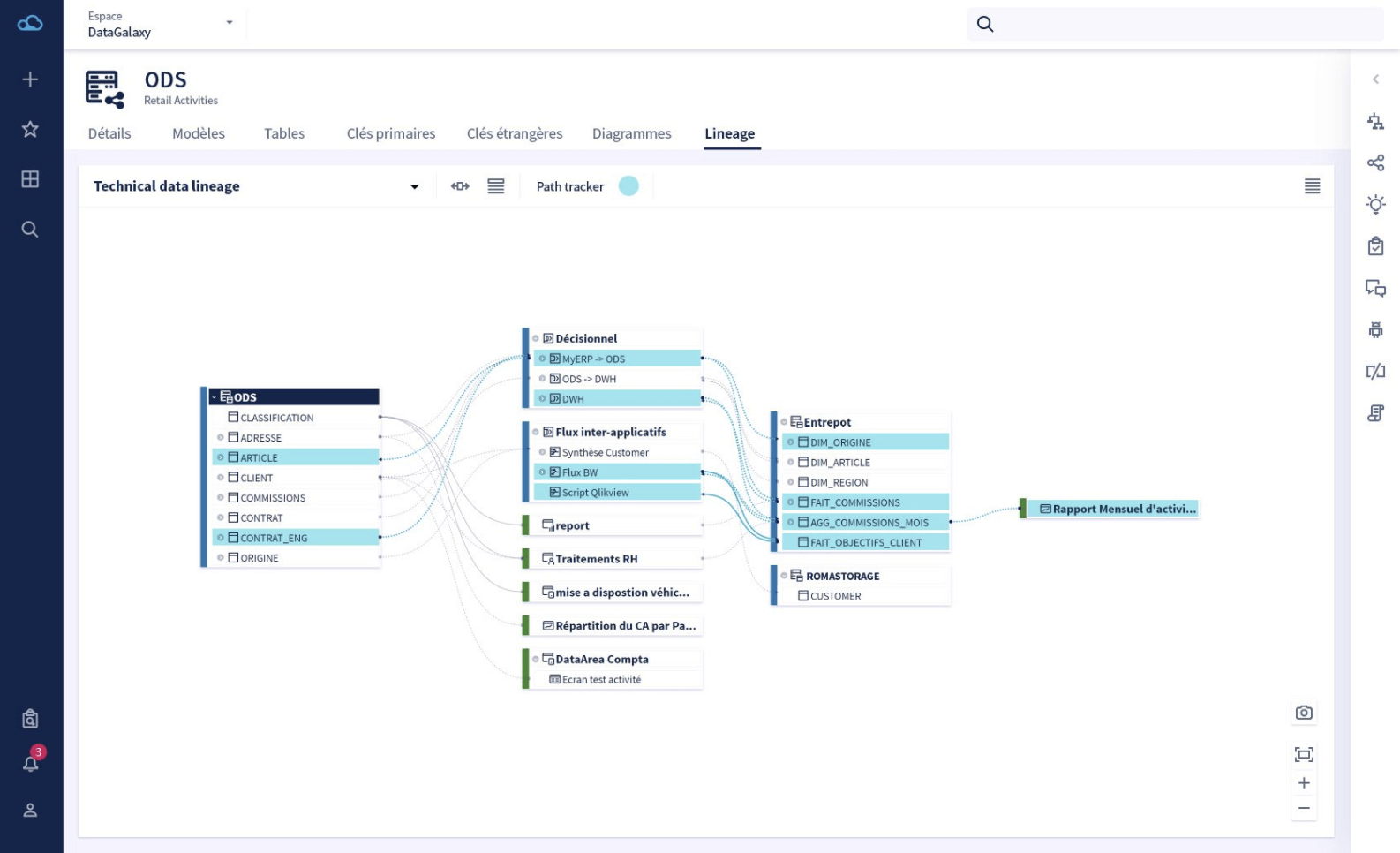
2.1、Data Galaxy
地址:https://www.datagalaxy.com/en-gb/home/
特点:实现数据治理最佳方式
1、理解业务数据并可以共享通用定义;即由团队成员共同维护定义业务术语词汇的知识库
2、统一企业数据字典:即快速定位感兴趣的数据及其附带的所有属性,并可以根据自定义的属性按照特定的需求调整数据目录
3、数据血缘,跟踪数据路径:所有者可以从杂乱复杂的信息系统中快速定位和跟踪路径或者分析数据或者使用变化影响的血缘可视化,实现数据可追溯性和可审计性,对于控制技术风险以及业务和合规风险至关重要。
2.2、Castordoc
地址:https://www.castordoc.com/
特点:发现、理解并使用数据资产
1、发现:快速直观的搜索,可浏览数以千计的表格、列、仪表板或 KPI。
2、理解:帮助用户理解数据。 Castor 会自动显示流行度、使用统计数据和血统。
3、审计:可记录到团队成员编写的SQL查询
4、文档:使用 Castor 的 Magic Paste 功能共享文档。使用管理面板优先处理和管理文档
5、管理:为治理目的分配所有者、标记个人信息并映射所有数据资产。
6、协作:在任何地方发表评论提及同事时会发送通知

2.3、Zeenea
地址:https://zeenea.com/
特点:
1、摆脱不必要的束缚:Zeenea 是一个 100% 基于云的解决方案,只需点击几下即可在世界任何地方使用。通过选择 Zeenea Data Catalog,控制实施和维护数据目录的成本,同时简化团队的信息访问。
2、轻松连接数据源:提供通用连接和 API 优先方法使 Zeenea 能够适应任何系统和任何数据策略(边缘、云、多云、跨云、混合),以构建企业范围的信息存储库。
3、借助自动化功能和连接器,可以在几分钟内使用包含来自每天使用的数据源和工具的信息的数据目录
4、从数据中立即创建价值:自动供给机制和提供的建议/校正算法降低目录的总体成本,并在短时间内为团队提供高质量的信息
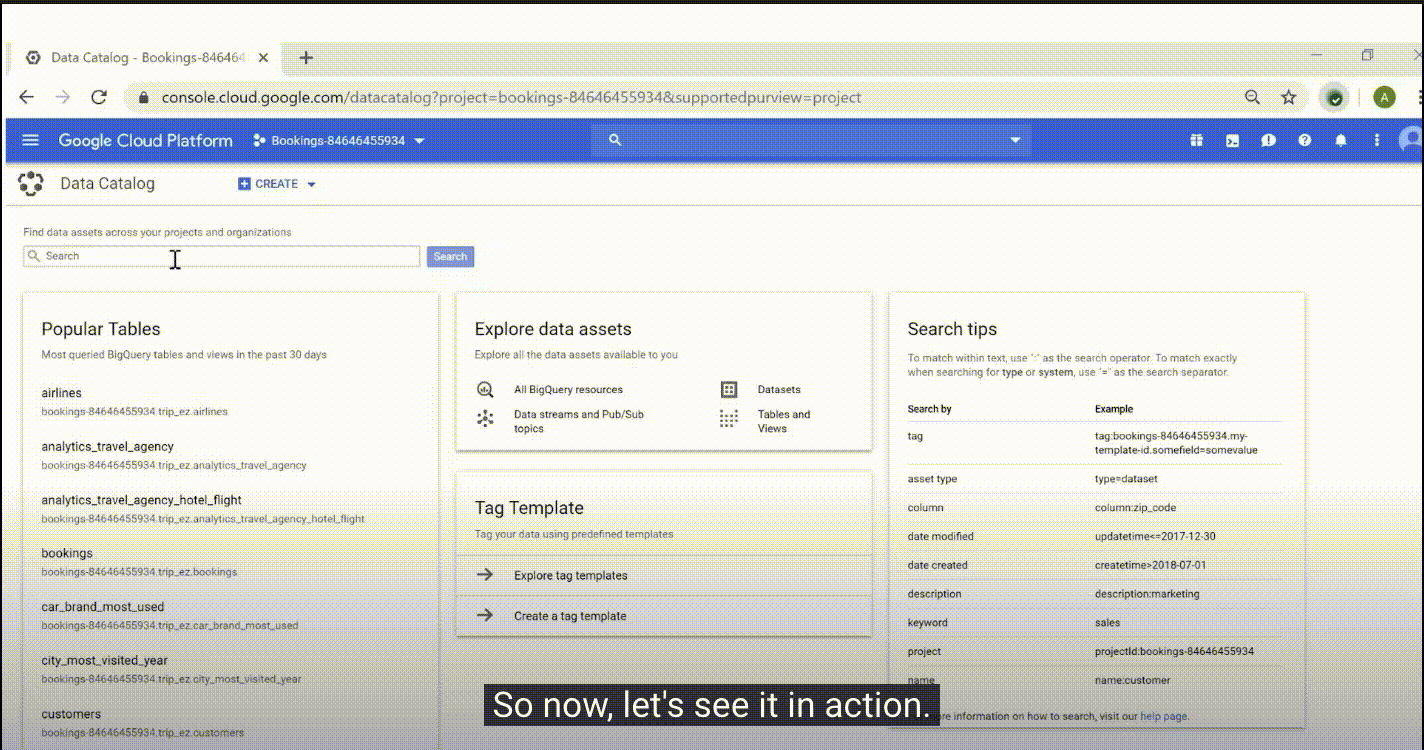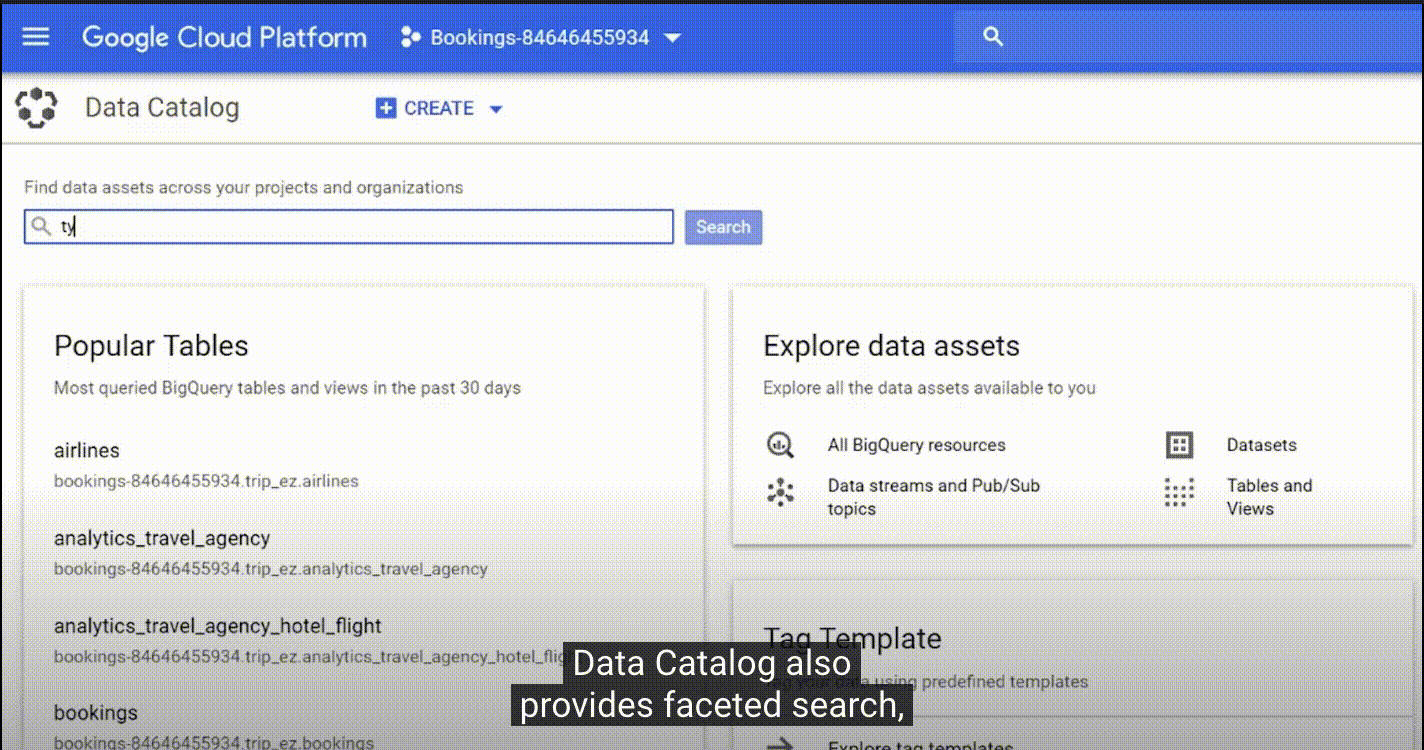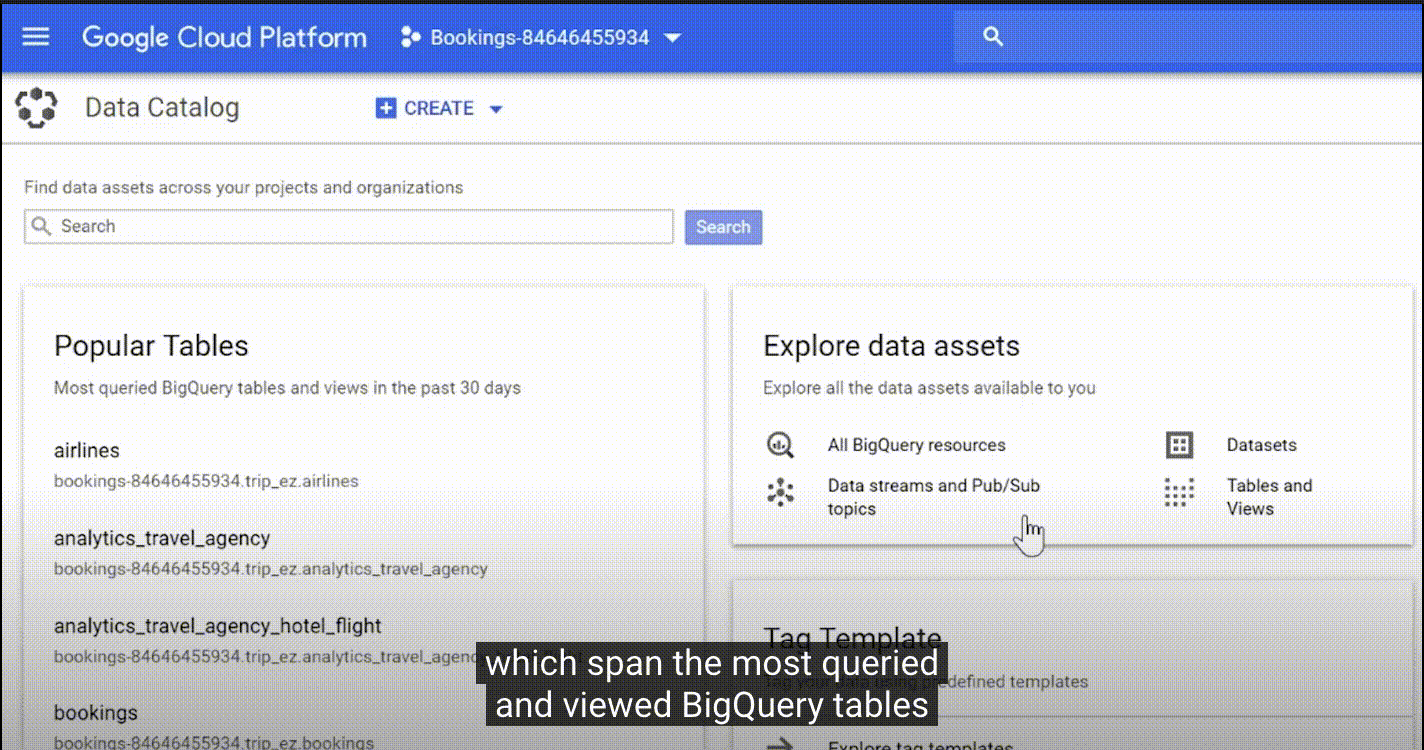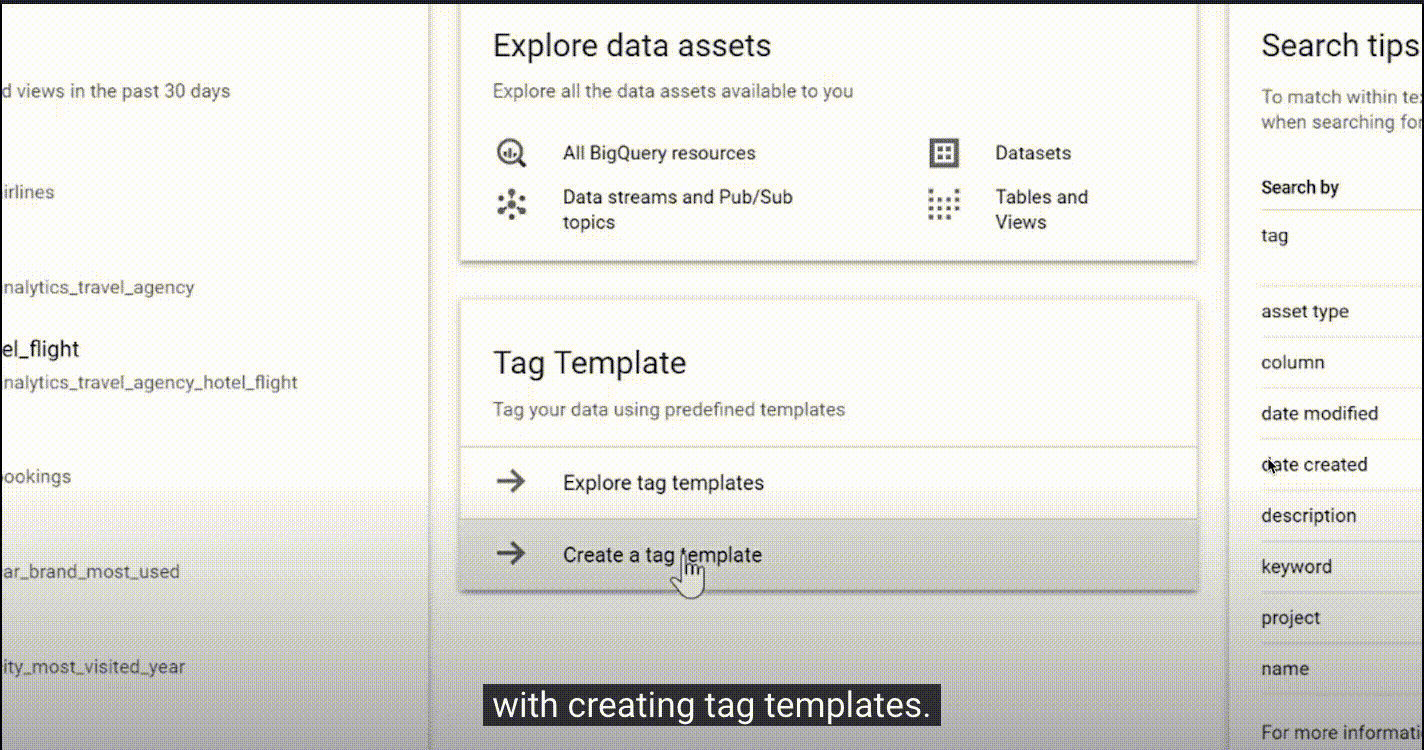
2.4、Google Data Catalog
地址:https://cloud.google.com/data-catalog
特点:
| 无服务器 | 可伸缩的全代管式元数据管理服务,不要求设置或管理任何基础架构,因此能够集中精力发展业务。 |
|---|---|
| 元数据即服务 | 利用元数据管理服务,可以使用自定义 API 和界面对数据资产进行编目,从而集中查看任何位置的数据。 |
| 集中式目录 | 灵活而强大的编目系统,能够自动捕获技术元数据并利用标记以结构化格式捕获业务元数据。 |
| 搜索和发现 | 界面简单易用,具有强大的结构化搜索功能,可让您轻松地快速查找数据资产,使用与 Gmail 和云端硬盘所用相同的 Google 搜索技术。 |
| 架构化元数据 | 支持架构化标记(例如 Enum、Bool、DateTime)而不仅仅是简单的文本标记,为组织提供丰富且有条理的业务元数据。 |
| Cloud DLP 集成 | 发现敏感数据并对其进行分类,以提供情报并帮助简化数据治理过程。 |
| 本地连接器 | 将非 Google Cloud 数据资产的技术元数据提取到 Data Catalog,可集中查看所有数据资产。 |
| Cloud IAM 集成 | 提供访问权限级别控制功能,在对数据资产进行读取、写入和搜索时遵循源 ACL,获享企业级的访问权限掌控力。 |
| 治理 | 集成了 Cloud DLP 和 Cloud IAM,可提供坚实的安全性和合规性基础。 |
2.5、Azure Purview
地址:https://azure.microsoft.com/en-in/services/purview/
特点:
1、创建跨整个数据资产的统一数据地图,为有效的数据治理和使用奠定基础
1.1、自动化和管理混合源的元数据;
1.2、使用内置和自定义分类器以及 Microsoft 信息保护敏感度标签对数据进行分类;
1.3、在 SQL Server、Azure、Microsoft 365 和 Power BI 中一致地标记敏感数据;
1.4、使用 Apache Atlas API 轻松集成所有数据系统
2、更加容易定位数据
2.1、使用熟悉的业务和技术搜索术语,更加快速A容易找到想要的数据;
2.2、使用企业级业务词汇表消除对 Excel 数据字典的需求;
2.3、通过交互式数据血缘可视化了解数据的来源为数据科学家、工程师和分析师提供 BI、分析、人工智能和机器学习所需的数据
3、通过预览版全面了解数据管理活动
3.1、按资源类型、分类和文件大小等资产维度查看整个数据资产及其分布
3.2、获取有关扫描成功、失败或取消的状态更新
3.3、添加重要观点或重新分发词汇表术语以获得更好的搜索结果
2.6、Atlan
地址:https://www.alation.com/
特点:
1、发现管理数据:Alation通过清点、分类和整理数据, 提供了对企业数据资产的可见性。与耗时的自上而下、孤立的方法相比,Alation 使企业能够将治理工作集中在最关键的数据资产上,以便对业务产生最大的影响。
2、推动实施、工作流程和管理:Alation 实现了治理策略、工作流和文档的敏捷批准和交流。通过提供分析和仪表板来监控和跟踪策展进度
3、积极吸引业务线用户:Alation 没有限制业务线用户使用数据,而是将治理、协作和通信功能直接放入他们的日常工作流程中,以鼓励准确、合规的数据驱动决策。
4、自动化数据治理流程:Alation 平台结合了机器学习和众包,以自动化和加速数据管理、数据分类、业务术语表和数据质量文档。
5、建立对数据的信任:Alation 对数据质量指标、描述和看板进行编目,并在消费和分析点实时向用户展示数据质量信息。通过触手可及的数据分析信息,数据使用者可以查看有关数据的重要特征、统计数据和数字图表,从而使他们能够自信地快速采取行动
6、主动降低风险:数据血缘可帮助用户了解数据的来源、谁使用它以及如何使用它。而且,通过影响分析报告,用户可以全面了解变更的下游影响,有助于主动降低风险
Alation.gif
2.7、Data.World
地址:https://data.world
特点:
1、数据发现:在整个数据生态系统进行统一搜索和发现
2、治理和访问:获得敏捷的环境治理,以便可以扩展自助分析。同时为每个人提供个性化的发现,使数据工作合规。
3、协作沟通:让不同的团队可以轻松地在数据项目上协同工作。让每个人都使用他们熟悉和喜爱的工具,以便他们可以充分贡献,这样可以在上下文中共享结果,并捕获跨工具、团队和数据源的血缘
4、复用:创建可重用、可扩展的数据和分析
2.8、Twitter Data Access Layer
地址:https://blog.twitter.com/engineering/en_us/topics/insights/2016/discovery-and-consumption-of-analytics-data-at-twitter.html
致力目标:
1、数据发现:我们如何找到最重要的数据集,谁拥有这些数据集,它们的语义和其他相关元数据是什么?
2、数据审计:谁创建或使用这些数据集,它们是如何创建的,它们的依赖关系和服务级别协议 (SLA) 是什么,它们的警报规则是什么以及它们与它们的依赖关系是否一致,以及数据集的生命周期如何管理?
3、数据抽象:数据在逻辑上代表什么,它的物理表示是什么,它位于哪里,复制到哪里,格式是什么?
2.9、Shopify Artifact
Artifact 是一种建立在数据模型之上的搜索和浏览工具,该模型将元数据集中在各种数据过程中。 Artifact 允许所有团队发现数据资产、他们的文档、血缘、使用、权限和其他有助于用户构建必要数据上下文的元数据。此工具可帮助团队在其角色中更有效地利用数据地址:https://shopify.engineering/solving-data-discovery-challenges-shopify
架构如下: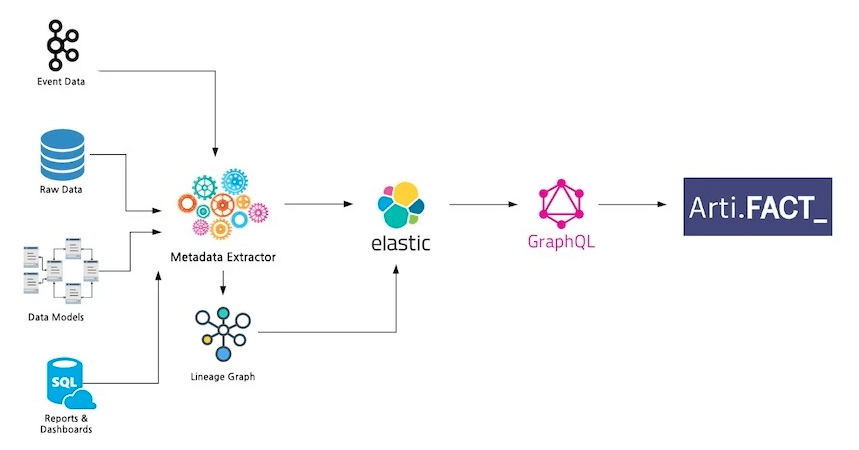
从一个通用数据模型和一个简单的元数据摄取管道开始,该管道从 Shopify 的各种数据存储和流程中提取信息。元数据提取器还会基于特征构建依赖图。处理后,信息存储在 Elasticsearch 索引中,GraphQL API 通过 Apollo 客户端将数据公开给 Artifact UI。
2.10、Netflix Metacat
Metacat 是一种元数据服务,使数据易于发现、处理和管理。在 Netflix,数据仓库由存储在 Amazon S3(通过 Hive)、Druid、Elasticsearch、Redshift、Snowflake 和 MySql 中的大量数据集组成。平台支持使用 Spark、Presto、Pig 和 Hive 来消费、处理和生成数据集。鉴于数据源的多样性,并确保数据平台可以作为一个“单一”数据仓库跨这些数据集进行互操作,由此构建了 Metacat。地址:https://netflixtechblog.com/metacat-making-big-data-discoverable-and-meaningful-at-netflix-56fb36a53520?gi=30b7bd4248ae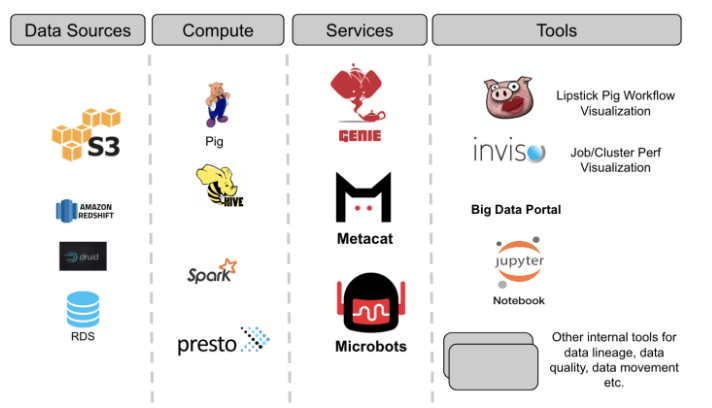
Netflix 大数据平台的核心架构涉及三个关键服务。它们是执行服务 (Genie)、元数据服务和事件服务。这些想法并不是 Netflix 独有的,他们认为这是构建一个系统所必需的架构。
许多年前,当Netflix开始构建平台时,采用 Pig 作为ETL 语言,采用 Hive 作为临时查询语言。由于 Pig 本身没有元数据系统,因此构建一个可以在两者之间进行互操作的系统似乎是当时的理想选择。
因此 Metacat 诞生了,一个系统充当支持的所有数据存储的联合元数据访问层。各种计算引擎可用于访问不同数据集的集中式服务。一般来说,Metacat 服务于三个主要目标:
1、元数据系统的联合视图
2、数据集元数据的统一 API
3、数据集的任意业务和用户元数据存储
值得注意的是,其他拥有大型分布式数据集的公司也面临着类似的挑战。 Apache Atlas、Twitter 的数据抽象层和 Linkedin 的 WhereHows(Linkedin 的数据发现)。
Metacat 提供统一的 REST/Thrift 接口来访问各种数据存储的元数据,相应的元数据存储仍然是模式元数据的真实来源,因此 Metacat 不会在其存储中实现它。它只直接存储有关数据集的业务和用户定义的元数据。它还将有关数据集的所有信息存储到 Elasticsearch 以进行全文搜索和发现。
在更高的层次上,Metacat 的功能可以分为以下几类:
1、数据抽象和互操作性
2、业务和用户定义的元数据存储
3、数据发现
4、数据变更审计和通知
5、Hive 元存储优化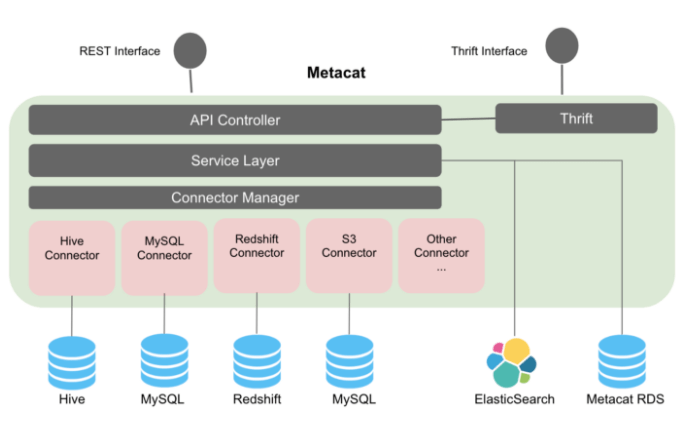
2.11、Uber Databook
Databook是Uber的内部平台,该平台可以显示和管理数据集的内部位置和所有者的元数据,能够将数据转化为知识地址:https://eng.uber.com/databook/
功能:
1、可扩展性:新的元数据、存储和实体很容易添加。
2、可访问性:服务可以以接口方式访问所有元数据
3、可伸缩性:支持高吞吐量读取
4、支持跨数据中心读写
Databook 提供了来自 Hive、Vertica、MySQL、Postgres、Cassandra 和其他几个内部存储系统的各种元数据,包括:表模式、表/列描述、样本数据、统计数据、血缘、、表新鲜度、SLA 和责任人等等。
所有元数据都可以通过UI可视化和 RESTful API 访问。
1、RESTful API 由 Dropwizard 提供支持,Dropwizard 是一种用于高性能 RESTful Web 服务的 Java 框架,部署在多台机器上,并由 Uber 的内部请求转发服务进行负载平衡。
2、可视化 UI 是用 React.js 和 Redux 以及 D3.js 编写的,主要提供整个公司的工程师、数据科学家、数据分析师和运营团队使用,以及对数据质量问题进行分类并识别和探索相关数据集。
架构: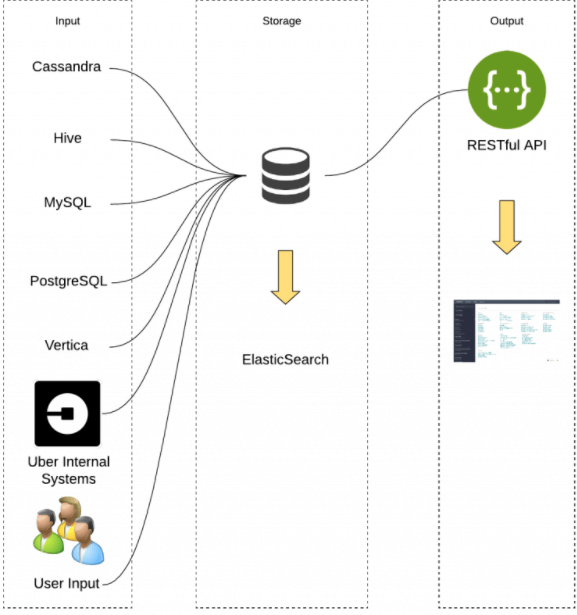
2.12、Spotify Lexicon
Lexikon是一个数据洞察库,可帮助用户查找和理解生成的数据和知识的一套内部产品,其目的是为了改善数据发现体验地址:https://engineering.atspotify.com/2020/02/27/how-we-improved-data-discovery-for-data-scientists-at-spotify/
2.13、Airbnb Data Portal
地址:https://medium.com/airbnb-engineering/democratizing-data-at-airbnb-852d76c51770
Airbnb内部的产品用于提升数据可发现性和探索性,建立对数据的信任。其主要功能有以下几点:
1、搜索:Dataportal 最重要的功能是对整个数据生态系统的统一搜索。用户可以搜索日志记录、数据表、图表、仪表板。搜索卡中尽可能多地显示有关资源的元数据,以建立上下文和信任。利用图的拓扑来提高搜索相关性,使用 PageRank 来推广高质量的相关资源,有据可查和经常使用的资源将导致更高的分数,这有助于确保搜索将用户吸引到最理想的实体。
2、上下文和元数据:从搜索中,用户可以通过访问其详细内容页面来进一步探索资源。没有上下文的数据通常毫无意义,可能会导致不明智和代价高昂的决策。因此,内容页面展示了拥有的跨数据工具资源的所有信息,以显示它如何适应整个数据生态系统:谁使用了资源,谁创建了它,它何时被创建或更新,它与哪些其他资源相关, 等等。
更多的元数据转化为更多的数据。对于数据表尤其如此,它是任何数据仓库的基础。易于编辑的元数据信息方便了表描述和列注释的更新,绕过了复杂和用户受限的命令。
3、以用户为中心的数据:Dataportal提供了一个专门的用户页面来整合用户创建、使用、收藏的所有数据资源,同时企业中的任何员工都可以查看任何其他员工的页面,这从生产和消费的角度都提高了透明度。
4、以团队为中心的数据:Dataportal提供了一个专门的团队页面,因为团队有他们查询的表格、他们创建和查看的仪表板、他们跟踪的团队指标等等。这样就可以把团队间链接起来,方便快速定位管理项目。
2.14、Facebook Nemo
Nemo是一个内部数据发现引擎,致力于让数据发现过程变得更加简单快速并对结果的准确性充满信心。
Nemo使用较复杂的搜索引擎架构实现可扩展性,同时能够解析和回答自然语言查询。例如,您可以问“Instagram 上每周有多少活跃用户?”并获取指向包含相关数据的表的地址。地址:https://engineering.fb.com/2020/10/09/data-infrastructure/nemo/
搜索引擎架构:
Nemo 有两个主要组件,索引和服务,前端位于服务部分的顶部。索引又分为批量索引(每天发生)和即时索引(立即更新索引)。因此,无论何时创建 Hive 表,即时更新都保证可以在几秒钟内按名称或创建者找到它。例如过去一个月访问该表的工程师数量,是在更繁重的批量过程中收集的,可能会滞后一两天。虽然最大的数据源(例如 Hive)由 Nemo 本身的工程师处理,但创建新型数据工件的工程师可以通过调用 Nemo API 自行搜索他们的工件。
对于服务,基于 spaCy 的 NLP 库执行文本解析;检索和初始排名步骤由 Unicorn 处理,更复杂的信号(如基于 kNN 的评分和 FBLearner 训练的 ML 模型)用于后处理。此外,在后处理过程中会考虑各种社交信号——例如给定工件的用户列表。无文本查询通常只是类型和质量限制的列表,经过特殊处理,最终得分强调个人和团队级别的使用。
前端负责显示结果和其他各种技术细节,例如提供查询构建系统,以便用户可以轻松指定多个限制,这些限制可以简单地转换为 Unicorn 查询。它还突出显示重复或低质量的工件,以引导用户做出正确的选择。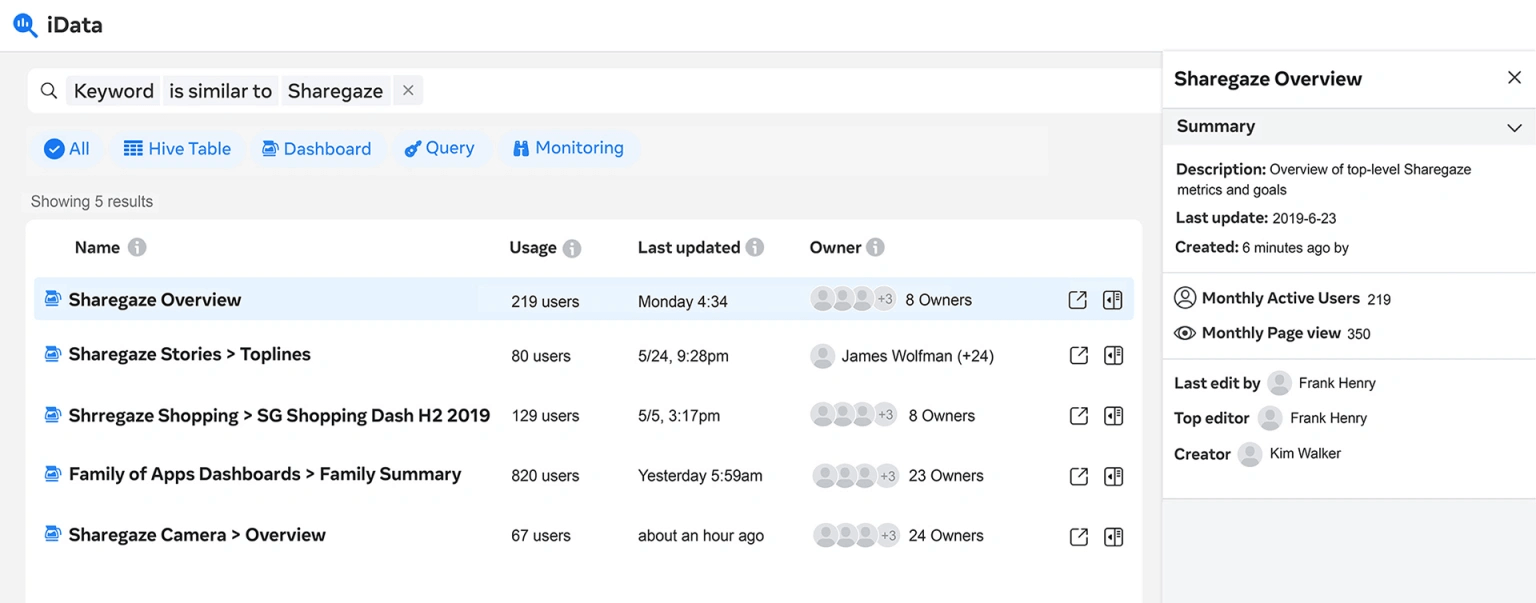
2.15、Alation
地址:https://www.alation.com/
特点:
1、数据治理促进增长:Alation 的主动数据治理以人为本,因此人们可以访问他们需要的数据,并在工作流程中提供有关如何使用数据的指导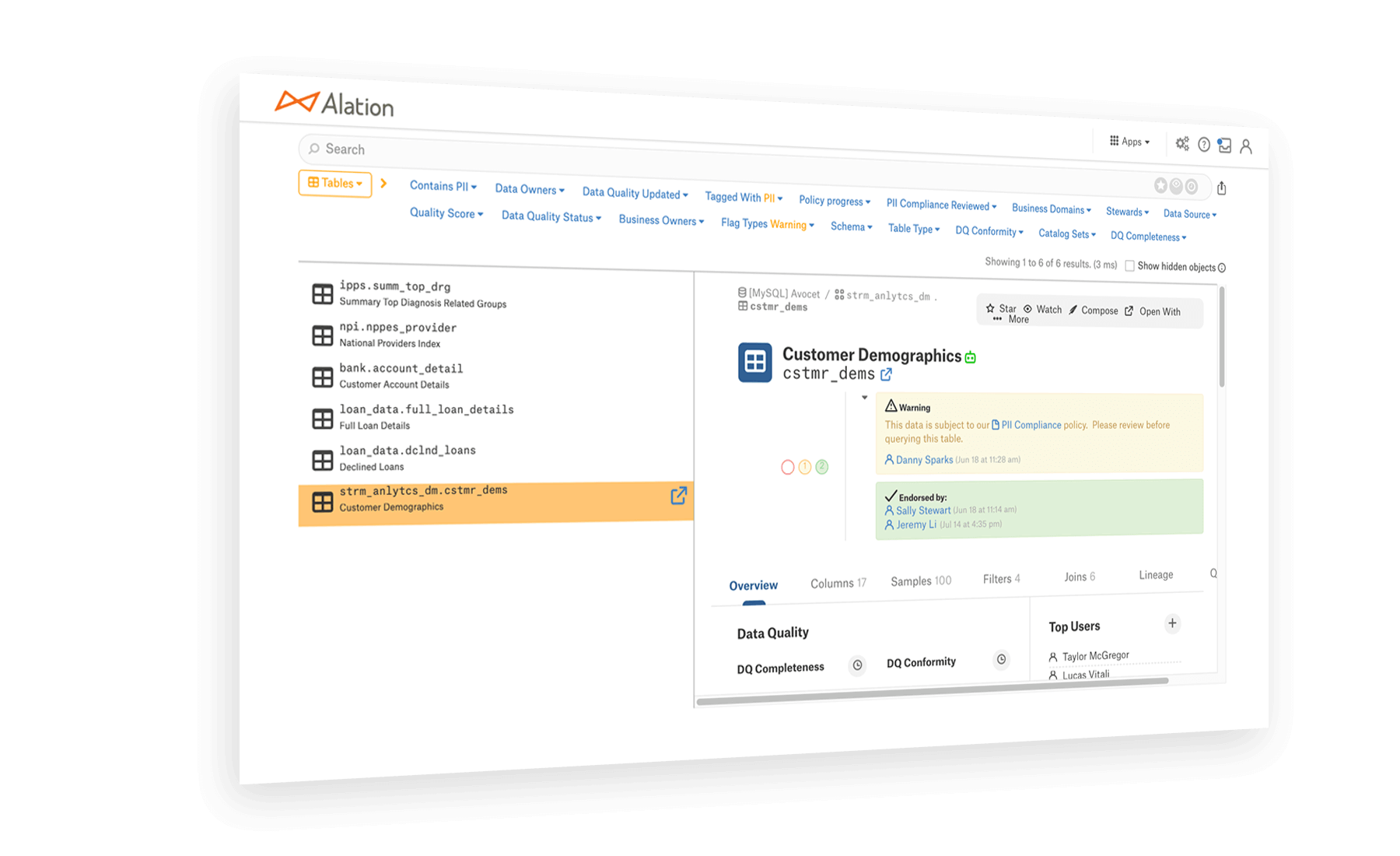
2、自助分析:共享查询以跨团队协作。欢迎更多人使用数据,并支持大规模的快速数据驱动决策。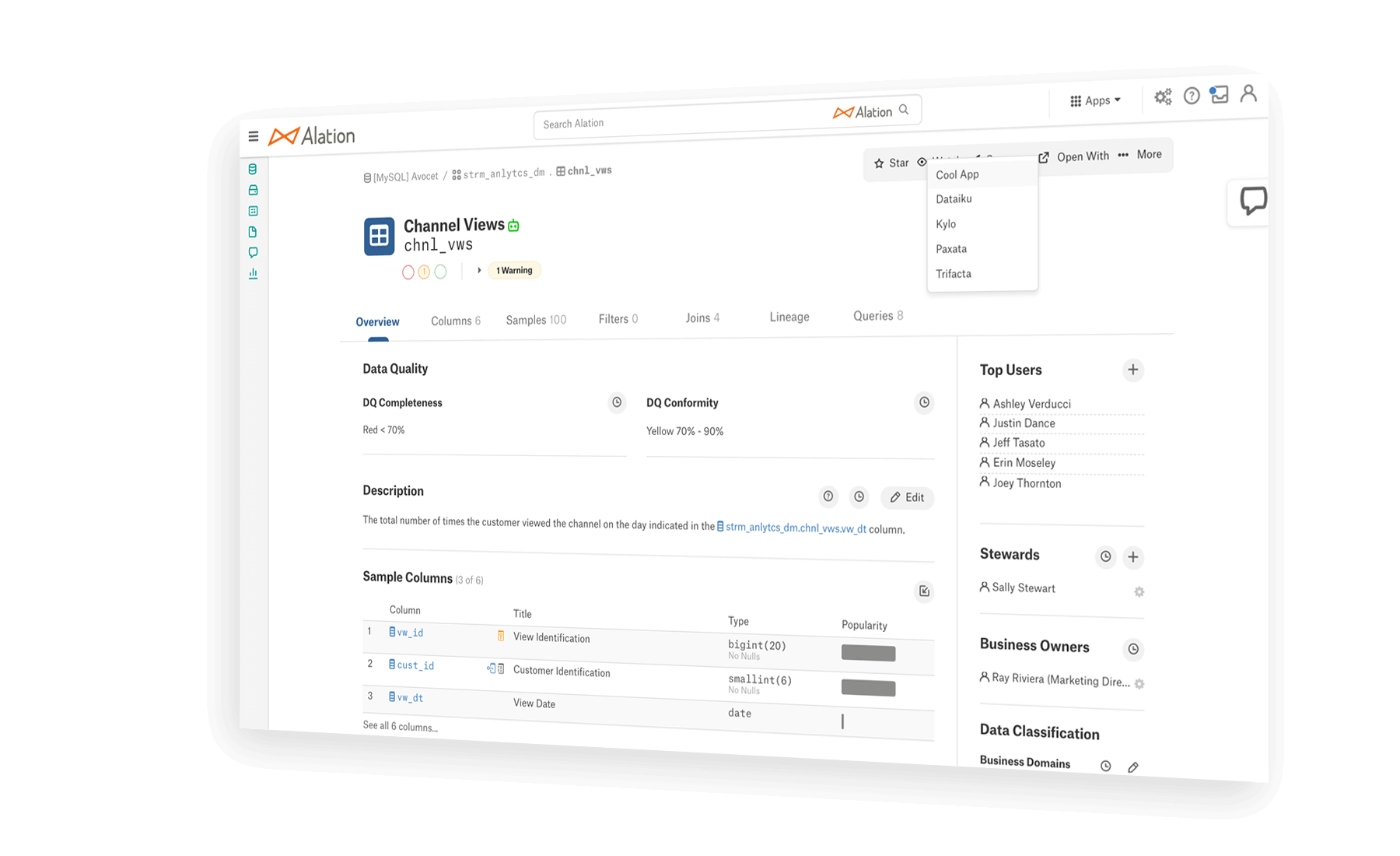
3、支持迁移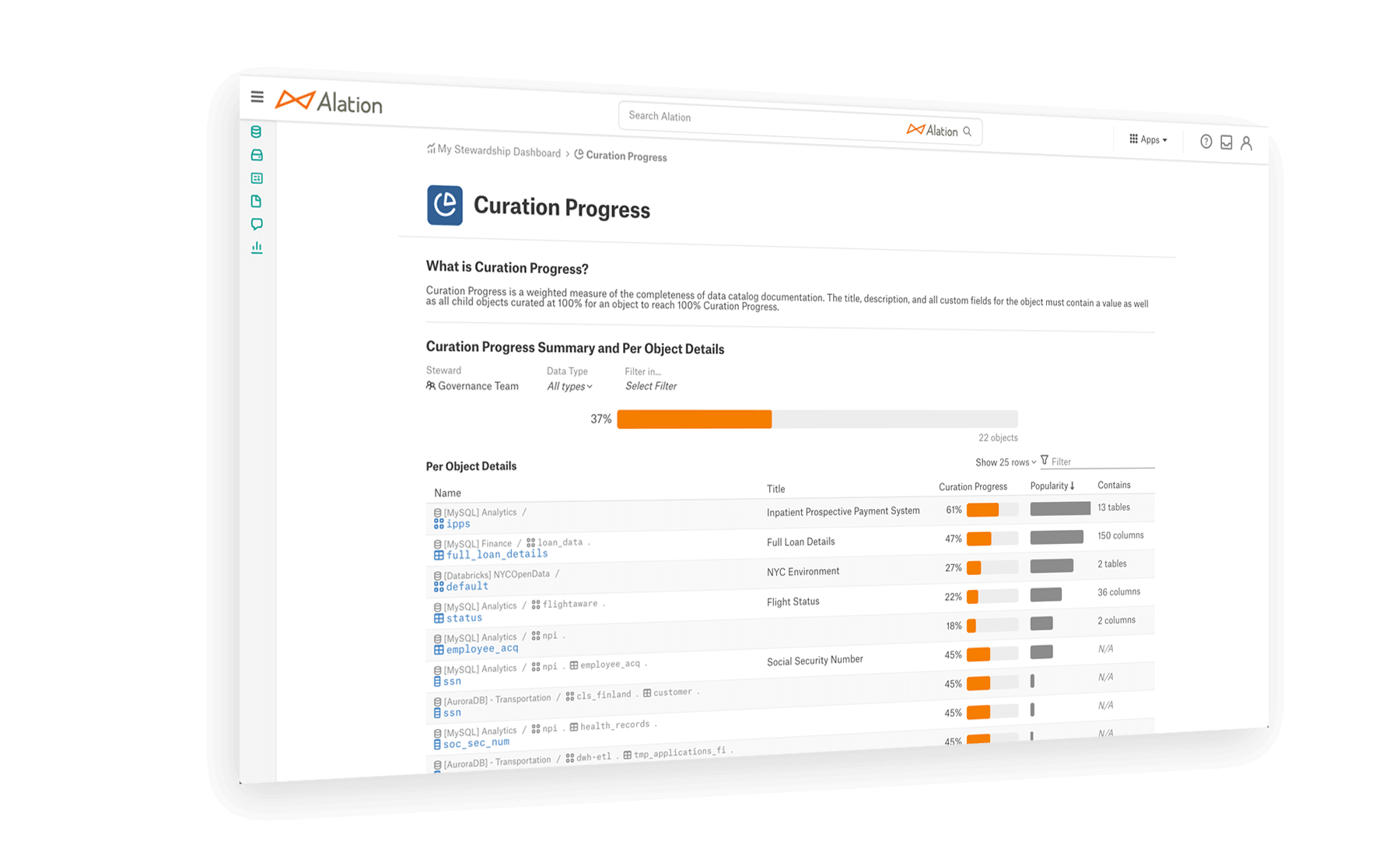
4、搜索与发现:为组织中的所有数据和数据用户提供单一的参考系统。一目了然地了解数据质量、上下文和使用模式
2.16、Collibra
Collibra 的数据智能云致力于整个公司的每个人、团队和系统与准确、可信的数据保持一致——将人们与事实结合起来,激发推动业务发展。其产品特点如下:
1、通过认证报告推动战略决策:由于业务术语和指标的不一致,组织通常对执行报告缺乏信任。Collibra的解决方案有助于集中、管理和认证报告和指标,从而节省大量成本。
2、提高数据湖的采用率和投资回报率:由于缺乏可管理性、可追溯性和数据访问策略,企业数据湖经常成为数据沼泽。Collibra的解决方案可帮助用户安全、合规地发现、理解、信任和访问其数据湖中的数据
3、利用数据基础加速隐私操作:组织通常缺乏可靠的数据基础来以可扩展的方式响应监管要求。Collibra的解决方案有助于集中、自动化和指导数据隐私工作流程,以支持全球法规
4、通过识别重复数据降低成本:许多组织在不知不觉中购买了类似的第三方数据集。Collibra的解决方案有助于自动识别重复数据集,使数据专业人员能够轻松清除重复数据。
地址:http://collibra.com/
3、开源解决方案
3.1、Apache Atlas
Atlas 是一组可扩展和可扩展的核心基础治理服务——使企业能够有效和高效地满足其在 Hadoop 中的合规性要求,并允许与整个企业数据生态系统集成。
Apache Atlas 为组织提供开放的元数据管理和治理功能,以构建其数据资产的目录,对这些资产进行分类和治理,并为数据科学家、分析师和数据治理团队提供围绕这些数据资产的协作功能。
地址:https://atlas.apache.org
特点:
1、元数据类型和实例
1.1、各种 Hadoop 和非 Hadoop 元数据的预定义类型
1.2、能够为要管理的元数据定义新类型
1.3、类型可以有原始属性、复杂属性、对象引用;可以从其他类型继承
1.4、类型的实例,称为实体,捕获元数据对象详细信息及其关系
1.5、用于处理类型和实例的 REST API 允许更轻松的集成
2、分类
2.1、能够动态创建分类 - 如 PII、EXPIRES_ON、DATA_QUALITY、SENSITIVE
2.2、分类可以包括属性 - 如 EXPIRES_ON 分类中的 expiry_date 属性
2.3、实体可以与多个分类相关联,从而更容易发现和安全实施
2.4、通过谱系传播分类 - 自动确保分类在数据经过各种处理时跟随数据
3、血缘
3.1、直观的 UI 可在数据通过各种流程时查看数据的血缘
3.2、用于访问和更新谱系的 REST API
4、搜索/发现
4.1、直观的 UI,可按类型、分类、属性值或自由文本搜索实体
4.2、丰富的 REST API 可按复杂条件进行搜索
4.3、用于搜索实体的 SQL 之类的查询语言 - 领域特定语言 (DSL)
5、安全和数据屏蔽
5.1、元数据访问的细粒度安全性,支持对实体实例的访问和添加/更新/删除分类等操作的控制
5.2、与 Apache Ranger 的集成支持基于与 Apache Atlas 中实体关联的分类对数据访问进行授权/数据屏蔽。例如:谁可以访问归类为 PII、敏感的数据。客户服务用户只能看到归类为 NATIONAL_ID 的列的最后 4 位数字
3.2、Datahub
Datahub也是业界比较熟悉的一款工具, 支持数据发现、数据可观察性和联合治理。其特点:
1、开源
2、庞大的生态系统:DataHub 已集成Kafka、Airflow、MySQL、SQL Server、Postgres、LDAP、Snowflake、Hive、BigQuery 等等。
3、DataHub 遵循基于推送的架构,这意味着它是为不断变化的元数据而构建的。模块化设计使其能够随着任何组织的数据增长而扩展。
地址:https://datahubproject.io/
3.3、Amundsen
Amundsen是一款开源数据发现和元数据引擎。其特点如下:
1、发现数据:通过简单的文本搜索搜索数据。受PageRank 启发的搜索算法会根据表格/仪表板上的名称、描述、标签和查询/查看活动推荐结果
2、查看自动化和精选的元数据:使用自动化和精选的元数据建立对数据的信任——表和列的描述、其他常用用户、表上次更新时间、统计信息、数据预览(如果允许)等。 通过链接 ETL 作业和生成的代码轻松分类数据。
3、协作:通过描述更新表和列,关于使用哪个表和列以及包含什么的问题,减少不必要沟通。
4、共享:查看同事经常使用、拥有或添加书签的数据。通过查看在给定表上构建的仪表板,了解最常见的表查询是什么样的。
地址:http://amundsen.io/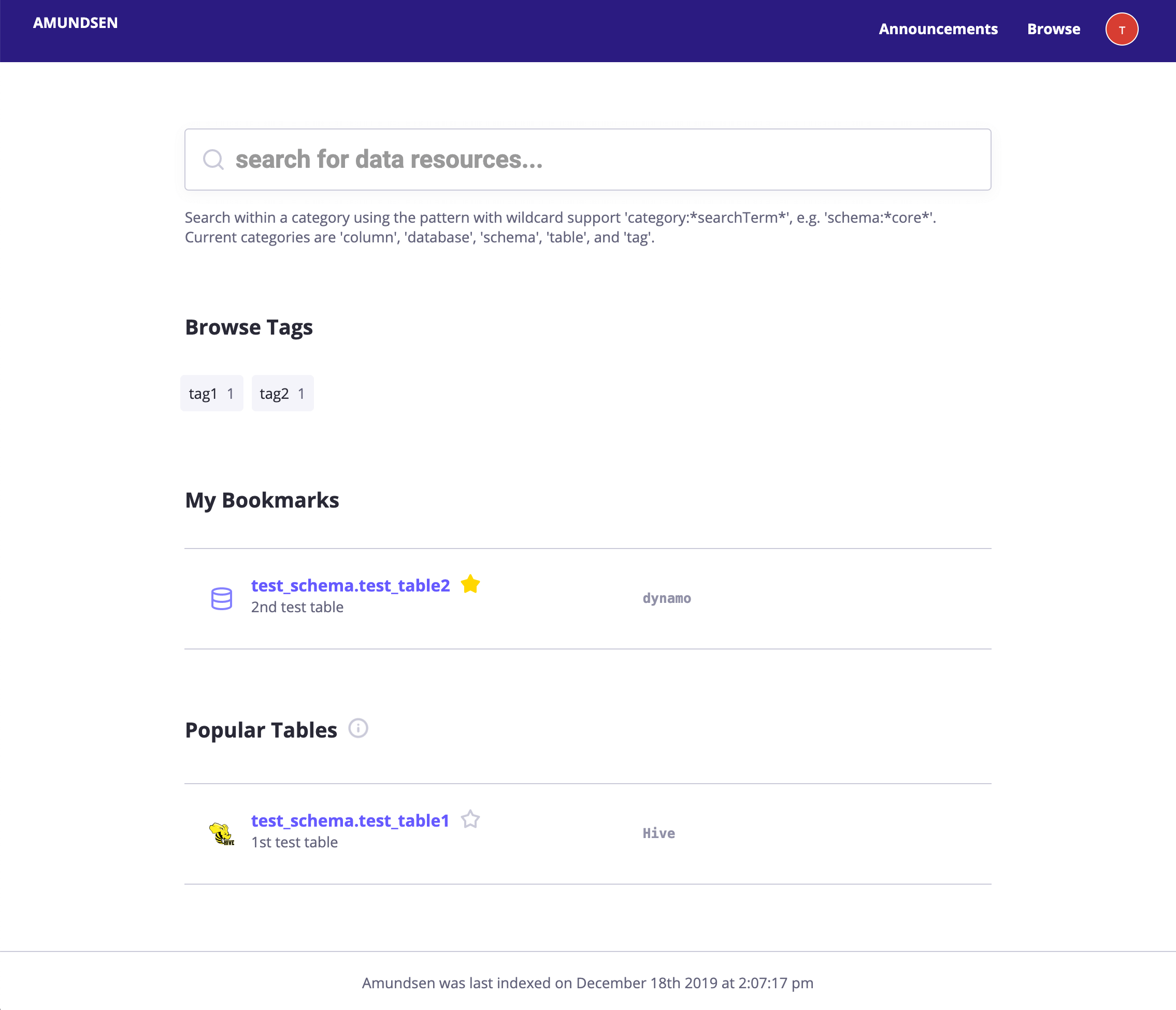
4、Lake Discovery
4.1、Databricks Unity Catalog
Unity Catalog 是由Databricks开发的一款统一目录数据和人工智能的细粒度治理工具,可与您现有的目录、数据和存储系统配合使用,因此您可以利用现有投资并构建面向未来的治理模型。例如,它允许您在 Apache Hive Metastores 或 Amazon S3 中挂载现有数据,并跨高级安全解决方案(如 Immuta 或 Privacera)管理策略,同时使用 ANSI SQL DCL 管理权限,所有这些都集中在一处。
其特点如下:
1、Unity Catalog UI 让您可以轻松地在一处地方发现、审核和管理数据资产。数据血缘、基于角色的安全策略、表或列级标签以及中央审计功能使数据管理员可以轻松自信地管理和保护数据访问,直接在 Lakehouse 上满足合规性和隐私需求。
2、Unity Catalog 通过开放标准 ANSI SQL DCL 为跨云的数据资产带来细粒度的集中治理。这意味着数据库管理员可以使用熟悉的 SQL 轻松地授予对任意、特定于用户的视图的权限,或对标记在一起的所有列设置权限
3、每个组织都需要与客户、合作伙伴和供应商共享数据,以更好地协作并从他们的数据中释放价值。 Unity Catalog 建立在开源 Delta Sharing 之上,以集中管理和治理组织内部和组织之间的共享资产。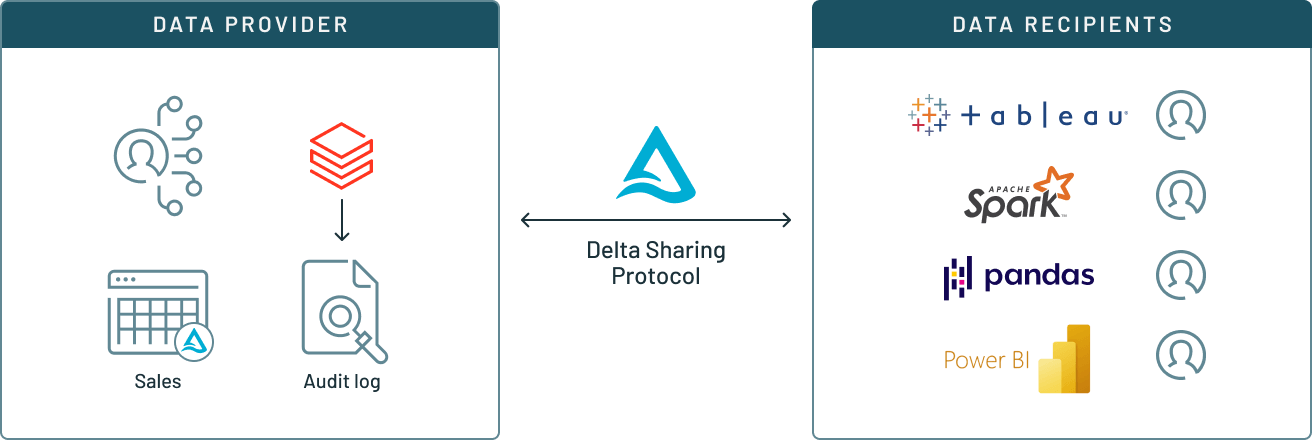
地址:https://databricks.com/product/unity-catalog

若有收获,就点个赞吧
0 人点赞

{kind=link}