8.1、HDFS
8.1.1、读流程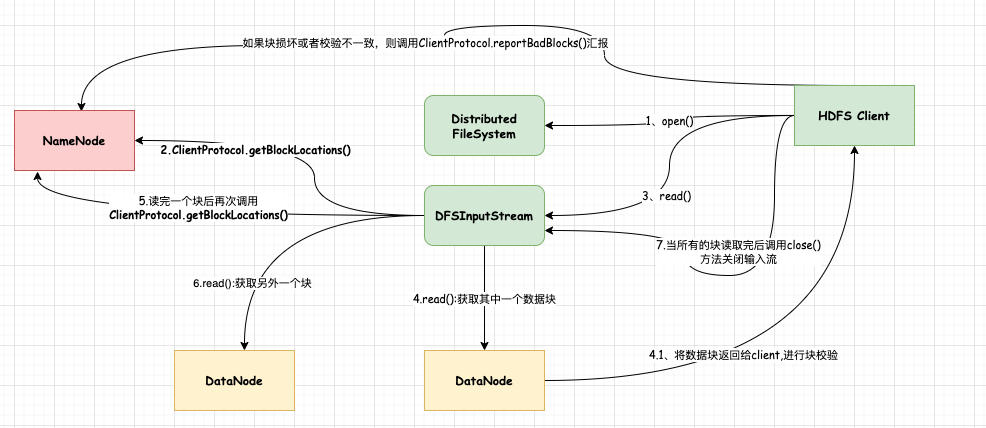
8.1.1.1、大致流程:
1、发起打开文件请求
2、获取DN位置信息
3、DN通信连续获取数据块
3.1、校验数据块,异常处理
4、关闭输入流
8.1.1.2、详细流程:
1、客户端执行读取命令或者调用读取接口,底层会通过ClientProtocol接口和NN进行通信,获取文件起始位置对应的所有数据块信息。
2、根据获取到的数据块信息(其中包含该数块对应的存储位置),选择离客户端最近的一个DataNode节点建立连接,进行读取数据块操作。
3、客户端底层通过调用DFSInputStream.read()方法以packet的方式从DataNode获取数据。
4、当客户端获取到返回的数据块时,会首先进行块检测校验,如果校验值不一样或者是DataNode节点出现异常时,会通过ClientProtocol.reportBadBlocks方法向NameNode汇报坏块信息。(延伸:这里NN会发出块平衡指令)
5、此时客户端会从副本数据块所在的DN节点进行通信获取,同样也会进行校验。
6、当该数据块读取完成后,会再次请求NN获取下一个数据块对应的DN节点信息。
7、以此循环执行1~6步骤,直到所有的数据块都读取完成。最后关闭输入流。
8.1.2、写流程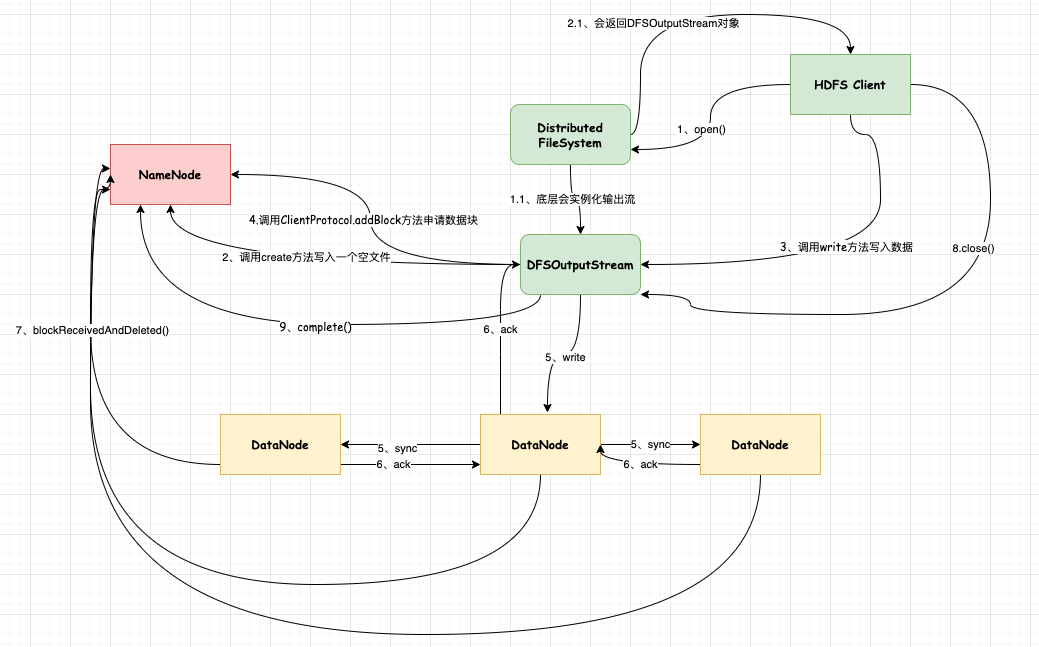
8.1.2.1、大致流程:
1、创建空文件
2、建立流管道
3、写数据
3.1、写入异常处理
4、关闭管道,提交文件
8.1.2.2、详细流程(这里未涉及到租约问题):
1、当客户端发起写请求时,会先让NN创建一个空的文件,然后把这个操作记录到editLog中。这个时候会返回一个DFSOutputStream输出流对象。
2、当客户端得到输出流对象时,会向NN申请数据块,拿到对应的DN位置信息后,开始通信建立管道用于传输数据。
3、客户端开始发送数据,这些数据会被切分成Packet,发送到DN节点,然后DN进行确认,返回给输出流一个ack消息。
4、当所有的DN节点都确认了数据已经写入后,输出流就会从缓存队列(都是未确认的packet)中删掉这个数据包。当DN成功接收一个块之后,会向NN汇报,NN更新内存中的元数据信息(即块和节点的关系。)
5、当客户端写满一个数据块后,会再次向NN申请新的数据块,然后循环执行1~5步骤。
6、当客户端把文件所有的数据都写完之后,就会关闭输出流,然后通知NN提交所有的数据块。
8.1.2.3、思考
思考1:如果在写的过程中,节点出现了异常会不会出现块丢失?
答:首先在输出流的设计中,会有缓存队列,用来存储未被确认的数据包,如果节点异常,会把未确认的数据包重新加入到发送队列中。因此就算节点出现了问题(挂掉或者网络不通无法写入),也不会导致某一个块的丢失,因为所有的块必须要进行确认的。
思考2:如何保障集群所有节点的数据块的一致准确?
答:这里会有一个时间戳机制,也就是说在写入数据块的时候会申请一个时间戳,然后用这个新的时间戳建立一个管道。
考虑两种情况:
一种是假死:当往一个DN写数据的时候,比如说DN没有发送心跳,认为这个DN挂掉了,那么这个时候客户端会向NN汇报,并重新申请时间戳建立新的时间戳,当假死DN节点恢复后会出现故障前的时间戳和NN上保存的时间戳不一致,因此会把失效的块进行删除。这样就保障了所有的数据块都是一致的。
另外一种是真的挂掉了,那么这个时候会向新的DN节点进行通信,申请新的时间戳建立管道,同时这个节点上没有存储这个新的数据块(注意:这个时候是该块还没有写满),因此会先通过其他的DN节点把数据块复制到该节点上。
8.1.3、追加流程
8.1.3.1、大致流程:
1、打开已有的文件
2、建立管道流
3、写入数据
4、关闭管道流
8.1.3.2、详细流程:
1、客户端发起往已存在文件写的请求,NN会返回该文件最后一个块的位置信息。并实例化一个DFSOutputStream输出流,获取文件租约
2、如果最后一个块已经写满了,则会返回null,并向NN申请新的数据块。否则建立管道开始写数据。
3、客户端开始发送数据,这些数据会被切分成Packet,发送到DN节点,然后DN进行确认,返回给输出流一个ack消息。
4、当所有的DN节点都确认了数据已经写入后,输出流就会从缓存队列(都是未确认的packet)中删掉这个数据包。当DN成功接收一个块之后,会向NN汇报,NN更新内存中的元数据信息(即块和节点的关系。)
5、当客户端写满一个数据块后,会再次向NN申请新的数据块,然后循环执行1~5步骤。
6、当客户端把文件所有的数据都写完之后,就会关闭输出流,通知NN提交所有的数据块。
8.2、HDFS Block Size Design
在前面介绍了HDFS三部曲,简单理解了HDFS底层是如何完成读写功能的,在存储层面,HDFS采用了块抽象的方式简化了存储系统设计,即一个文件会被切分成多个块进行存储,在Hadoop 1.x中块的大小是64MB;在Hadoop 2.x中块的大小是128MB,当然在实际生产环境中,也有设置为256MB。
那么这里大家思考一下,Hadoop为什么要设计块大小为64、128或者256呢?为什么不能是100、200、300呢?为什么在Hadoop 1.X设置的块大小是64MB?为什么在Hadoop2.X就调整为128MB呢?
当然这个问题在面试中也会经常被问到。本文将来为大家详细介绍一下其中的设计思想,通过本文你将可以了解到:
1、系统磁盘块原理
2、磁盘读写流程
3、通过实际生活中的借款例子来诠释HDFS块设计思想
如有错误的地方,欢迎大佬指出~
首先大家应该要先清晰的知道,HDFS支持的文件语义是属于一次写入多次读取的,文件被切分成块在不同的机器上存储,假设我们有一个500MB的文件存储到HDFS上,那么Hadoop就会将文件进行切块存储,我们按照128MB来计算大概会生成4个块。如下图可见,最后一个Block实际大小不足128MB,但仍会占用一个块。这里需要和操作系统中的磁盘块区分开来,下文会简单介绍下磁盘块的知识点(这块属于操作系统层面的东西,不想看的同学直接往下翻就行);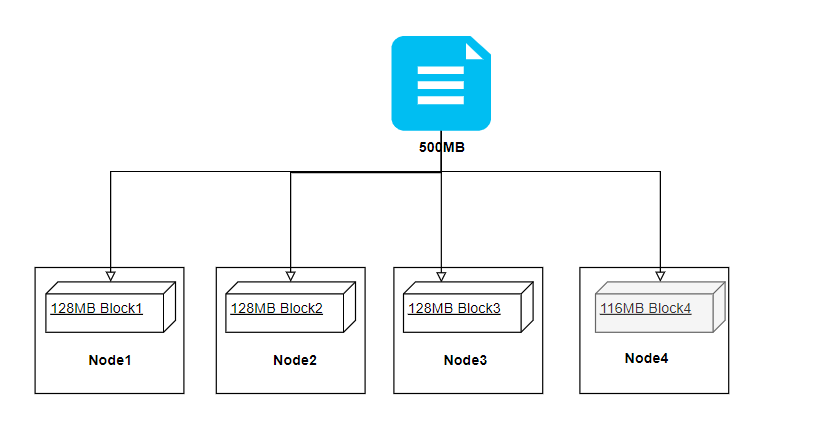
8.2.1、磁盘块
我们先来简单复习了解下系统层面的知识,因为这和下面讲解HDFS的块设计是有关系的。我们就拿日常的硬盘举例,
比如常使用的移动硬盘是由多个盘片叠加组成的(可以想象成以前我们玩的的光碟),盘片上面有一层特殊的磁性材质是由刚性材料制成,这也是硬盘名称的由来,和硬盘相对应的还有一种叫做软盘,可想而知,软盘是由一种软性材料组成的。硬盘的一个主轴上通常能安装好几个盘片,盘片是有正反两面的(也称为盘面),每一面都有这种磁性物质,而且 都能存储二进制信息,所以每个盘片需要两个磁头来读写数据。

磁头采用了非接触式头,与盘片之间的间隙只有0.1~0.3um,这样可以获得很好的数据传输率。而且磁头靠近主轴(转轴)接触的表面,即线速度最小的地方,是一个特殊的区域,它不存放任何数据,又被称为启停区或者是着陆区(Landing Zone),启停区外就是数据区。在最外圈,离主轴最远的地放是“0”磁道,硬盘数据的存放就是从最外圈开始的。
硬盘内部结构中还有一个电动机来带动盘片旋转,副电动机会带动一组磁头到相对应的盘片上并确定是读取正面还是反面,当磁盘旋转的时候,磁头要是保持在一个位置上,则每个磁头都会在磁盘表面上划出一个圆形轨迹,这些圆形轨迹就叫做磁道(Track)。
磁道会被等分为多个弧段,这些弧段就是扇区(Sector),等分的目的就是在读取和写入数据的时候,磁盘会以扇区为单位进行读取和写入这样可以提高运行速度。数据硬盘的第一个扇区又叫做引导扇区。每个扇区就是一个个磁盘块,存储固定数量用户可访问的数据,原来的扇区设计都是512Byte(即0.5KB)的容量,但目前大多数硬盘驱动器使用4KB扇区来存储大量的数据减少数据的拆解。

上图展示了关于磁道、扇面、扇区、扇区组之间的关系:A代表的是磁道;B代表的是扇面;C代表的是扇区;D代表的是簇(扇区组)。
8.2.2、磁盘读写流程
8.2.2.1、写流程
当我们写入文件到磁盘的时候,内部是按照柱面、磁头、扇区的方式进行的,即先是在第一磁道的第一个磁头下的所有扇区下存储,然后是同一个柱面的下一个磁头,直到把所有的内容写入到磁盘中。
8.2.2.2、读流程
当我们需要从磁盘中读取数据的时候,系统会把数据逻辑地址传给磁盘,磁盘内部的控制电路会按照寻址逻辑将逻辑地址翻译成物理地址,即要先确定读取的数据在哪个磁道上的哪个扇区(物理地址由柱面号、磁头号、扇区号三部分组成),当拿到物理地址后,需要将磁头放到这个扇区上方,为了能够到达这个扇区,那么磁头需要移动,这个过程就是我们常说的寻道,这个过程所花费的时间又叫做寻道时间,寻道时间越短,IO操作越快;
同时磁盘会将目标扇区进行旋转,到达磁头下,这个过程花费得时间又叫做旋转时间,该时间延迟取决于磁盘转速;
最后才开始读取数据,然后将数据存放到系统缓冲区中,这个传输过程所花费的时间是传输数据,该部分的时间和前面两个时间相比可以几乎忽略不计。
因此在磁盘上读取数据所花费的总时间=寻道时间+旋转时间+实际传输时间,但真正决定一个硬盘读写速度的是它的平均存取时间(也就是平均寻道时间和平均旋转延迟之和)。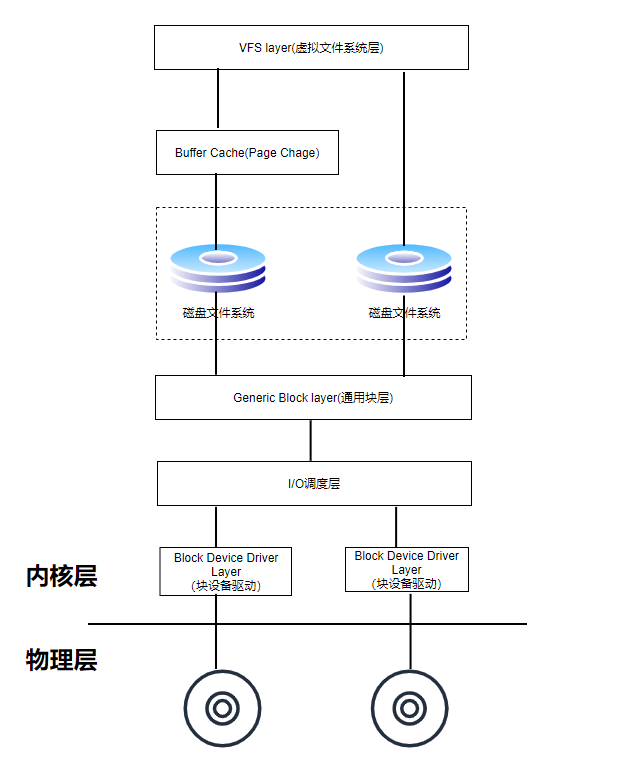
如上图所示,一次完整的磁盘读请求会经过cache层,Mapping层、通用层、I/O调用层和块设备驱动层,最后是物理设备层。文件系统中的块大小是要大于扇区大小的,一般是其整数倍。 而上层的各种逻辑系统设计都是基于文件系统逻辑块的整数倍 ,所以一般块大小的设置都不会是100,200之类的。而是2的次方。
8.2.3、借钱案例
那么我们继续回到今天的主题上,磁盘读写跟HDFS 块的大小又有什么关系呢?我们来举一个现实生活中真实的例子:相信大家都借出去过钱吧,假如你手里有10w块钱可以借出去,那么这里有几种借钱选择:
- 第一种情况:借给100个人,每个人1000块
- 第二种情况:借给10个人,每个人1w块
- 第三种情况:借给2个人,每个人5w块
- 第四种情况:借给1个人,10w全借出去
如果是你的话,第1,2种情况是不是肯定不会选择,想想看,你会时刻惦记着10个人以上还债情况吗?你有那么多精力吗?
同样的道理,如果HDFS的块大小越大,那么即使大文件那么切分的块个数也不会太多,在NameNode中存储也是能够cover住的,如果设置的块太小,那么就会生成大量的块,恐怕很快会消耗完NameNode的内存,这个和小文件危害问题其实是一样的,而且也会加大NN恢复加载元数据的时间。假设你设置的块大小为1MB,有一个1G的文件要存储,那么就会切分1024个块存储到DataNode上,这里还有一个问题就是1024个块有可能会分布到很多的DataNode上,在数据读写和副本复制的时候,无非增加了网络IO资源,这些也是要考虑进去的。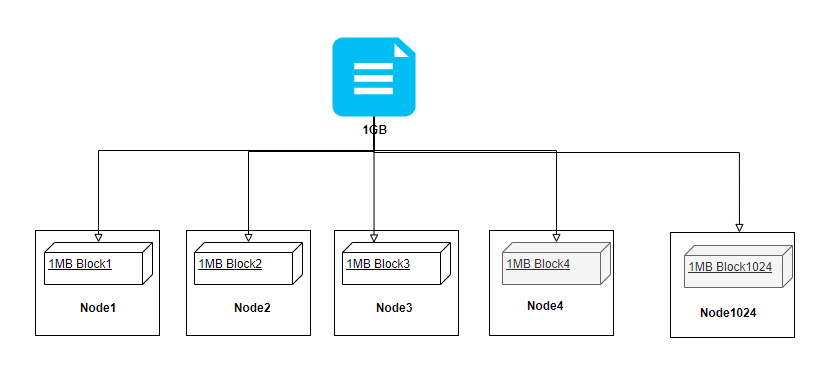
那既然块大小不能太小,如果设置块大小非常大呢?那么就和前面介绍的磁盘原理挂钩了,如果设置的块大小非常大,虽然切分的块个数是少了,对NameNode保存元数据信息也不会有太大压力,但是并行度就低了(想想MR模型),效率就会下降了,你说是不是呢?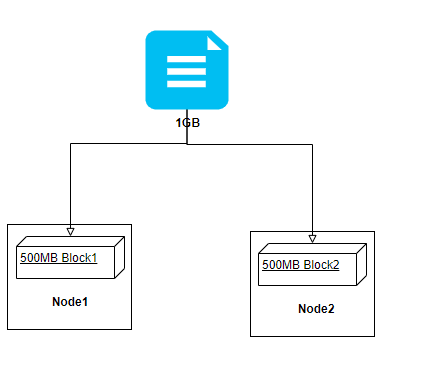
那么既然块大小不能太大,也不能太小,那为什么在Hadoop2.x之后把块大小调整为128MB呢?这个其实是跟早期的Hadoop设计有关系的,在学习Hadoop的时候,我们知道该系统是参考了Google的GFS论文,在GFS设计中就是使用的64MB作为默认的块大小(感兴趣的朋友可以再回过头来看看该论文中的Chunk Size部分),这里列出文中提到的几点原因:
- Lower the loading of master(减少NameNode负载). The master server of GFS only provides metadata of the chunk instead of chunk content. Therefore, less requests will be sent to master server if the chunk is relative large.
- Reduce network overhead(降低网络IO), it encourage applications to finish many operations on a single chunk and persistent network connection. Applications also get their data in fewer request.
- Reduce metadata size stored in the master(减少NameNode元数据存储). There is only one master server in GFS’s design. All metadata of chunks are stored in the memory of master server in order to reduce the latency and increase the throughput. Large chunks means less metadata, and less metadata means less load time of the metadata.

介绍到这里,可能会有朋友说既然这样的话,那为什么不是设置成256MB呢?其实这个块的大小设置并不是固定的,128MB是属于比较通用的配置,也是做过基准测试的,具体还要根据你的实际情况来抉择,如果说你们的数据量非常大,而且机器配置也很高,那么可能设置256MB或者512MB性能会更好。如果要调整块大小,可以修改hdfs-site.xml文件中的dfs.block.size属性

若有收获,就点个赞吧
0 人点赞
