- 一、Hive
- 首先初始化namenode,打开cmd执行下面的命令
- 当初始化完成后,启动hadoop
- 1.0.2、服务启动
- 1.1、流程剖析
- 1.2、Filter PushDown Cases And Outer Join Behavior
- 1.3、Function Cases
- 1.4、UDF/UDTF/UDAF
- 1.4.1、函数帮助
- 1.4.2、数学函数
- 1.4.2.1、abs
- 1.4.2.2、acos—>从Hive0.13.0
- 1.4.2.3、asin—>从Hive0.13.0
- 1.4.2.4、atan—>从Hive0.13.0
- 1.4.2.5、bin
- 1.4.2.6、bround—>Hive1.3.0
- 1.4.2.7、cbrt—>Hive1.2.0
- 1.4.2.8、ceil
- 1.4.2.9、conv
- 1.4.2.10、cos—>Hive0.13.0
- 1.4.2.11、degress—>Hive0.13.0
- 1.4.2.12、e
- 1.4.2.13、exp—>Hive0.13.0
- 1.4.2.14、factorial—>Hive1.2.0
- 1.4.2.15、floor
- 1.4.2.16、greatest—>Hive1.1.0
- 1.4.2.17、hex
- 1.4.2.18、least
- 1.4.2.19、ln—>Hive0.13.0
- 1.4.2.20、log2—>Hive0.13.0
- 1.4.2.21、log10—>Hive0.13.0
- 1.4.2.22、negative
- 1.4.2.23、pi
- 1.4.2.24、pmod
- 1.4.2.25、positive
- 1.4.2.26、pow
- 1.4.2.27、radians—>Hive0.13.0
- 1.4.2.28、rand
- 1.4.2.29、round
- 1.4.2.30、shiftleft—>Hive1.2.0
- 1.4.2.31、shiftright—>Hive1.2.0
- 1.4.2.32、shiftrightunsigned—>Hive1.2.0
- 1.4.2.33、sign—>Hive0.13.0
- 1.4.2.34、sin—>Hive0.13.0
- 1.4.2.35、sqrt—>Hive0.13.0
- 1.4.2.36、tan—>Hive0.13.0
- 1.4.2.37、unhex—>Hive0.12.0
- 1.4.2.38、width_bucket—>Hive3.0.0
- 1.4.3、集合函数
- 1.4.3.1、size
- 1.4.3.2、map_keys
- 1.4.3.3、map_values
- 1.4.3.4、array_contains
- 1.4.3.5、sort_array—>0.9.0
- 1.4.4、类型转化函数
- 1.4.4.1、binary
- 1.4.4.2、cast
- 1.4.5、日期函数
- 1.4.5.1、from_unixtime
- 1.4.5.2、unix_timestamp
- 1.4.5.3、to_date
- 1.4.5.4、year
- 1.4.5.5、quarter—>Hive1.3.0
- 1.4.5.6、month
- 1.4.5.7、day
- 1.4.5.8、hour
- 1.4.5.9、minute
- 1.4.5.10、second
- 1.4.5.11、weekofyear
- 1.4.5.12、extract—>Hive2.2.0
- 1.4.5.13、datediff
- 1.4.5.14、date_add
- 1.4.5.15、date_sub
- 1.4.5.16、from_utc_timestamp—>Hive0.8.0
- 1.4.5.17、to_utc_timestamp—>Hive0.8.0
- 1.4.5.18、current_date —>Hive1.2.0
- 1.4.5.19、current_timestamp —>Hive1.2.0
- 1.4.5.20、add_months—>Hive1.1.0
- 1.4.5.21、last_day —> Hive1.1.0
- 1.4.5.22、next_day —> Hive1.2.0
- 1.4.5.23、trunc —> Hive1.2.0
- 1.4.5.24、months_between—>Hive1.2.0
- 1.4.5.25、date_format —> Hive1.2.0
- 1.4.6、判断函数
- 1.4.6.1、if
- 1.4.6.2、isnull
- 1.4.6.3、isnotnull
- 1.4.6.4、nvl
- 1.4.6.5、coalesce
- 1.4.6.6、case when
- 1.4.6.7、nullif —>Hive2.3.0
- 1.4.6.8、assert_true —> Hive0.8.0
- 1.4.7、字符串函数
- 1.4.7.1、ascii
- 1.4.7.2、base64—>Hive0.12.0
- 1.4.7.3、character_length—>Hive2.2.0
- 1.4.7.4、chr—>Hive1.3.0
- 1.4.7.5、concat
- 1.4.7.6、context_ngrams
- 1.4.7.7、concat_ws
- 1.4.7.8、decode —>Hive0.12.0
- 1.4.7.9、elt
- 1.4.7.10、encode —>Hive0.12.0
- 1.4.7.11、field
- 1.4.7.12、find_in_set
- 1.4.7.13、format_number—>Hive0.10.0
- 1.4.7.14、get_json_object
- 1.4.7.15、in_file
- 1.4.7.16、instr
- 1.4.7.17、length
- 1.4.7.18、locate
- 1.4.7.19、lower
- 1.4.7.20、lpad
- 1.4.7.21、ltrim
- 1.4.7.22、ngrams
- 1.4.7.23、octet_length —>Hive2.2.0
- 1.4.7.24、parse_url
- 1.4.7.25、printf —>0.9.0
- 1.4.7.26、regexp_extract
- 1.4.7.27、regexp_replace
- 1.4.7.28、repeat
- 1.4.7.29、replace—>HIve1.3.0
- 1.4.7.30、reverse
- 1.4.7.31、rpad
- 1.4.7.32、rtrim
- 1.4.7.33、sentences
- 1.4.7.34、space
- 1.4.7.35、split
- 1.4.7.36、str_to_map
- 1.4.7.37、substr
- 1.4.7.38、substring_index —>Hive1.3.0
- 1.4.7.39、translate—>Hive0.14.0
- 1.4.7.40、trim
- 1.4.7.41、unbase64 —>Hive0.12.0
- 1.4.7.42、upper
- 1.4.7.43、initcap—>Hive1.1.0
- 1.4.7.44、levenshtein —>Hive1.2.0
- 1.4.7.45、soundex —>Hive1.2.0
- 1.4.8、掩码函数
- 1.4.8.1、mask—>Hive2.1.0
- 1.4.8.12、mask_first_n->Hive2.1.0
- 1.4.8.13、mask_last_n —>Hive2.1.0
- 1.4.8.14、mask_show_first_n—>Hive2.1.0
- 1.4.8.15、maskshow__last_n —>Hive2.1.0
- 1.4.8.16、mask_hash —>Hive2.1.0
- 1.4.9、杂项函数
- 1.4.9.1、java_method—>Hive0.9.0
- 1.4.9.2、reflect —> Hive0.7.0
- 1.4.9.3、hash —> Hive0.4
- 1.4.9.4、current_user —> Hive1.2.0
- 1.4.9.5、logged_in_user —> Hive2.2.0
- 1.4.9.6、current_database —>Hive0.13.0
- 1.4.9.7、md5 —>Hive1.3.0
- 1.4.9.8、sha1 —> Hive1.3.0
- 1.4.9.9、crc32 —> Hive1.3.0
- 1.4.9.10、sha2—>Hive1.3.0
- 1.4.9.11、aes_encrypt —> Hive1.3.0
- 1.4.9.12、version —> Hive2.1.0
- 1.4.9.13、surrogate_key
- 1.4.10、内置UDAF函数
- 1.4.10.1、count
- 1.4.10.2、sum
- 1.4.10.3、avg
- 1.4.10.4、min
- 1.4.10.5、max
- 1.4.10.6、variance
- 1.4.10.7、var_sample
- 1.4.10.8、stddev_pop
- 1.4.10.9、covar_pop
- 1.4.10.10、covar_samp
- 1.4.10.11、corr
- 1.4.10.12、percentile
- 1.4.10.13、percentile_approx
- 1.4.10.14、regr_avgx —>Hive2.2.0
- 1.4.10.15、regr_avgy —>Hive2.2.0
- 1.4.10.16、regr_count —>Hive2.2.0
- 1.4.10.17、regr_intercept —>Hive2.2.0
- 1.4.10.18、regr_r2 —>Hive2.2.0
- 1.4.10.19、regr_slope —>Hive2.2.0
- 1.4.10.20、regr_sxx —>Hive2.2.0
- 1.4.10.21、regr_sxy —>Hive2.2.0
- 1.4.10.22、regr_syy —>Hive2.2.0
- 1.4.10.23、histogram_numeric
- 1.4.10.24、collect_set
- 1.4.10.25、collect_list —> Hive0.13.0
- 1.4.10.26、ntile —> Hive0.11.0
- 1.4.11、内置UDTF函数
- 1.4.11.1、explode
- 1.4.11.2、posexplode
- 1.4.11.3、parse_url_tuple
- 1.4.11.5、inline
- 1.4.11.6、stack
- 1.4.11.7、json_tuple
- 1.4.12、三者区别
- 1.4.12.1、UDF
- 1.4.12.2、UDF编写
- 1.4.12.3、UDAF
- 1.4.12.4、UDAF编写
- 1.4.12.5、UDTF
- 1.4.12.6、UDTF编写

一、Hive
该文涉及到的所有软件包均已上传云盘,自行下载
链接:https://pan.baidu.com/s/1_fg4p-_Ch5_WAmcPbBqAvg
提取码:hi68
1.0.1、环境准备
1.0.1.0、maven安装
1.0.1.0.1、下载软件包
1.0.1.0.2、配置环境变量

1.0.1.0.3、调整maven仓库
打开$MAVEN_HOME/conf/settings.xml文件,调整maven仓库地址以及镜像地址
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0https://maven.apache.org/xsd/settings-1.0.0.xsd"><localRepository>你自己的路径</localRepository><mirrors><mirror><id>alimaven</id><name>aliyun maven</name><url>http://maven.aliyun.com/nexus/content/groups/public/</url><mirrorOf>central</mirrorOf></mirror></mirrors></settings>
1.0.1.1、cywin安装
该软件安装主要是为了支持windows编译源码涉及到的基础环境包
1.0.1.1.1、下载软件包
1.0.1.1.2、安装相关编译包
需要安装cywin,gcc+相关的编译包
binutilsgccgcc-mingwgdb
1.0.1.2、源码包下载
https://downloads.apache.org/hive/hive-2.3.9/
1.0.1.3、JDK安装
1.0.1.3.1、下载软件包
1.0.1.3.2、配置环境变量
1.0.1.3.2.1、创建JAVA_HOME系统变量

1.0.1.3.2.2、创建CLASSPATH系统变量

1.0.1.3.2.3、追加到Path变量中

1.0.1.4、Hadoop安装
1.0.1.4.1、下载软件包
1.0.1.4.2、配置环境变量
创建HADOOP_HOME系统变量,然后将该变量追加到Path全局变量中

1.0.1.4.3、编辑配置文件
注意:下载的软件包中可能不包含下列的文件,但提供了template文件,直接重命名即可。由于该篇是属于学习自用,所以只需要配置基础核心信息即可。下列文件位于$HADOOP_HOME/etc/hadoop目录下。
1.0.1.4.3.1、修改core-site.xml文件
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration>
1.0.1.4.3.2、修改yarn-site.xml文件
<configuration><!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property></configuration>
1.0.1.4.3.3、修改mapred-site.xml文件
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
1.0.1.4.4、初始化启动
首先初始化namenode,打开cmd执行下面的命令
$HADOOP_HOME/bin> hadoop namenode -format
当初始化完成后,启动hadoop
$HADOOP_HOME/sbin> start-all.cmd

当以下进程都启动成功后,hadoop基本环境也算是搭建成功了!
1.0.1.5、Mysql安装
1.0.1.5.1、软件包下载解压缩
官网或者直接从百度云盘中下载即可。
https://dev.mysql.com/downloads/mysql/
1.0.1.5.2、环境变量配置
1.0.1.5.2.1、创建系统环境变量MYSQL_HOME

1.0.1.5.2.2、将系统环境变量配置到Path上

1.0.1.5.2.3、生成Data文件
使用系统管理员打开CMD窗口
--执行下面命令mysqld --initialize-insecure --user=mysql
1.0.1.5.2.4、安装MYSQL并启动服务
--执行命令mysqld -install--启动服务net start MySQL
1.0.1.5.2.5、登录Mysql并修改密码
--初始登录时不需要密码,直接回车即可mysql -u root -p--修改root默认密码ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '123456';--刷新提交flush privileges;
1.0.1.6、Hive安装
如果你想要深入学习Hive底层,那么源码编译是必不可少的,所以本篇将采用源码包编译安装的方式。
1.0.1.6.1、下载软件包并解压缩
1.0.1.6.2、编译
mvn clean package -Phadoop-2 -DskipTests -Pdist

注意:在编译的过程中遇到问题的可能性非常大,大部分是因为maven,可能是网络问题,也可能跟你的镜像配置也有关系。另外对于一些模块编译过程中出现Could not transfer artifact XXXX的问题,可以先把pom文件中的scope设置注释掉!
1.0.1.6.3、安装
编译完成后,可以在$HIVE_SRC_HOME/packaging/target目录下找到对应的可执行的压缩包
1.0.1.6.3.1、配置环境变量
创建HIVE_HOME系统变量,然后将该变量追加引用到Path变量中

1.0.1.6.3.2、编辑配置文件
1.0.1.6.3.2.1、编辑hive-env.sh文件
# 配置环境信息# Set HADOOP_HOME to point to a specific hadoop install directoryexport HADOOP_HOME=D:\GitCode\hadoop-2.7.2# Hive Configuration Directory can be controlled by:export HIVE_CONF_DIR=D:\GitCode\apache-hive-2.3.9-bin\conf# Folder containing extra libraries required for hive compilation/execution can be controlled by:export HIVE_AUX_JARS_PATH=D:\GitCode\apache-hive-2.3.9-bin\lib
1.0.1.6.3.2.2、编辑hive-site.xml文件
该文件中的参数稍微有些多,不过我们只改动基础的部分即可。
<property><name>hive.repl.rootdir</name><value>D:\GitCode\apache-hive-2.3.9-bin\tmp_local</value></property><property><name>hive.repl.cmrootdir</name><value>D:\GitCode\apache-hive-2.3.9-bin\tmp_local</value></property><property><name>hive.exec.local.scratchdir</name><value>D:\GitCode\apache-hive-2.3.9-bin\tmp_local</value></property><property><name>hive.downloaded.resources.dir</name><value>D:\GitCode\apache-hive-2.3.9-bin\tmp_local\${hive.session.id}_resources</value></property><property><name>hive.querylog.location</name><value>D:\GitCode\apache-hive-2.3.9-bin\tmp_local</value></property><property><name>hive.server2.logging.operation.log.location</name><value>D:\GitCode\apache-hive-2.3.9-bin\tmp_local</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>hive.metastore.schema.verification</name><value>false</value></property>
1.0.1.6.3.2.3、log文件重命名
将conf文件中的几个Log文件后缀带有template移除即可
1.0.1.6.3.3、驱动包加载
本文使用mysql作为元数据存储,因此需要将JDBC的驱动包放到$HIVE_HOME/lib目录下
1.0.1.6.3.4、元数据初始化
在windows环境下,$HIVE_HOME/bin目录下并未找到cmd结尾的可执行文件,因此为了调通基础环境,可以从低版本中进行拷贝。本文涉及到的脚本和软件包都打包上传到云盘中
# 打开cmd命令行$HIVE_HOME/bin> hive schematool -dbType mysql -initSchema --verbose
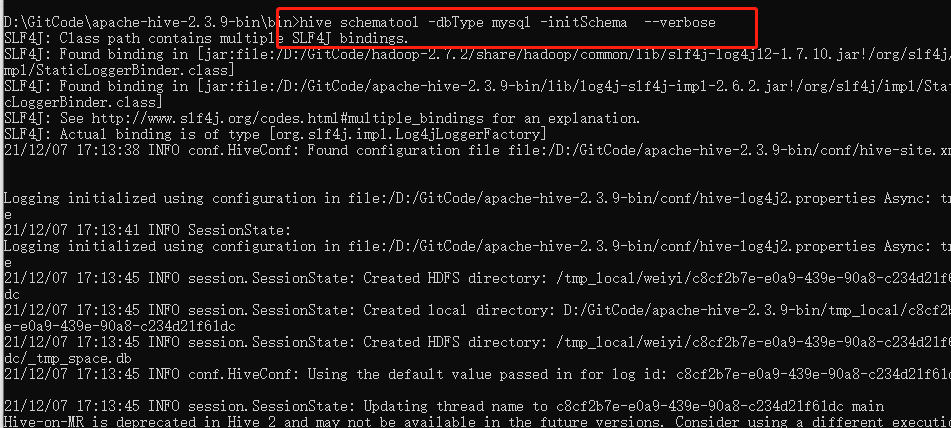
注意:在初始化过程中,可能会有表无法创建的问题,这里手动创建即可。或者直接source sql文件。本篇文章使用的是hive-shceam-2.3.0.mysql.sql
SQL文件位置于HIVE_HOME/scripts/metastore/upgrade/mysql下:

1.0.2、服务启动
在搭建Hadoop的环节中,已经将Hadoop服务启动了,这里将Hive Metastore服务启动
hive --service metastore
1.0.2.1、服务端启动Debug模式
为了方便学习,大家可以在IDEA中打开Terminal,开启debug模式和metastore服务启动。
hive --debug
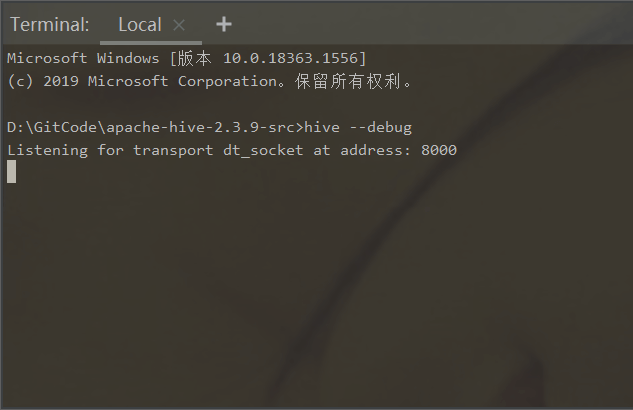
1.0.2.2、客户端断点模式
1.0.2.2.1、配置remote debug

1.0.2.2.2、断点
由于是在客户端进行源码追溯,所以一般会进入CliDriver类中,比如在main方法中打上断点,然后开始Debug


到这里,整个调试功能就已经实现了,大家可以在本地编写HSQL,然后根据断点深入学习Hive底层具体的执行流程,甚至自己改造源码!
1.1、流程剖析
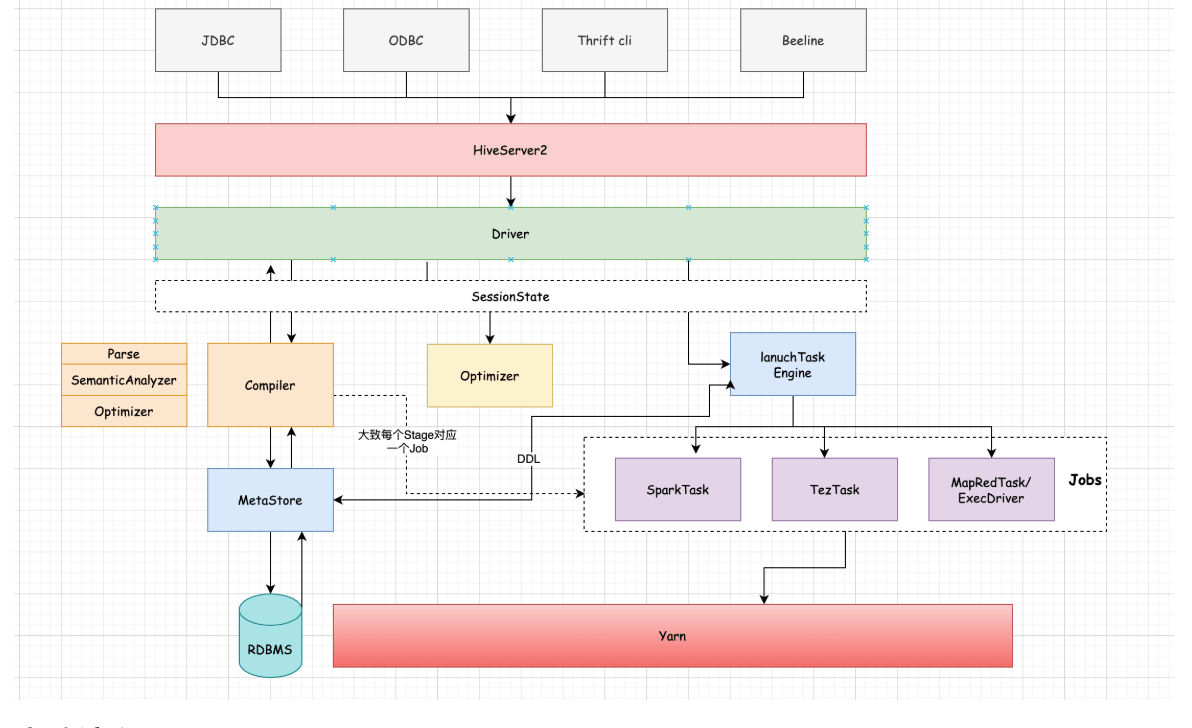
大致流程:
1、客户端连接到HS2(HiveServer2,目前大多数通过beeline形式连接,Hive Cli模式相对较重,且直接略过授权访问元数据),建立会话
2、提交sql,通过Driver进行编译、解析、优化逻辑计划,生成物理计划
3、对物理计划进行优化,并提交到执行引擎进行计算
4、返回结果
细节流程:
1、客户端和HiveServer2建立连接,创建会话
2、提交查询或者DDL,转交到Driver进行处理
3、Driver内部会通过Parser对语句进行解析,校验语法是否正确
4、然后通过Compiler编译器对语句进行编译,生成AST Tree
5、SemanticAnalyzer会遍历AST Tree,进一步进行语义分析,这个时候会和Hive MetaStore进行通信获取Schema信息,抽象成QueryBlock,逻辑计划生成器会遍历QueryBlock,翻译成Operator(计算抽象出来的算子)生成OperatorTree,这个时候是未优化的逻辑计划
6、Optimizer会对逻辑计划进行优化,如进行谓词下推、常量值替换、列裁剪等操作,得到优化后的逻辑计划。
7、SemanticAnalyzer会对逻辑计划进行处理,通过TaskCompiler生成物理执行计划TaskTree。
8、TaskCompiler会对物理计划进行优化,然后根据底层不同的引擎进行提交执行。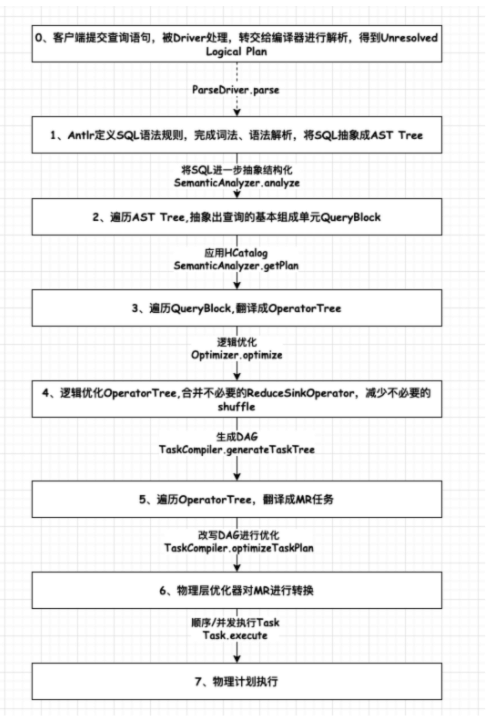
1.1.1、Analyze Sql
语法:
EXPLAIN [EXTENDED|CBO|AST|DEPENDENCY|AUTHORIZATION|LOCKS|VECTORIZATION|ANALYZE] query
版本支持:
Hive0.14.0支持AUTHORIZATION;[HIVE-5961]
Hive2.3.0支持VECTORIZATION;[HIVE-11394]
Hive3.2.0支持LOCKS;[HIVE-17683]
Explain结果总共分为三个部分:
1、对应查询的抽象语法树 AST
2、每个计划阶段Stage之间的依赖关系
3、每个计划阶段的描述(可能是map/reduce,也可能是操作元数据或者文件操作)
聚合操作分析示例:
EXPLAIN FROM src INSERT OVERWRITE TABLE dest_g1 SELECT src.key, sum(substr(src.value,4)) GROUP BY src.key;
聚合操作分析输出信息:
STAGE DEPENDENCIES: --每个Stage之间的依赖关系Stage-1 is a root stage --Stage1是根阶段Stage-2 depends on stages: Stage-1 --当Stage1执行完成后才会执行Stage2Stage-0 depends on stages: Stage-2 --当Stage2执行完成后才会执行Stage0STAGE PLANS: --具体Stage信息Stage: Stage-1Map Reduce --MapReduce阶段Alias -> Map Operator Tree: --map阶段从一个特定表或者上一个map/reduce阶段结果中读取src --表名Reduce Output Operatorkey expressions:expr: keytype: stringsort order: +Map-reduce partition columns:expr: rand()type: doubletag: -1value expressions:expr: substr(value, 4)type: stringReduce Operator Tree: --执行部分聚合Group By Operatoraggregations:expr: sum(UDFToDouble(VALUE.0))keys:expr: KEY.0type: stringmode: partial1File Output Operatorcompressed: falsetable:input format: org.apache.hadoop.mapred.SequenceFileInputFormatoutput format: org.apache.hadoop.mapred.SequenceFileOutputFormatname: binary_tableStage: Stage-2Map Reduce --MapReduce阶段Alias -> Map Operator Tree:/tmp/hive-zshao/67494501/106593589.10001Reduce Output Operatorkey expressions:expr: 0type: stringsort order: + --列排序;+表示升序;-表示降序;一个+代表对一个列进行排序操作,如sort order:++ :代表按照两个列升序序排列Map-reduce partition columns:expr: 0type: stringtag: -1value expressions:expr: 1type: doubleReduce Operator Tree: --从Stage1中的部分聚合计算进行再次聚合Group By Operator --分组操作aggregations: --聚合函数信息expr: sum(VALUE.0)keys: --分组字段expr: KEY.0type: stringmode: final --聚合模式:hash:随机聚合,final:最终聚合Select Operatorexpressions:expr: 0type: stringexpr: 1type: doubleSelect Operator --选取操作expressions: --需要的字段名和类型expr: UDFToInteger(0)type: intexpr: 1type: doubleFile Output Operator --过滤操作compressed: falsetable:input format: org.apache.hadoop.mapred.TextInputFormatoutput format: org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormatserde: org.apache.hadoop.hive.serde2.dynamic_type.DynamicSerDename: dest_g1Stage: Stage-0Move Operator --文件操作,将从临时目录移动到结果目录下tables:replace: truetable:input format: org.apache.hadoop.mapred.TextInputFormatoutput format: org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormatserde: org.apache.hadoop.hive.serde2.dynamic_type.DynamicSerDename: dest_g1
依赖分析示例:
EXPLAIN DEPENDENCY SELECT key, count(1) FROM srcpart WHERE ds IS NOT NULL GROUP BY key
依赖分析结果:
{"input_partitions":[{"partitionName":"default<at:var at:name="srcpart" />ds=2008-04-08/hr=11"},{"partitionName":"default<at:var at:name="srcpart" />ds=2008-04-08/hr=12"},{"partitionName":"default<at:var at:name="srcpart" />ds=2008-04-09/hr=11"},{"partitionName":"default<at:var at:name="srcpart" />ds=2008-04-09/hr=12"}],"input_tables":[{"tablename":"default@srcpart","tabletype":"MANAGED_TABLE"}]}
分析实际数据量示例:
explain analyze select t1.user_id,t2.visit_url from wedw_tmp.tmp_url_info t1 full join wedw_tmp.tmp_url_info t2 on t1.user_id = t2.user_id;
分析实际数量结果:
STAGE DEPENDENCIES:Stage-1 is a root stageStage-0 depends on stages: Stage-1STAGE PLANS:Stage: Stage-1Map ReduceMap Operator Tree:TableScanalias: t1Statistics: Num rows: 9/9 Data size: 1041 Basic stats: COMPLETE Column stats: NONESelect Operatorexpressions: user_id (type: string)outputColumnNames: _col0Statistics: Num rows: 9/9 Data size: 1041 Basic stats: COMPLETE Column stats: NONEReduce Output Operatorkey expressions: _col0 (type: string)sort order: +Map-reduce partition columns: _col0 (type: string)Statistics: Num rows: 9/9 Data size: 1041 Basic stats: COMPLETE Column stats: NONETableScanalias: t2Statistics: Num rows: 9/9 Data size: 1041 Basic stats: COMPLETE Column stats: NONESelect Operatorexpressions: user_id (type: string), visit_url (type: string)outputColumnNames: _col0, _col1Statistics: Num rows: 9/9 Data size: 1041 Basic stats: COMPLETE Column stats: NONEReduce Output Operatorkey expressions: _col0 (type: string)sort order: +Map-reduce partition columns: _col0 (type: string)Statistics: Num rows: 9/9 Data size: 1041 Basic stats: COMPLETE Column stats: NONEvalue expressions: _col1 (type: string)Reduce Operator Tree:Join Operatorcondition map:Outer Join 0 to 1keys:0 _col0 (type: string)1 _col0 (type: string)outputColumnNames: _col0, _col2Statistics: Num rows: 9/41 Data size: 1145 Basic stats: COMPLETE Column stats: NONESelect Operatorexpressions: _col0 (type: string), _col2 (type: string)outputColumnNames: _col0, _col1Statistics: Num rows: 9/41 Data size: 1145 Basic stats: COMPLETE Column stats: NONEFile Output Operatorcompressed: falseStatistics: Num rows: 9/41 Data size: 1145 Basic stats: COMPLETE Column stats: NONEtable:input format: org.apache.hadoop.mapred.SequenceFileInputFormatoutput format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormatserde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDeStage: Stage-0Fetch Operatorlimit: -1Processor Tree:ListSink
1.1.2、Stage division(不够细致,需要例子)
Stage理解:
结合对前面讲到的Hive对查询的一系列执行流程的理解,那么在一个查询任务中会有一个或者多个Stage.每个Stage之间可能存在依赖关系。没有依赖关系的Stage可以并行执行。
Stage是Hive执行任务中的某一个阶段,那么这个阶段可能是一个MR任务,也可能是一个抽取任务,也可能是一个Map Reduce Local ,也可能是一个Limit。
何时划分Stage:
那么Stage划分的时机其实是发生在逻辑计划转化OperatorTree转化成物理计划的阶段TaskTree,按照深度优先遍历OperatorTree,再结合具体执行引擎的Compiler(MR/Tez/Spark)应用规则生成对应的Task。
Stage划分的界限决定于ReduceSinkOperator,在遇到ReduceSinkOperator之前的Operator都划分到Map阶段,同时也标识这Map阶段的结束。该ReduceSinkOperator到下一个ReduceSinkOperator阶段中间的部分划分为Reduce阶段。一个MR任务代表一个Stage(当然也包括其他非MR,如FetchTask、MoveTask、CopyTask)。
划分规则(按照MR为例子):
R1: TS% ——>生成MapRedTask对象,确定MapWork
R2:TS%.RS —->遇到第一个ReduceSinkOperator,划分Map阶段,确定ReduceWork
R3:RS%.RS% ——>生成新的MapRedTask,切分MapRedTask。这个时候已经生成一个Job
R4:FS% ——> 连接MapRedTask和MoveTask。
R5:UNION% ——>如果所有的子查询都是map-only,则把所有的MapWork进行合并连接。
R6:UNION%.RS% —->遇到ReduceSinkOpeartor,则合并Stage,
R7:MAPJOIN%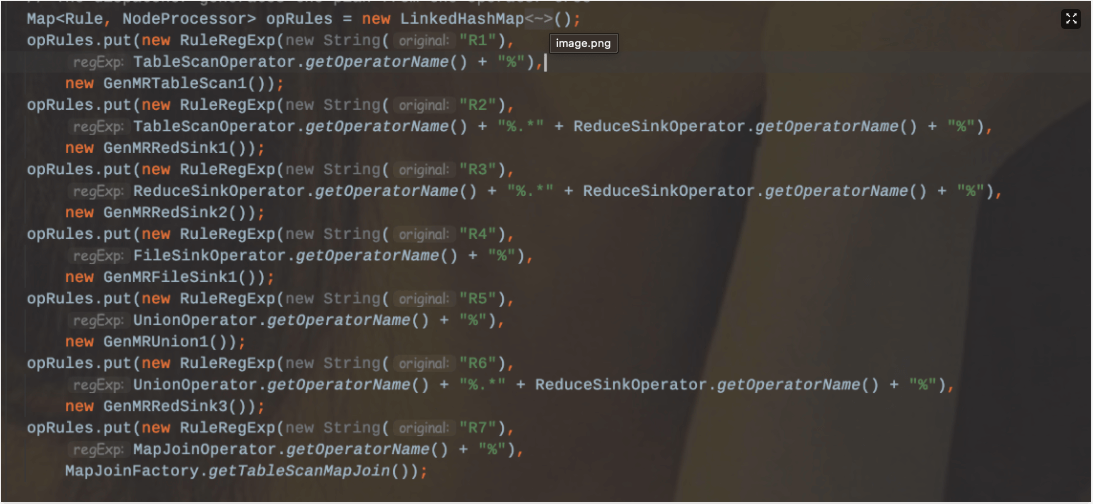
*demo
insert ovewrite table testselectdistinct urlfrom tmp.testwhere date_id='2021-06-08' and length(url)>0 and url is not nulldistribute by rand()limit 10000
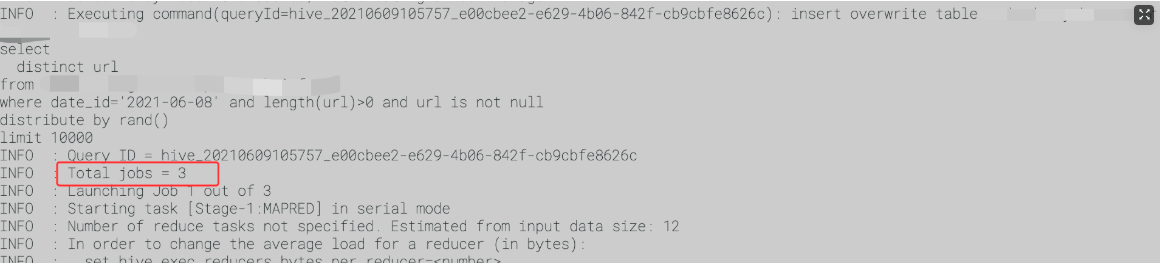
第一个Job发生的Map阶段: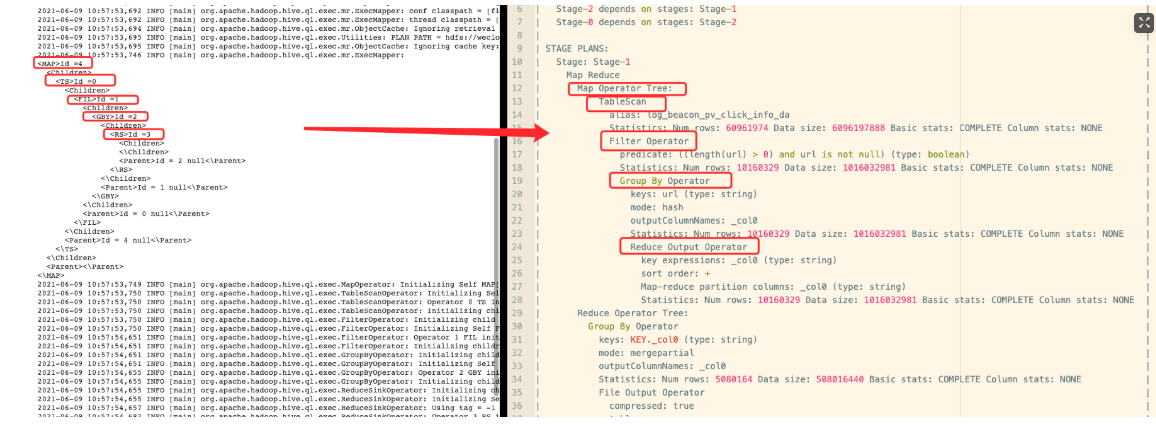
第一个Job发生的Reduce阶段: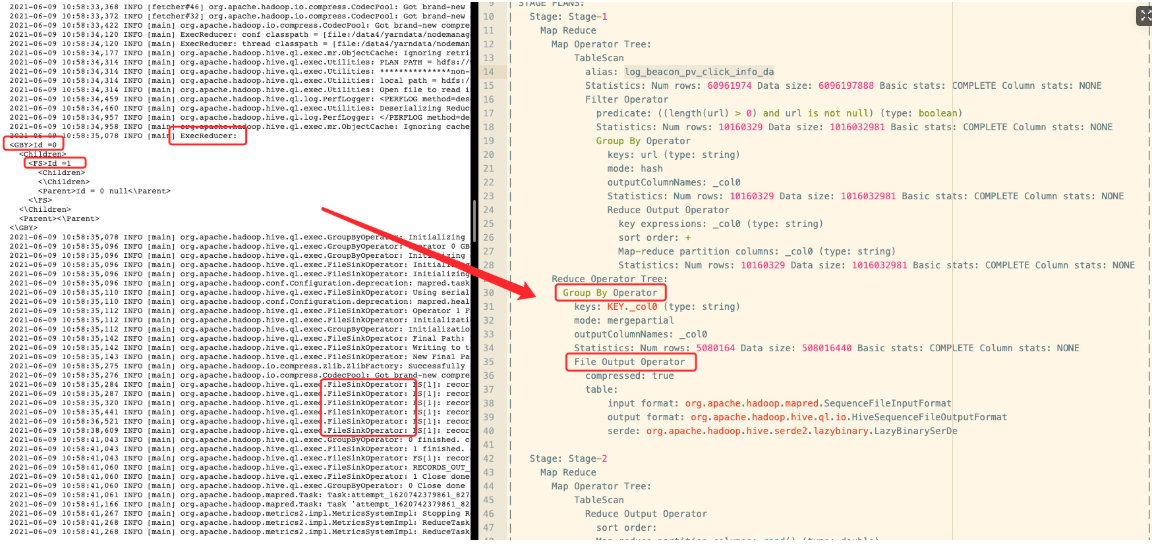
第二个Job发生的Map阶段
第二个Job发生的Reduce阶段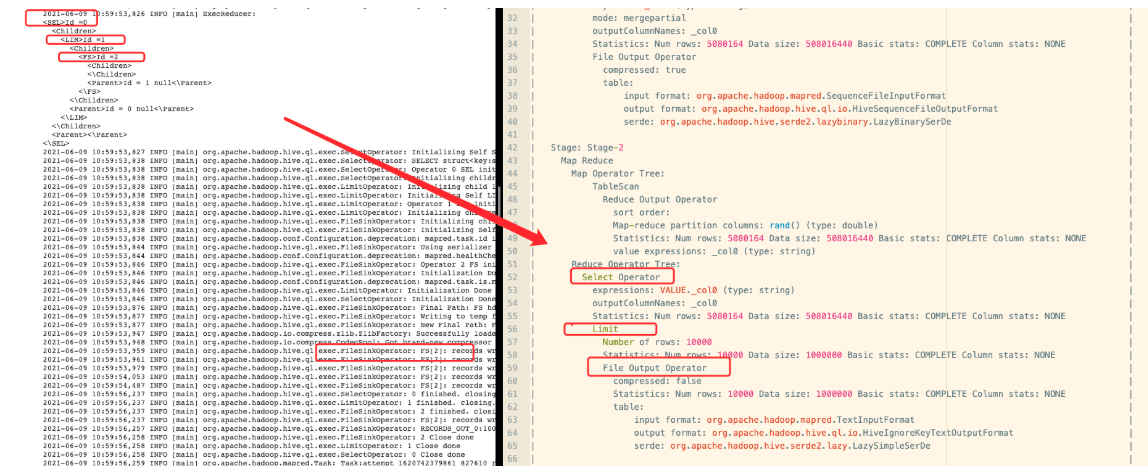
第三个Job发生的Map阶段
第三个Job发生的Reduce阶段
从sql查看具体的生成的job
create table wedw_tmp.test asselectt1.user_id,count(1)from test1 t1left join test1 t2on t1.user_id = t2.user_idwhere t1.date_id='2021-06-08' and t2.date_id='2021-06-08' and t1.user_id='12313' and t2.user_id='12313'group by t1.user_iddistribute by rand()limit 10000

1.1.3、Statistics Job
从OperatorTree生成Job的过程:
1、对输出表生成MoveTask
2、从OperatorTree中的一个根节点向下深度优先遍历
3、ReduceSinkOperator标识Map/Reduce界限,多个Job间的界限
4、遍历其他根节点,遇到JoinOpeartor合并MapReduceTask
5、生成StatTask更新元数据
6、剪断Map和Reduce之间的Operator关系
代码层面:
Utilities.getMRTasks(plan.getRootTasks()).size()+ Utilities.getTezTasks(plan.getRootTasks()).size()+ Utilities.getSparkTasks(plan.getRootTasks()).size();
计算生成MR Job的逻辑:
从执行计划根节点任务开始遍历,当该task属于ExecDriver实例,那么Job数+1
计算TezTask生成的Job数逻辑:
也是从执行计划根节点开始遍历,如果该task属于TezTask,那么Job数+1
计算Spark Job数的逻辑:
也是从执行计划根节点开始遍历,如果该task属于SparkTask,那么Job数+1
分析层面:
从explain可以看出一个sql语句会被划分多少个Stage,其实Stage总数就是Job数。但是有些Stage并不是MR或者Spark/Tez任务。所以要根据Operator类型来确定大概有多少个Job.
1.1.4、Only Map?
总结:即只要不发生shuffle,只是做简单的处理,如简单查或者文件移动/删除就会只有map阶段。
1、Creaet table As Select field from table [where condition]
2、select field from table [where condition] —需要设置hive.fetch.task.conversion=none
3、insert into/overwrite targettable select * from table [where condition]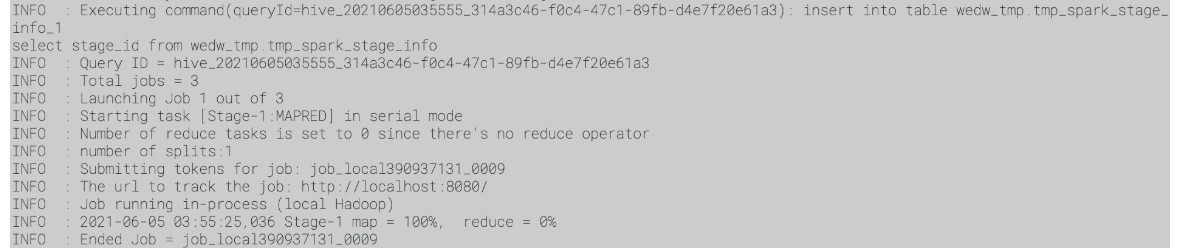
4、select /+MAPJOIN(…)_/ ….
5、使用transform,只调用map script;
具体使用可参考:https://github.com/rgordon/hive-transform-example
cat>/tmp/myscript.shsed -r -e 's/\{(.*)\}/\1/' -e 's/"//g' -e 's/v(.)/v\100/g'create table d (item map<string,string>);create table s (item map<string,string>);insert into s select map('k1','v1','k2','v2','k3','v3');add file /tmp/myscript.sh;selectstr_to_map (result)from(selecttransform (item) using "myscript.sh" as resultfrom s) t

1.1.5、Only Reduce?
常规上思考MapReduce任务肯定是要有map阶段的,reduce阶段输入数据是通过map端输出数据拿来的。所以MapReduce不可能存在只有reduce的场景。
同样在hive的源码中也可以发现,ExecDriver在配置Job的时候是绑定了ExecMapper和ExecReducer,那么底层引擎是依赖于MapReduce的。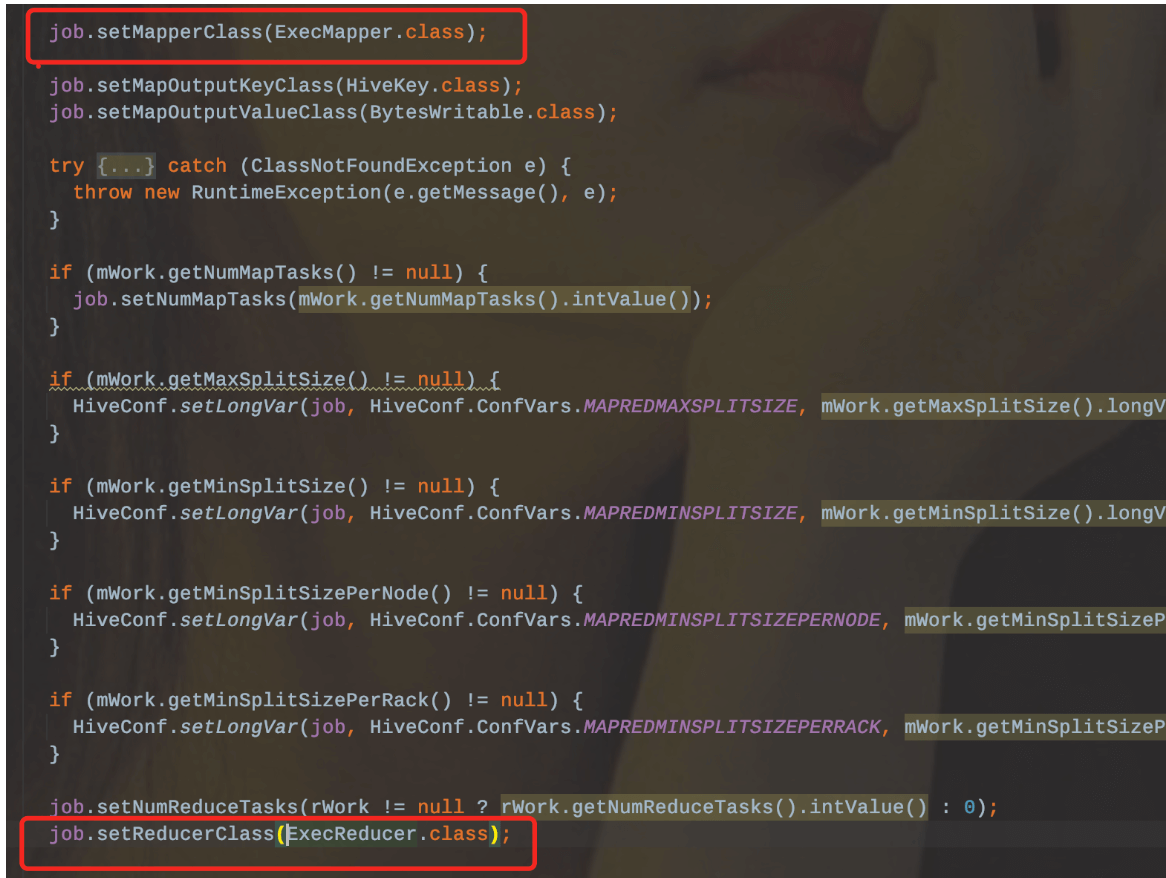
这么看来Hive也是不可能支持的。
但是在Hive的源码中存在另外一个MR框架。是hive自己实现的。
该框架内的MapReduce和hadoop底层的MR组件不一样,hive自身的MR框架,Map和Reduce是独立开的,每个阶段都是直接使用输入输出流,两者之间并没有依赖关系。
所以hive自身框架内的MR是可以支持只有reduce阶段的。可以使用transform函数来实现。
FROM (FROM srcMAP value, keyUSING 'java -cp hive-contrib-${system:hive.version}.jar org.apache.hadoop.hive.contrib.mr.example.IdentityMapper'AS k, vCLUSTER BY k) map_outputREDUCE k, vUSING 'java -cp hive-contrib-${system:hive.version}.jar org.apache.hadoop.hive.contrib.mr.example.WordCountReduce'AS k, v;

1.2、Filter PushDown Cases And Outer Join Behavior
前提:关闭优化器
set hive.auto.convert.join=false;set hive.cbo.enable=false;
Inner Join:
1、Join On中的谓词: 左表下推、右表下推
2、Where谓词:左表下推、右表下推
-- 第一种情况:join on 谓词selectt1.user_id,t2.user_idfrom wedw_tmp.tmp_test_1 t1join wedw_tmp.tmp_test_2 t2on t1.user_id = t2.user_id and t1.user_id='111' and t2.user_id='222'--第二种情况:where谓词selectt1.user_id,t2.user_idfrom wedw_tmp.tmp_test_1 t1join wedw_tmp.tmp_test_2 t2on t1.user_id = t2.user_idwhere t1.user_id='111' and t2.user_id='222'

Left join:
1、Join On中的谓词: 左表不下推、右表下推(前提:关闭mapjoin优化)
2、Where谓词:左表下推、右表下推
-- 第一种情况:join on 谓词selectt1.user_id,t2.user_idfrom wedw_tmp.tmp_test_1 t1left join wedw_tmp.tmp_test_2 t2on t1.user_id = t2.user_id and t1.user_id='111' and t2.user_id='222'--第二种情况:where谓词selectt1.user_id,t2.user_idfrom wedw_tmp.tmp_test_1 t1left join wedw_tmp.tmp_test_2 t2on t1.user_id = t2.user_idwhere t1.user_id='111' and t2.user_id='222'

Right Join:
1、Join On中的谓词: 左表下推、右表不下推(前提:关闭mapjoin优化)
2、Where谓词:左表下推、右表下
-- 第一种情况:join on 谓词selectt1.user_id,t2.user_idfrom wedw_tmp.tmp_test_1 t1right join wedw_tmp.tmp_test_2 t2on t1.user_id = t2.user_id and t1.user_id='111' and t2.user_id='222'--第二种情况:where谓词selectt1.user_id,t2.user_idfrom wedw_tmp.tmp_test_1 t1right join wedw_tmp.tmp_test_2 t2on t1.user_id = t2.user_idwhere t1.user_id='111' and t2.user_id='222'
Full Join:
1、Join On中的谓词: 左表不下推、右表不下推(前提:关闭mapjoin优化)
2、Where谓词:左表不下推、右表不下推
-- 第一种情况:join on 谓词selectt1.user_id,t2.user_idfrom wedw_tmp.tmp_test_1 t1full join wedw_tmp.tmp_test_2 t2on t1.user_id = t2.user_id and t1.user_id='111' and t2.user_id='222'--第二种情况:where谓词selectt1.user_id,t2.user_idfrom wedw_tmp.tmp_test_1 t1full join wedw_tmp.tmp_test_2 t2on t1.user_id = t2.user_idwhere t1.user_id='111' and t2.user_id='222'


1.3、Function Cases
1.3.1、窗口函数
row_number:使用频率 ★★★★★
rank :使用频率 ★★★★
dense_rank:使用频率 ★★★★
rank/dense_rank/row_number对比
first_value:使用频率 ★★★
last_value:使用频率 ★
lead:使用频率 ★★
lag:使用频率 ★★
1.3.2、集合相关
collect_set:使用频率 ★★★★★
collect_list:使用频率 ★★★★★
sort_array:使用频率 ★★★
1.3.3、URL相关
parse_url:使用频率 ★★★★
reflect:使用频率 ★★
1.3.4、JSON相关
1.3.5、列转行相关
1.3.6、Cube相关
1.3.7、字符相关
concat:使用频率 ★★★★★
concat_ws:使用频率 ★★★★★
instr:使用频率 ★★★★
length:使用频率 ★★★★★
size:使用频率 ★★★★★
trim:使用频率 ★★★★★
regexp_replace:使用频率 ★★★★★
regexp_extract:使用频率 ★★★★
substring_index:使用频率 ★★
1.3.8、条件判断
if:使用频率 ★★★★★
case when :使用频率 ★★★★★
coalesce:使用频率 ★★★★★
1.3.9、数值相关
round:使用频率 ★★
ceil:使用频率 ★★★
floor:使用频率 ★★★
hex:使用频率 ★
1.3.10、时间相关(比较简单)
from_unxitime:使用频率 ★★★★★
unix_timestamp:使用频率 ★★★★★
to_date:使用频率 ★★★★★
year:使用频率 ★★★★★
month:使用频率 ★★★★★
day:使用频率 ★★★★★
date_add:使用频率 ★★★★★
date_sub:使用频率 ★★★★★
1.4、UDF/UDTF/UDAF
UDF:用户自定义函数
主要功能:一对一输入输出,如substr,date_add,instr,size等。
public final class Lower extends UDF {public Text evaluate(final Text s) {if (s == null) { return null; }return new Text(s.toString().toLowerCase());}}
UDTF:拆解函数
主要功能:一对多输入输出,如explode,array,json_tuple等
限制(可以使用lateral view 替代):
1、Select语句中不允许使用其他的表达式
2、不能嵌套,如explode(explode(adid_list))
3、不支持GROUP BY / CLUSTER BY / DISTRIBUTE BY / SORT BY
自定义:
public class GenericUDTFCount2 extends GenericUDTF {Integer count = Integer.valueOf(0);Object forwardObj[] = new Object[1];@Overridepublic void close() throws HiveException {forwardObj[0] = count;forward(forwardObj);forward(forwardObj);}@Overridepublic StructObjectInspector initialize(ObjectInspector[] argOIs) throws UDFArgumentException {ArrayList<String> fieldNames = new ArrayList<String>();ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();fieldNames.add("col1");fieldOIs.add(PrimitiveObjectInspectorFactory.javaIntObjectInspector);return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,fieldOIs);}@Overridepublic void process(Object[] args) throws HiveException {count = Integer.valueOf(count.intValue() + 1);}}
UDAF:聚合函数
主要功能:sum,avg,min,max,collect_set
自定义函数:参考org.apache.hadoop.hive.ql.udf.generic.GenericUDAFMax
源码测试用例: ql/src/test/queries/clientpositive
1.4.1、函数帮助
注意:Hive中所有的关键词都是忽略大小写的。无论是通过Beeline还是CLI模式,都可以通过以下命令来查看Hive 函数
-- 查看所有的函数show functions;---查看具体某个函数的帮助手册desc function function_name;--查看函数示例功能desc function extended function_name;


注意点:当hive.cache.expr.evaluation参数设置为true的时候(当然默认值就是true),在0.12.0、0.13.0和0.13.1版本中,使用UDF嵌套到其他UDF函数中可能会有问题。具体可以见HIVE-7314
1.4.2、数学函数
1.4.2.1、abs
作用:返回绝对值
select abs(-1),abs(1);
1.4.2.2、acos—>从Hive0.13.0
作用:如果 -1<=a<=1 或 NULL,则返回 a 的反余弦值。
select acos(0.1),acos(-1),acos(1),acos(-0.6)
1.4.2.3、asin—>从Hive0.13.0
作用:如果 -1<=a<=1 或 NULL,则返回 a 的反正弦。
select asin(0.1),asin(-1),asin(1),asin(-0.6),asin(null);
1.4.2.4、atan—>从Hive0.13.0
select atan(1.1),atan(0.543535)
1.4.2.5、bin

1.4.2.6、bround—>Hive1.3.0
select bround(2.4),bround(2.5),bround(3.5),bround(3.6554),bround(8.324,2),bround(3.234,1);
1.4.2.7、cbrt—>Hive1.2.0

1.4.2.8、ceil
select ceil(2.234),ceil(2.65),ceil(3.343);
1.4.2.9、conv
select conv(234234,10,2),conv(234234,10,16);
1.4.2.10、cos—>Hive0.13.0
select cos(23.23),cos(60),cos(90),cos(180);
1.4.2.11、degress—>Hive0.13.0
select degrees(23.23432),degrees(23.66545);
1.4.2.12、e

1.4.2.13、exp—>Hive0.13.0
select exp(23.234),exp(23.354),exp(23.65),exp(2);
1.4.2.14、factorial—>Hive1.2.0
1.4.2.15、floor
select floor(2.34),floor(2.756),floor(3.54);
1.4.2.16、greatest—>Hive1.1.0
select greatest(1,2,34,45,234,342,42324);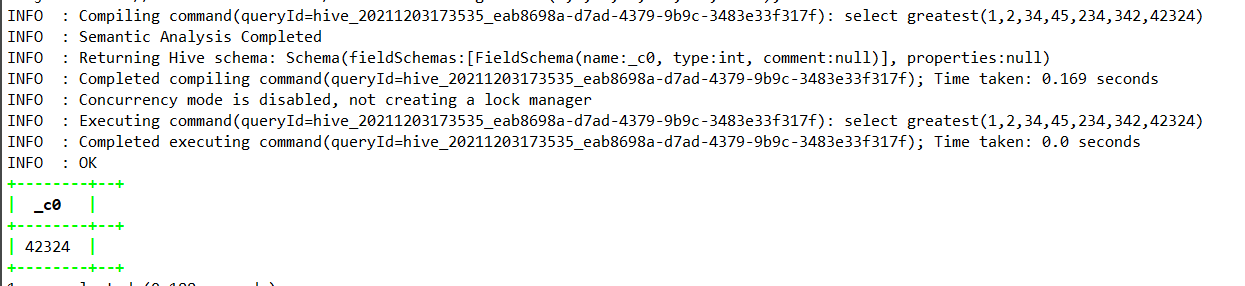
1.4.2.17、hex

1.4.2.18、least
select least(1,2,34,45,234,342,42324);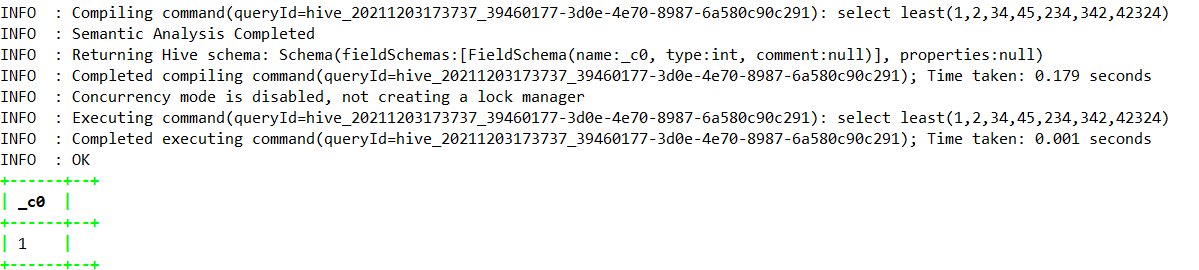
1.4.2.19、ln—>Hive0.13.0
select ln(10),ln(20),ln(0),ln(1);
1.4.2.20、log2—>Hive0.13.0
select log2(4),log2(6),log2(8);
1.4.2.21、log10—>Hive0.13.0
select log10(40),log10(60),log10(80),log10(100);
1.4.2.22、negative
select negative(1),negative(20.234),negative(-20);
1.4.2.23、pi

1.4.2.24、pmod
select pmod(10,2),pmod(10,3),pmod(10,4);
1.4.2.25、positive
select positive(20),positive(10.234353);
1.4.2.26、pow

1.4.2.27、radians—>Hive0.13.0
select radians(4),radians(180),radians(360);
1.4.2.28、rand
— 可以指定种子序列,这样可以保障每次的结果都一致
select rand(),rand(5),rand(10);
1.4.2.29、round
select round(3),round(3.2),round(3.43);
1.4.2.30、shiftleft—>Hive1.2.0
1.4.2.31、shiftright—>Hive1.2.0
1.4.2.32、shiftrightunsigned—>Hive1.2.0
1.4.2.33、sign—>Hive0.13.0
select sign(23.23),sign(23),sign(-10);
1.4.2.34、sin—>Hive0.13.0
select sin(60),sin(90),sin(180),sin(270),sin(360)
1.4.2.35、sqrt—>Hive0.13.0
select sqrt(3),sqrt(4),sqrt(10);
1.4.2.36、tan—>Hive0.13.0
select tan(30),tan(90),tan(180);
1.4.2.37、unhex—>Hive0.12.0

1.4.2.38、width_bucket—>Hive3.0.0
| 支持版本+ | 返回值类型 | 函数名称 | 功能描述 |
|---|---|---|---|
| DOUBLE | abs(DOUBLE a) | 返回绝对值 | |
| Hive0.13.0 | DOUBLE | acos(DOUBLE a), acos(DECIMAL a) | 如果 -1<=a<=1 或 NULL,则返回 a 的反余弦值。 |
| Hive0.13.0 | DOUBLE | asin(DOUBLE a), asin(DECIMAL a) | 如果 -1<=a<=1 或 NULL,则返回 a 的反正弦。 |
| Hive0.13.0 | DOUBLE | atan(DOUBLE a), atan(DECIMAL a) | 返回a的正切值。 |
| STRING | bin(BIGINT a) | 返回二进制格式的数字 | |
| Hive1.3.0 | DOUBLE | bround(DOUBLE a) | 使用HALF_EVEN四舍五入模式返回a的BIGINT值。例如:bround(2.5) = 2, bround(3.5) = 4. |
| Hive1.3.0 | DOUBLE | bround(DOUBLE a, INT d) | 使用HALF_EVEN四舍五入模式返回一个四舍五入到小数点后d位的数值。例如:bround(8.25, 1) = 8.2,bround(8.35, 1) = 8.4 |
| Hive1.2.0 | DOUBLE | cbrt(DOUBLE a) | 返回双精度值的立方根 |
| BIGINT | ceil(DOUBLE a), ceiling(DOUBLE a) | 返回等于或大于 a 的最小 BIGINT 值 | |
| STRING | conv(BIGINT num, INT from_base, INT to_base), conv(STRING num, INT from_base, INT to_base) | 将一个数字从一个给定的基数转换为另一个基数 | |
| Hive0.13.0 | DOUBLE | cos(DOUBLE a), cos(DECIMAL a) | 返回 a 的余弦(a 以弧度为单位) |
| Hive0.13.0 | DOUBLE | degrees(DOUBLE a), degrees(DECIMAL a) | 将 a 的值从弧度转换为度数 |
| DOUBLE | e() | 返回 e 的值。 | |
| Hive0.13.0 | DOUBLE | exp(DOUBLE a), exp(DECIMAL a) | 返回 ea,其中 e 是自然对数的底数 |
| Hive1.2.0 | BIGINT | factorial(INT a) | 返回a的阶乘 |
| BIGINT | floor(DOUBLE a) | 返回等于或小于 a 的最大 BIGINT 值。 | |
| Hive1.1.0 | T | greatest(T v1, T v2, …) | 返回值列表的最大值 |
| STRING | hex(BIGINT a) hex(STRING a) hex(BINARY a) | 如果参数是 INT 或二进制,则十六进制将数字作为十六进制格式的 STRING 返回。否则,如果数字是 STRING,它会将每个字符转换为其十六进制表示并返回结果 STRING。 | |
| T | least(T v1, T v2, …) | 返回值列表的最小值 | |
| Hive0.13.0 | DOUBLE | ln(DOUBLE a), ln(DECIMAL a) | 返回参数 a 的自然对数 |
| Hive0.13.0 | DOUBLE | log2(DOUBLE a), log2(DECIMAL a) | 返回参数 a 的以 2 为底的对数 |
| Hive0.13.0 | DOUBLE | log10(DOUBLE a), log10(DECIMAL a) | 返回参数 a 的以 10 为底的对数 |
| DOUBLE | log(DOUBLE base, DOUBLE a) log(DECIMAL base, DECIMAL a) |
返回参数 a 的底对数 | |
| INT or DOUBLE | negative(INT a), negative(DOUBLE a) | 返回-a。 | |
| DOUBLE | pi() | 返回π的值 | |
| INT or DOUBLE | pmod(INT a, INT b), pmod(DOUBLE a, DOUBLE b) | 返回 a mod b 的正值 | |
| INT or DOUBLE | positive(INT a), positive(DOUBLE a) | 返回a | |
| DOUBLE | pow(DOUBLE a, DOUBLE p), power(DOUBLE a, DOUBLE p) | 返回 ap 它返回 a值的 p 次幂 |
|
| Hive0.13.0 | DOUBLE | radians(DOUBLE a), radians(DOUBLE a) | 将 a 的值从度数转换为弧度 |
| DOUBLE | rand(), rand(INT seed) | 返回从 0 到 1 均匀分布的随机数(从行到行变化)。指定种子将确保生成的随机数序列是确定性的 | |
| DOUBLE | round(DOUBLE a) | 返回a的四舍五入的BIGINT值 | |
| DOUBLE | round(DOUBLE a, INT d) | 返回四舍五入到 d 位小数 | |
| Hive1.2.0 | INT BIGINT |
shiftleft(TINYINT|SMALLINT|INT a, INT b) shiftleft(BIGINT a, INT b) |
位数左移(从Hive 1.2.0开始)。将a b的位置向左移动。对于tinyint、smallint和int a,返回int;对于bigint a,返回bigint。 |
| Hive1.2.0 | INT BIGINT |
shiftright(TINYINT|SMALLINT|INT a, INT b) shiftright(BIGINT a, INT b) |
位数右移(从Hive 1.2.0开始)。将a b的位置向右移动。对于tinyint、smallint和int a,返回int;对于bigint a,返回bigint |
| Hive1.2.0 | INT BIGINT |
shiftrightunsigned(TINYINT|SMALLINT|INT a, INT b), shiftrightunsigned(BIGINT a, INT b) |
Bitwise无符号右移(从Hive 1.2.0开始)。将a b的位置向右移动。对于tinyint、smallint和int a,返回int;对于bigint a,返回bigint。 |
| Hive0.13.0 | DOUBLE or INT | sign(DOUBLE a), sign(DECIMAL a) | 将 a 的符号返回为“1.0”(如果 a 为正)或“-1.0”(如果 a 为负),否则返回“0.0”。十进制版本返回 INT 而不是 DOUBLE |
| Hive0.13.0 | DOUBLE | sin(DOUBLE a), sin(DECIMAL a) | 返回 a 的正弦值(a 以弧度为单位 |
| Hive0.13.0 | DOUBLE | sqrt(DOUBLE a), sqrt(DECIMAL a) | 返回 a 的平方根 |
| Hive0.13.0 | DOUBLE | tan(DOUBLE a), tan(DECIMAL a) | 返回a的正切值(a的单位是弧度) |
| Hive0.12.0 | BINARY | unhex(STRING a) | 十六进制的倒数。将每对字符解释为一个十六进制数并转换为该数的字节表示 |
| Hive3.0.0 | INT | width_bucket(NUMERIC expr, NUMERIC min_value, NUMERIC max_value, INT num_buckets) | 通过将 expr 映射到第 i 个相同大小的存储桶,返回 0 到 num_buckets+1 之间的整数。通过将 [min_value, max_value] 分成大小相等的区域来制作桶。如果expr < min_value,返回1,如果expr > max_value 返回num_buckets+1 |
1.4.3、集合函数
1.4.3.1、size
select map(‘a’,1,’b’,2),size(map(‘a’,1,’b’,2)),array(1,2,3,4),size(array(1,2,3,4));
1.4.3.2、map_keys
select map(‘a’,1,’b’,2), map_keys(map(‘a’,1,’b’,2));
1.4.3.3、map_values
select map(‘a’,1,’b’,2), map_values(map(‘a’,1,’b’,2));
1.4.3.4、array_contains
select array(1,2,3,4),array_contains(array(1,2,3,4),1),array_contains(array(1,2,3,4),5);
注意:该函数中判断参数的类型要和数组元素类型保持一致,否则会查询失败
select array(1,2,3,4),array_contains(array(1,2,3,4),1),array_contains(array(1,2,3,4),’a’);
1.4.3.5、sort_array—>0.9.0
select array(4,2,3,234,234,23454,23),sort_array(array(4,2,3,234,234,23454,23));
| 支持版本+ | 返回值类型 | 函数名称 | 功能描述 |
|---|---|---|---|
| int | size(Map |
返回map中的元素个数 | |
| int | size(Array |
返回array数组中的元素个数 | |
| array |
map_keys(Map |
返回map中的所有key | |
| array |
map_values(Map |
返回map中的所有value | |
| boolean | array_contains(Array |
如果数组包含值,则返回 TRUE。 | |
| Hive0.9.0 | array |
sort_array(Array |
根据数组元素的自然顺序对输入数组进行升序排序并返回 |
1.4.4、类型转化函数
1.4.4.1、binary
select binary(‘a’),binary(‘2’);
1.4.4.2、cast
select cast(‘123’ as int);
| 返回值类型 | 函数名称 | 功能描述 |
|---|---|---|
| binary | binary(string|binary) | 将参数转换为二进制 |
| Expected “=” to follow “type” | cast(expr as |
将表达式 expr 的结果转换为 |
1.4.5、日期函数
1.4.5.1、from_unixtime
select from_unixtime(1638602968),from_unixtime(1638602968,’yyyy-MM-dd HH:mm:SS’),from_unixtime(1638602968,’yyyy-MM-dd’);
1.4.5.2、unix_timestamp
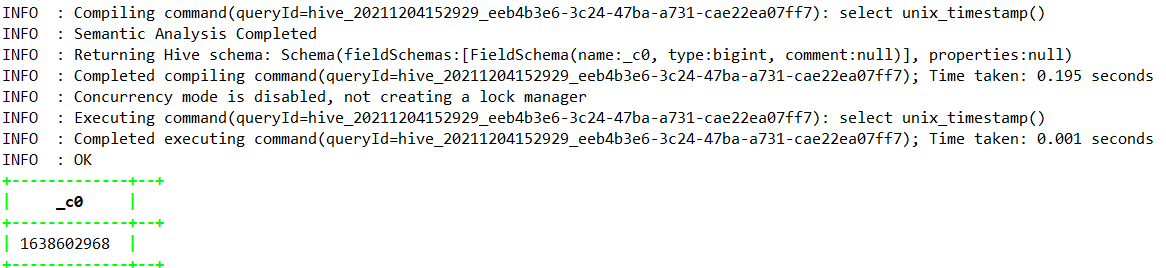
1.4.5.3、to_date
select to_date(‘2021-12-04 2021-12-04 15:29:28’),to_date(‘2021-12-04 15:29:28’);
1.4.5.4、year
select year(‘2021-12-04 15:29:28’);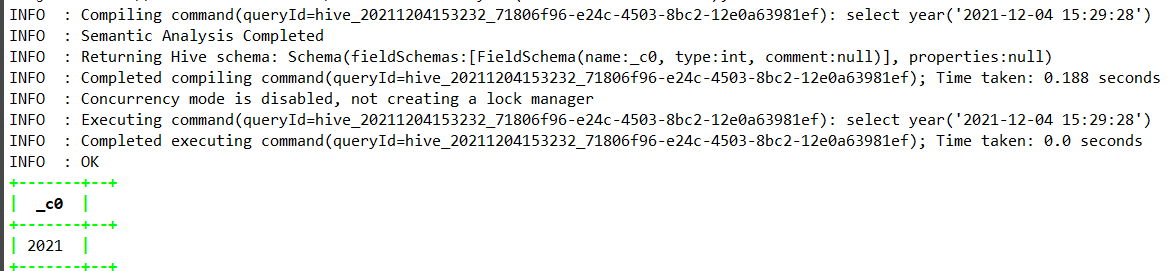
1.4.5.5、quarter—>Hive1.3.0
1.4.5.6、month
select month(‘2021-12-04 15:29:28’);
1.4.5.7、day
select day(‘2021-12-04 15:29:28’);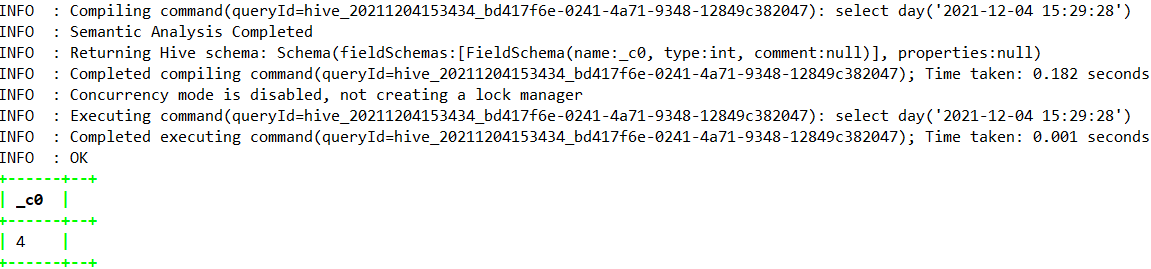
1.4.5.8、hour
select hour(‘2021-12-04 15:29:28’);
1.4.5.9、minute
select minute(‘2021-12-04 15:29:28’);
1.4.5.10、second
select second(‘2021-12-04 15:29:28’);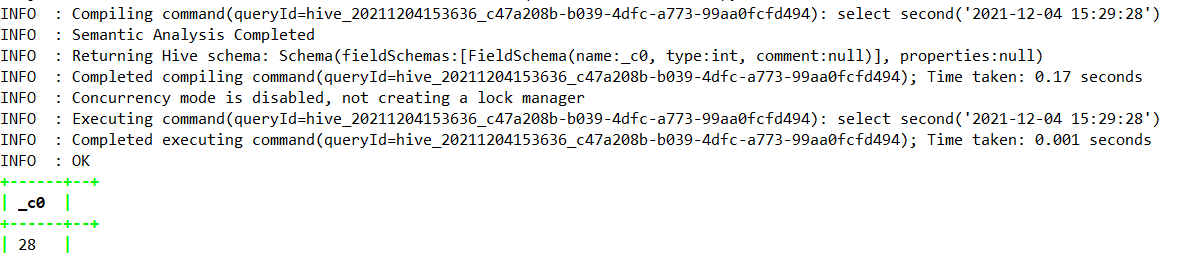
1.4.5.11、weekofyear
select weekofyear(‘2021-12-04 15:29:28’);
1.4.5.12、extract—>Hive2.2.0
1.4.5.13、datediff
select datediff(‘2009-03-01’, ‘2009-02-27’) ;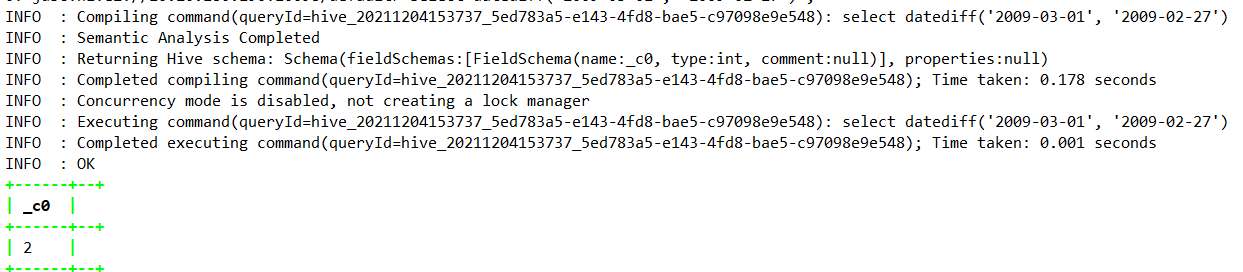
1.4.5.14、date_add
select date_add(‘2021-12-04 15:29:28’,1);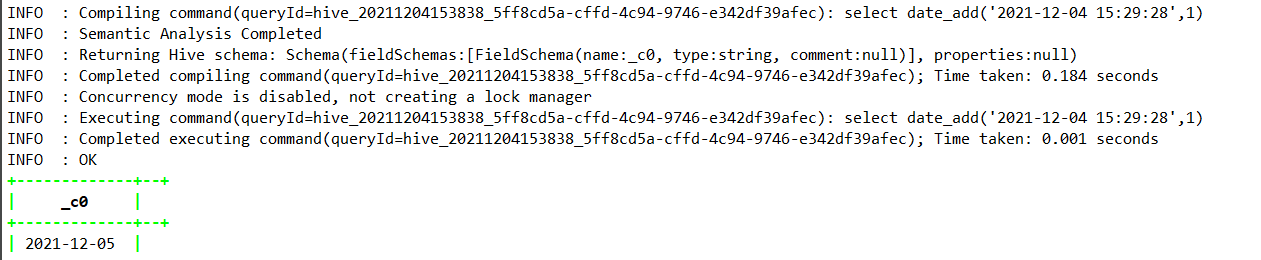
1.4.5.15、date_sub
select date_add(‘2021-12-04 15:29:28’,-1),date_sub(‘2021-12-04 15:29:28’,1),date_sub(‘2021-12-04 15:29:28’,-1);
1.4.5.16、from_utc_timestamp—>Hive0.8.0
select from_utc_timestamp(timestamp ‘1970-01-30 16:00:00’,’PST’) ,from_utc_timestamp(2592000.0,’PST’);
1.4.5.17、to_utc_timestamp—>Hive0.8.0
select to_utc_timestamp(2592000.0,’PST’), to_utc_timestamp(2592000000,’PST’),to_utc_timestamp(timestamp ‘1970-01-30 16:00:00’,’PST’) ;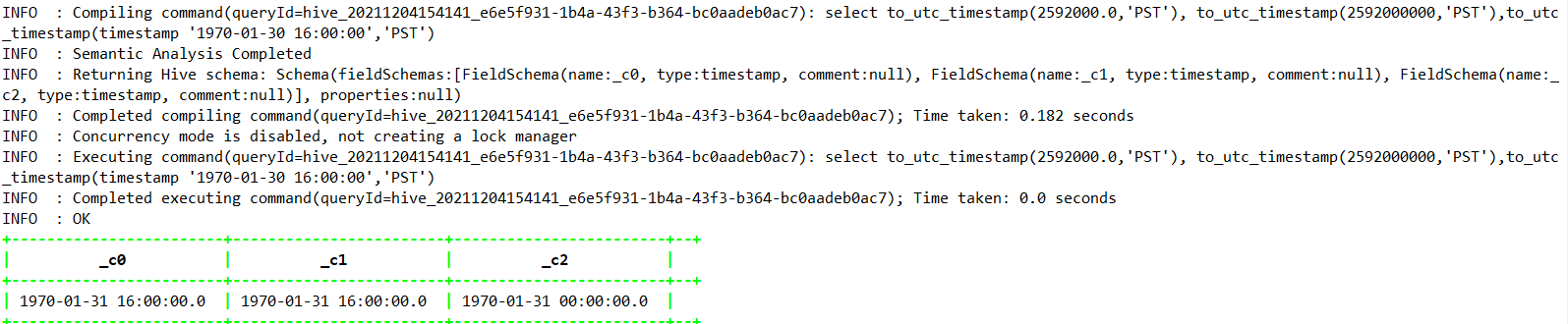
1.4.5.18、current_date —>Hive1.2.0

1.4.5.19、current_timestamp —>Hive1.2.0

1.4.5.20、add_months—>Hive1.1.0
select add_months(‘2009-08-31’, 1),add_months(‘2017-12-31 14:15:16’,3) ;
1.4.5.21、last_day —> Hive1.1.0
select last_day(‘2021-12-04’);
1.4.5.22、next_day —> Hive1.2.0
—获取下一个周二
select next_day(‘2021-12-04’, ‘TU’);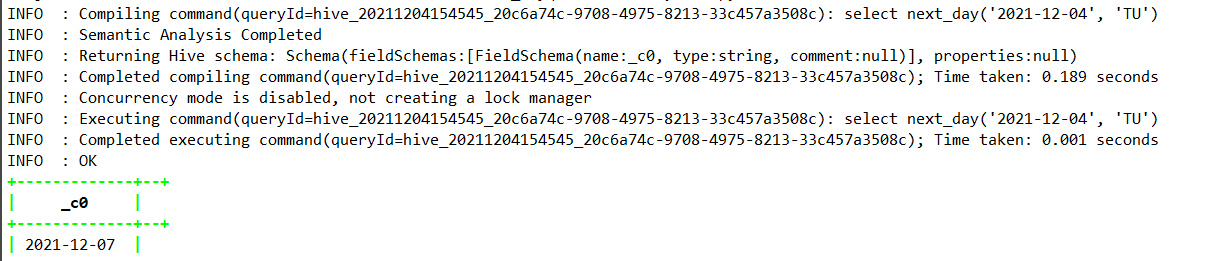
1.4.5.23、trunc —> Hive1.2.0
—返回截断为格式指定单位的日期(从 Hive 1.2.0 开始)。支持的格式:MONTH/MON/MM、YEAR/YYYY/YY。
select trunc(‘2021-12-04’, ‘MM’);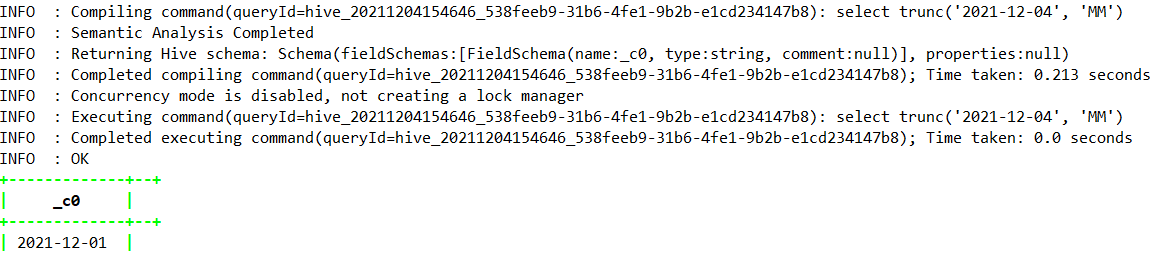
1.4.5.24、months_between—>Hive1.2.0
1.4.5.25、date_format —> Hive1.2.0
| 支持版本+ | 返回值类型 | 函数名称 | 功能描述 |
|---|---|---|---|
| string | from_unixtime(bigint unixtime[, string format]) | 将 unix epoch (1970-01-01 00:00:00 UTC) 的秒数转换为表示当前系统时区中该时刻时间戳的字符串,格式为“1970-01-01 00:00: 00”。 | |
| bigint | unix_timestamp() | 以秒为单位获取当前的 Unix 时间戳。这个函数不是确定性的,它的值在查询执行的范围内不是固定的,因此阻止了查询的正确优化 - 自 2.0 以来,它已被弃用,以支持 CURRENT_TIMESTAMP 常量 | |
| bigint | unix_timestamp(string date) | 将格式为 yyyy-MM-dd HH:mm:ss 的时间字符串转换为 Unix 时间戳(以秒为单位),使用默认时区和默认语言环境,如果失败则返回 0: unix_timestamp(‘2009-03-20 11:30:01 ‘) = 1237573801 | |
| bigint | unix_timestamp(string date, string pattern) | 将具有给定模式的时间字符串转换为 Unix 时间戳(以秒为单位),如果失败则返回 0:unix_timestamp(‘2009-03-20’, ‘yyyy-MM-dd’) = 1237532400 | |
| pre 2.1.0: string 2.1.0 on: date |
to_date(string timestamp) | 返回时间戳字符串的日期部分(Hive 2.1.0 之前):to_date(“1970-01-01 00:00:00”) = “1970-01-01”。从 Hive 2.1.0 开始,返回一个日期对象。 在 Hive 2.1.0 (HIVE-13248) 之前,返回类型是 String,因为在创建方法时不存在 Date 类型。 |
|
| int | year(string date) | 返回日期或时间戳字符串的年份部分:year(“1970-01-01 00:00:00”) = 1970, year(“1970-01-01”) = 1970。 | |
| Hive1.3.0 | int | quarter(date/timestamp/string) | 返回 1 到 4 范围内的日期、时间戳或字符串的一年中的季度(从 Hive 1.3.0 开始))。示例:季度(’2015-04-08’)= 2 |
| int | month(string date) | 返回日期或时间戳字符串的月份部分:month(“1970-11-01 00:00:00”) = 11, month(“1970-11-01”) = 11 | |
| int | day(string date) dayofmonth(date) | 返回日期或时间戳字符串的日期部分:day(“1970-11-01 00:00:00”) = 1, day(“1970-11-01”) = 1 | |
| int | hour(string date) | 返回时间戳的小时数:hour(‘2009-07-30 12:58:59’) = 12, hour(‘12:58:59’) = 12 | |
| int | minute(string date) | 返回时间戳的分钟。 | |
| int | second(string date) | 返回时间戳的第二个 | |
| int | weekofyear(string date) | 返回时间戳字符串的周数:weekofyear(“1970-11-01 00:00:00”) = 44, weekofyear(“1970-11-01”) = 44 | |
| Hive2.2.0 | int | extract(field FROM source) | 从源(从 Hive 2.2.0 开始)检索字段,例如天数或小时数。来源必须是日期、时间戳、间隔或可以转换为日期或时间戳的字符串。支持的字段包括:天、星期几、小时、分钟、月、季度、秒、周和年 示例: select extract(month from “2016-10-20”) results in 10. select extract(hour from “2016-10-20 05:06:07”) results in 5. select extract(dayofweek from “2016-10-20 05:06:07”) results in 5. select extract(month from interval ‘1-3’ year to month) results in 3. select extract(minute from interval ‘3 12:20:30’ day to second) results in 20. |
| int | datediff(string enddate, string startdate) | 返回从 startdate 到 enddate 的天数:datediff(‘2009-03-01’, ‘2009-02-27’) = 2。 | |
| pre 2.1.0: string 2.1.0 on: date |
date_add(date/timestamp/string startdate, tinyint/smallint/int days) | 将天数添加到开始日期:date_add(‘2008-12-31’, 1) = ‘2009-01-01’。在 Hive 2.1.0 (HIVE-13248) 之前,返回类型是 String,因为在创建方法时不存在 Date 类型 | |
| pre 2.1.0: string 2.1.0 on: date |
date_sub(date/timestamp/string startdate, tinyint/smallint/int days) | 减去开始日期的天数:date_sub(‘2008-12-31’, 1) = ‘2008-12-30’。在 Hive 2.1.0 (HIVE-13248) 之前,返回类型是 String,因为在创建方法时不存在 Date 类型 | |
| Hive0.8.0 | timestamp | fromutc_timestamp({_any primitive type} ts, string timezone) | 将 UTC 中的时间戳转换为给定的时区(从 Hive 0.8.0 开始)。timestamp 是原始类型,包括timestamp/date、tinyint/smallint/int/bigint、float/double 和decimal。小数值被视为秒。整数值被视为毫秒。例如 from_utc_timestamp(2592000.0,’PST’), from_utc_timestamp(2592000000,’PST’) 和 from_utc_timestamp(timestamp ‘1970-01-30 16:00:00’,’PST’)1930-1930-1930-时间戳08:00:00 |
| Hive0.8.0 | timestamp | toutc_timestamp({_any primitive type} ts, string timezone) | 将给定时区中的时间戳 转换为 UTC(从 Hive 0.8.0 开始)。timestamp 是原始类型,包括timestamp/date、tinyint/smallint/int/bigint、float/double 和decimal。小数值被视为秒。整数值被视为毫秒。例如 to_utc_timestamp(2592000.0,’PST’), to_utc_timestamp(2592000000,’PST’) 和 to_utc_timestamp(timestamp ‘1970-01-30 16:00:00’,’PST’)1930-1930-1930-timestamp都返回时间戳00:00:00 |
| Hive1.2.0 | date | current_date | 返回查询开始时的当前日期(从Hive 1.2.0开始)。在同一个查询中对current_date的所有调用都会返回相同的值 |
| Hive1.2.0 | timestamp | current_timestamp | 返回查询评估开始时的当前时间戳(从Hive 1.2.0开始)。在同一个查询中调用current_timestamp,都会返回相同的值 |
| Hive1.1.0 | string | add_months(string start_date, int num_months, output_date_format) | 返回 start_date 之后 num_months 的日期(从 Hive 1.1.0 开始)。 start_date 是一个字符串、日期或时间戳。 num_months 是一个整数。如果 start_date 是该月的最后一天,或者如果结果月份的天数少于 start_date 的日期部分,则结果是结果月份的最后一天。否则,结果与 start_date 具有相同的日期部分。默认输出格式为“yyyy-MM-dd”。在 Hive 4.0.0 之前,忽略日期的时间部分。 从 Hive 4.0.0 开始,add_months 支持可选参数 output_date_format,它接受一个表示输出的有效日期格式的 String。这允许在输出中保留时间格式 For example : add_months(‘2009-08-31’, 1) 返回’2009-09-30’. add_months(‘2017-12-31 14:15:16’, 2, ‘YYYY-MM-dd HH:mm:ss’) 返回’2018-02-28 14:15:16’. |
| Hive1.1.0 | string | last_day(string date) | 返回日期所属月份的最后一天(从 Hive 1.1.0 开始)。日期是格式为“yyyy-MM-dd HH:mm:ss”或“yyyy-MM-dd”的字符串。日期的时间部分被忽略。 |
| Hive1.2.0 | string | next_day(string start_date, string day_of_week) | 返回晚于 start_date 并命名为 day_of_week 的第一个日期(从 Hive 1.2.0)。 start_date 是一个字符串/日期/时间戳。 day_of_week 是星期几的 2 个字母、3 个字母或全名(例如 Mo、tue、FRIDAY)。 start_date 的时间部分被忽略。示例:next_day(‘2015-01-14’, ‘TU’) = 2015-01-20 |
| Hive1.2.0 | string | trunc(string date, string format) | 返回截断为格式指定单位的日期(从 Hive 1.2.0 开始)。支持的格式:MONTH/MON/MM、YEAR/YYYY/YY。示例: trunc(‘2015-03-17’, ‘MM’) = 2015-03-01 |
| Hive1.2.0 | double | months_between(date1, date2) | 返回日期 date1 和 date2 之间的月数(从 Hive 1.2.0)。如果 date1 晚于 date2,则结果为正。如果 date1 早于 date2,则结果为负数。如果 date1 和 date2 是该月的同一天或都是该月的最后几天,则结果始终为整数。否则,UDF 会根据有 31 天的月份计算结果的小数部分,并考虑时间分量 date1 和 date2 的差异。 date1 和 date2 类型可以是日期、时间戳或字符串,格式为“yyyy-MM-dd”或“yyyy-MM-dd HH:mm:ss”。结果四舍五入到小数点后 8 位。示例:months_between(‘1997-02-28 10:30:00’, ‘1996-10-30’) = 3.94959677 |
| Hive1.2.0 | string | date_format(date/timestamp/string ts, string fmt) | 将日期/时间戳/字符串转换为日期格式 fmt 指定格式的字符串值(从 Hive 1.2.0 开始)。第二个参数 fmt 应该是常量. 示例: date_format(‘2015-04-08’, ‘y’) = ‘2015’. date_format can be used to implement other UDFs, e.g.: - dayname(date) is date_format(date, ‘EEEE’) - dayofyear(date) is date_format(date, ‘D’) |
1.4.6、判断函数
1.4.6.1、if
select if(1=1,’a’,’b’),if(1=2,’a’,’b’) ;
1.4.6.2、isnull
select isnull(1),isnull(null);
1.4.6.3、isnotnull
select isnotnull(1),isnotnull(null);
1.4.6.4、nvl

1.4.6.5、coalesce
select coalesce(1,null,2,3,null,4,null),coalesce(null,null,null,2,3,4),coalesce(null,null,null,null);
1.4.6.6、case when
select case when 1=1 then ‘1’ else ‘b’ end ,case when 1=1 then ‘1’ end;
1.4.6.7、nullif —>Hive2.3.0
1.4.6.8、assert_true —> Hive0.8.0
select assert_true(1=1),assert_true(1=2);
| 支持版本 | 返回值类型 | 函数名称 | 功能描述 |
|---|---|---|---|
| T | if(boolean testCondition, T valueTrue, T valueFalseOrNull) | 当 testCondition 为真时返回 valueTrue,否则返回 valueFalseOrNull | |
| boolean | isnull( a ) | 如果 a 为 NULL,则返回 true,否则返回 false。 | |
| boolean | isnotnull ( a ) | 如果 a 不是 NULL,则返回 true,否则返回 false。 | |
| T | nvl(T value, T default_value) | 如果值为 null 则返回默认值,否则返回值(从 Hive 0.11 开始) | |
| T | COALESCE(T v1, T v2, …) | 返回第一个不是 NULL 的 v,如果所有 v 都是 NULL,则返回 NULL。 | |
| T | CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END | 当 a = b 时,返回 c;当 a = d 时,返回 e;否则返回 f | |
| T | CASE WHEN a THEN b [WHEN c THEN d]* [ELSE e] END | 当 a = true 时,返回 b;当 c = true 时,返回 d;否则返回 e。 | |
| Hive2.3.0 | T | nullif( a, b ) | 如果 a=b,则返回 NULL;否则返回一个(从 Hive 2.3.0 开始)。简写:CASE WHEN a = b then NULL else a |
| Hive0.8.0 | void | assert_true(boolean condition) | 如果“条件”不为真,则抛出异常,否则返回 null(从 Hive 0.8.0 开始)。例如,选择 assert_true (2<1) |
1.4.7、字符串函数
1.4.7.1、ascii

1.4.7.2、base64—>Hive0.12.0
select base64(cast(‘abcd’ as binary));
1.4.7.3、character_length—>Hive2.2.0
1.4.7.4、chr—>Hive1.3.0
1.4.7.5、concat
select concat(1,’1’,’2’,’a’),concat(1,’a’,null);
1.4.7.6、context_ngrams
1.4.7.7、concat_ws
—该拼接函数仅支持字符串类型或者字符串数组类型
select concat_ws(‘-‘,’1’,’2’,’3’),concat_ws(‘-‘,array(‘1’,’2’,’3’));
1.4.7.8、decode —>Hive0.12.0
select decode(cast(‘abc’ as binary),’ISO-8859-1’);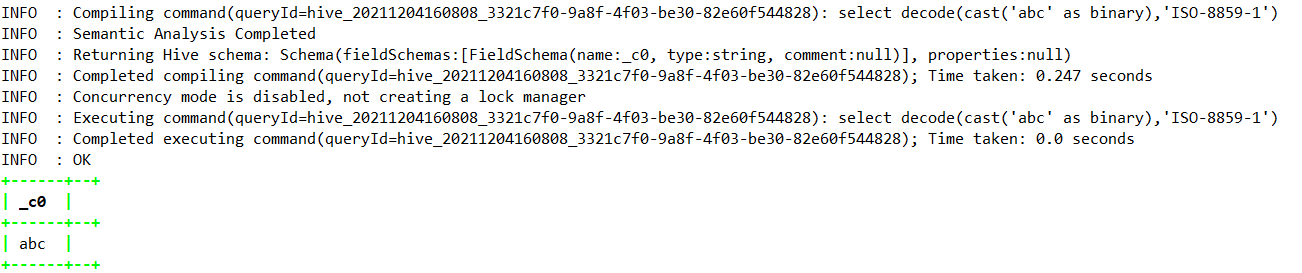
1.4.7.9、elt
—返回指定索引处的字符串
SELECT elt(2,’hello’,’world’),elt(1,’jello’,’world’);
1.4.7.10、encode —>Hive0.12.0
select encode(‘abc1233424asfsd’,’UTF-16LE’);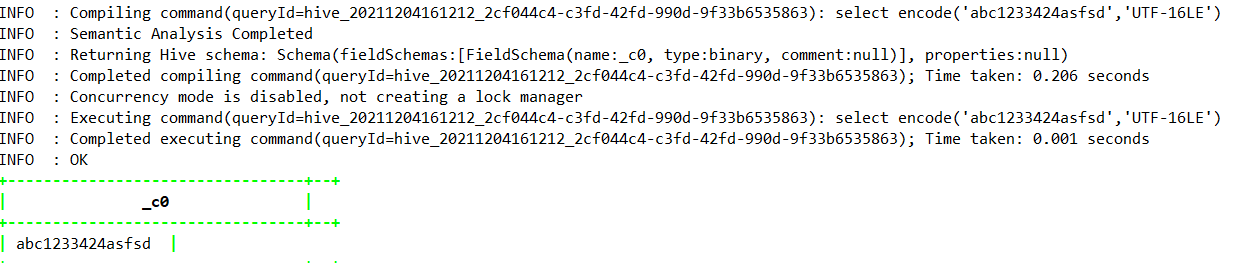
1.4.7.11、field
—返回指定字符串所在的索引处,如world字符串在第3个位置上
select field(‘world’,’say’,’hello’,’world’)
1.4.7.12、find_in_set
—返回 ‘abc,b,ab,c,def’ 中第一次出现的 ab ,其中 ‘abc,b,ab,c,def’ 是逗号分隔的字符串。如果任一参数为 null,则返回 null。如果第一个参数包含任何逗号,则返回 0
select find_in_set(‘ab’, ‘abc,b,ab,c,def’) ;
1.4.7.13、format_number—>Hive0.10.0
select format_number(2,1),format_number(2,2),format_number(2,3);
1.4.7.14、get_json_object
select get_json_object(‘{“a”:2,”b”:1}’,’$.a’);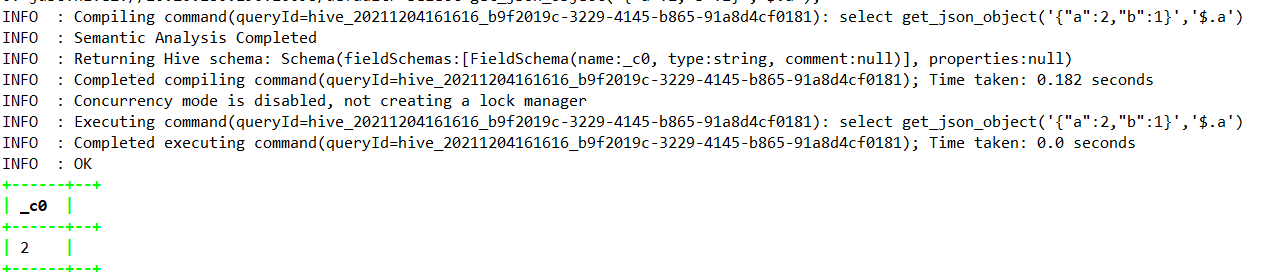
1.4.7.15、in_file
1.4.7.16、instr
select instr(‘asfdsarsrsf234’,’6’),instr(‘asfdsarsrsf234’,’a’);
1.4.7.17、length
select length(‘asfdsarsrsf234’);
1.4.7.18、locate
select locate(‘a’,’asfdsarsrsf234’),locate(‘6’,’asfdsarsrsf234’);
1.4.7.19、lower

1.4.7.20、lpad
—返回10位长度的字符串,如果不原始字符串不足10位,则用在左位填充
select lpad(‘sdfsd’,10,’‘);
1.4.7.21、ltrim
select ltrim(‘safdsf ‘),length(ltrim(‘safdsf ‘)),length(‘safdsf ‘);
1.4.7.22、ngrams
1.4.7.23、octet_length —>Hive2.2.0
1.4.7.24、parse_url
— 可以指定HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, 和 USERINFO
select parse_url(‘http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1‘, ‘HOST’);
1.4.7.25、printf —>0.9.0
SELECT printf(“His Name is%s, Age Is %d”,”Jetty”,100);
1.4.7.26、regexp_extract
SELECT regexp_extract(‘foothebar’, ‘foo(.*?)(bar)’, 2) ;
1.4.7.27、regexp_replace
select regexp_replace(“foobar”, “oo|ar”, “”);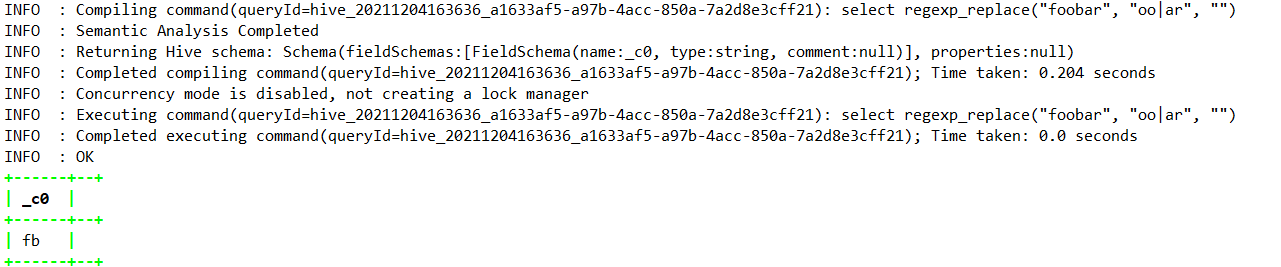
1.4.7.28、repeat
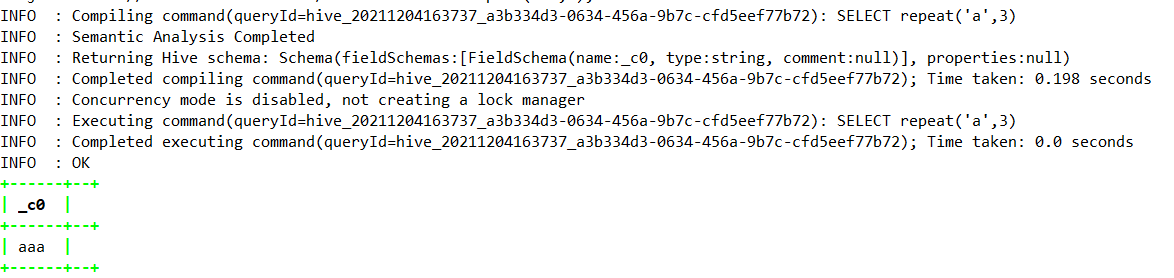
1.4.7.29、replace—>HIve1.3.0
1.4.7.30、reverse
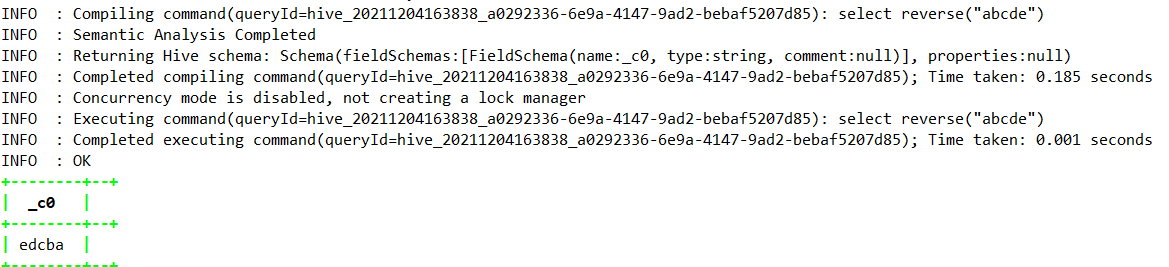
1.4.7.31、rpad

1.4.7.32、rtrim
select rtrim(‘ safdsf ‘),length(rtrim(‘ safdsf ‘)),length(‘ safdsf ‘);
1.4.7.33、sentences
select sentences(‘Hello there! How are you?’);
1.4.7.34、space
select space(3),length(space(3));
1.4.7.35、split
select split(‘ansdasdfc’,’a’);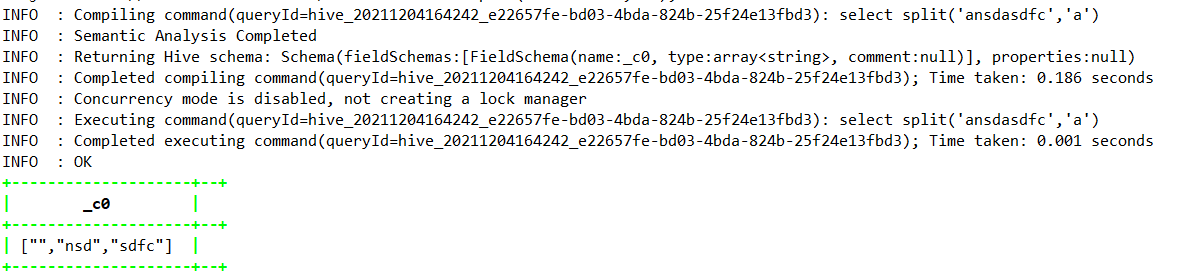
1.4.7.36、str_to_map
select str_to_map(‘a-1,b-2,c-3’,’,’,’-‘);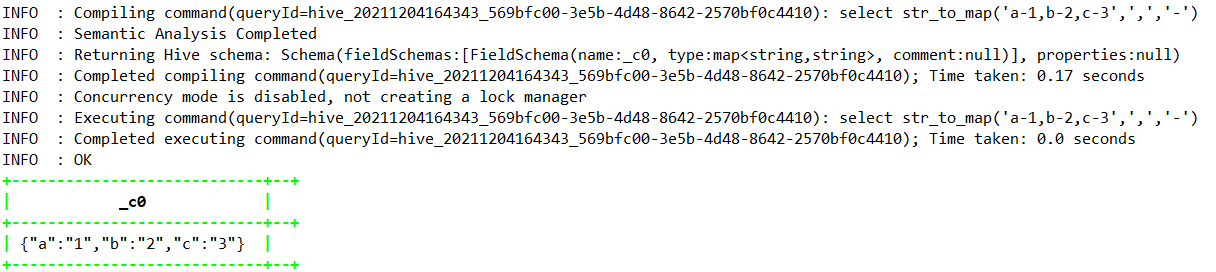
1.4.7.37、substr
select substr(‘foobar’, 4), substr(‘foobar’, 4, 1);
1.4.7.38、substring_index —>Hive1.3.0
1.4.7.39、translate—>Hive0.14.0
select translate(‘asefsda12313asdf’,’123’,’*’);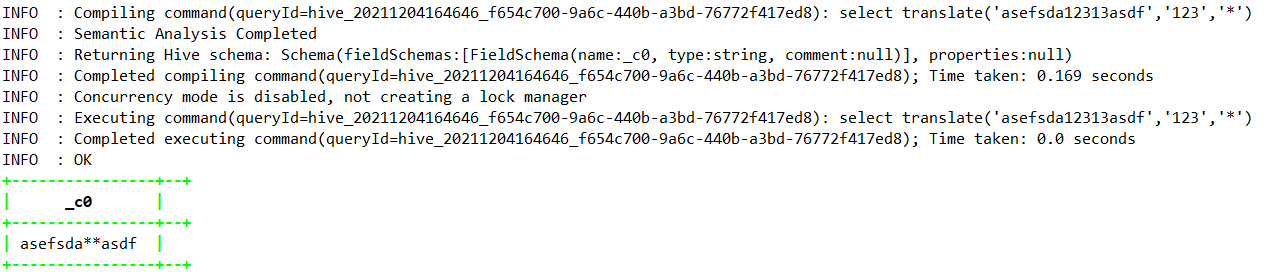
1.4.7.40、trim
select trim(‘ safdsf ‘),length(trim(‘ safdsf ‘)),length(‘ safdsf ‘);
1.4.7.41、unbase64 —>Hive0.12.0
select unbase64(‘wwewe.csdf’);
1.4.7.42、upper

1.4.7.43、initcap—>Hive1.1.0

1.4.7.44、levenshtein —>Hive1.2.0
levenshtein(‘kitten’, ‘sitting’);
1.4.7.45、soundex —>Hive1.2.0
select soundex(‘Miller’);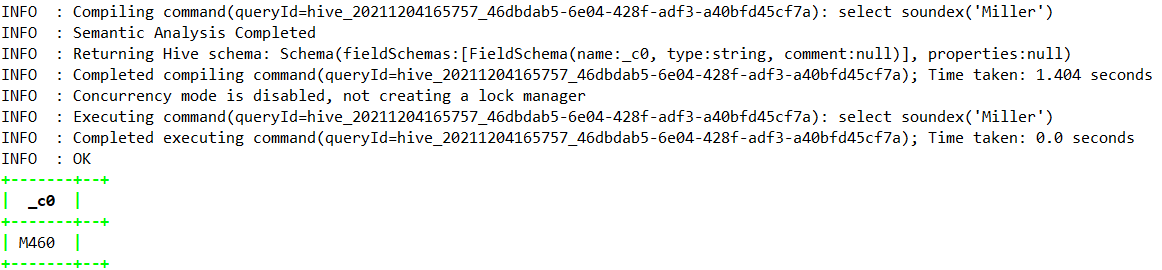
| 支持版本 | 返回值类型 | 函数名称 | 功能描述 |
|---|---|---|---|
| int | ascii(string str) | 返回 str 的第一个字符的数值。 | |
| Hive0.12.0 | string | base64(binary bin) | 将参数从二进制转换为 base 64 字符串(从 Hive 0.12.0 开始) |
| Hive2.2.0 | int | character_length(string str) | 返回 str 中包含的 UTF-8 字符数(从 Hive 2.2.0 开始)。函数 char_length 是该函数的简写。 |
| Hive1.3.0 | string | chr(bigint|double A) | 返回二进制等同于 A 的 ASCII 字符(从 Hive 1.3.0 和 2.1.0 开始)。如果 A 大于 256,则结果等同于 chr(A % 256)。示例:选择 chr(88);返回“X”。 |
| string | concat(string|binary A, string|binary B…) | 返回按顺序连接作为参数传入的字符串或字节所产生的字符串或字节。例如, concat(‘foo’, ‘bar’) 结果为 ‘foobar’。请注意,此函数可以接受任意数量的输入字符串。 | |
| array |
context_ngrams(array |
给定一串“上下文”,从一组标记化的句子中返回前 k 个上下文 N-gram。 | |
| string | concat_ws(string SEP, string A, string B…) | 与上面的 concat() 类似,但使用自定义分隔符 SEP | |
| string | concat_ws(string SEP, array |
与上面的 concat_ws() 类似,但采用字符串数组。 (从 Hive 0.9.0 开始) | |
| Hive0.12.0 | string | decode(binary bin, string charset) | 使用提供的字符集(’US-ASCII’、’ISO-8859-1’、’UTF-8’、’UTF-16BE’、’UTF-16LE’、’UTF- 16’)。如果任一参数为空,则结果也将为空。 (从 Hive 0.12.0 开始。) |
| string | elt(N int,str1 string,str2 string,str3 string,…) | 返回索引号处的字符串。例如 elt(2,’hello’,’world’) 返回 ‘world’。如果 N 小于 1 或大于参数数量,则返回 NULL。 | |
| Hive0.12.0 | binary | encode(string src, string charset) | 使用提供的字符集(’US-ASCII’、’ISO-8859-1’、’UTF-8’、’UTF-16BE’、’UTF-16LE’、’UTF- 16’)。如果任一参数为空,则结果也将为空。 (从 Hive 0.12.0 开始。) |
| int | field(val T,val1 T,val2 T,val3 T,…) | 返回 val1,val2,val3,… 列表中 val 的索引,如果未找到则返回 0。例如 field(‘world’,’say’,’hello’,’world’) 返回 3。支持所有原始类型,使用 str.equals(x) 比较参数。如果 val 为 NULL,则返回值为 0。 | |
| int | find_in_set(string str, string strList) | 返回 strList 中第一次出现的 str ,其中 strList 是逗号分隔的字符串。如果任一参数为 null,则返回 null。如果第一个参数包含任何逗号,则返回 0。例如, find_in_set(‘ab’, ‘abc,b,ab,c,def’) 返回 3 | |
| Hive0.10.0 | string | format_number(number x, int d) | 将数字 X 格式化为类似 ‘#,###,###.##’ 的格式,四舍五入到 D 位小数,并将结果作为字符串返回。如果 D 为 0,则结果没有小数点或小数部分。 (从 Hive 0.10.0 开始;在 Hive 0.14.0 中修复了浮点类型的错误,在 Hive 0.14.0 中添加了十进制类型支持) |
| string | get_json_object(string json_string, string path) | 根据指定的json路径从json字符串中提取json对象,并返回提取的json对象的json字符串。如果输入的 json 字符串无效,它将返回 null。注意:json 路径只能包含字符 [0-9a-z_],即不能包含大写或特殊字符。此外,键不能以数字开头。这是由于对 Hive 列名称的限制 | |
| boolean | in_file(string str, string filename) | 如果字符串 str 在文件名中显示为整行,则返回 true。 | |
| int | instr(string str, string substr) | 返回 substr 在 str 中第一次出现的位置。如果任一参数为 null,则返回 null,如果在 str 中找不到 substr,则返回 0。请注意,这不是基于零的。 str 中的第一个字符的索引为 1 | |
| int | length(string A) | 返回字符串的长度 | |
| int | locate(string substr, string str[, int pos]) | 返回位置 pos 之后 str 中第一次出现 substr 的位置。 | |
| string | lower(string A) lcase(string A) | 返回将 B 的所有字符转换为小写的字符串。例如,lower(‘fOoBaR’) 结果是 ‘foobar’ | |
| string | lpad(string str, int len, string pad) | 返回 str,用 pad 左填充,长度为 len。如果 str 比 len 长,则返回值将缩短为 len 个字符。如果填充字符串为空,则返回值为空 | |
| string | ltrim(string A) | 返回从 A 的开头(左侧)修剪空格产生的字符串。例如, ltrim(‘ foobar ‘) 结果为 ‘foobar ‘ | |
| array |
ngrams(array |
返回一组标记化的句子中的top-k N-grams,例如由sentences()UDAF返回的那些 | |
| Hive2.2.0 | int | octet_length(string str) | 返回以 UTF-8 编码保存字符串 str 所需的八位字节数(自 Hive 2.2.0)。请注意,octet_length(str) 可以大于 character_length(str)。 |
| string | parse_url(string urlString, string partToExtract [, string keyToExtract]) | 从 URL 返回指定的部分。 partToExtract 的有效值包括 HOST、PATH、QUERY、REF、PROTOCOL、AUTHORITY、FILE 和 USERINFO。例如, parse_url(‘http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1‘, ‘HOST’) 返回 ‘facebook.com’。还可以通过提供键作为第三个参数来提取 QUERY 中特定键的值,例如, parse_url(‘http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1‘, ‘QUERY’, ‘k1’) 返回 ‘v1’。 | |
| Hive0.9.0 | string | printf(String format, Obj… args) | 返回按照printf风格的格式字符串格式化的输入(从Hive 0.9.0开始) |
| string | quote(String text) | 返回带引号的字符串(包括任何单引号 HIVE-4.0.0 的转义字符) |
|
| string | regexp_extract(string subject, string pattern, int index) | 返回使用模式提取的字符串。例如,regexp_extract(‘foothebar’, ‘foo(.*?)(bar)’, 2) 返回 ‘bar.’请注意,在使用预定义字符类时需要小心:使用 ‘\s’ 作为第二个参数将匹配字母 s; ‘\\s’ 是匹配空格等所必需的。’index’ 参数是 Java 正则表达式 Matcher group() 方法索引 | |
| string | regexp_replace(string INITIAL_STRING, string PATTERN, string REPLACEMENT) | 返回将 INITIAL_STRING 中与 PATTERN 中定义的 java 正则表达式语法匹配的所有子字符串替换为 REPLACEMENT 实例所产生的字符串。例如,regexp_replace(“foobar”, “oo|ar”, “”) 返回 ‘fb.’。请注意,在使用预定义字符类时需要小心:使用 ‘\s’ 作为第二个参数将匹配字母 s; ‘\\s’ 是匹配空格等所必需的。 | |
| string | repeat(string str, int n) | 重复 str n 次。 | |
| Hive1.3.0 | string | replace(string A, string OLD, string NEW) | 返回所有非重叠出现的OLD被替换为NEW的字符串A(从Hive 1.3.0和2.1.0起). 例如:选择 replace(“ababab”, “abab”, “Z”); 返回 “Zab” |
| string | reverse(string A) | 返回反转的字符串 | |
| string | rpad(string str, int len, string pad) | 返回 str,用 pad 右填充,长度为 len。如果 str 比 len 长,则返回值将缩短为 len 个字符。如果填充字符串为空,则返回值为空。 | |
| string | rtrim(string A) | 返回从 A 的末尾(右侧)修剪空格产生的字符串。例如, rtrim(‘ foobar ‘) 结果为 ‘ foobar’ | |
| array |
sentences(string str, string lang, string locale) | 将一串自然语言文本标记为单词和句子,其中每个句子在适当的句子边界处断开并作为单词数组返回。 ‘lang’ 和 ‘locale’ 是可选参数。例如,句子(‘Hello there! How are you?’) 返回 ( (“Hello”, “there”), (“How”, “are”, “you”) ) | |
| string | space(int n) | 返回一个包含 n 个空格的字符串 | |
| array | split(string str, string pat) | 在 pat 周围拆分 str (pat 是一个正则表达式) | |
| map |
str_to_map(text[, delimiter1, delimiter2]) | 使用两个分隔符将文本拆分为键值对。 Delimiter1 将文本分成 K-V 对,Delimiter2 拆分每个 K-V 对。默认分隔符是“,”用于 delimiter1,“:”用于 delimiter2。 | |
| string | substr(string|binary A, int start) substring(string|binary A, int start) | 返回 A 的字节数组的子字符串或切片,从起始位置到字符串 A 的结尾。例如, substr(‘foobar’, 4) 结果为 ‘bar | |
| string | substr(string|binary A, int start, int len) substring(string|binary A, int start, int len) | 返回 A 的字节数组的子字符串或切片,从起始位置开始,长度为 len。例如, substr(‘foobar’, 4, 1) 结果为 ‘b’ | |
| Hive1.3.0 | string | substring_index(string A, string delim, int count) | 在分隔符 delim 出现计数之前返回字符串 A 中的子字符串(从 Hive 1.3.0 开始))。如果 count 为正数,则返回最终分隔符左侧的所有内容(从左侧开始计数)。如果计数为负,则返回最终分隔符右侧的所有内容(从右侧开始计数)。 Substring_index 在搜索 delim 时执行区分大小写的匹配。示例:substring_index(‘www.apache.org’, ‘.’, 2) = ‘www.apache’ |
| Hive0.14.0 | string | translate(string|char|varchar input, string|char|varchar from, string|char|varchar to) | 通过用 to 字符串中的相应字符替换 from 字符串中存在的字符来翻译输入字符串。这类似于 PostgreSQL 中的 translate 函数。如果此 UDF 的任何参数为 NULL,则结果也为 NULL。 (从 Hive 0.10.0 开始可用,用于字符串类型)。从 Hive 0.14.0 开始添加 Char/varchar 支持 |
| string | trim(string A) | 返回从 A 的两端修剪空格产生的字符串。例如,trim(‘ foobar ‘) 结果为 ‘foobar’ | |
| Hive0.12.0 | binary | unbase64(string str) | 将参数从 base 64 字符串转换为 BINARY。 (从 Hive 0.12.0 开始。) |
| string | upper(string A) ucase(string A) | 返回将 A 的所有字符转换为大写的字符串。例如, upper(‘fOoBaR’) 结果为 ‘FOOBAR’ | |
| Hive1.1.0 | string | initcap(string A) | 返回字符串,每个单词的第一个字母大写,所有其他字母小写。单词由空格分隔。 (截至 Hive 1.1.0.) |
| Hive1.2.0 | int | levenshtein(string A, string B) | 返回两个字符串之间的 Levenshtein 距离(从 Hive 1.2.0)。例如, levenshtein(‘kitten’, ‘sitting’) 结果为 3 |
| Hive1.2.0 | string | soundex(string A) | 返回字符串的 soundex 代码(从 Hive 1.2.0 开始)。例如, soundex(‘Miller’) 结果为 M460 |
1.4.8、掩码函数
1.4.8.1、mask—>Hive2.1.0
1.4.8.12、mask_first_n->Hive2.1.0
1.4.8.13、mask_last_n —>Hive2.1.0
1.4.8.14、mask_show_first_n—>Hive2.1.0
1.4.8.15、maskshow__last_n —>Hive2.1.0
1.4.8.16、mask_hash —>Hive2.1.0
| 支持版本 | 返回值类型 | 函数名称 | 功能描述 |
|---|---|---|---|
| Hive2.1.0 | string | mask(string str[, string upper[, string lower[, string number]]]) | 返回 str 的掩码版本(从 Hive 2.1.0 开始)。默认情况下,大写字母转换为“X”,小写字母转换为“x”,数字转换为“n”。例如 mask(“abcd-EFGH-8765-4321”) 结果为 xxxx-XXXX-nnnn-nnnn。您可以通过提供附加参数来覆盖掩码中使用的字符:第二个参数控制大写字母的掩码字符,第三个参数控制小写字母,第四个参数控制数字。例如, mask(“abcd-EFGH-8765-4321”, “U”, “l”, “#”) 结果为 llll-UUUU-####-#### |
| Hive2.1.0 | string | mask_first_n(string str[, int n]) | 返回前 n 个值被屏蔽的 str 的屏蔽版本(从 Hive 2.1.0 开始)。大写字母转换为“X”,小写字母转换为“x”,数字转换为“n”。例如, mask_first_n(“1234-5678-8765-4321”, 4) 结果为 nnnn-5678-8765-4321 |
| Hive2.1.0 | string | mask_last_n(string str[, int n]) | 返回一个掩码版本的 str 掩码了最后 n 个值(从 Hive 2.1.0 开始)。大写字母转换为“X”,小写字母转换为“x”,数字转换为“n”。例如: mask_last_n(“1234-5678-8765-4321”, 4) 结果为 1234-5678-8765-nnnn |
| Hive2.1.0 | string | mask_show_first_n(string str[, int n]) | 返回 str 的掩码版本,显示未掩码的前 n 个字符(从 Hive 2.1.0 开始)。大写字母转换为“X”,小写字母转换为“x”,数字转换为“n”。例如:mask_show_first_n(“1234-5678-8765-4321”, 4) 结果为 1234-nnnn-nnnn-nnnn |
| Hive2.1.0 | string | mask_show_last_n(string str[, int n]) | 返回 str 的掩码版本,显示未掩码的最后 n 个字符(从 Hive 2.1.0 开始)。大写字母转换为“X”,小写字母转换为“x”,数字转换为“n”。例如, mask_show_last_n(“1234-5678-8765-4321”, 4) 结果为 nnnn-nnnn-nnnn-4321 |
| Hive2.1.0 | string | mask_hash(string|char|varchar str) | 返回基于 str 的散列值(从 Hive 2.1.0)。散列是一致的,可用于跨表将掩码值连接在一起。对于非字符串类型,此函数返回 null。 |
1.4.9、杂项函数
1.4.9.1、java_method—>Hive0.9.0
SELECT java_method(“java.lang.String”, “valueOf”, 1),
java_method(“java.lang.String”, “isEmpty”),
java_method(“java.lang.Math”, “max”, 2, 3),
java_method(“java.lang.Math”, “min”, 2, 3),
java_method(“java.lang.Math”, “round”, 2.5),
java_method(“java.lang.Math”, “exp”, 1.0),
java_method(“java.lang.Math”, “floor”, 1.9)
1.4.9.2、reflect —> Hive0.7.0
SELECT reflect(“java.lang.String”, “valueOf”, 1),
reflect(“java.lang.String”, “isEmpty”),
reflect(“java.lang.Math”, “max”, 2, 3),
reflect(“java.lang.Math”, “min”, 2, 3),
reflect(“java.lang.Math”, “round”, 2.5),
reflect(“java.lang.Math”, “exp”, 1.0),
reflect(“java.lang.Math”, “floor”, 1.9)
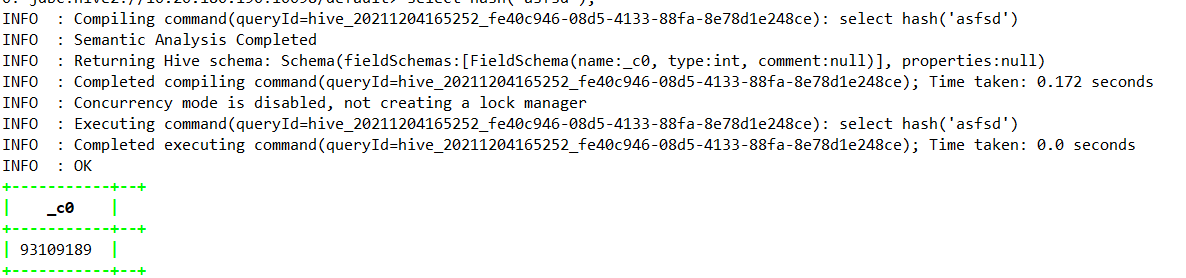
1.4.9.3、hash —> Hive0.4
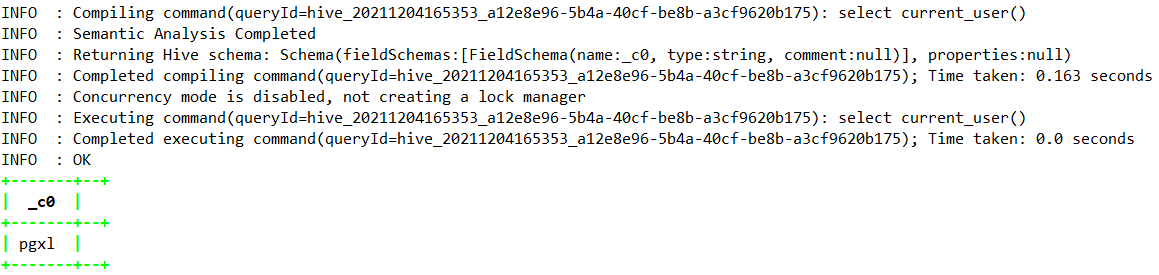
1.4.9.4、current_user —> Hive1.2.0
1.4.9.5、logged_in_user —> Hive2.2.0
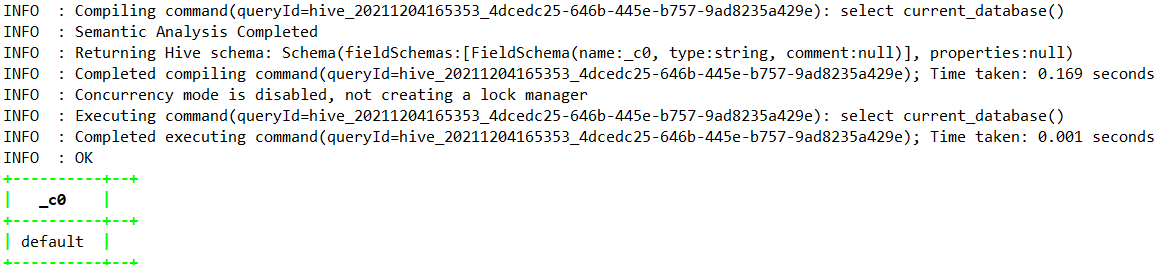
1.4.9.6、current_database —>Hive0.13.0
1.4.9.7、md5 —>Hive1.3.0

1.4.9.8、sha1 —> Hive1.3.0
1.4.9.9、crc32 —> Hive1.3.0
1.4.9.10、sha2—>Hive1.3.0
1.4.9.11、aes_encrypt —> Hive1.3.0
1.4.9.12、version —> Hive2.1.0
1.4.9.13、surrogate_key
| 支持版本 | 返回值类型 | 函数名称 | 功能描述 |
|---|---|---|---|
| Hive0.9.0 | varies | java_method(class, method[, arg1[, arg2..]]) | 反射 |
| Hive0.7.0 | varies | reflect(class, method[, arg1[, arg2..]]) | 使用反射通过匹配参数签名来调用 Java 方法。 |
| Hive0.4 | int | hash(a1[, a2…]) | 返回参数的哈希值。 (从 Hive 0.4 开始) |
| Hive1.2.0 | string | current_user() | 从配置的身份验证器管理器返回当前用户名(从 Hive 1.2.0)。可能与连接时提供的用户相同,但对于某些身份验证管理器(例如 HadoopDefaultAuthenticator),它可能不同。 |
| Hive2.2.0 | string | logged_in_user() | 从会话状态返回当前用户名(从 Hive 2.2.0)。这是连接到 Hive 时提供的用户名。 |
| Hive0.13.0 | string | current_database() | 返回当前数据库名称(从 Hive 0.13.0 开始) |
| Hive1.3.0 | string | md5(string/binary) | 计算字符串或二进制的 MD5 128 位校验和(从 Hive 1.3.0 开始)。该值作为 32 个十六进制数字的字符串返回,如果参数为 NULL,则返回 NULL。示例:md5(‘ABC’) = ‘902fbdd2b1df0c4f70b4a5d23525e932’ |
| Hive1.3.0 | string | sha1(string/binary) sha(string/binary) |
计算字符串或二进制的 SHA-1 摘要并将值作为十六进制字符串返回(从 Hive 1.3.0)。示例:sha1(‘ABC’) = ‘3c01bdbb26f358bab27f267924aa2c9a03fcfdb8’ |
| Hive1.3.0 | bigint | crc32(string/binary) | 计算字符串或二进制参数的循环冗余校验值并返回 bigint 值(从 Hive 1.3.0)。示例:crc32(‘ABC’) = 2743272264。 |
| Hive1.3.0 | string | sha2(string/binary, int) | 计算 SHA-2 系列哈希函数(SHA-224、SHA-256、SHA-384 和 SHA-512)(从 Hive 1.3.0 开始))。第一个参数是要散列的字符串或二进制文件。第二个参数表示结果的所需位长,其值必须为 224、256、384、512 或 0(相当于 256)。从 Java 8 开始支持 SHA-224。如果任一参数为 NULL 或哈希长度不是允许的值之一,则返回值为 NULL。示例:sha2(‘ABC’, 256) = ‘b5d4045c3f466fa91fe2cc6abe79232a1a57cdf104f7a26e716e0a1e2789df78’ |
| Hive1.3.0 | binary | aes_encrypt(input string/binary, key string/binary) | 使用 AES 加密输入(从 Hive 1.3.0 开始)。可以使用 128、192 或 256 位的密钥长度。如果安装了 Java Cryptography Extension (JCE) Unlimited Strength Jurisdiction Policy Files,则可以使用 192 和 256 位密钥。如果任一参数为 NULL 或密钥长度不是允许的值之一,则返回值为 NULL。示例:base64(aes_encrypt(‘ABC’, ‘1234567890123456’)) = ‘y6Ss+zCYObpCbgfWfyNWTw==’。 |
| Hive1.3.0 | binary | aes_decrypt(input binary, key string/binary) | 使用 AES 解密输入(从 Hive 1.3.0 开始)。可以使用 128、192 或 256 位的密钥长度。如果安装了 Java Cryptography Extension (JCE) Unlimited Strength Jurisdiction Policy Files,则可以使用 192 和 256 位密钥。如果任一参数为 NULL 或密钥长度不是允许的值之一,则返回值为 NULL。示例:aes_decrypt(unbase64(‘y6Ss+zCYObpCbgfWfyNWTw==’), ‘1234567890123456’) = ‘ABC’。 |
| Hive2.1.0 | string | version() | 返回 Hive 版本(从 Hive 2.1.0 开始)。该字符串包含 2 个字段,第一个是内部版本号,第二个是内部版本哈希。示例:select version()可能会返回“2.1.0.2.5.0.0-1245 r027527b9c5ce1a3d7d0b6d2e6de2378fb0c39232”。实际结果将取决于您的构建 |
| bigint | surrogate_key([write_id_bits, task_id_bits]) | 当您将数据输入表格时,自动为行生成数字 ID。只能用作酸表或仅插入表的默认值。 |
1.4.10、内置UDAF函数

1.4.10.1、count
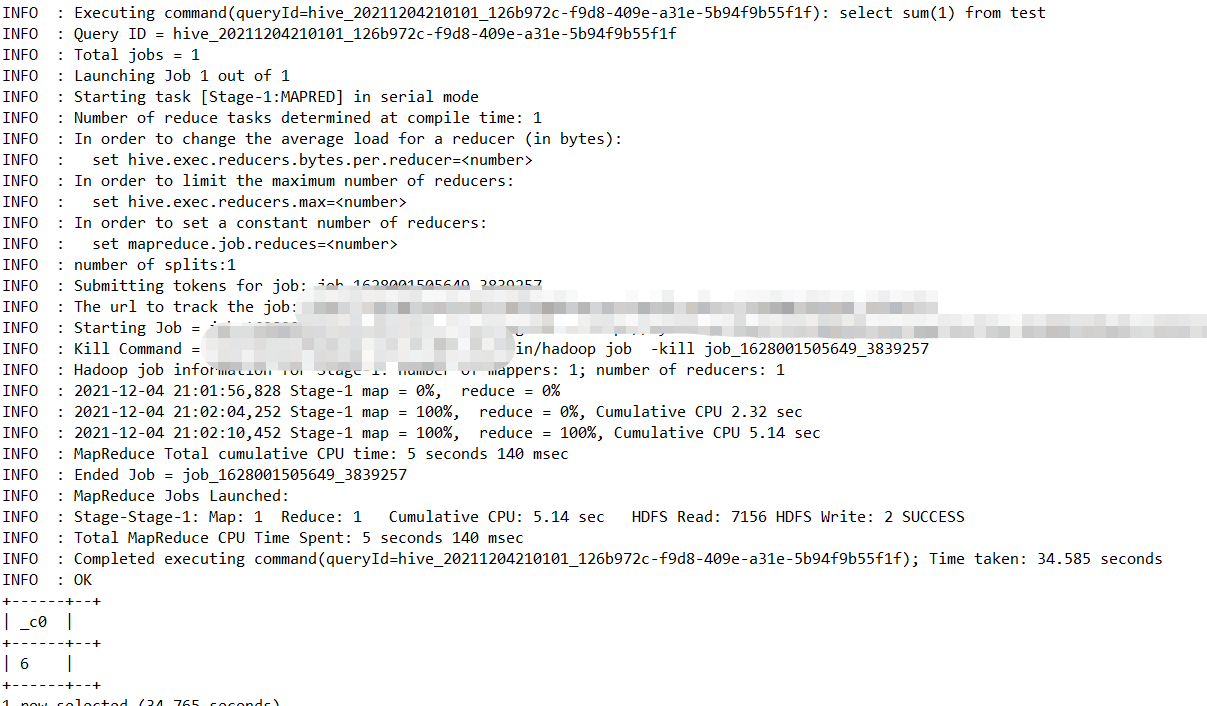
—可以发现count(id)会把id=null的值剔除掉
select count(1),count(*),count(distinct id),count(id) from test
1.4.10.2、sum
1.4.10.3、avg
1.4.10.4、min
1.4.10.5、max
1.4.10.6、variance
1.4.10.7、var_sample
1.4.10.8、stddev_pop
1.4.10.9、covar_pop
1.4.10.10、covar_samp
1.4.10.11、corr
1.4.10.12、percentile
1.4.10.13、percentile_approx
1.4.10.14、regr_avgx —>Hive2.2.0
1.4.10.15、regr_avgy —>Hive2.2.0
1.4.10.16、regr_count —>Hive2.2.0
1.4.10.17、regr_intercept —>Hive2.2.0
1.4.10.18、regr_r2 —>Hive2.2.0
1.4.10.19、regr_slope —>Hive2.2.0
1.4.10.20、regr_sxx —>Hive2.2.0
1.4.10.21、regr_sxy —>Hive2.2.0
1.4.10.22、regr_syy —>Hive2.2.0
1.4.10.23、histogram_numeric
1.4.10.24、collect_set
select collect_set(id),count(1) from test;
1.4.10.25、collect_list —> Hive0.13.0
select collect_list(id),count(1) from test;
1.4.10.26、ntile —> Hive0.11.0
select
id,
ntile(1) over(partition by id),—分组内的数据切分为1份
ntile(2) over(partition by id),—分组内的数据切分为2份
ntile(3) over(partition by id )—分组内的数据切分为2份
from test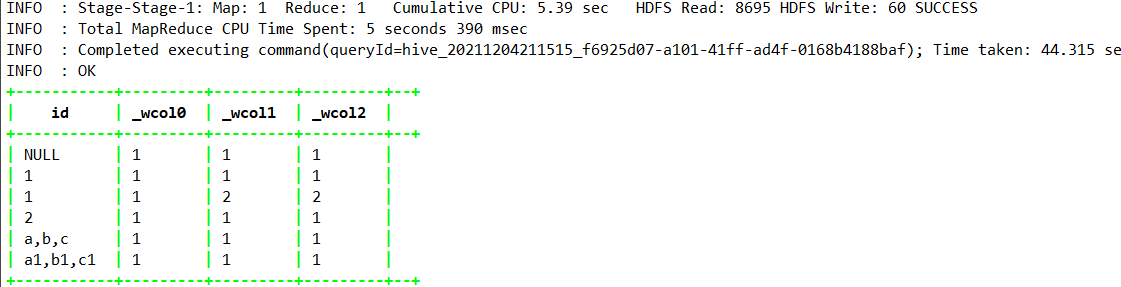
| 支持版本 | 返回值类型 | 函数名称 | 功能描述 |
|---|---|---|---|
| BIGINT | count(*), count(expr), count(DISTINCT expr[, expr…]) | count(*) - 返回检索到的总行数,包括包含 NULL 值的行 count(expr) - 返回提供的表达式为非 NULL 的行数. count(DISTINCT expr[, expr]) -返回提供的表达式唯一且非 NULL 的行数。可以使用 hive.optimize.distinct.rewrite 优化此操作的执行. |
|
| DOUBLE | sum(col), sum(DISTINCT col) | 返回组中元素的总和或组中列的不同值的总和。 | |
| DOUBLE | avg(col), avg(DISTINCT col) | 返回组中元素的平均值或组中列的不同值的平均值 | |
| DOUBLE | min(col) | 返回组中列的最小值 | |
| DOUBLE | max(col) | 返回组中列的最大值。 | |
| DOUBLE | variance(col), var_pop(col) | 返回组中数字列的方差 | |
| DOUBLE | var_samp(col) | 返回组中数字列的无偏样本方差 | |
| DOUBLE | stddev_pop(col) | 返回组中数字列的标准差 | |
| DOUBLE | stddev_samp(col) | 返回组中数字列的无偏样本标准差 | |
| DOUBLE | covar_pop(col1, col2) | 返回组中一对数值列的总体协方差 | |
| DOUBLE | covar_samp(col1, col2) | 返回组中一对数字列的样本协方差 | |
| DOUBLE | corr(col1, col2) | 返回组中一对数字列的 Pearson 相关系数 | |
| DOUBLE | percentile(BIGINT col, p) | 返回组中列的确切第 p 个百分位数(不适用于浮点类型)。 p 必须介于 0 和 1 之间。注意:只能为整数值计算真正的百分位数。如果您的输入是非整数,请使用 PERCENTILE_APPROX。 | |
| array |
percentile(BIGINT col, array(p1 [, p2]…)) | 返回组中列的确切百分位数 p1、p2、…(不适用于浮点类型)。 pi 必须介于 0 和 1 之间。注意:只能为整数值计算真正的百分位数。如果您的输入是非整数,请使用 PERCENTILE_APPROX | |
| DOUBLE | percentile_approx(DOUBLE col, p [, B]) | 返回组中数字列(包括浮点类型)的近似第 p 个百分位。 B 参数以内存为代价控制近似精度。较高的值会产生更好的近似值,默认值为 10,000。当 col 中不同值的数量小于 B 时,这给出了精确的百分位值 | |
| array |
percentile_approx(DOUBLE col, array(p1 [, p2]…) [, B]) | 同上,但接受并返回百分位值数组而不是单个值 | |
| Hive2.2.0 | double | regr_avgx(independent, dependent) | 相当于 avg(依赖)。从 Hive 2.2.0 开始。 |
| Hive2.2.0 | double | regr_avgy(independent, dependent) | 相当于 avg(独立)。从 Hive 2.2.0 开始 |
| Hive2.2.0 | double | regr_count(independent, dependent) | 返回用于拟合线性回归线的非空对的数量。从 Hive 2.2.0 开始 |
| Hive2.2.0 | double | regr_intercept(independent, dependent) | 返回线性回归线的 y 截距,即等式中 b 的值依赖 = a * independent + b。从 Hive 2.2.0 开始 |
| Hive2.2.0 | double | regr_r2(independent, dependent) | 返回回归的决定系数。从 Hive 2.2.0 开始。 |
| Hive2.2.0 | double | regr_slope(independent, dependent) | 返回线性回归线的斜率,即等式中 a 的值依赖 = a * independent + b。从 Hive 2.2.0 开始。 |
| Hive2.2.0 | double | regr_sxx(independent, dependent) | 相当于 regr_count(independent,dependent) * var_pop(dependent)。从 Hive 2.2.0 开始。 |
| Hive2.2.0 | double | regr_sxy(independent, dependent) | 相当于 regr_count(independent,dependent) * covar_pop(independent,dependent)。从 Hive 2.2.0 开始 |
| Hive2.2.0 | double | regr_syy(independent, dependent) | 相当于 regr_count(independent,dependent) * var_pop(independent)。从 Hive 2.2.0 开始 |
| array |
histogram_numeric(col, b) | 使用 b 个非均匀间隔的 bin 计算组中数字列的直方图。输出是表示 bin 中心和高度的双值 (x,y) 坐标的大小为 b 的数组 | |
| array | collect_set(col) | 返回一组消除了重复元素的对象,可实现去重作用 | |
| Hive0.13.0 | array | collect_list(col) | 返回具有重复项的对象列表,(从 Hive 0.13.0 开始。) |
| Hive0.11.0 | INTEGER | ntile(INTEGER x) | 将一个有序的分区分成 x 个称为桶的组,并为分区中的每一行分配一个桶号。这允许轻松计算三分位数、四分位数、十分位数、百分位数和其他常见的汇总统计数据。 (从 Hive 0.11.0 开始。) |
1.4.11、内置UDTF函数
1.4.11.1、explode
select explode(array(100,200,300));
| Array |
|---|
| [100,200,300] |
| [400,500,600] |
得到的结果如下:
| (int) myNewCol |
|---|
| 100 |
| 200 |
| 300 |
| 400 |
| 500 |
| 600 |
1.4.11.2、posexplode
select posexplode(array(‘A’,’B’,’C’));
1.4.11.3、parse_url_tuple
select parse_url_tuple(‘http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1','HOST‘, ‘PATH’, ‘QUERY’, ‘QUERY:id’);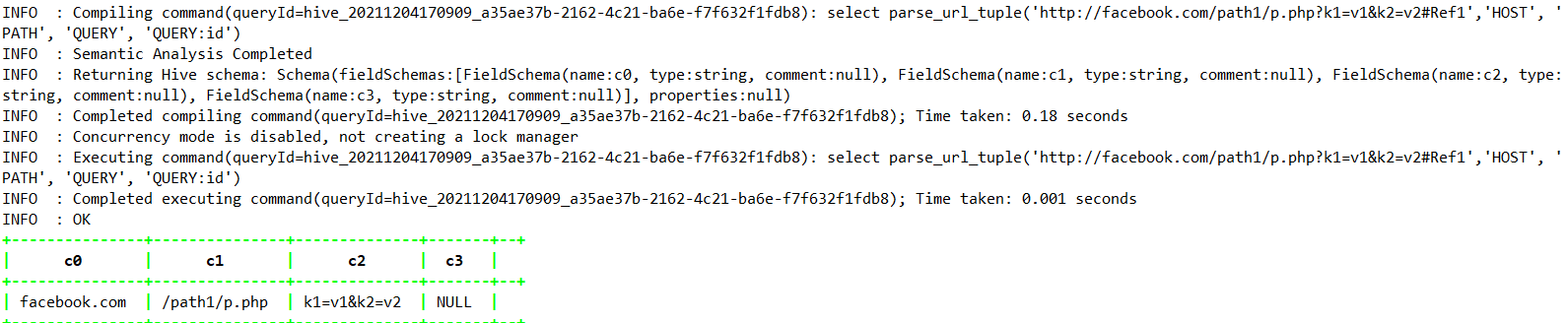
1.4.11.5、inline
select inline(array(struct(‘A’,10,date ‘2015-01-01’),struct(‘B’,20,date ‘2016-02-02’)));
1.4.11.6、stack
select stack(2,’A’,10,date ‘2015-01-01’,’B’,20,date ‘2016-01-01’);
1.4.11.7、json_tuple
select json_tuple(‘{“a”:1,”b”:2}’,’a’,’b’,’c’);
| 返回值类型 | 函数名称 | 功能描述 |
|---|---|---|
| T | explode(ARRAY |
将数组分解为多行。返回具有单列 (col) 的行集,数组中的每个元素对应一行。 |
| Tkey,Tvalue | explode(MAP |
将map分解为多行。返回一个包含两列 (key,value) 的行集,输入映射中的每个键值对对应一行。 (从 Hive 0.8.0 开始。),炸裂 |
| int,T | posexplode(ARRAY |
使用 int 类型的附加位置列(原始数组中项目的位置,从 0 开始)将数组分解为多行。返回一个包含两列 (pos,val) 的行集,数组中的每个元素占一行,其实就是带有序号的explode功能 |
| T1,…,Tn | inline(ARRAY |
将一个结构数组分解为多行。返回一个有N列的行集(N=结构中顶级元素的数量),每个结构在数组中都有一行。(从Hive 0.10开始) |
| T1,…,Tn/r | stack(int r,T1 V1,…,Tn/r Vn) | 将 n 个值 V1,…,Vn 分解为 r 行。每行将有 n/r 列。 r 必须是常数 |
| string1,…,stringn | json_tuple(string jsonStr,string k1,…,string kn) | 接受 JSON 字符串和一组 n 个键,并返回 n 个值的元组。这是 get_json_object UDF 的更高效版本,因为它可以通过一次调用获取多个键。 |
| string 1,…,stringn | parse_url_tuple(string urlStr,string p1,…,string pn) | 获取 URL 字符串和一组 n 个 URL 部分,并返回一个包含 n 个值的元组。这类似于 parse_url() UDF,但可以一次从 URL 中提取多个部分。有效的部分名称为:HOST、PATH、QUERY、REF、PROTOCOL、AUTHORITY、FILE、USERINFO、QUERY: |
1.4.12、三者区别
1.4.12.1、UDF
UDF全称为User Defined Function(即用户自定义函数),UDF开发在日常工作当中是非常普遍的。我们写一段SQL,调用UDF,得到结果就算是结束了,但大家有没有想过UDF底层是怎么执行的呢?那么我们拿MR引擎为例,那UDF是在Map端执行还是在Reduce端执行的呢?说实话,我之前没想过。
既然没想过,那今天就来想一想。首先抛开在哪端执行不说,那我们知道UDF的模式是我们给一个值,然后再返回一个值。如上图所示,传一个A,返回给一个A_1;传一个B,返回给一个B_1;传一个C返回给一个C_1;
这种模式就相当于在传入的一个值上进行了一些修饰后再返回给我们,相当于是一对一的模式。梳理到这里,答案也比较清晰了,这不就是map功能吗。有些同学可能会质疑,没关系,我们explain一下就知道了。
如上图所示,只有一个fetch Operator,当然这个demo比较简单,不会走MR的。从这里也可以看出来这就是一个转换功能,但有些同学仍有疑惑,没关系,让我们来一个走MR的例子。
explain select substr(id,2),count(1) from test group by substr(id,2);
到这里总能证明UDF函数是在Map阶段执行的吧!
1.4.12.2、UDF编写
对于如何开发UDF,网上模板一大堆,这里不再叙述。下面出一个关于year函数的内部实现,供大家参考
public class UDFYear extends UDF {private final SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd");private final Calendar calendar = Calendar.getInstance();private final IntWritable result = new IntWritable();public UDFYear() {}public IntWritable evaluate(Text dateString) {if (dateString == null) {return null;}try {Date date = formatter.parse(dateString.toString());calendar.setTime(date);result.set(calendar.get(Calendar.YEAR));return result;} catch (ParseException e) {return null;}}public IntWritable evaluate(DateWritable d) {if (d == null) {return null;}calendar.setTime(d.get());result.set(calendar.get(Calendar.YEAR));return result;}public IntWritable evaluate(TimestampWritable t) {if (t == null) {return null;}calendar.setTime(t.getTimestamp());result.set(calendar.get(Calendar.YEAR));return result;}}
1.4.12.3、UDAF
UDAF全称为User-defined Aggregation Function,从命名来看,这是一种聚合函数,比如像我们常用的sum、max。如下图所示,可以抽象的理解成传入多个值,最后返回给我们一个值。那么对于该类型的函数是不是一定在reduce端执行了,为什么这么说呢?你看sum函数是不是会发生shuffle,是不是在reduce端做全局聚合呢(如果你这样想也没问题,但也有问题)
我们通过explain命令来验证一下想法。我们执行如下命令:
explain select sum(id) from test

如上图所示,对于SUM类型的UDAF是在map端和reduce端都执行了,哎呦,这是怎么回事呢?我们回想一下MapReduce机制,如果我们要做全局聚合,难道要把所有的数据都拉取到reduce端吗?那reduce端压力是不是就会很大。所以有了局部聚合的这么一种优化方式。
那我们把局部聚合优化阶段给关闭后,再来看一下UDAF会在那一端执行
--关闭map端聚合set hive.map.aggr=false;

如上图所示,当我们把局部聚合优化功能给关闭后,UDAF只会在reduce执行。
1.4.12.4、UDAF编写
如UDF一样,这里给出内置Max示例函数的实现
public class UDAFExampleMax extends UDAF {static public class MaxShortEvaluator implements UDAFEvaluator {private short mMax;private boolean mEmpty;public MaxShortEvaluator() {super();init();}public void init() {mMax = 0;mEmpty = true;}public boolean iterate(ShortWritable o) {if (o != null) {if (mEmpty) {mMax = o.get();mEmpty = false;} else {mMax = (short) Math.max(mMax, o.get());}}return true;}public ShortWritable terminatePartial() {return mEmpty ? null : new ShortWritable(mMax);}public boolean merge(ShortWritable o) {return iterate(o);}public ShortWritable terminate() {return mEmpty ? null : new ShortWritable(mMax);}}static public class MaxIntEvaluator implements UDAFEvaluator {private int mMax;private boolean mEmpty;public MaxIntEvaluator() {super();init();}public void init() {mMax = 0;mEmpty = true;}public boolean iterate(IntWritable o) {if (o != null) {if (mEmpty) {mMax = o.get();mEmpty = false;} else {mMax = Math.max(mMax, o.get());}}return true;}public IntWritable terminatePartial() {return mEmpty ? null : new IntWritable(mMax);}public boolean merge(IntWritable o) {return iterate(o);}public IntWritable terminate() {return mEmpty ? null : new IntWritable(mMax);}}static public class MaxLongEvaluator implements UDAFEvaluator {private long mMax;private boolean mEmpty;public MaxLongEvaluator() {super();init();}public void init() {mMax = 0;mEmpty = true;}public boolean iterate(LongWritable o) {if (o != null) {if (mEmpty) {mMax = o.get();mEmpty = false;} else {mMax = Math.max(mMax, o.get());}}return true;}public LongWritable terminatePartial() {return mEmpty ? null : new LongWritable(mMax);}public boolean merge(LongWritable o) {return iterate(o);}public LongWritable terminate() {return mEmpty ? null : new LongWritable(mMax);}}static public class MaxFloatEvaluator implements UDAFEvaluator {private float mMax;private boolean mEmpty;public MaxFloatEvaluator() {super();init();}public void init() {mMax = 0;mEmpty = true;}public boolean iterate(FloatWritable o) {if (o != null) {if (mEmpty) {mMax = o.get();mEmpty = false;} else {mMax = Math.max(mMax, o.get());}}return true;}public FloatWritable terminatePartial() {return mEmpty ? null : new FloatWritable(mMax);}public boolean merge(FloatWritable o) {return iterate(o);}public FloatWritable terminate() {return mEmpty ? null : new FloatWritable(mMax);}}static public class MaxDoubleEvaluator implements UDAFEvaluator {private double mMax;private boolean mEmpty;public MaxDoubleEvaluator() {super();init();}public void init() {mMax = 0;mEmpty = true;}public boolean iterate(DoubleWritable o) {if (o != null) {if (mEmpty) {mMax = o.get();mEmpty = false;} else {mMax = Math.max(mMax, o.get());}}return true;}public DoubleWritable terminatePartial() {return mEmpty ? null : new DoubleWritable(mMax);}public boolean merge(DoubleWritable o) {return iterate(o);}public DoubleWritable terminate() {return mEmpty ? null : new DoubleWritable(mMax);}}static public class MaxStringEvaluator implements UDAFEvaluator {private Text mMax;private boolean mEmpty;public MaxStringEvaluator() {super();init();}public void init() {mMax = null;mEmpty = true;}public boolean iterate(Text o) {if (o != null) {if (mEmpty) {mMax = new Text(o);mEmpty = false;} else if (mMax.compareTo(o) < 0) {mMax.set(o);}}return true;}public Text terminatePartial() {return mEmpty ? null : mMax;}public boolean merge(Text o) {return iterate(o);}public Text terminate() {return mEmpty ? null : mMax;}}}
1.4.12.5、UDTF
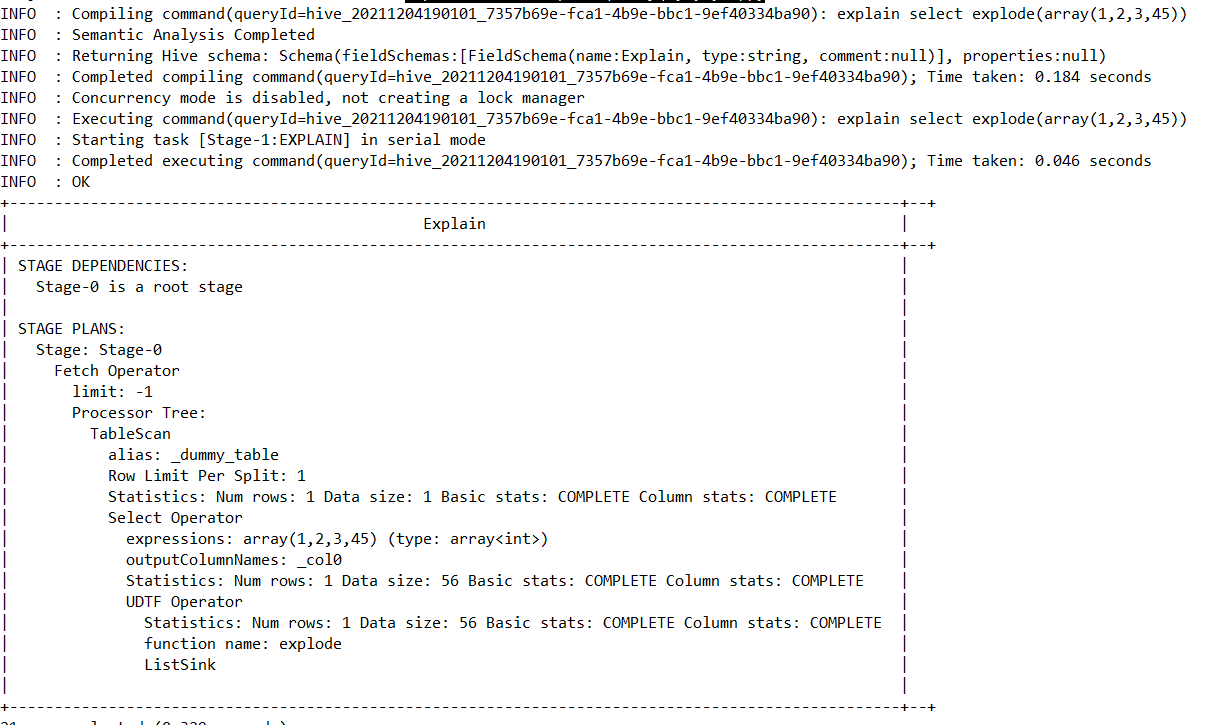
UDTF全称为User-defined Table Generating Function,该模式的功能是通过输入一行,返回多行。在实际场景中用的不多,该类型的执行阶段通常是在本地,大家也可以理解成是做map转换和UDF是一样的阶段。
我们仍然用示例sql通过explain命令来验证一下
explain select explode(array(1,2,3,45));
1.4.12.6、UDTF编写
同上面两个方式一样,给出官方的example示例供大家参考
public class GenericUDTFExplode extends GenericUDTF {private transient ObjectInspector inputOI = null;@Overridepublic void close() throws HiveException {}@Overridepublic StructObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException {if (args.length != 1) {throw new UDFArgumentException("explode() takes only one argument");}ArrayList<String> fieldNames = new ArrayList<String>();ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();switch (args[0].getCategory()) {case LIST:inputOI = args[0];fieldNames.add("col");fieldOIs.add(((ListObjectInspector)inputOI).getListElementObjectInspector());break;case MAP:inputOI = args[0];fieldNames.add("key");fieldNames.add("value");fieldOIs.add(((MapObjectInspector)inputOI).getMapKeyObjectInspector());fieldOIs.add(((MapObjectInspector)inputOI).getMapValueObjectInspector());break;default:throw new UDFArgumentException("explode() takes an array or a map as a parameter");}return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,fieldOIs);}private transient final Object[] forwardListObj = new Object[1];private transient final Object[] forwardMapObj = new Object[2];@Overridepublic void process(Object[] o) throws HiveException {switch (inputOI.getCategory()) {case LIST:ListObjectInspector listOI = (ListObjectInspector)inputOI;List<?> list = listOI.getList(o[0]);if (list == null) {return;}for (Object r : list) {forwardListObj[0] = r;forward(forwardListObj);}break;case MAP:MapObjectInspector mapOI = (MapObjectInspector)inputOI;Map<?,?> map = mapOI.getMap(o[0]);if (map == null) {return;}for (Entry<?,?> r : map.entrySet()) {forwardMapObj[0] = r.getKey();forwardMapObj[1] = r.getValue();forward(forwardMapObj);}break;default:throw new TaskExecutionException("explode() can only operate on an array or a map");}}@Overridepublic String toString() {return "explode";}}
1.5、FileFormats
1.5.1、FileFormat
对比:
1.5.1.1、Text File
每一行都是一条记录,每行都以换行符(\ n)结尾。数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
缺点:
1、磁盘开销大
2、解析不方便,如JSON/Xml,比二进制格式解析更消耗资源
3、不具备类型和模式,如数值或者日期类型的数据,无法使用mr排序,需要转换为有模式的二进制文件。
1.5.1.2、SequenceFile
Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。每个Key-Value被看作是一条记录,支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。
缺点:
1、不支持append操作,序列化后存储的kv数据不是按照key的某个顺序存储的。
2、需要合并文件,且合并后不方便查看
优点:
1、可切分
2、难度低,因为是Hadoop框架提供的API,所以业务侧修改比较简单。
1.5.1.3、RCFile
行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block,那么一个块上可能存在多个行组。其次,块数据列式存储,有利于数据压缩和快速的列存取。
一个行组包括三个部分。第一部分是行组头部的同步标识,主要用于分隔HDFS块中的两个连续行组;第二部分是行组的元数据头部,用 于存储行组单元的信息,包括行组中的记录数、每个列的字节数、列中每个域的字节数;第三部分是表格数据段,即实际的列存储数据。 在该部分中,同一列的所有域顺序存储。从图可以看出,首先存储了列A的所有域,然后存储列B的所有域等。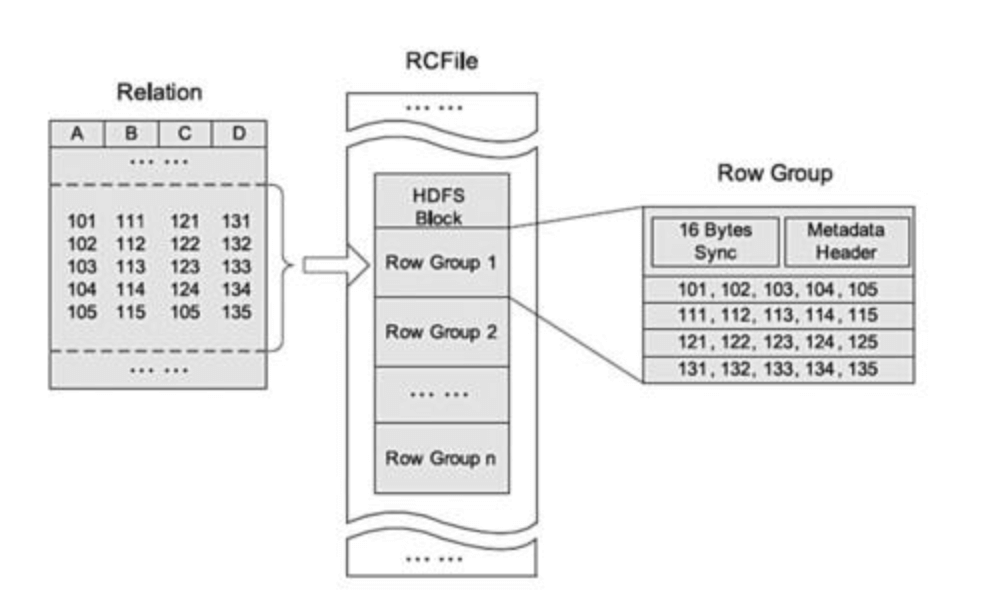
注意:
1、采用先水平划分、再垂直划分的思想。
2、RCFile对于重复的数据不会重复压缩,大大节约了存储空间。
3、RCFile默认的行组大小是4MB。
1.5.1.4、Avro Files
Avro是一个基于二进制数据传输高性能的中间件。在Hadoop的其他项目中例如HBase(Ref)和Hive(Ref)的Client端与服务端的数据传输 也采用了这个工具。Avro是一个数据序列化的系统。Avro 可以将数据结构或对象转化成便于存储或传输的格式。Avro设计之初就用来支 持数据密集型应用,适合于远程或本地大规模数据的存储和交换。
Avro的数据格式总是以易于处理的形式存储数据结构与数据。Avro可以在运行时使用这些定义以通用的方式向应用程序呈现数据,而不 是需要代码生成。
代码生成在Avro中是可选的。它在一些编程语言有时使用特定的数据结构,对应于经常序列化的数据类型是非常好用的。但是在像Pig和 Hive这样的脚本系统中,代码生成将是一种负担,所以Avro不需要它。
存储全部的数据结构定义和数据的另外一个优势是允许数据被更快更简洁的写入。Protocol Buffere 为数据添加注解,因此即使定义和数 据不完全匹配,数据仍有可能被处理。然而这些注释使得数据更大和更慢的被处理。Avro不需要这些注释,使得Avro数据比其他序列化 系统更小和更快地处理。
注意:不支持通过CTAS语法写入Avro文件,必须要先有Schema。
CREATE TABLE kstPARTITIONED BY (ds string)ROW FORMAT SERDE'org.apache.hadoop.hive.serde2.avro.AvroSerDe'STORED AS INPUTFORMAT'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'OUTPUTFORMAT'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'TBLPROPERTIES ('avro.schema.url'='http://schema_provider/kst.avsc');--hive0.14之后写法CREATE TABLE kst (string1 string,string2 string,int1 int,boolean1 boolean,long1 bigint,float1 float,double1 double,inner_record1 struct<int_in_inner_record1:int,string_in_inner_record1:string>,enum1 string,array1 array<string>,map1 map<string,string>,union1 uniontype<float,boolean,string>,fixed1 binary,null1 void,unionnullint int,bytes1 binary)PARTITIONED BY (ds string)STORED AS AVRO;
1.5.1.5、ORC (Optimized Row Columnar) Files
高效的行列存储格式。使用ORC格式,在读写方面性能都会有很大的提升。在一定程度上扩展了RCFile,并进行了优化(主要在压缩编码、查询性能方面)。相对于RCFile格式,ORC好处如下:
1、单个文件作为每个任务的输出,降低了 NameNode 的负载
2、支持Hive类型中的 datetime, decimal和复杂类型(List,Map,Struct)
3、文件存储采用了轻量级索引(稀疏索引,默认是跳过10000行)。
4、基于数据类型的块模式压缩
5、使用独立的RecordReaders并发读取同一个文件
6、无需扫描标记就可以拆分文件
7、限制读取或写入所需的内存量
8、使用协议缓冲区存储的元数据,允许添加和删除字段
存储结构:
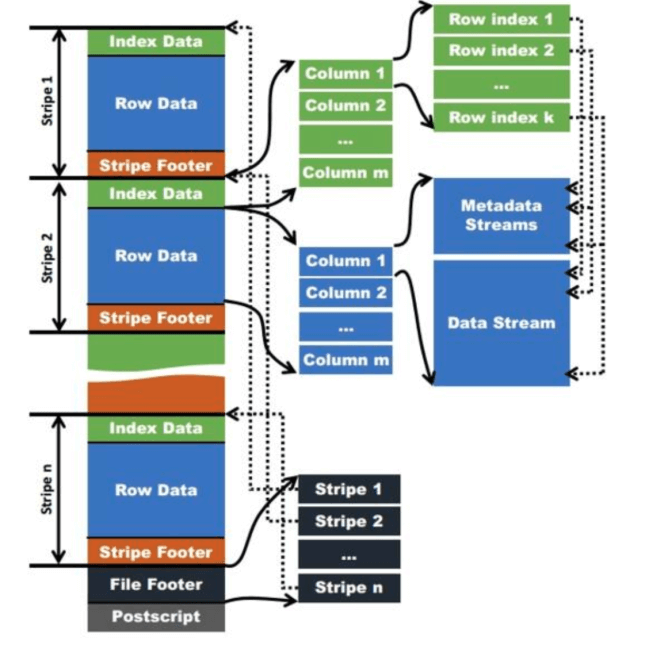
注意点:
1、Stripes默认大小是250MB.
2、File Footer包含这个文件的strips列表以及每个stripe中的行数和列类型。包含列级别的聚合计数,如sum/count/max/min
3、Stripe footer包含文件目录信息。
4、Index data包含每列的最大值和最小值。以及每列所在的行位置(还包括Bloom Filter和位字段)
三种指定文件类型
--1、参数指定SET hive.default.fileformat=Orc;--2、创建表时指定CREATE TABLE ... STORED AS ORC--3、修改表存储类型ALTER TABLE ... [PARTITION partition_spec] SET FILEFORMAT ORC
1.5.1.6、Parquet
基于Dremel数据模型算法实现的,即“record shredding and assembly algorithm”,面向列的二进制文件格式,不能直接读取。Parquet对于大型查询的类型是高效的。对于扫描特定表格中的特定列的查询,Parquet特别有用。Parquet支持压缩Snappy,gzip;目前Snappy默认。
组件交互架构:
查询引擎:Hive,Impala,Pg,Presto,Drill,HAWQ
计算框架:MR,Spark,Crunch,Kite,Cascading
数据模型:Avro,Thrif,Protocol Buffers,POJOS
数据模型:
支持嵌套数据模型,每个模型的Schema(可以理解为树结构)包含多个字段,每个字段由可以包含多个字段,每个字段有三个属性:重复数、类型、字段名
1、重复数:required(出现1次),repeated(出现0次或多次),optional(出现0次或1次)
2、类型:group(复杂类型),primitive(基本类型)
Parquet文件格式: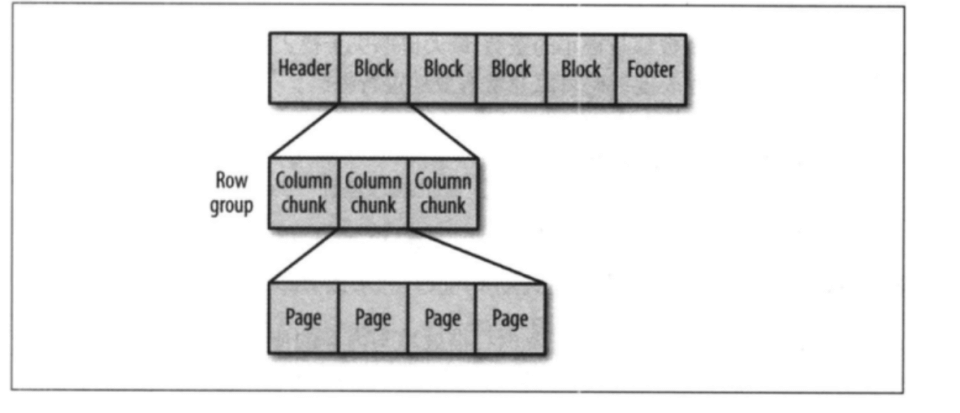
parquet文件由一个文件头(header),紧随一个或多个文件块(block),以及一个结尾文件(footer)构成。
1、文件头header包括每个文件块存储一个行组,一个行组的大小通常是一个块的大小,这个一个mapper就可以处理一个行组,增大任务执行度。
2、行组由列块构成,每个列块存储一个列的数据。
3、每个列块中的数据以页为单位,页是最小为编码单位,不同页可能用不用的编码方式。
4、parquet文件存在三种不同页:数据页、字典页、索引页
4.1、数据页用来存储当前行组中该列的值
4.2、字典页存储该列值的编码字典,每个列块最多包含一个字典页
4.3、索引页存储当前行组下列的索引。
5、parquet文件格式对于谓词下推的优化方法在于对每个行组中的每个列块,在存储的时候都会去计算对应的统计信息,比如列块的最大值、最小值和空值个数,通过这些信息可以判断该行组是否需要扫描;同时也引入了布隆过滤器以及索引等优化手段。
Metadata文件格式:
文件首位是存储的Magic Code,用来校验是否为一个Parquet文件
和ORC对比
1、Parquet支持复杂嵌套结构
2、Parquet不支持ACID和update
3、两者压缩性能差不多
4、Parquet支持的查询引擎相对丰富些。orc和hive适配性高。
1.5.1.7、JSONFILE (Hive4.0.0+)
通过hive.default.fileformat 参数配置,默认使用的是Text file.
1.5.2、Compression
通过set hive.exec.compress.output命令来查看当前系统环境支持的压缩类型。
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec
各种压缩类型对比
1.5.2.1、ORC With Zlib/Snappy
表描述配置信息:
orc.compress:压缩类型
orc.compress.size:压缩大小
orc.stripe.size:每个strips的大小
orc.row.index.stride:索引之间的行数,必须得大于1000
orc.create.index:是否创建行索引
orc.bloom.filter.columns:创建字段对应的布隆过滤器,字段之间以逗号分隔。
orc.bloom.filter.fpp:布隆过滤器的误报概率
创建表的时候指定:
TBLPROPERTIES (“orc.compress”=”ZLIB”)
TBLPROPERTIES(“orc.compress”=”SNAPPY”)
TBLPROPERTIES (“orc.compress”=”NONE”)
1.5.2.2、SequenceFile With Gzip/Bzip2
在一些场景下,可能会先生成压缩文件,然后再导入到Hive中。那么针对中这种已经压缩好的数据,Hive支持一些压缩格式,在读取的时候会自动进行解压缩。比如Gzip或者Bzip2,当然对于一些不可切分的压缩格式,在生成MR任务的时候,Map数就会有所限制,不能很好的发挥算力。
--示例CREATE TABLE raw (line STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n';LOAD DATA LOCAL INPATH '/tmp/weblogs/20090603-access.log.gz' INTO TABLE raw;
最佳实践:
针对上面提到的问题,可以先把源文件加载到一张临时表中,然后写入到支持可切分的文件存储Hive表中,如SequenceFile。
--临时表,用于存储原始压缩文件CREATE TABLE raw (line STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n';--目标表,该存储文件是可切分的。CREATE TABLE raw_sequence (line STRING)STORED AS SEQUENCEFILE;--加载数据LOAD DATA LOCAL INPATH '/tmp/weblogs/20090603-access.log.gz' INTO TABLE raw;--设置参数SET hive.exec.compress.output=true;SET io.seqfile.compression.type=BLOCK; --压缩方式 NONE/RECORD/BLOCK (see below)INSERT OVERWRITE TABLE raw_sequence SELECT * FROM raw;
1.5.2.3、LZO
配置:
编辑core-site.xml文件
<property><name>io.compression.codecs</name><value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec</value></property><property><name>io.compression.codec.lzo.class</name><value>com.hadoop.compression.lzo.LzoCodec</value></property>
创建
CREATE EXTERNAL TABLE IF NOT EXISTS hive_table_name (column_1 datatype_1......column_N datatype_N)PARTITIONED BY (partition_col_1 datatype_1 )ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS INPUTFORMAT "com.hadoop.mapred.DeprecatedLzoTextInputFormat"OUTPUTFORMAT "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat"
查询LZO存储表
SET mapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzoCodecSET hive.exec.compress.output=trueSET mapreduce.output.fileoutputformat.compress=true
1.6、External Table or Managed Table
表类型查看:
DESCRIBE EXTENDED table_name
具体见https://cwiki.apache.org/confluence/display/Hive/Managed+vs.+External+Tables
区别:
1、内部表又称为托管表,Hive管理其数据、元数据,统计信息;外部表的数据由HDFS管理,并不是只能通过Hive方式命令来操作数据。
2、基于第1条,当内部表被删除时,其数据也会删除;但外部表数据仍然存在。(Hive4.0.0通过配置external.table.purge=true可以在删除表的时候同样删除数据)
3、内部表的数据存储在hive.metastore.warehouse.dir参数配置下的路径。而外部表则对于存储位置没有限制。
4、对于CTAS语法不能应用到外部表上,或分桶表上。
CREATE TABLE page_view(viewTime INT, userid BIGINT,page_url STRING, referrer_url STRING,ip STRING COMMENT 'IP Address of the User')COMMENT 'This is the page view table'PARTITIONED BY(dt STRING, country STRING)CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETSROW FORMAT DELIMITEDFIELDS TERMINATED BY '\001'COLLECTION ITEMS TERMINATED BY '\002'MAP KEYS TERMINATED BY '\003'STORED AS SEQUENCEFILE;
5、对于archive/unarchive/truncate/merge/concatenate只能作用于内部表
6、对于事务/ACID只能作用域内部表
7、查询的结果缓存只能作用于内部表
8、当外部表的结构或者分区发生变化,需要使用msck repair table刷新元数据
1.7、Bucket
意义:
1、如果单个分区的数据量也很大,且不能更加细粒度划分数据的时候,那么这个时候就需要使用分桶再次对数据进行划分管理。
2、对于数据抽样和join操作效率(如mapjoin)会更好。
规则:
1、根据指定字段结合分桶策略进行划分。采用hash方式计算落入某个桶。
创建:
CREATE TABLE user_info_bucketed(user_id BIGINT, firstname STRING, lastname STRING)COMMENT 'A bucketed copy of user_info'PARTITIONED BY(ds STRING)CLUSTERED BY(user_id) INTO 256 BUCKETS;
基于user_id字段进行分桶,总桶数为256个。
插入:
set hive.enforce.bucketing = true; -- hive2.0+之后不需要加这个参数。早期这个参数可以自动决定reduce和bucket数量;否则需要手动设置mapre.reduce.task=256来保障reduce个数和bucket个数一致。INSERT OVERWRITE TABLE user_info_bucketedPARTITION (ds='2009-02-25')SELECTuserid, firstname, lastnameFROM user_idWHERE ds='2009-02-25';
查询使用:
--按照比例抽样SELECT * FROM source TABLESAMPLE(0.1 PERCENT) s;--按照大小抽样SELECT * FROM source TABLESAMPLE(100M) s;--按照行数抽样SELECT * FROM source TABLESAMPLE(10 ROWS);--按照指定桶数抽样SELECT * FROM source TABLESAMPLE(BUCKET 3 OUT OF 32 ON rand()) s;
1.8、Scheduled Queries(Hive4.0)
底层:
HiverServer底层会定期轮询Metastore拿到定时查询计划进行执行。
语法:
--创建定时调度CREATE SCHEDULED QUERY <scheduled_query_name><scheduleSpecification> --具体调度策略[<executedAsSpec> ] --执行人[<enableSpecification>] --是否开启<definedAsSpec> --具体的查询计划定义--修改定时调度ALTER SCHEDULED QUERY <scheduled_query_name>(<scheduleSpec>|<executedAsSpec>|<enableSpecification>|<definedAsSpec>|<executeSpec>);--删除定时调度DROP SCHEDULED QUERY <scheduled_query_name>;
对于scheduleSpecification语法:
1、基于CRON
例如:CRON ‘0 /10 ? ‘ 每10分钟执行一次
2、基于EVERY
EVERY [integer] (SECOND|MINUTE|HOUR) [(OFFSET BY|AT) timeOrDate]
例如:
EVERY 2 MINUTES
EVERY HOUR AT ‘0:07:30’
EVERY DAY AT ‘11:35:30’
对于ExecutedAs syntax语法使用:
EXECUTED AS
对于enableSpecification语法使用:
(ENABLE[D] | DISABLE[D])
对于Defined AS 的语法使用:
[DEFINED] AS
对于executeSpec的语法使用:
EXECUTE:将下次执行时间调整为现在。用于调试
*例子:
--通过hive.scheduled.queries.create.as.enabled参数来启用或禁用--每10min插入一行create scheduled query sc1 cron '0 */10 * * * ? *' as insert into t values (1);--启用执行计划alter scheduled query sc1 enabled;--等待执行或者立即执行。alter scheduled query sc1 execute;
元数据存储:
对于执行信息的保留策略通过metastore.scheduled.queries.execution.max.age参数配置。
1、information_schema.scheduled_queries:调度计划定义信息
2、information_schema.scheduled_executions:调度计划执行信息
1.9、Parameter optimization
hive参数大全
MR配置大全
1.9.1、Storage
存储层面的调优主要是针对文件压缩,序列化这些方面考虑。避免小文件的产生,同时尽量选用可切分的文件格式和压缩,充分利用算力。
1.9.1.1 Serde
--序列化相关的参数set hive.script.serdeset hive.script.recordreaderset hive.script.recordwriterset hive.default.serde
1.9.1.2 IO
1.9.1.3 Compress
1.9.2、Execute
1.9.2.1、设置合理的map和reduce task数量
map的个数取决于input端的文件个数以及大小及文件是否可切分的特性。同时需要结合集群配置的块大小设置。
1、map数调整
--确定合并文件块大小--每个map最大输入大小set mapred.max.split.size=100000000;set mapred.min.split.size=100000000;set mapred.min.split.size.per.node=100000000;set mapred.min.split.size.per.rack=100000000;--map执行前进行文件合并set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
2、reduce数调整
hive自动推测reduce个数的公式:
N = min(hive.exec.reducers.max,总输入数据量/hive.exec.reducers.bytes.per.reducer)
--直接设置reduce个数set mapred.reduce.task=?--每个reduce处理的数据量set hive.exec.reducers.bytes.per.reducer=?--每个任务最大的reduce个数set hive.exec.reducers.max=?
1.9.2.2、sql优化
1.9.2.2.1、列裁剪
1.9.2.2.2、分区裁剪
1.9.2.2.3、谓词下推
1.9.2.2.4、MapJoin使用
当出现一个小表和一个大表关联的时候,需要走MapJoin,这个可以通过参数配置让hive自动抉择是否使用mapjoin。
--设置自动选择mapjoinset hive.auto.convert.join=true;--设置大小表的阈值set hive.mapjoin.smalltable.filesize=250000000;
1.9.2.2.5、使用groupBy代替distinct
要考虑避免出现倾斜的情况
--开启map端聚合set hive.map.aggr=true;--map端聚合的记录set hive.groupby.mapaggr.checkinterval=10000;--出现倾斜的时候自动进行均衡set hive.groupby.skewindata=true;
1.9.2.2.6、四个By的选择
sort by:只能保证分区内有序distribte by:只是决定分配到reduce的方式。cluster by: distribute by + sort by 的结合实现order by:全局有序,只能保证有一个reduce用来全局排序扩展:全局有序的实现1、sort by + order by该种实现缓解了只使用order by 产生一个reduce的问题。先通过使用sort by 使得每个分区内部有序,然后再使用order by 对所有的分区进行全排序2、sort by + distribute byselect * from tabdistribute by (case when age>23 then 1 else 0 end)sort by age
1.9.2.2.7、向量化查询
开启向量化功能,可以提高执行效率。批量执行代替单次执行。
set hive.vectorized.execution.enabled=true;set hive.vectorized.execution.reduce.enabled=true;
1.9.2.2.8、模式选择
1、对于小数据集的处理,可以选择使用本地模式执行。
通过配置参数hive.exec.mode.local.auto=true,由hive自动执行优化。但需要满足以下几个条件:
1、job的输入数据必须小于参数:hive.exec.mode.local.auto.inputbytes.max
2、job的map数必须小于参数:hive.exec.mode.local.auto.tasks.max
3、job对应的reduce数必须为0或者1;
2、另对于一些Fetch抓取任务是没有必要走MR计算的。
设置hive.fetch.task.conversion=more;在全局查找、字段查以及limit查询都不会走mr.
对于其参数值有以下几种:
1、none:禁用该效果,所有的查询都会走mr程序
2、minimal:只在select 、分区列过滤、含有limit的语句上不走mr。也就是说比较简单的select查询是不走mr程序
3、more:相对于minimal效果,select不仅仅是,还可以单独选择某几列,而且filter也不再限制分区字段,同时支持虚拟列。
1.9.2.2.9、尽量使用相同的连接键
*1.9.2.2.10、开启CBO优化
开启该优化功能,可以在逻辑计划优化阶段基于代价分析自动的选择最优的算法。
set hive.cbo.enable=true;set hive.compute.query.using.stats=true;set hive.stats.fetch.column.stats=true;set hive.stats.fetch.partition.stats=true;
1.9.2.3、避免小文件
合并输出参数
--是否合并map端输出文件set hive.merge.mapfiles=true;--是否合并reduce端输出文件set hive.merge.mapredfiles=false--合并文件大小set hive.merge.size.per.task=256*100*100;--map执行前进行文件合并set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;--当输出文件平均大小小于设置值时,会启动一个独立的MR任务去合并set hive.merge.smallfiles.avgsize=1600000
1.9.2.4、JVM复用
通过配置mapred.job.reuse.jvm.num.tasks来设置。
1.9.2.5、并行执行
sql查询会转化为一个或多个阶段。如果某些阶段之间没有依赖关系,那么可以并行执行。
开启并行执行:set hive.exec.parallel=true
设置并行度:set hive.exec.parallel.thread.number=8
1.9.2.6、推测执行
推测执行会对重复执行一些任务,为了保证任务能够尽快的获取数据以及增加job的稳定性,不会因为部分task失败导致任务失败。
set mapred.map.tasks.speculative.execution=true;set mapred.reduce.tasks.speculative.execution=true;
1.10、Problem
1.10.1、倾斜
1.10.1.1、理解倾斜本质
数据分布不均匀,导致部分task处理大量的数据量。
1.10.1.2、如何定位倾斜
方法1、通过yarn log上输出的key信息进行查看。
方法2、采用分桶取样的方式,提取topN对应的key并再次进行量级统计
1.10.1.3、倾斜场景及解决方案
1.10.1.3.1、shuffle阶段key的分配不均导致部分reduce处理大量数据
1、空值/无用数据/脏数据可直接过滤
2、数据类型不同(根据key分配的原理:hash值),统一类型关联
3、Join 关联键倾斜。
3.1、如果是部分key造成的倾斜,可以单独拿出来进行计算
3.2、如果是大量的key造成的情况,可以采用二次聚合的方式(有一定的限制,只能是一些聚合统计操作,如sum/min/max;非聚合类操作产生结果会有问题,比如说Join)。
3.3、针对3.2的一些限制,可以采用扩容的操作,即key前缀增加n个数,非倾斜部分数据要扩大N倍。这种操作也有一定的局限,对于扩大N倍的数据,其数据量不能很大。
3.4、如果是大表Join小表,那么就走mapJoin。不过现在大部分对于mapjoin的开关都是启用的,无非变更是具体多大数据量才算是小表,这个参数是用户可以控制的。
3.5、针对3.3的限制,那么可以增加reduce个数,减少reduce端处理的key个数。
1.10.1.3.2、源头文件不可切分,部分map处理大量数据
1、对于一些压缩且不可切分的存储文件,那么会造成一个map读取一个文件。如果文件大小分布不均匀的话,会造成map端处理时间拉长。
解决方案:源头改用可切分的压缩算法,或者产生一张临时表进行转换。
1.10.2、小文件
1.10.2.1、源头产生
在计算前对源头进行合并处理操作。
解决方案:
1、archive归档(也可以使用hive自带的archive命令)。
使用和hdfs一样(不支持修改重命名),但是uri不一样。
hadoop archive -archiveName archiveName -p PartentDir [-r 复制因子] sourcePath(multi) targetPath
2、SequenceFile
由一系列二进制key/value组成,key为小文件名,value为文件内容。可以将大批小文件合并成一个大文件。
3、使用CombineFileInputFormat格式类型(hive通过参数配置)
将多个小文件打包到一个分片,同时会考虑到数据所在的位置,避免过多的数据传输。需要写MR,自定义InputFileformat
1.10.2.2、计算过程产生
根据1.9.2.3提到的避免小文件问题进行解决,设置参数,合并中间过程发生的小文件。
1.10.2.3、计算结果产生
当输出的时候,会产生小文件的场景:
1、首先要知道的是文件输出的个数是根据reduce个数决定的;因此可以通过参数配置调整reduce数量。
2、动态分区下产生的小文件;假设动态分区产生了N个Mapper,最后生成了M个分区,那么最后生成的文件为NM,可以使用distribute by关键词进行数据打散,保证reduce端的数据分配均匀。
1.10.3、UDF Jar Not Found
1.10.4、权限问题
1.10.5、数据错位
1.10.6、正则匹配转义问题
1.10.7、新增字段为NULL
1.10.8、时区问题
1.10.9、Spark共用数据,元数据不共享问题
**1.10.10、select count(1) 查询有数据,select from 无数据
1.11、Hive Dynamic Partition Limit**
hive.optimize.sort.dynamic.partition
背景:hive动态分区为什么要限制分区个数?
动态分区因为会在短时间内创建大量的分区,可能会占用大量的资源
1、内存方面:在Insert场景下,每个动态目录分区写入器(File Writer)至少会打开一个文件,特别是对于parquert或者orc格式的文件,在写入的时候会首先写到缓冲区中,而这些缓冲区是按照分区来维护的,在运行的时候需要的内存量会随着分区数增加而增加。所以经常导致OOM的mapper或者reduce,可能是由于打开的文件写入器的数量。如常见的错误:Error: GC overhead limit exceeded,针对该问题,对应的解决方案如下:
1.1、可开启hive.optimize.sort.dynamic.partition参数
1.2、增加mapper端的内存,设置mapreduce.map.memory.mb和mapreduce.map.java.opts
2、文件句柄:如果分区数过多,那么每个分区都会打开对应的文件句柄写入数据,可能会导致系统文件句柄占用过多,影响系统其他应用运行。因此hive又提出了一个hive.exec.max.created.files参数来控制创建文件数量(默认是100000)

若有收获,就点个赞吧
0 人点赞
