- 2.1、Spark Core
- 2.1.2、RDD
- 2.1.3、Partition
- 2.1.4 By
- 2.1.5、SparkContext
- 2.1.6、Shuffle
- 2.1.7、Cache&Checkpoint&Broadcast&Accumulate
- 2.1.8、Memory Model
- 2.1.8.5、Memory addressing
- 2.1.8.6、Memory Configuration
- 2.1.8.7、Tungsten Optimize-CPU
- 2.1.8.8、Demo of Memory Divison
- 2.1.8.9、Optimize Configuration
- 2.1.9、Optimize—->Submit
- 2.1.9.0、Spark On Yarn
- 2.1.9.1、Optimize—->Operator&RDD
- 2.1.9.1.1、使用mapPartitions或者mapPartitionWithIndex代替map操作。
- 2.1.9.1.2、使用foreachPartition代替foreach
- 2.1.9.1.3、使用coalesce代替repartition,避免不必要的shuffle
- 2.1.9.1.4、使用repartitionAndSortWithinPartitions取代repartition和sort联合操作
- 2.1.9.1.5、使用treeAggregate代替Aggregate
- 2.1.9.1.6、使用treeReduce代替reduce
- 2.1.9.1.7、使用AggregateByKey代替groupByKey(减少不必要的数据传输,可提前进行combine)
- 2.1.9.1.8、RDD复用
- 2.1.9.1.9、广播变量使用
- 2.1.9.1.10、使用kryo代替默认的序列化器
- 2.1.9.1.11、使用FastUtil优化JVM数据格式解析(性能上提升不会很大)
- 2.1.9.1.12、Persist和Checkpoint
- 2.1.9.1.13、序列化问题
- 2.1.9.2、Optimize—->Parallelity&Resouce allocate
- 2.1.9.3、Optimize—->Mapper/Reducer
- 2.1.9.4、Optimize—->JVM On Compute
- 2.1.9.5、Optimize—->Shuffle On Compute
- 2.1.9.6、Optimize——>Data Skew
- 2.2、Spark SQL
- 2.2.1、Execute Engine
- 2.2.2、Join Type
- 2.2.2.1、Broadcast Hash Join (Not Shuffled)
- 2.2.2.2、Broadcast Nested Loop Join (Fallback option)
- 2.2.2.3、Shuffle Hash Join(Single Partition is small engough to build a hash table)
- 2.2.2.4、Shuffle Sort Merge Join (Matching join keys are sortable)
- 2.2.2.5、Cartesian Product Nested Loop Join
- 2.2.2.6、Conclusion
- 2.2.3、Optimize
- 2.3.0、Overview
- 2.3.1、Receiver
- 2.3.2、Window Operations
- 2.3.3、Stream Join
- 2.3.4、Output Operations On DStreams
- 2.3.5、DataFrame And Sql Operations
- 2.3.6、BackPressure
- 2.3.7、Fault Tolerance
- 2.3.8、Upgrading Application
- 2.3.9、Monitor
- 2.3.10、Elegant Start And Stop
- 2.3.11、Small File
- 2.3.12、Optimize
- 2.3.12.1、Reduceing the Batch Processing Time —> batchDuration
- 2.3.12.2、Reduceing the Batch Processing Time —> Parallelism
- 2.3.12.3、Reduceing the Batch Processing Time —> Kryo Serializable
- 2.3.12.4、Reduceing the Batch Processing Time —> Task Launching Overheads
- 2.3.12.5、Right Batch Interval——> Cache Data & Compress
- 2.3.12.6、Right Batch Interval——> Clean Data
- 2.3.12.7、Right Batch Interval——> GC
- 2.3.12.8、Right Batch Interval——> CPU
2.1、Spark Core
2.1.1、Overall Architecture&Run Schema
2.1.1.1、schema
具体流程:
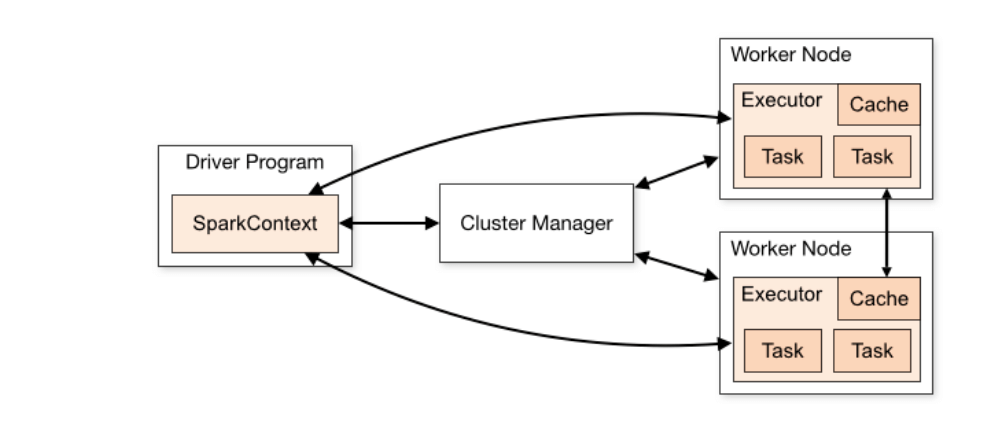
从运行的角度来看,主要包括Master、Worke、Executor、Driver和ExecutorBackend.具体流程如下:
1、构建Spark程序运行环境,即初始化SparkContext后,向ClusterManager进行注册,并申请资源
2、ClusterManager接收到程序后,会分配一个ID,同时会分配具体的计算资源并在对应的Worker节点上启动Executor进程
3、Executor启动后会定期发送心跳给Driver
4、SparkContext构建DAG,然后把DAG划分多个stage,并把每个Stage中的TaskSet发送给TaskScheduler。
5、Executor向SparkContext申请Task,TashScheduler会把Task分发给Executor执行
6、Executor端执行Task,并把执行结果反馈给TaskScheduler,然后向上反馈给DAGSchedler。
7、当所有stage执行完后,SparkContext向ClusterManager注销释放资源。
该架构有以下几个特点:
1、每个应用程序都有自己独立的进程,且在多个线程中运行任务,减少了多进程频繁启动切换的开销。这样独立的好处在于每个程序在独立的JVM中调度各自的任务,从资源层面上的隔离结合执行调度层面的隔离保证每个应用相互独立,提高其稳定性。
2、Spark服务和集群管理器无关,只要能够获取到executor进程使其执行任务,并且进程间可以互相通信,那么底层采用什么样的管理器(如mesos/yarn)都是可以的。
3、驱动程序必须能够在其整个生命周期内监听并接受来自executor的通信。
4、优先数据本地化和推测执行计算。尽量减少数据网络传输。
5、Executor上的BlockManager提供了内存和磁盘的共同存储机制,所以在迭代计算产生中间结果的时候不需要存储到分布式系统中,这样后续可以直接读取中间结果,避免了网络IO或者磁盘IO。
2.1.1.2、Launching Spark On Yarn
1、Yarn On Cluster
1、当客户端提交Spark任务之后,其会跟RM进行通信,会在AM上启动Driver。此时应用后续的动作都不会局限于客户端,客户端的退出不会影响应用的执行。
2、 该模式下,Driver运行在AM中,负责向Yarn申请资源,并监控作业的运行状况
3、该种模式适用于线上操作
2、Yarn On Client
1、当客户端提交Spark任务之后,会其客户端启动Driver,然后申请资源启动task,此时客户端不能退出,否则应用就会被kill掉。
2、AM只负责向Yarn申请资源,告诉NodeManager为其启动Container,产生Executor。
3、该种模式适用于测试调试使用。
提交参数
./bin/spark-submit --class org.apache.spark.examples.SparkPi \--master yarn \--deploy-mode cluster \--driver-memory 4g \--executor-memory 2g \--executor-cores 1 \--queue thequeue \examples/jars/spark-examples*.jar \--jars my-other-jar.jar,my-other-other-jar.jar \10
2.1.2、RDD
2.1.2.1 Feature
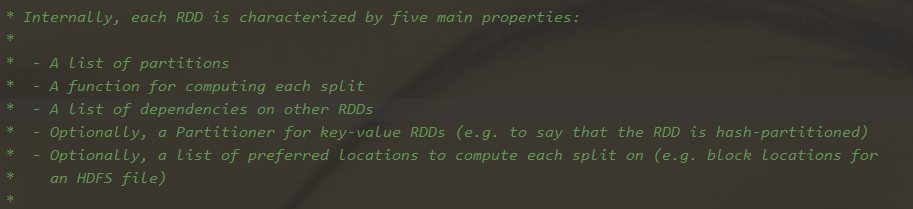
1、可分区
RDD是可以被分区的,每一个分区被一个Task处理,分区数决定了并行度,并行度默认从父RDD传递给子RDD。
默认情况下,HDFS上的一个数据块就是一个分区。
2、存储位置信息(即优选位置)
每个RDD都会有一个优先位置列表,用来存储每个分区的优先位置
3、存储依赖列表
RDD每次转换都会生成新的RDD,所以RDD之间会形成依赖关系,对于这种关系,RDD会进行存储,这样当发生错误的时候可以从上一个RDD中进行恢复,这样保证了容错,对于RDD的容错又分为了几种情况。
DAG层面
即当Stage输出失败的时候,那么DAGScheduler就会进行重试
Task层面
当内部的task失败时,会根据底层的调度器进行重试
当然对于RDD之间的依赖类型又分为窄依赖和宽依赖,主要区别在于是否会发生shuffle。
窄依赖:父RDD的一个分区最多只能被一个子RDD的一个分区使用
宽依赖:父RDD的一个分区可以被多个子RDD的分区依赖;如groupByKey、SortBykey算子
4、分区器
分区器的使用只针对于KV类型的RDD,也就是说对于非KV类型的RDD没有具体的分区器。对于分区器的分配策略,目前有两种:
两种策略:
1.1、Hash
1.2、Range
5、可计算
每个RDD是有一个compute函数,并且是以分片为基本单位执行具体的业务逻辑进行计算的。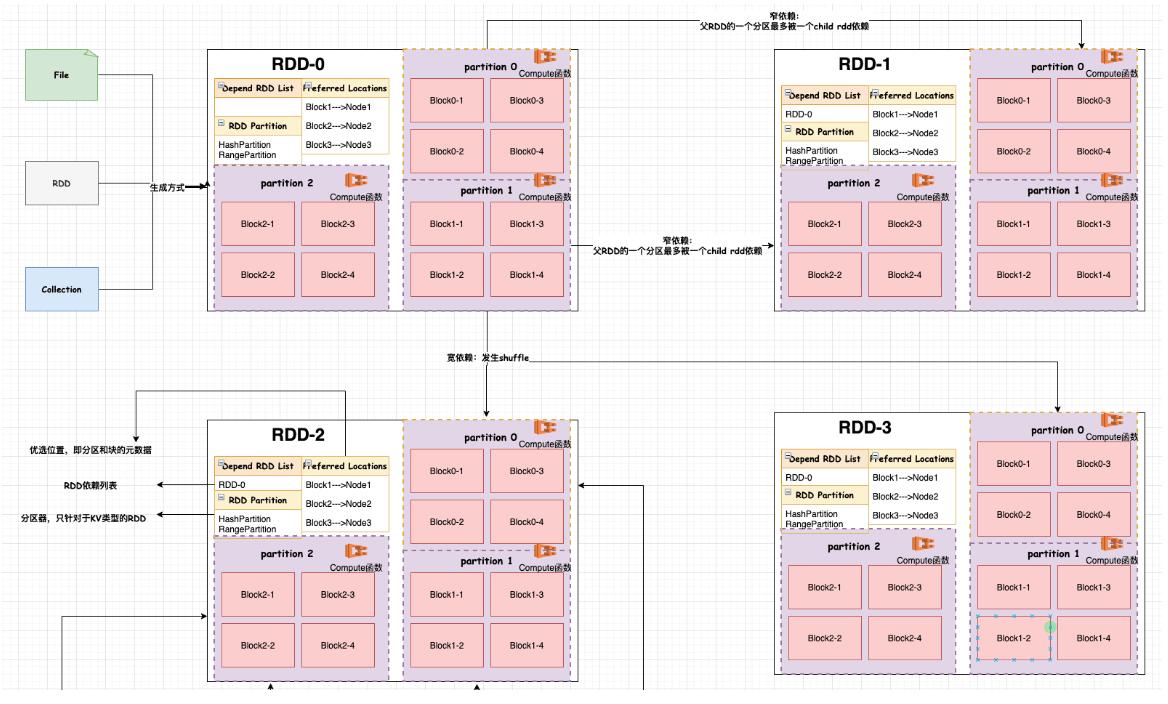
2.1.3、Partition
2.1.3.1、coalesce
重分区,默认不进行shuffle。至于是否要进行shuffle,要根据具体 场景分析:
1、如果源分区数S>目标分区数T,则一般不会进行shuffle。比如从1000个分区数进行重新分配到100个分区,那么就不会发生shuffle。
2、如果源分区数S>目标分区数T,且是一种极端的合并,比如从1000个分区数进行重新分配到几个分区,那么这个时候可能会造成运行节点IO异常甚至OOM,所以为了避免这种情况发生,可以设置shuffle=true
3、如果源分区数S<目标分区数T,那么这个需要分两种情况:
3.1、当设置shuffle=false时候不会发生shuffle,最后得到S个分区。比如从100个分区重复分配到1000个分区,最后得到100个分区
3.2、当设置shuffle=true时会发生shuffle,最后得到T个分区。比如从100个分区重复分配到1000个分区,最后得到1000个分区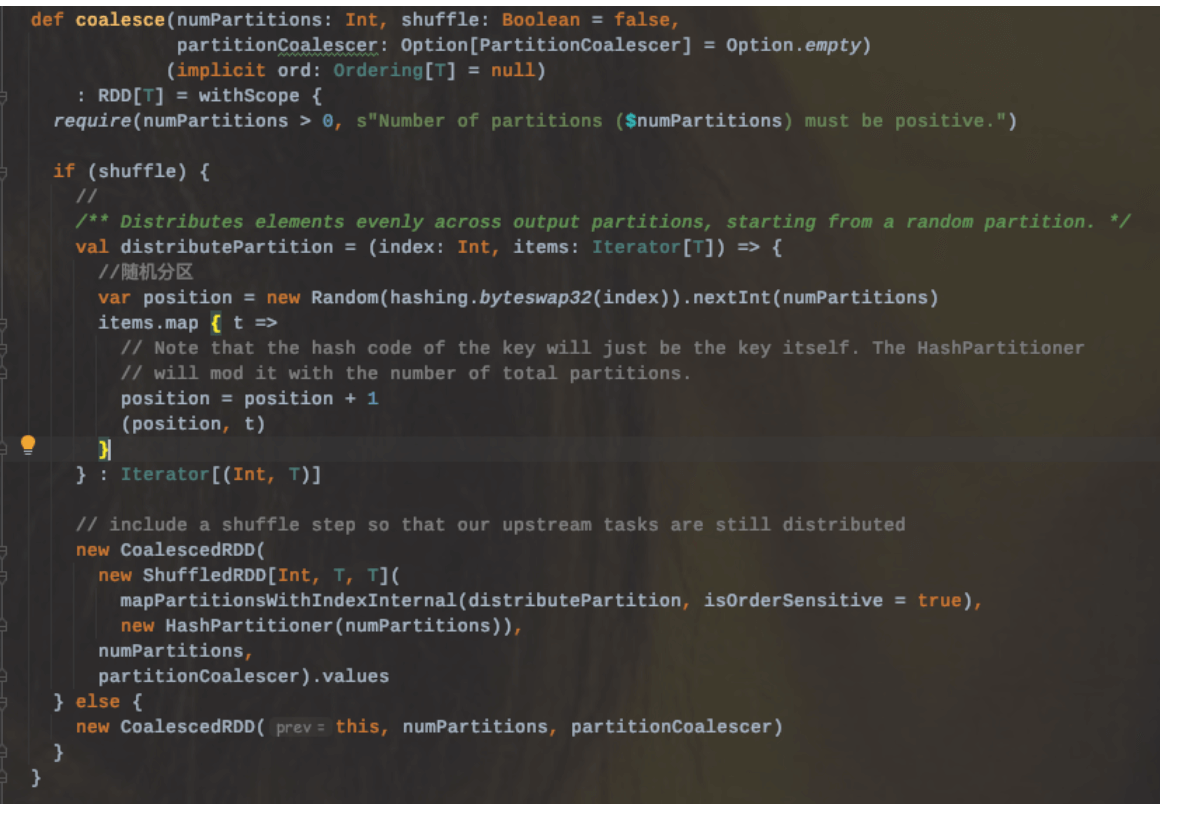
2.1.3.2、repartition
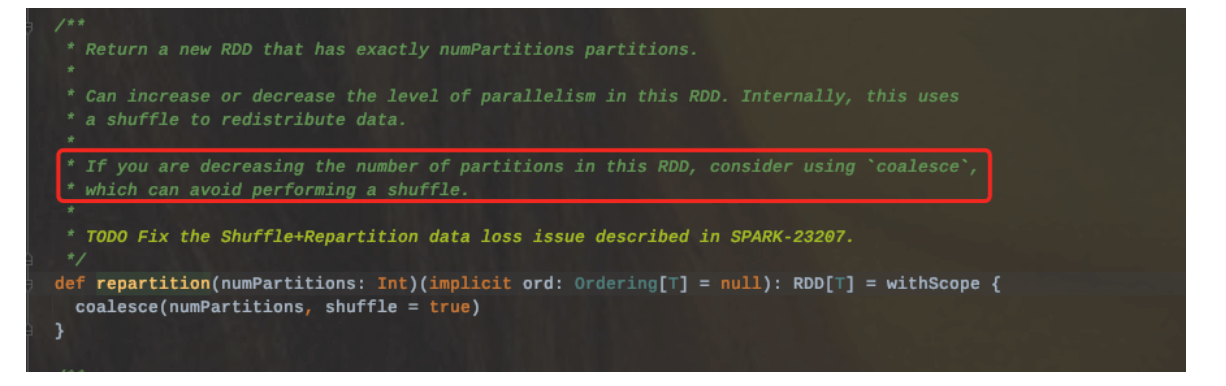
repartition可以增加或者减少RDD并行度。底层其实调用的就是coalesce(numPartitions,shuffle=true),使用hash随机分区;
所以在使用repartition的时候,一定会发生shuffle的。
因此如果要减少分区数的时候,使用coalesce(shuffle=false)会避免shuffle发生。
2.1.4 By
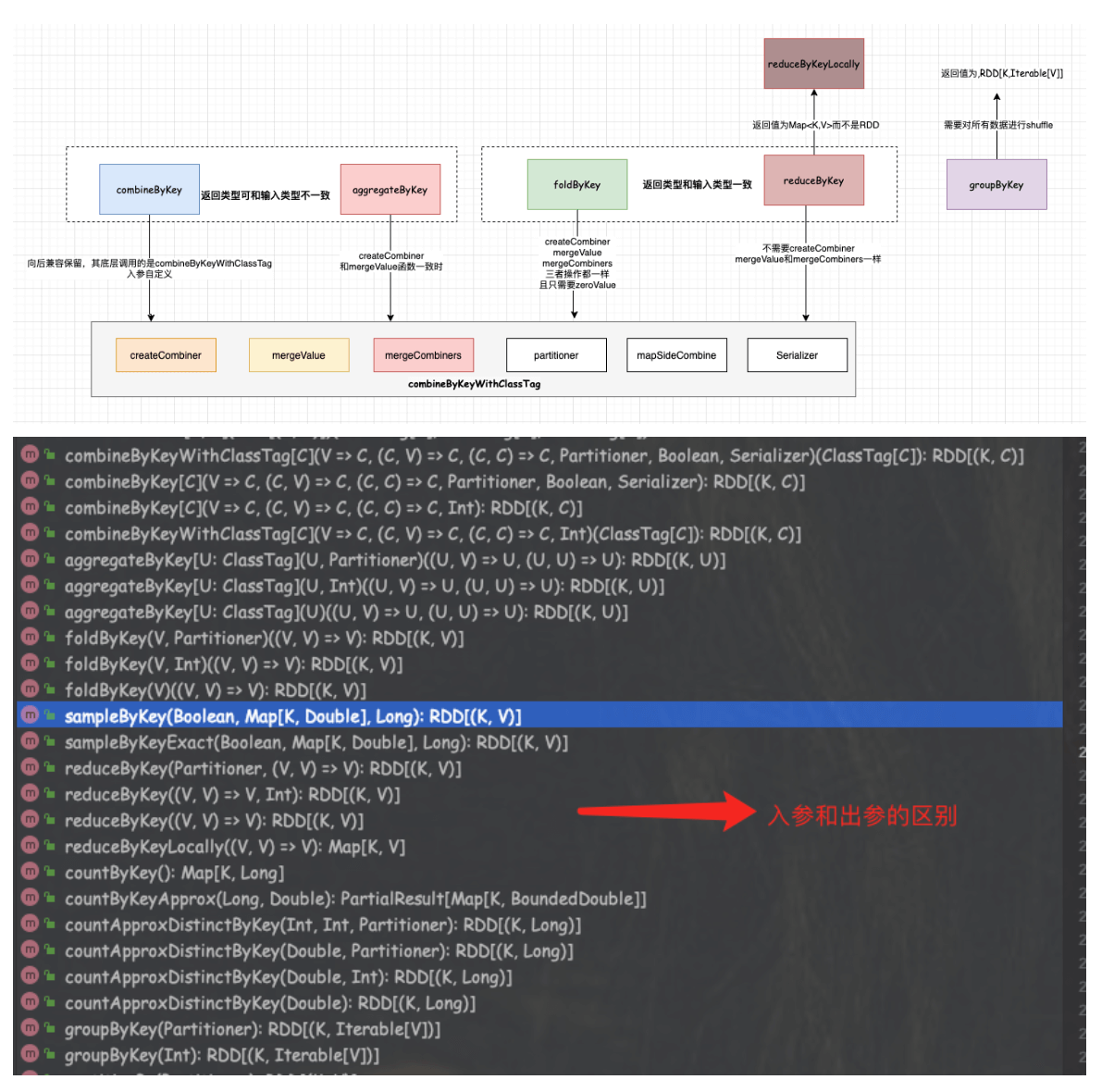
2.1.4.1、combineByKey
功能:使用一组自定义聚合函数来组合每个键元素的通用函数。
返回:将RDD[K,V]转换成RDD[K,C]
操作:底层其实也是调用的combineByKeyWithClassTag
def combineByKey[C](//类似于一个初始化操作来创建key对应的累积器的初始值。(每个分区会有多个,这跟key是不是第一次在分区内出现有关)createCombiner: V => C,//合并同一个分区内的值mergeValue: (C, V) => C,//合并多分区的值mergeCombiners: (C, C) => C): RDD[(K, C)] = self.withScope {combineByKeyWithClassTag(createCombiner, mergeValue, mergeCombiners)(null)}
2.1.4.2、groupByKey
功能:将RDD中的每个Key进行分组到一个序列集合中
返回:RDD[(K, Iterable[V])]
操作:其实就是按照一定分区规则进行分组,将相同的key的value组装到一个序列中去,然后不保证组内有序的。这个操作比较耗资源,如果一个key对应的value非常多,那么很容易出现OOM。所以一般使用reduceByKey或者aggregateByKey来替代。
2.1.4.3、reduceByKey(Lazy)
功能:使用关联和可交换的归约函数合并每个键的值;分区内聚合和分区见聚合的逻辑一样。
返回:RDD[(K, V)]
操作:这个算子在将结果发送到reduce端之前会先在本地进行合并,类似于MR中的Combiner功能。底层会调用combineByKeyWithClassTag
2.1.4.3.1、reduceByKeyLocally
区别:和reduceByKey的区别在于返回的结果值不是一个RDD[K,V],而是一个Map[K,V]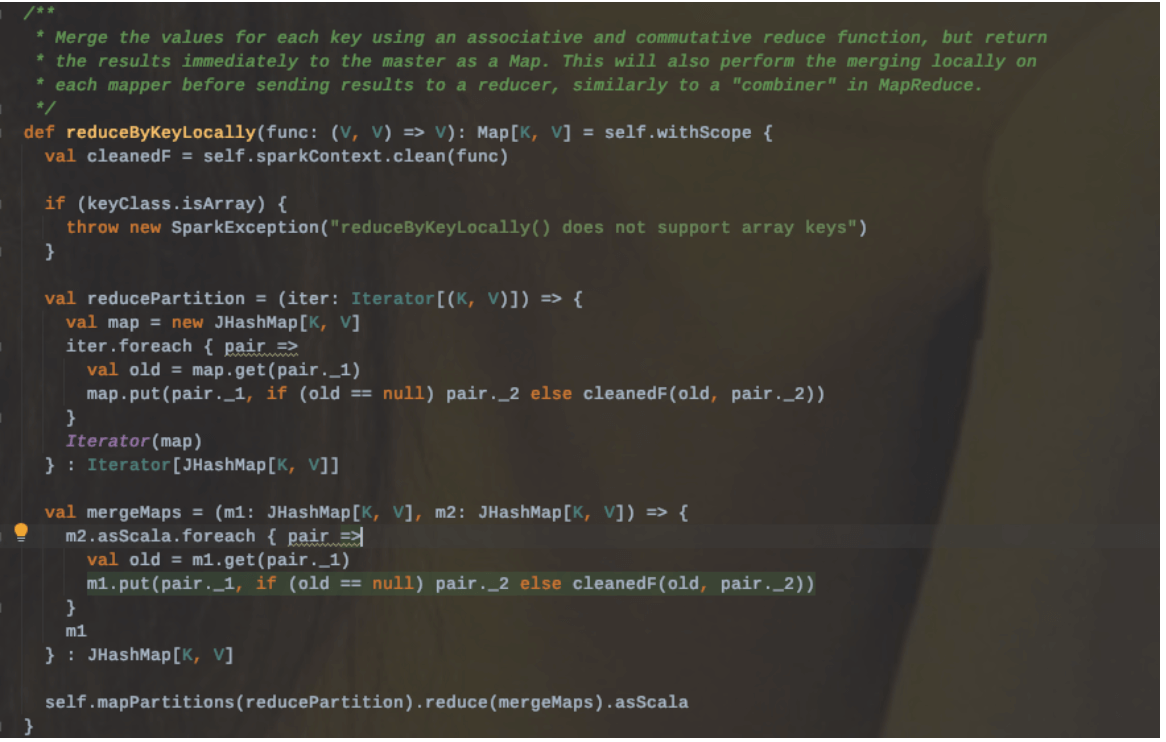
2.1.4.4、aggregateByKey
功能:使用给定的组合函数和默认/中性值(比如0)聚合每个键的值
返回:返回结果的类型可能会和值的类型不一样。即可以返回和这个RDD V中的值类型不同的结果类型U
操作:首先会合并分区内的值(即mergeValue),然后再合并分区之间的值(mergeCombiners)。其实底层会调用combineByKeyWithClassTag。
在内部调用了一个cleanedSeqOp(createZero(), v)函数,其实这个函数的功能跟combineByKey中的createCombiner功能一样。该函数同时也是mergeValue。也就是说当createCombiner和mergeValue函数相同的时候,使用aggregateByKey代替combineByKey比较合适。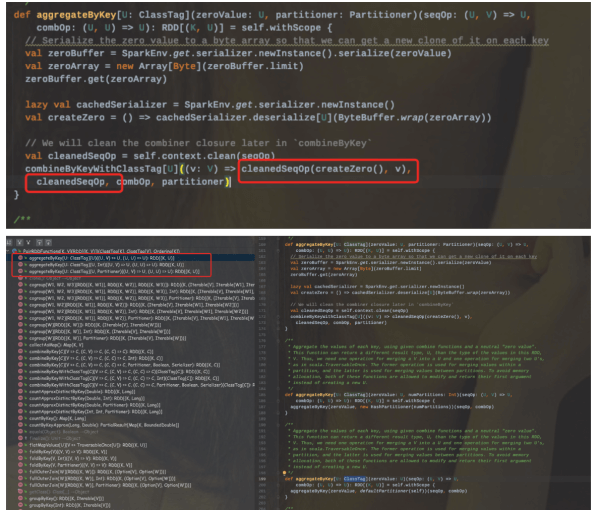
2.1.4.5、foldByKey
功能:使用关联函数和中性的“零值”合并每个键的值,可以将其添加到结果中任意次数,并且不得更改结果;相对于aggregateByKey来说局部聚合和全局聚合的规则是一样的,而aggregateByKey对应的局部聚合和全局聚合的规则可以不一样。和reduceByKe相比,多了一个0值处理的功能。
返回:用于RDD[K,V]根据K将V做折叠、合并处理。
操作:其中第一个参数zeroValue会先应用到Value值中做初始化操作,然后再将func应用于初始化之后的value值上。
2.1.4.6、VS
2.1.5、SparkContext
SparkContext可以说是spark框架中最为重要的一部分。为什么这么说呢?我们以spark应用的生命周期为例子来阐述一下。
1、应用提交时期
当我们把应用程序打包部署提交到集群时,那么首先要做的事情就是要实例化SparkContext,并初始化应用程序运行时所用到的一些组件,比如说DAGScheduler、TaskScheduler、SChedulerBackend。同时程序启动时还会向Master注册,那么这个工作也是由SparkContext完成的。
2、应用计算时期
当程序提交之后,获取到资源就开始真正的计算了,那么在计算的过程中需要分发Task,task在执行的过程中需要监控其运行状态,以及中间的资源分配释放等动作。那么这一切的操作其都是在SparkContext为核心的调度指挥下进行的。
3、应用结束时期
当所有的task执行完成之后,也就意味着应用程序的结束,那么这个时候sparkContext就是关闭代表着资源的释放。
因此SparkContext贯穿着应用程序的整个生命周期,可想而知其重要程度。
2.1.6、Shuffle
2.1.6.0 Shuffle Read And Write
MR框架中涉及到一个重要的流程就是shuffle,由于shuffle涉及到磁盘IO和网络IO,所以shuffle的性能直接影响着整个作业的性能。Spark其本质也是一种MR框架,所以也有自己的shuffle实现。但是和MR中的shuffle流程稍微有些不同(Spark相当于Mr来说其中一些环节是可以省略的),比如MR中的Shuffle过程是必须要有排序的,且不能省略掉,但Spark中的Shuffle是可以省略的;另对于MR的Shuffle中间结果是要落盘的,而对于Spark Shuffle来说,可以根据存储策略存储在内存或者磁盘中。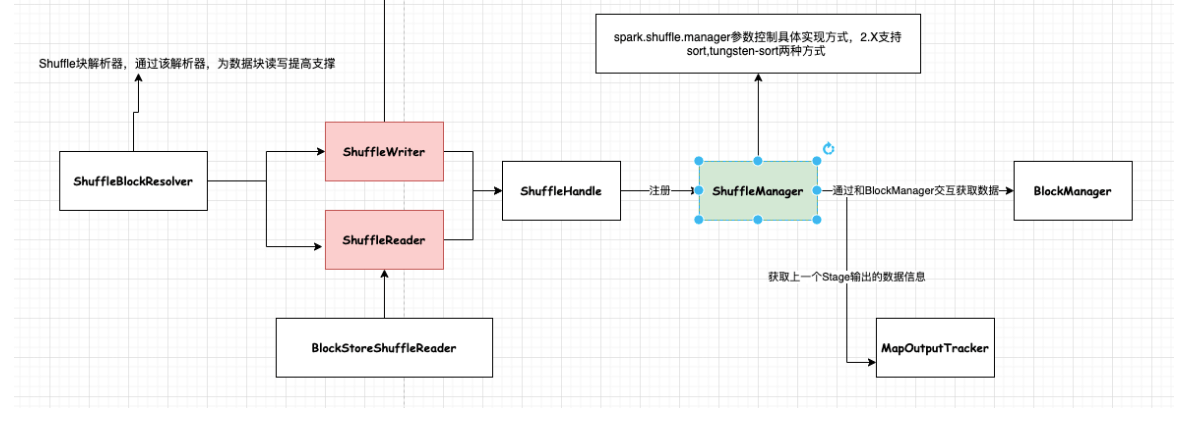
Shuffle阶段中涉及到一个很重要的插拔式接口ShuffleManager,该接口可以作为一个入口,可以获取用于数据读写处理句柄ShuffleHandle,然后通过ShuffleHandle获取特定的读写接口即ShuffleWriter和ShuffleReader,以及获取块数据信息解析接口ShuffleBlockResolver。
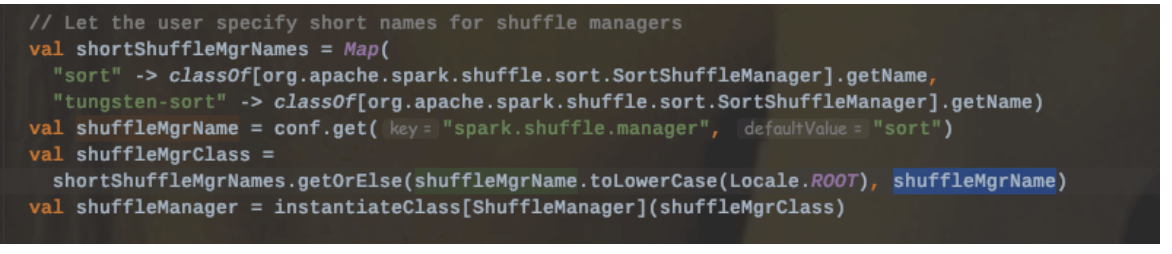
目前Spark提供了两种ShuffleManager:sort和tungsten-sort
2.1.6.0.1、Shuffle Writer
Shuffle写数据的时候,在内存中是有一个Buffer缓冲区,同时本地磁盘也有对应的文件(具体位置可以通过spark.local.dir配置);因此该部分内存中主要被两部分内容所占用:1、存储Buffer数据;2、管理文件句柄。
如果shuffle过程中写入大量的文件,那么内存消耗也是一种压力,很容易产生OOM,频繁GC。
扩展:关于GC引发的shuffle fetch不到文件
有那么一种现象:即Reduce端的Stage去拉取上一个Stage的产生结果,但是因为找不到文件而抛出异常,其实并不是不存在,而是可能由于正在进行GC操作而未回应。
Spark2.X提供了三种Shuffle Writer模式:
2.1.6.0.1.1 BypassMergeSortShuffleWriter
该种模式是带了Hash风格的基于Sort的Shuffle机制,为每个reduce端生成一个文件。
适用场景:该种模式适用于分区数比较少的场景下,可以作为一种优化方案。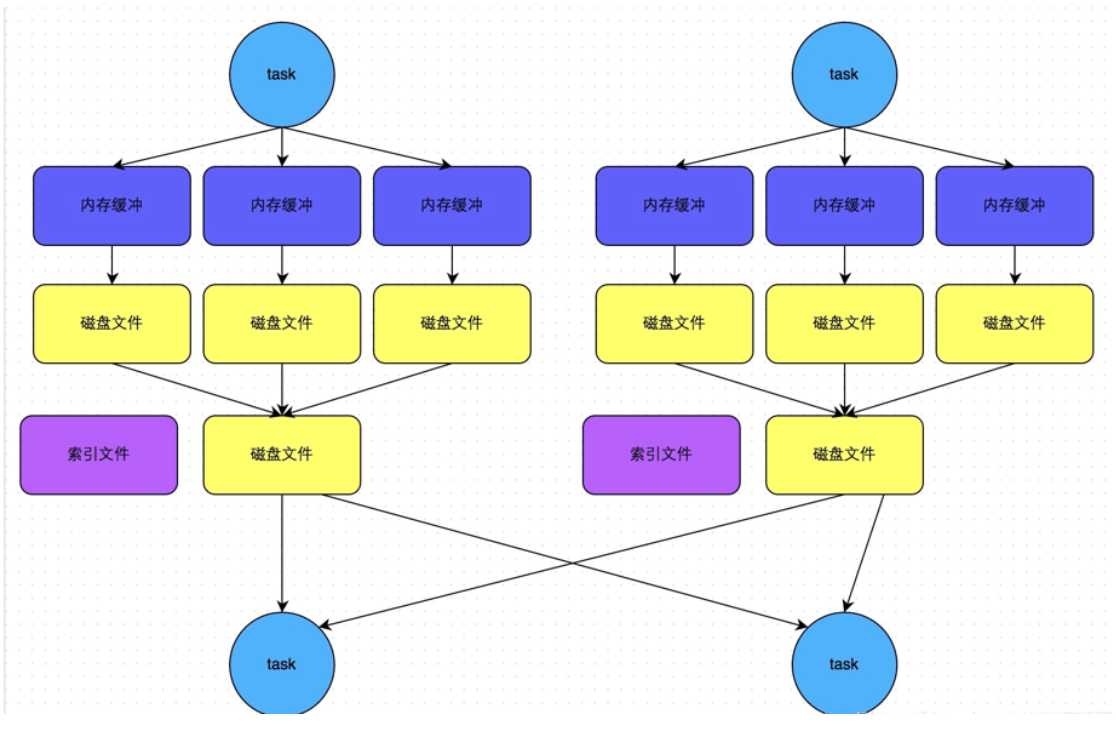
上图的合并机制即就是BypassMergeSortShuffleWriter的部分流程。
写入文件命名: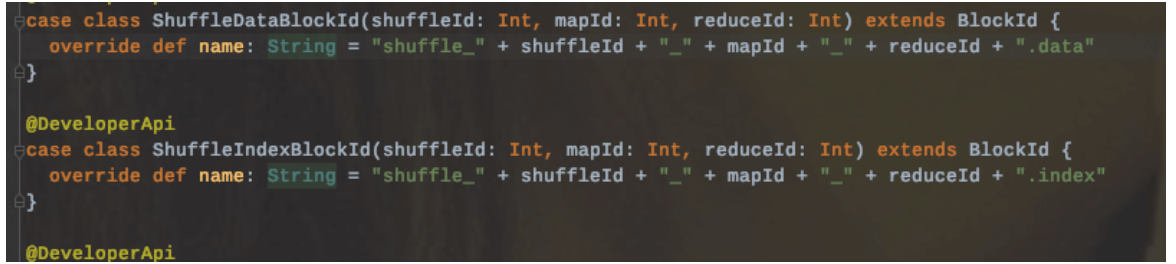
该种模式的缺点:
1、不能使用aggregator,以32条记录批次直接写入的(通过spark.shuffle.file.buffer参数配置),所以会造成后续的网络IO开销比较大。
2、每个分区都会生成一个对应的磁盘写入器DiskBlockObjectWriter,先对每个reduce产生的数据写入临时文件中,最后合并输出一个文件。所以分区数不能设置过大,避免同时打开过多实例加大内存开销
3、不能指定Ordering,也就是说该种模式的排序是采用分区Id进行的,分区内的数据是不保证有序的。
2.1.6.0.1.2 SortShuffleWriter
流程:
1、Sort Shuffle Writer模式首先会实例化一个ExternalSorter,根据是否在map端聚合来决定是否在实例化的时候传入aggregator和Ordering变量。
2、把所有的记录放到外部排序器中ExternalSorter(会调用Sorter.insertAll和writePartitionedFile两个方法)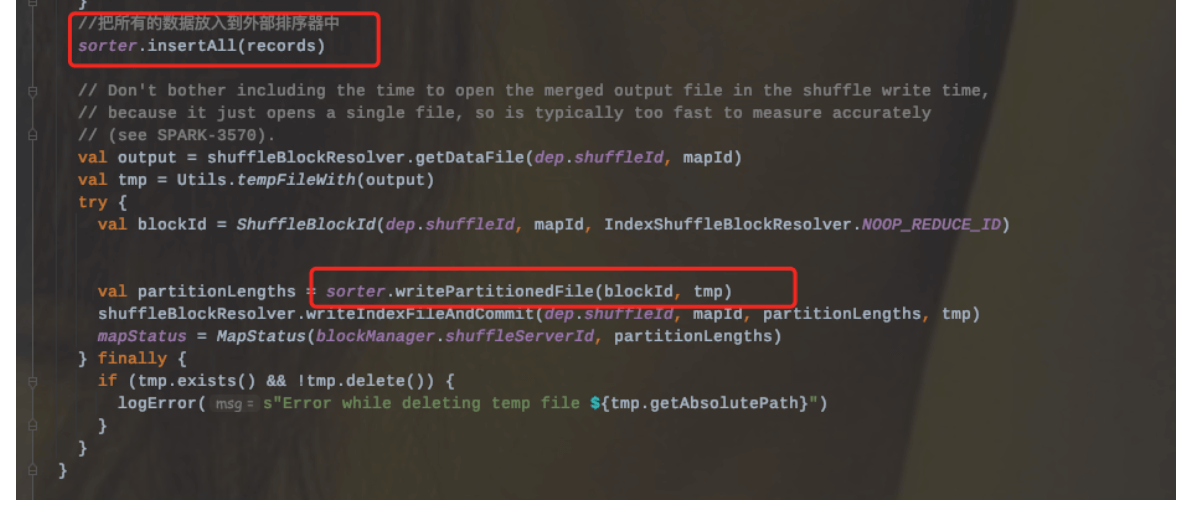
3、Sorter.insertAll内部会根据是否进行合并采用不同的存储。如果需要进行合并,那么就会使用AppendOnlyMap在内存中进行合并;如果不需要进行合并,那么就会存放到Buffer中。
3.1、无论是否进行合并,都会进行的是否溢写检查(即调用maybeSpillCollection检查是否溢写到磁盘),其底层内部调用的是maybeSpill方法。
4.其溢写策略:
4.1、首先检查是否需要spill;判断依据为:
4.1.1、当前记录数是否是32的倍数—即对小批量的数据集进行spill
4.1.2、检查当前需要的内存大小是否达到或者超过了当前分配的内存阈值spark.shuffle.spill.initialMemoryThreshold=5_1024_1025
4.2、如果以上条件都满足的话,那么会向Shuffle内存池申请当前2倍内存,然后再次判断是否需要spill。
4.3、再次判断的依据是:
4.3.1、当前判断结果为true|从上次spill之后读取的记录数是否超过了配置的阈值spark.shuffle.spill.numElementsForceSpillThreshold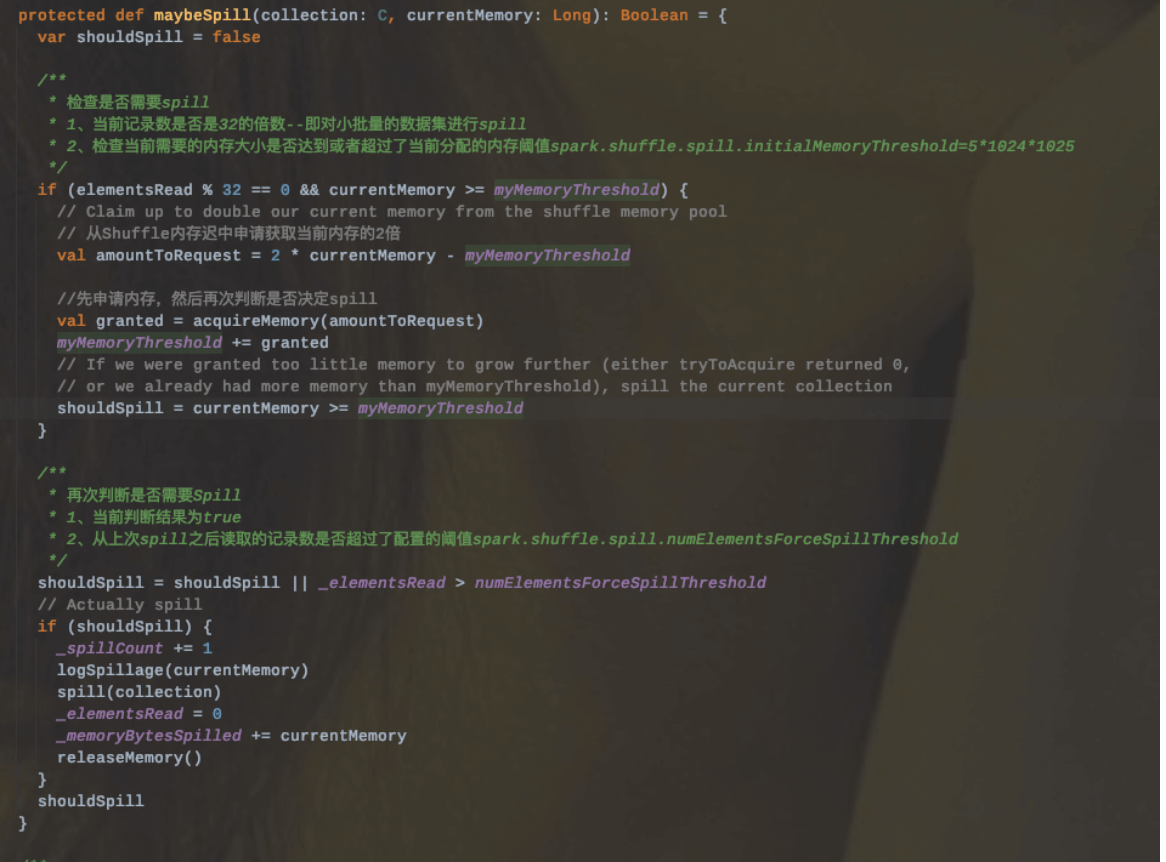
缺点:
1、内存中的数据是以反序列化的形式存储的,这样会增加内存的开销,同时也意味着增加GC负载。
2、存储到磁盘的时候会对数据进行序列化,而反序列化和序列化操作会增加CPU的开销。
2.1.6.0.1.3 UnsafeShuffleWriter
和Sort Shuffle Writer基本一致,主要不同在于使用的是序列化排序模式。
上述中说到在spark.shuffle.manager设置为sort时,内部会自动选择具体的实现机制。
Tungsten-Sort Shuffle内部的写入器是使用的UnsafeShuffleWriter,该类在构建的时候会传入一个context.taskMemoryManager(),构建一个TaskMemoryManager实例,主要负责管理分配task内存。
该写入器有以下三个关键步骤:
1、通过循环遍历将记录写入到外部排序器中
2、closeAndWriteOutput方法写数据文件和索引文件,在写的过程中会先合并外部排序器在插入过程中生成的中间文件。该方法主要有三个步骤:
2.1、触发外部排序器,获取spill信息
2.2、合并Spill中间文件,生成数据文件,并返回各个分区对应的数据量信息。
2.3、根据各个分区的数据量信息生成数据文件对应的索引文件。
3、sorter.cleanupresources最后释放外部排序器的资源。
2.1.6.0.2、Shuffle Read
2.1.6.1、Hash Shuffle(Spark2.X abandoned)
早期引入Hash Shuffle主要是为了避免不必要的排序(MR中的Shuffle过程sort是必经的一个过程)。
在Spark1.1之前,每个Mapper阶段的Task都会为每个Reduce阶段的Task生成一个文件,那么也就会生成MR个中间文件(M表示Mapper阶段的Task个数,R表示Reduce阶段的Task个数)。
后来为了缓解这种大量文件产生的问题,基于Hash Shuffle实现又引入了*Shuffle Consolidate机制,也就是将中间文件进行合并。通过配置spark.shuffle.consolidateFiles=true减少中间文件生成的个数。该种机制把中间文件生成方式调整为每个执行单元(类似于Slot)为每个Reduce阶段的Task生成一个文件,那么最后生成的文件个数为E_(C/T)_R;
E:表示Executors个数
C:表示Mapper阶段可用Cores个数
T:表示Mapper阶段Task分配的Cores个数。
从抽象的角度来说,Consolidate Shuffle是通过ShuffleFileGroup的概念,即每个ShuffleFileGroup对应一批Shuffle文件,文件数量和Reducer端的Task个数一样。同个Core上执行的MapTask任务会往这一批Shuffle文件里写,这样可以进行复用,在一定程度上对多个task进行了合并。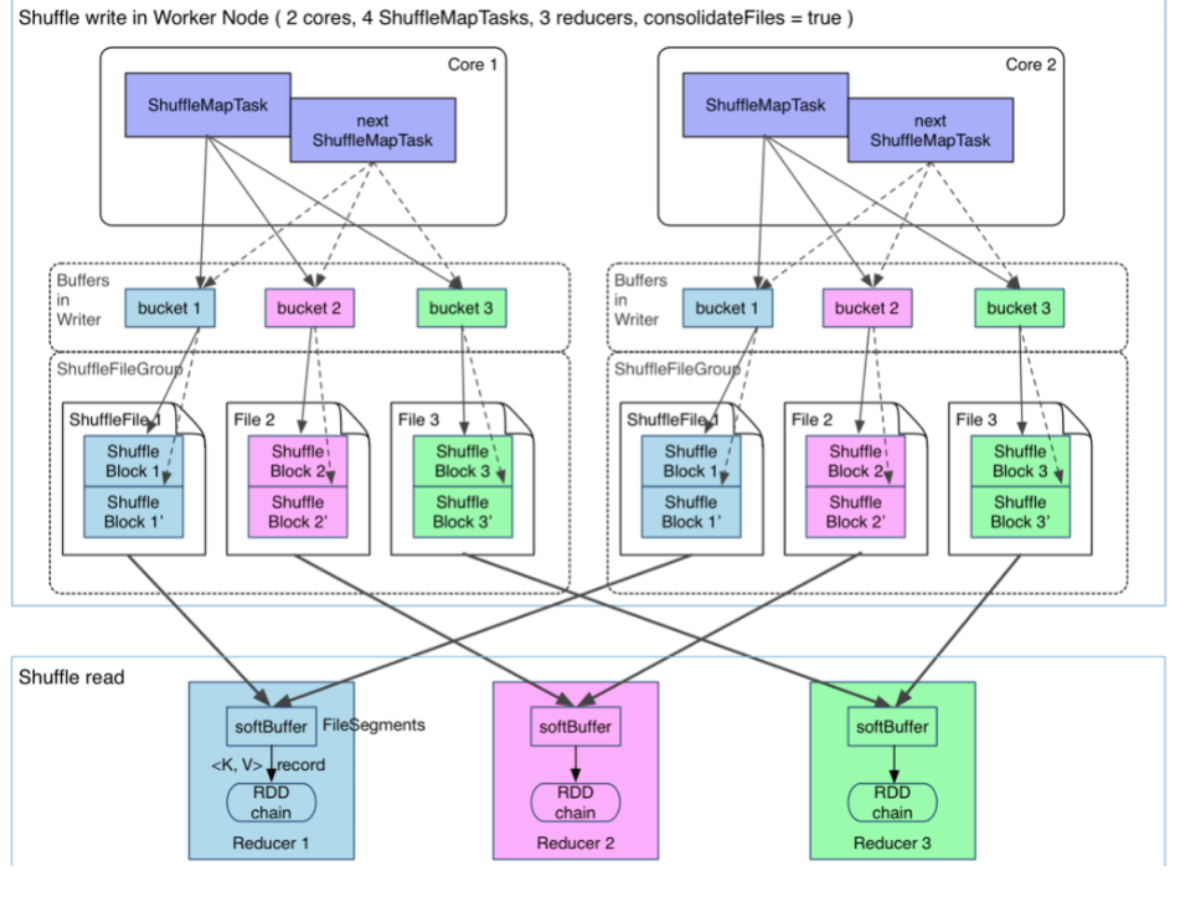
2.1.6.2、Sort Shuffle
2.1.6.2.1、引入背景
基于Hash的Shuffle实现方式,生成的中间结果文件个数取决于Reduce阶段的Task个数,即Reduce端的并行度。虽然引入了consolidate机制,但是仍然解决不了大量文件生成的问题。
因此在Spark1.1中又引入了基于Sort的Shuffle方式,在2.X中废弃掉了hash shuffle。也就是说现在1.1之后所有的版本中默认都是Sort Shuffle(早期版本其实可以调整ShuffleManager为hash方式)。
为什么说Sort Shuffle解决了Hash Shuffle生成大量文件的问题?那么最后又是会生成多少个文件呢?
解答:基于sort shuffle的模式是将所有的数据写入到一个数据文件里,同时会生成一个索引文件。那么最终文件生成的个数变成了2M;
M表示Mapper阶段的Task个数,每个Mapper阶段的Task分别生成两个文件(1个数据文件、1个索引文件)
其中索引文件存储了数据文件通过Partitioner的分类的信息,所以下一个阶段Stage中的Task就是根据这个index文件获取自己所需要的上一个Stage中ShuffleMapTask产生的数据。而ShuffleMapTask产生数据写入是顺序写的(根据自身的Key写进去的,同时也是按照Partition写进去的)
2.1.6.2.2、原理
Sort Shuffle主要是在Mapper阶段,在Mapper阶段,会进行两次排序(第一次是根据PartitionId进行排序;第二次是根据数据本身的Key进行排序,当然第二次排序除非调用了带排序的方法,在方法里指定了Key值的Ordering实例,这个时候才会对分区内的数据进行排序)。
sort shuffle其核心借助于ExternalSorter首先会把每个ShuffleMapTask的输出排序内存中,当超过内存容纳的时候,会spill到一个文件中(FileSegmentGroup),同时还会写一个索引文件用来区分下一个阶段Reduce Task不同的内容来告诉下游Stage的并行任务哪些数据是属于自己的。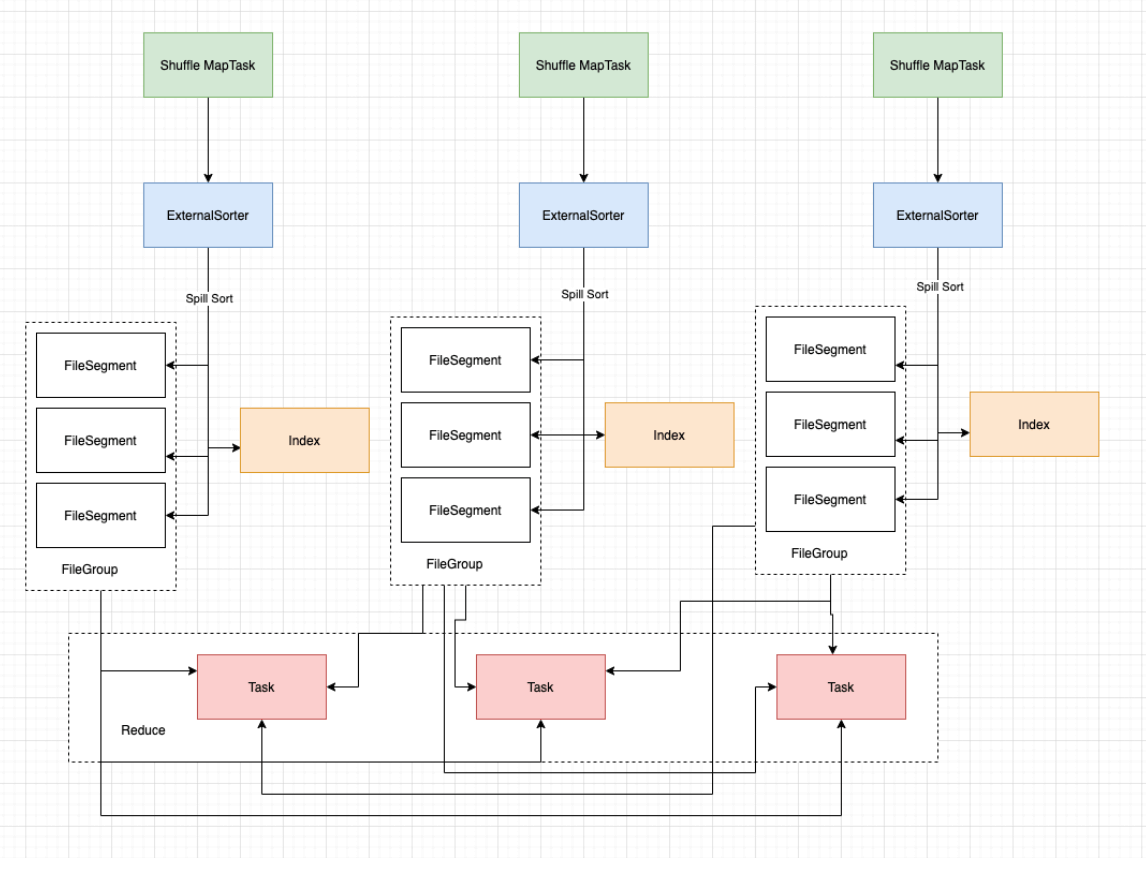
2.1.6.2.3、缺点
1、sort shuffle产生的文件数量为2M,那么这个文件数量的大小也是取决于M的个数,也就是Map端的TASK个数。如果task数过多,那么这个时候Reduce端需要大量记录并进行反序列化,同样会造成OOM,甚至full GC
2、Mapper端强制排序(和MR中的Shuffle是一样的)
3、如果分区内也需要进行排序,那么就都要在mapper端和reducer端进行排序。
4、sort shuffle是基于记录本身进行排序的,会有一定的性能消耗。
2.1.6.3、Tungsten Sort Shuffle
tungen-sort shuffle对排序算法进行了改造优化了排序的速度。其优化(从避免反序列化的数据量过大消耗内存方面考虑;借助于Tungsten内存管理模型,可以直接处理序列化的数据,同时也降低了CPU开销。
使用该模式需要具备以下几个条件:
1、shuffle依赖中不存在聚合操作或者没有对输出排序的要求
2、shuffle的序列化器支持序列化值的重定位(目前仅支持KryoSerializer以及SparkSQL子框架自定义的序列化器)
3、Shuffle过程重化工的输出分区个数少于16777216个。
所以使用基于Tungsten-sort的Shuffle实现机制条件还是比较苛刻的。
2.1.6.4、Shuffle & Storage (TODO)
2.1.7、Cache&Checkpoint&Broadcast&Accumulate
2.1.7.1、Cache
2.1.7.1.1、Cache原理
RDD是通过iterator进行计算的。当然该方法是内部调用的,不会暴露给用户使用;
1、CacheManager通过BlockManager从Local或者Remote获取数据,然后通过RDD的compute进行计算(这个时候需要考虑是否进行checkpoint),根据数据的读取策略,BlockManager首先会从本地获取,如果读取不到,则从远程获取。
2、在计算的时候,会先看当前的RDD是否进行了Checkpoint,如果进行了CK,就会直接读取,否则进行计算。另外因为RDD需要进行缓存,所以计算结果就会通过BlockManager再次进行持久化。
3、根据持久化策略,要么存储到磁盘,要么存储到内存;如果只是缓存到磁盘中国,就直接使用BlockManager.doPut方法写入(这个时候需要考虑Replication);如果是写入内存,那么会使用MemoryStore.unrollSafely尝试安全将数据保存到内存中,如果内存不够,就会使用一个方法来整理一部分空间。
4、当直接通过RDD的compute进行计算的时候,可能需要考虑checkpoint。
2.1.7.2、Checkpoint
2.1.7.2.0、什么时候需要Checkpoint
1、当计算中有大量的RDD,且本身计算特别复杂且耗时,这个时候需要考虑将计算结果进行持久化
2、需要对曾经计算的结果数据进行复用的时候,可以提升效率
3、当采用persist把数据放到内存或者磁盘时,可能会造成数据丢失
针对以上3种场景,引入了checkpoint来更加可靠持久化数据,可以指定数据放到本地且多副本的方式(生产一般是存储于HDFS);另一方面确保了RDD复用计算的可靠性,最大程度保证数据安全;通过对RDD启动Checkpoint机制来实现容错和高可用。
2.1.7.2.1、Checkpoint原理
RDD在进行计算之前会先看一下是否有checkpoint,如果有则不需要计算,如果没有被持久化,则进行compute
1、通过Sparkcontext.setCheckpointDir方法设置Checkpoint路径。(这里会进行检查,如果程序在集群中运行,但是目录设置的是本地,那么会记录一个警告,然后driver会试图从它的本地文件系统重建RDD的checkpoint检测点,因为checkpoint文件检查点不正确。实际上应该是在Executor机器上,因为计算是发生在Executor端)
2、如果某个RDD需要进行checkpoint,那么就会生成RDDCheckpointData对象,首先会调用doCheckpoint方法,其内部会通过checkpoint方法会标记RDD的检查点,移除所有引用的父RDDS,来截断RDD血统,并保存到对应的目录中。
当RDD上运行过一个Job后,就会触发RDDCheckpointData.doCheckpoint方法,把路径信息广播给所有的Executor,然后其内部会调用runJob来执行当前的RDD的数据写到checkpoint目录中,同时会产生ReliableCheckpointRDD实例,并调用writeRDDToCheckpointDirectory方法进行checkpoint工作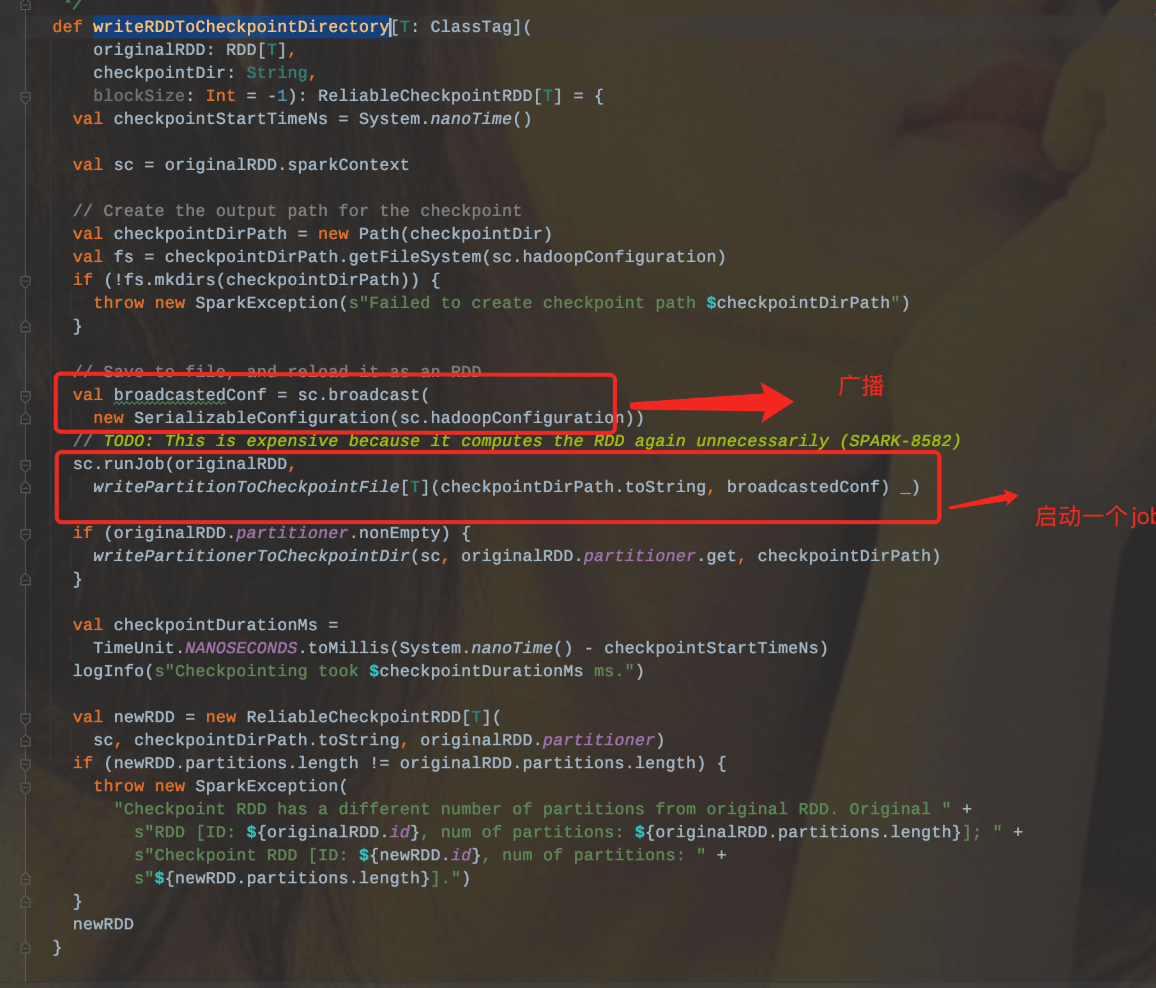
3、在进行RDD的checkpoint时候,它所依赖的所有的RDD都会从计算链条上清空掉。
4、由于checkpoint是懒加载的,必须得有Job的执行,当Job执行完成之后,才会从后往前回溯哪个RDD进行了checkpoint标记,然后对标记过的RDD再启动一个Job执行具体的checkpoint过程。
2.1.7.2.2、Checkpoint Vs Persist Vs Cache
Cache:底层其实调用的就是Persist(StorageLevel.MEMORY_ONLY),即把数据缓存到内存中
Persist:根据配置的StorageLevel存储策略,将数据缓存到内存或者磁盘。
Checkpoint:通常是将数据持久化到HDFS上,主要用于故障恢复容错保障,且根据上面对checkpoint的原理介绍,checkpoint会切断RDD之间的血缘关系,而persist和cache则会保留RDD之间的血缘关系。从另一方面讲Checkpoint保存数据的文件是不会随着应用程序的结束而删除,除非用户手动删除,而persist或cache则会在程序结束后自动删除。
2.1.7.3、Broadcast
2.1.7.3.1、场景
通常是将数据从一个节点上发送到其他节点上,且存储在内存或者磁盘上,所以不适合存放太大的数据,否则会造成网络I/O压力过大。一般用于处理配置文件、通用的DataSet、数据结构等。
Spark2.X版本中目前存在的Broadcast类型仅有TorrentBroadcast(可能会有网络压力),1.6版本还有HttpBroadcast(见SPARK-12588),但其可能会有单点压力。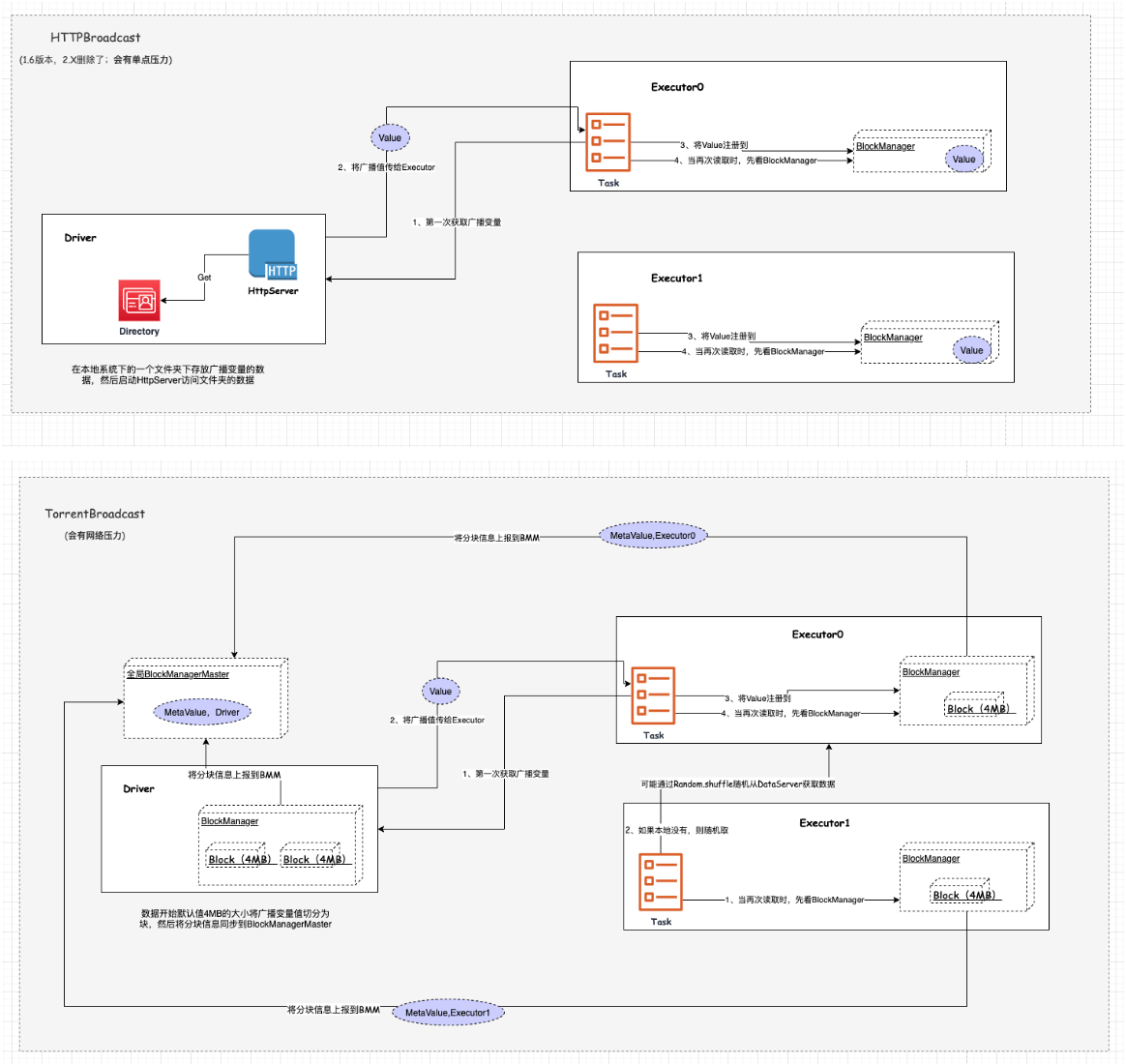
2.1.7.3.2、原理
首先其在SparkContext初始化的时候会创建SparkEnv,这个时候开始初始化广播相关的类。即入口为:
1、其首先会创建BroadcastManager,内部会初始化TorrentBroadcastFactory,该工厂类用于实例化TorrentBroadcast。
2、当调用sc.broadcast进行广播RDD或者其他数据时,那么底层会调用TorrentBroadcast,并首先将其数据写入到Driver端,底层是通过BlockManager进行操作,并将数据会被分成4MB大小的块,然后将块信息上报到BlockManagerMaster中
3、当Executor端的task需要使用到广播变量值的时候,那么会调用value方法获取。那么底层其实是会先进行判断,如果该Executor是首次获取该值的话,那么会向Driver进行请求,当拿到结果后会写入本地,也会像Driver端操作一样,通过BlockManager进行管理,将数据分块上报到全局的BlockManagerMaster中去;如果不是第一次获取且本地存在,则直接读取本地,否则根据随机洗牌向其他的DataServer(Executor/Driver)获取。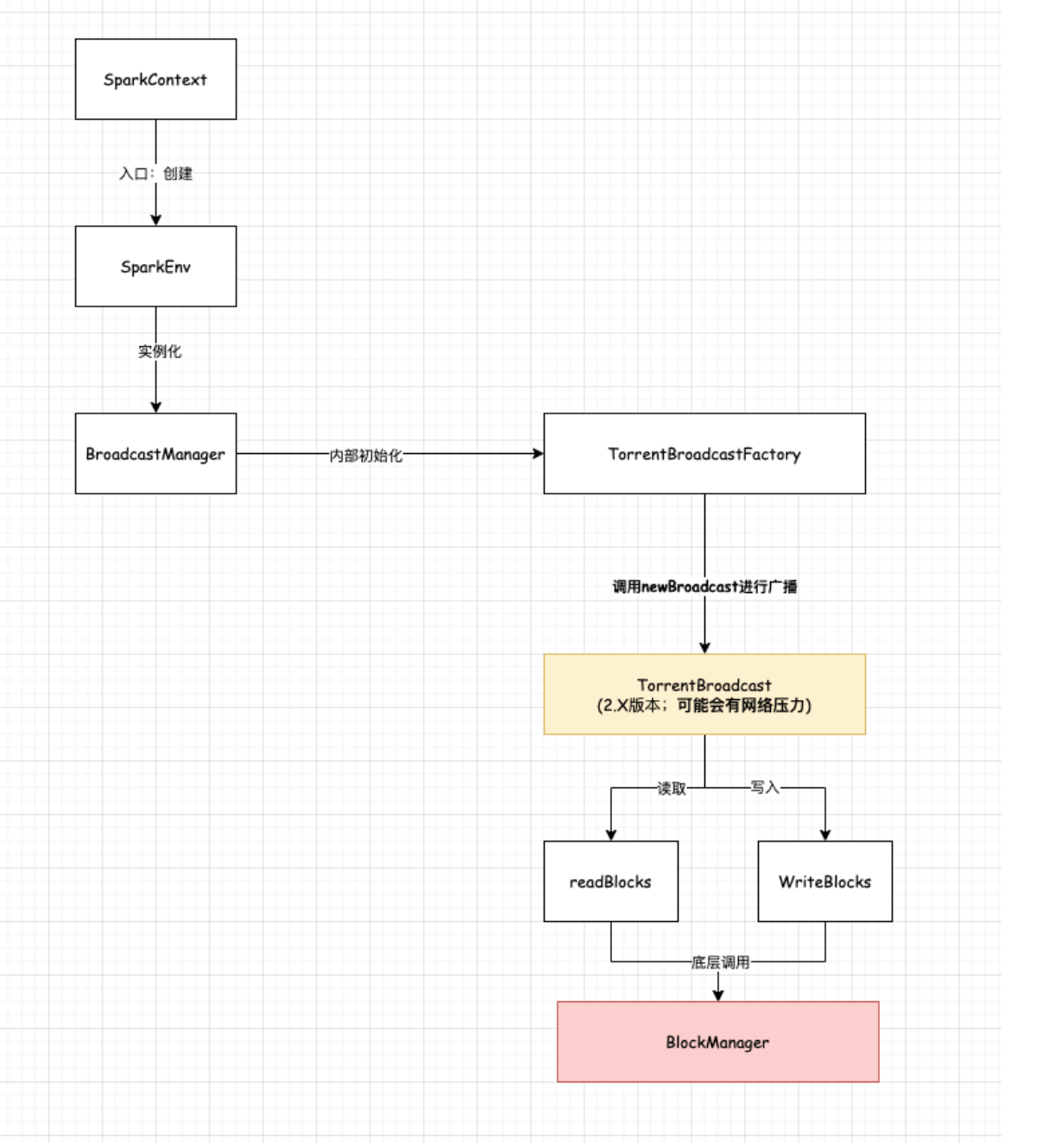
管理及生命周期:底层通过BlockManager管理,由于Spark应用程序可能会存在多个Job,并不是每个Job都需要广播变量,也可能一个Job需要很多广播变量,那么其具体生命周期可以手动指定来销毁。
注意:Broadcast变量是只读的,其主要是为了保障数据一致性。避免了容错、更新顺序逻辑的考虑
2.1.7.4、Accumulate
1、分布式全局只写的数据结构、用于数据的累加。只能在Driver端进行读取
2、累加器更新只在action动作内执行,spark保证每个任务对累加器的更新只应用一次,即重新启动的任务不会更新该值;在transformations转换中,如果重新执行任务或者Stage,那么每个任务的更新可能会执行多次。
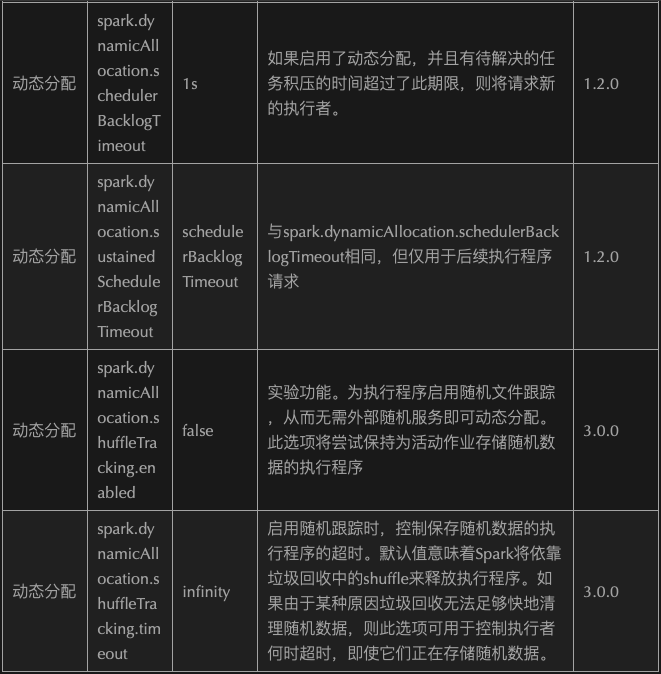
2.1.8、Memory Model
https://mp.weixin.qq.com/s/dmHm7YyG4ypVh3FviedehA
2.1.8.1、Tungsten Origin background
众所周知,Spark是由Scala+Java开发的一种基于内存计算的大数据解决方案,底层运行在JVM上,那么自然而然的会有GC的问题反过来限制Spark的性能,而且绝大多数Spark应用程序的主要瓶颈不在于IO/网络,而是在于CPU和内存。此时Project Tungsten由DataBricks提出,并在Spark1.5中引入,在1.6.X对内存进行了优化,在2.X对CPU进行了优化,也就是说该项目主要是针对于CPU和Memory进行优化,具体优化集中在以下三个方面:
Memory Management And Binary Processing(内存管理和二进制处理)
Cacahe-aware Computation(缓存感知计算):使用了友好的数据结构和算法来完成数据的存储和复用,提升缓存命中率
Code Generation(代码生成):扩展了更多的表达式求值和SQL操作,把已有的代码变成本地的字节,不需要很多的抽象和匹配等,避免了昂贵的虚拟函数调用
2.1.8.2、Tungsten Optimize-Memory
本篇主要讲述tungsten在内存这块的优化点,以及spark是如何进行内存分配的(On-Heap和Off-Heap结合,Storage/Executor/Other划分),通过何种方式的寻址(通过引入了Page table来管理On-Heap和Off-Heap)来实现的统一内存管理。
2.1.8.2.0 堆划分
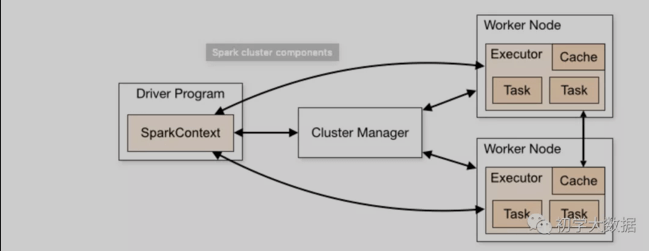
这里先复习一下Spark运行的整体流程:
1、通过spark-submit命令提交Spark作业,启动Driver(根据不同的模式如yarn-client,yarn-cluster,启动点不同),生成SparkContext对象(这里会进行DAG—>Stage—>Task划分)
2、SparkContext和Cluster Manager进行通信,申请资源以及后续的任务分配和监控,并在指定Worker节点上启动Executor
3、SparkContext在实例化的时候,会构建DAG,并分解为多个Stage,并把每个Stage中的TaskSet发送给TaskScheduler
4、Executor向Driver申请Task,然后Driver将应用程序以及相关依赖包发送到Executor端,并在Executor端执行task
5、Executor将task运行结果反馈给TaskScheduler,然后再反馈给DAGScheduler
当整个作业结束后,SparkContext会向ClusterManager注销并释放所有资源
从运行的整体流程上看,Driver端的工作主要是负责创建SparkContext,提交作业以及协调任务;Executor端的工作主要就是执行task。
从内存使用的角度上看,Executor端的内存设计相当比较复杂些,所以本文也将基于Executor的内存进行概述(本文中讲到Spark内存指的也是Executor端的内存)。
那么接下来再针对Executor端的内存设计进行拆解,见下图: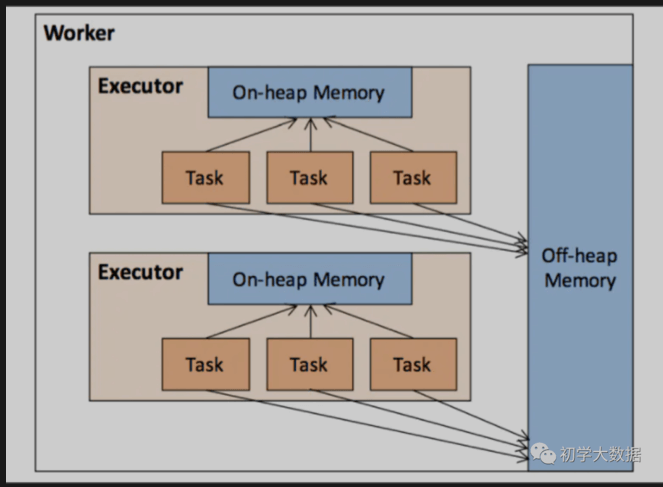
Worker节点启动的Executor其实也是一个JVM进程,因此Executor的内存管理是建立在JVM内存管理上的(On-Heap堆内内存),同时Spark也引入了Off-Heap(堆外内存),使之可以直接在系统内存中开辟空间,避免了在数据处理过程中不必要的序列化和反序列化的开销,同时也降低了GC的开销。
2.1.8.2.1 On-Heap(堆内)
Spark对堆内内存的管理其实只是一种逻辑上的管理,内存的申请和释放都是由JVM来完成的,而Spark只是在申请后和释放前记录这些内存。
申请内存后:如创建一个对象,JVM从堆内内存中分配空间,并返回对象的引用,而Spark会保存该对象的引用,记录该对象占用的内存
释放内存前:spark删除该对象的引用,记录该对象释放的内存,等待JVM来真正释放掉该对象占用的内存
这里需要说明一下spark关于序列化的一个小知识点:
经过序列化的对象,是以字节流的形式存在,占用的内存大小是可以直接计算,而对于非序列化的对象,占用的内存只能通过周期性地采样近似估算得到的,也就是说每次新增的数据项都会计算一次占用的内存大小,这种方式会有一定的误差,可能会导致某一时刻的实际内存超过预期。当被Spark标记为释放的对象实例时,也有可能没有被JVM回收,导致实际可用的内存小于spark记录的可用内存,造成OOM的发生。
为了减少OOM异常的发生,Spark对堆内内存再次进行了划分(即分为Storage,Executor,Other,下一小节将进行详解),通过内存划分方式各自规划管理来提升内存的利用率。
2.1.8.2.2 Off-Heap(堆外)
为了解决基于JVM托管方式存在的缺陷,Tungsten引入了基于Off-Heap管理内存的方式,通过sun.misc.Unsafe管理内存,这样可以使得Spark的operation直接使用分配的二进制数据,而不是JVM对象,降低了GC带来的开销。而且对于序列化的数据占用的空间可以被精准计算,相对堆内内存来说降低了管理难度。当然默认情况堆外内存是没有启用的,需要通过配置参数spark.memory.offHeap.enabled来启用.
2.1.8.3、Memory division
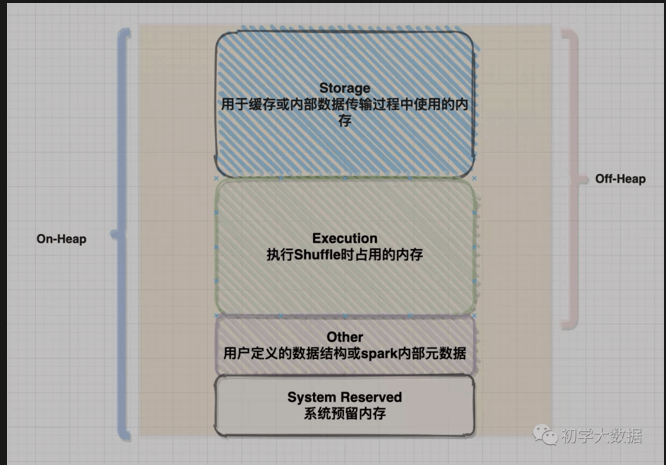
根据内存使用目的不同,对堆内外内存进行了如上图的划分:
针对堆内内存来说,划分了4块:
存储内存(Storage Memory):该部分的内存主要是用于缓存或者内部数据传输过程中使用的,比如缓存RDD或者广播数据
执行内存(Execution Memory):该部分的内存主要用于计算的内存,包括shuffles,Joins,sorts以及aggregations
其他内存(Other Memory):该部分的内存主要给存储用户定义的数据结构或者spark内部的元数据
预留内存:和other内存作用是一样的,但由于spark对堆内内存采用估算的方式,所以提供了预留内存来保障有足够的空间
针对堆外内存来说,划分了2块(前面也提到过了spark对堆外内存的使用可以精准计算):
1、存储内存(Storage Memory)
2、执行内存(Execution Memory)
2.1.8.4、Memory management
Tungsten使用了Off-Heap使得spark实现了自己独立的内存管理,避免了GC引发的性能问题,省去了序列化和反序列化的过程。Spark1.6版本之前使用了静态内存管理模式,而在此之后使用统一内存管理模型,并,可以直接操作内存中的二进制数据,而不是Java对象,很大程度上摆脱了JVM内存管理的限制。
2.1.8.4.1 Spark1.6之前-静态内存管理模型
下面的两张图相信有些读者已经很熟悉了。
静态内存模型最大的特点就是:堆内内存中的每个区域的大小在spark应用程序运行期间是固定的,用户可以在启动前进行配置;这也需要用户对spark的内存模型非常熟悉,否则会因为配置不当造成严重后果
对于堆内内存区域的划分以及比例如下图:
1、存储内存(Storage Memory): 默认情况下,存储内存占用整个堆内存的60%(该占比由spark.storage.memoryFraction来控制),主要用了存储缓存的RDD或者广播数据;
2、执行内存(Execution Memory): 默认情况下,执行内存占用整个堆内存的20%(该占比由spark.shuffle.memoryFraction来控制),主要用来存储进行shuffle计算的内容
3、预留内存: 默认情况下,预留内存占用整个堆内存的20%(该占比取决于上面两个内存区域的大小),主要用来存储一些元数据或者用户定义的数据结构
这里需要说一下Unroll过程:RDD以Block形式被缓存到存储内存,Record在堆内或堆外存储内存中占用一块连续的空间。把Partition由不连续的存储空间转换为连续空间的过程就是Unroll,也称之为展开操作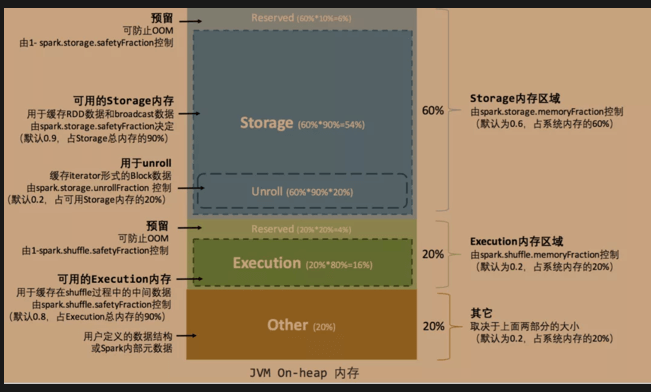
对于堆外内存的划分,比较简单,即只有存储内存和执行内存(具体原因上文也已经讲到了,即spark对堆外内存的使用计算是比较精确的,所以不需要额外的预留空间来避免OOM的发生)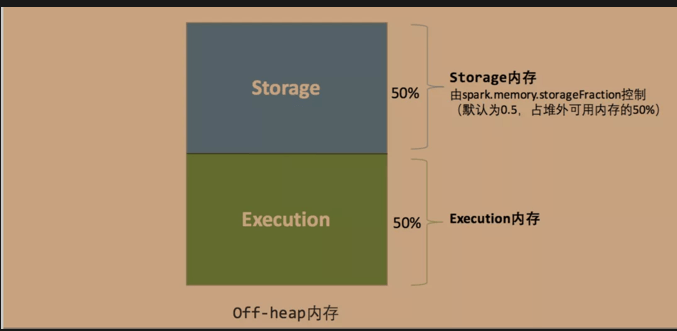
源码实现
基类MemoryManager封装了静态内存管理模型和统一内存管理模型,而StaticMemoryManager类负责实现静态内存模型,UnifiedMemoryManager类实现统一内存模型。具体采用哪种内存分配由tungstenMemoryMode来决定,即由MemoryAllocator来负责具体分配(分别实现了两个子类),其中allocate和free函数来提供内存的分配和释放,分配的内存以MemoryBlock来表示。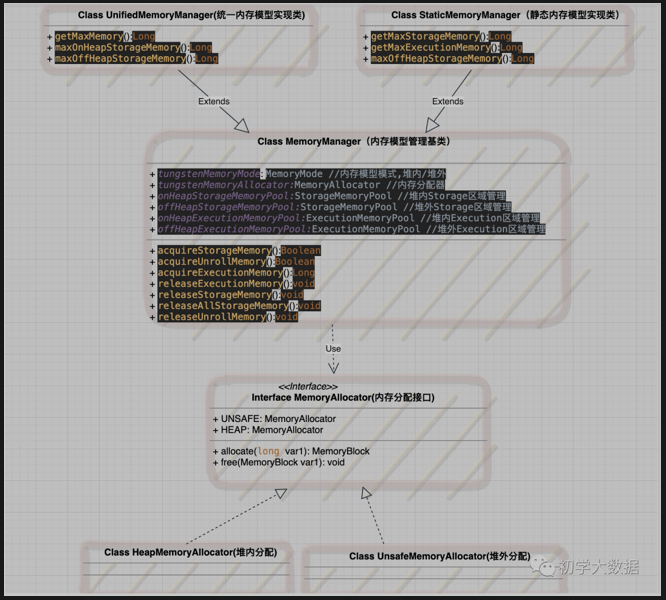
静态内存模型管理器-StaticMemoryManager类
//Unroll过程中可用的内存,占最大Storage内存的0.2private val maxUnrollMemory: Long = {(maxOnHeapStorageMemory * conf.getDouble("spark.storage.unrollFraction", 0.2)).toLong}//获取最大的Storage内存private def getMaxStorageMemory(conf: SparkConf): Long = {val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)val memoryFraction = conf.getDouble("spark.storage.memoryFraction", 0.6) //Storage内存占全部内存占比val safetyFraction = conf.getDouble("spark.storage.safetyFraction", 0.9) //Storage内存的安全系数(systemMaxMemory memoryFraction safetyFraction).toLong}//获取最大的Execution内存private def getMaxExecutionMemory(conf: SparkConf): Long = {val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)if (conf.contains("spark.executor.memory")) {val executorMemory = conf.getSizeAsBytes("spark.executor.memory")}val memoryFraction = conf.getDouble("spark.shuffle.memoryFraction", 0.2) //Execution内存占全部内存占比val safetyFraction = conf.getDouble("spark.shuffle.safetyFraction", 0.8) //Execution内存的安全系数(systemMaxMemory memoryFraction safetyFraction).toLong}
2.1.8.4.2、Spark1.6之后-统一内存管理模型
关于新的统一内存管理模型,有兴趣的读者可以参考https://issues.apache.org/jira/secure/attachment/12765646/unified-memory-management-spark-l0000.pdf
统一内存模型和静态内存模型的区别在于:存储内存和执行内存共享同一块空间(占堆内内存的60%),且可以动态占用对方的空闲区域
统一内存模型关于堆内内存区域的划分,这里有以下几点需要注意:
1、执行内存和存储内存共享同一空间,该空间占用可用内存的60%,例如我们设置1G内存,那么Execution和Storage共用内存就是(1024-300)*0.6 = 434MB
2、执行内存和存储内存可以互相占用对方空闲空间
3、存储内存可以借用执行内存,直到执行内存重新占用它的空间为止。当发生这种情况的时候,缓存块将从内存中清除,直到足够的借入内存被释放,满足执行内存、请求内存的需要
4、执行内存可以借用尽可能多空闲的存储内存,但是执行内存由于执行操作所涉及的复杂性,执行内存永远不会被存储区逐出,也就是说如果执行内存已经占用存储内存的大部分空间,那么缓存块就会有可能失败,在这种情况下,根据存储级别的设置,新的块会被立即逐出内存
5、虽然存储内存和执行内存共享同一空间,但是会存在一个初始边界值,具体可见UnifiedMemoryManager.apply方法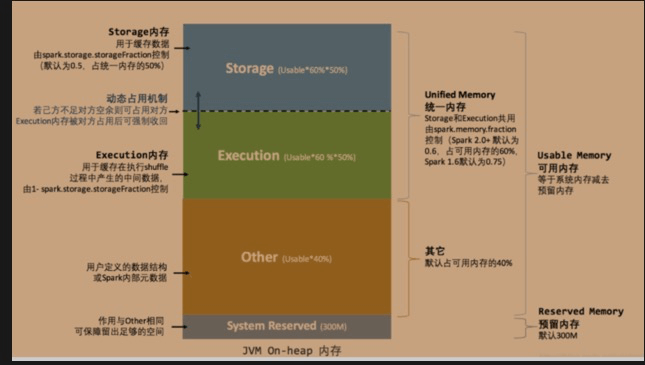
统一内存模型对于堆外内存的设计和静态内存模型是一样的,这里不再重复介绍了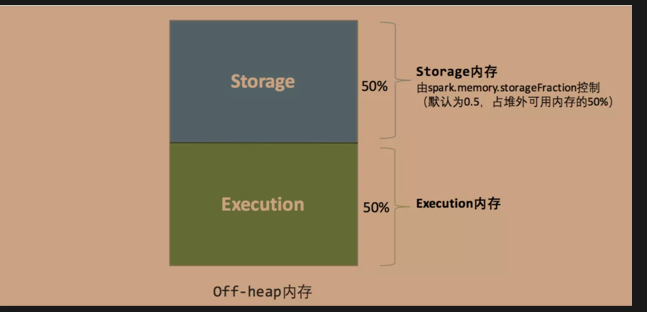
//源码实现-UnifiedMemoryManagerprivate def getMaxMemory(conf: SparkConf): Long = {val systemMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)//系统预留的内存大小,默认为300MBval reservedMemory = conf.getLong("spark.testing.reservedMemory",if (conf.contains("spark.testing")) 0 else RESERVED_SYSTEM_MEMORY_BYTES)//当前最小的内存需要300*1.5,即450MB,不满足条件就会退出val minSystemMemory = (reservedMemory * 1.5).ceil.toLongif (systemMemory < minSystemMemory) {throw new IllegalArgumentException(s"System memory $systemMemory must " +s"be at least $minSystemMemory. Please increase heap size using the --driver-memory " +s"option or spark.driver.memory in Spark configuration.")}// SPARK-12759 Check executor memory to fail fast if memory is insufficientif (conf.contains("spark.executor.memory")) {val executorMemory = conf.getSizeAsBytes("spark.executor.memory")if (executorMemory < minSystemMemory) {throw new IllegalArgumentException(s"Executor memory minSystemMemory. Please increase executor memory using the " +}val usableMemory = systemMemory - reservedMemory//当前Execution和Storage共享的最大内存占比默认为0.6val memoryFraction = conf.getDouble("spark.memory.fraction", 0.6)(usableMemory * memoryFraction).toLong}def apply(conf: SparkConf, numCores: Int): UnifiedMemoryManager = {val maxMemory = getMaxMemory(conf)new UnifiedMemoryManager(conf,maxHeapMemory = maxMemory,//通过配置参数spark.memory.storageFraction,设置Execution和Storage共享内存初始边界,即默认各占总内存一半onHeapStorageRegionSize =(maxMemory * conf.getDouble("spark.memory.storageFraction", 0.5)).toLong,numCores = numCores)}
2.1.8.5、Memory addressing
以上小节介绍了spark对堆的划分,根据使用目的不同,对堆进行了区域划分,并说明了spark1.6之前和之后使用的两种不同内存模型管理以及之间的区别,那么这里继续逐步分析,说到内存管理,spark是如何通过进行内存寻址,内存块是如何封装的,通过何种方式来组织管理这些内存块?
问1:如何进行内存寻址的?
答:这里需要再次回到Project Tungsten计划中,由于spark引入了Off-Heap内存模式,为了方便统一管理On-Heap和Off-Heap这两种模式,Tungsten引入了统一的地址表示形式,即通过MemoryLocation类来表示On-Heap或Off-Heap两种内存模式下的地址,该类中有两个属性obj和offset,当处于On-Heap模式下,通过使用obj(即为对象的引用)和64 bit的offset来表示内存地址,当处于Off-Heap模式下,直接使用64 bit的offset绝对地址来描述内存地址。而这个64bit 的offset在对外编码时,前13 bit用来表示Page Number,后51 bit用来表示对应的offset
问2:内存块是如何封装的?
答:在Project Tungsten内存管理中,会使用一块连续的内存空间来存储数据,通过MemoryBlock类对内存块进行封装。该类继承了MemoryLocation类,采用了组合复用方式,即指定了内存块的地址,也提供了内存块本身的内存大小
问3:如何组织管理内存块?
答:Project Tungsten采用了类似于操作系统的内存管理模式,使用Page Table方式(其实本质就是一个数组,从源码中就可以看出)来管理内存,内部以Page来管理存储内存块(通过MemoryBlock来封装),通过pageNumber找到对应的Page,Page内部会根据Off-Heap或On-Heap两种模式分别存储Page对应内存块的起始地址(或对象内偏移地址)
在spark中,数据是以分区进行处理的,而每个分区对应一个task,所以对于内存的组织和管理可以借助于TaskMemoryManager来理解,同时以上这些疑惑均可以在TaskMemoryManager类(该类对MemoryManager又做了一层封装)中找到解答。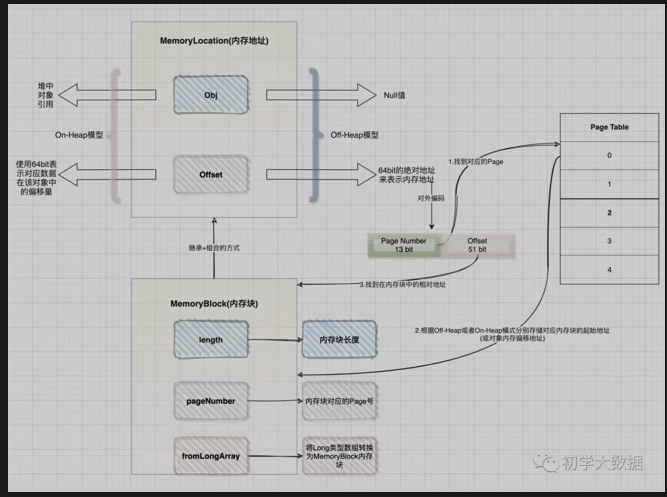
源码实现-TaskMemoryManager
属性信息
//Page Number长度位数private static final int PAGE_NUMBER_BITS = 13;//Offset位数static final int OFFSET_BITS = 64 - PAGE_NUMBER_BITS;//Page Table底层实现,其实就是一个MemoryBlock数组private final MemoryBlock[] pageTable = new MemoryBlock[PAGE_TABLE_SIZE];//真正进行内存分配和释放private final MemoryManager memoryManager;// 内存模式final MemoryMode tungstenMemoryMode;//分配页;调用ExectorMemoryManager进行内存分配,分配得到一个内存页,并将其添加到page table中,以便内存地址映射public MemoryBlock allocatePage(long size, MemoryConsumer consumer) {assert(consumer != null);assert(consumer.getMode() == tungstenMemoryMode);if (size > MAXIMUM_PAGE_SIZE_BYTES) {throw new TooLargePageException(size);}//申请一定的内存量long acquired = acquireExecutionMemory(size, consumer);if (acquired <= 0) {return null;}final int pageNumber;synchronized (this) {//获取当前未被分配的页码pageNumber = allocatedPages.nextClearBit(0);if (pageNumber >= PAGE_TABLE_SIZE) {releaseExecutionMemory(acquired, consumer);}//设置该页码已经被占用allocatedPages.set(pageNumber);}MemoryBlock page = null;try {//开始通过MemoryAllocator进行真正的内存分配,注意:这里并不是真正的内存分配,只是控制内存使用大小而已page = memoryManager.tungstenMemoryAllocator().allocate(acquired);} catch (OutOfMemoryError e) {//当没有足够的内存时,应该保持获得的内存synchronized (this) {acquiredButNotUsed += acquired;allocatedPages.clear(pageNumber);}//触发溢出,释放一些页面return allocatePage(size, consumer);}//分配得到内存块后,会设置该内存块对应的page numberpage.pageNumber = pageNumber;pageTable[pageNumber] = page;return page;}//释放页public void freePage(MemoryBlock page, MemoryConsumer consumer) {//首先断言确定要释放的内存块在pageTable中,即页码必须有效assert (page.pageNumber != MemoryBlock.NO_PAGE_NUMBER) :"Called freePage() on memory that wasn't allocated with allocatePage()";assert (page.pageNumber != MemoryBlock.FREED_IN_ALLOCATOR_PAGE_NUMBER) :"Called freePage() on a memory block that has already been freed";assert (page.pageNumber != MemoryBlock.FREED_IN_TMM_PAGE_NUMBER) :"Called freePage() on a memory block that has already been freed";assert(allocatedPages.get(page.pageNumber));pageTable[page.pageNumber] = null;//控制Page Table中对应的位置是否可用,这里考虑到释放和分配的并发性,需要同步处理synchronized (this) {allocatedPages.clear(page.pageNumber);}if (logger.isTraceEnabled()) {logger.trace("Freed page number {} ({} bytes)", page.pageNumber, page.size());}long pageSize = page.size();page.pageNumber = MemoryBlock.FREED_IN_TMM_PAGE_NUMBER;//通过MemoryAllocator真正释放内存块memoryManager.tungstenMemoryAllocator().free(page);releaseExecutionMemory(pageSize, consumer);}//地址编码 给定分配到的内存页和页内偏移,生成一个64 bits的逻辑地址public long encodePageNumberAndOffset(MemoryBlock page, long offsetInPage) {if (tungstenMemoryMode == MemoryMode.OFF_HEAP) {offsetInPage -= page.getBaseOffset();}return encodePageNumberAndOffset(page.pageNumber, offsetInPage);}//高13bits是page number,低51bits是页内偏移public static long encodePageNumberAndOffset(int pageNumber, long offsetInPage) {assert (pageNumber >= 0) : "encodePageNumberAndOffset called with invalid page";return (((long) pageNumber) << OFFSET_BITS) | (offsetInPage & MASK_LONG_LOWER_51_BITS);}//地址解码;给定逻辑地址,获取page numberpublic static int decodePageNumber(long pagePlusOffsetAddress) {return (int) (pagePlusOffsetAddress >>> OFFSET_BITS);}//给定逻辑地址,获取页内偏移private static long decodeOffset(long pagePlusOffsetAddress) {return (pagePlusOffsetAddress & MASK_LONG_LOWER_51_BITS);}//获取对象的引用,对于Off-Heap模式,则返回Nullpublic Object getPage(long pagePlusOffsetAddress) {if (tungstenMemoryMode == MemoryMode.ON_HEAP) {//从地址中解析出PageNumberfinal int pageNumber = decodePageNumber(pagePlusOffsetAddress);assert (pageNumber >= 0 && pageNumber < PAGE_TABLE_SIZE);//根据页码从pageTable中获取内存块final MemoryBlock page = pageTable[pageNumber];assert (page != null);assert (page.getBaseObject() != null);//获取内存块对应的Objectreturn page.getBaseObject();} else {//如果是Off-Heap模型,则Obj为nullreturn null;}}
2.1.8.6、Memory Configuration

2.1.8.7、Tungsten Optimize-CPU
2.1.8.7.1 缓存感知计算Cache-aware computation
缓存感知计算通过使用L1/L2/L3 CPU缓存来提升速度,同时也可以处理超过寄存器大小的数据。Spark开发者们在做性能分析的时候发现大量的CPU时间会因为等待从内存中读取数据而浪费,所以在Tungsten项目中,通过设计了更加友好的缓存算法和数据结构,让spark花费更少的时间等待cpu从内存中读取数据,提供了更多的计算时间。
缓存感知计算的解析
网上有很多关于缓存感知的说明,都是以KV排序为例,那么笔者这里也使用同样的例子再结合自己的理解,尽量解释的通俗易通。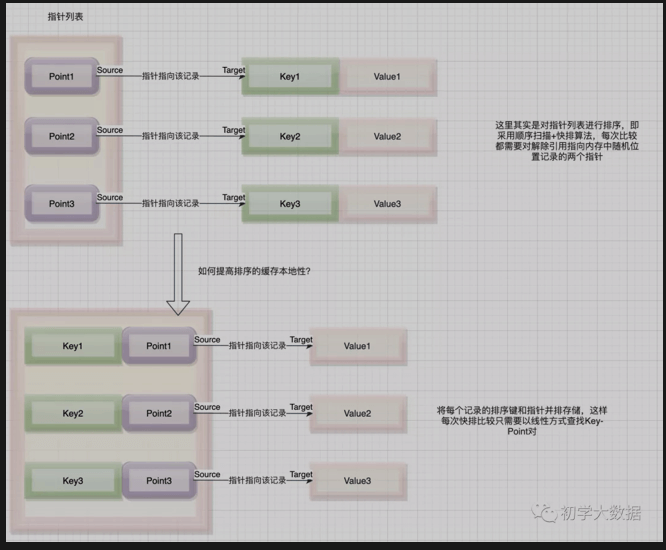
3.2 代码生成Code Generation
代码生成指的是在运行时,spark会动态生成字节码,而不需要通过解释器对原始数据类型进行打包,同时也避免了虚拟函数的调用。当然该技术的优势并不止于此,还包括了将中间数据从存储器移动到CPU寄存器;使用向量化技术,利用现代CPU功能加快了对复杂操作运行速度
这里以一个sql为例,可以通过explain来查看spark在哪些过程中使用了代码生成的功能。
当算子前面有一个*时,说明全阶段代码生成被启用,在下面的例子中,Exchange算子没有实现代码生成,这是因为这里会发生Shuffle,需要通过网络发送数据。
select count(1) from tmp.user where id='123'== Physical Plan ==*(2) HashAggregate(keys=[], functions=[count(1)])+- Exchange SinglePartition+- *(1) HashAggregate(keys=[], functions=[partial_count(1)])+- *(1) Project+- *(1) Filter ((id#2802514 = 123))+- HiveTableScan [id#2802514], HiveTableRelation tmp.user, org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, [id#2802514]
2.1.8.8、Demo of Memory Divison
/usr/local/spark-current/bin/spark-submit \--master yarn \--deploy-mode client \--executor-memory 1G \--queue root.default \--class my.Application \--conf spark.ui.port=4052 \--conf spark.port.maxRetries=100 \--num-executors 2 \--jars mongo-spark-connector_2.11-2.3.1.jar \App.jar 20201118000000
这里配置两个Executor,每个Executor内存给1G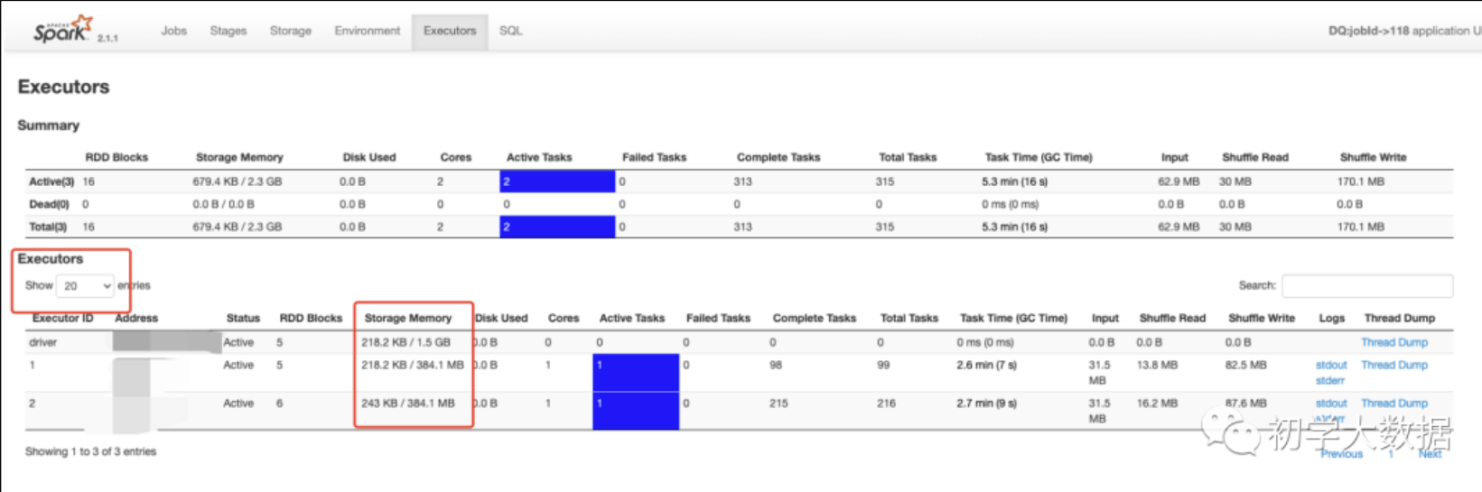
如图所示,spark申请到了两个Executor,每个Executor得到的Storage Memory内存分别为384.1MB(注意:这里Storage Memory其实就是Storage+Execution的总和内存),这里有一个疑惑,我们分配的是每个Executor内存为1G,为什么只得到384MB呢?这里给出具体的计算公式:
1、我们申请为1G内存,但是真正拿到内存会比这个少,这里涉及到一个Runtime.getRuntime.maxMemory 值的计算(UnifiedMemoryManager源码分析中提到过),Runtime.getRuntime.maxMemory对应的值才是程序能够使用的最大内存,上面也提到了堆划分了Eden,Survivor,Tenured区域,所以该值计算公式为:
ExecutorMemory = Eden + 2 * Survivor + Tenured = 1GB = 1073741824 字节
systemMemory = Runtime.getRuntime.maxMemory = Eden + Survivor + Tenured = 954437176.888888888888889 字节
//org.apache.spark.memory.UnifiedMemoryManager(这里讨论的还是动态内存模型)private def getMaxMemory(conf: SparkConf): Long = {val systemMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)val reservedMemory = conf.getLong("spark.testing.reservedMemory",if (conf.contains("spark.testing")) 0 else RESERVED_SYSTEM_MEMORY_BYTES)val usableMemory = systemMemory - reservedMemoryval memoryFraction = conf.getDouble("spark.memory.fraction", 0.6)//这里即获取最大的内存值(usableMemory * memoryFraction).toLong}
2、基于Spark的动态内存模型设计,其中有300MB的预留内存,因此剩余可用内存为总申请得到的内存-预留内存
reservedMemory = 300MB = 314572800字节
usableMemory = systemMemory - reservedMemory = 954437176.888888888888889 - 314572800 = 639864376.888888888888889字节
3、Spark Web UI界面上虽然显示的是Storage Memory,但其实是Execution+Storage内存,即该部分占用60%比例
Storage + Execution = usableMemory 0.6 = 639864376.888888888888889 0.6 = 383918626.133333333333333 字节
4、通过第三步骤即可看出实际的内存分配情况了,注意:web ui界面得到的结果计算是除于1000转换得到的值。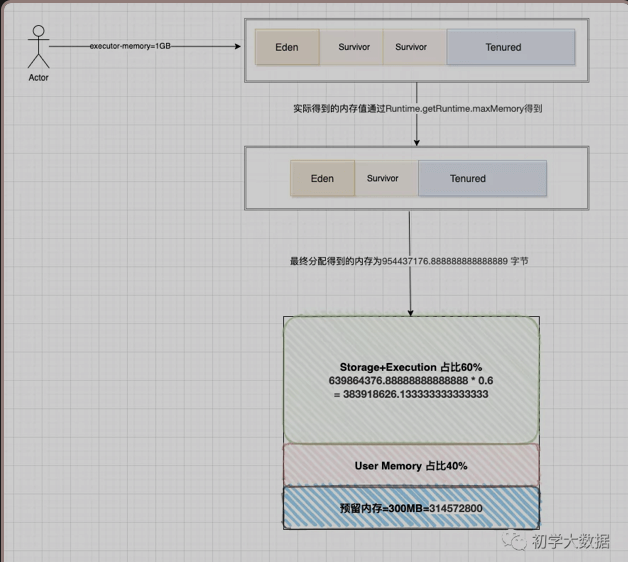
2.1.8.9、Optimize Configuration
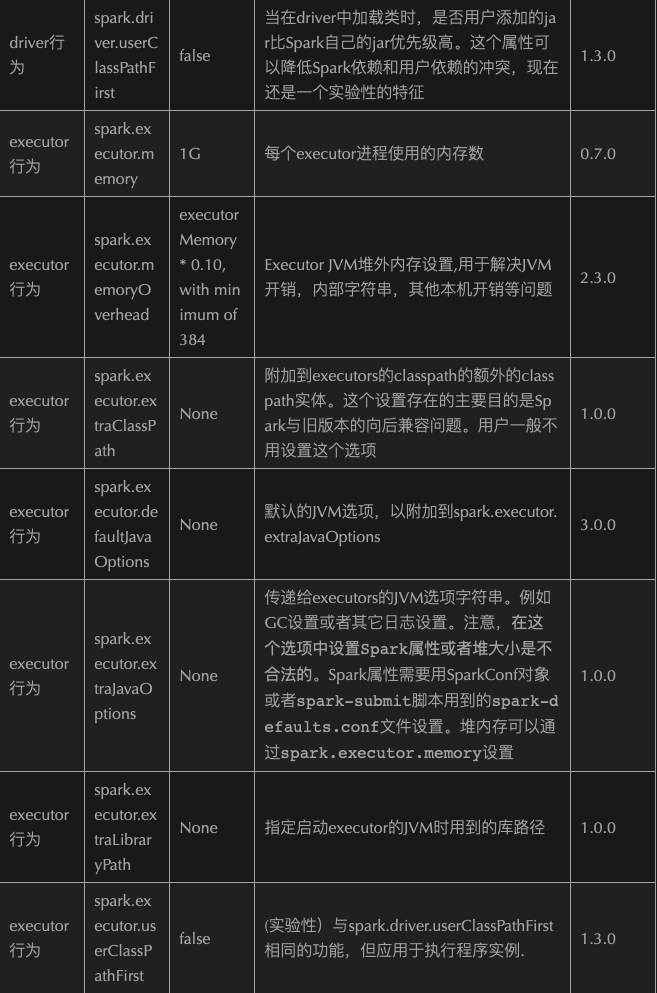

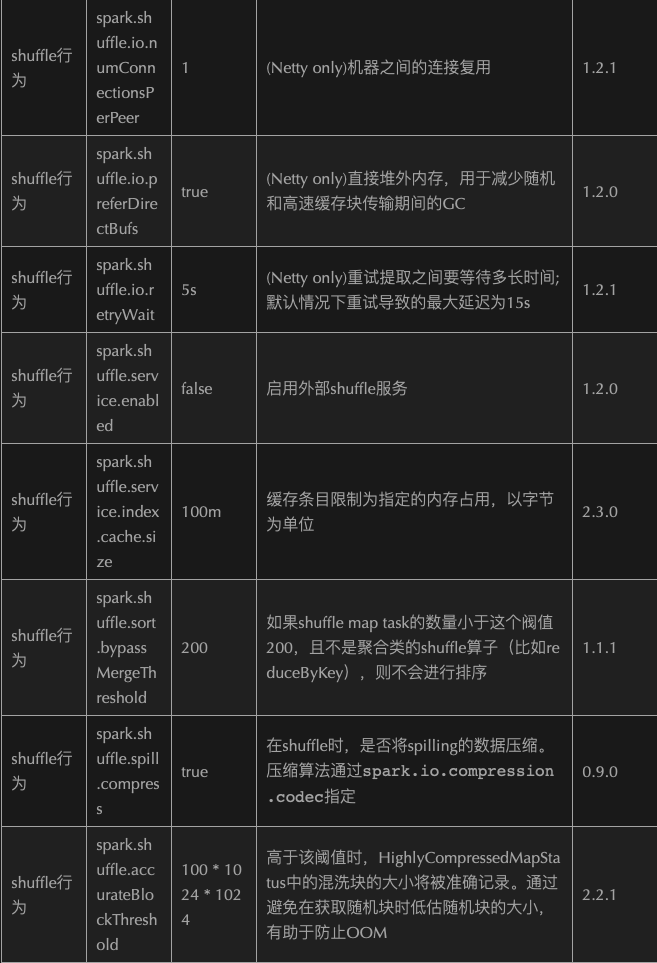
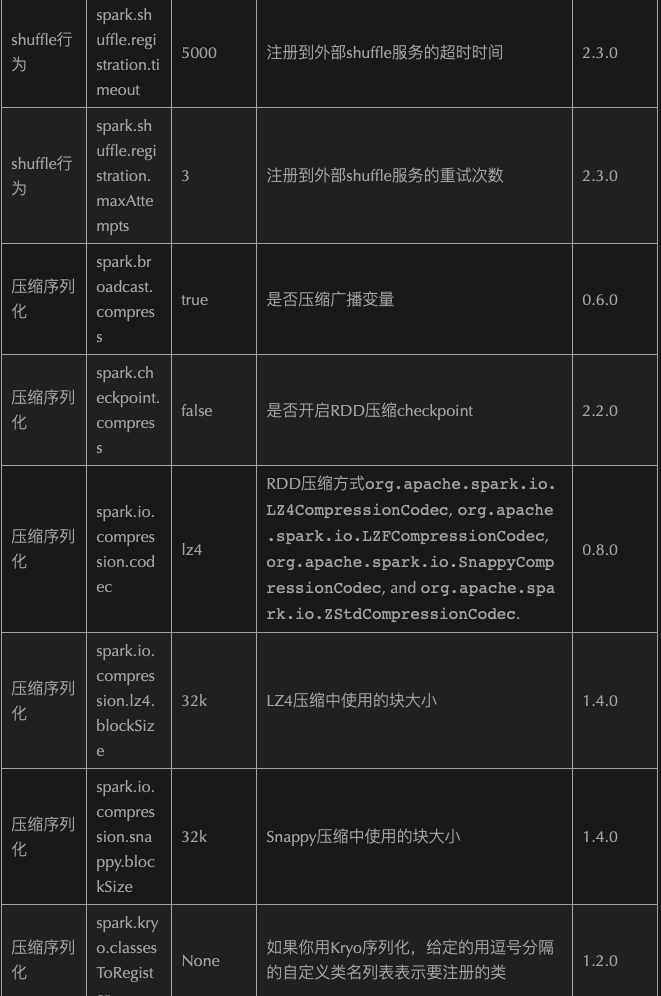

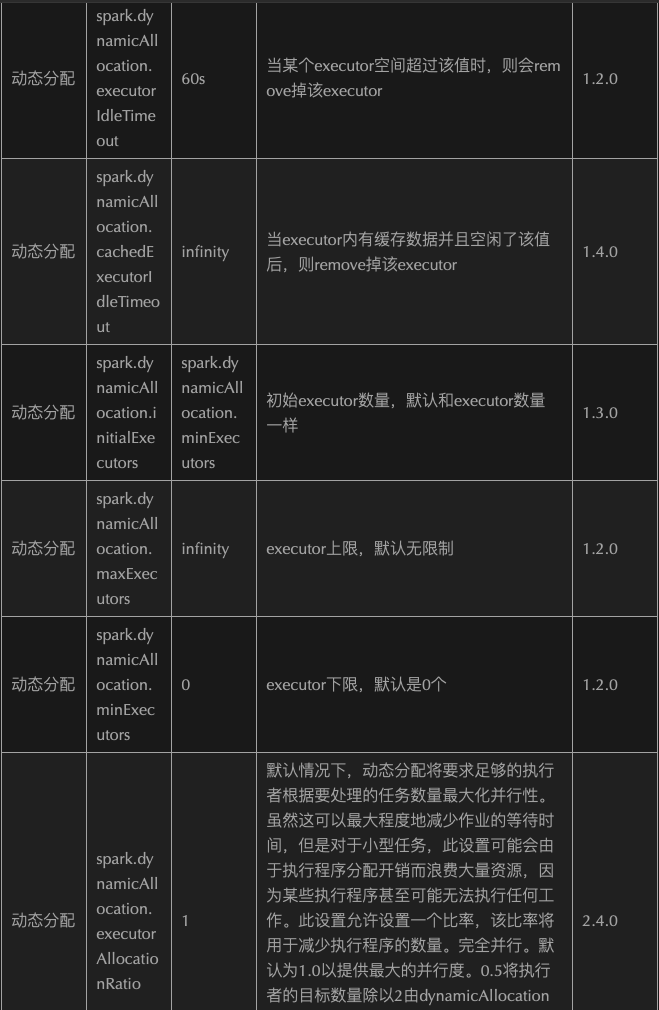
2.1.9、Optimize—->Submit
2.1.9.0、Spark On Yarn
2.1.9.0.1、Jar包管理及本地性调优
spark.yarn.jars :将jar包放到hdfs上,避免每次driver启动的时候都要进行jar包的分发。
yarn.nodemanager.localizer.cache.cleanip.interval-ms:配置缓存清理间隔,spark程序启动时,其他节点会根据上面的参数配置下载jar包并缓存在本地,如果下次启动的时候包没有变化,则直接使用。
2.1.9.0.2、调度模型调优
1、Yarn层面的队列资源分配
主要是在提交阶段,如果需要申请的资源大于当前yarn可用资源,那么应用程序就会一直处于等待状态,因此可以根据应用程序类型进行分类,提交到不同的队列上,或者调整队列的资源,或者调整分配策略(Fair/Capcaity/FIFO)
2、Executor端的资源分配
“常见的一个错误如:Container Killed By Yarn for exceeding memory limits. 42GB of 40GB physical memory used.Consider boosting spark.yarn.executor.memoryOverhead。”
从错误提示可以看出Executor端内存被用完了,可以按照提示的参数进行调整内存。
通常出现这种问题可以考虑以下几个方案(总体还是围绕着统一动态内存模型):
1、减少RDD缓存的操作(主要是减少存储内存占用)
2、增加Job的spark.storage.memroyFraction值(增大计算内存)
3、增加spark.yarn.executor.memoryOverhead (增大堆外内存)
3、Driver端的资源分配
1、当需要把结果返回到Driver端时,可以调大内存。
2、当使用yarn-cluster模式时,Driver运行在某个节点上,那么对应的JVM PermGen一般是默认值(82MB),很容易会出现栈溢出的问题,即出现PermGen Out Of Memory error Log信息。这个时候可以在spark-submit脚本中配置PermGen。
-conf spark.driver.extraJavaOptions=”-XX:PermSize=128MB -XX:MaxPermSize=256MB”
2.1.9.1、Optimize—->Operator&RDD
2.1.9.1.1、使用mapPartitions或者mapPartitionWithIndex代替map操作。
2.1.9.1.2、使用foreachPartition代替foreach
2.1.9.1.3、使用coalesce代替repartition,避免不必要的shuffle
2.1.9.1.4、使用repartitionAndSortWithinPartitions取代repartition和sort联合操作
2.1.9.1.5、使用treeAggregate代替Aggregate
2.1.9.1.6、使用treeReduce代替reduce
treeReduce类似于treeAggregate,在Executor端进行多次Aggregate来减少Driver的计算开销
2.1.9.1.7、使用AggregateByKey代替groupByKey(减少不必要的数据传输,可提前进行combine)
2.1.9.1.8、RDD复用
原则:
1、避免创建重复的RDD
2、尽可能复用同一个RDD
3、对多次使用的RDD进行持久化(无需每次从源头开始计算)
2.1.9.1.9、广播变量使用
2.1.9.1.10、使用kryo代替默认的序列化器
spark提供了两个序列化类库
Java序列化:默认序列化,适用于所有实现了java.io.Serializable的类。可以通过继承java.io.Externalizable,能进一步控制序列化的性能。Java序列化比较灵活,但是速度较慢。
Kryo序列化:速度高且结果更加紧凑,但是不支持所有的类型,也就是说支持org.apache.spark.serializer的子类,但不支持java.io.serializable接口的类型,所以需要提前注册程序中所使用的类。对于网络密集型的应用,可以采用该种方式。
如通过System.setProperty(“spark.serializer”,”spark.kryo.serializer”)
当然如果不使用kryo序列化器的话,也是可以的,但是每个对象实例的序列化结果都会包含一份完整的类名,有点浪费空间。
2.1.9.1.11、使用FastUtil优化JVM数据格式解析(性能上提升不会很大)
FastUtil扩展了Java标准集合框架(Map,List,Set…)的类库,提供了特殊类型的map,set,list和queue。
FastUtil提供了更小的内存占用,更快的存取速度。可以使用FastUtil提供的集合类代替JDK原生的集合。除了对象和原始类型为元素的集合外,FastUtil还提供了引用类型的支持,但是对引用类型是使用=来进行比较的,而不是equals方法。
使用场景:
1、如果算子函数使用了外部变量,
一:可以使用广播变量进行优化;
二:可以使用kryo序列化器,提升序列化性能和效率
三:如果外部变量是某种比较大的集合,那么可以使用FastUtil改写外部变量,即从源头上减少内存占用,然后再结合第一、二两个手段进行优化;
2、如果在算子函数内的计算逻辑里面,要创建比较大的Map,List等集合,那么会占用比较大的内存空间,也可能会涉及到遍历、存取等操作;这个时候可以考虑使用FastUtil类库进行重写,在一定程度上减少Task创建出来的集合类型的内存占用,避免Executor内存爆满,频繁GC
2.1.9.1.12、Persist和Checkpoint
Persist操作根据缓存数据量情况以及内存大小来选择存储策略。
在执行checkpoint之前先对RDD进行persist操作,主要是因为checkpoint会触发一个job,如果执行checkpoint的rdd是由其他rdd经过计算转换过来的,而如果没有persist这个rdd的话,那么就又要从头开始计算这个rdd,也就是做了很多重复性的计算工作。
因此建议先perist RDD,在执行checkpoint的时候会丢弃该RDD之前的依赖关系,使得该rdd作为顶层父RDD。
2.1.9.1.13、序列化问题
在spark应用程序中如果引用了无法序列化的变量或者类的话,会遇到”org.apache.spark.SparkException:Task not serializable”问题,对于变量只需要标注@transient注解即可,即表示不需要进行序列化;对于类的话需要进行序列化(extends Serializable)
2.1.9.2、Optimize—->Parallelity&Resouce allocate
2.1.9.2.1、内存示意图
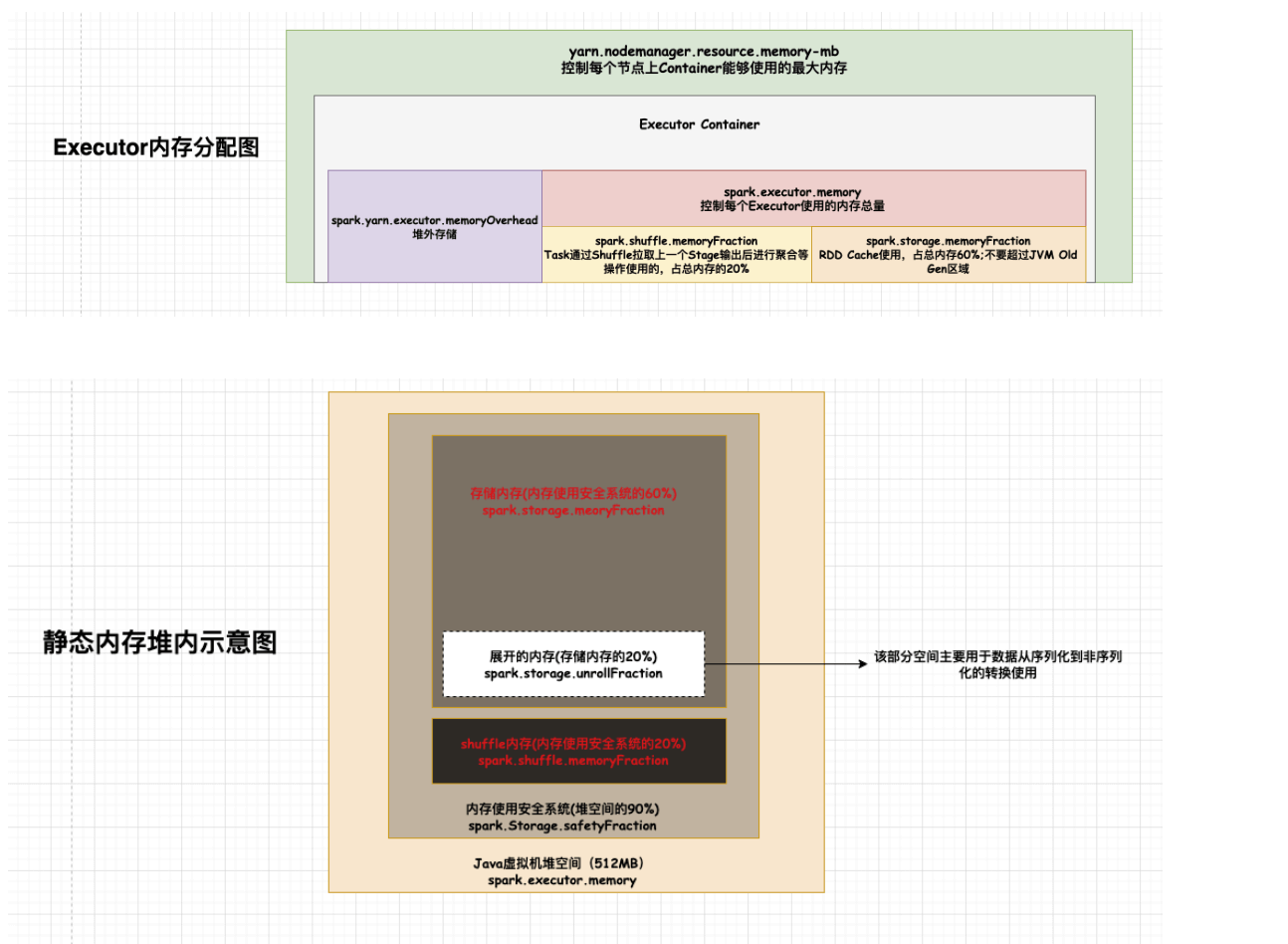
每个Executor支持的Task的并行处理数量取决于其Cpu Core的数量。
例如通过spark-submit或者spark-shell启动提交spark的时候,指定以下参数:—num-executors 10 —executor-cores 2
那么10指的是启动executor的数量;而2指的是每个executor运行的核数,也就是Executor能最大运行的并行数,对应每个核共享Executor分配到的总内存。
2.1.9.2.2、并行度
并行度就是spark作业中,每个Stage的同时运行Task数量。
合理的设置并行度,能够有效利用集群资源,避免造成浪费或者计算不足。适当提高并行度,可以减少task处理的数据量,同时也可以减少轮询的次数。
Task数量至少设置成和spark应用程序申请的总cpu core数量相同,例如一共150个Cpu Core,那么分配150个Task一起运行,差不多同一时间运行完毕。
当然官方推荐的是把Task数量设置成spark程序总cpu core数量的2~3倍。也就是说150个cpu core,那么基本上要设置task数量为300~500
2.1.9.3、Optimize—->Mapper/Reducer
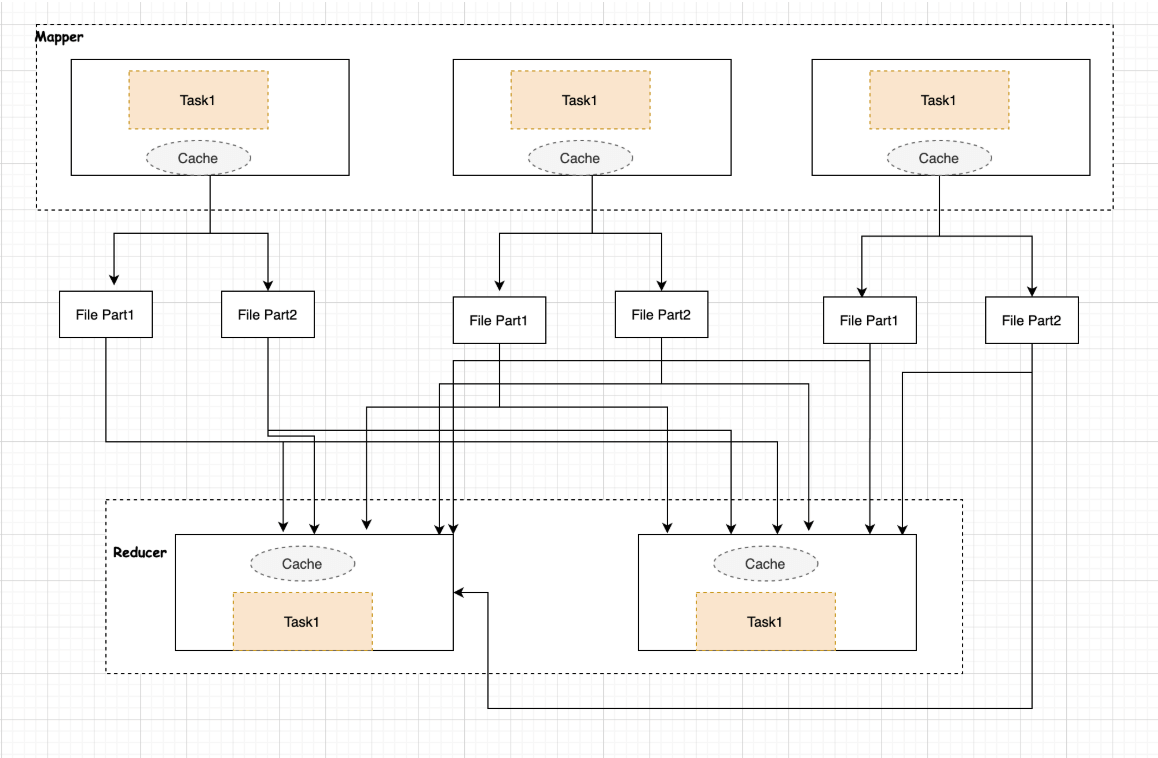
2.1.9.3.1、Mapper端调优
Spark Shuffle分为两部分:Mapper端和Reducer端。数据在传输到Reducer端的时候先进行Mapper端的处理,Mapper端会有一个缓存,数据会从缓存写入文件中,Mapper端的缓存根据Reducer的需求,将数据分成不同的部分,然后Reducer端抓取属于自己的数据进行reduce操作。那么在reducer端也有一个缓存,用来定义逻辑运行的地方。
由此可见对于Mapper端的内存性能调优主要在于缓存,通过log和web ui界面来观察不同的Stage分布在什么地方,读写的数据量等等来设置缓存大小,如果mapper端的缓存设置不合理的话,那么会频繁的往本地磁盘写数据,就会产生大量的磁盘IO操作。
Mapper端的缓存参数spark.shuffle.file.buffer的默认大小是32KB,用户根据数量和并发量来适当调整该参数,避免频繁发生磁盘IO。
2.1.9.3.2、Reducer端调优
spark shuffle中的reducer阶段获取数据,并不是等Mapper端全部结束之后才抓取数据,而是一边进行shuffle,一边抓取处理数据,Reducer在抓取的数据中间有一个缓存,类似于Java NIO方式,通过创建一个缓存区ByteBuffer,从通道把数据读入到缓冲区中,然后交由task进行处理。
在这里需要有三点可以作为性能调优的地方:
1、reducer端的代码基于缓存层处理数据,默认配置是为每个task配置48MB的缓存,设置参数为spark.reducer.maxSizeInFlight。也就是说可以调整缓存层的大小。当出现OOM的情况,那么就需要调小缓存层,因为占用的缓存越多,会产生大量的对象,从而出现OOM。同时如果调小缓存层,那么向Mapper端提取的次数就会变多,性能也就会降低,但相对而言首先思考的是应该先让程序跑起来,然后再考虑增加Executor内存,或者调大缓存来对性能层面进一步的改善。
2、在业务逻辑处理运行这一层,如果空间分配不够,那么数据会溢写到磁盘上,这个时候就会出现磁盘IO,也会导致不安全(读写故障),基于这种情况可以调节spark.shuffle.memoryFraction(reducer端默认的task堆大小是20%的空间),从20%调节到30%,40%等。调节越大,那么溢写的次数就会越少。
3、当Reducer端根据Driver提供的信息到Mapper端指定的位置获取数据的时候,会先定位所在的文件,但如果Mapper端出现GC那么就会无法响应数据的请求,那么就会出现shuffle file not found的问题。这个时候可以调节以下两个参数:
spark.shuffle.io.maxRetries=30;
spark.shuffle.io.retryWait=30s;
2.1.9.4、Optimize—->JVM On Compute
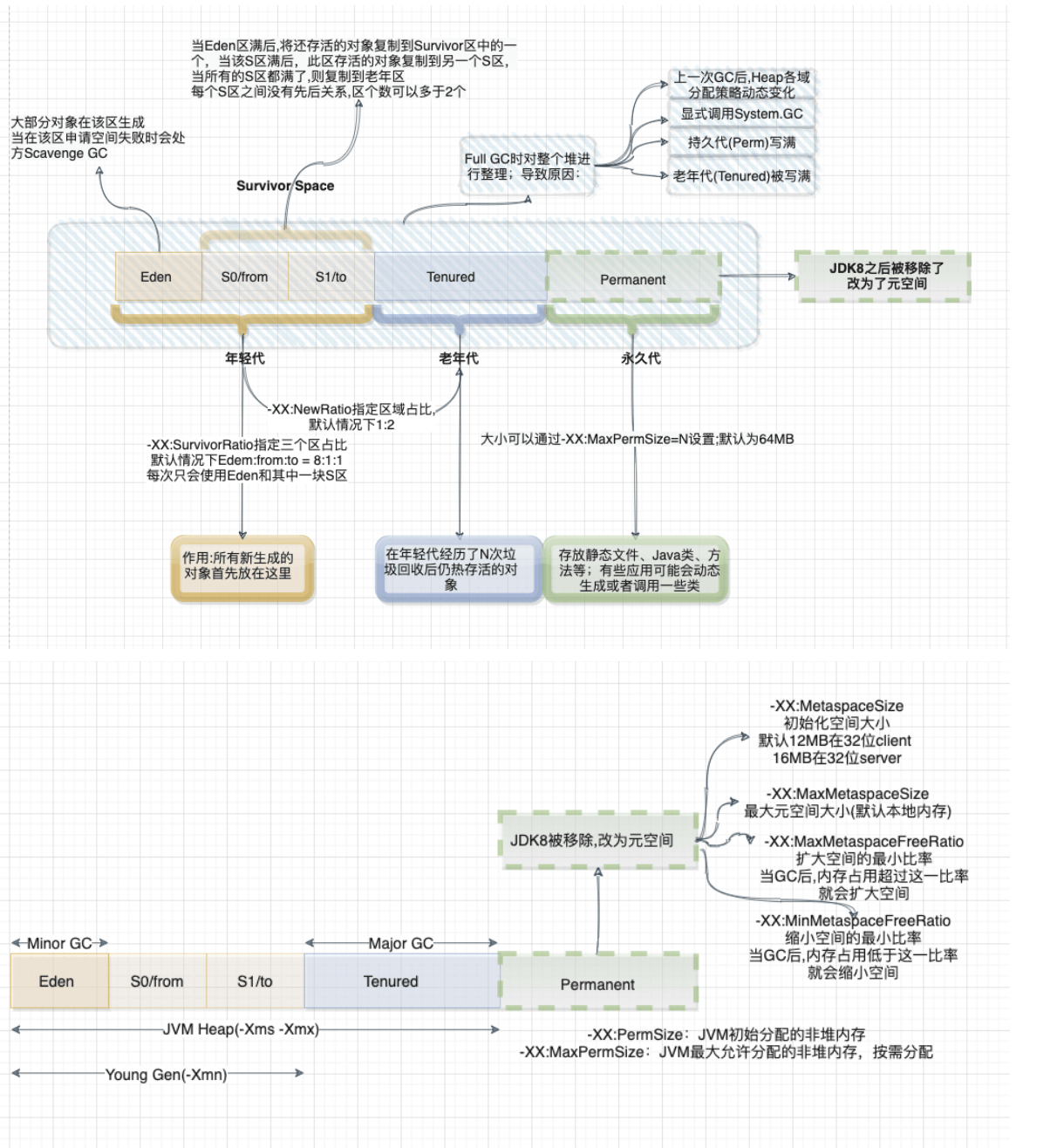
首要的一个问题就是GC,那么先来了解下其原理:
1、内存管理其实就是对象的管理,包括对象的分配和释放,如果显式的释放对象,只要把该对象赋值为null,即该对象变为不可达.GC将负责回收这些不可达对象的内存空间。
2、GC采用有向图的方式记录并管理堆中的所有对象,通过这些方式来确定哪些对象是可达的,哪些对象是不可达的。根据上图的JVM内存分配来看,当Eden满了之后,一个小型的GC将会被触发,Eden和Survivor1中幸存的仍被使用的对象被复制到Survivor2中。同时Survivor1和Survivor2区域进行交换,当一个对象生存的时间足够长,或者Survivor2满了,那么就会把存活的对象移到Old代,当Old空间快满的时候,这个时候会触发一个Full GC.
根据以上简单对GC的回顾,Spark GC调优的目的是确保Old代只存生命周期长的RDD,Young 代只保存短生命周期的对象,尽量避免发生Full GC。
那么这里梳理一下spark中关于Jvm的一些参数调优以及一些调优步骤:
1、针对MetaSpace:
-XX:MetaspaceSize:初始化元空间的大小
-XX:MaxMetaspaceSize:最大元空间大小
-XX:MinMetaspaceFreeRatio:扩大空间的最小比率,当GC后,内存占用超过这一比率后,就会扩大空间
-XX:MaxMetaspaceFreeRatio:缩小空间的最小比率,当GC后,内存占用低于这一比率,就会缩小空间。
默认的Metaspace只会受限于本地内存大小,当Metaspace达到MetaSpaceSize的当前大小时,就会触发GC.
2、GC查看步骤:
2.1、首先查看GC统计日志观察GC启动次数是否太多,可以给JVM设置参数-verbose:GC -XX:+PrintGCDetails,那么就可以在Worker日志中看到每次GC花费的时间;如果某个任务在结束之前,多次发生了Full GC,那么说明执行该任务的内存不够
spark-submit —name “app-name” \
—master local[4] \
—conf spark.shuffle.spill=false \
—conf “spark.executor.extraJavaOptions=-XX:+PrintGCDetails -XX:+PrintGCTimeStamps” \
jar_name.jar
2.2、如果GC信息显示,Old代空间快满了,那么可以降低spark.memory.storageFraction来减少RDD缓存占用的内存。先不要考虑执行性能问题,先让程序跑起来再说
2.3、如果Major GC比较少,但是Minor GC比较多,可以把Eden内存调大些。
3、计算内存和存储内存调整(钨丝计划就是专门来解决JVM性能问题的)
两者之间没有硬性界限,可以相互借用空间,通过参数spark.memory.fraction(默认0.75)来设置整个堆空间的比例。
spark.storage.memoryFraction:设置RDD持久化数据在Executor内存能占用的比例,默认是0.6;如果作业有较多的RDD持久化的话,那么该参数值可以调高些,避免内存不够缓存所有的数据,导致溢写磁盘;如果作业中shuffle类操作比较多,且频繁发生GC,那么可以适当调低该参数值。
spark.yarn.executor.memoryoverhead:如果数据量很大,导致Stage内存溢出,导致后面的Stage无法获取数据,如出现Shuffle file not found、Executor Task lost、Out Of Memory等问题时,可以调整该参数增大堆外内存。
spark.core.connection.ack.wait.timeout:当然对于not found ,file lost问题也可能是因为某些task去其他节点上拉取数据,而该节点正好正在进行GC,导致连接超时(默认60s),那么可以试着调大该参数值。
spark.shuffle.memoryFraction:设置shuffle过程一个task拉取上一个Stage的task输出后,进行聚合操作时能够使用Executor内存的比例,默认是0.2;如果shuffle使用的内存超过了这个限制,那么就会把多余的数据溢写到磁盘中,如果作业中RDD持久化的操作比较少的话,shuffle比较多的话,那么可以调大该值,降低缓存内存占用比例。
2.1.9.5、Optimize—->Shuffle On Compute
更详细的参数配置见2.1.8.6部分。
1、使用Broadcast实现Mapper端Shuffle。
也就是常说的MapJoin,即将较小的RDD进行广播到Executor上,让该Executor上的所有Task都共享该数据
2、Shuffle传输过程中的序列化和压缩。
序列化和压缩
spark.serializer=org.apache.spark.serializer.KryoSerializer
spark.shuffle.compress=true
spark.shuffle.spill.compress=true
spark.io.compression.codec=snappy
使用KryoSerializer的原因是因为其支持relocation,也就是说在把对象进行序列化之后进行排序,这种排序效果和先对数据排序再序列化是一样的。这个属性会在UnsafeShuffleWriter进行排序中用到。
3、为了避免Spark下的JVM GC可能会导致Shuffle拉取文件失败的问题,可以使用以下措施:
3.1、调整获取Shuffle数据的重试次数,默认是3次
3.2、调整获取Shuffle数据重试间隔,通过spark.shuffle.io.retryWait参数配置,默认为5s
3.3、适当增大reduce端的缓存空间,否则会spill到磁盘,同时也减少GC次数,可以通过spark.reducer.maxSizeInFlight参数配置
3.4、ShuffleMapTask端也可以增大Map任务写缓存,可以通过spark.shuffle.file.buffer,默认为32k
3.5、可以适当调大计算内存,减少溢写磁盘。
2.1.9.6、Optimize——>Data Skew
spark层面的数据倾斜定位可以通过以下几个方面:
1、通过spark web ui界面,查看每个Stage下的每个Task运行的数据量大小
2、通过Log日志分析定位是在哪个Stage中出现了倾斜,然后再定位到具体的Shuffle代码
3、代码走读,重点看Join,各种byKey的关键性代码
4、数据特征分布分析
针对数据倾斜有以下几种解决手段:
2.1.9.6.1、聚合过滤导致倾斜的Keys
2.1.9.6.2、提高并行度
其主要思想在于把一个Task处理的数据量拆分为多份给不同的task进行处理,进而减轻Task的压力,其本质在于数据的分区策略。
例如
1、通过repartition或者coalesce进行重分区
2、对外部数据读取设置最小分区数
3、在使用涉及到shuffle类算子时,可以显示指定分区数(默认spark会推导分区数)
4、设置默认spark.default.parallelism并行度
2.1.9.6.3、随机Key二次聚合
使用场景:对于各种byKey操作,可以将每个key通过加上随机数前缀进行拆分,先做局部聚合,然后将随机数拆掉在做全局聚合。
2.1.9.6.4、MapJoin
使用场景:两个RDD的数据量,其中一个RDD的数据量特别小,可以放到内存中。
2.1.9.6.5、采样倾斜Key单独处理
使用场景:两个RDD进行join操作,如果一个RDD倾斜严重,那么可以通过采样方式进行拆分,然后再分别和另外一个RDD进行join,最后把结果进行union。
2.1.9.6.6、随机Join
使用场景:两个RDD中的某一个Key或者某几个Key对应的数量很大,那么在Join的时候会发生倾斜。可以将RDD1中的一个或者几个Key加上随机数前缀,然后RDD2在相同的Key上做同样的处理。
2.1.9.6.7、扩容Join
使用场景:如果两个RDD的倾斜Key特别多,则可以将其中一个RDD的数据进行扩容N倍,另一个RDD的每条数据都打上一个n以内的随机前缀,最后进行join
2.2、Spark SQL
2.2.1、Execute Engine
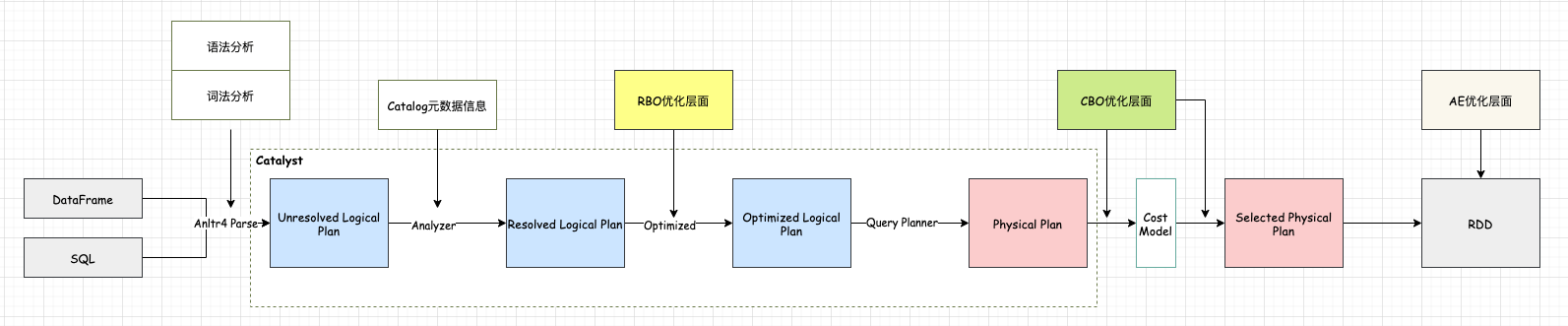
SparkSql的整体提交执行流程和Hive的执行流程基本上一致。站在通用的角度,对于SparkSql来说,从Sql到Spark的RDD执行需要经历两个大的阶段:逻辑计划和物理计划
逻辑计划层面会把用户提交的sql转换成树型结构,把sql中的逻辑映射到逻辑算子树的不同节点,该阶段并不会真正的进行提交执行,只是作为中间阶段。在这个过程中会经历三个阶段:
1、未解析的逻辑算子树(Unresolved LogicalPlan),该阶段只是通过Antlr Parser把sql进行词法分析,语法验证得到数据结构,并不包含任何数据信息。
2、解析后的逻辑算子数(Analyzed LogicalPlan),这个阶段会结合Catalog元数据信息对第一阶段得到的节点进行绑定
3、优化逻辑算子树(Optimized LogicalPlan),该阶段结合节点数据信息,应用一些优化规则对一些低效的逻辑计划进行转换。
物理计划层面会把上一步优化后的逻辑算子树进行进一步的转换,生成物理算子树,物理算子树上的节点会直接生成RDD或者对RDD进行transformation操作,并最终执行。那么对物理计划进行细分的话,又可以分为三个子阶段:
1、物理算子树列表(Iterable[PhysicalPlan]):根据优化后得到的逻辑算子树进行转换生成物理算子树的列表。
2、最优物理算子树(SparkPlan):从物理算子树列表中按照一定的策略选取最优的物理算子树。
3、准备算子树(Prepared SparkPlan):得到最优的算子树之后,那么就开始准备一些执行工作,如执行代码生成、确保分区操作正确、物理算子树节点重用等工作。
最后会对生成的RDD执行Action操作进行真正的作业执行。以上所有的流程均是在Spark的Driver端完成的,这个时候还不涉及到集群环境。
上述的所有流程可以通过SparkSession类的sql方法作为入口,调用SessionState各种对象(SparkSqlParser、Analyzer、Optimizer、SparkPlanner),最后封装一个QueryExecution对象。所以上面的每一步流程都有单独独立的类功能实现,对于我们日常开发工作中进一步剥离分析进行二次加工提供了很大的。
Spark SQL在执行SQL之前,会将SQL或者Dataset程序解析成逻辑计划,然后经历一系列的优化,最后确定一个可执行的物理计划。最终选择的物理计划的不同对性能有很大的影响。如何选择最佳的执行计划,这便是Spark SQL的Catalyst优化器的核心工作。Catalyst早期主要是基于规则的优化器(RBO),在Spark 2.2中又加入了基于代价的优化(CBO)。
2.2.1.1. RBO
根据上面的执行流程,SparkSql在逻辑优化层面主要是基于规则的优化,即RBO(Rule-Based-Optimization)
1、每个优化都是以Rule的形式存在,每条Rule都是对Analyzed Plan的等价转换
2、RBO易于扩展,新增规则可以非常方便嵌入到Optimizer中
3、RBO优化的主要思路在于减少参与计算的数据量以及计算本身的代价。
如常见的谓词下推、常量合并、列裁剪等优化手段
2.2.1.2、CBO
RBO层面的优化主要是针对逻辑计划,未考虑到数据本身的特点(数据分布、大小)以及算子执行(中间结果集分布、大小)的代价,因此sparksql又引入了CBO优化机制(Cost-Based Optimized),该优化主要在物理计划层面,其原理是计算所有可能的物理计划的代价,并挑选出代价最小的物理计划,其核心在于评估一个给定的物理执行计划的代价,其代价等于每个执行节点的代价总和。而每个执行节点的代价,又分为两个部分:
1、该执行节点对数据集的影响,或者说该节点输出数据集的大小和分布。
2、该执行节点操作算子的代价。操作算子的代价相对比较固定,可以用规则来描述。
而执行节点输出数据集主要分为两部分:
1、初始数据集,例如原始文件,其数据集的大小和分布可以直接统计得到的。
2、中间节点输出数据集的大小和分布可以根据输入数据集的信息和操作本身的特点来推算。
因此CBO优化最主要需要先解决两个问题:
1、怎么样子可以获取到原始数据集的统计信息
2、如何根据输入数据集估算特定算子的输出数据特征情况
2.2.1.2.1、如何统计到原始数据集的信息
可以通过Analyze table来分析统计出原始数据集的大小
-- 分析表整体数据情况>ANALYZE TABLE table_name COMPUTE STATISTICS;>DESC EXTENDED table_name# Detailed Table InformationDatabase database_nameTable table_nameOwner testCreated Time Sat Sep 15 14:00:40 CST 2018Last Access Thu Jan 01 08:00:00 CST 1970Created By Spark 2.3.1Type EXTERNALProvider hiveTable Properties [transient_lastDdlTime=1536997324]Statistics 37026233 bytes, 280000 rowsLocation hdfs://pathSerde Library org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDeInputFormat org.apache.hadoop.mapred.TextInputFormatOutputFormat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormatStorage Properties [field.delim=|, serialization.format=|]Partition Provider Catalog--分析字段情况>ANALYZE TABLE table_name COMPUTE STATISTICS FOR COLUMNS [column1] [,column2] [,column3] [,column4] ... [,columnn];--启用histogram,其distinct_count是通过HyperLogLog统计的一个近似值,主要是速度快;其中bin的个数是由spark.sql.statistics.histogram.numBins来控制> SET spark.sql.statistics.histogram.enabled=true;>DESC EXTENDED table_namecol_name column_namedata_type bigintcomment NULLmin 1max 280000num_nulls 0distinct_count 274368avg_col_len 8max_col_len 8histogram height: 1102.3622047244094, num_of_bins: 254bin_0 lower_bound: 1.0, upper_bound: 1090.0, distinct_count: 1089bin_1 lower_bound: 1090.0, upper_bound: 2206.0, distinct_count: 1161bin_2 lower_bound: 2206.0, upper_bound: 3286.0, distinct_count: 1124
2.2.1.2.2、算子代价估计
SQL中最常见的就是Join操作,这里以Join方法为例,说明SparkSql的CBO是如何进行估价的。主要是通过以下公式:
Cost = rows weight + size (1-weight) ;其中rows为行数代表CPU代价,Size为大小代表IO代价。
Cost = CostCpu weight + CostIO (1-weight)
Weight权重的配置可以通过spark.sql.cbo.joinRecorder.card.weight决定,默认为0.7
2.2.1.3、AE
参考设计文档
2.2.1.3.1、背景
在生产环境中,往往需要提前配置好分区数以及使用资源,然后在运行的过程中或者事后进行不断的调整参数值来达到最优。但是由于每次计算的数据量可能会变化很大,那么可能需要每次都会人工干涉进行调优,这也意味sql作业很难以最优的性能去运行。而且Catalyst优化器的一些优化工作是在计划阶段,一旦优化完成之后,在运行期间就不能改变。因此需要在运行期间拿到更多的运行信息,不断调整执行计划来达到最优,因此在Spark2.3之后引入了一个Adaptive(自适应)执行机制,需要通过spark.sql.adaptive.enabled参数来开启其机制
2.2.1.3.2、执行原理
根据Spark作业执行流程可知是先根据RDD的DAG图进行划分生成Stage然后提交作业执行,因此在执行过程中计划是不会发生变化的。那么
自适应执行的基本思路是在执行计划中事先划分好stage,然后按stage提交执行,在运行时收集当前stage的shuffle统计信息,以此来优化下一个stage的执行计划,然后再提交执行后续的stage。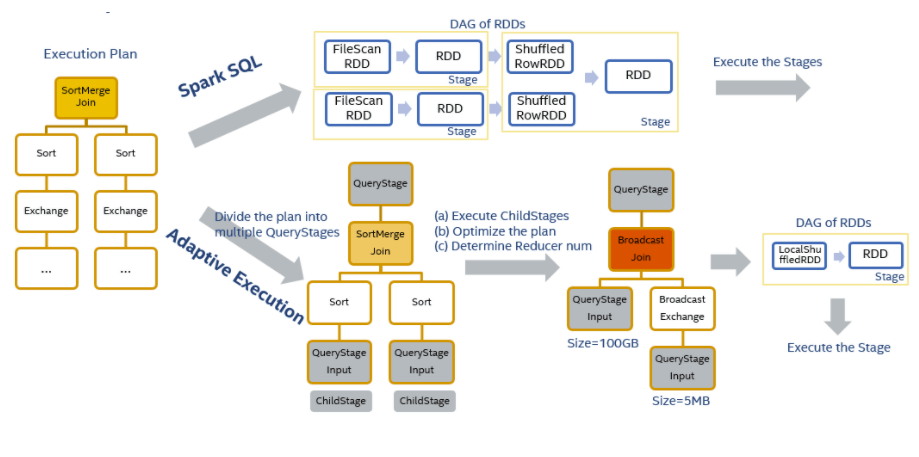
对于图中两表join的执行计划来说会创建3个QueryStage。最后一个QueryStage中的执行计划是join本身,它有2个QueryStageInput代表它的输入,分别指向2个孩子的QueryStage。在执行QueryStage时,我们首先提交它的孩子stage,并且收集这些stage运行时的信息。当这些孩子stage运行完毕后,我们可以知道它们的大小等信息,以此来判断QueryStage中的计划是否可以优化更新。例如当我们获知某一张表的大小是5M,它小于broadcast的阈值时,我们可以将SortMergeJoin转化成BroadcastHashJoin来优化当前的执行计划。我们也可以根据孩子stage产生的shuffle数据量,来动态地调整该stage的reducer个数。在完成一系列的优化处理后,最终我们为该QueryStage生成RDD的DAG图,并且提交给DAG Scheduler来执行
2.2.1.3.3、实现点
该机制主要有三个功能点:
1、自动设置shuffle分区数
主要解决的问题有以下几点:
1.1、如果设置分区数过小可能会导致每个task处理大量的数据,会发生溢写磁盘的情况影响性能,甚至发生频繁GC或者OOM。
1.2、如果设置分区数过大可能会导致每个task处理小量的数据,而且会有可能产生小文件,甚至会出现资源空闲的情况。
1.3、设置分区数是对所有的Stage都会生效,而每个Stage所处理的数据量和分布都不太一样,所以全局的分区数只能对某些Stage是最优的,无法做到全局最优。
例如我们设置的shufflepartition个数为5,在map stage结束之后,我们知道每一个partition的大小分别是70MB,30MB,20MB,10MB和50MB。假设我们设置每一个reducer处理的目标数据量是64MB,那么在运行时,我们可以实际使用3个reducer。第一个reducer处理partition 0 (70MB),第二个reducer处理连续的partition 1 到3,共60MB,第三个reducer处理partition 4 (50MB)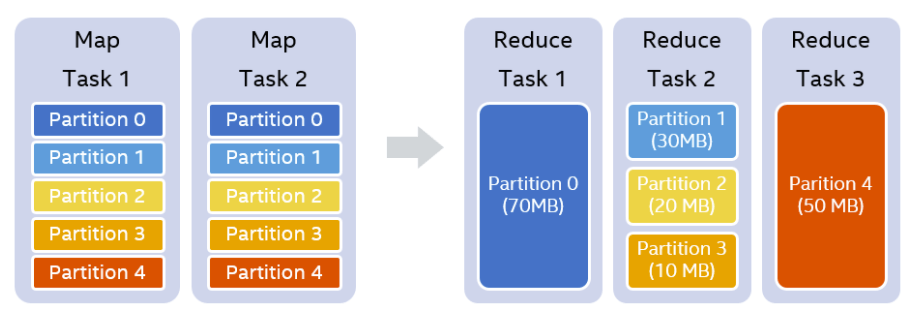

2、动态调整执行计算
以join操作为例,在Spark中最常见的策略是BroadcastHashJoin和SortMergeJoin。BroadcastHashJoin属于map side join,其原理是当其中一张表存储空间大小小于broadcast阈值时,Spark选择将这张小表广播到每一个Executor上,然后在map阶段,每一个mapper读取大表的一个分片,并且和整张小表进行join,整个过程中避免了把大表的数据在集群中进行shuffle。而SortMergeJoin在map阶段2张数据表都按相同的分区方式进行shuffle写,reduce阶段每个reducer将两张表属于对应partition的数据拉取到同一个任务中做join。CBO根据数据的大小,尽可能把join操作优化成BroadcastHashJoin。Spark中使用参数spark.sql.autoBroadcastJoinThreshold来控制选择BroadcastHashJoin的阈值,默认是10MB。然而对于复杂的SQL查询,它可能使用中间结果来作为join的输入,在计划阶段,Spark并不能精确地知道join中两表的大小或者会错误地估计它们的大小,以致于错失了使用BroadcastHashJoin策略来优化join执行的机会。但是在运行时,通过从shuffle写得到的信息,我们可以动态地选用BroadcastHashJoin。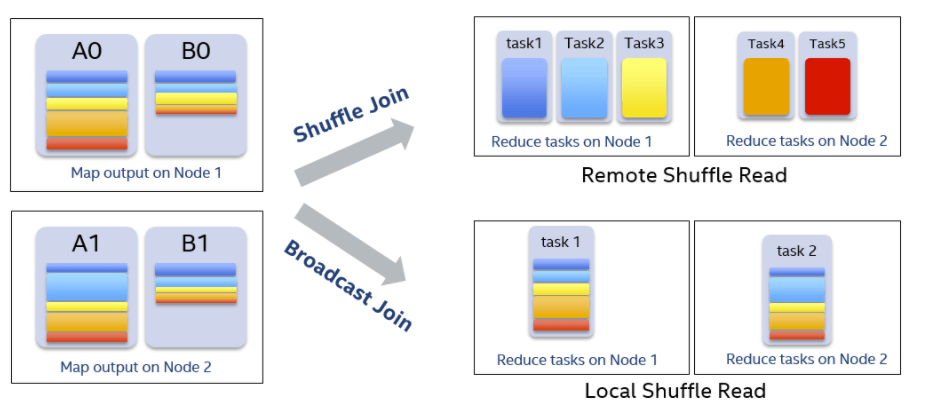
3、动态处理数据倾斜
在SQL作业中,数据倾斜是很常见的问题,但都是事后人为通过一些手段进行解决的,那么能不能在运行时自动处理掉呢?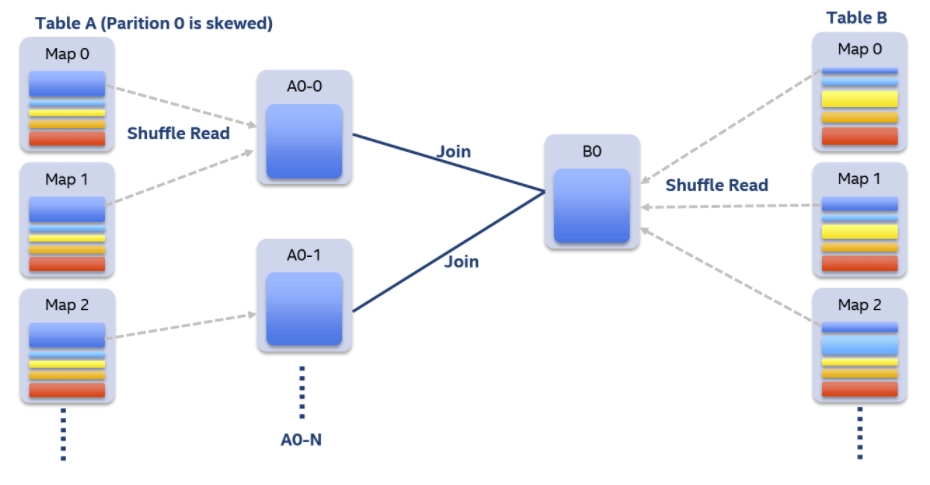
假设A表和B表做inner join,并且A表中第0个partition是一个倾斜的partition。
一般情况下,A表和B表中partition 0的数据都会shuffle到同一个reducer中进行处理,由于这个reducer需要通过网络拉取大量的数据并且进行处理,它会成为一个最慢的任务拖慢整体的性能。
在自适应执行框架下,一旦我们发现A表的partition 0发生倾斜,我们随后使用N个任务去处理该partition,每个任务只读取若干个mapper的shuffle 输出文件,然后读取B表partition 0的数据做join。最后,我们将N个任务join的结果通过Union操作合并起来。
为了实现这样的处理,我们对shuffle read的接口也做了改变,允许它只读取部分mapper中某一个partition的数据。在这样的处理中,B表的partition 0会被读取N次,虽然这增加了一定的额外代价,但是通过N个任务处理倾斜数据带来的收益仍然大于这样的代价。
如果B表中partition 0也发生倾斜,对于inner join来说我们也可以将B表的partition 0分成若干块,分别与A表的partition 0进行join,最终union起来。但对于其它的join类型例如Left Semi Join我们暂时不支持将B表的partition 0拆分。
4、Left join build left side map
参考字节关于SparkSQL的优化
对于left join的情况,可以对左表进行HashMapBuild。可以实现小左表left join 大右表的情况下进行ShuffledHashJoin调整。
原理:
1、在构建左表Map的时候,额外维持一个“是否匹配成功”的映射表。
2、在和右表join结束之后,把所有没有匹配到的key,用null来join填充。


2.2.2、Join Type
2.2.2.1、Broadcast Hash Join (Not Shuffled)
就是常说的MapJoin,join操作在map端进行的。
场景:join的其中一张表要很小,可以放到Driver或者Executor端的内存中。
原理:
1、将小表的数据广播到所有的Executor端,利用collect算子将小表数据从Executor端拉到Driver端,然后在Driver端使用广播到Executor端
2、Executor端将大表和这个广播数据进行Join,这样就避免了Shuffle.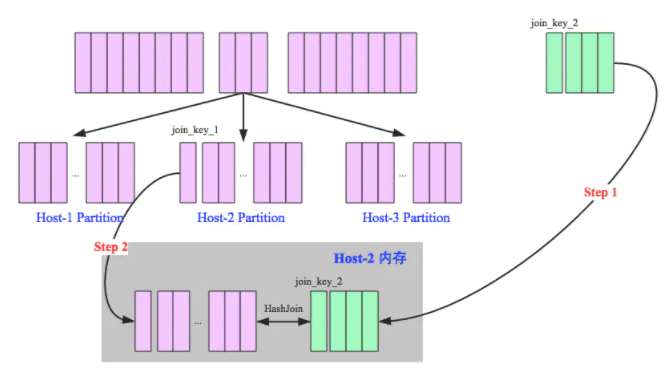
条件:
1、小表必须足够小,可以通过spark.sql.autoBroadcastJoinThreshold参数来设置,默认是10MB。如果设置为-1,则关闭Broadcast Hash Join
2、只能用于等值Join,不要求参与Join的keys排序
3、除了full outer join,支持其他所有Join
4、人为添加Hint(MAPJOIN、BROADCASTJOIN、BROADCAST) (Option)
2.2.2.2、Broadcast Nested Loop Join (Fallback option)

该Join策略是在没有合适的Join机制可以选择的时候,最后选择的一种。在Cartesian和Broadcast Nested Loop Join之间,如果是内连接,或者是非等值连接,那么会优先选择Broadcast Nested Loop策略。该类型Join会根据相关条件对小表进行广播,以减少表的扫描次数。触发条件:
1、Rigth Outer Join是会广播左表
2、Left Outer,Left semi ,Left Anti或者existence Join会广播右表
3、inner join的时候两张表都会广播
条件:
支持等值和非等值Join。
2.2.2.3、Shuffle Hash Join(Single Partition is small engough to build a hash table)
当Join一张小表的时候,可以使用Broadcast Hash Join,但是如果小表逐渐变大,那么广播所需要的内存、网络IO资源也相应变大,所以如果小表的数据量超过了10M的限制,那么可以使用Shuffle Hash Join策略。
原理:(Key相同,分区必然相同)
1、Shuffle:大表和小表按照相同分区算法和分区数进行分区(根据参与join的keys进行分区),这样保证了hash值一样的数据都被分发到了同一个分区中,然后在同一个Executor中两个表hash值一样的分区就可以进行本地hash join了。
2、单机Hash Join:在进行join之前,还会对小表hash完的分区构建hash map。shuffle hash join采用了分治思想,把大问题拆解成小问题去解决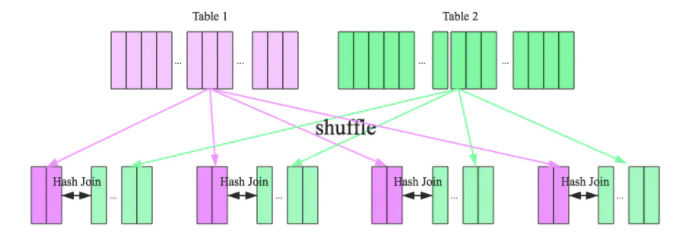
条件:
1、仅支持等值join,不要求参与join的keys排序
2、spark.sql.join.preferSortMergeJoin 参数必须设置为 false,参数是从 Spark 2.0.0 版本引入的,默认值为 true,也就是默认情况下选择 Sort Merge Join
3、小表的大小(plan.stats.sizeInBytes)必须小于 spark.sql.autoBroadcastJoinThreshold spark.sql.shuffle.partitions;而且小表大小(stats.sizeInBytes)的三倍必须小于等于大表的大小(stats.sizeInBytes),也就是 a.stats.sizeInBytes 3 < = b.stats.sizeInBytes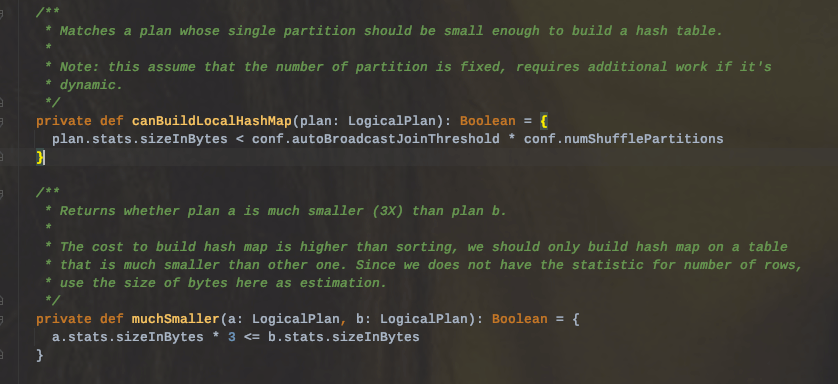
2.2.2.4、Shuffle Sort Merge Join (Matching join keys are sortable)
Hash Join通常适用于存在至少一个小表的情况,但如果都是大表的话,那么就需要考虑Sort Merge Join了。该Join策略是Spark默认的,可以通过spark.sql.join.preferSortMergeJoin进行配置(默认就是true)
原理:
1、Shuffle阶段:对两个表参与Join的keys使用相同的分区算法和分区数进行分区,目的就是为了保障相同的key都分配到相同的分区里面
2、Sort阶段:分区之后再对每个分区按照参与keys进行排序
3、Merge阶段:最后reducer端获取两张表相同分区的数据基于顺序查找的方式进行Merge Join,如果keys相同就说明join上了。如果流表的迭代遍历器得到的Key值比构建表迭代得到的Key值小,那么就移动流表的迭代器;如果流表的迭代遍历器比构建表迭代得到的Key值要大,那么则移动构建表的迭代器;如果二者相同,则说明满足Join条件。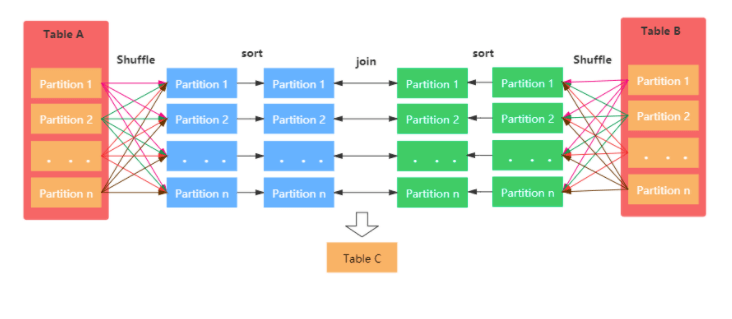
条件:
仅支持等值join,而且要求参与join的keys是可排序的
2.2.2.5、Cartesian Product Nested Loop Join
如果Spark中多个表参与Join而且没有指定Key,那么就会产生Cartesian Product Join。
产生的数据行数是两表的乘积,当Join的表很大的时候,效率是非常低的。尽量不使用
条件:
1、必须是inner join,支持等值和不等值Join
2、参数spark.sql.crossJoin.enabled=true
2.2.2.6、Conclusion
/*** Select the proper physical plan for join based on joining keys and size of logical plan.** At first, uses the [[ExtractEquiJoinKeys]] pattern to find joins where at least some of the* predicates can be evaluated by matching join keys. If found, join implementations are chosen* with the following precedence:** - Broadcast hash join (BHJ):* BHJ is not supported for full outer join. For right outer join, we only can broadcast the* left side. For left outer, left semi, left anti and the internal join type ExistenceJoin,* we only can broadcast the right side. For inner like join, we can broadcast both sides.* Normally, BHJ can perform faster than the other join algorithms when the broadcast side is* small. However, broadcasting tables is a network-intensive operation. It could cause OOM* or perform worse than the other join algorithms, especially when the build/broadcast side* is big.** For the supported cases, users can specify the broadcast hint (e.g. the user applied the* [[org.apache.spark.sql.functions.broadcast()]] function to a DataFrame) and session-based* [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold to adjust whether BHJ is used and* which join side is broadcast.** 1) Broadcast the join side with the broadcast hint, even if the size is larger than* [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]]. If both sides have the hint (only when the type* is inner like join), the side with a smaller estimated physical size will be broadcast.* 2) Respect the [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold and broadcast the side* whose estimated physical size is smaller than the threshold. If both sides are below the* threshold, broadcast the smaller side. If neither is smaller, BHJ is not used.** - Shuffle hash join: if the average size of a single partition is small enough to build a hash* table.** - Sort merge: if the matching join keys are sortable.** If there is no joining keys, Join implementations are chosen with the following precedence:* - BroadcastNestedLoopJoin (BNLJ):* BNLJ supports all the join types but the impl is OPTIMIZED for the following scenarios:* For right outer join, the left side is broadcast. For left outer, left semi, left anti* and the internal join type ExistenceJoin, the right side is broadcast. For inner like* joins, either side is broadcast.** Like BHJ, users still can specify the broadcast hint and session-based* [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold to impact which side is broadcast.** 1) Broadcast the join side with the broadcast hint, even if the size is larger than* [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]]. If both sides have the hint (i.e., just for* inner-like join), the side with a smaller estimated physical size will be broadcast.* 2) Respect the [[SQLConf.AUTO_BROADCASTJOIN_THRESHOLD]] threshold and broadcast the side* whose estimated physical size is smaller than the threshold. If both sides are below the* threshold, broadcast the smaller side. If neither is smaller, BNLJ is not used.** - CartesianProduct: for inner like join, CartesianProduct is the fallback option.** - BroadcastNestedLoopJoin (BNLJ):* For the other join types, BNLJ is the fallback option. Here, we just pick the broadcast* side with the broadcast hint. If neither side has a hint, we broadcast the side with* the smaller estimated physical size.*/object JoinSelection extends Strategy with PredicateHelper {def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {// --- BroadcastHashJoin --------------------------------------------------------------------// broadcast hints were specified;如果指定了broadcast方言,那么就优先使用case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)if canBroadcastByHints(joinType, left, right) =>val buildSide = broadcastSideByHints(joinType, left, right)Seq(joins.BroadcastHashJoinExec(leftKeys, rightKeys, joinType, buildSide, condition, planLater(left), planLater(right)))// broadcast hints were not specified, so need to infer it from size and configuration.//如果没有指定方言,那么会根据数据量大小来自行决定是否进行broadcastcase ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)if canBroadcastBySizes(joinType, left, right) =>val buildSide = broadcastSideBySizes(joinType, left, right)Seq(joins.BroadcastHashJoinExec(leftKeys, rightKeys, joinType, buildSide, condition, planLater(left), planLater(right)))// --- ShuffledHashJoin ---------------------------------------------------------------------// 发生Shuffle 的Hash Join,分区内的数据可构建Hash Tablecase ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)if !conf.preferSortMergeJoin && canBuildRight(joinType) && canBuildLocalHashMap(right)&& muchSmaller(right, left) ||!RowOrdering.isOrderable(leftKeys) =>Seq(joins.ShuffledHashJoinExec(leftKeys, rightKeys, joinType, BuildRight, condition, planLater(left), planLater(right)))case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)if !conf.preferSortMergeJoin && canBuildLeft(joinType) && canBuildLocalHashMap(left)&& muchSmaller(left, right) ||!RowOrdering.isOrderable(leftKeys) =>Seq(joins.ShuffledHashJoinExec(leftKeys, rightKeys, joinType, BuildLeft, condition, planLater(left), planLater(right)))// --- SortMergeJoin ------------------------------------------------------------//谓词可排序case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)if RowOrdering.isOrderable(leftKeys) =>joins.SortMergeJoinExec(leftKeys, rightKeys, joinType, condition, planLater(left), planLater(right)) :: Nil// --- Without joining keys ------------------------------------------------------------// 非等值Join// Pick BroadcastNestedLoopJoin if one side could be broadcastcase j @ logical.Join(left, right, joinType, condition)if canBroadcastByHints(joinType, left, right) =>val buildSide = broadcastSideByHints(joinType, left, right)joins.BroadcastNestedLoopJoinExec(planLater(left), planLater(right), buildSide, joinType, condition) :: Nilcase j @ logical.Join(left, right, joinType, condition)if canBroadcastBySizes(joinType, left, right) =>val buildSide = broadcastSideBySizes(joinType, left, right)joins.BroadcastNestedLoopJoinExec(planLater(left), planLater(right), buildSide, joinType, condition) :: Nil// Pick CartesianProduct for InnerJoincase logical.Join(left, right, _: InnerLike, condition) =>joins.CartesianProductExec(planLater(left), planLater(right), condition) :: Nilcase logical.Join(left, right, joinType, condition) =>val buildSide = broadcastSide(left.stats.hints.broadcast, right.stats.hints.broadcast, left, right)// This join could be very slow or OOMjoins.BroadcastNestedLoopJoinExec(planLater(left), planLater(right), buildSide, joinType, condition) :: Nil// --- Cases where this strategy does not apply ---------------------------------------------case _ => Nil}}}
Spark2.4 + 引入了Join Hint,来优化spark的计算引擎,从而选择正确的Join策略。当然用户也可以手动选择策。用户指定的Join Hint优先级是最高的。逻辑如下:
1、先判断是不是等值Join
1.1、判断用户是否指定了BroadCast Hint(Broadcast、BroadcastJoin以及MapJoin中的一个),如果指定了则用Broadcast Hash Join。
1.2、判断用户是否指定了Shuffle Merge Hint(Shuffle_Merge,Merge以及MergeJoin中的一个),如果指定了则用Shuffle Sort Merge。
1.3、判断用户是否指定了Shuffle Hash Join Hint(SHUFFLE_HASH),如果指定了则用Shuffle Hash Join。
1.4、判断用户是否指定了Shuffle-and-replicate Nested Loop Join(SHUFFLE_REPLICATE_NL),如果指定了则用Cartesian Product Join。
1.5、如果用户没有指定任何Join Hint,那么就根据Join的策略Broadcast Hash Join —-> Shuffle Hash Join —> Sort Merge Join —-> Cartesian Product Join —> Broadcast Nested Loop Join顺序选择Join策略。
2、如果不是等值Join,则按照下面的顺序选择Join策略
2.1、判断用户是不是指定了 BROADCAST hint (BROADCAST、BROADCASTJOIN 以及 MAPJOIN 中的一个),如果指定了,那就广播对应的表,并选择 Broadcast Nested Loop Join;
2.2、用户是不是指定了 shuffle-and-replicate nested loop join hint (SHUFFLE_REPLICATE_NL),如果指定了,那就用 Cartesian product join;
2.3、如果用户没有指定任何 Join hint,那根据 Join 的适用条件按照 Broadcast Nested Loop Join—->Cartesian Product Join 顺序选择 Join 策略
2.2.3、Optimize
2.2.3.1、SQL
3.3.1.1、RB
1、Join选择
在Hadoop中,MR使用DistributedCache来实现mapJoin。即将小文件存放到DistributedCache中,然后分发到各个Task上,并加载到内存中,类似于Map结构,然后借助于Mapper的迭代机制,遍历大表中的每一条记录,并查找是否在小表中,如果不在则省略。
而Spark是使用广播变量的方式来实现MapJoin.
2、谓词下推
3、列裁剪
4、常量替换
5、分区剪枝
3.3.1.2、CBO
开启cbo之后(通过配置spark.sql.cbo.enabled),有以下几个优化点:
1、Build选择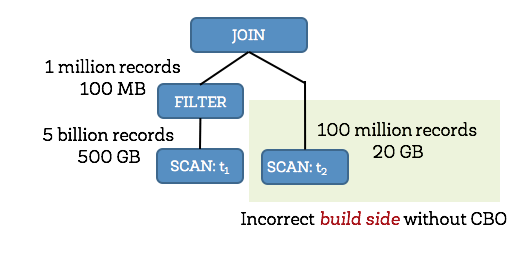
2、优化Join类型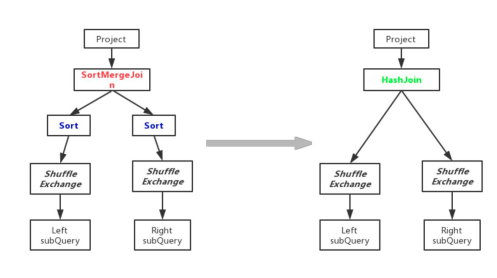
3、优化多Join顺序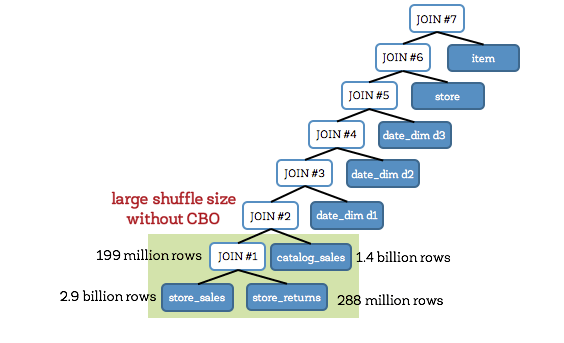
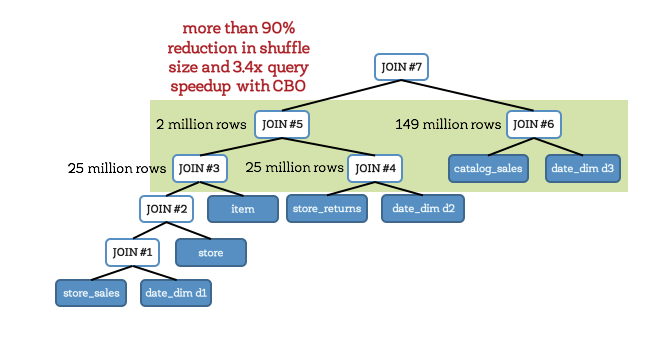
3.3.1.3、AE
3.3.1.3.1、Auto Setting The Shuffle Partition Number
| Property Name | Default | Meaning |
|---|---|---|
| spark.sql.adaptive.enabled | false | 设置为true,开启自适应机制 |
| spark.sql.adaptive.minNumPostShufflePartitions | 1 | 自适应机制下最小的分区数,可以用来控制最小并行度 |
| spark.sql.adaptive.maxNumPostShufflePartitions | 500 | 自适应机制下最大的分区数,可以用来控制最大并行度 |
| spark.sql.adaptive.shuffle.targetPostShuffleInputSize | 67108864 | 动态reducer端每个Task最少处理的数据量. 默认为 64 MB. |
| spark.sql.adaptive.shuffle.targetPostShuffleRowCount | 20000000 | 动态调整每个task最小处理 20000000条数据。该参数只有在行统计数据收集功能开启后才有作用 |
3.3.1.3.2、Optimizing Join Strategy at Runtime
| Property Name | Default | Meaning |
|---|---|---|
| spark.sql.adaptive.join.enabled | true | 运行过程是否动态调整join策略的开关 |
| spark.sql.adaptiveBroadcastJoinThreshold | equals to spark.sql.autoBroadcastJoinThreshold | 运行过程中用于判断是否满足BroadcastJoin条件。如果不设置,则该值等于 spark.sql.autoBroadcastJoinThreshold . |
3.3.1.3.3、Handling Skewed Join
| Property Name | Default | Meaning |
|---|---|---|
| spark.sql.adaptive.skewedJoin.enabled | false | 运行期间自动处理倾斜问题的开关 |
| spark.sql.adaptive.skewedPartitionFactor | 10 | 如果一个分区的大小大于所有分区大小的中位数而且大于spark.sql.adaptive.skewedPartitionSizeThreshold,或者分区条数大于所有分区条数的中位数且大于spark.sql.adaptive.skewedPartitionRowCountThreshold,那么就会被当成倾斜问题来处理 |
| spark.sql.adaptive.skewedPartitionSizeThreshold | 67108864 | 倾斜分区大小不能小于该值 |
| spark.sql.adaptive.skewedPartitionRowCountThreshold | 10000000 | 倾斜分区条数不能小于该值 |
| spark.shuffle.statistics.verbose | false | 启用后MapStatus会采集每个分区条数信息,用来判断是否倾斜并进行相应的处理 |
2.2.3.2、Compute
2.2.3.2.1、Dynamic Executor Allocation
2.2.3.2.2、Paralliesm
2.2.3.2.3、Data Skew/Shuffle
2.2.3.2.4、Properties
更多配置见
| Property Name | Default | Meaning |
|---|---|---|
| spark.sql.inMemorycolumnarStorage.compressed | true | 内存中列存储压缩 |
| spark.sql.codegen | false | 设置为true,可以为大型查询快速编辑创建字节码 |
| spark.sql.inMemoryColumnarStorage.batchSize | 10000 | 默认列缓存大小为10000,增大该值可以提高内存利用率,但要避免OOM问题 |
| spark.sql.files.maxPartitionBytes | 134217728 (128 MB) | The maximum number of bytes to pack into a single partition when reading files. This configuration is effective only when using file-based sources such as Parquet, JSON and ORC. |
| spark.sql.files.openCostInBytes | 4194304 (4 MB) | The estimated cost to open a file, measured by the number of bytes could be scanned in the same time. This is used when putting multiple files into a partition. It is better to over-estimated, then the partitions with small files will be faster than partitions with bigger files (which is scheduled first). This configuration is effective only when using file-based sources such as Parquet, JSON and ORC. |
| spark.sql.files.minPartitionNum | Default Parallelism | The suggested (not guaranteed) minimum number of split file partitions. If not set, the default value is spark.default.parallelism. This configuration is effective only when using file-based sources such as Parquet, JSON and ORC. |
| spark.sql.broadcastTimeout | 300 | Timeout in seconds for the broadcast wait time in broadcast joins |
| spark.sql.autoBroadcastJoinThreshold | 10485760 (10 MB) | Configures the maximum size in bytes for a table that will be broadcast to all worker nodes when performing a join. By setting this value to -1 broadcasting can be disabled. Note that currently statistics are only supported for Hive Metastore tables where the command ANALYZE TABLE |
| spark.sql.shuffle.partitions | 200 | Configures the number of partitions to use when shuffling data for joins or aggregations |
| spark.sql.sources.parallelPartitionDiscovery.threshold | 32 | Configures the threshold to enable parallel listing for job input paths. If the number of input paths is larger than this threshold, Spark will list the files by using Spark distributed job. Otherwise, it will fallback to sequential listing. This configuration is only effective when using file-based data sources such as Parquet, ORC and JSON. |
| spark.sql.sources.parallelPartitionDiscovery.parallelism | 10000 | Configures the maximum listing parallelism for job input paths. In case the number of input paths is larger than this value, it will be throttled down to use this value. Same as above, this configuration is only effective when using file-based data sources such as Parquet, ORC and JSON. |
| spark.sql.adaptive.coalescePartitions.enabled | true | When true and spark.sql.adaptive.enabled is true, Spark will coalesce contiguous shuffle partitions according to the target size (specified by spark.sql.adaptive.advisoryPartitionSizeInBytes), to avoid too many small tasks |
| spark.sql.adaptive.coalescePartitions.minPartitionNum | Default Parallelism | The minimum number of shuffle partitions after coalescing. If not set, the default value is the default parallelism of the Spark cluster. This configuration only has an effect when spark.sql.adaptive.enabled and spark.sql.adaptive.coalescePartitions.enabled are both enabled. |
| spark.sql.adaptive.coalescePartitions.initialPartitionNum | (none) | The initial number of shuffle partitions before coalescing. If not set, it equals to spark.sql.shuffle.partitions . This configuration only has an effect when spark.sql.adaptive.enabled and spark.sql.adaptive.coalescePartitions.enabled are both enabled. |
| spark.sql.adaptive.advisoryPartitionSizeInBytes | 64 MB | The advisory size in bytes of the shuffle partition during adaptive optimization (when spark.sql.adaptive.enabled is true). It takes effect when Spark coalesces small shuffle partitions or splits skewed shuffle partition. |
| spark.sql.adaptive.localShuffleReader.enabled | true | 开启自适应执行后,spark会使用本地的shuffle reader读取shuffle数据。这种情况只会发生在没有shuffle重分区的情况 |
| spark.sql.adaptive.skewJoin.enabled | true | When true and spark.sql.adaptive.enabled is true, Spark dynamically handles skew in sort-merge join by splitting (and replicating if needed) skewed partitions. |
| spark.sql.adaptive.skewJoin.skewedPartitionFactor | 5 | A partition is considered as skewed if its size is larger than this factor multiplying the median partition size and also larger than spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes . |
| spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes | 256MB | A partition is considered as skewed if its size in bytes is larger than this threshold and also larger than spark.sql.adaptive.skewJoin.skewedPartitionFactor multiplying the median partition size. Ideally this config should be set larger than spark.sql.adaptive.advisoryPartitionSizeInBytes . |
| spark.sql.optimizer.maxIterations | 100 | The max number of iterations the optimizer and analyzer runs |
| spark.sql.optimizer.inSetConversionThreshold | 10 | The threshold of set size for InSet conversion |
| spark.sql.inMemoryColumnarStorage.partitionPruning | true | When true,enable partition pruning for in-memory columnar tables |
| spark.sql.inMemoryColumnarStorage.enableVectorizedReader | true | Enables vectorized reader for columnar caching |
| spark.sql.columnVector.offheap.enabled | true | When true, use OffHeapColumnVector in ColumnarBatch. |
| spark.sql.join.preferSortMergeJoin | true | When true, prefer sort merge join over shuffle hash join |
| spark.sql.sort.enableRadixSort | true | When true, enable use of radix sort when possible. Radix sort is much faster but requires additional memory to be reserved up-front. The memory overhead may be significant when sorting very small rows (up to 50% more in this case) |
| spark.sql.limit.scaleUpFactor | 4 | Minimal increase rate in number of partitions between attempts when executing a take on a query. Higher values lead to more partitions read. Lower values might lead to longer execution times as more jobs will be run |
| spark.sql.hive.advancedPartitionPredicatePushdown.enabled | true | When true, advanced partition predicate pushdown into Hive metastore is enabled |
| spark.sql.subexpressionElimination.enabled | true | When true, common subexpressions will be eliminated |
| spark.sql.caseSensitive | false | Whether the query analyzer should be case sensitive or not. Default to case insensitive. It is highly discouraged to turn on case sensitive mode |
| spark.sql.crossJoin.enabled | false | When false, we will throw an error if a query contains a cartesian product without explicit CROSS JOIN syntax. |
| spark.sql.files.ignoreCorruptFiles | false | Whether to ignore corrupt files. If true, the Spark jobs will continue to run when encountering corrupted files and the contents that have been read will still be returned. |
| spark.sql.files.ignoreMissingFiles | false | Whether to ignore missing files. If true, the Spark jobs will continue to run when encountering missing files and the contents that have been read will still be returned. |
| spark.sql.files.maxRecordsPerFile | 0 | Maximum number of records to write out to a single file.If this value is zero or negative, there is no limit. |
| spark.sql.cbo.enabled | false | Enables CBO for estimation of plan statistics when set true. |
| spark.sql.cbo.joinReorder.enabled | false | Enables join reorder in CBO |
| spark.sql.cbo.joinReorder.dp.threshold | 12 | The maximum number of joined nodes allowed in the dynamic programming algorithm |
| spark.sql.cbo.joinReorder.card.weight | 0.7 | The weight of cardinality (number of rows) for plan cost comparison in join reorder: rows weight + size (1 - weight). |
| spark.sql.cbo.joinReorder.dp.star.filter | false | Applies star-join filter heuristics to cost based join enumeration |
| spark.sql.cbo.starSchemaDetection | false | When true, it enables join reordering based on star schema detection |
| spark.sql.cbo.starJoinFTRatio | 0.9 | Specifies the upper limit of the ratio between the largest fact tables for a star join to be considered |
| spark.sql.windowExec.buffer.in.memory.threshold | 4096 | Threshold for number of rows guaranteed to be held in memory by the window operator |
2.2.3.3、Storage
2.2.3.3.1、Small File
小文件的危害就不再叙述了,这个时候就要思考什么时候会产生小文件。其产生的地方有:
1、源头:如果原始文件就存在小文件,那么就需要先进行合并,然后再计算,避免产生大量的task造成资源浪费
2、计算过程中:这个时候就要结合实际的数据量大小和分布,以及分区数进行调整。
3、写入:写入文件的数量跟reduce/分区的个数有关系,可以根据实际的数据量进行调整并行度或者配置自动合并
2.2.3.3.2、Cold And Hot Data
2.2.3.3.3、Compress And Serializable
1、文件采用合适的存储类型以及压缩格式
2、使用合适高效的序列化器,如kryo
| Property Name | Default | Meaning |
|---|---|---|
| spark.sql.parquet.compression.codec | snappy | parquet存储类型文件的压缩格式,默认为snappy |
| spark.sql.sources.fileCompressionFactor | 1.0 | When estimating the output data size of a table scan, multiply the file size with this factor as the estimated data size, in case the data is compressed in the file and lead to a heavily underestimated result |
| spark.sql.parquet.mergeSchema | false | When true, the Parquet data source merges schemas collected from all data files, otherwise the schema is picked from the summary file or a random data file if no summary file is available |
| spark.sql.parquet.respectSummaryFiles | false | When true, we make assumption that all part-files of Parquet are consistent with summary files and we will ignore them when merging schema. Otherwise, if this is false, which is the default, we will merge all part-files. This should be considered as expert-only option, and shouldn’t be enabled before knowing what it means exactly |
| spark.sql.parquet.binaryAsString | false | Some other Parquet-producing systems, in particular Impala and older versions of Spark SQL, do not differentiate between binary data and strings when writing out the Parquet schema. This flag tells Spark SQL to interpret binary data as a string to provide compatibility with these systems |
| spark.sql.parquet.filterPushdown | true | Enables Parquet filter push-down optimization when set to true |
| spark.sql.parquet.columnarReaderBatchSize | 4096 | The number of rows to include in a parquet vectorized reader batch. The number should be carefully chosen to minimize overhead and avoid OOMs in reading data. |
2.2.3.4、Other
2.2.3.4.1、Closed Loop FeedBack
2.2.3.4.1.1、实时运行信息分析
2.2.3.4.1.2、运行信息离线统计分析
高频表、列统计,错误信息汇总,策略生效情况记录等。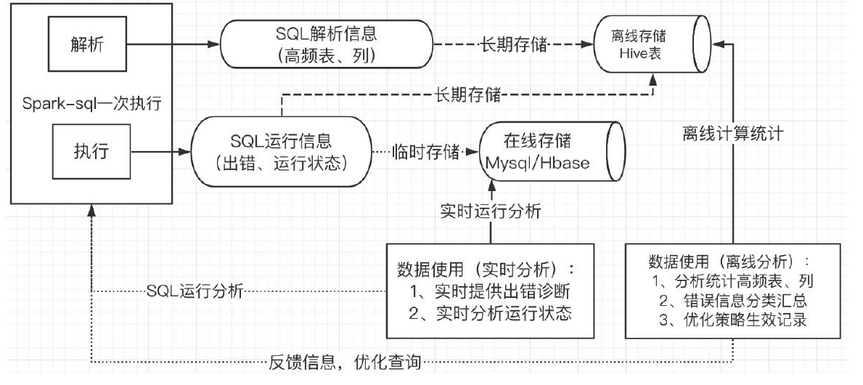
2.3、Spark Streaming
2.3.0、Overview
Spark Streaming 是核心 Spark API 的扩展,它支持实时数据流的可扩展、高吞吐量、容错流处理。数据可以从许多来源(如 Kafka、Kinesis 或 TCP 套接字)获取,并且可以使用复杂的算法进行处理,这些算法由 map、reduce、join 和 window 等高级函数表示。最后,可以将处理后的数据推送到文件系统、数据库和实时仪表板。当然也可以在数据流上应用机器学习和图处理。
工作原理如下:Spark Streaming 接收实时输入的数据流,并将数据分成批处理,然后由 Spark 引擎处理以批处理生成最终的结果流。其中SparkStreaming提供了一种离散流或DStream的高级抽象来代表一个连续的数据流,底层就是由一系列RDD来表示。
DStream 中的每个 RDD 都包含来自某个区间的数据,如下图: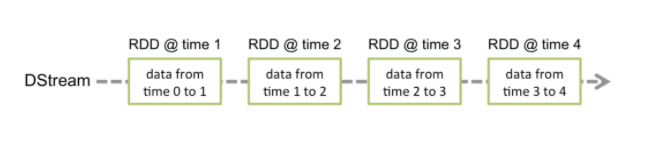
2.3.0.1、Example
import org.apache.spark._import org.apache.spark.streaming._import org.apache.spark.streaming.StreamingContext._ // not necessary since Spark 1.3// Create a local StreamingContext with two working thread and batch interval of 1 second.// The master requires 2 cores to prevent a starvation scenario.val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")val ssc = new StreamingContext(conf, Seconds(1))// Create a DStream that will connect to hostname:port, like localhost:9999val lines = ssc.socketTextStream("localhost", 9999)// Split each line into wordsval words = lines.flatMap(_.split(" "))// Count each word in each batchval pairs = words.map(word => (word, 1))val wordCounts = pairs.reduceByKey(_ + _)// Print the first ten elements of each RDD generated in this DStream to the consolewordCounts.print()ssc.start() // Start the computationssc.awaitTermination() // Wait for the computation to terminate
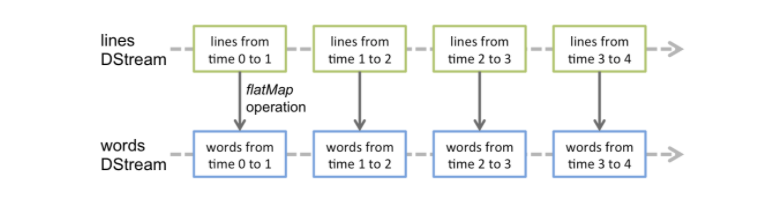
如上面的demo所示,每个输入流都会和一个Receiver对象相关联,该对象用来接收数据并将其存储在Spark内存中进行下一步的处理。因此如果你想要在流应用程序中并行接收多个数据流的话,那么就得需要创建多个Receiver对象用来接收数据。同时也需要记住的是SparkStreaming应用程序是属于常驻的,而且也是Spark程序,那么Worker/Executor也会占用一部分资源,所以为了能够保障运行Receiver以及正常处理数据,那么就需要申请到足够的资源,所以其分配的核数一定要大于receivers的个数。
2.3.0.2、Points To Remember
1、一旦Context启动之后,就不能增加或者设置新的流计算
2、一旦Context停止后,就无法重新启动。这里说的是容错方面。
3、同一时间一个JVM内只能有一个StreamingContext。
4、在StreamingContext上调用stop()方法,同时也会把SparkContext给停止;如果只是想停止StreamingContext,那么可以在调用stop()方法的时候指定stopSparkContext=false。
5、一个SparkContext可以被复用创建多个StreamingContext(即在下一个StreamingContext被创建之前停止上一个StreamingContext,且不停止SparkContext)
2.3.1、Receiver
SparkStreaming可以从任意的数据源来接收数据并处理,目前内置的数据源包括Kafka、File、Socket等等。当然目前Spark内置支持的数据源可以满足日常大部分的场景,但有些时候仍然需要自定义Receiver来定制接收数据源。这小节将来讲述如何实现一个自定义的Receiver。首先要继承Receiver,然后重写onStart和onStop方法。onStart()方法会在启动的时候负责接收数据;onStop()方法将停止这些接收数据的线程,当然还可以使用isStopped()方法来检查它们是否停止接收数据。
在 Spark Streaming 中,当一个 Receiver 启动时,每隔 spark.streaming.blockInterval 毫秒就会产生一个新的块,每个块都会变成 RDD 的一个分区,最终由 DStream 创建。例如,由 KafkaInputDStream 创建的 RDD 中的分区数由 batchInterval / spark.streaming.blockInterval 确定,其中 batchInterval 是将流数据分成批次的时间间隔(通过 StreamingContext 的构造函数参数设置)。例如,如果批处理间隔为 2 秒(默认),块间隔为 200 毫秒(默认),则RDD 将包含 10 个分区,还有一个流程路径涉及从迭代器接收数据,由 ReceivedBlockHandler 表示。创建 RDD 后,驱动程序的 JobScheduler 可以将其处理安排为作业。在 Spark Streaming 的当前实现和默认配置下,任何时间点只有一个作业处于活动状态(即正在执行)。因此,如果一个批次的处理时间比批次间隔长,那么下一个批次的作业将保持排队,将其设置为 1 的原因是并发作业可能会导致奇怪的资源共享,并且可能难以调试系统中是否有足够的资源来足够快地处理摄取的数据,当然可以通过实验性 Spark 属性 spark.streaming.concurrentJobs 进行更改,默认情况下设置为 1。一次只运行一个作业,不难看出,如果批处理时间小于批处理间隔,那么系统将是稳定的。
Receiver一旦接收到数据后,那么就会调用store(data)方法进行存储,这里有两种处理方式来保障Receiver是否可靠:
1、来一条存储一条,这种可靠性较差
2、存储整个对象/序列化集合。(阻塞的方式存储)
其自定义实现store()方法会影响到整体的容错和可靠。当应用程序发生了异常时应该要有捕获机制,并要有重试机制。
如果应用程序发生重启的时候,那么会调用Receiver类中的restart()方法,其内部会异步调用onStop方法并隔一定延迟后调用onStart()方法完成重启动作。
public class JavaCustomReceiver extends Receiver<String> {String host = null;int port = -1;public JavaCustomReceiver(String host_ , int port_) {super(StorageLevel.MEMORY_AND_DISK_2());host = host_;port = port_;}@Overridepublic void onStart() {// Start the thread that receives data over a connectionnew Thread(this::receive).start();}@Overridepublic void onStop() {// There is nothing much to do as the thread calling receive()// is designed to stop by itself if isStopped() returns false}/** Create a socket connection and receive data until receiver is stopped */private void receive() {Socket socket = null;String userInput = null;try {// connect to the serversocket = new Socket(host, port);BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream(), StandardCharsets.UTF_8));// Until stopped or connection broken continue readingwhile (!isStopped() && (userInput = reader.readLine()) != null) {System.out.println("Received data '" + userInput + "'");store(userInput);}reader.close();socket.close();// Restart in an attempt to connect again when server is active againrestart("Trying to connect again");} catch(ConnectException ce) {// restart if could not connect to serverrestart("Could not connect", ce);} catch(Throwable t) {// restart if there is any other errorrestart("Error receiving data", t);}}}调用自定义Receiver:// Assuming ssc is the JavaStreamingContextJavaDStream<String> customReceiverStream = ssc.receiverStream(new JavaCustomReceiver(host, port));JavaDStream<String> words = customReceiverStream.flatMap(s -> ...);...
2.3.2、Window Operations
SparkStreaming提供了窗口计算功能,允许我们可以对数据的滑动窗口应用转换。基于窗口的操作会在一个比StreamingContext的批次间隔更长的时间范围内,通过整合多个批次的结果,计算出整个窗口的结果。如下图案例琐事,窗口时长为3个时间单位,步长为2个时间单位。这说明任何窗口操作都需要指定两个参数:
1、窗口长度:窗口的持续时间
2、滑动间隔:执行基于窗口操作计算的时间间隔,默认值和批处理间隔时间相等。
以上两个参数值必须是源DStream的batch间隔的倍数。
示例:
// Reduce last 30 seconds of data, every 10 seconds;每10s处理近30s的数据JavaPairDStream<String, Integer> windowedWordCounts = pairs.reduceByKeyAndWindow((i1, i2) -> i1 + i2, Durations.seconds(30), Durations.seconds(10));
2.3.2.1、Window Transformation
| Transformation | Meaning |
|---|---|
| window(windowLength, slideInterval) | Return a new DStream which is computed based on windowed batches of the source DStream. |
| countByWindow(windowLength, slideInterval) | Return a sliding window count of elements in the stream. |
| reduceByWindow(func, windowLength, slideInterval) | Return a new single-element stream, created by aggregating elements in the stream over a sliding interval using func. The function should be associative and commutative so that it can be computed correctly in parallel. |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function func over batches in a sliding window. Note: By default, this uses Spark’s default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism ) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | A more efficient version of the above reduceByKeyAndWindow() where the reduce value of each window is calculated incrementally using the reduce values of the previous window. This is done by reducing the new data that enters the sliding window, and “inverse reducing” the old data that leaves the window. An example would be that of “adding” and “subtracting” counts of keys as the window slides. However, it is applicable only to “invertible reduce functions”, that is, those reduce functions which have a corresponding “inverse reduce” function (taken as parameter invFunc). Like in reduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. Note that checkpointing must be enabled for using this operation. |
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, Long) pairs where the value of each key is its frequency within a sliding window. Like in reduceByKeyAndWindow , the number of reduce tasks is configurable through an optional argument. |
2.3.3、Stream Join
JavaPairDStream<String, String> stream1 = ...JavaPairDStream<String, String> stream2 = ...JavaPairDStream<String, Tuple2<String, String>> joinedStream = stream1.join(stream2);//基于window的joinJavaPairDStream<String, String> windowedStream1 = stream1.window(Durations.seconds(20));JavaPairDStream<String, String> windowedStream2 = stream2.window(Durations.minutes(1));JavaPairDStream<String, Tuple2<String, String>> joinedStream = windowedStream1.join(windowedStream2);//Stream-DataSet joinJavaPairRDD<String, String> dataset = ...JavaPairDStream<String, String> windowedStream = stream.window(Durations.seconds(20));JavaPairDStream<String, String> joinedStream = windowedStream.transform(rdd -> rdd.join(dataset));
2.3.4、Output Operations On DStreams
| Output Operation | Meaning |
|---|---|
| print() | Prints the first ten elements of every batch of data in a DStream on the driver node running the streaming application. This is useful for development and debugging. Python API This is called pprint() in the Python API. |
| saveAsTextFiles(prefix, [suffix]) | Save this DStream’s contents as text files. The file name at each batch interval is generated based on prefix and suffix: “prefix-TIME_IN_MS[.suffix]”. |
| saveAsObjectFiles(prefix, [suffix]) | Save this DStream’s contents as SequenceFiles of serialized Java objects. The file name at each batch interval is generated based on prefix and suffix: “prefix-TIME_IN_MS[.suffix]”. Python API This is not available in the Python API. |
| saveAsHadoopFiles(prefix, [suffix]) | Save this DStream’s contents as Hadoop files. The file name at each batch interval is generated based on prefix and suffix: “prefix-TIME_IN_MS[.suffix]”. Python API This is not available in the Python API. |
| foreachRDD(func) | The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to files, or writing it over the network to a database. Note that the function func is executed in the driver process running the streaming application, and will usually have RDD actions in it that will force the computation of the streaming RDDs. |
对于foreachRDD的用法需要说明一点:通常我们使用该算子将数据写入外部系统,如数据库,那么在使用该算子的时候需要注意连接的创建问题。例如:
dstream.foreachRDD(rdd -> {Connection connection = createNewConnection(); // executed at the driverrdd.foreach(record -> {connection.send(record); // executed at the worker});});
上面代码的写法其实是有问题的,连接在Driver端创建,然后再进行序列化发送到executor,通常情况下会有connection object not serializable错误;因此正确写法应该是在executor端,每个分区下创建一个连接,这样可以分摊批次记录的连接创建开销。
dstream.foreachRDD(rdd -> {rdd.foreachPartition(partitionOfRecords -> {Connection connection = createNewConnection();while (partitionOfRecords.hasNext()) {connection.send(partitionOfRecords.next());}connection.close();});});
当然还可以有另外一种做法就是可以维护一个静态的连接对象池,当多个批次的 RDD 被推送到外部系统时可以重用,从而进一步减少开销。
dstream.foreachRDD(rdd -> {rdd.foreachPartition(partitionOfRecords -> {// ConnectionPool is a static, lazily initialized pool of connectionsConnection connection = ConnectionPool.getConnection();while (partitionOfRecords.hasNext()) {connection.send(partitionOfRecords.next());}ConnectionPool.returnConnection(connection); // return to the pool for future reuse});});
2.3.5、DataFrame And Sql Operations
public final class JavaSqlNetworkWordCount {private static final Pattern SPACE = Pattern.compile(" ");public static void main(String[] args) throws Exception {if (args.length < 2) {System.err.println("Usage: JavaNetworkWordCount <hostname> <port>");System.exit(1);}StreamingExamples.setStreamingLogLevels();// Create the context with a 1 second batch sizeSparkConf sparkConf = new SparkConf().setAppName("JavaSqlNetworkWordCount");JavaStreamingContext ssc = new JavaStreamingContext(sparkConf, Durations.seconds(1));// Create a JavaReceiverInputDStream on target ip:port and count the// words in input stream of \n delimited text (e.g. generated by 'nc')// Note that no duplication in storage level only for running locally.// Replication necessary in distributed scenario for fault tolerance.JavaReceiverInputDStream<String> lines = ssc.socketTextStream(args[0], Integer.parseInt(args[1]), StorageLevels.MEMORY_AND_DISK_SER);JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(SPACE.split(x)).iterator());// Convert RDDs of the words DStream to DataFrame and run SQL querywords.foreachRDD((rdd, time) -> {SparkSession spark = JavaSparkSessionSingleton.getInstance(rdd.context().getConf());// Convert JavaRDD[String] to JavaRDD[bean class] to DataFrameJavaRDD<JavaRecord> rowRDD = rdd.map(word -> {JavaRecord record = new JavaRecord();record.setWord(word);return record;});Dataset<Row> wordsDataFrame = spark.createDataFrame(rowRDD, JavaRecord.class);// Creates a temporary view using the DataFramewordsDataFrame.createOrReplaceTempView("words");// Do word count on table using SQL and print itDataset<Row> wordCountsDataFrame =spark.sql("select word, count(*) as total from words group by word");System.out.println("========= " + time + "=========");wordCountsDataFrame.show();});ssc.start();ssc.awaitTermination();}}/** Lazily instantiated singleton instance of SparkSession */class JavaSparkSessionSingleton {private static transient SparkSession instance = null;public static SparkSession getInstance(SparkConf sparkConf) {if (instance == null) {instance = SparkSession.builder().config(sparkConf).getOrCreate();}return instance;}}
2.3.6、BackPressure
2.3.6.1、Problem
早期SparkStreaming以生产者的速率(或者用户配置的速率限制)通过receivers接收数据,但当一个批次的处理时间超过批次间隔时,整个流应用程序就会变得不稳定,会导致数据阻塞排队,资源被耗尽最终失败(比如OOM)。即使用户配置了速率限制,但也会因为各种各样的问题不能完美的解决处理赶不上生产的问题,因此需要sparkstreaming内部自身能够实现感知动态调整速率才是王道(通过JobScheduler来反馈)。
2.3.6.2、Architecture
Back-pressure的灵感来自于Reactive Streams(采用生产-消费者+迭代器),旨在为具有非阻塞背压的异步流处理提供标准。它由旨在实现高吞吐量和弹性的规范(由四个类和大约 30 多条规则组成)组成。大致有以下几个原则:
1、Subscriber端使用有限大小的缓冲区,在该规范中,Subscriber会发送一个背压信号来量化它目前所面临的阻塞。
2、尽管受到Subscriber侧的限制,在这个范围内,Publisher应该会尽可能快的发送数据。因此Reactive Stream是一种当Subscriber端消费快时,采用push模式,当publisher快些的时候,则采用pull模式。
3、对于Subscriber发出的信号规则是一种异步方式,所以在Reactive Streams API中规定了所有背压信号的处理都不能阻塞publisher,但是publisher可以采用同步/异步方式传输数据。
2.3.6.2.1、Old Architecture(spark1.5)
基于刚才提到的数据阻塞的情况,在spark1.5之前,为了解决这个问题,对于基于Receiver-Based模式的数据接收,通过配置spark.streaming.receiver.maxRate参数来限制每个receiver每秒最大可以接收的记录数据;对于Direct Approach模式下,通过配置spark.streaming.kafka.maxRatePerPartition参数来限制每次作业中每个分区最多能读取的记录数。虽然这些手段可以限制接收速率来适配当前的处理能力,但也存在一些问题:
1、需要将参数糅合到代码中,且需要重启sparkstreaming应用程序。
2、需要人为结合当前的阻塞情况调整对应的速率限制,如果当前处理能力大于我们设置的maxRate,那么就会造成资源浪费。
先来看下1.5之前的流程: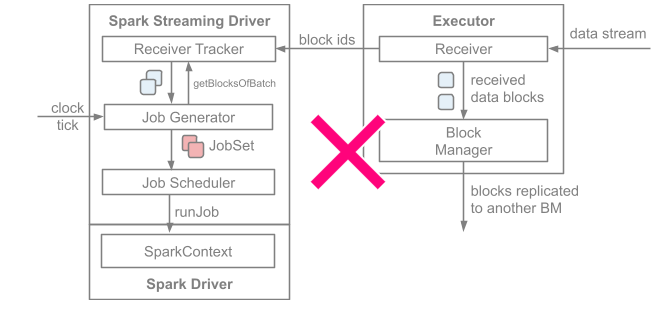
1、数据到达receiver(在executor上运行)。随着数据流入,它被保存到BlockManager中并复制到另一个 BM以此来防止数据丢失
2、当Receiver Tracker接收收到 被存储的block IDs 的通知后,内部维护一个批处理时间到这些 ID 的映射关系。
3、Job Generator会每隔 batchInterval 毫秒获取一个事件。在此事件中,Job Generator将所有未分配的块 ID 分配给新的批处理时间并创建一个JobSet。
4、Job Scheduler开始调度执行JobSet。
2.3.6.2.2、New architecture(Spark1.5+)
为了实现自动调节数据的传输速率,1.5版本之后采用了以下的架构流程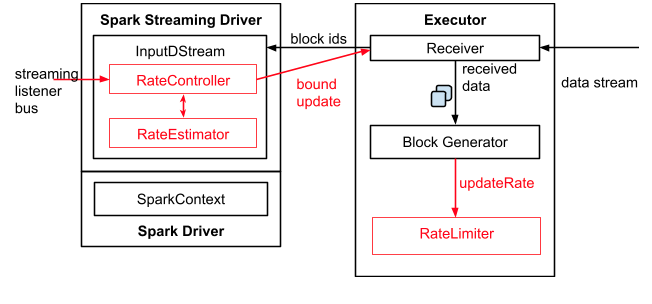
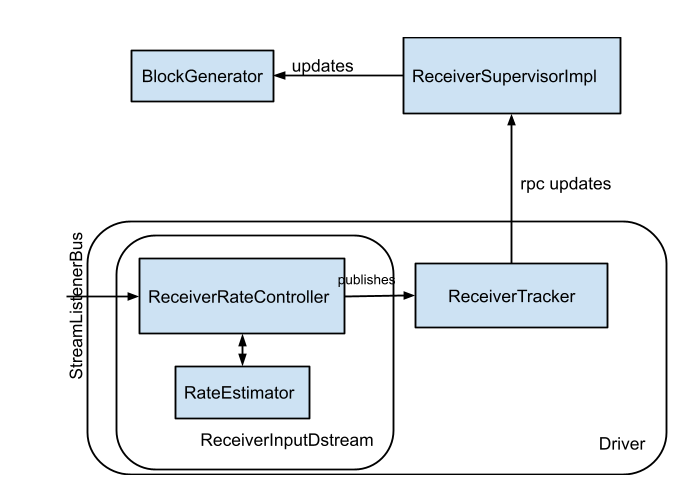
第一个相关的Issus(SPARK-7398)关于背压大致的思路是在Driver端进行速率估算,然后把速率更新到Executor端的各个Receiver,从而实现背压。其特性主要有三大模块实现:
1、速率控制
2、速率估算
3、速率更新
基于三大模块,1.5版本之后的核心流程如下:
1、在InputDStreams内部增加了RateController 组件,继承自StreamingListener,该组件通过 onBatchCompleted方法 根据 processingDelay 和 scheduleDelay 和当前数据量得出估计的处理速度,然后更新每个流的估计最大处理速率(元素/秒);该功能委托给RateEstimator的compute方法来计算具体的速率。
RateController有不同的实现的地方:一个是基于receiver的ReceiverInputDStream(主要控制块生成个数);另外一个是DirectKafkaInputDStream(控制每个分区消费记录数)。
RateController通过receiver tracker异步发送新的速率给receiver,Kafka使用它来计算下一个分区的大小。其原理为:RateController从streaming listener bus接收批量完成更新,如果这些更新之一对应于其流,那么就会调用它的RateEstimator上的compute()方法来更新接收速率。其是通过ssc.scheduler.receiverTracker.sendRateUpdate(id,newRate)来调用更新的。
RateEstimator的实现PIDRateEstimator,其实现了一个PID(比例积分微分控制算法,本质上是一种反馈回路),误差是读取速率和处理速率之间的速度差(都是以每秒消息数为单位)。
可以通过spark.streaming.rateEstimator参数配置来选择RateEstimator的速率估算实现,可选值为noop或者pid,也就是说目前spark只支持pid。
2、InputDStreams会保留实现者可以使用的最大期望速率并收到其更改的通知:其实现类ReceiverInputDStream通过ReceiverSupervisor将此速率传递给BlockGenerator。然后BlockGenerator根据这个新速率来调整;比如如果设置spark.streaming.kafka.maxRatePerPartition,那么每个分区所取数据最大量为计算出的结果以及设置参数的最小值,否则就直接用计算出的值
3、默认情况下,基于receiver的输入流通过ReceiverTracker和 ReceiverSupervisor 将此速率转发到 BlockGenerator(已经有一个 RateLimiter)
4、其他 DStream 实现应该使用这个新的速率限制。
5、对于预先存在的速率限制,例如 spark.streaming.receiver.maxRate、spark.streaming.kafka.maxRatePerPartition 始终作为上限(考虑到如果遇到故障恢复的时候可能会有很大的生产速率,所以需要保持这个上限有助于避免在第一个批次间隔内就让系统崩溃)。
Spark Streaming 内部详细流程如图所示:
RDD 创建之前的数据流以粗体箭头表示,元数据流以正常宽度箭头表示。私有结构在虚线块中,公共结构使用连续线。队列以红色表示。这些只是显式队列:例如JobScheduler 中的 jobSets 是一个以毫秒为单位的时间索引的数组,并以相同的方式访问。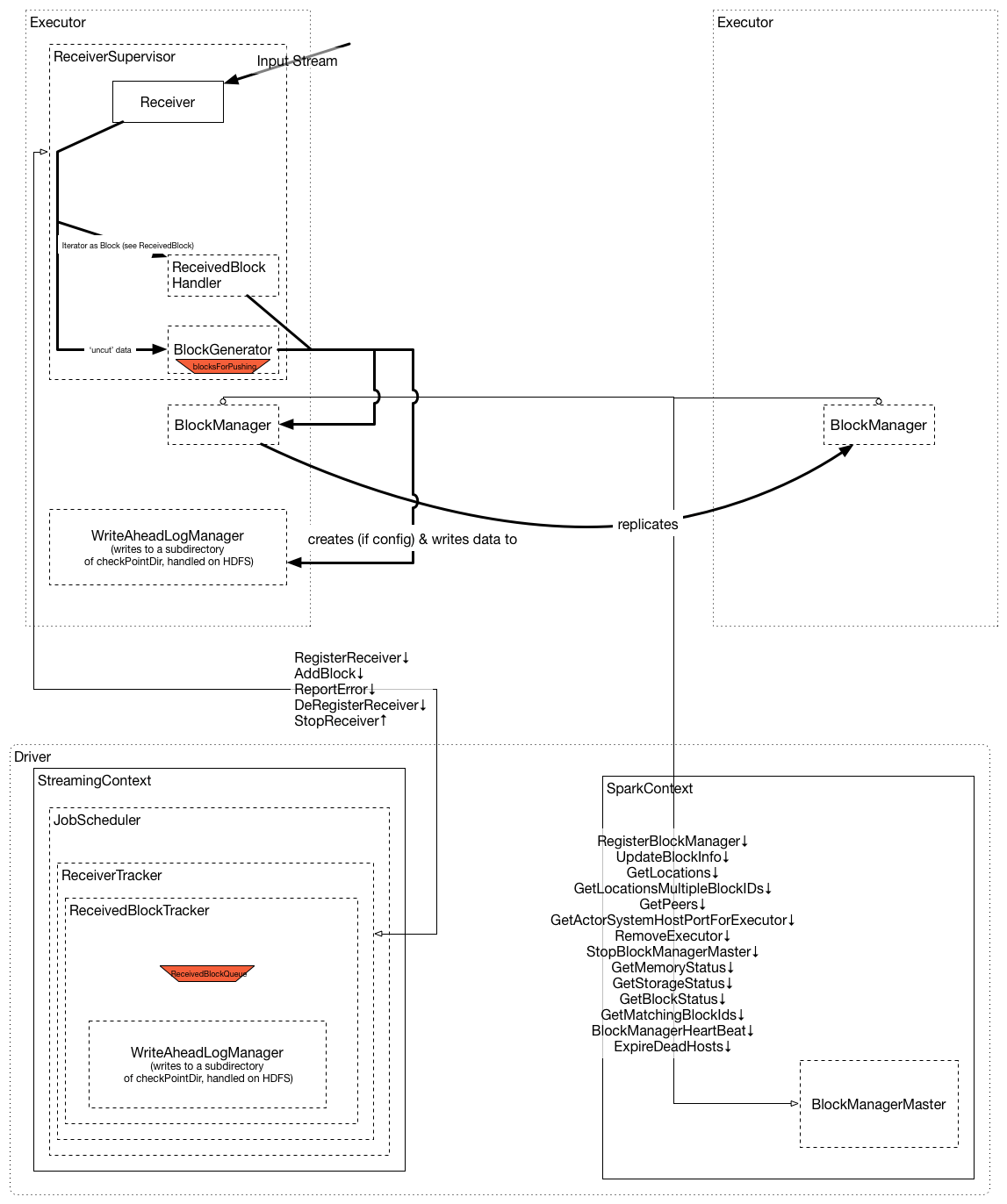
需要注意的是:
1、ReceiverSupervisor 每个 Dstream 只处理一个 Receiver。
2、注意 WriteAheadLogManager 访问相同的结构,在 ReceivedBlockHandler 中和作为块生成的一部分。
3、如图所示,BlockManager 和 ReceiverTracker 都使用 actor 来传达控制和元数据。
4、另一个需要注意的点是现有流的数量是固定的:接收器仅在处于 streamingContext.start() 时启动。因此,只有在所有输入 DStream 都已创建之后才必须启动上下文,并且一旦上下文启动,就不能创建新的输入 Dstream
5、最后,SPARK-1341 的限制仅适用于 Spark 自己将数据切片成块的情况。如果块作为迭代器交付,则不可能进行节流
DirectKafkaInput背压大致流程如图所示:
反压主要分为三个流程:
1、启动服务时注册rateCotroller
2、监听到批次结束事件后采样计算新的消费速率
3、提交job时利用消费速率计算每个分区消费的数据条数
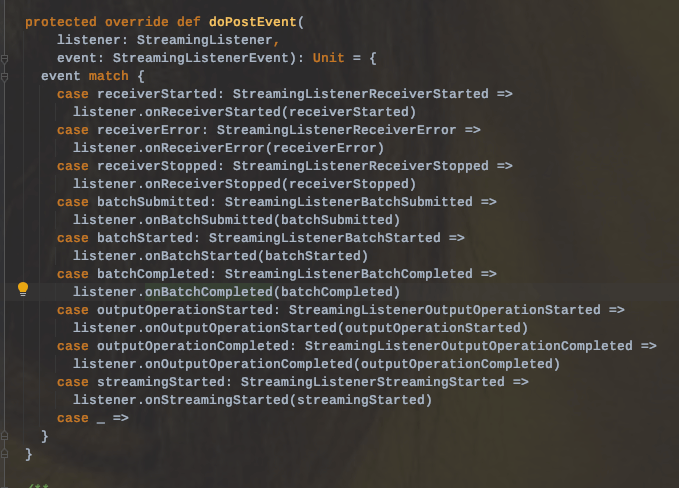
2.3.6.2.3、How To Limit Rate?
在4.6.2.2小节介绍了SparkStreaming关于RateController的两种实现机制流程,那么虽然在sparkstreaming内部做到了速率控制,但具体是怎么生效的呢?
其实内部是通过Guava的令牌桶限流算法来实现。首先当Receiver收到一条数据后,那么会放入到缓存中,然后再取出来封装成一个个block。那么令牌桶就是作用于数据放入缓存的步骤中,如果桶内没有令牌,那么数据就不会被放入到缓存中,从而限制了数据块的生成。具体算法细节可以参考令牌桶。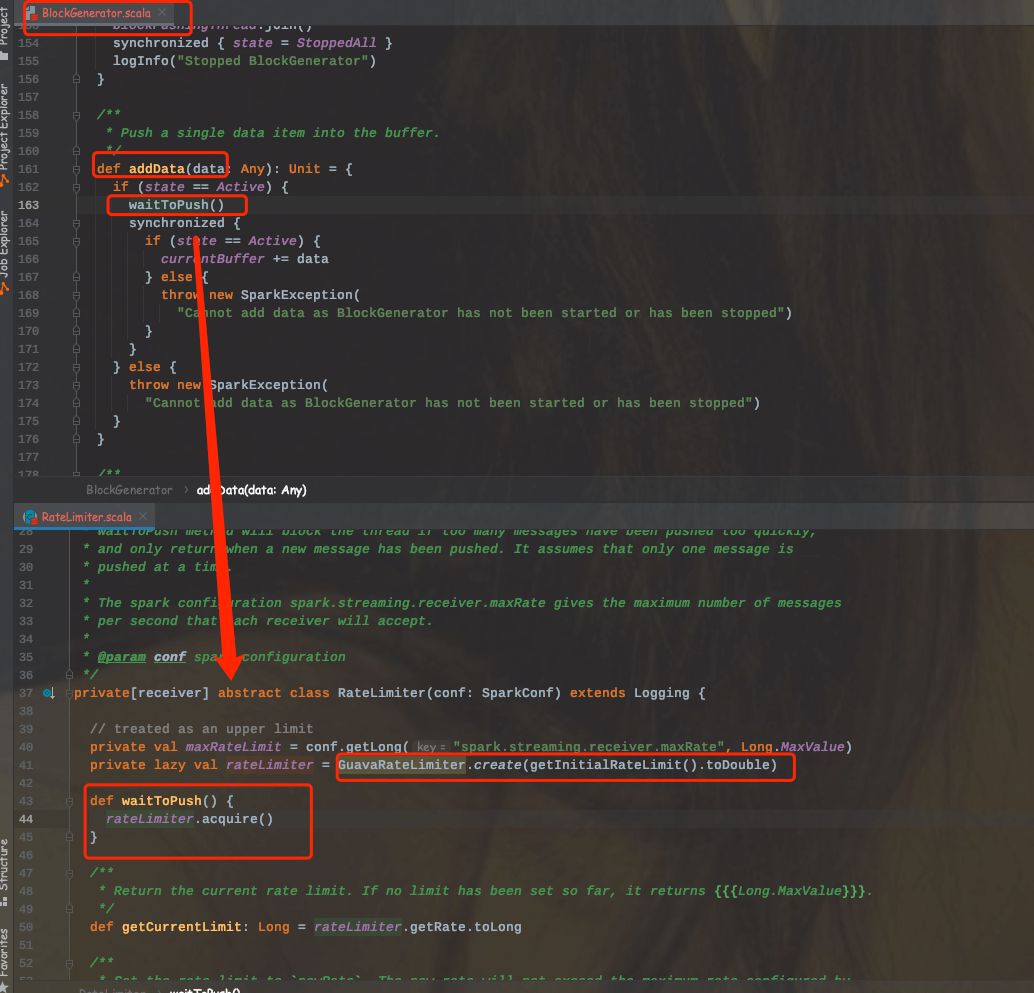
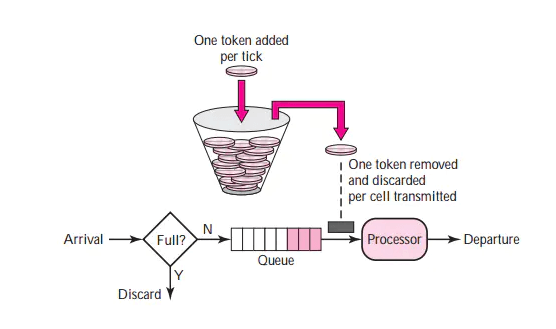
2.3.6.3、Configure
| Property | Default | Meaning |
|---|---|---|
| spark.streaming.backpressue.enabled | false | 默认关闭反压 |
| spark.streaming.kafka.maxRatePerPartition | 每个partition每秒最多消费条数 | |
| spark.streaming.backpressure.pid.proportional | 1 | 用于响应错误的权重(最后批次和当前批次之间的更改) |
| spark.streaming.backpressure.pid.integral | 0.2 | 错误积累的响应权限,具有抑制作用 |
| spark.streaming.backpressure.pid.derived | 0 | 对错误趋势的响应权重,可能会引起batch size的波动,可以帮助快速增加/减少容量 |
| spark.streaming.backpressure.pid.minRate | 100 | 可以估算的最低费率 |
| spark.streaming.blockInterval | 200ms | 生成块的间隔 |
| spark.streaming.blockQueueSize | 10 | 存储块队列长度 |
| spark.streaming.receiver.maxRate | Long.MaxValue | 每个receiver能够接收的最大速率 |
| spark.streaming.backpressure.initialRate | 和spark.streaming.receiver.maxRate一样 | 背压初始速率 |
2.3.7、Fault Tolerance
2.3.7.0、Background
Spark 对 HDFS 或 S3 等容错文件系统中的数据进行操作。因此,从容错数据生成的所有 RDD 也是容错的,但是,Spark Streaming 并非如此,因为大多数情况下数据是通过网络接收的(使用 fileStream 时除外)。因此为了所有生成RDD实现相同的容错特性,接收到的数据会在多个executor之间进行复制(默认复制因子是2),这也导致当系统发生故障时需要恢复两种数据:
1、已经接收且复制的数据:此类数据在单个worker节点上发生故障时仍然存在,这是因为它的副本存在其他节点上。
2、已接收但未复制的数据(仍在缓冲区):此类数据还未被复制,因此需要从源头再次重新计算获取。
在Spark框架内,需要考虑两种类型的故障:
1、Worker节点上的失败:如果worker节点发生故障,那么其上的executor中内存存储的数据就会丢失,而如果有receiver工作在故障worker上的话,那么其缓存的数据也会丢失。
2、Driver端的失败:如果运行sparkstreaming程序的driver失败的话,那么对应的SparkContext就是丢失,而且所有的executor和内存中的数据都会丢失。
考虑流系统可能出现的故障,其提供了三种保障机制类型:
1、at-most-once:每条记录最多被处理一次
2、at-least-once:每条记录至少被处理一次,比at-most-once更加健壮,但是会有数据重复的情况。
3、exactly-once:每条记录精准处理一次,这种机制不会出现数据丢失以及数据重复处理的情况。
对于任何流系统来说,都会存在三步:1、接收数据;2、处理数据;3、数据输出;根据上面提供的三种保障机制,如果想要让流应用程序实现端到端精准一致的话,那么这三步都必须要提供精准一次的保证。那么针对这三步分别来讲解如何实现每一步骤的精准一次:
1、接收数据:接收数据需要根据不同的数据源提供的不同的保障机制来讲解。在spark层面提供了WAL机制至少保障不会丢失数据。
2、数据转换/处理:该步可以根据RDD的特性来保障容错且数据一致(这里指的是幂等一致)
3、数据输出:对于数据输出的操作默认是至少一次保障机制,因为这取决于输出操作的类型是否可实现幂等和下游系统是否支持事务;但是我们通常是可以实现事务机制以此来达到精准一次的,但这也要取决于具体的存储介质特性。
例如foreachRDD算子是具有至少一次语义,也就是说当出现故障的时候,数据可能会被写入多次,虽然这对于使用saveAs…Files保存到文件系统是可以接受的(可能会被相同的数据覆盖掉),但是如果要保障精准一次的话,需要额外的方法来实现:
方法1、幂等更新:当尝试多次写入相同的数据时候,最后写入生成的文件的数据都是一样的。
方法2、事务更新:所有更新都是以事务方式进行的,因此更新仅以原子方式进行一次。执行此操作的一种方法如下:
1、使用批处理时间(在 foreachRDD 中可用)和 RDD 的分区索引来创建标识符。此标识符唯一标识流应用程序中的 blob 数据。
2、使用标识符以事务性方式(即,以原子方式)使用此 blob 更新外部系统,也就是说,如果标识符尚未提交,则以原子方式提交分区数据和标识符。否则,如果这已经提交,请跳过更新。
dstream.foreachRDD { (rdd, time) =>rdd.foreachPartition { partitionIterator =>val partitionId = TaskContext.get.partitionId()val uniqueId = generateUniqueId(time.milliseconds, partitionId)// use this uniqueId to transactionally commit the data in partitionIterator}}
| Deployment Scenario | Worker Failure | Driver Failure |
|---|---|---|
| Spark 1.1 or earlier, OR Spark 1.2 or later without write-ahead logs |
Buffered data lost with unreliable receivers Zero data loss with reliable receivers At-least once semantics |
Buffered data lost with unreliable receivers Past data lost with all receivers Undefined semantics |
| Spark 1.2 or later with write-ahead logs | Zero data loss with reliable receivers At-least once semantics |
Zero data loss with reliable receivers and files At-least once semantics |
2.3.7.1、Cache/Persistence
与 RDD 类似,DStreams 也允许开发人员将流的数据保存在内存中。也就是说,在 DStream 上使用 persist() 方法将自动将该 DStream 的每个 RDD 持久化在内存中.如果 DStream 中的数据将被多次计算(例如,对同一数据进行多次操作),这将很有用;
对于像reduceByWindow 和reduceByKeyAndWindow 这样的基于窗口的操作和像updateStateByKey 这样的基于状态的操作,这是隐式的。因此,由基于窗口的操作生成的 DStream 会自动持久保存在内存中,而无需开发人员调用 persist()。
对于通过网络接收数据的输入流(如 Kafka、sockets 等),默认持久化级别设置为将数据复制到两个节点以实现容错。
注意:与 RDD 不同,DStreams 的默认持久化级别将数据序列化在内存中。
2.3.7.2、Checkpointing
流应用程序必须 24/7 全天候运行,因此必须能够应对与应用程序逻辑无关的故障(例如,系统故障、JVM 崩溃等);为了使这成为可能,Spark Streaming 需要将足够的信息检查点到容错存储系统,以便它可以从故障中恢复。检查点有两种类型的数据:
1、元数据检查点
将定义流计算的信息保存到容错存储,如 HDFS;这用于从运行流应用程序驱动程序的节点故障中恢复。其中元数据包括:
1.1、配置信息:用于创建流应用程序的配置。
1.2、DStream操作算子:定义流应用程序的一组 DStream 操作
1.3、未完成的批次:作业已排队但尚未完成的批次。
2、数据检查点
将生成的 RDD 保存到可靠的存储中,这在一些跨多个批次组合数据的有状态转换中是必要的,在这样的转换中,生成的 RDD 依赖于之前批次的 RDD,这导致依赖链的长度随时间不断增加,为了避免恢复时间的这种无限增加(与依赖链成比例),有状态转换的中间 RDD 会定期检查点到可靠存储(例如 HDFS)以切断依赖链。
总而言之,元数据检查点主要用于从驱动程序故障中恢复,而如果使用有状态转换,即使对于基本功能,数据或 RDD 检查点也是必要的。
2.3.7.2.1、Enable Checkpointing
对于以下情况是必须要开启checkpoin的:
1、使用有状态的transformation算子:例如使用updateStateByKey或者reduceByKeyAndWindow,那么是必须要配置checkpoint的
2、需要从故障中恢复的:那么这个时候就需要对元数据进行checkpoint,以此用于恢复进度信息。
2.3.7.2.2、Configure Checkpointing
如果要开启checkpoint,那么需要调用streamingContext.checkpoint(checkpointDirectory);另外,如果您让应用程序从驱动程序故障中恢复,那么应该重写应用程序以具备以下行为:
1、当程序第一次启动时,它会创建一个新的 StreamingContext,设置所有的流,然后调用 start()。
2、当程序在失败后重新启动时,它会从检查点目录中的检查点数据重新创建一个 StreamingContext。
如果 checkpointDirectory 存在,则将从检查点数据重新创建上下文。具体示例如下:
需要特别注意的是累加器和广播变量是不会从checkpoint中恢复的。因此需要创建为单例实例,以便在应用程序出现故障后重启后可以重新实例化它们。
class JavaWordExcludeList {private static volatile Broadcast<List<String>> instance = null;public static Broadcast<List<String>> getInstance(JavaSparkContext jsc) {if (instance == null) {synchronized (JavaWordExcludeList.class) {if (instance == null) {List<String> wordExcludeList = Arrays.asList("a", "b", "c");instance = jsc.broadcast(wordExcludeList);}}}return instance;}}/*** Use this singleton to get or register an Accumulator.*/class JavaDroppedWordsCounter {private static volatile LongAccumulator instance = null;public static LongAccumulator getInstance(JavaSparkContext jsc) {if (instance == null) {synchronized (JavaDroppedWordsCounter.class) {if (instance == null) {instance = jsc.sc().longAccumulator("DroppedWordsCounter");}}}return instance;}}public final class JavaRecoverableNetworkWordCount {private static final Pattern SPACE = Pattern.compile(" ");private static JavaStreamingContext createContext(String ip,int port,String checkpointDirectory,String outputPath) {// If you do not see this printed, that means the StreamingContext has been loaded// from the new checkpointSystem.out.println("Creating new context");File outputFile = new File(outputPath);if (outputFile.exists()) {outputFile.delete();}SparkConf sparkConf = new SparkConf().setAppName("JavaRecoverableNetworkWordCount");// Create the context with a 1 second batch sizeJavaStreamingContext ssc = new JavaStreamingContext(sparkConf, Durations.seconds(1));ssc.checkpoint(checkpointDirectory);// Create a socket stream on target ip:port and count the// words in input stream of \n delimited text (e.g. generated by 'nc')JavaReceiverInputDStream<String> lines = ssc.socketTextStream(ip, port);JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(SPACE.split(x)).iterator());JavaPairDStream<String, Integer> wordCounts = words.mapToPair(s -> new Tuple2<>(s, 1)).reduceByKey((i1, i2) -> i1 + i2);wordCounts.foreachRDD((rdd, time) -> {// Get or register the excludeList BroadcastBroadcast<List<String>> excludeList =JavaWordExcludeList.getInstance(new JavaSparkContext(rdd.context()));// Get or register the droppedWordsCounter AccumulatorLongAccumulator droppedWordsCounter =JavaDroppedWordsCounter.getInstance(new JavaSparkContext(rdd.context()));// Use excludeList to drop words and use droppedWordsCounter to count themString counts = rdd.filter(wordCount -> {if (excludeList.value().contains(wordCount._1())) {droppedWordsCounter.add(wordCount._2());return false;} else {return true;}}).collect().toString();String output = "Counts at time " + time + " " + counts;System.out.println(output);System.out.println("Dropped " + droppedWordsCounter.value() + " word(s) totally");System.out.println("Appending to " + outputFile.getAbsolutePath());Files.append(output + "\n", outputFile, Charset.defaultCharset());});return ssc;}public static void main(String[] args) throws Exception {if (args.length != 4) {System.err.println("You arguments were " + Arrays.asList(args));System.err.println("Usage: JavaRecoverableNetworkWordCount <hostname> <port> <checkpoint-directory>\n" +" <output-file>. <hostname> and <port> describe the TCP server that Spark\n" +" Streaming would connect to receive data. <checkpoint-directory> directory to\n" +" HDFS-compatible file system which checkpoint data <output-file> file to which\n" +" the word counts will be appended\n" +"\n" +"In local mode, <master> should be 'local[n]' with n > 1\n" +"Both <checkpoint-directory> and <output-file> must be absolute paths");System.exit(1);}String ip = args[0];int port = Integer.parseInt(args[1]);String checkpointDirectory = args[2];String outputPath = args[3];// Function to create JavaStreamingContext without any output operations// (used to detect the new context)Function0<JavaStreamingContext> createContextFunc =() -> createContext(ip, port, checkpointDirectory, outputPath);JavaStreamingContext ssc =JavaStreamingContext.getOrCreate(checkpointDirectory, createContextFunc);ssc.start();ssc.awaitTermination();}}
注意:checkpoint操作可能会导致 RDD 获得检查点的那些批次的处理时间增加,所以设置checkpoint的间隔要特别注意下;在小批量(比如 1 秒)下,每批检查点可能会显着降低操作吞吐量,相反,检查点太少会导致RDD依赖关系和任务大小增加,这可能会产生不利影响。
对于需要 RDD 检查点的有状态转换,默认间隔是批处理间隔的倍数,至少为 10 秒;通常,DStream 的 5 - 10 个滑动间隔的检查点间隔是一个很好的尝试设置。可以通过dstream.checkpoint(checkpointInterval)来设置。
2.3.8、Upgrading Application
一般情况下,我们会对已运行的SparkStreaming程序进行多次迭代,那么这个时候需要注意两件事情:
1、升级后的 Spark Streaming 应用程序启动并与现有应用程序并行运行。一旦新的(接收与旧的相同的数据)已经预热并准备好黄金时间,旧的就可以被关闭。需要注意的是这可以用于支持将数据发送到两个目的地的数据源(即较早的和升级的应用程序)。
2、现有应用程序正常关闭,确保在关闭之前完全处理已接收的数据,在调用stop方法的时候可以设置stopGracefully=true;然后就可以启动升级的应用程序,它将从较早的应用程序停止的同一点开始处理。注意:这只能使用支持源端缓冲的输入源(如 Kafka)来完成,因为数据需要在前一个应用程序关闭且升级的应用程序尚未启动时进行缓冲,而且无法从升级前代码的较早检查点信息重新启动。检查点信息本质上包含序列化的 Scala/Java/Python 对象,尝试使用新的、修改过的类反序列化对象可能会导致错误。在这种情况下,要么使用不同的检查点目录启动升级后的应用程序,要么删除之前的检查点目录。
2.3.9、Monitor
1、Spark Web UI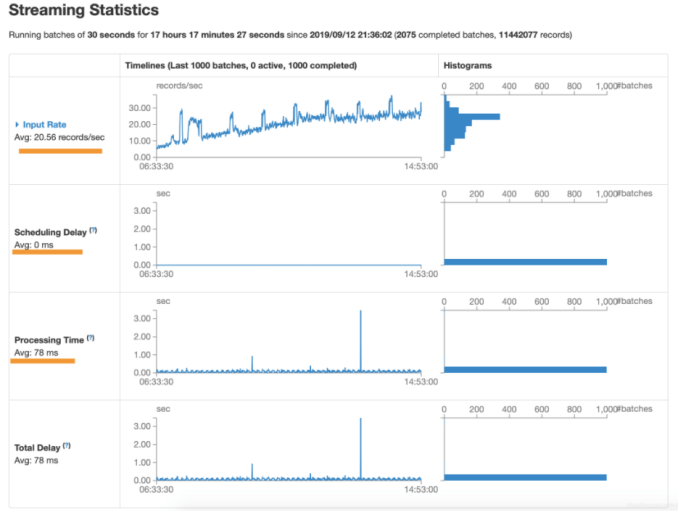
2、StreamingListener
class StatsReportListener(numBatchInfos: Int = 10) extends StreamingListener {// Queue containing latest completed batchesval batchInfos = new Queue[BatchInfo]()override def onBatchCompleted(batchStarted: StreamingListenerBatchCompleted) {batchInfos.enqueue(batchStarted.batchInfo)if (batchInfos.size > numBatchInfos) batchInfos.dequeue()printStats()}def printStats() {showMillisDistribution("Total delay: ", _.totalDelay)showMillisDistribution("Processing time: ", _.processingDelay)}def showMillisDistribution(heading: String, getMetric: BatchInfo => Option[Long]) {org.apache.spark.scheduler.StatsReportListener.showMillisDistribution(heading, extractDistribution(getMetric))}def extractDistribution(getMetric: BatchInfo => Option[Long]): Option[Distribution] = {Distribution(batchInfos.flatMap(getMetric(_)).map(_.toDouble))}}//streamingListener不需要在配置中设置,可以直接添加到streamingContext中object My{def main(args : Array[String]) : Unit = {val sparkConf = new SparkConf()val ssc = new StreamingContext(sparkConf,Seconds(20))ssc.addStreamingListener(new StatsReportListener())}}
2.3.10、Elegant Start And Stop
在实际场景中,当我们使用SparkStreaming开发好功能并通过测试之后部署到生产环境,那么之后就会7*24不间断执行的,除非出现异常退出。当然SparkStreaming提供了checkpoint和WAL机制能够保证我们的程序再次启动时候不会出现数据丢失的情况。但是需求并不是一成不变的,相信读者们都经历过需求不断迭代的情况,当我们需要迭代逻辑的时候,那么我们如何停止线上正在运行的程序呢?本文将为读者们详细介绍一些关于SparkStreaming优雅关闭的手段。接下来我们将针对以下几个问题进行展开讲解:
- 为什么需要优雅关闭?
- 什么时候触发关闭?
- 采用什么策略关闭?
2.3.10.1、Why Elegant Stop?
当我们的场景需要保证数据准确,不允许数据丢失,那么这个时候我们就得考虑优雅关闭了。说到关闭,那么非优雅关闭就是通过kill -9 processId的方式或者yarn -kill applicationId的方式进行暴力关闭,为什么说这种方式是属于暴力关闭呢?由于Spark Streaming是基于micro-batch机制工作的,按照间隔时间生成RDD,如果在间隔期间执行了暴力关闭,那么就会导致这段时间的数据丢失,虽然提供了checkpoin机制,可以使程序启动的时候进行恢复,但是当出现程序发生变更的场景,必须要删除掉checkpoint,因此这里就会有丢失的风险。
2.3.10.2、When Trigger Stop?
首先我们先来了解一下整体流程:
- 首先StreamContext在做初始化的时候,会增加Shutdown hook方法 ,放入到一个钩子队列中,并设置优先级为51
- 当程序jvm退出时,会启动一个线程从钩子队列中按照优先级取出执行,然后就会执行Shutdown钩子方法
- 当执行Shutdown钩子方法时,首先会将receiver进行关闭,即不再接收数据
- 然后停止生成BatchRDD
- 等待task全部完成,停止Executor
- 最后释放所有资源,即整个关闭流程结束
接下来看源码的具体实现:StreamingContext.scala:调用start方法会调用ShutdownHookManager注册stopOnShutdown函数
def start(): Unit = synchronized {state match {case INITIALIZED =>startSite.set(DStream.getCreationSite())....../*** StreamContext启动时会增加Shutdown钩子函数,优先级为51*/shutdownHookRef = ShutdownHookManager.addShutdownHook(StreamingContext.SHUTDOWN_HOOK_PRIORITY)(() => stopOnShutdown())....case ACTIVE =>logWarning("StreamingContext has already been started")case STOPPED =>throw new IllegalStateException("StreamingContext has already been stopped")}}
ShutdownHookManager.scala:在增加钩子函数的时候底层调用了SparkShutdownHookManager内部类:
def addShutdownHook(priority: Int)(hook: () => Unit): AnyRef = {shutdownHooks.add(priority, hook)}private lazy val shutdownHooks = {val manager = new SparkShutdownHookManager()manager.install()manager}private [util] class SparkShutdownHookManager {def install(): Unit = {val hookTask = new Runnable() {override def run(): Unit = runAll()}org.apache.hadoop.util.ShutdownHookManager.get().addShutdownHook(hookTask, FileSystem.SHUTDOWN_HOOK_PRIORITY + 30)}/*** jvm退出的时候会开启一个线程按照优先级逐个调用钩子函数*/def runAll(): Unit = {shuttingDown = truevar nextHook: SparkShutdownHook = nullwhile ({ nextHook = hooks.synchronized { hooks.poll() }; nextHook != null }) {Try(Utils.logUncaughtExceptions(nextHook.run()))}}def add(priority: Int, hook: () => Unit): AnyRef = {hooks.synchronized {if (shuttingDown) {throw new IllegalStateException("Shutdown hooks cannot be modified during shutdown.")}val hookRef = new SparkShutdownHook(priority, hook)hooks.add(hookRef)hookRef}}}private class SparkShutdownHook(private val priority: Int, hook: () => Unit)extends Comparable[SparkShutdownHook] {//这里真正调用注册的函数def run(): Unit = hook()}
那么接下来看下真正执行关闭的逻辑,即StreamingContext#stopOnShutdown方法:
private def stopOnShutdown(): Unit = {val stopGracefully = conf.getBoolean("spark.streaming.stopGracefullyOnShutdown", false)stop(stopSparkContext = false, stopGracefully = stopGracefully)}def stop(stopSparkContext: Boolean, stopGracefully: Boolean): Unit = {synchronized {state match {case ACTIVE =>//调度相关的关闭Utils.tryLogNonFatalError {scheduler.stop(stopGracefully)}//监控Utils.tryLogNonFatalError {env.metricsSystem.removeSource(streamingSource)}//uiUtils.tryLogNonFatalError {uiTab.foreach(_.detach())}Utils.tryLogNonFatalError {unregisterProgressListener()}StreamingContext.setActiveContext(null)//设置状态为停止state = STOPPED}}if (shutdownHookRefToRemove != null) {ShutdownHookManager.removeShutdownHook(shutdownHookRefToRemove)}// a user might stop(stopSparkContext = false) and then call stop(stopSparkContext = true).if (stopSparkContext) sc.stop()}
可以看到这里有一个spark.streaming.stopGracefullyOnShutdown参数来传给底层的stop方法,即调用Jobscheduler#stop方法
def stop(processAllReceivedData: Boolean): Unit = synchronized {//1.首先停止接收数据if (receiverTracker != null) {receiverTracker.stop(processAllReceivedData)}if (executorAllocationManager != null) {executorAllocationManager.foreach(_.stop())}//2.停止生成BatchRdd,处理剩余的数据jobGenerator.stop(processAllReceivedData)//3.停止ExectuorjobExecutor.shutdown()val terminated = if (processAllReceivedData) {jobExecutor.awaitTermination(1, TimeUnit.HOURS) // just a very large period of time} else {jobExecutor.awaitTermination(2, TimeUnit.SECONDS)}if (!terminated) {jobExecutor.shutdownNow()}// Stop everything elselistenerBus.stop()eventLoop.stop()eventLoop = nulllogInfo("Stopped JobScheduler")}
2.3.10.3、Which policy stops?
2.3.10.3.1、配置策略
根据刚才梳理的触发关闭流程中,其实可以通过配置spark.streaming.stopGracefullyOnShutdown=true来实现优雅关闭,但是需要发送 SIGTERM 信号给driver端,这里有两种方案。
方案一,具体步骤如下:
1. 通过Spark UI找到driver所在节点。1. 登录driver节点,执行 **ps -ef |grep java |grep ApplicationMaster**命令找到对应的pid1. 执行**kill -SIGTERM **发送SIGTERM信号1. 当spark driver收到该信号时,在日志中会有以下信息
ERROR yarn.ApplicationMaster: RECEIVED SIGNAL 15: SIGTERMINFO streaming.StreamingContext: Invoking stop(stopGracefully=true) from shutdown hookINFO streaming.StreamingContext: StreamingContext stopped successfullyINFO spark.SparkContext: Invoking stop() from shutdown hookINFO spark.SparkContext: Successfully stopped SparkContextINFO util.ShutdownHookManager: Shutdown hook called
注意:
这里有一个坑,默认情况下在yarn模式下,spark.yarn.maxAppAttempts参数值和yarn.resourcemanager.am.max-attempts是同一个值,即为2。当通过Kill命令杀掉AM时,Yarn会自动重新启动一个AM,因此需要再发送一次Kill命令。当然也可以通过spark-submit命令提交的时候指定spark.yarn.maxAppAttempts=1这个配置参数;但这里也会有容灾风险,比如出现网络问题的时候,这里就无法自动重启了,程序就会以失败而告终。
2.3.10.3.2、标记策略
该种策略通过借助于三方系统来标记状态, 一种方法是将标记HDFS文件,如果标记文件存在,则调用scc.stop(true,true);或者是借助于redis的key是否存在等方式
val checkIntervalMillis = 60000var isStopped = falsewhile (! isStopped) {isStopped = ssc.awaitTerminationOrTimeout(checkIntervalMillis)checkShutdownMarkerif (!isStopped && stopFlag) {ssc.stop(true, true)}}def checkShutdownMarker = {if (!stopFlag) {val fs = FileSystem.get(new Configuration())stopFlag = fs.exists(new Path(shutdownMarker))}
2.3.10.3.3、服务策略
即提供一个restful服务,暴露出一个接口提供关闭功能。
def httpServer(port:Int,ssc:StreamingContext)={val server = new Server(port)val context = new ContextHandler()context.setContextPath("/shutdown")context.setHandler( new CloseStreamHandler(ssc) )server.setHandler(context)server.start()}class CloseStreamHandler(ssc:StreamingContext) extends AbstractHandler {override def handle(s: String, baseRequest: Request, req: HttpServletRequest, response: HttpServletResponse): Unit ={ssc.stop(true,true)response.setContentType("text/html; charset=utf-8");response.setStatus(HttpServletResponse.SC_OK);val out = response.getWriter();baseRequest.setHandled(true);}}
2.3.11、Small File
当使用 Spark Streaming 通过实时计算写入到 HDFS,那么不可避免的会遇到一个问题,那就是在默认情况下会产生非常多的小文件,这是由 Spark Streaming 的微批处理模式和 DStream(RDD) 的分布式(partition)特性导致的,Spark Streaming 为每个 Partition 启动一个独立的线程(一个 task/partition 一个线程)来处理数据,一旦文件输出到 HDFS,那么这个文件流就关闭了,再来一个 batch 的 parttition 任务,就再使用一个新的文件流,那么假设,一个 batch 为10s,每个输出的 DStream 有32个 partition,那么一个小时产生的文件数将会达到(3600/10)*32=11520个之多。众多小文件带来的结果是有大量的文件元信息,比如文件的 location、文件大小、block number 等需要 NameNode 来维护,NameNode 侧的负载就会很高。不管是什么格式的文件,parquet、text、JSON 或者 Avro,都会遇到这种小文件问题,这里讨论几种处理 Spark Streaming 小文件的典型方法。
2.3.11.1、Add Batch Interval
batch 越大,从外部接收的 event 就越多,内存积累的数据也就越多,那么输出的文件数也就会变少,比如上边的时间从10s增加为100s,那么一个小时的文件数量就会减少到1152个
2.3.11.2、Coalesce
小文件的基数是 batch_number * partition_number,而第一种方法是减少 batch_number,那么这种方法就是减少 partition_number 了,这个 api 不细说,就是减少初始的分区个数。对于窄依赖,一个子 RDD 的 partition 规则继承父 RDD,对于宽依赖,如果没有特殊指定分区个数,也继承自父 rdd。那么初始的 SourceDstream 是几个 partiion,最终的输出就是几个 partition。所以 Coalesce 大法的好处就是,可以在最终要输出的时候,来减少 partition 个数。但是这个方法的缺点也很明显,本来是32个线程在写256M数据,现在可能变成了4个线程在写256M数据,而没有写完成这256M数据,这个 batch 是不算结束的。那么一个 batch 的处理时延必定增长,batch 挤压会逐渐增大.
2.3.11.3、HQL/SparkSQL
既然把数据输出到 hdfs,那么说明肯定是要用 Hive 或者 Spark Sql 这样的“sql on hadoop”系统类进一步进行数据分析,而这些表一般都是按照半小时或者一小时、一天,这样来分区的(注意不要和 Spark Streaming 的分区混淆,这里的分区,是用来做分区裁剪优化的),那么我们可以考虑在 Spark Streaming 外再启动定时的批处理任务来合并 Spark Streaming 产生的小文件。但是需要注意的是,批处理的合并任务在时间切割上要把握好,搞不好就可能会去合并一个还在写入的 Spark Streaming 小文件
2.3.11.4、Append
Spark Streaming 提供的 foreach 这个 outout 类 api (一种 Action 操作),可以让我们自定义输出计算结果的方法。那么我们其实也可以利用这个特性,那就是每个 batch 在要写文件时,并不是去生成一个新的文件流,而是把之前的文件打开。考虑这种方法的可行性,首先,HDFS 上的文件不支持修改,但是很多都支持追加,那么每个 batch 的每个 partition 就对应一个输出文件,每次都去追加这个 partition 对应的输出文件,这样也可以实现减少文件数量的目的。当然这种方法要注意的就是不能无限制的追加,当判断一个文件已经达到某一个阈值时,就要产生一个新的文件进行追加了。(需要注意的是像orc和parquet存储类型是不支持追加的)
2.3.12、Optimize
更多关于spark相关的配置详见spark配置大全
对于流作业的优化,主要关注点在于:
1、高效利用集群资源,减少每批数据的处理时间
2、设置正确的批次大小,以便数据批次可以在接收时尽快处理(即数据处理跟上数据摄取)
确定应用程序正确批量大小的一个好方法是使用保守的批量间隔(例如 5-10 秒)和低数据速率对其进行测试,为了验证系统是否能够跟上数据速率,可以检查每个处理批次所经历的端到端延迟的值.如果延迟保持与批量大小相当,则系统是稳定的。否则,如果延迟不断增加,则表示系统跟不上,因此不稳定
2.3.12.1、Reduceing the Batch Processing Time —> batchDuration
spark会隔batchDuration时间去提交一次Job,如果Job处理的时间超过了batchDuration,那么就会导致后面的作业无法提交,随着时间的推移,越来越多的作业会被积压,最后导致整个流作业被阻塞无法实时处理数据。
一般根据经验值,batchDuration尽量不要少于500ms;通常在提交作业的时候可以先设置为一个比较大的值(比如5s),然后根据web ui观察处理速率来不断调整该值,直到这个batchDuration时间内可以完美的处理好job作业。
2.3.12.2、Reduceing the Batch Processing Time —> Parallelism
增加并行度能够充分利用集群资源,尽可能将Task分配到不同的节点上。例如在对接Kafka消费分区的时候(现在SparkStreaming对应的Task数是和分区数一样的),可以达到负载均衡。
当然这里的并行度调整包括InputDStream的并行度、Task并行度、数据处理并行度等。
1、InputDstream并行度:例如当同时消费多个Topic的时候,那么可以把每个Topic对应的DStream进行合并处理,然后进行后续的处理;或者可以将一个Topic的多个分区被多个DStream进行消费,然后再合并为一个DSteram.
int numStreams = 5;List<JavaPairDStream<String, String>> kafkaStreams = new ArrayList<>(numStreams);for (int i = 0; i < numStreams; i++) {kafkaStreams.add(KafkaUtils.createStream(...));}JavaPairDStream<String, String> unifiedStream = streamingContext.union(kafkaStreams.get(0), kafkaStreams.subList(1, kafkaStreams.size()));unifiedStream.print();
2、Task并行度:流作业中有一个RecurringTimer对象会周期性发送BlockGenerator消息,进而周期性生成Block。这个周期有一个配置参数spark.streaming.blockInterval(默认是200ms),而spark streaming是按照Batch Interval来接收数据并处理,所以interval内的block个数就是RDD的Partition数,也就是RDD的并行Task数。所以Task并行度等于Batch Interval/Block Interval。例如Batch Interval 为2s, BlockInterval是200ms,那么Task并行度就是10;一般建议BlockInterval不低于50ms
3、数据处理并行度:可以通过设置spark.default.parallelism来调整Stage上的并发任务数
4、重分区:在处理数据前,进行重分区。避免倾斜情况发生
2.3.12.3、Reduceing the Batch Processing Time —> Kryo Serializable
通过调整序列化格式可以减少数据序列化的开销。在流的情况下,有两种类型的数据正在被序列化:
1、Input Data:默认情况下,通过Receiver接收到的数据通过StorageLevel.MEMORY_AND_DISK_SER_2存储策略被保存到executor的内存中。因此数据被序列化为字节可以减少GC的开销,并复制来容忍程序的失败;另外数据保存到内存中,当内存不足时那么会溢写到磁盘上,显然这种序列化就会带来一定的开销,接收方必须反序列化接收到的数据并使用 Spark 的序列化格式重新序列化。
2、Persisted RDDs generated by Streaming Operations:例如,窗口操作将数据保存在内存中,因为它们将被多次处理;但不像spark core默认使用StorageLevel.MEMORY_ONLY,流计算使用的是StorageLevel.MEMORY_ONLY_SER策略进行持久化,以此来最小化GC的开销。
基于以上两种场景,可以使用kryo序列化来降低CPU和内存负载。在流应用程序需要保留的数据量不大的情况下,将数据(两种类型)持久化为反序列化对象而不产生过多的 GC 开销可能是可行的,例如,如果使用几秒钟的批处理间隔并且没有窗口操作,那么可以尝试通过相应地显式设置存储级别来禁用持久数据中的序列化,这将减少由于序列化而导致的 CPU 开销,从而潜在地提高性能而不会产生过多的 GC 开销。
2.3.12.4、Reduceing the Batch Processing Time —> Task Launching Overheads
如果每秒启动的任务数量很高(比如每秒 50 个或更多),那么向executor发送任务的开销可能很大,并且很难实现亚秒级延迟。可以通过改变执行方式来避免这种情况:
在standalone模式或者粗粒度Mesos模式下运行spark会比细粒度Mesos模型获得更好的任务启动时间。这些更改可能会将批处理时间减少 100 毫秒,从而使亚秒级的批处理大小可行。
2.3.12.5、Right Batch Interval——> Cache Data & Compress
1、对于常使用的数据,可以进行缓存;但缓存数据的同时要注意内存资源,不然内存不够会溢写到磁盘反而会降低性能。
2、对于需要缓存的数据同时可以进行序列化操作,以及进行压缩手段(spark.rdd.compress默认为false),降低内存使用率,当然另一方面可能会造成cpu紧张。需要根据实际的情况进行选择。
2.3.12.6、Right Batch Interval——> Clean Data
1、例如在缓存内存中,可能存在一些不需要的数据,那么这个时候可以清除掉,释放内存资源,可以通过spark.cleaner.ttl设置一个清理值,注意:该值不能过小,不然可能会把使用的数据给清除掉。
2、智能持久化RDD,可以通过设置spark.streaming.unpersist=true参数来智能持久化一些不需要经常保留的RDD,尽量减少内存的使用
3、可以设置streamingContext.remember,来决策保留数据的时间长短。例如如果使用 10 分钟的窗口操作,那么 Spark Streaming 将保留最近 10 分钟的数据,并主动丢弃旧数据,当然也可以通过调用该方法来调整保留时间。
2.3.12.7、Right Batch Interval——> GC
1、流式作业中,应尽量避免GC对Job的影响,通常可以设置高效的GC回收器来提升GC时间,如可以开启Mark-Sweep(CMS)来并行GC,即通过配置spark.executor.extraJavaOptions=-XX:+UseConcMarkSweepGC,如果要使用的话,需要Driver端和Executor端都要开启,而且会降低吞吐量;或者设置G1 GC回收器来提升性能。
2、为了尽量减少GC触发,可以使用OFF_HEAP存储级别来持久化RDD
2.3.12.8、Right Batch Interval——> CPU
根据数据体量和业务逻辑复杂合理设置CPU资源;同时可以通过压缩(spark.rdd.compress)参数来决定是否开启压缩来增加cpu代价

若有收获,就点个赞吧
0 人点赞
