锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,锁可以从偏向锁升级到轻量级锁,再升级的重量级锁。但是锁的升级是单向的,也就是说只能从低到高升级,不会出现锁的降级。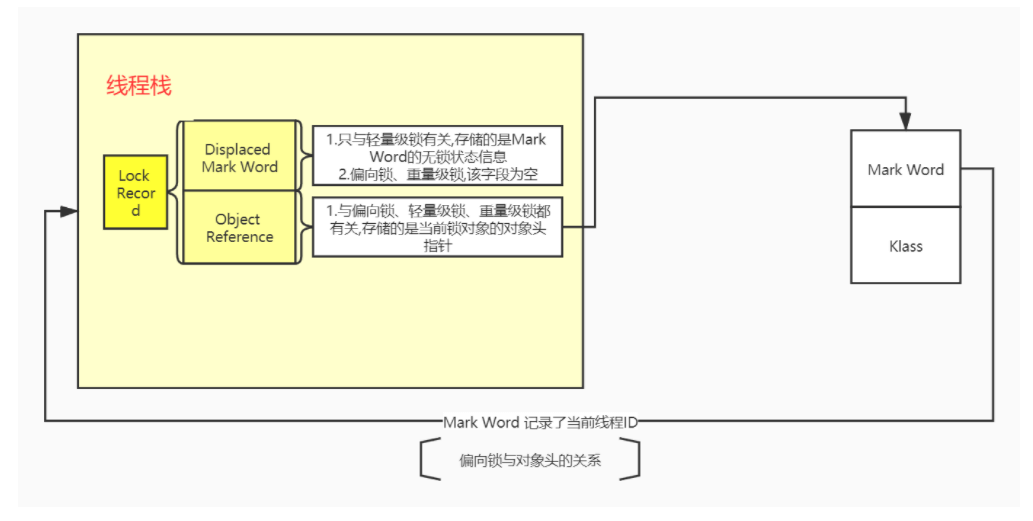
自旋锁
线程互斥同步进入阻塞状态的开销都很大,应该尽量避免。在许多应用中,共享数据的锁定状态只会持续很短的一段时间。自旋锁的思想是让一个线程在请求一个共享数据的锁时执行忙循环(自旋)一段时间,如果在这段时间内能获得锁,就可以避免进入阻塞状态。
自旋锁虽然能避免进入阻塞状态从而减少开销,但是它需要进行忙循环操作占用 CPU 时间,它只适用于共享数据的锁定状态很短的场景。(在自旋的时候,会光占用CPU,但是做不了什么产出)
自旋锁以前的自旋次数是固定的,但是在1.6以后,引入了自适应的自旋锁。自适应意味着自旋的次数不再固定了,而是由前一次在同一个锁上的自旋次数及锁的拥有者的状态来决定。
线程如果自旋成功了,那么下次自旋的次数会更加多,因为虚拟机认为既然上次成功了,那么此次自旋也很有可能会再次成功,那么它就会允许自旋等待持续的次数更多。反之,如果对于某个锁,很少有自旋能够成功,那么在以后要或者这个锁的时候自旋的次数会减少甚至省略掉自旋过程,以免浪费处理器资源。
偏向锁
偏向锁可以减少不必要的CAS操作,仅在有竞争的时候才会释放(需等待运行至安全点),线程不会主动释放偏向锁
- 检测当前类的Mark Word是否为可偏向状态,即是否为偏向锁1,锁标识位为01;
- 若为可偏向状态,则测试线程ID是否为当前线程ID,如果是,则执行步骤(5),否则执行步骤(3);
- 如果测试线程ID不为当前线程ID,则通过CAS操作竞争锁,竞争成功,则将Mark Word的线程ID替换为当前线程ID(不拷贝,只有轻量级锁才会拷贝,并且会在线程中创建一个Lock Record,把Lock Record中的),否则执行线程(4);
- 通过CAS竞争锁失败,证明当前存在多线程竞争情况,当到达全局安全点,获得偏向锁的线程被挂起,偏向锁升级为轻量级锁,然后被阻塞在安全点的线程继续往下执行同步代码块;
- 执行同步代码块;
当到达全局安全点时
- 暂停拥有偏向锁的线程;
判断锁对象是否还处于被锁定状态,
否,则恢复到无锁状态(01),以允许其余线程竞争。<br /> 是,则挂起持有锁的当前线程,并将指向当前线程的锁记录(Lock Record)地址的指针放入对象头Mark Word,升级为轻量级锁状态 (00),然后恢复持有锁的当前线程,进入轻量级锁的竞争模式;
轻量级锁
引入轻量级锁的主要目的是 在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。
当关闭偏向锁功能或者多个线程竞争偏向锁导致偏向锁升级为轻量级锁,则会尝试获取轻量级锁,其步骤如下:在线程进入同步块时,如果同步对象锁状态为无锁状态(锁标志位为“01”状态,是否为偏向锁为“0”),虚拟机首先将在当前线程的栈帧中建立一个名为锁记录(Lock Record)的空间,用于存储锁对象目前的Mark Word的拷贝,官方称之为 Displaced Mark Word。
- 拷贝对象头中的Mark Word复制到锁记录(Lock Record)中;
- 拷贝成功后,虚拟机将使用CAS操作尝试将对象Mark Word中的Lock Word更新为指向当前线程Lock Record的指针,并将Lock record里的owner指针指向object mark word。如果更新成功,则执行步骤(4),否则执行步骤(5);
- 如果这个更新动作成功了,那么当前线程就拥有了该对象的锁,并且对象Mark Word的锁标志位设置为“00”
- 如果这个更新操作失败了,虚拟机首先会检查对象Mark Word中的Lock Word是否指向当前线程的栈帧,如果是,就说明当前线程已经拥有了这个对象的锁,那就可以直接进入同步块继续执行。否则说明多个线程竞争锁,进入自旋执行(3),若自旋结束时仍未获得锁,轻量级锁就要膨胀为重量级锁,锁标志的状态值变为“10”,Mark Word中存储的就是指向重量级锁(互斥量)的指针,当前线程以及后面等待锁的线程也要进入阻塞状态。
轻量级锁和偏向锁的区别,轻量级锁会自旋获取,偏向锁不会
对于轻量级锁,其性能提升的依据是 “对于绝大部分的锁,在整个生命周期内都是不会存在竞争的”,如果打破这个依据则除了互斥的开销外,还有额外的CAS操作,因此在有多线程竞争的情况下,轻量级锁比重量级锁更慢。
重量级锁
synchronized通过操作系统的互斥锁来实现,依赖于操作系统Mutex Lock。依赖操作系统互斥锁的锁都是重量级锁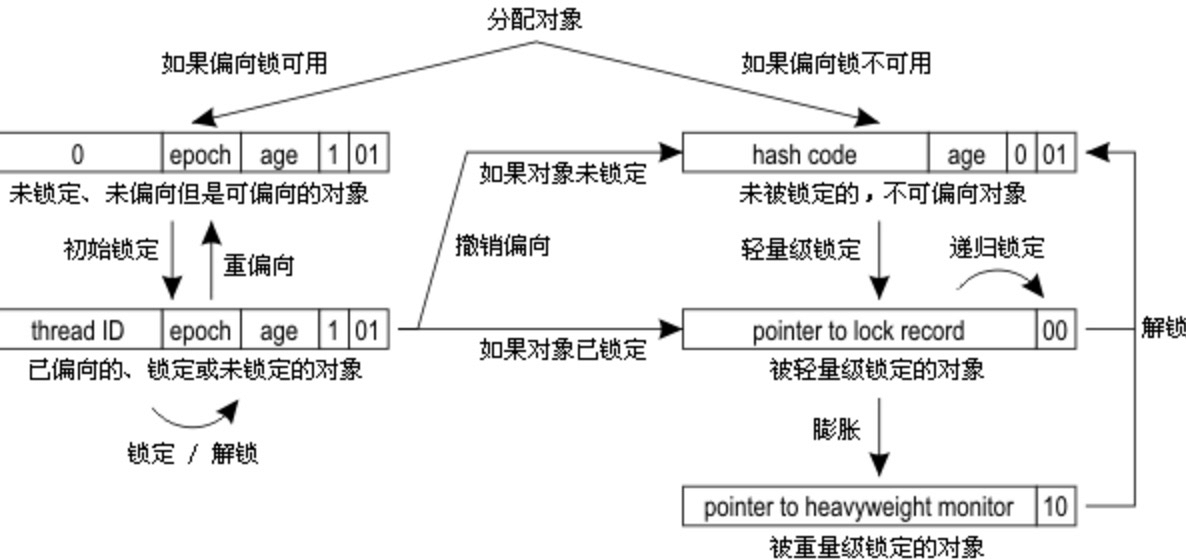
锁粗化
在使用同步锁的时候,需要让同步块的作用范围尽可能小—仅在共享数据的实际作用域中才进行同步,这样做的目的是 为了使需要同步的操作数量尽可能缩小,如果存在锁竞争,那么等待锁的线程也能尽快拿到锁。
在大多数的情况下,上述观点是正确的。但是如果一系列的连续加锁解锁操作,可能会导致不必要的性能损耗,所以引入锁粗话的概念。
锁粗话概念比较好理解,就是将多个连续的加锁、解锁操作连接在一起,扩展成一个范围更大的锁
如上面实例:
vector每次add的时候都需要加锁操作,JVM检测到对同一个对象(vector)连续加锁、解锁操作,会合并一个更大范围的加锁、解锁操作,即加锁解锁操作会移到for循环之外。
锁消除
为了保证数据的完整性,在进行操作时需要对这部分操作进行同步控制,但是在有些情况下,JVM检测到不可能存在共享数据竞争,这是JVM会对这些同步锁进行锁消除。
锁消除的依据是逃逸分析的数据支持
如果不存在竞争,为什么还需要加锁呢?所以锁消除可以节省毫无意义的请求锁的时间。变量是否逃逸,对于虚拟机来说需要使用数据流分析来确定,但是对于程序员来说这还不清楚么?在明明知道不存在数据竞争的代码块前加上同步吗?但是有时候程序并不是我们所想的那样?虽然没有显示使用锁,但是在使用一些JDK的内置API时,如StringBuffer、Vector、HashTable等,这个时候会存在隐形的加锁操作。比如StringBuffer的append()方法,Vector的add()方法:
public void vectorTest(){Vector<String> vector = new Vector<String>();for(int i = 0 ; i < 10 ; i++){vector.add(i + "");}}
此处vector并未作用于其他地方,所以此处锁可以进行消除

若有收获,就点个赞吧
0 人点赞
