ConcurrentHashMap是线程安全的HashMap,和HashTable不同,ConcurrentHashMap通过锁分离技术,运行效率比HashTable高
一、JDK1.7版本的ConcurrentHashMap
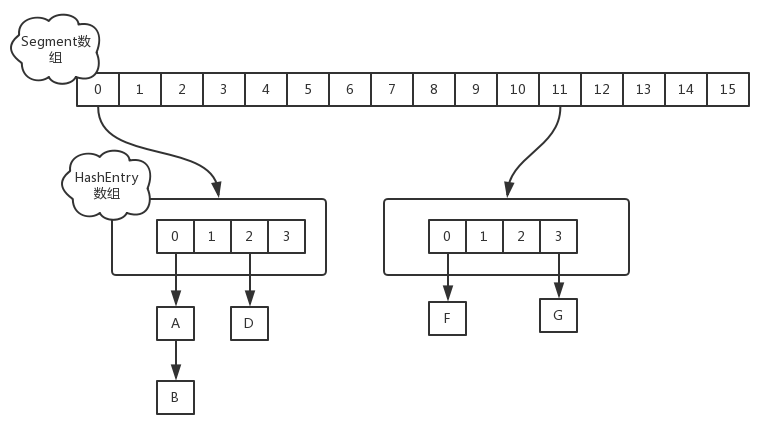
在JDK1.7中,ConcurrentHashMap通过Segement数组实现锁分离技术
其数组结构由原来的桶,增加了一个Segement数组
其内部结构为 Segement->table->link
static final class Segment<K,V> extends ReentrantLock implements Serializable {transient volatile HashEntry<K,V>[] table;}
在Segement内部声明了table,通过位运算初始化Segement的大小,,默认是16个,其最大值为65536既2的16次方
int sshift = 0;int ssize = 1;while (ssize < concurrencyLevel) {++sshift;ssize <<= 1;}
二、Put(1.7)
static class Segment<K,V> extends ReentrantLock implements Serializable {
当执行put操作时,会进行第一次key的hash来定位Segment的位置,如果该Segment还没有初始化,即通过CAS操作进行赋值,然后进行第二次hash操作,找到相应的HashEntry的位置,这里会利用继承过来的锁的特性,在将数据插入指定的HashEntry位置时(链表的尾端),会通过继承ReentrantLock的tryLock()方法尝试去获取锁,如果获取成功就直接插入相应的位置,如果已经有线程获取该Segment的锁,那当前线程会以自旋的方式去继续的调用tryLock()方法去获取锁,超过指定次数就挂起,等待唤醒
二、Put(1.8)
在1.7版本中锁的粒度是Segement,1.8是table,降级了锁的粒度,在1.8中就不涉及到Segement了
final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)tab = initTable();else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {V oldVal = null;synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;}
①ConcurrentHashMap不允许空的Key和Value出现
if (key == null || value == null) throw new NullPointerException();
②当table处无数据时,直接进行无锁插入
Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)tab = initTable();else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}
③如果在扩容,则等待扩容
if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);
④若有数据时,则进行加锁插入,链表长度超过8转换成红黑树
V oldVal = null;synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}
四、Get(1.7)
ConcurrentHashMap的get操作跟HashMap类似,只是ConcurrentHashMap第一次需要经过一次hash定位到Segment的位置,然后再hash定位到指定的HashEntry,遍历该HashEntry下的链表进行对比,成功就返回,不成功就返回null
五、Get(1.8)
- 计算hash值,定位到该table索引位置,如果是首节点符合就返回
- 如果遇到扩容的时候,会调用标志正在扩容节点ForwardingNode的find方法,查找该节点,匹配就返回
以上都不符合的话,就往下遍历节点,匹配就返回,否则最后就返回null
六、Size(1.7)
在1.7中对Size的求法有两种方案
第一种方案他会使用不加锁的模式去尝试多次计算ConcurrentHashMap的size,最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入,计算的结果是准确的
- 第二种方案是如果第一种方案不符合,他就会给每个Segment加上锁,然后计算ConcurrentHashMap的size返回
七、Size(1.8)
public int size() {long n = sumCount();return ((n < 0L) ? 0 :(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :(int)n);}
Size在执行put的时候就已经计算好了final long sumCount() {CounterCell[] as = counterCells; CounterCell a;long sum = baseCount;if (as != null) {for (int i = 0; i < as.length; ++i) {if ((a = as[i]) != null)sum += a.value;}}return sum;}

若有收获,就点个赞吧
0 人点赞
