B树
B树也称B-树,它是一颗多路平衡查找树
- 每个节点最多有m-1个关键字(可以存有的键值对)。阶数减一
- 根节点最少可以只有1个关键字。 根节点只有一个关键字
- 非根节点至少有m/2个关键字。 m/2 < x < m
- 每个节点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它。
- 所有叶子节点都位于同一层,或者说根节点到每个叶子节点的长度都相同。
- 每个节点都存有索引和数据,也就是对应的key和value。
需要注意的是,B树每个节点都是存储数据的,而B+树,只有在叶子节点才存储数据
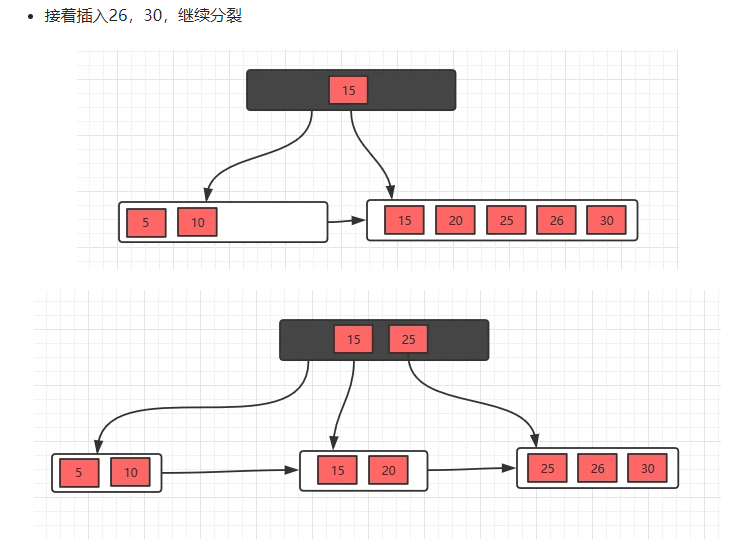
B树的插入
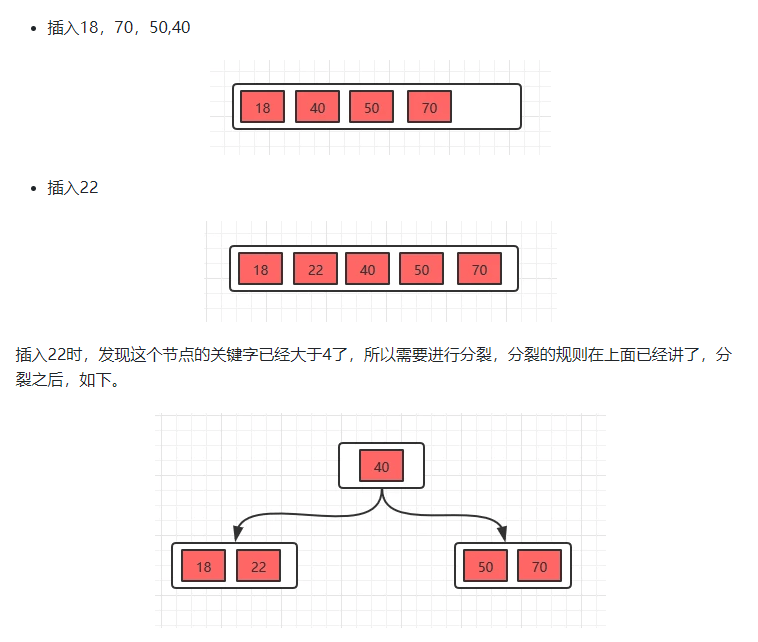
B+树
B+树只有在叶子节点存储数据,中间节点只存储指针
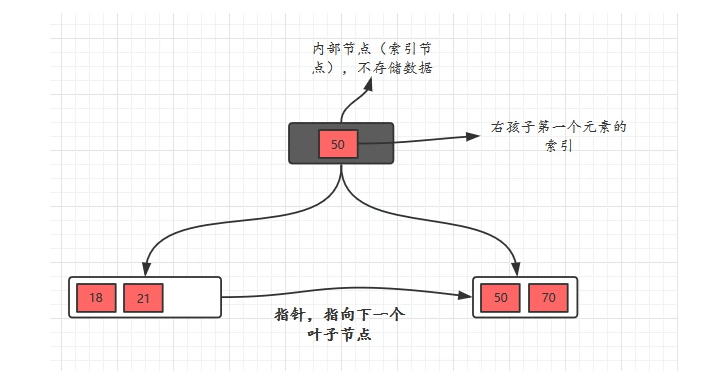
- B+树有两种类型的节点:内部结点(也称索引结点)和叶子结点。内部节点就是非叶子节点,内部节点不存储数据,只存储索引,数据都存储在叶子节点。
- 内部结点中的key都按照从小到大的顺序排列,对于内部结点中的一个key,左树中的所有key都小于它,右子树中的key都大于等于它。叶子结点中的记录也按照key的大小排列。
- 每个叶子结点都存有相邻叶子结点的指针,叶子结点本身依关键字的大小自小而大顺序链接。
- 父节点存有右孩子的第一个元素的索引。
- 非根节点元素范围:m/2 <= k <= m-1
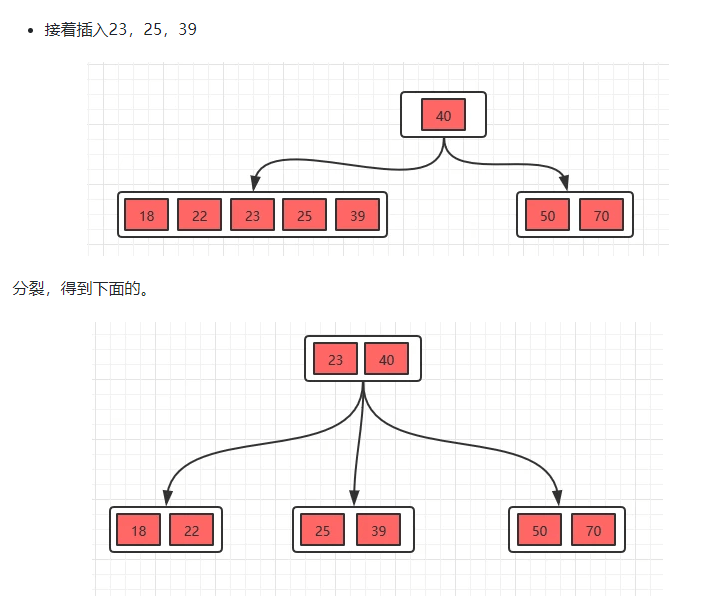
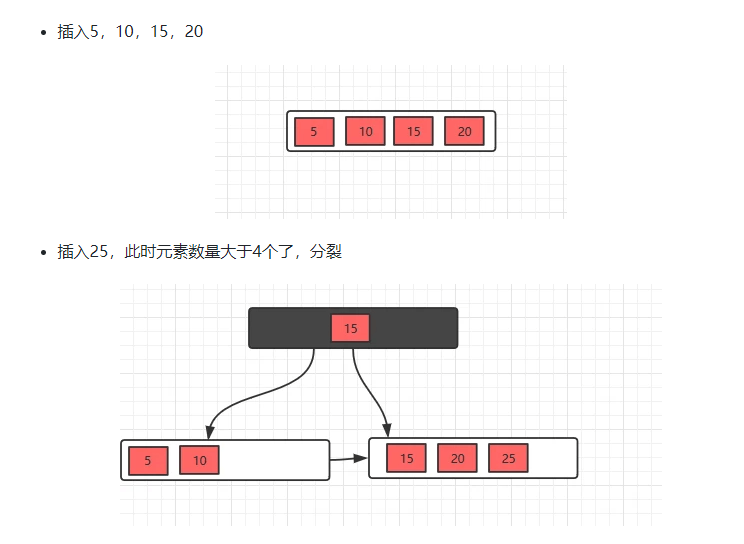
B+树的插入
B树和B+树总结
B+树相对于B树有一些自己的优势,可以归结为下面几点。
- 单一节点存储的元素更多,使得查询的IO次数更少,所以也就使得它更适合做为数据库MySQL的底层数据结构了。
- 所有的查询都要查找到叶子节点,查询性能是稳定的,而B树,每个节点都可以查找到数据,所以不稳定。
- 所有的叶子节点形成了一个有序链表,更加便于查找。
磁盘IO与预读
计算机存储设备一般分为两种:内存储器(main memory)和外存储器(external memory)。
外存储器即为磁盘读取,磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分,寻道时间指的是磁臂移动到指定磁道所需要的时间,主流磁盘一般在5ms以下;
为什么说B+树比B树更适合数据库索引?
数据库是一页一页(Page)读的
InnoDB 一页16K
1)B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了;
2)B+树查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当;
3)B+树便于范围查询(最重要的原因,范围查找是数据库的常态)
B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低;不懂可以看看这篇解读-》范围查找
4)千万级别的Mysql索引 约3-5层
5) 其实这也很好算,我们假设主键 ID 为 bigint 类型,长度为 8 字节,而指针大小在 InnoDB 源码中设置为 6 字节,这样一共 14 字节,我们一个页中能存放多少这样的单元,其实就代表有多少指针,即 16384/14=1170。
一个节点可以存储1170个指针,阶数就位1171
b+树的查找过程
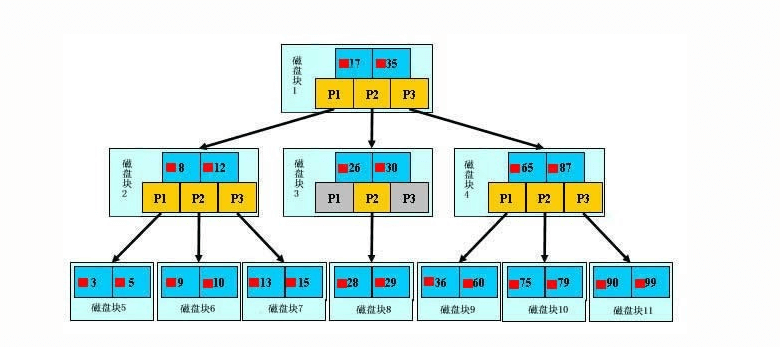
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。

若有收获,就点个赞吧
0 人点赞
