1、flink介绍:
开源流处理框架。核心由java与scala编写,目前国内最好的实时流处理框架。 版本选择为:1.13.1版本
可处理无界、有界流,实际常用于要求严格的实时流处理。
代码实现
- 实现方式* Java API* Scala API- 统一数据处理过程抽象* 将实时和批处理的数据过程,均抽象成三个过程,即Source->Transform->Sink。* Source为源数据读入,即Source算子。* Transform是数据转换处理过程,即Transform算子。* Sink即数据接收器,即数据落地到存储层,即Sink算子。- 代码实现复杂度* 丰富的API和算子操作,抽象封装统一性较高,支持类SQL编程,编程复杂度并不高
2、架构设计
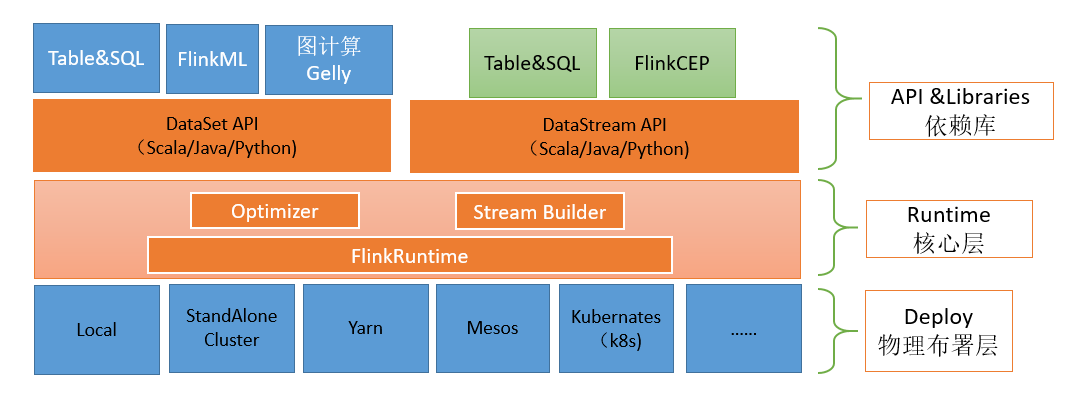
Deploy— 部署在某个位置视需求而定
Runtime— 实现框架,对上层接口提供服务
依赖库 — 提升用户体验、提供api 支持流与批
3、运行模式
- 运模模式核心区分点
- 集群生命周期和资源隔离保证
- 应用程序的main()方法是在客户端还是在集群上执行
- 本地运行模式 —-测试用 一个机器启动一个进程的多线程
- standalone模式 —完全独立的flink模式。资源不共享
- 集群运行模式
- session模式 集群资源充分、频繁任务提交、小作业居多、实时性要求高的场景 (出场少)
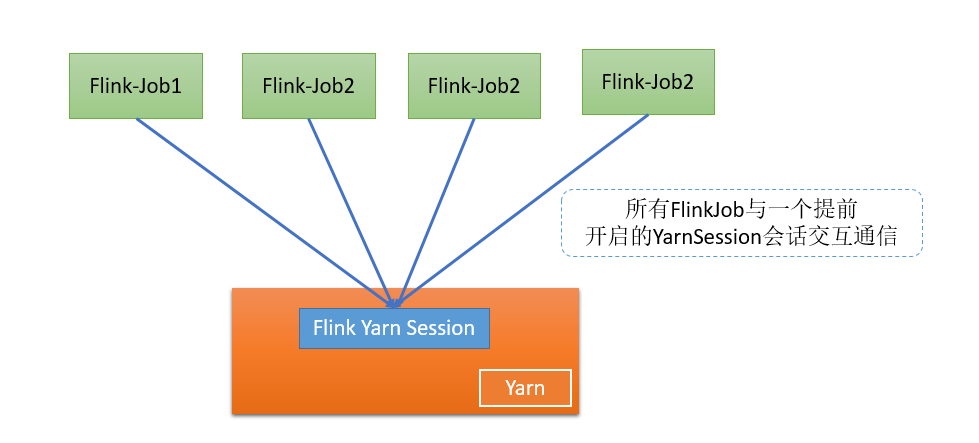
- per-job模式 作业少、大作业、实时性要求低的场景

- application模式 实时性要求不太高、安全性有一定要求均可以使用,普遍适用性最强
session有附加模式和分离模式。Flink Job(per-job)与Flink Application直接是分离模式
一般建议用per-job或是application模式,提供了更好的资源隔离性和安全性。
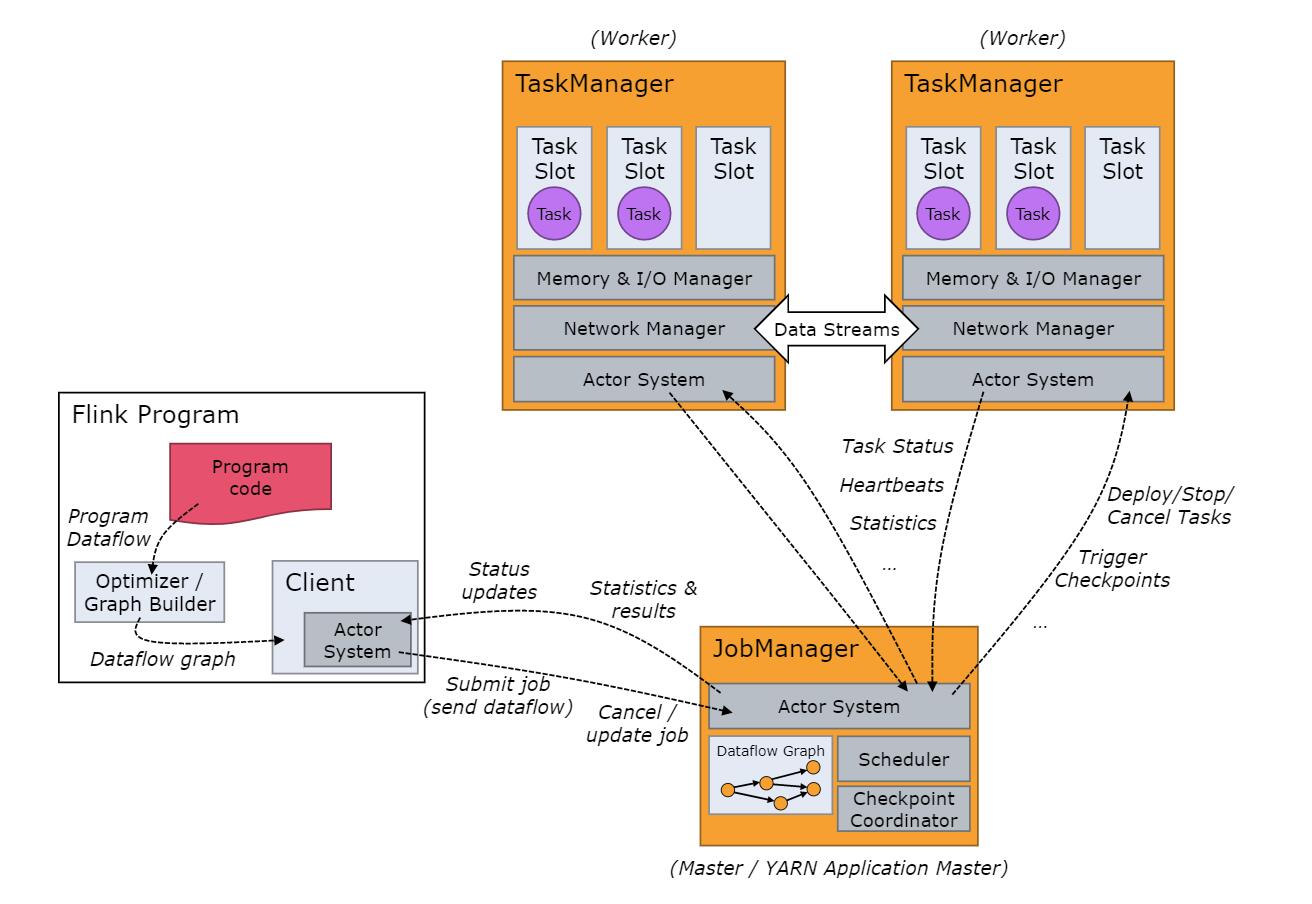
4、运行流程
3.1) 运行时核心角色组成 工作流程图
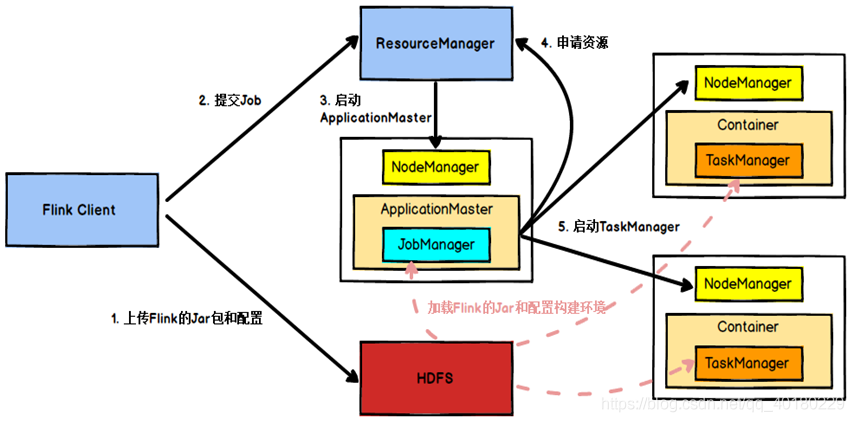
- 3.2)Yarn模式提交任务的工作流程
- 工作流程图

若有收获,就点个赞吧
0 人点赞
