- 库
- 1. Hive 的架构设计与运行流程,及其各模块的主要作用?
- 2.
- Hive 的数据模型组成,及各组成模块的应用场景?
- 3. Hive 支持的文件格式和压缩格式,及其各自的特点?
- 4. Hive 内外表的区分方法,及内外表的差异点?
- 5. Hive 视图如何创建,视图有什么特点,及其应用场景?
- 6、Hive 常用的 12 个命令,及其作用?
- 7、Hive 常用的 10 个系统函数,及其作用?
- 8、请详细描述将一个有结构的文本文件 student.txt 导入到一个 Hive 表当中的步骤,及 其关键字?
- 9、请简述 udf/udaf/udtf 是什么,各自解决的问题,及典型代表应用场景。
- 10、udaf 的实现步骤,及其包含的主要方法,及每个方法要解决的问题,并写代码自实 现聚合函数 max 函数?
- 11、 hive 设置参数的方法有哪些?并列举 8 个常用的参数设置?
- 12、HIVE 数据倾斜的可能原因有哪些?主要解决方法有哪些?
- 13、数据仓库之数据架构设计图,及每个模块的主要作用?
- 14、利用 HiveSQL 语句,创建如下两张表: 创建员工基本信息表(EmployeeInfo),字段包括(员工 ID,员工姓名,员工身份证号, 性别,年龄,所属部门,岗位,入职公司时间,离职公司时间),分区字段为入职公司时间, 其行分隔符为”\n “,字段分隔符为”\t “。其中所属部门包括行政部、财务部、研发部、 教学部,其对应岗位包括行政经理、行政专员、财务经理、财务专员、研发工程师、测试 工程师、实施工程师、讲师、助教、班主任等,时间类型值如:2018-05-10 11:00:00
- 创建员工收入表(IncomeInfo),字段包括(员工 ID,员工姓名,收入金额,收入所属 月份,收入类型,收入薪水的时间),分区字段为发放薪水的时间,其中收入类型包括薪资、 奖金、公司福利、罚款四种情况 ; 时间类型值如:2018-05-10 11:00:00。
- 15、用 HQL 实现,求公司每年的员工费用总支出各是多少,并按年份降序排列?
- 16、用 HQL 实现,求各部门每年的员工费用总支出各是多少,并按年份降序,按部门的 支出升序排列?
- 17、用 HQL 实现,求各部门历史所有员工费用总支出各是多少,按总支出多少排名降序, 遇到值相等情况,不留空位。
- 18、用 HQL 实现,创建并生成员工薪资收入动态变化表,即员工 ID,员工姓名,员 工本月薪资,本月薪资发放时间,员工上月薪资,上月薪资发放时间。分区字段为本 月薪资发放时间。
- 19、用 HQL 实现,薪资涨幅方面,2018 年 5 月份谁的工资涨的最多,谁的涨幅最大
- git—-10个命令,版本控制
- 4个项目
- 分析
库
1. Hive 的架构设计与运行流程,及其各模块的主要作用?
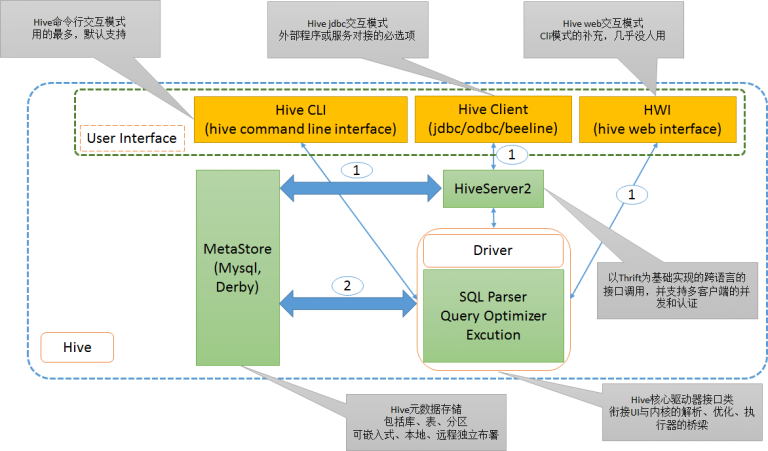
2.
Hive 的数据模型组成,及各组成模块的应用场景?

表—-分区 根据不同分区以文件夹形式存储在hdfs上,多条数据有相同字段值的情况,比如所属分类。
表—-分桶 分桶表是以多个数据文件的形式存储在表数据目录下。数据字段没有重复的情况
表—-分区、分桶 意义在于快速查询。
3. Hive 支持的文件格式和压缩格式,及其各自的特点?
可切割运算
txt方便查看,但无压缩占空间大,传输压力大、
sequence、 kv存储,支持行行和块压缩,查看不方便。
rcfile、加载、查询、空间利用方面都很好,但每方面都不是最高。
orcfile —rcfile文件的升级。加载、查询、空间利用方面都很好,但每方面都不是最高。
loz、可切分 文件越大,优势越明显
bzip、可切分 原生支持 适用于高压缩率
gzip、不可切分 原生支持
snappy 不可切分 map reduce 或是job数据流中间格式
4. Hive 内外表的区分方法,及内外表的差异点?
外部导入的表为外表,元数据被hive管理,数据本身存储在hdfs。删除时只删除元数据,数据本身不被删除。
hive自生成的表为内表,元数据和数据本身都被hive管理。删除时元数据和数据本身都被删除。
5. Hive 视图如何创建,视图有什么特点,及其应用场景?
create view view_name select id,username from student;
视图是一张虚表。本身不存储数据,只存储数据关系,使用时再通过关系查找数据。
hive中查询变得很长时,可以通过视图分割查询语句。
可通过视图限制基于条件过滤
6、Hive 常用的 12 个命令,及其作用?
hive
show databases;
use databases_name;
show tables;
desc table_name;
show create table table_name;
create table student(id,int usernam,string);
load data inpath ‘$path_hdfs’ overwrite into table ‘$table’
select * from table limit 10;
insert into table_name(id,username) values(1,xuyunfeng);
insert overwrite table student select id,username from people where username=’xuyunfeng’;
drop table student;
7、Hive 常用的 10 个系统函数,及其作用?
desc function split;
show functions;
count
if
case…when..
coalesce(null,null,2)
split
explode
lateral view
size
year
month
trim
length
8、请详细描述将一个有结构的文本文件 student.txt 导入到一个 Hive 表当中的步骤,及 其关键字?
rz -bye 将文件加载到linux上
hdfs dfs -put -f student.txt /user/xuyunfeng/ 将文件上传到hdfs
load data path ‘/user/xuyunfeng/student.txt’ overwrite into table table_name 将hdfs的文件数据导入到表中
9、请简述 udf/udaf/udtf 是什么,各自解决的问题,及典型代表应用场景。
是自定义函数。
udf 1:1 输入一条,输出一条。 split、substring
udaf n:1 输入n条,输出1条 count、max、min
udtf 1:n 输入1条,输出n条 应用较少,一般用udaf+lateral view explode代替
10、udaf 的实现步骤,及其包含的主要方法,及每个方法要解决的问题,并写代码自实 现聚合函数 max 函数?
实现步骤: 自定义一个java类,继承udaf类。内部定义一个静态类,实现UDAFEvaluator接口。
实现init,iterate,terminatePartial,merge,terminate 共5个方法。
init—-初始化Map相关变量
iterate—-迭代处理同一组排好序的记录
terminatePartial—-做map端数据的汇总
merge—-逐条处理reduce端 terminatePartial端返回的数据
terminate—-对merge完成后的结果做最后的业务处理
xxx
iterate和merge返回值为boolean terminatePartial与terminate返回值为int
11、 hive 设置参数的方法有哪些?并列举 8 个常用的参数设置?
hive -e
12、HIVE 数据倾斜的可能原因有哪些?主要解决方法有哪些?
假倾斜
数据格式不对。 —更改数据格式
sql语句编写不合理 —优化代码
真倾斜
如vip会员数据倒卖问题。 分而治之。将倾斜与正常的数据分类,然后分别计算。
硬件机器本身配置不均衡。 —将机器配置均衡。
13、数据仓库之数据架构设计图,及每个模块的主要作用?
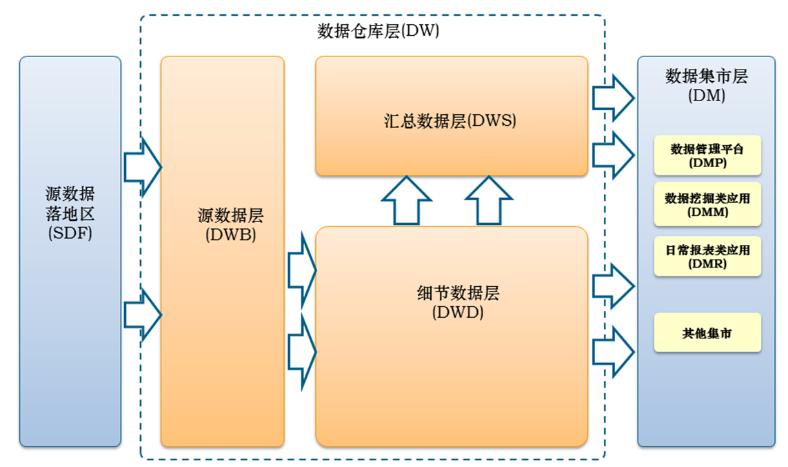
源数据落地区—-放众多各种源数据。
源数据层——放生产系统的原始数据,主要满足未来大量不可预知需求。
细节数据层——按主题进行组织、保留历史、数据粒度与生产系统一致。
汇总数据层—-为预见的多个应用提供数据。
数据集市层——为外部提供具体的功能
14、利用 HiveSQL 语句,创建如下两张表: 创建员工基本信息表(EmployeeInfo),字段包括(员工 ID,员工姓名,员工身份证号, 性别,年龄,所属部门,岗位,入职公司时间,离职公司时间),分区字段为入职公司时间, 其行分隔符为”\n “,字段分隔符为”\t “。其中所属部门包括行政部、财务部、研发部、 教学部,其对应岗位包括行政经理、行政专员、财务经理、财务专员、研发工程师、测试 工程师、实施工程师、讲师、助教、班主任等,时间类型值如:2018-05-10 11:00:00
创建员工收入表(IncomeInfo),字段包括(员工 ID,员工姓名,收入金额,收入所属 月份,收入类型,收入薪水的时间),分区字段为发放薪水的时间,其中收入类型包括薪资、 奖金、公司福利、罚款四种情况 ; 时间类型值如:2018-05-10 11:00:00。
15、用 HQL 实现,求公司每年的员工费用总支出各是多少,并按年份降序排列?
select subString(in_month,1,4) as yeard,sum(incomein)
from incomeinfo group by(subString(in_month,1,4))
order by yeard desc;
—小结 order by,group by,partition by用法时机,sum不一定非要和over连用
既求明细,又求汇总用分析函数,如果不是,用一般sql即可。 subString(字段,1,4)
16、用 HQL 实现,求各部门每年的员工费用总支出各是多少,并按年份降序,按部门的 支出升序排列?
关联两个表 select ebase.id,ebase.username em_department,incomein,subString(in_month,1,4) from employeeinfo as ebase inner join incomeinfo as ecome on ebase.id=ecome.id;
按部门求每年员工支出总费用select em_department,yeard,sum(incomein) as total from (
select ebase.id,em_department,incomein,subString(in_month,1,4) as yeard
from employeeinfo as ebase inner join incomeinfo as ecome on ebase.id=ecome.id
) base group by em_department,yeard;
按年份降序 同时 按部门升序select em_department,yeard,sum(incomein) as total from (select ebase.id,em_department,incomein,subString(in_month,1,4) as yeard from employeeinfo as ebase inner join incomeinfo as ecome on ebase.id=ecome.id
) base group by em_department,yeard order by yeard desc,total asc;
小结:——注意语句前面的tab —-各部门每年 —group department,yeard
没有明细,只有汇总,常规sql就可搞定
按年份降序,按部门支出升序 order by yeard desc,total asc
17、用 HQL 实现,求各部门历史所有员工费用总支出各是多少,按总支出多少排名降序, 遇到值相等情况,不留空位。
dense_rank —如果字段是字符串,位数不同时,结果跟预期可能不相符
select *,dense_rank() over(order by total desc) as TopN from (select em_department,yeard,sum(incomein) as total from (
select ebase.id,em_department,incomein,subString(in_month,1,4) as yeard
from employeeinfo as ebase inner join incomeinfo as ecome on ebase.id=ecome.id
) base group by em_department,yeard) as test;
select ebase.id,ebase.username,em_department,incomein,in_month,dense_rank() over(order by incomein desc)as topN from employeeinfo as ebase inner join incomeinfo as ecome on ebase.id=ecome.id;
18、用 HQL 实现,创建并生成员工薪资收入动态变化表,即员工 ID,员工姓名,员 工本月薪资,本月薪资发放时间,员工上月薪资,上月薪资发放时间。分区字段为本 月薪资发放时间。
题目分析:
1) 创建一个与上述字段匹配的新表-income_dynamic
2) 注意用数据分析函数来为该表填充数据
考点分析:
1)对Lag,Lead函数的使用
考官意图:
1) 对数据分析函数复杂使用的考查
答题技巧:

19、用 HQL 实现,薪资涨幅方面,2018 年 5 月份谁的工资涨的最多,谁的涨幅最大
考点: 常规SQL、数据分析函数当中的dense_rank,lag(字段,往上翻,默认值)
题目分析:
1) 求谁涨的绝对值金额最多
2) 求谁涨的幅度百分度最大
考点分析:
1)rank/dense_rank/row_number的使用上
考官意图:
1)对数据分析函数的综合运用考查
答题技巧:

git—-10个命令,版本控制
查看所有操作记录 git reflog
版本回退, git reset —hard HEAD^ git reset —hard HEAD@{1} 回退到指定版本
撤销修改 应用场景
1、工作空间已修改 2、已提交到缓存区 3、工作空间已修改,已提交缓存区,已添加到版本库
4、rm -rf误删除某文件的还原 5、git rm误删git文件的还原,并没有commit提交
10命令 —
1、git init 2、git add 3、git commit -m 4、git push 5、git pull
6、git diff 7、git reflog 8、git reset 9、git branch branchName 10、git checkout branchName
11、git checkout -b branchname 12、git branch -d 13、git branch -D
4个项目
一 7、导出结果 —-导出到hive上, hive上再导本地上,本地sz下载到。INSERT OVERWRITE DIRECTORY ‘/user/xuyunfeng/tags_rank.txt’ SELECT * FROM appResult;
二 通过java web实现 数据抽取,存入到hdfs表中
三 数据分析
(基础分析题)各频道评论量排行,求top5————查频道,关联查出需要字段,group by,dense_rank与order by,where条件过滤
(综合分析题)各频道活跃度排行 关联表,关联查询出所有候选因子,基于计算口径和公式进行加权求和,对求和结果排名,输出 select remark, (content_count1.0 + user_count1.1 + reposts_count2+comment_count1.5) as score from (
(综合分析题)各频道的博主的行为特征分析之每天的活跃时间段分析
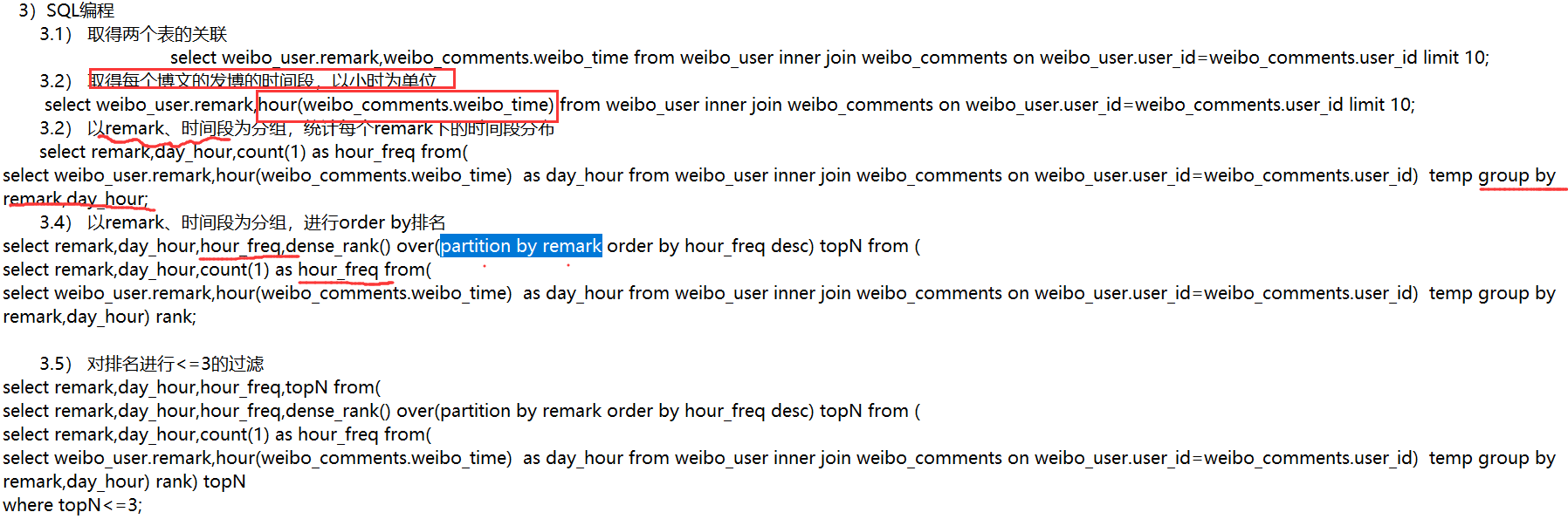
四 微博舆情
微博舆情—流程化。shell脚本,黑白名单过滤。将数据装载到mysql上。
批量解压 ls | xargs -n 1 | unzip -o -d ../tag_cvs_dir
分析

若有收获,就点个赞吧
0 人点赞
