谷歌三驾马车 gfs mapreduce bigTable(hbase)
1 Hbase 简介
命令行一般就测试一下用,更多时用api操作
1.1 Hbase定义

分布式:可搭集群,, 可扩展:上下限调
hdfs不支持随机写。 hbase实现了hdfs的随机写(其实就是将数据下载后修改再重新上传)。
表 增删改(改是重点)查
1.2 Hbase 数据模型
1.2.1 Hbase逻辑结构


rowKey 按字典排,有>无
实际信息都是放到hdfs中存储。 这边store存储实际信息。
Region 表的切片内容
1.2.2 Hbase 物理存储结构
 学hbase框架时,时间很重要~ 主要根据时间戳进行一些操作、
学hbase框架时,时间很重要~ 主要根据时间戳进行一些操作、
删除时,删除的时间戳要大于/等于 要删除数据的最新时间戳
1.2.3 数据模型





缺少 time Stamp时,不同时间戳 单元格中的内容cell 是不同的
hbase拆到最小是cell
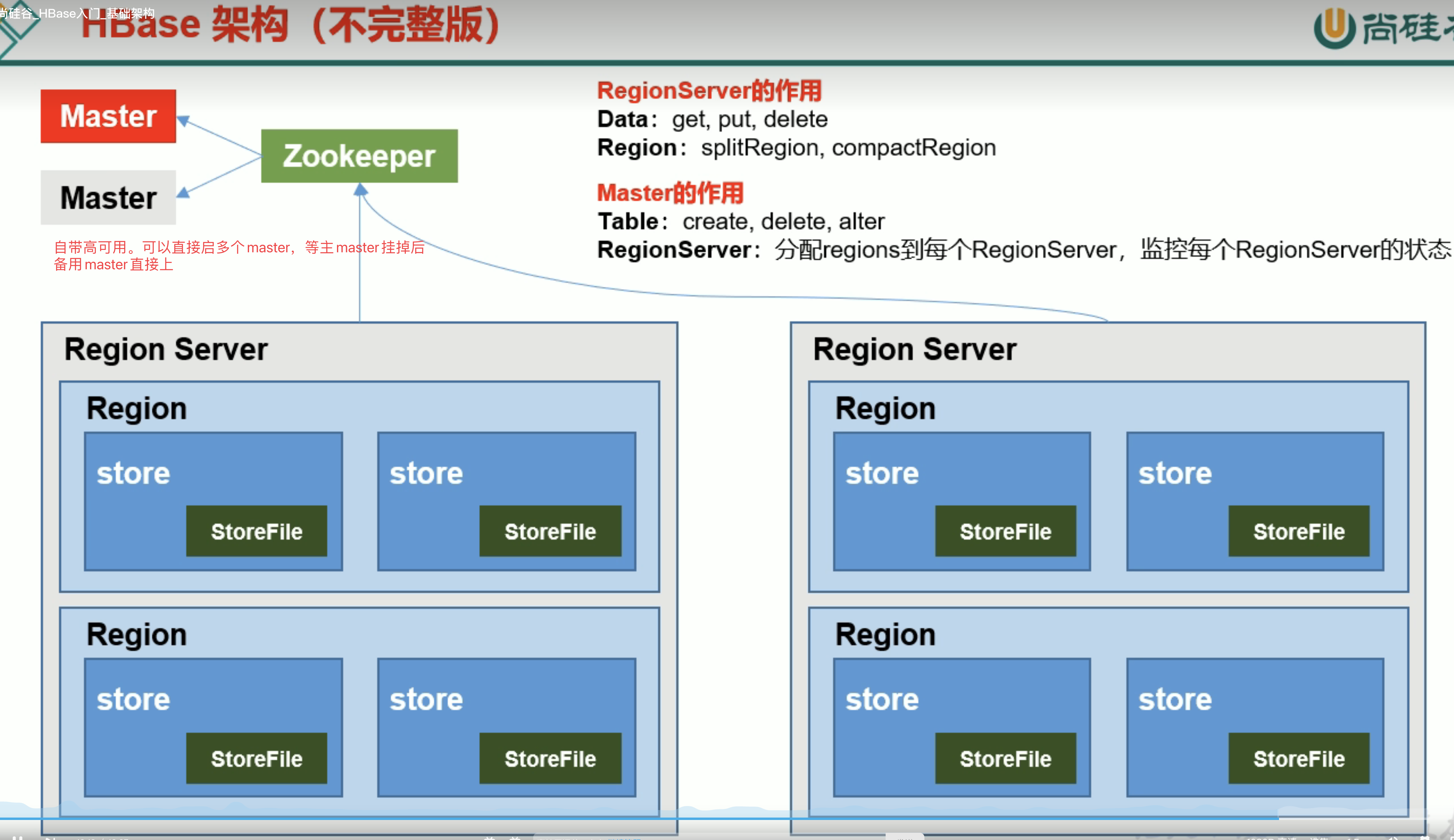
1.3 HBase基本架构


2 Hbase 快速入门
测试用的较多,生产环境应用比较少
2.1 Hbase 安装部署
注:hbase配置文档中不会出现大写。
哒哒哒,需要注意会有 ReginServer 要单独启动。
2.2 Hbase shell操作 DDL DML
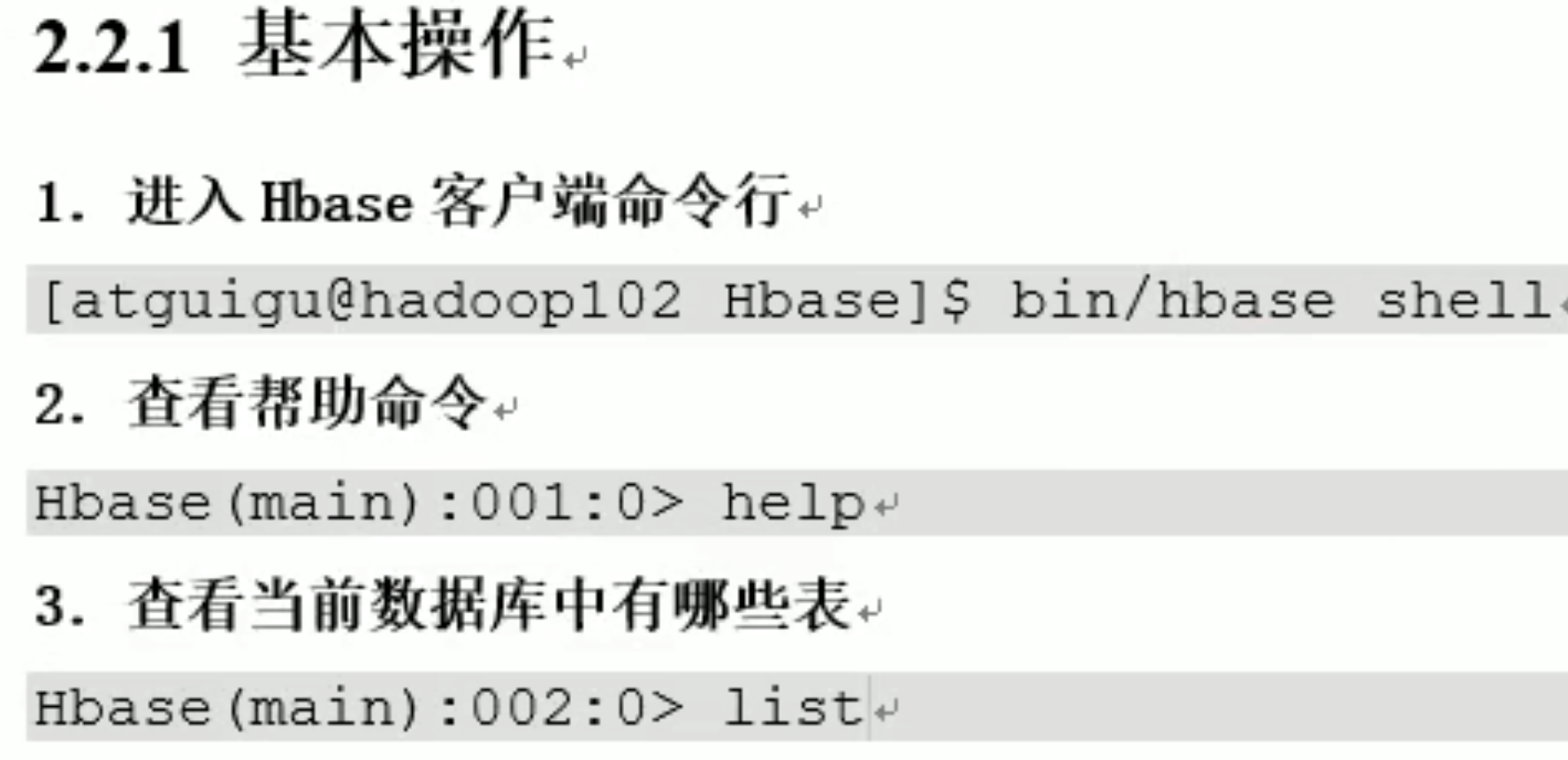

如果哪个常用命令不会写了,直接 输出,然后回车


删除命名空间时,要先删除命名空间中的表
scan(左闭右开)、get、put、

增删改查都是根据时间戳进行

versions 几个版本—-是hbase将来会为你存几个版本~
3 HBase 进阶 重点!
hlog与wal意思相同
3.1 架构详细图

Hlog 预写入日志
HMaster (表DDL)
RegionServer(数据DML) 维护多个Region
同一个HRegion的不同store对应不同的列族
Store存储是相互分离的。 内容存在两个位置1 Mem store(内存中) 2 StoreFile(格式是HFile 磁盘中)
Mem store中内容可以刷写出1到多个storeFile。 storeFile最终要写如到hdfs的datanode,最终磁盘
3.2 写数据流程
最早还会有个-root- 表。先请求 -root-表再请求 meta表。当时主要担心meta表会做切分,但经过实际生产长时间验证,meta几乎是不会做切分的,于是后来就去掉了-root-表。
Hbase 读比写要慢

1个源数据对应的是1个region
先写到wal,再写到内存。
源码层面:构建时也是先构建wal,当wal写入成功后 内存才会成功,如果wal不成功,内存中内容清空。

hbase存储特点:稀疏性。
3.3 MemStore Flush流程
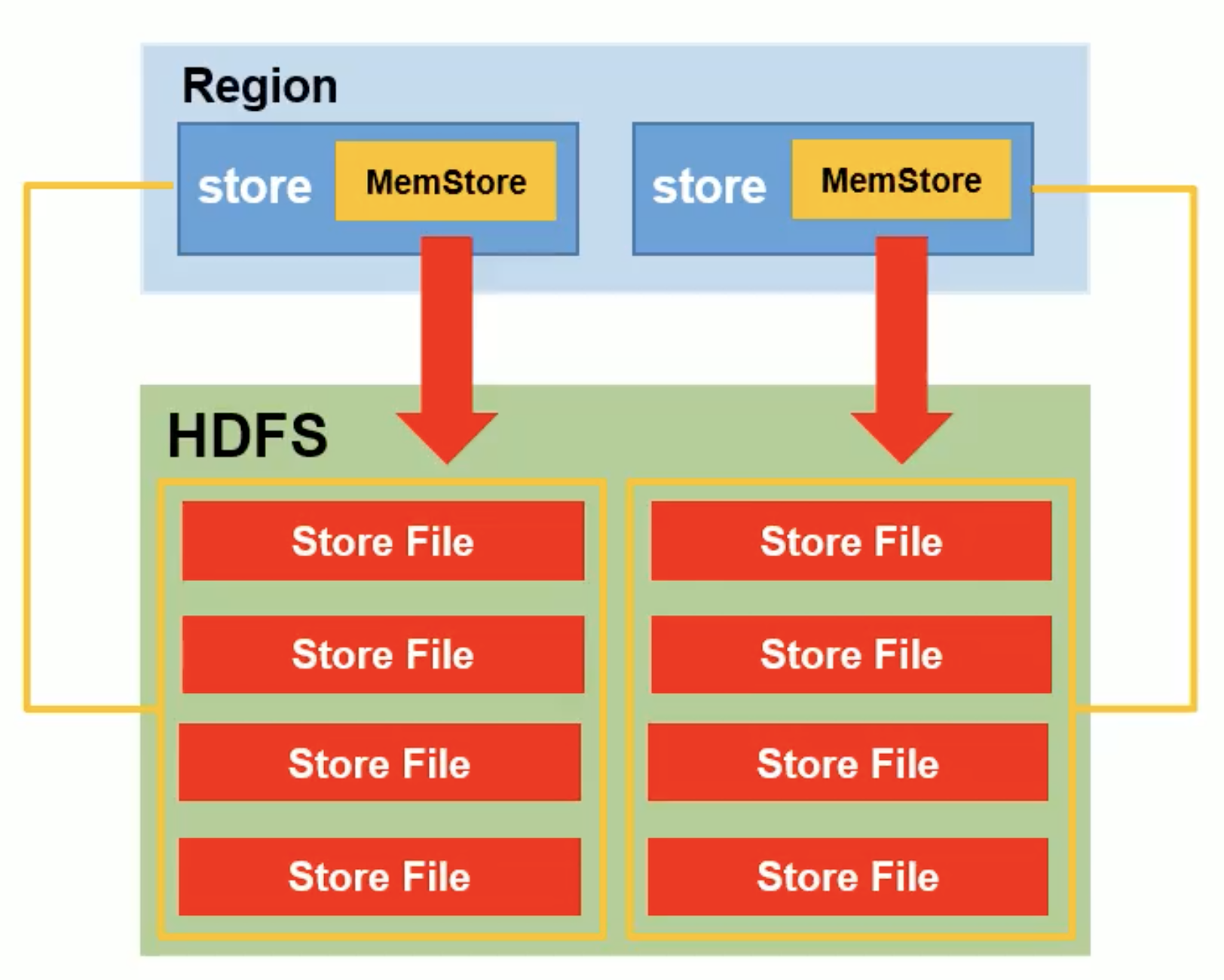

哒哒哒,下面还会有。应用时去搜索就好
在配置文件中可以配置的。 配置时,搜 flush会快速一点

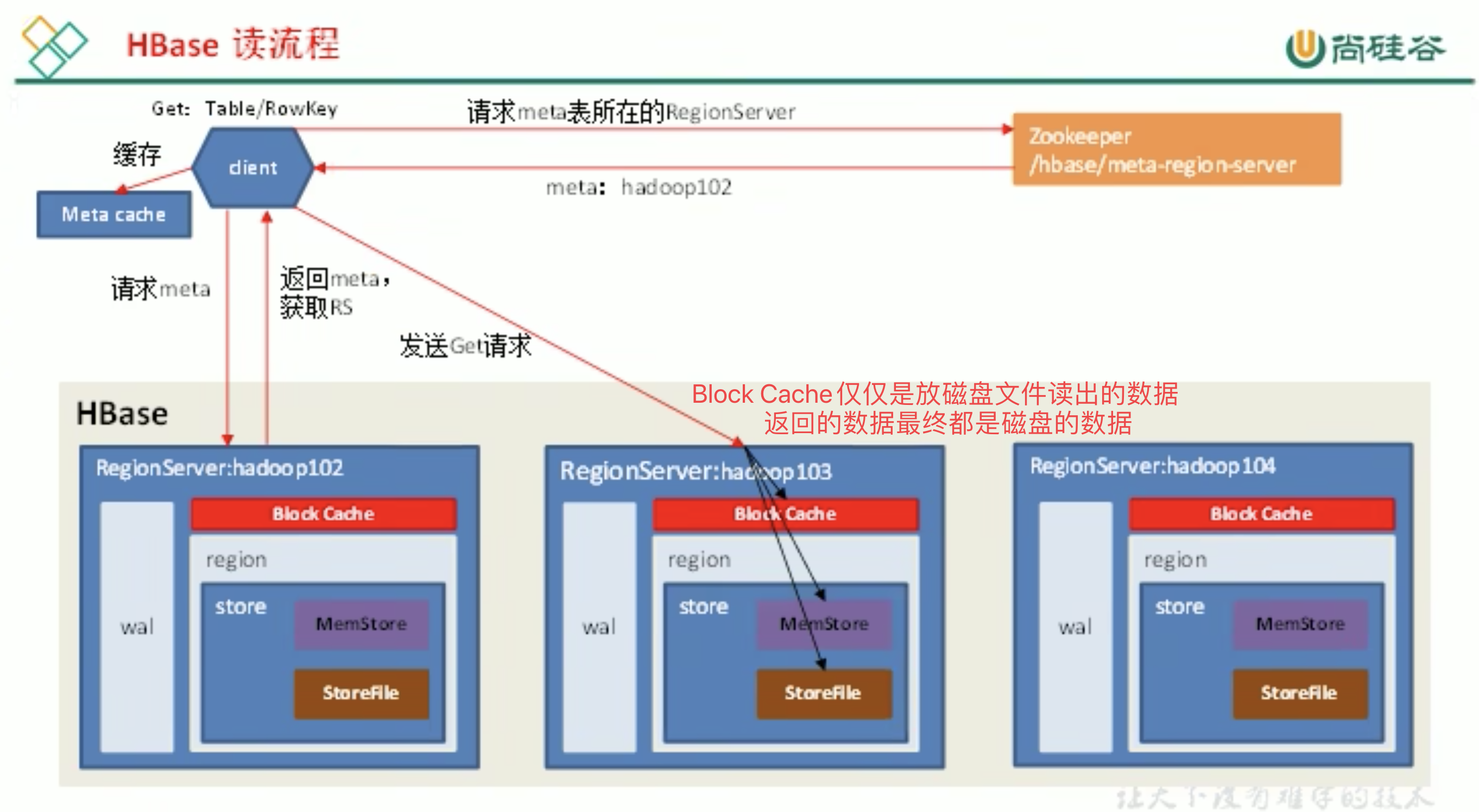
3.4 读流程
元数据
LRU cache 最近最少使用
查看解析HFile 工具及使用方式
读比写慢。

3.5 StoreFile Compaction


读写流程是可以不需要master的,但如果没有master 集群不健康
数据真正删除时间 看博客
视频22
flush针对内存
触发删除数据的情况
- flush 或 comcat (major)
- flush 可删除在同一个内存中的(已经push了/已标记的)数据,不可删除的是跨越多个文件的数据(flush删除的是必须与flush在同一个文件中的数据)
- comcat(major) 将内存中内容都放一起了,见面后知道删不删除
- 删除标记会被删,在major见面时删除,也将其他该删除的内容一并删除
- 涉及多个版本时,会保留最大的版本
3.6 Region Split


自动切分会带来数据的热点问题; 一般建表的时候预分区—-防止数据倾斜,如3w数据建3个分区,第一个分区1~1w,第二个分区2~2w,第三个分区3~3w
官网建议使用列族时,使用一个列族; 防止生成太多小文件(flush刷写时,全局[所有列族]都刷写,不论文件大小)。
生产环境中可以使用多个,要自己分好(设计时几个文件尽量保持内容增长速度相同)。
4 Hbase API 重点! 这部分讲到的细节比较多 实操中
这个看官网好
视频P31 总结很nice
视频P37 总结
先学怎么用,再看原理,再看代码;
HbaseAPI
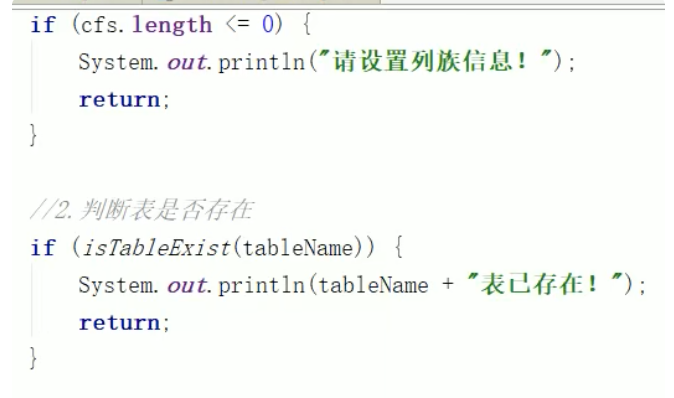
DDL 判断表是否存在
共用方法,可以提出来/放静态代码块中
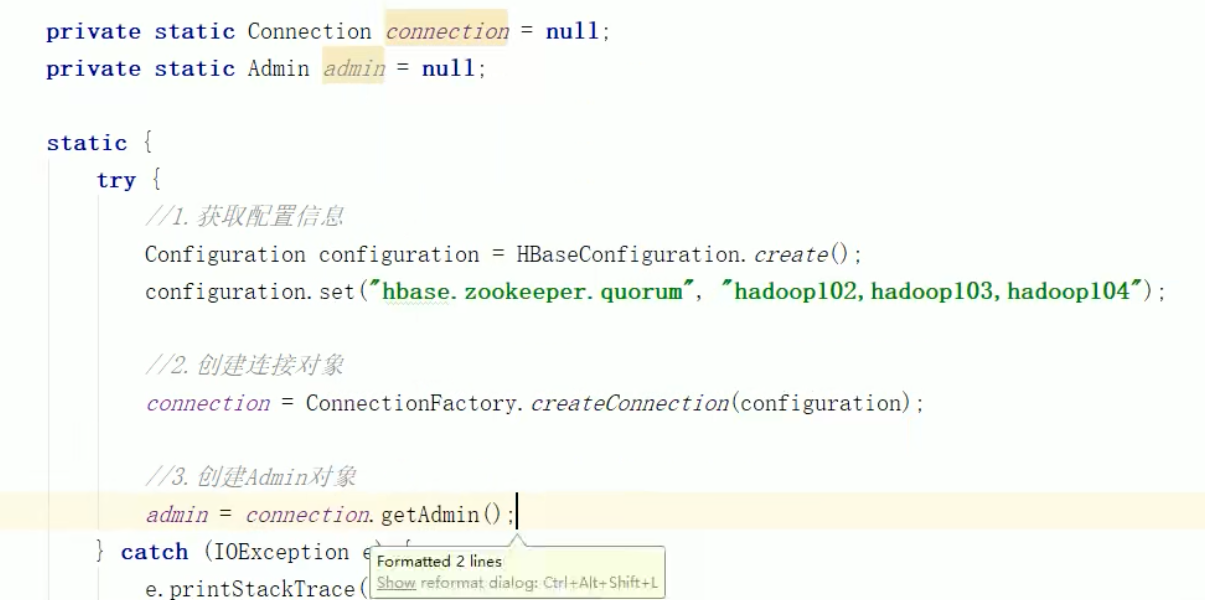

可以在最后关闭,这个公共的对象都用完后再关(main中关闭 也是看作用域).
DDL 创建表
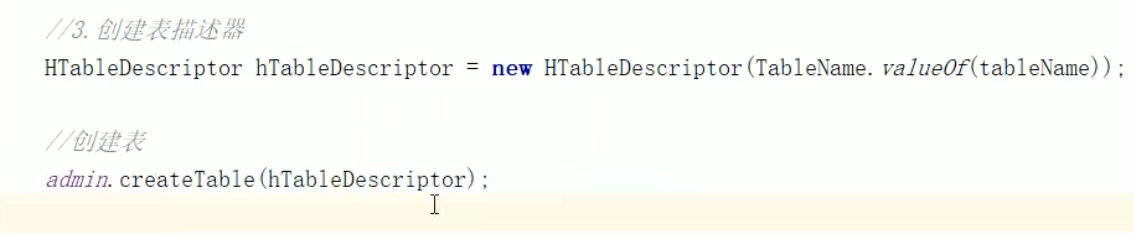
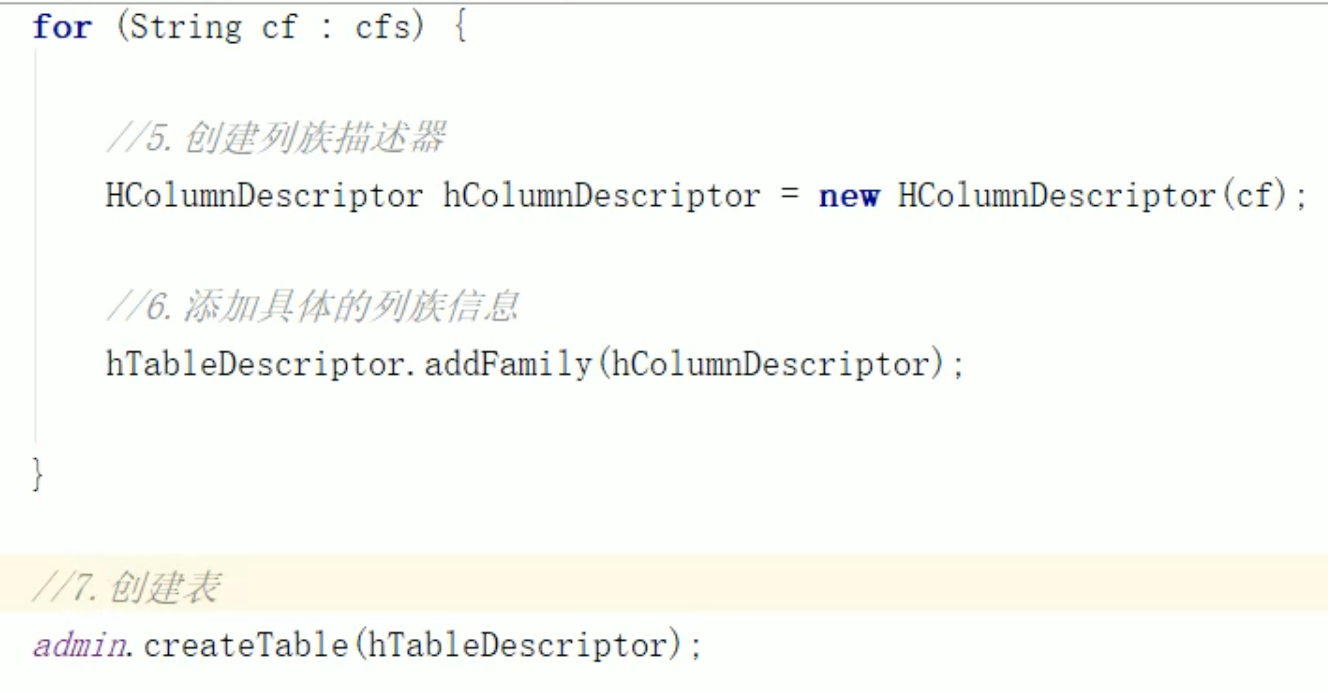
DDL 创建命名空间
DDL 删除表
DML 插入数据
DML 查数据(get)
get返回的数据是 list集合/单个的某个值。
查可以指定到 列、列族、rowkey 都可
DML 查数据(scan)
scan返回的数据是一个新的容器类,类似set集合。但不是set集合,因为hbase扫描表 会扫描到很多内容,如果将扫描到的内容一个个放入集合中,会消耗大量内存客户端会崩掉,一般客户端也不会向set中存放太大数据,所以使用一个新容器类。 扫描时不断向该容器类中放内容,类似一个iterator过程。
ResultScanner
DML 删除数据
视频31
删除时,尽量使用 加s的这种方式。

知其然,知其所以然。
p35 17分钟
建议建表时,指定单个版本。
大数据中框架最难的点是数据一致性问题。它里面很多都是在做判断、做校验
两军问题,拜占廷将军问题 可以了解了解
视频P37 总结
MapReduce

官方 HBase-MapReduce
只要能连接hbase,可分析(的框架) 就都可做为hbase的分析引擎。
word文档格式容易出现问题,最好先放到别的位置看一看有没有多空格、多制表符。
本地==>hbase hbase==>本地 本地<==>Hbase 可以通过mapReduce引擎 就是之前接触到的。
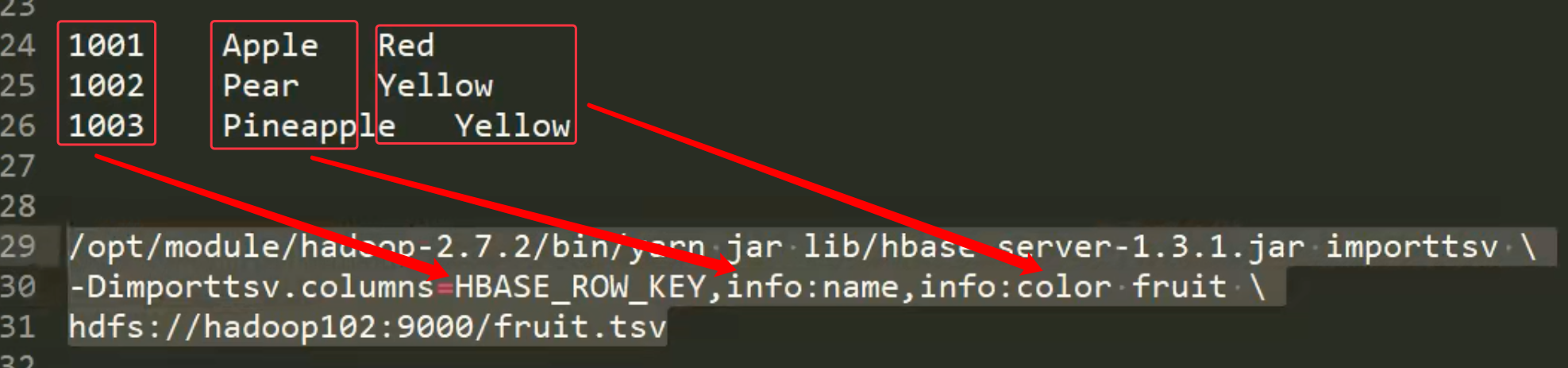
命令行中 \ 是换行的意思。命令行中没有回车,回车就代表执行命令了。 如果去掉上面的\,可能会报错也可能会直接执行。写成多行方便阅读。
官方是读hdfs文件放到hbase表中
自定义HBase-MapReduce
就是做读写。没有复杂逻辑。
读hbase表,将内容写到另外一张hbase表中,做一些数据的过滤
注意:版本不同可能会有细微差别。
避免reduce产生数据倾斜,可以在map端先做一些事情。
结果驱动过程,以结果为导向。挺强~
与Hive的集成
本质:hive是分析框架,hbase是存储框架
HBase 与 Hive 的对比


Hbase与Hive集成使用
P43 P44 兼容性问题; 可以重新编译 ==> 将源码(hive)撸下来放到hbase中重新编译打包。 让环境发生一点事情;
hive中插入,hbase中查看到; hbase中插入,hive中查看到。
API 回顾
api的删除;
mapReduce;
与hive集成; 兼容不兼容; cdh是解决兼容性的。 cdh会略慢于正常版本的;建立关联表。放数据时hive有类型,hbase没有类型
5 Hbase 优化
5.1 高可用
的的的;节点挂了还可用-。-
RegionServer挂掉了,但master活着;master将RegionServer给其他去管理
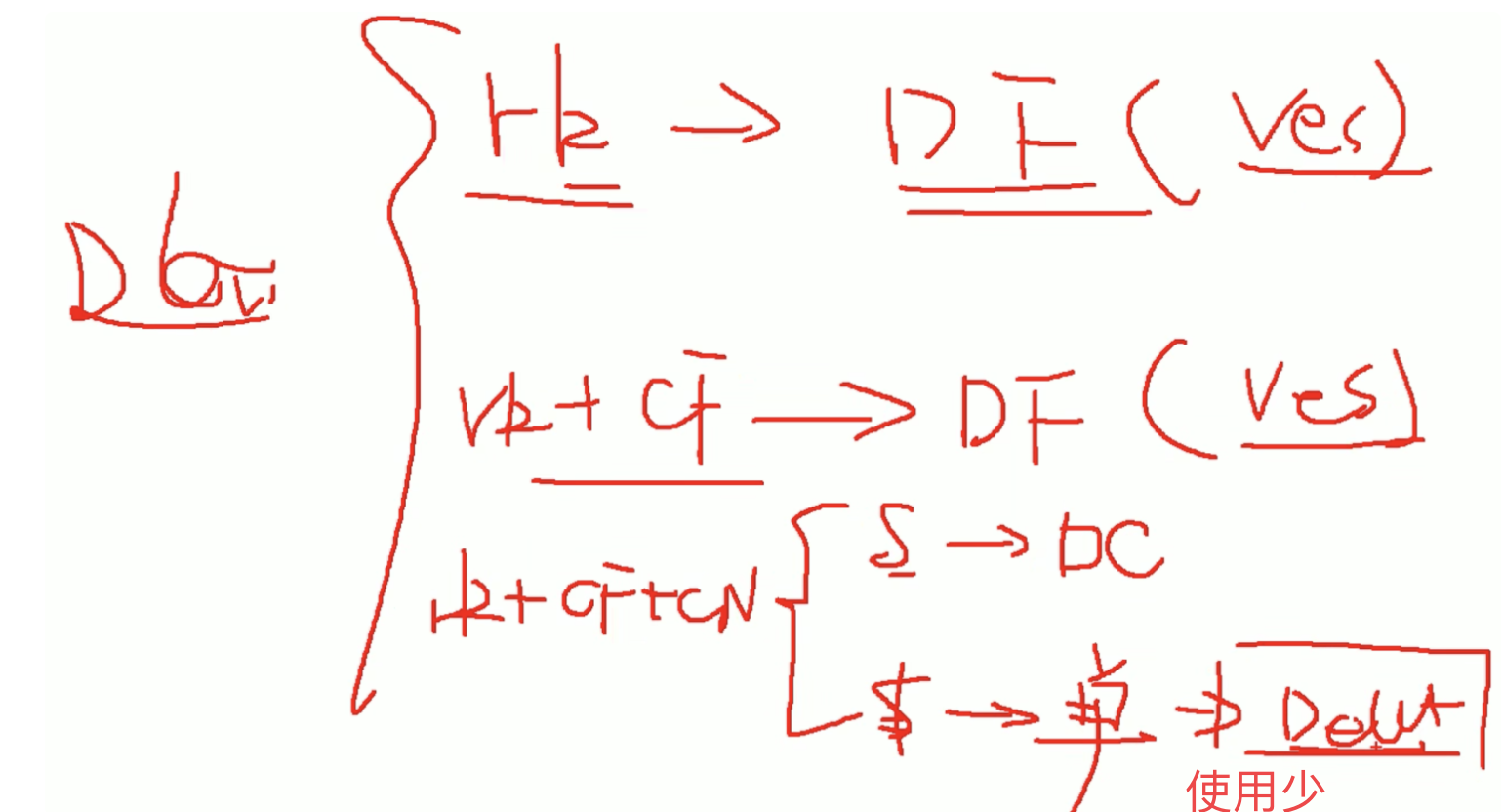
5.2 预分区 重点 7 预分区/设计,2读写,1 其他
P48
预分区决定要素:1、未来发展数据量,2、机器规模
生产模式下一般1个机器最大放2~3个Region;
如果未来发展数据量超出预估很多很多,一般会换一个新的表把数据导出去。
如果某个rowkey设计的不合理,可以split切一下动态扩展一两个;而如果是想从5个扩展到10、20个直接重新建表导入比较好。
id会补成统一位数,方便管理的

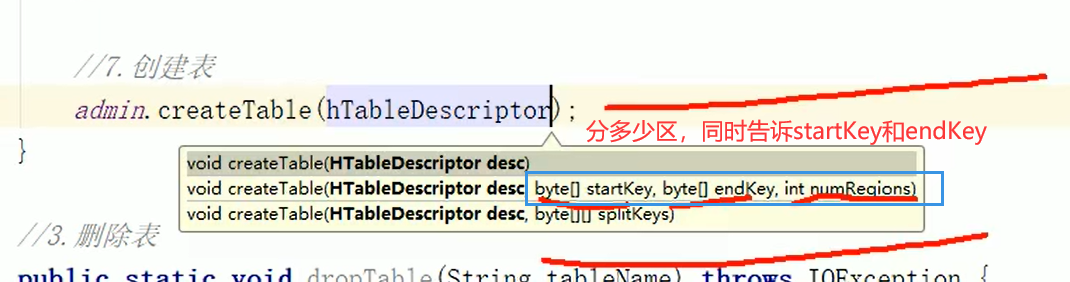 图中这两种用的都少
图中这两种用的都少
一些。
5.3 RowKey 设计 重点 7 预分区/设计,2读写,1 其他 经常一块读的数据放到一个Region中且最好放在一起,所以也要考虑集中性这方面是考虑业务性,业务决定将来什么数据在一起读。
经常一块读的数据放到一个Region中且最好放在一起,所以也要考虑集中性这方面是考虑业务性,业务决定将来什么数据在一起读。
从原则性
- 散列性:尽量均匀分布在多个分区中;
- 唯一性
- 长度规则 生产环境一般是 70~100位
如果只有一个表,没有散列性可言;设计时主要还是考虑散列性;另外两个比较简单。
散列最好的方式还是轮询
P50
5.4 内存优化

5.5 基础优化

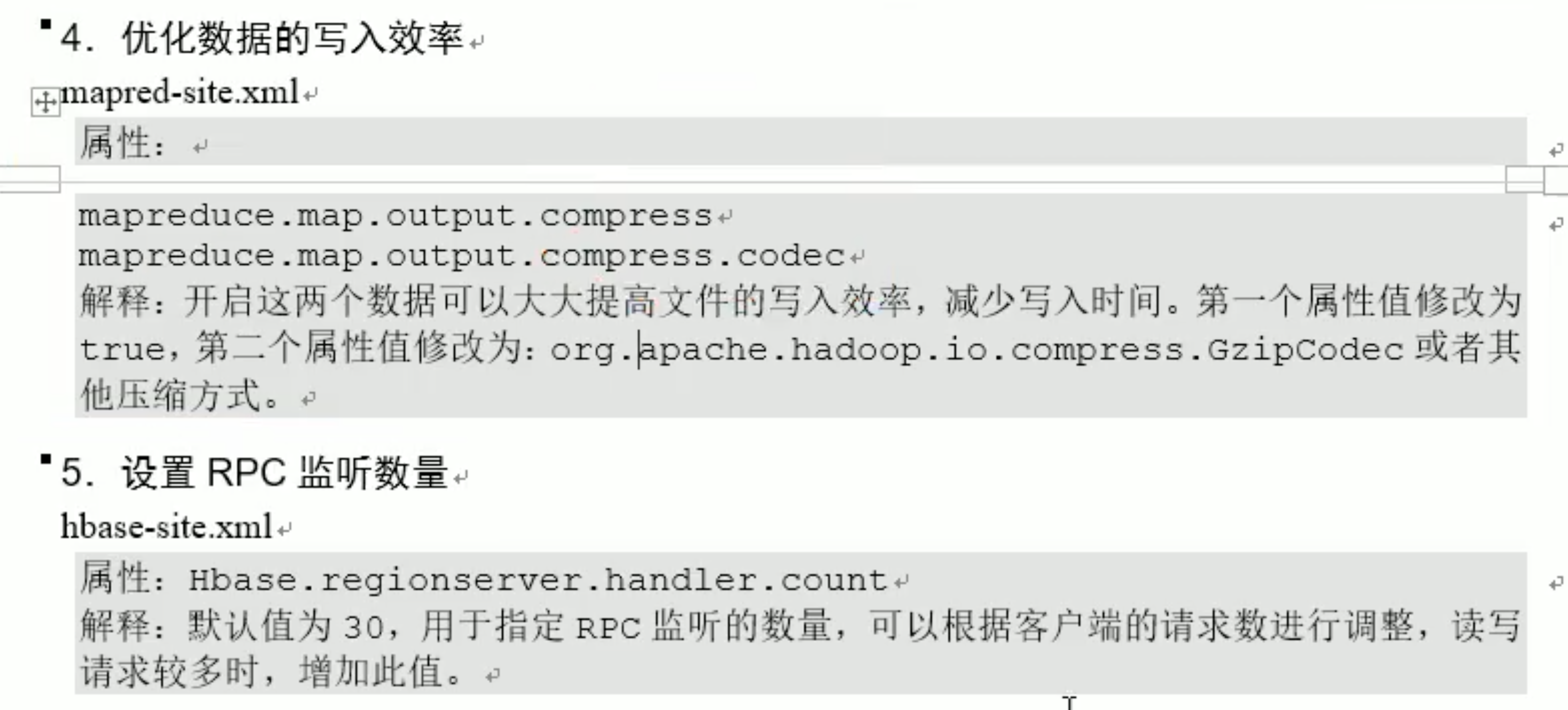


预分区和rowKey设计是最重要的; 前期服务端设计的好,可以对客户端进行微调让性能更好;但如果服务端设计的差,调客户端意义不大。
6 Hbase 实战之谷粒微博
P53 4

若有收获,就点个赞吧
0 人点赞
