舆情项目数据处理流程
1.上传到linux系统,zip格式*
2.解压,上传到hdfs,csv格式*
3.hive创建表,并导入数据,在weibo_origin中*
4.去掉每天的第一行,转入weibo_product中*
5.编写分词UDF,将分词结果导入weibo_seg_result中*
6.无过滤生成wc排序表V0,存入weibo_seg_wc中 * (V0结果,有单字,符号,各种词性的词)
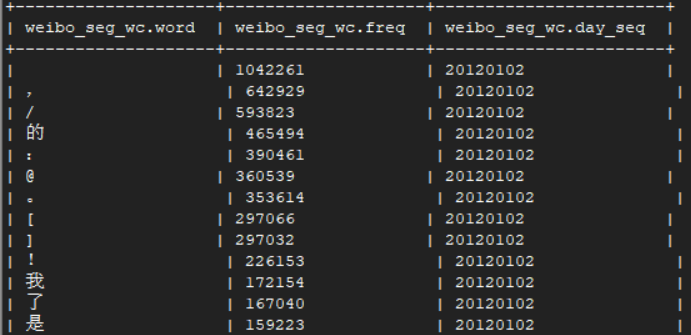
6.1.按词长度过滤生成wc排序表,存入weibo_seg_wc中 * (V1结果,无单字,符号,但是有英文单词与各种词性的词)
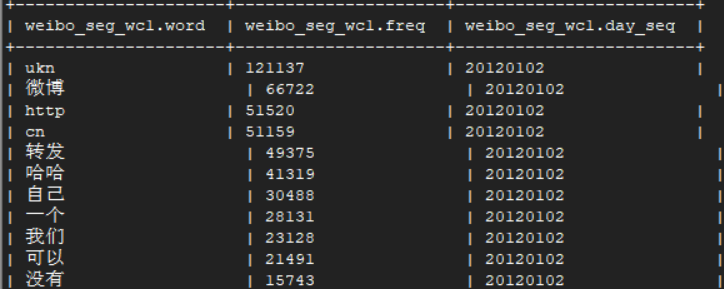
5.2.修改UDF加入按词性过滤(词性1),将分词结果导入weibo_seg_result中
6.2.按词长度过滤生成wc排序表,存入weibo_seg_wc中 (V2结果,无单字,符号,有规定词性1的词)
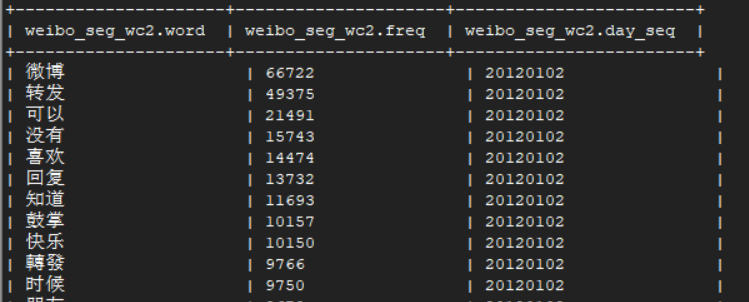
5.3.修改UDF加入按词性过滤(词性2),将分词结果导入weibo_seg_result中
6.3.按词长度过滤生成wc排序表,存入weibo_seg_wc中 (V3结果,无单字,符号,有规定词性2的词)
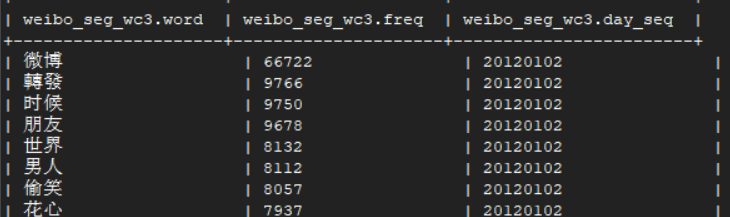
7.编写黑名单txt文件,创建停用词表weibo_stopwords并导入
6.4.按词长度和停用词表过滤生成wc排序表,存入weibo_seg_wc中 (V4结果,无单字,符号,有规定词性2的词,并排除停用词表中的词)

若有收获,就点个赞吧
0 人点赞
