一、 分布式文件系统 HDFS 特点
高容错高可用性:文件存储副本/备份机制、坏了备份上。
流式数据访问:按顺序读写、批量处理
弹性存储,支持大规模数据集:需要处理数据变多(双11)就加机器;变少就减机器
简单一致模型:初始化时一次修改,之后没问题就不支持修改,想修改再尾部追加。
移动计算而非移动数据:数据量大,不好移动。移动计算模式更方便。
适合大数据,不适合很多小文件中数据。不适合更改。 不适合低延时数据访问
二、 HDFS 架构设计
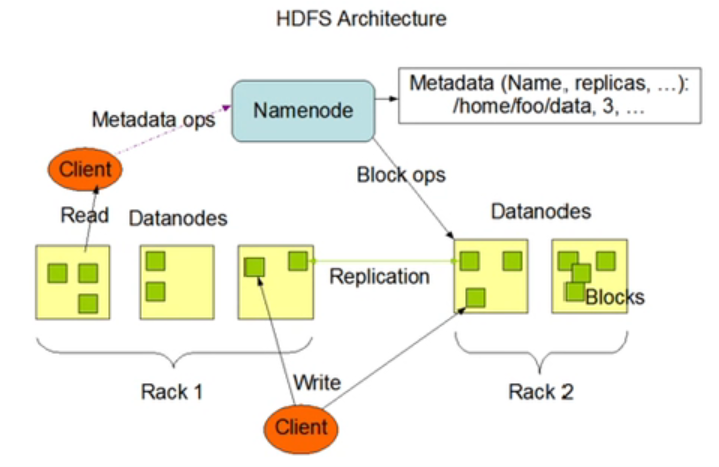
HDFS(Hadoop Distributed File System )Hadoop 分布式文件系统
HDFS主从式结构,NameNode主, 很多DataNode从
HDFS 组件角色 NameNode DataNode Client
NameNode—-管理者 管理元数据(内存),管理NameSpace(文件系统命名空间)。 有备份,出错备份上
元数据文件:fsimage,edits 集群重启后,重新加载这两个文件。SecondaryNameNode 辅助 NameNode 进行管理。
DataNode—-具体干事情,存具体数据。 接收NameNode指令,对数据块操作。通过心跳机制定期对NameNode反馈结果。
Client—-用户利用Client方便与NameNode、DataNode交互。
流程:Client——>NameNode——>DataNode,DataNode干活——>反馈给DataNode
三、 HDFS 高可靠性措施
冗余备份:有备份文件
跨机架副本存放:1个block块有3个文件—-同一机架上2个,外加一个存储在不同机架上。
心跳检测:DataNode定时向NameNode发送心跳包,如果没发,就是有意外了,备份顶上。
数据完整性检测 :取数据时,会将数据与存储时对比,看是否完整。
安全模式:HDFS启动时,进去安全模式,不允许写操作。此时NameNode接收所有DataNode节点报告,检查没问题后自动退出安全模式
核心文件备份:备份(NameNode)印象文件,事务日志内容。
空间回收:删除掉的文件先放到/trash中,6小时内可找到。
四 读写原理
写数据原理
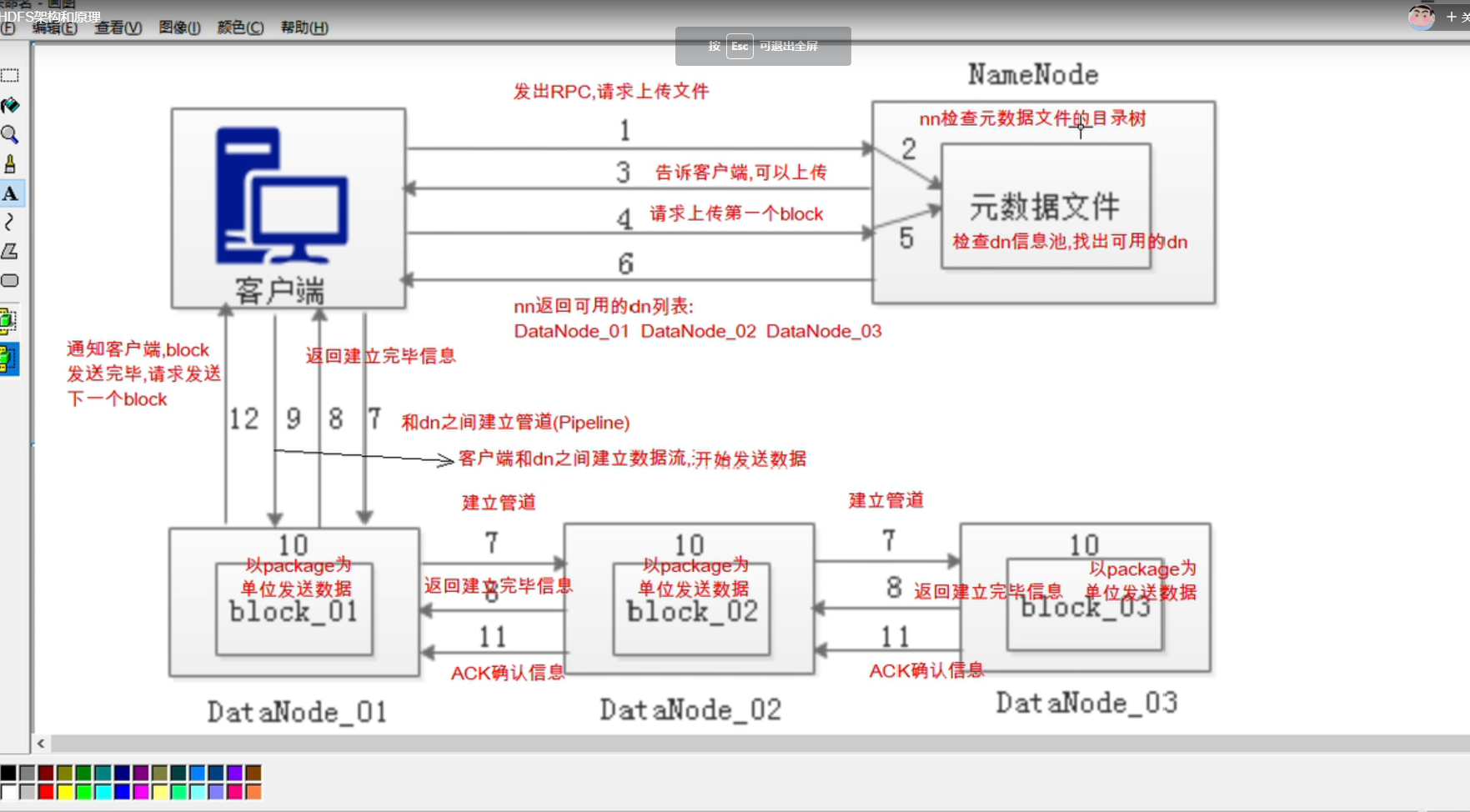
第 10 步:发送 block 时,以 package 为单位,一个 package 大小是 64kb
第 11 步:确认发送成功
第 12 步:block 是一个一个发的
读数据原理
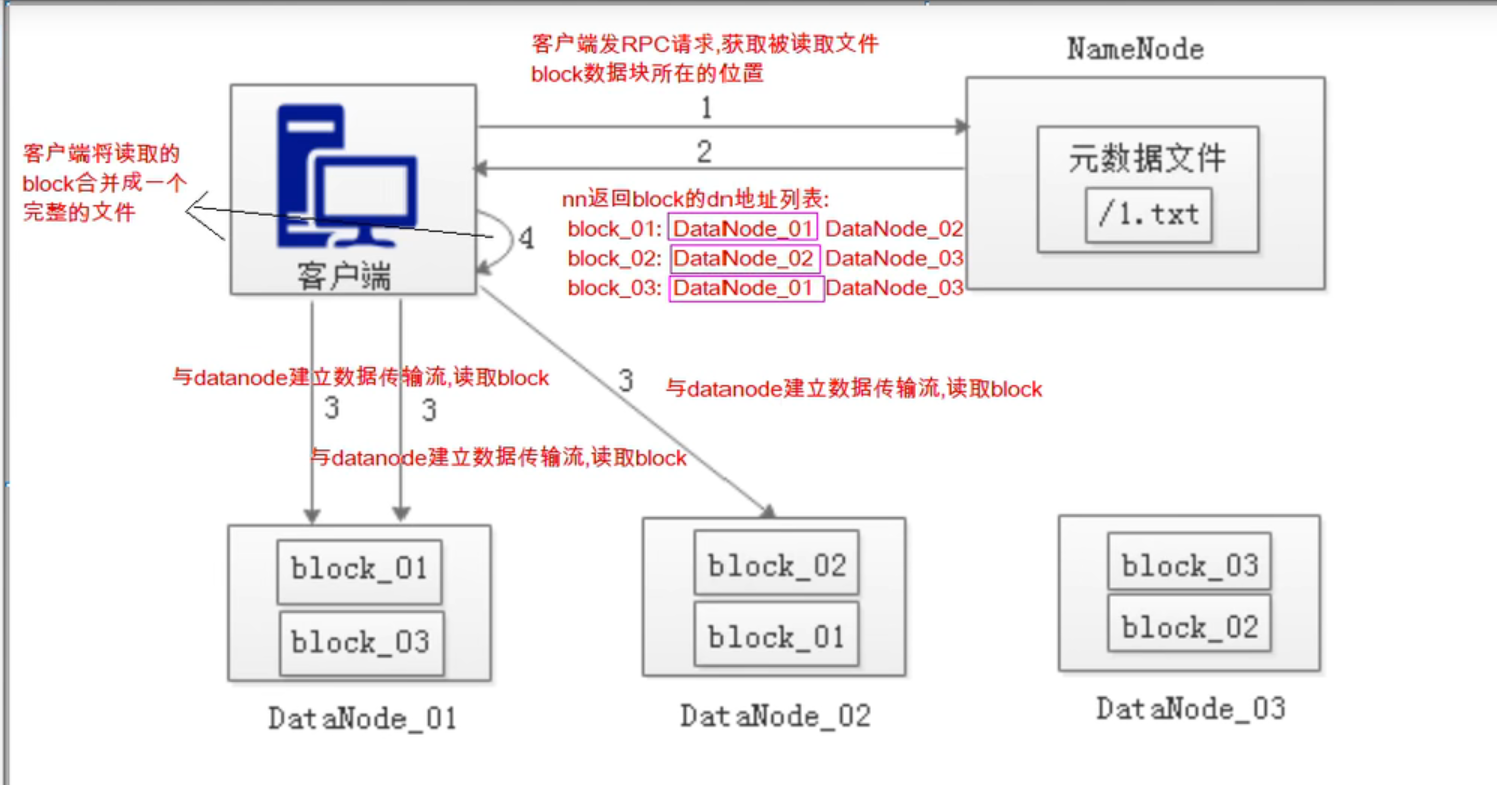
2 返回后,客户端会做一个筛选 ===> 优先选择 与客户端在同一台机架/健康的 block 块
读取时,dataNode 会做完整性校验,保证文件完整,如果文件不完整, 客户端向 NameNode 获取下一批 DataNode 地址列表,继续读,直到文件是完整的

若有收获,就点个赞吧
0 人点赞
