背景
在大数据分析与计算的场景中,我们通常会需要一套规则引擎来对采集到的数据进行分类,比如针对输入的一组规则将人群进行分类。开源类规则引擎中使用频率比较高的是QlExpress,本文将介绍一种通过Scala Runtime ToolBox实现的规则化引擎,该引擎运用了Scala运行时编译机制, 经实验, 该方案的运行效率将高于QlExpress。
方案一: 通过QLExpress在运行时解析规则
该方案的基本思想为
- 将数据集中的数据填充到规则表达式中
- 通过QLExpress来执行规则判断语句
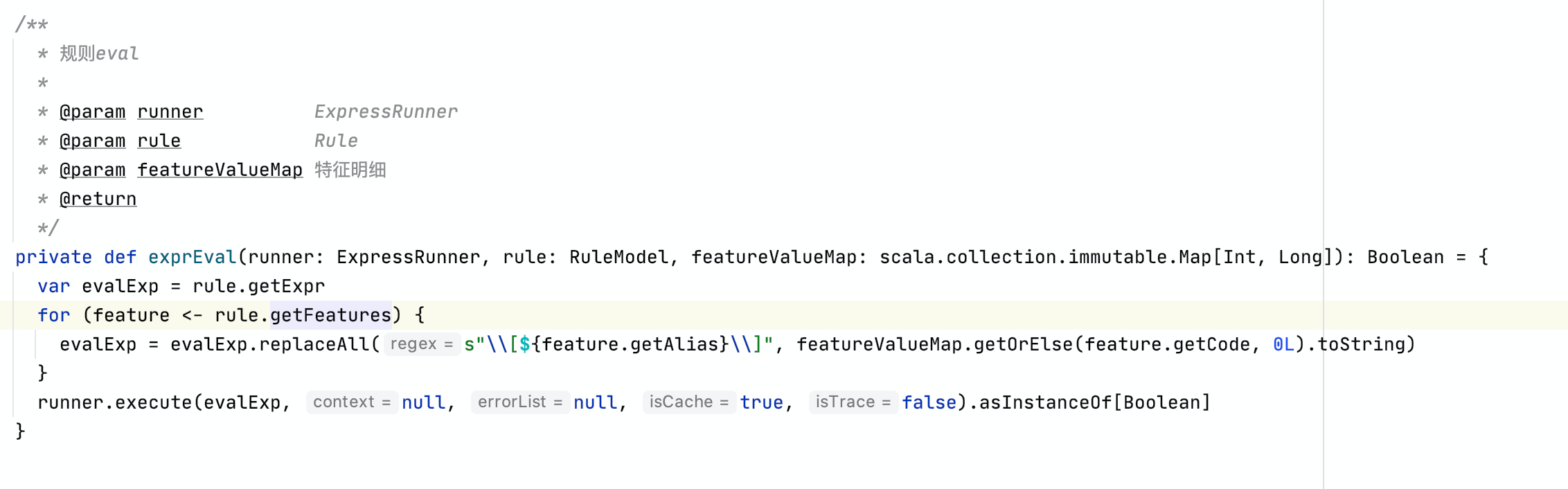
方案二: 通过scala.tools.reflect.ToolBox在运行时提前编译规则
该方案的基本思想为
- 每一个规则都是一个编译好的匿名函数
- 将数据输入匿名函数中
- 省去了针对每一行数据替换字符串并解析的时间

性能对比
方案二的性能是方案一的一倍左右

若有收获,就点个赞吧
0 人点赞
