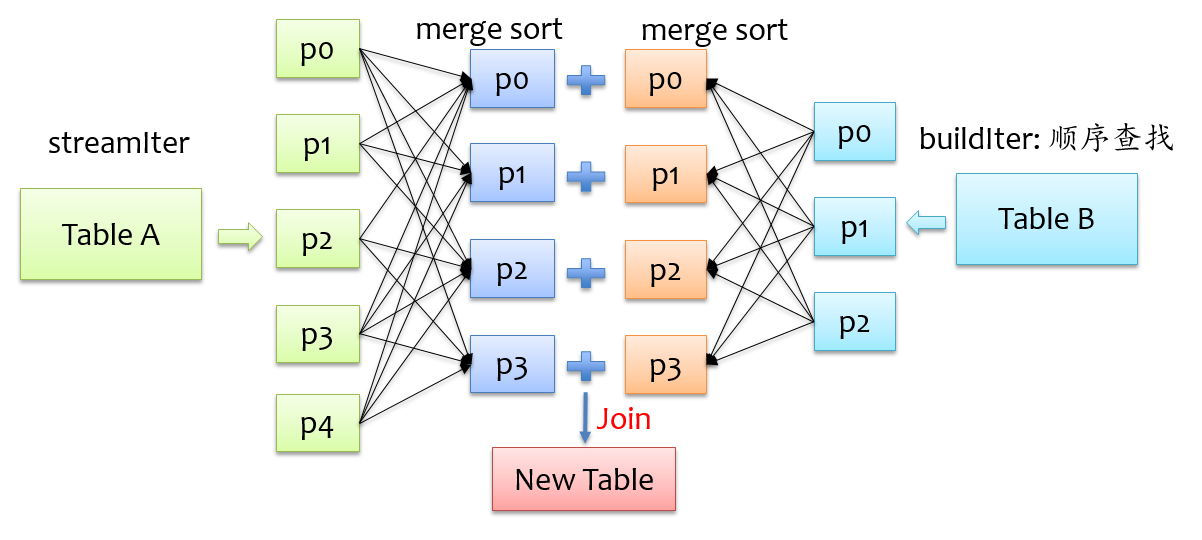
Join实现
sort merge join
基本思想:
- shuffle write阶段将相同的key发送到同一个节点,
- shuffle read阶段对key排序,最后做join
broadcast join(map join)
将小表(大小可以直接放在单个节点的内存中)广播到集群中的各个节点做join,避免了shuffle,节省了网络IO
broadcast join触发的条件
- shuffle write阶段与sort merge join类似
- shuffle read阶段将较小的表放入hashmap中,省去了排序
hash join触发的条件
- buildIter总体估计大小超过spark.sql.autoBroadcastJoinThreshold设定的值,即不满足broadcast join条件
- 开启尝试使用hash join的开关,spark.sql.join.preferSortMergeJoin=false
- 每个分区的平均大小不超过spark.sql.autoBroadcastJoinThreshold设定的值,即shuffle read阶段每个分区来自buildIter的记录要能放到内存中
- streamIter的大小是buildIter三倍以上
不同种类的Join
https://www.cnblogs.com/suanec/p/7560399.html
inner join
left outer join
full outer join(仅采用sort merge join实现)
left semi join
left anti join

若有收获,就点个赞吧
0 人点赞
