- Key-Value RDD
- 什么是Key-Value RDD?
- 如何从RDD创建Key-Value RDD
- 1. 通过Map函数转换RDD->Key-Value RDD
- 2. KeyBy函数
- Key-Value RDD基本操作
- 对值进行映射
- mapValues
- flatMapValues
- Aggregations & Join
- Aggregation
- countByKey
- groupByKey
- reduceByKey
- aggregate & treeAggregate
- aggregateByKey
- combineByKey
- foldByKey
Key-Value RDD
什么是Key-Value RDD?
Key-Value RDD指按照键值对存储的RDD,基于RDD的许多方法要求数据是KeyValue格式,这种方法都有形如
如何从RDD创建Key-Value RDD
1. 通过Map函数转换RDD->Key-Value RDD
val spark = SparkSession.builder().master("local").appName("yifan_spark_test").getOrCreate()val myCollection = "Spark The Definitive Guide: Big Data Processing Made Simple".split(" ")val words = spark.sparkContext.parallelize(myCollection, 2)words.map(word => (word.toLowerCase, 1))
2. KeyBy函数
val keyword = words.keyBy(word => word.toLowerCase.toSeq(0).toString)
Key-Value RDD基本操作
对值进行映射
mapValues
keyword.mapValues(word => word.toUpperCase()).collect()
 #### flatMapValues
#### flatMapValues
keyword.flatMapValues(word => word.toUpperCase()).collect()
提取Key和Value
val keySet = keyword.keys.collect()
keySet.foreach(println)
val valueSet = keyword.values.collect()
valueSet.foreach(println)
lookup
val lookupResult = keyword.lookup("s")
sampleByKey
Aggregations & Join
Aggregation
val chars = words.flatMap(word => word.toLowerCase.toSeq)
val KVcharacters = chars.map(letter => (letter, 1))
def maxFunc(left:Int, right:Int) = math.max(left, right)
def addFunc(left:Int, right:Int) = left + right
val nums = spark.sparkContext.parallelize(1 to 30, 5)
countByKey
统计每一个Key的个数
val timeout = 1000L //milliseconds
val confidence = 0.95
KVcharacters.countByKey().foreach(println)
KVcharacters.countByKeyApprox(timeout, confidence)
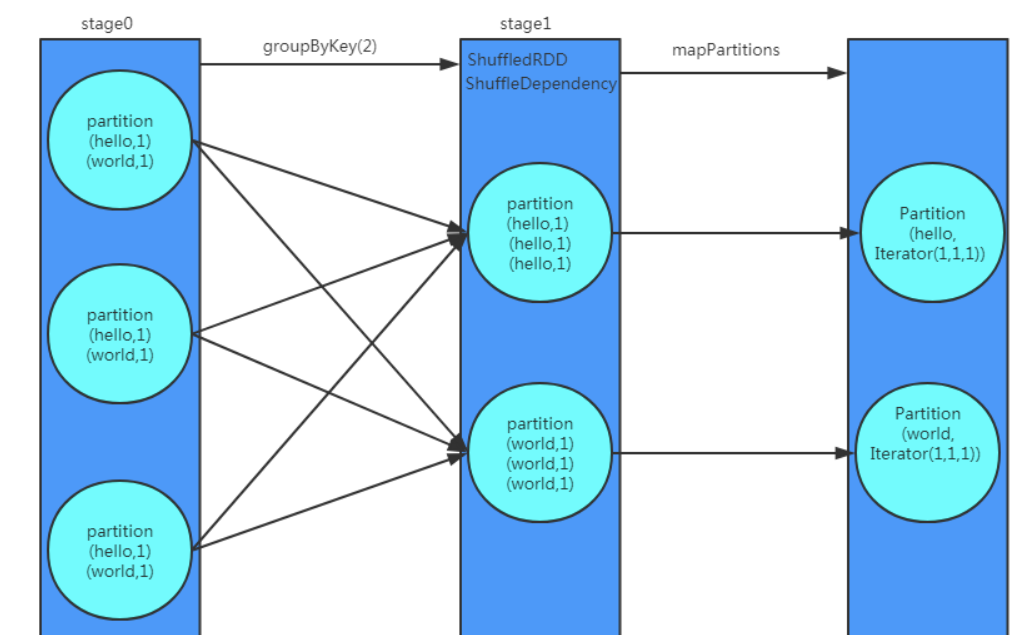
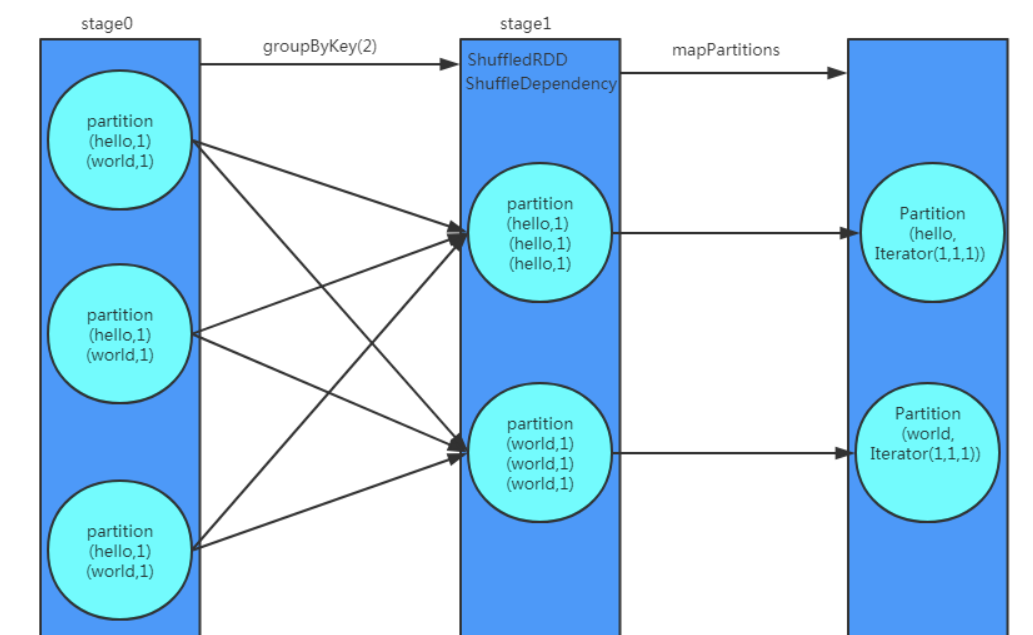
groupByKey
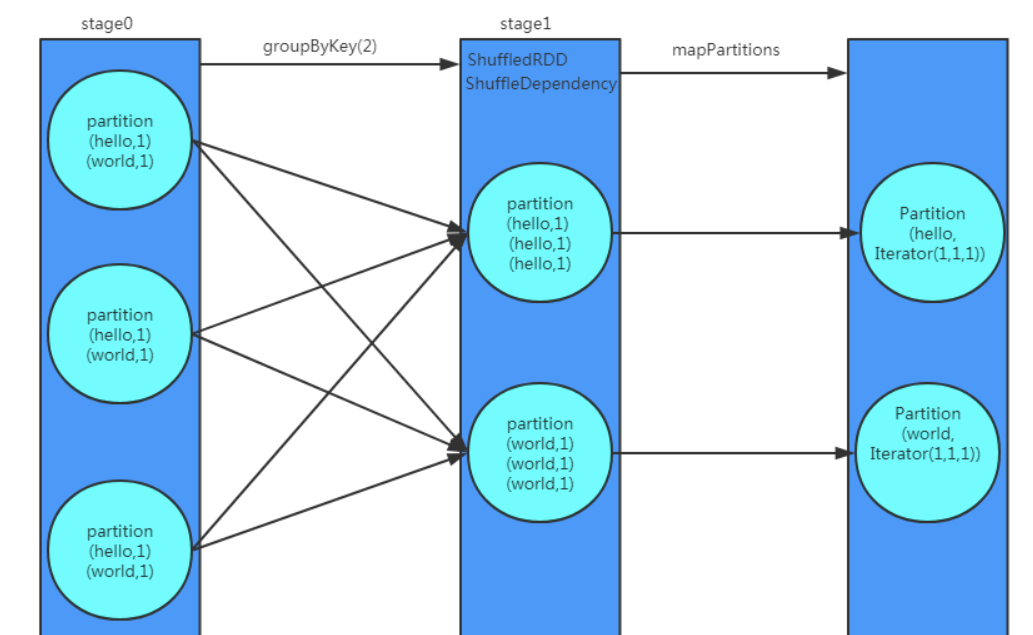
根据Key分组聚合, Row By Row, 相同的Key会被分配到同一个Iterator, 当每个Key的数据条数分布均匀时,可采用groupByKey
KVcharacters.groupByKey().map(row => (row._1, row._2.reduce(addFunc))).collect()
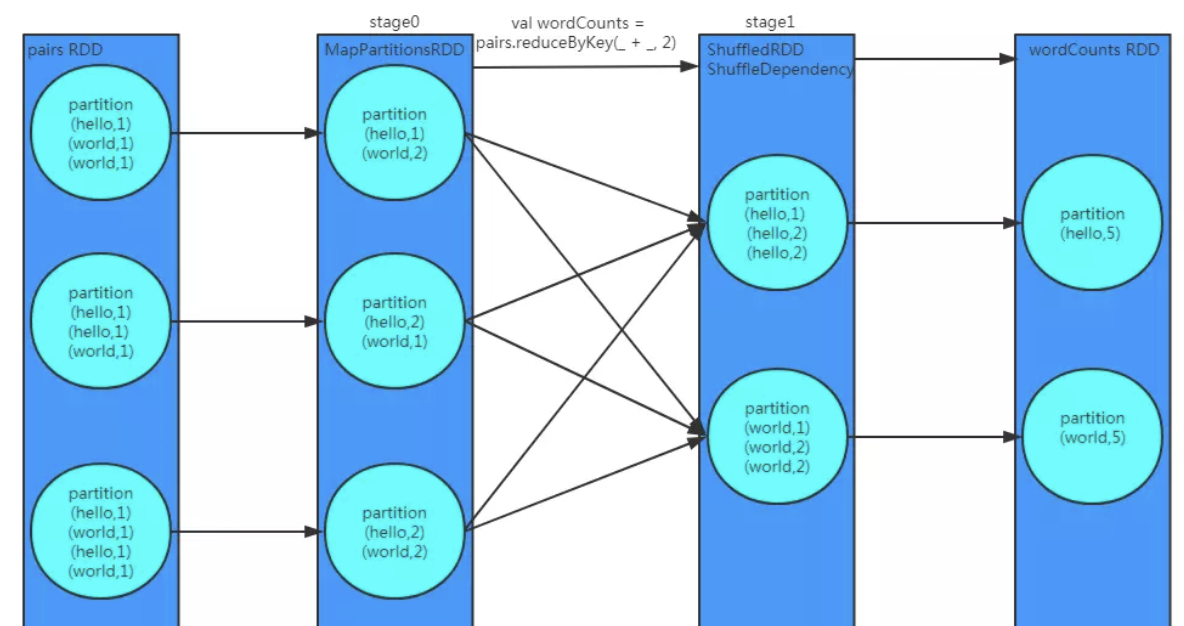
reduceByKey
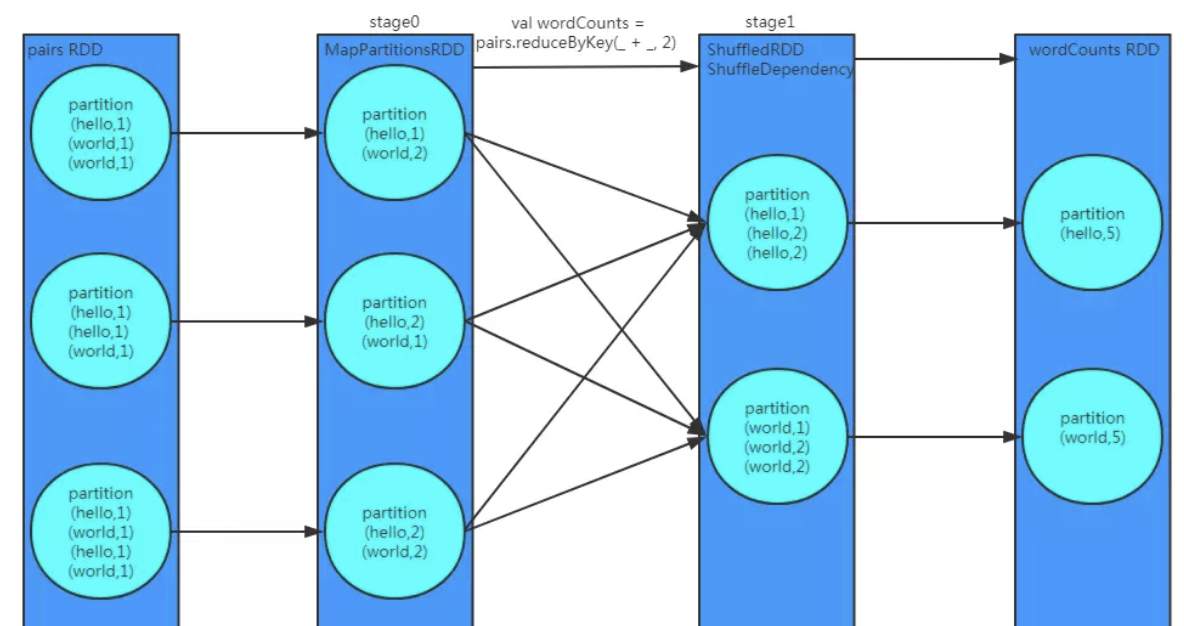
作用和groupByKey类似,在具体实现时,会对同一分区相同Key做预聚合,减少了Shuffle时的网络IO和磁盘IO, 当数据倾斜比较严重时,可以采用reduceByKey提升性能
aggregate & treeAggregate
指定分区内的聚合函数&分区间的聚合函数对RDD做聚合
val aggregateResult = nums.aggregate(0)(maxFunc, addFunc)
println(aggregateResult)
val depth = 3
nums.treeAggregate(0)(maxFunc, addFunc, depth)
aggregateByKey
指定分区内的聚合函数&分区间的聚合函数对Key-Value RDD做聚合
KVcharacters.aggregateByKey(0)(addFunc, maxFunc).collect()
combineByKey
createCombiner: V => C ,这个函数把当前的值作为参数,此时我们可以对其做些附加操作(类型转换)并把它返回 (这一步类似于初始化操作)
mergeValue: (C, V) => C,该函数把元素V合并到之前的元素C(createCombiner)上 (这个操作在每个分区内进行)
mergeCombiners: (C, C) => C,该函数把2个元素C合并 (这个操作在不同分区间进行)
val valToCombiner = (value:Int) => List(value)
val mergeValuesFunc = (vals:List[Int], valToAppend:Int) => valToAppend :: vals
val mergeCombinerFunc = (vals1:List[Int], vals2:List[Int]) => vals1 ::: vals2
// now we define these as function variables
val outputPartitions = 6
KVcharacters
.combineByKey(
valToCombiner,
mergeValuesFunc,
mergeCombinerFunc,
outputPartitions)
.collect().foreach(println)
foldByKey
KVcharacters.foldByKey(0)(addFunc).collect()
Join
CoGroup
val distinctChars = words.flatMap(word => word.toLowerCase.toSeq).distinct
val charRDD = distinctChars.map(c => (c, new Random().nextDouble()))
val charRDD2 = distinctChars.map(c => (c, new Random().nextDouble()))
val charRDD3 = distinctChars.map(c => (c, new Random().nextDouble()))
charRDD.cogroup(charRDD2, charRDD3).take(5)
join
val keyedChars = distinctChars.map(c => (c, new Random().nextDouble()))
KVcharacters.join(keyedChars).count()
Zip
println(words.getNumPartitions)
val numRange = spark.sparkContext.parallelize(0 to 8, 2)
words.zip(numRange).collect()
Custom Partitioning
words.coalesce(1).getNumPartitions
words.repartition(10)
val df = spark.read.option("header", "true").option("inferSchema", "true")
.csv("/Users/yuyifan/Desktop/Repository/Spark-The-Definitive-Guide/data/retail-data/all")
val rdd = df.coalesce(10).rdd
Coalesce
一般用于将多个分区合并成一个
words.coalesce(1).getNumPartitions
repartition
数据重分区, 会进行Shuffle
words.repartition(10)
HashPartitioner & RangePartitioner
Scala自带的分区器
import org.apache.spark.HashPartitioner
rdd.map(r => r(6)).take(5).foreach(println)
val keyedRDD = rdd.keyBy(row => row(6).asInstanceOf[Int].toDouble)
keyedRDD.partitionBy(new HashPartitioner(10)).take(10)
自定义Partitioner
当数据倾斜比较严重时,比如大量的不同的Key分布在了同一个分区内,我们可能希望对某些Key做特殊的划分,这个时候就需要自定义分区器
import org.apache.spark.Partitioner
class DomainPartitioner extends Partitioner {
def numPartitions = 3
def getPartition(key: Any): Int = {
val customerId = key.asInstanceOf[Double].toInt
if (customerId == 17850.0 || customerId == 12583.0) {
return 0
} else {
return new java.util.Random().nextInt(2) + 1
}
}
}
keyedRDD
.partitionBy(new DomainPartitioner).map(_._1).glom().map(_.toSet.toSeq.length)
.take(5)
Attachments:
 image-20210123-051041.pngimage-20210123-055636.pngimage-20210123-055636.pngimage-20210123-055656.pngimage-20210123-055656.png
image-20210123-051041.pngimage-20210123-055636.pngimage-20210123-055636.pngimage-20210123-055656.pngimage-20210123-055656.png

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}