前言
本文为阅读”Spark The Definitive Guide”Chapter 7 所做的归纳和整理,部分代码来自于书中,部分为自己在本机试验所得
Definition of Aggregation
Aggregation is the act of collecting something together.
Brief Overview
聚合的类型主要有以下几种
- 针对整个数据集(Dataframe)
- 分组聚合
- 窗口聚合
- Grouping Sets
- rollup (Hierarchically)
- cube (所有可能的组合)
返回的结果: RelationalGroupedDataset
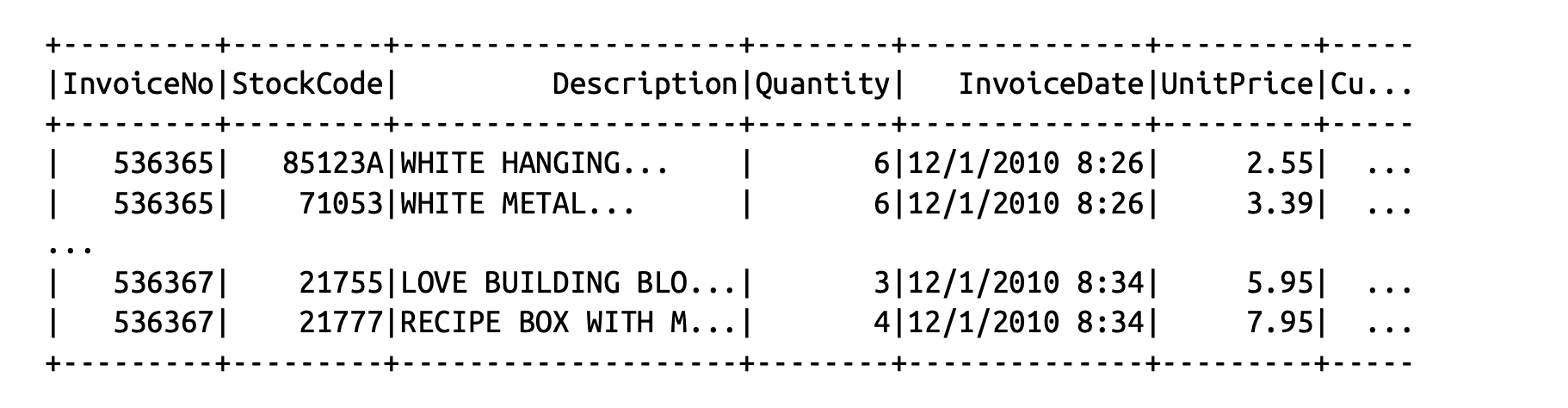
| val df = spark.read.format(“csv”) .option(“header”, “true”) .option(“inferSchema”, “true”) .load(“/data/retail-data/all/*.csv”) .coalesce(5) df.cache() df.createOrReplaceTempView(“dfTable”) |
|---|
Aggregation Functions
聚合函数大部分被定义在 or.apache.spark.sql.functions
count
| import org.apache.spark.sql.functions.count df.select(count(“StockCode”)).show() // 541909 |
|---|
countDistinct
| ``` import org.apache.spark.sql.functions.countDistinct df.select(countDistinct(“StockCode”)).show() // 4070
|| --- |<a name="Aggregation-approx_count_distinct"></a>## approx_count_distinct|
import org.apache.spark.sql.functions.approx_count_distinct df.select(approx_count_distinct(“StockCode”, 0.1)).show() // 3364
|
| --- |
<a name="Aggregation-firstandlast"></a>
## first and last
|
import org.apache.spark.sql.functions.{first, last} df.select(first(“StockCode”), last(“StockCode”)).show()
|
| --- |
<a name="Aggregation-minandmax"></a>
## min and max
|
import org.apache.spark.sql.functions.{min, max} df.select(min(“Quantity”), max(“Quantity”)).show()
|
| --- |
<a name="Aggregation-sum"></a>
## sum
|
import org.apache.spark.sql.functions.sum df.select(sum(“Quantity”)).show() // 5176450
|
| --- |
<a name="Aggregation-sumDistinct"></a>
## sumDistinct
|
import org.apache.spark.sql.functions.sumDistinct df.select(sumDistinct(“Quantity”)).show() // 29310
|
| --- |
<a name="Aggregation-avg"></a>
## avg
|
import org.apache.spark.sql.functions.{sum, count, avg, expr}
df.select( count(“Quantity”).alias(“total_transactions”), sum(“Quantity”).alias(“total_purchases”), avg(“Quantity”).alias(“avg_purchases”), expr(“mean(Quantity)”).alias(“mean_purchases”)) .selectExpr( “total_purchases/total_transactions”, “avg_purchases”, “mean_purchases”).show()
|
| --- |
<a name="Aggregation-varianceandstandarddeviation"></a>
## variance and standard deviation
|
import org.apache.spark.sql.functions.{var_pop, stddev_pop} import org.apache.spark.sql.functions.{var_samp, stddev_samp} df.select(var_pop(“Quantity”), var_samp(“Quantity”), stddev_pop(“Quantity”), stddev_samp(“Quantity”)).show()
|
| --- |
<a name="Aggregation-skewnessandkurtosis"></a>
## skewness and kurtosis
|
import org.apache.spark.sql.functions.{skewness, kurtosis} df.select(skewness(“Quantity”), kurtosis(“Quantity”)).show()
|
| --- |
<a name="Aggregation-covarianceandcorrelation"></a>
## covariance and correlation
| import org.apache.spark.sql.functions.{corr, covar_pop, covar_samp}<br />df.select(corr("InvoiceNo", "Quantity"), covar_samp("InvoiceNo", "Quantity"),<br /> covar_pop("InvoiceNo", "Quantity")).show() |
| --- |
<a name="Aggregation-aggregatingtocomplextypes"></a>
## aggregating to complex types
|
import org.apache.spark.sql.functions.{collect_set, collect_list} df.agg(collect_set(“Country”), collect_list(“Country”)).show()
|
| --- |
<a name="Aggregation-Grouping"></a>
# Grouping
分组聚合,输入多行,输出一行
<a name="Aggregation-GroupingWithExpressions"></a>
## Grouping With Expressions
|
df.groupBy(“InvoiceNo”).agg( count(“Quantity”).alias(“quan”), expr(“count(Quantity)”)).show()
|
| --- |
<a name="Aggregation-GroupingWithMaps"></a>
## Grouping With Maps
|
df.groupBy(“InvoiceNo”).agg(“Quantity”->”avg”, “Quantity”->”stddev_pop”).show()
|
| --- |
<a name="Aggregation-WindowFunctions"></a>
# Window Functions
对输入的每一行在一个分组的窗口范围内做计算,最后为每一行输出一个结果<br />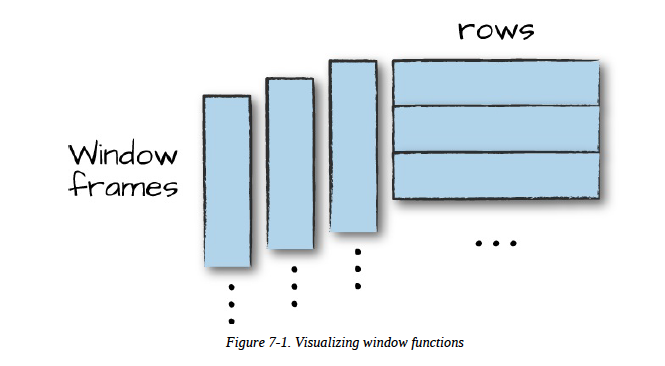<br />执行一个窗口函数需要两个要素
- 定义一个窗口<br />
- 定义一个窗口函数 , 输入: 窗口内的所有行, 输出:一行,目前Spark支持三种窗口函数
- aggregate function<br />
- ranking function<br />
- analytic function<br />
<a name="NjnjH"></a>
## 如何定义一个窗口
一个窗口的定义需要三个要件
- 分组定义,即partition by 的条件,窗口只在指定的分组内生效<br />
- 分组内排序条件,即order by的条件,指定了在一个分组内的每一行如何排列<br />
- Window Frame的定义,即rowsBetween, 指定了哪些行可以落在当前行的窗口内<br />
为了更好的说明,举个例子
|
import org.apache.spark.sql.expressions.Window import org.apache.spark.sql.functions.col val windowSpec = Window .partitionBy(“CustomerId”, “date”) .orderBy(col(“Quantity”).desc) .rowsBetween(Window.unboundedPreceding, Window.currentRow)
|
| --- |
上述代码定义了一个窗口,首先`Window.partitionBy("CustomerId", "date")` 指定了当前窗口的分组为相同CustomerId, 相同日期的行,接着`orderBy`指定了在分组内按照Quantity来排序,最后,`rowsBetween` 定义了对于每一行来说窗口作用的范围,在上述例子中代表当前行前的所有行到当前行,当然也可以用数字,例如`rowsBetween(-1,0)`代表前一行到当前行
<a name="7YiRI"></a>
## 定义一个窗口函数
目前Spark支持的窗口函数主要有三种
- aggregate function<br />
- ranking function<br />
- analytic function<br />
分别举例说明
<a name="Aggregation-aggregatefunction"></a>
### aggregate function
|
import org.apache.spark.sql.functions.max val maxPurchaseQuantity = max(col(“Quantity”)).over(windowSpec)
|
| --- |
上述代码返回了窗口内的最大Quantity值
<a name="Aggregation-rankingfunction"></a>
### ranking function
|
import org.apache.spark.sql.functions.{dense_rank, rank} val purchaseDenseRank = dense_rank().over(windowSpec) val purchaseRank = rank().over(windowSpec)
|
| --- |
- dense_rank() 返回去重后的rank<br />
- rank() 返回真实排名,如果同一个排名有多个相同的值,后续的rank依次累加<br />
<a name="BEsmT"></a>
## 完整的例子
<a name="Aggregation-Scala"></a>
### Scala
|
import org.apache.spark.sql.functions.{col, to_date} val dfWithDate = df.withColumn(“date”, to_date(col(“InvoiceDate”), “MM/d/yyyy H:mm”)) dfWithDate.createOrReplaceTempView(“dfWithDate”)
// in Scala import org.apache.spark.sql.expressions.Window import org.apache.spark.sql.functions.col val windowSpec = Window .partitionBy(“CustomerId”, “date”) .orderBy(col(“Quantity”).desc) .rowsBetween(Window.unboundedPreceding, Window.currentRow)
import org.apache.spark.sql.functions.max val maxPurchaseQuantity = max(col(“Quantity”)).over(windowSpec)
// in Scala import org.apache.spark.sql.functions.{dense_rank, rank} val purchaseDenseRank = dense_rank().over(windowSpec) val purchaseRank = rank().over(windowSpec)
// in Scala import org.apache.spark.sql.functions.col
dfWithDate.where(“CustomerId IS NOT NULL”).orderBy(“CustomerId”) .select( col(“CustomerId”), col(“date”), col(“Quantity”), purchaseRank.alias(“quantityRank”), purchaseDenseRank.alias(“quantityDenseRank”), maxPurchaseQuantity.alias(“maxPurchaseQuantity”)).show()
|
| --- |
<a name="Aggregation-SQL"></a>
### SQL
| SELECT CustomerId, date, Quantity,<br /> rank(Quantity) OVER (PARTITION BY CustomerId, date<br /> ORDER BY Quantity DESC NULLS LAST<br /> ROWS BETWEEN<br /> UNBOUNDED PRECEDING AND<br /> CURRENT ROW) as rank,<br /> dense_rank(Quantity) OVER (PARTITION BY CustomerId, date<br /> ORDER BY Quantity DESC NULLS LAST<br /> ROWS BETWEEN<br /> UNBOUNDED PRECEDING AND<br /> CURRENT ROW) as dRank,<br /> max(Quantity) OVER (PARTITION BY CustomerId, date<br /> ORDER BY Quantity DESC NULLS LAST<br /> ROWS BETWEEN<br /> UNBOUNDED PRECEDING AND<br /> CURRENT ROW) as maxPurchase<br />FROM dfWithDate WHERE CustomerId IS NOT NULL ORDER BY CustomerId |
| --- |

<a name="Aggregation-GroupingSets"></a>
# Grouping Sets
grouping sets可以理解为按照一个或多个维度分组并统计,grouping sets只作用于SQL<br />例如,下面两段SQL在结果上是等效的
| SELECT CustomerId, stockCode, sum(Quantity) FROM dfNoNull<br />GROUP BY customerId, stockCode<br />ORDER BY CustomerId DESC, stockCode DESC |
| --- |
|
SELECT CustomerId, stockCode, sum(Quantity) FROM dfNoNull GROUP BY customerId, stockCode GROUPING SETS((customerId, stockCode)) ORDER BY CustomerId DESC, stockCode DESC
|
| --- |
如果我们想要得到对整个结果集以及根据 (CustomerId, stockCode)维度的统计,则需要用到grouping sets
|
SELECT CustomerId, stockCode, sum(Quantity) FROM dfNoNull GROUP BY customerId, stockCode GROUPING SETS((customerId, stockCode),()) ORDER BY CustomerId DESC, stockCode DESC
|
| --- |
同时需要注意的是,grouping sets的数据源必须没有null,否则将会和结果集的null有冲突<br />
<a name="Aggregation-Rollups"></a>
## Rollups
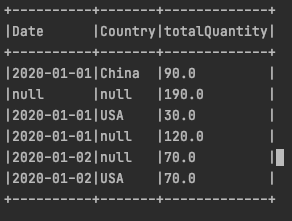
Rollups 将 group中的每个元素按照层级进行group by,例如
|
val rolledUpDf = Seq(
(“2020-01-01”, “USA”, “30”),
(“2020-01-02”, “USA”, “70”),
(“2020-01-01”,”China”,”90”))
.toDF(“Date”,”Country”,”Quantity”)
.rollup(“Date”,”Country”)
.agg(sum(“Quantity”))
.selectExpr(“Date”, “Country”,”sum(Quantity) as totalQuantity”)
rolledUpDf.show(false)
|
| --- |
上述代码将按照三个level进行聚合
- ()<br />
- group by (Date)<br />
- group by (Date, Country)<br />
<a name="Aggregation-Cube"></a>
## Cube
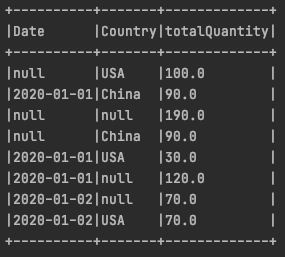
按照所有可能的组合进行group by
|
val cubedDF = Seq(
(“2020-01-01”, “USA”, “30”),
(“2020-01-02”, “USA”, “70”),
(“2020-01-01”,”China”,”90”))
.toDF(“Date”,”Country”,”Quantity”)
.cube(“Date”,”Country”)
.agg(sum(“Quantity”))
.selectExpr(“Date”, “Country”,”sum(Quantity) as totalQuantity”)
cubedDF.show(false)
|
| --- |
<a name="Aggregation-GroupingMetadata"></a>
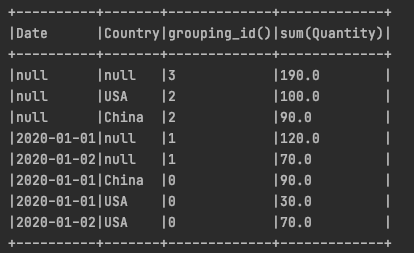
## Grouping Metadata
为不同的grouping打上编号
|
import org.apache.spark.sql.functions.{grouping_id, sum, expr}
val cubedDF = Seq( (“2020-01-01”, “USA”, “30”), (“2020-01-02”, “USA”, “70”), (“2020-01-01”,”China”,”90”)) .toDF(“Date”,”Country”,”Quantity”) .cube(“Date”,”Country”) .agg(grouping_id(),sum(“Quantity”)) .orderBy(expr(“grouping_id()”).desc) cubedDF.show(false)
|
| --- |
<a name="Aggregation-Pivot"></a>
## Pivot
行转列
|
val pivoted = dfWithDate.groupBy(“date”).pivot(“Country”).sum()
pivoted.where(“date > ‘2011-12-05’”).select(“date” ,”USA_sum(Quantity)“).show()
|
| --- |

<a name="Aggregation-User-DefinedAggregationFunctions"></a>
# User-Defined Aggregation Functions
用户自定义聚合函数(UDAF)的几个要件
- inputSchema<br />
- bufferSchema<br />
- deterministic<br />
- initialize<br />
- update<br />
- merge<br />
- evaluate<br />
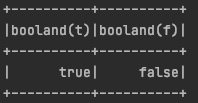
例子:实现一个聚合函数,输入多行,返回多行是否都为true
```scala
import org.apache.spark.sql.expressions.MutableAggregationBuffer
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction
import org.apache.spark.sql.Row
import org.apache.spark.sql.types._
class BoolAnd extends UserDefinedAggregateFunction {
def inputSchema: org.apache.spark.sql.types.StructType =
StructType(StructField("value", BooleanType) :: Nil)
def bufferSchema: StructType = StructType(
StructField("result", BooleanType) :: Nil
)
def dataType: DataType = BooleanType
def deterministic: Boolean = true
def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = true
}
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer(0) = buffer.getAs[Boolean](0) && input.getAs[Boolean](0)
}
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getAs[Boolean](0) && buffer2.getAs[Boolean](0)
}
def evaluate(buffer: Row): Any = {
buffer(0)
}
}
object BoolAnd {
def main(args: Array[String]):Unit = {
val ba = new BoolAnd
val spark = SparkSession.builder().master("local").appName("yifan_spark_test2")
.getOrCreate()
spark.udf.register("booland", ba)
spark.range(1)
.selectExpr("explode(array(TRUE, TRUE, TRUE)) as t")
.selectExpr("explode(array(TRUE, FALSE, TRUE)) as f", "t")
.select(ba(col("t")), expr("booland(f)"))
.show()
}
Q&A
Spark SQL 在执行聚合时(groupBy)底层调用了哪些函数?(TODO)
countDistinct 和 groupBy哪一个性能比较好? (TODO)

若有收获,就点个赞吧
0 人点赞
