Linux基础
1.四层和七层负载均衡区别
四层负载均衡工作在OSI模型中的四层,即传输层。四层负载均衡只能根据报文中目标地址和源地址对请求进行转发而无法修改或判断所请求资源的具体类型,然后经过负载均衡内部的调度算法转发至要处理请求的服务器。四层负载均衡单纯的提供了终端到终端的可靠连接,将请求转发至后端,连接始终都是同一个。LVS就是很典型的四层负载均衡。
七层负载均衡工作在OSI模型的第七层应用层,所以七层负载均衡可以基于请求的应用层信息进行负载均衡,例如根据请求的资源类型分配到后端服务器,而不再是根据IP和端口选择。七层负载均衡的功能更丰富更灵活,也能使整个网络更智能。如上图所示,在七层负载均衡两端(面向用户端和服务器端)的连接都是独立的。
简言之,四层负载均衡就是基于IP+端口实现的。七层负载均衡就是通过应用层资源实现的。
2.并发/并行,异步/同步,阻塞/非阻塞
并发/并行CPU在执行多个任务时的方式。并发表示同一段时间里面有多个进程在同一CPU执行,在极短的时间互相切换使人不会发觉。并行只会出现在多个CPU的情况下,表示同一时刻之内有多个进程在执行
同步/异步关注的是请求和响应的通讯机制,描述的是被调用方。当发出请求后,该请求是否等待结果后再返回。同步就是没有得到结果前不会返回,返回即得到请求结果。异步就是得到发出请求后就直接返回,也可能不会立即得到结果,服务得到结果后再通过通知或者回调函数等方法通知调用者。去买咖啡,付了钱在前台等待咖啡制作完毕,就是同步,付了钱不在前台等待,找位置坐下,服务员送过来就是异步
阻塞/非阻塞关注的是请求在等待结果时的状态,描述的是调用方。阻塞就是在等待结果的时候,当前线程会被挂起,在得到结果之后返回;非阻塞则是没有得到结果之前也不会阻塞当前线程。阻塞的情况就是卖咖啡的时候什么都不能做,只能挂起;非阻塞的时候就是边等咖啡边玩手机,过会检查咖啡是否好了
3.OSI七层模型和TCP/IP四层模型
4. 常见的http状态码


5. TOP含义
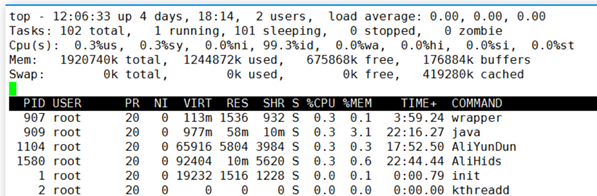
第一行top:系统当前时间系统运行时间当前用户登陆数系统负载(load average,这里有三个数值,分别是系统最近1分钟,5分钟,15分钟的平均负载。一般对于单个处理器来说,负载在0 — 1.00 之间是正常的,超过1.00就要引起注意了。在多核处理器中,你的系统均值不应该高于处理器核心的总数。)
第二行Tasks:total进程总数、running正在运行的进程数、sleeping睡眠的进程数、stopped停止的进程数、zombie僵尸进程数。
第三行Cpu:%us用户空间占用CPU百分比、%sy内核空间占用CPU百分比、%ni用户进程空间内改变过优先级的进程占用CPU百分比、%id空闲CPU百分比、%wa等待输入输出(I/O)的CPU时间百分比、%hi指的是cpu处理硬件中断的时间、%si指cpu处理软中断的时间%st用于有虚拟cpu的情况,用来指示被虚拟机偷掉的cpu时间。(通常id%值可以反映一个系统cpu的闲忙程度。)
第四行Mem:total物理内存总量、used使用的物理内存总量、free空闲内存总量、buffers 用作内核缓存的内存量。
第五行Swap:total交换区总量、 used使用的交换区总量、free空闲交换区总量、cached缓冲的交换区总量。
第六行 PID、USER、PR(优先级)、NI(任务nice值)、VIRT(虚拟内存用量)VIRT=SWAP+RES 、RES(物理内存用量)、SHR(共享内存用量)、S(进程状态)、%CPU(CPU占用比)、%MEM(物理内存占用比)、TIME+(累计CPU占用时间)、 COMMAND 命令名/命令行。
6. HTTP的无状态,有连接和短连接
无状态:指的是服务器端无法知道2次请求之间的联系,即使是前后2次请求来自同一个浏览器,也没有任何数据能够判断出是同一个浏览器的请求。后来可以通过cookie、session机制来判断。
览器端第一次HTTP请求服务器端时,在服务器端使用session这种技术,就可以在服务器产生一个随机值即SessionID发给浏览器端,浏览器端收到后会保持这个SessionID在Cookie当中,这个Cookie值一般不能持久存储,浏览器关闭就消失。浏览器在每一次提交HTTP请求的时候会把这个SessionID传给服务器端,服务器端就可以通过比对知道是谁了。
- Session通常会保存在服务器端内存中,如果没有持久化,则易丢失
- Session会定时过期。过期后浏览器如果再访问,服务端发现没有此ID,将给浏览器端重新发新的SessionID
- 更换浏览器也将重新获得新的SessionID
服务器端如果故障,即使Session被持久化了,但是服务没有恢复前都不能使用这些SessionID。如果使用HAProxy或者Nginx等做负载均衡器,调度到了不同的Tomcat上,那么也会出现找不到SessionID的情况。
会话保持方式: ①session sticky会话粘性②sesssion复制集群③session server (使用memcached,redis做共享session服务器)
有连接:是因为它基于TCP协议,是面向连接的,需要3次握手、4次断开。
短连接:Http 1.1前,都是一个请求一个连接,而Tcp的连接创建销毁成本高,对服务器有很大的影响。所以自Http 1.1开始,支持keep-alive,默认也开启,一个连接打开后会保持一段时间(可设置),浏览器再访问该服务器就使用这个Tcp连接,减轻了服务器压力,提高了效率。
7. 实现session持久机制
- session绑定,基于IP或session cookie的。其部署简单,尤其基于session黏性的方式,粒度小,对负载均衡影响小。但一旦后端服务器有故障,其上的session丢失。
2. session复制集群,基于tomcat实现多个服务器内共享同步所有session。此方法可以保证任意一台后端服务器故障,其余各服务器上还都存有全部session,对业务无影响。但是它基于多播实现心跳,TCP单播实现复制,当设备节点过多,这种复制机制不是很好的解决方案。且并发连接多的时候,单机上的所有session占据的内存空间非常巨大,甚至耗尽内存。
3. session服务器,将所有的session存储到一个共享的内存空间中,使用多个冗余节点保存session,这样做到session存储服务器的高可用,且占据业务服务器内存较小。是一种比较好的解决session持久的解决方案。
生产环境中,应根据实际需要合理选择。不过以上这些方法都是在内存中实现了session的保持,可以使用数据库或者文件系统,把session数据存储起来,持久化。这样服务器重启后,也可以重新恢复session数据。不过session数据是有时效性的,是否需要这样做,视情况而定
8.比较memcached和redis
Memcached 只支持能序列化的数据类型(纯k/v),不支持持久化,基于Key-Value的内存缓存系统; 支持最大的内存存储对象为1M,超过1M的数据可以使用客户端压缩或拆分报包放到多个key中; 可以通过做集群同步的方式让各memcached服务器的数据同步实现数据的一致性.
借助了操作系统的 libevent 工具做高效的读写: libevent是个程序库,它将Linux的epoll、BSD类操作系统的kqueue等事件处理功能封装成统一的接口。即使对服务器的连接数增加,也能发挥高性能。memcached使用这个libevent库,因此能在Linux、BSD、Solaris等操作系统上发挥其高性能; 内存分配机制:用了Slab Allocator机制来分配、管理内存; 懒过期 Lazy Expiration: memcached不会监视数据是否过期,而是在取数据时才看是否过期,如果过期,把数据有效期限标识为0,并不清除该数据。以后可以覆盖该位置存储其它数据; LRU: 当内存不足时,memcached会使用LRU(Least Recently Used)机制来查找可用空间,分配给新记录使用。
常见数据库端口号
MySQL 3306 Oracle 1521 Mssql 1433 Pgsql 5432
解决ssh登录缓慢的问题
服务器端的配置文件: /etc/ssh/sshd_config
UseDNS yes #提高速度可改为noGSSAPIAuthentication yes #提高速度可改为no
磁盘存储和文件系统设备
1.为什么分区
优化I/O性能
实现磁盘空间配额限制
提高修复速度
隔离系统和程序
安装多个OS
采用不同文件系统
服务
1. DNS原理★
2.docker中的网络模式

若有收获,就点个赞吧
0 人点赞
