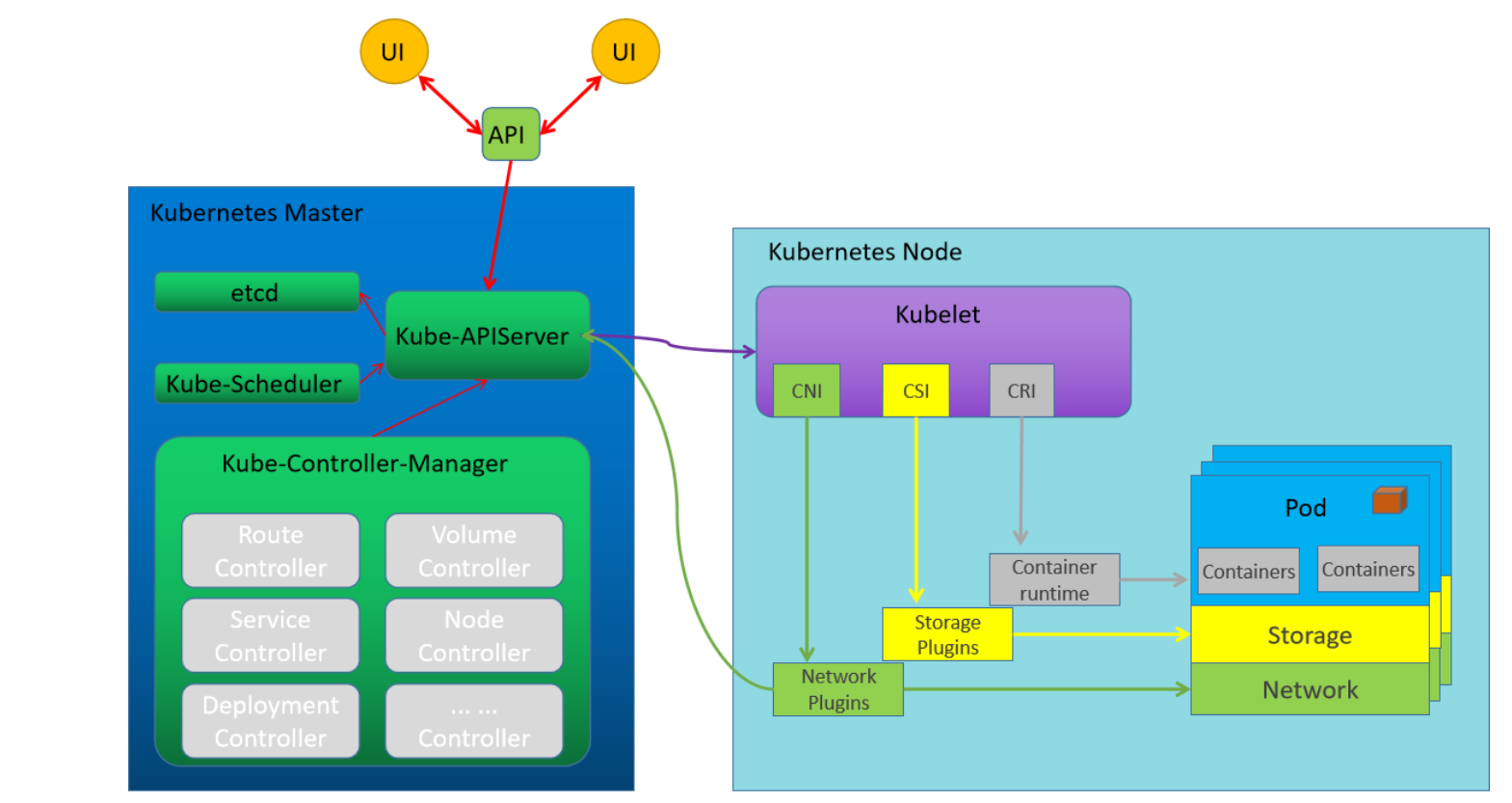
控制原理
k8s集群中的所有资源对象都是通过 master角色主机上的各种组件进行统一管理;基于node角色上的kubelet组件实现信息的交流。
pod内部的应用对象:基于CRI让应用本身是运行在容器内部;
基于CSI实现各种持久化数据的保存;
基于CNI实现多个pod应用程序之间的通信交流。
1.资源对象:对于k8s集群应用来说,所有的程序应用都是
- 运行在 Pod资源对象里面,
- 借助于service资源对象向外提供服务访问。
- 借助于各种存储资源对象实现数据的可持久化
- 借助于各种配置资源对象实现配置属性、敏感信息的管理操作
2.任务编排:就是对多个子任务执行顺序进行确定的过程。对于k8s来说,
- 对于紧密相关的多个子任务,我们把它们放到同一个pod内部,
- 对于非紧密关联的多个任务,分别放到不同的pod中,
- 然后借助于endpoint+service的方式实现彼此之间的相互调用。
- 为了让这些纷乱繁杂的任务能够互相发现自己,我们通过集群的CornDNS组件实现服务注册发现功能
3.控制器—-这用于对pod实现所谓的任务编排功能的组件
节点控制器(Node Controller),负责在节点出现故障时进行通知和响应
任务控制器(Job controller),监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
端点控制器(Endpoints Controller),填充端点(Endpoints)对象(即加入 Service与Pod)
服务帐户和令牌控制器(Service Account & Token Controllers),为新的命名空间创建默认帐户和API 访问令牌
根据我们之前对各种应用程序对象的操作,比如pod、service、token、configmap等等。我们知道,这些应用程序主要有两种在形式:数据形态(应用程序的条目) - 存储在API Server中的各种数据条目实体形态(真正运行的对象) - 通过kube-controller-manager到各节点上创建的具体对象。比如每一个Service,就是一个Service对象的定义,同时它还代表了每个节点上iptables或ipvs规则,而这些节点上的规则,是由kube-controller-manager结合 kube-proxy来负责进行落地。每一个Pod,就是一个应用程序的定义,同时它还代表了每个节点上资源的限制,而这些节点上的应用程序,是由kube-controller-manager结合kubelet来负责进行落地。资源在创建的时候,一般会由Scheduler调度到合适的Node节点上。这个时候,kubeServer在各个节点上的客户端kubelet组件,如果发现调度的节点是本地,那么会在本地节点将对应的资源进行落地,同时负责各个节点上的与APIServer相关的资源对象的监视功能。
控制流程

kubectl get pod -o yaml
1 用户向 APIserver中插入一个应用资源的数据形态
- 这个数据形态中定义了该资源对象的 "期望"状态,
- 数据经由 APIserver 保存到 ETCD 中。
2 kube-controller-manager 中的各种控制器会监视 Apiserver上与自己相关的资源对象的变动
比如 Service Controller只负责Service资源的控制,Pod Controller只负责Pod资源的控制等。
3 一旦APIServer中的资源对象发生变动,对应的Controller执行相关的配置代码,到对应的node节点上运行
- 该资源对象会在当前节点上,按照用户的"期望"进行运行
- 这些实体对象的运行状态我们称为 "实际状态"
- 即,控制器的作用就是确保 "期望状态" 与 "实际状态" 相一致
4 Controller将这些实际的资源对象状态,通过APIServer存储到ETCD的同一个数据条目的status的字段中
5 资源对象在运行过程中,Controller 会循环的方式向 APIServer 监控 spec 和 status 的值是否一致
- 如果两个状态不一致,那么就指挥node节点的资源进行修改,保证 两个状态一致
- 状态一致后,通过APIServer同步更新当前资源对象在ETCD上的数据
控制器分类
ReplicationController 最早期的Pod控制器,目前已被废弃。
RelicaSet 副本集,负责管理一个应用(Pod)的多个副本状态
Deployment 它不直接管理Pod,而是借助于ReplicaSet来管理Pod;最常用的无状态应用控制器;
DaemonSet 守护进程集,用于确保在每个节点仅运行某个应用的一个Pod副本。用于完成系统级任务。
StatefulSet 功能类似于Deployment,但StatefulSet专用于编排有状态应用
Job 有终止期限的一次性作业式任务,而非一直处于运行状态的服务进程;
CronJob 有终止期限的周期性作业式任务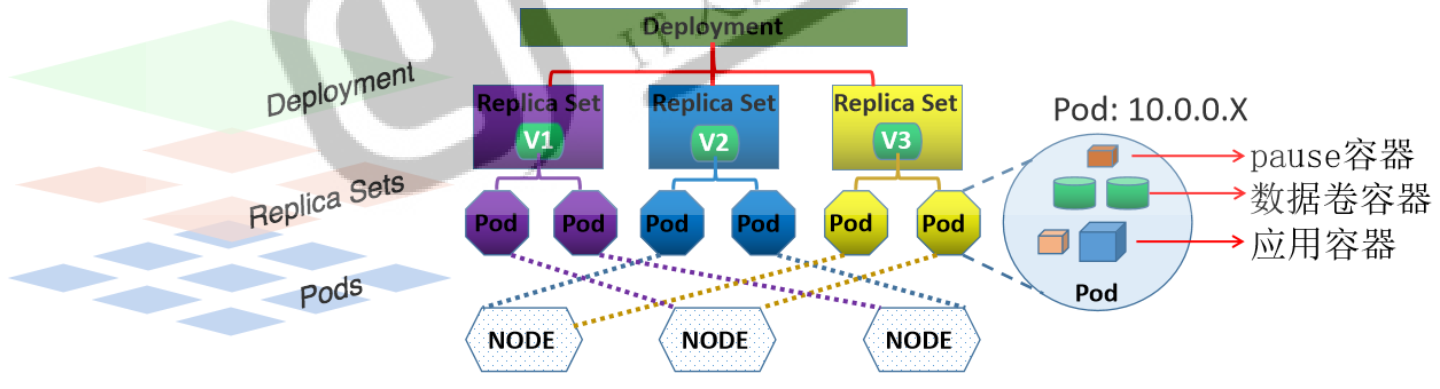
标签
控制器主要是通过管理pod来实现任务的编排效果,那么控制器是通过什么机制找到pod的呢?—- 标签 或者 标签选择器
关于label的操作主要有两种:
- 资源文件方式
```bash
资源对象Lablel不是单独定义的,是需要依附在某些资源对象上才可以,常见的就是依附在Pod对象上。
apiVersion: v1
kind: Pod
metadata:
name: nginx-test
labels:
app: nginx
release: 1.21.3
arch: frontend
role: proxy
spec:
containers:
- name: nginx
image: 10.0.0.19:80/mykubernetes/nginx:1.21.3
env:
- name: HELLO value: “Hello kubernetes nginx”
- name: nginx
image: 10.0.0.19:80/mykubernetes/nginx:1.21.3
env:
kubectl get pod pod-test —show-labels kubectl get pods -l app=nginx #列出指定的标签
2. 命令行方式
`kubectl get pods -l label_name=label_value ` 查看标签<br />`kubectl label 资源类型 资源名称 label_name=label_value` 增加标签
<a name="swMbk"></a>
### 标签选择器
Lablel附加到Kubernetes集群中的各种资源对象上,目的对这些资源对象进行分组管理,而分组管理的核心就是:Lablel Selector。<br />分组管理原理:我们可以通过Label Selector(标签选择器)查询和筛选某些特定Label的资源对象,进而可以对他们进行相应的操作管理,类似于我们的sql语句中where的条件:select * from where ... <br />Lablel Selector跟Label一样,不能单独定义,必须附加在一些资源对象的定义文件上。一般附加在RC和Service的资源定义文件中。
```bash
Label Selector使用时候有两种常见的表达式:等式和集合
1.等式:
name = nginx 匹配所有具有标签 name = nginx 的资源对象
name != nginx 匹配所有不具有标签 name = nginx 的资源对象
2.集合:
env in (dev, test) 匹配所有具有标签 env = dev 或者 env = test 的资源对象
name not in (frontend) 匹配所有不具有标签 name = frontend 的资源对象
随着Kubernetes功能的不断完善,集合表达式逐渐有了两种规范写法:匹配标签、匹配表达式
1.匹配标签:
matchLabels:
name: nginx
2.匹配表达式:
matchExpressions:
- {key: name, operator: NotIn, values: [frontend]}
常见的operator操作属性值有:In、NotIn、Exists、NotExists等,Exists和DostNotExist时,values必须为空,即:
{ key: environment, opetator: Exists,values:}
注意:这些表达式,一般应用在RS、RC、Deployment等其它管理对象中。
应用场景:监控具体的Pod、负载均衡调度、定向调度,常用于 Pod、Node等资源对象,当设env=dev的Label Selector,会匹配到Node1和Node2上的Pod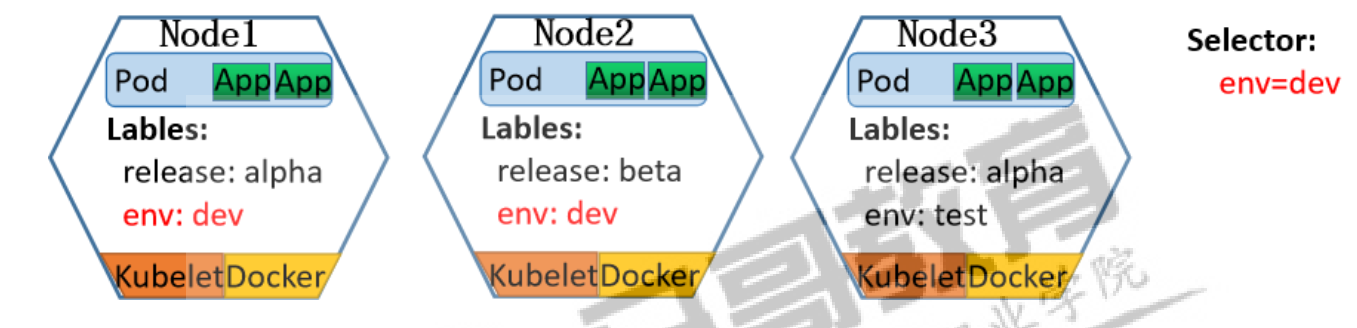
1.命令方式
1.等值过滤
kubectl get pods -l env=prod
kubectl get pods -l env==prod
kubectl get pods -l app!=nginx
kubectl get pods -l app
kubectl get pods -l '!app'
2.集合过滤
kubectl get pods -l "app in (nginx-test, hah, heh)" #多条件取交集
kubectl get pods -l "app notin (nginx, hah, heh)"
3.删除标签
kubectl label pod nginx-test pro- release-
2.配置文件
kubectl run nginx-test1 --image=10.0.0.19:80/mykubernetes/pod_test:v0.1 --labels="app=nginx"
kubectl run nginx-test2 --image=10.0.0.19:80/mykubernetes/pod_test:v0.1 --labels="app=nginx"
kubectl run nginx-test3 --image=10.0.0.19:80/mykubernetes/pod_test:v0.1 --labels="app=nginx1"
kubectl get pod --show-labels -o wide
kind: Service
apiVersion: v1
metadata:
name: service-test
spec:
selector:
app: nginx
ports:
- name: http
protocol: TCP
port: 80
targetPort: 80
kubectl apply -f 03-pod-service.yml
kubectl get svc -o wide
kubectl describe svc service-test #结果显示service自动关联了两个Endpoints
TargetPort: 80/TCP
Endpoints: 10.244.1.10:80,10.244.1.9:80
curl 10.103.78.193
curl: (7) Failed to connect to 10.103.78.193 port 80: Connection refused
结果显式:后端随机代理到不同的pod应用了
RC
Replication Controller(RC),是kubernetes系统中的核心概念之一。RC是Kubernetes集群实现Pod资源对象自动化管理的基础。
简单来说,RC其实是定义了一个期望的场景,RC有以下特点:
1.组成:定义了Pod副本的期望状态:包括数量,筛选标签和模板
- Pod期待的副本数量(replicas).
- 永远筛选目标Pod的标签选择器(Label Selector)
- Pod数量不满足预期值,自动创建Pod时候用到的模板(template)
2.意义:自动监控Pod运行的副本数目符合预期,保证Pod高可用的核心组件,常用于Pod的生命周期管理
RC资源对象定义文件遵循资源对象定义文件格式,spec期望的部分是RC主要内容。例:编辑一个04-controller-rc.yaml文件,由RC自动控制Pod资源对象的预期状态效果:运行2个nginx容器,运行的容器携带两个标签,运行容器的模板文件在sepc.template.spec部分
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 2
selector:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx-container
image: 10.0.0.19:80/mykubernetes/nginx:1.21.3
当我们通过"资源定义文件"定义好了一个RC资源对象,把它提交到Kubernetes集群中以后,Master节点上的Controller Manager组件就得到通知(问:为什么?因为什么?),定期巡检系统中当前存活的Pod,并确保Pod实例数量刚到满足RC的期望值。
如果Pod数量大于RC定义的期望值,那么就杀死一些Pod
如果Pod数量小于RC定义的期望值,那么就创建一些Pod
通过RC资源对象,Kubernetes实现了业务应用集群的高可用性,大大减少了人工干预,提高了管理的自动化。
想要扩充Pod副本的数量,可以直接修改replicas的值即可
当其中一个Node的Pod意外终止,根据RC的定义,Pod的期望值是2,所以会随机找一个Node结点重新再创建一个新的Pod,来保证整个集群中始终存在两个Pod运行
删除RC并不会影响通过该RC资源对象创建好的Pod。如果要删除所有的Pod那么可以设置RC的replicas的值为0,然后更新该RC。
另外kubectl提供了stop和delete命令来一次性删除RC和RC控制的Pod。
Pod提供的是无状态服务,不会影响到客户的访问效果
RS
Replication Controller与Kubernetes代码中的模块Replication Controller同名,而且这个名称无法准确表达其本意:Pod副本的控制,所以从kubernetes v1.2开始,它就升级成了一个新的概念:Replica Set(RS)。
RS和RC两者功能上没有太大的区别,只不过是表现形式上不一样:
- RC中的Label Selector是基于等式的
- RS中的Label Selector是基于集合的 #这就使得Replica Set的功能更强大
实现逻辑:
Controller Manager根据ReplicaSet Control Loop管理 ReplicaSet Object,由该对象向API Server请求管理Pod对象(标签选择器选定的)
如果没有pod:以Pod模板向API Server请求创建Pod对象,由Scheduler调度并绑定至某节点,由相应节点kubelet负责运行。
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: replicaset-test
spec:
minReadySeconds: 0
replicas: 3
selector:
matchLabels:
app: rs-test
release: stable
version: v1.0
template:
metadata:
labels:
app: rs-test
release: stable
version: v1.0
spec:
containers:
- name: rs-test
image: 10.0.0.19:80/mykubernetes/pod_test:v0.1
RC调整Pod数量
基于对象调整副本数:kubectl scale --replicas=5 rc/rc_name
基于文件调整副本数:kubectl scale --replicas=3 -f rc_name.yaml
更新命令:kubectl set image 资源类型/资源名称 pod名称=镜像版本
kubectl set image replicaset/replicaset-test rs-test=10.0.0.19:80/mykubernetes/pod_test:v0.2
结果显示:虽然镜像的模板信息更新了,但是pod的访问效果没有变
RS遵循的是删除式更新,也就是说,只有删除老的replicaset,新生成的pod才会使用新的模板信息
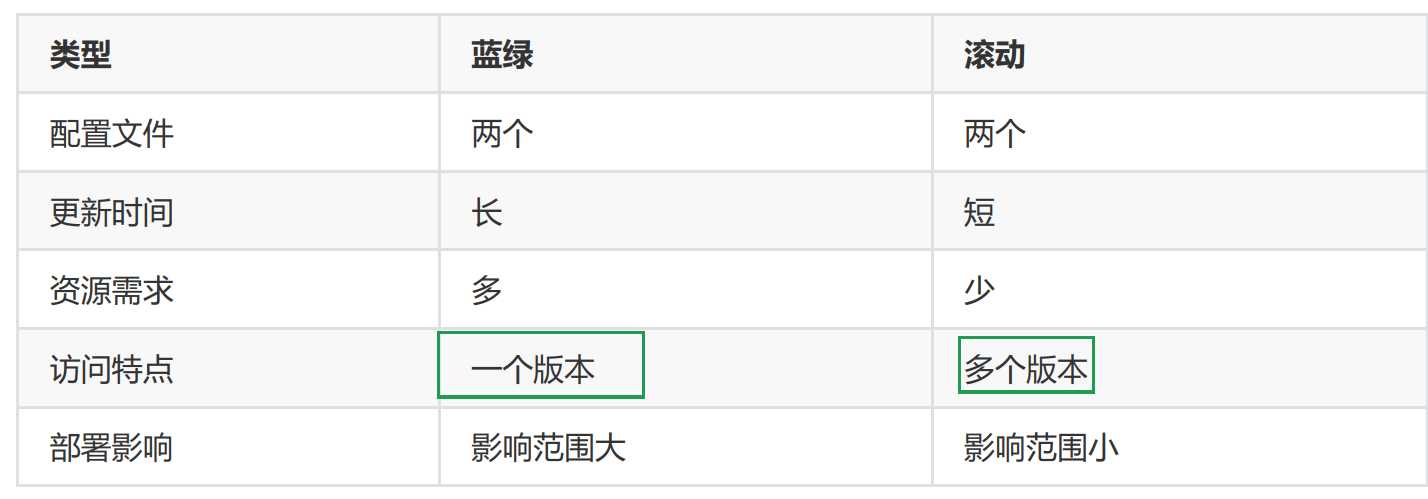
1.滚动更新
apiVersion: v1
kind: Service
metadata:
name: replicaset-svc
spec:
type: ClusterIP
selector:
app: rs-test
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
kubectl apply -f 06-controller-replicaset-svc.yaml
kubectl run pod-$RANDOM --image=10.0.0.19:80/mykubernetes/admin-box:v0.1 -it --rm --command -- /bin/bash
while true; do curl --connect-timeout 1 replicaset-svc.default.svc; sleep 2;done
准备两个版本的RS,更改 07-controller-replicaset-2.yaml 的版本信息和镜像版本
cp 05-controller-replicaset.yaml 07-controller-replicaset-1.yaml
cp 05-controller-replicaset.yaml 07-controller-replicaset-2.yaml
由于两个RS的标签不一样,所以可以同时启动,只不过一个数量为1,一个数量为0
kubectl apply -f 07-controller-replicaset-1.yaml
kubectl apply -f 07-controller-replicaset-2.yaml
轮询将1版本减1,2版本加1,结果显式:更新的过程中,新旧版本是共存的效果
2.蓝绿更新
apiVersion: v1
kind: Service
metadata:
name: replicaset-blue-green
spec:
type: ClusterIP
selector:
app: rs-test
ctr: rs-${DEPLOY}
version: ${VERSION}
ports:
- name: http
port: 80
protocol: TCP
targetPort: 80
---
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: rs-${DEPLOY}
spec:
minReadySeconds: 3
replicas: 2
selector:
matchLabels:
app: rs-test
ctr: rs-${DEPLOY}
version: ${VERSION}
template:
metadata:
labels:
app: rs-test
ctr: rs-${DEPLOY}
version: ${VERSION}
spec:
containers:
- name: pod-test
image: 10.0.0.19:80/mykubernetes/pod_test:${VERSION}
基于envsubst的方式生成对应的文件,效果如下
DEPLOY=blue VERSION=v0.1 envsubst < 08-controller-replicaset-blue-green | kubectl apply -f -
发布绿版本
DEPLOY=green VERSION=v0.2 envsubst < 08-controller-replicaset-blue-green | kubectl apply -f -
结果显式:
进行蓝绿部署的时候,必须等到所有新的版本更新完毕后,再开放新的service,否则就会导致服务中断的效果
Deployment
Deployment资源对象在内部使用Replica Set来实现Pod的自动化编排。Deployment资源对象不管是在作用、文件定义格式、具体操作等方面都可以看做RC的一次升级,两者的相似度达90%。(高度自动化的pod管理控制器 )
相对于RC的一个最大的升级是:我们可以随时知道当前Pod的”部署”进度,即Pod创建--调度--绑定Node--在目标Node上启动容器
Deployment的定义与Replica Set除了API声明与Kind类型有所区别其他基本一样。 不过 Deployment对滚动更新多了更新策略的内容
maxSurge # 更新期间可比期望的Pod数量多出的数量或比例;(先添加)
maxUnavailable # 更新期间可比期望的Pod数量缺少的数量或比例;(先减少)
minReadySeconds # 在等待设置的时间后才进行升级
1.创建命令
kubectl create deployment pod-test --image=10.0.0.19:80/mykubernetes/pod_test:v0.1 --replicas=3
2.创建资源对象文件
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-test
spec:
replicas: 3
selector:
matchLabels:
app: rs-test
template:
metadata:
labels:
app: rs-test
spec:
containers:
- name: nginxpod-test
image: 10.0.0.19:80/mykubernetes/pod_test:v0.1
kubectl apply -f 09-controller-deployment-test.yaml
kubectl get deployments.apps
kubectl get rs deployment-test-656d6db766
kubectl get pod deployment-test-656d6db766-2mb9s
kubectl describe deployment deployment-test 查看deployment的详细过程
1.扩容缩容
基于资源对象调整:kubectl scale --current-replicas=3 --replicas=5 deployment/deploy_name(携带当前副本数量信息)
kubectl scale --replicas=2 deployment/deployment-test(不携带当前副本数量信息)
基于资源文件调整:kubectl scale --replicas=4 -f deploy_name.yaml
2.动态更新
kubectl set image deployment/deployment-test nginxpod-test='10.0.0.19:80/mykubernetes/pod_test:v0.1' --record=true
kubectl set image deployment/deployment-test nginxpod-test='10.0.0.19:80/mykubernetes/pod_test:v0.2' --record=true
kubectl rollout status deployment deployment-test 更新状态
kubectl rollout history deployment deployment-test 更新历史
kubectl rollout undo deployment deployment-test 撤销更改
kubectl rollout undo --to-revision=3 deployment deployment-test 回到版本3(将3号重新执行一遍,原来的3号就没了)
kubectl rollout pause deployment deployment-test 标记提供的resource为中止状态,仅支持 deployment对象
kubectl rollout status deployment deployment-test 显示 rollout 的状态
kubectl rollout resume deployment deployment-test 继续一个停止的 resource
kubectl patch deployment deployment-test -p '{"spec":{"replicas":2}}' 修改副本数量
kubectl patch deployment deployment-test -p '{"spec":{"strategy":{"rollingUpdate":{"maxSurge":1,"maxUnavailable":0}}}}'
DaemonSet
DaemonSet能够让所有(或者特定)的节点”精确的”运行同一个pod,它一般应用在集群环境中所有节点都必须运行的守护进程的场景。我们在部署k8s环境的时候,网络的部署样式就是基于这种DaemonSet的方式,因为对于网络来说,是所有节点都必须具备的基本能力,而且不能随意中断,否则的话,节点上的容器通信就会出现问题。grep kind kube-flannel.yml
kubectl get ds -n kube-system
当节点加入到K8S集群中,pod会被(DaemonSet)调度到该节点上运行,当节点从K8S集群中被移除,被DaemonSet调度的pod会被移除,如果删除DaemonSet,所有跟这个DaemonSet相关的pods都会被删除。
在某种程度上,DaemonSet承担了RC的部分功能,它也能保证相关pods持续运行,如果一个DaemonSet的Pod被杀死、停止、或者崩溃,那么DaemonSet将会重新创建一个新的副本在这台计算节点上。
常用于后台支撑服务
集群存储守护进程,如:glusterd,ceph
日志收集服务,如:fluentd,logstash
监控服务,如:Prometheus,collectd
之前我们在Node上启动Pod需要在RC中指定replicas的副本数的值,有些情况下,我们需要在所有节点都运行一个Pod,因为Node数量会变化,所以Pod的副本数使用RC来指定就不合适了,这个时候Daemon Sets就派上了用场。简单来说,Daemon Sets就是让一个pod在所有的k8s集群节点上都运行一个。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: daemonset-test
spec:
selector:
matchLabels:
app: pod-test
template:
metadata:
labels:
app: pod-test
spec:
containers:
- name: pod-test
image: 10.0.0.19:80/mykubernetes/pod_test:v0.2
kubectl create -f 11-controller-daemonset-test.yaml
kubectl get daemonset
daemonset对象也支持滚动更新,不支持pause动作
kubectl set image daemonsets daemonset-test pod-test='10.0.0.19:80/mykubernetes/pod_test:v0.1' --record=true
实践2 - 监控软件在所有节点上都部署采集数据的功能
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: daemonset-demo
namespace: default
labels:
app: prometheus
component: node-exporter
spec:
selector:
matchLabels:
app: prometheus
component: node-exporter
template:
metadata:
name: prometheus-node-exporter
labels:
app: prometheus
component: node-exporter
spec:
containers:
- image: 10.0.0.19:80/mykubernetes/node-exporter:v1.2.2
name: prometheus-node-exporter
ports:
- name: prom-node-exp
containerPort: 9100
hostPort: 9100
livenessProbe:
tcpSocket:
port: prom-node-exp
initialDelaySeconds: 3
readinessProbe:
httpGet:
path: '/metrics'
port: prom-node-exp
scheme: HTTP
initialDelaySeconds: 5
hostNetwork: true
hostPID: true
kubectl apply -f 12-controller-daemonset-prometheus.yaml
job
在k8s场景中,关于job的执行,主要有两种类型
串行job:即所有的job任务都在上一个job执行完毕后,再开始执行
并行job:如果存在多个job,我们可以设定并行执行的job数量。
串行运行共5次任务:
spec
parallelism: 1
completion: 5
并行2队列共运行5次任务:
spec
parallelism: 2
completion: 5
对于job来说,他的重启策略只有两种:仅支持Never和OnFailure两种,不支持Always,否则的话就成死循环了。
实践1:单个任务
apiVersion: batch/v1
kind: Job
metadata:
name: job-single
spec:
template:
metadata:
name: job-single
spec:
restartPolicy: Never
containers:
- name: job-single
image: 10.0.0.19:80/mykubernetes/admin-box:v0.1
command: [ "/bin/sh", "-c", "for i in 9 8 7 6 5 4 3 2 1; do echo $i; sleep 2; done" ]
kubectl apply -f 13-controller-job-single.yaml (job任务执行完毕后,状态是 Completed)
实践2:多个串行任务
apiVersion: batch/v1
kind: Job
metadata:
name: job-multi-chuan
spec:
completions: 5
parallelism: 1
template:
spec:
containers:
- name: job-multi
image: 10.0.0.19:80/mykubernetes/admin-box:v0.1
command: ["/bin/sh","-c","echo job; sleep 3"]
restartPolicy: OnFailure
kubectl apply -f 14-controller-job-multi-chuan.yaml
kubectl get job
job_list=$(kubectl get pod | grep job | sort -k 5 | awk '{print $1}')
for i in $job_list; do kubectl logs $i --timestamps=true; done
结果显示:这些任务,确实是串行的方式来执行,由于涉及到任务本身是启动和删除,所以时间间隔要大于3s
实践3 - 并行任务
apiVersion: batch/v1
kind: Job
metadata:
name: job-multi-bing
spec:
completions: 6
parallelism: 2
template:
spec:
containers:
- name: job-multi-bing
image: 10.0.0.19:80/mykubernetes/admin-box:v0.1
command: ["/bin/sh","-c","echo job; sleep 3"]
restartPolicy: OnFailure
kubectl apply -f 15-controller-job-multi-bing.yaml
job_list=$(kubectl get pod | grep job | sort -k 5 | awk '{print $1}')
for i in $job_list; do kubectl logs $i --timestamps=true; done
结果显示:这6条任务确实是两两并行执行的
CronJob
CronJob其实就是在Job的基础上加上了时间调度,我们可以:在给定的时间点运行一个任务,也可以周期性地在给定时间点运行。其效果与linux中的crontab效果非常类似,一个CronJob对象其实就对应中crontab文件中的一行,它根据配置的时间格式周期性地运行一个Job,格式和crontab也是一样的。
crontab的格式如下:
分 时 日 月 周 命令
(0~59) (0~23) (1~31) (1~12) (0~7)
apiVersion: batch/v1
kind: CronJob
metadata:
name: cronjob
spec:
schedule: "*/2 * * * *"
jobTemplate:
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- name: cronjob
image: 10.0.0.19:80/mykubernetes/admin-box:v0.1
command: ["/bin/sh","-c","echo job"]
kubectl apply -f 16-controller-cronjob-simple.yaml
实践2 - 秒级周期任务
apiVersion: batch/v1
kind: CronJob
metadata:
name: cronjob-second
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- name: cronjob
image: 10.0.0.19:80/mykubernetes/admin-box:v0.1
command: ["/bin/sh","-c","i=0; until [ $i -eq 60 ]; do sleep 10; let i=i+10; echo $i job; done"]
kubectl apply -f 17-controller-cronjob-second.yaml

若有收获,就点个赞吧
0 人点赞
