官方:https://kubernetes.io/
Kubernetes是分布式架构,从Kubernetes的架构图上来看,Kubernetes集群存在有Master和Node(即slave)两种类型的节点,彼此间基于API进行通信。
🔣辅助环境
1.同步/etc/hosts和ssh验证
1.同步主机名解析/etc/hosts10.0.0.12 master1.sswang.com master110.0.0.13 master2.sswang.com master210.0.0.14 master3.sswang.com master310.0.0.15 node1.sswang.com node110.0.0.16 node2.sswang.com node210.0.0.17 ha1.sswang.com ha110.0.0.18 ha2.sswang.com ha210.0.0.19 register.sswang.com register2.实现主机间免密认证#!/bin/bash#--------------------------设置ssh跨主机免密码认证apt install expect -y[ -d /root/.ssh ] && rm -rf /root/.sshssh-keygen -t rsa -P "" -f /root/.ssh/id_rsa#--------------------------取消ssh通信时候的指纹认证sed -i '/ask/{s/#/ /; s/ask/no/}' /etc/ssh/ssh_config#--------------------------跨主机密码认证for i in {12..19}doexpect -c "spawn ssh-copy-id -i /root/.ssh/id_rsa.pub root@10.0.0.$iexpect {\"*yes/no*\" {send \"yes\r\"; exp_continue}\"*assword*\" {send \"root\r\"; exp_continue}\"*assword*\" {send \"root\r\";}} "donefor i in master{1..3} node{1..2} ha{1..2} registerdoexpect -c "spawn ssh-copy-id -i /root/.ssh/id_rsa.pub root@$iexpect {\"*yes/no*\" {send \"yes\r\"; exp_continue}\"*assword*\" {send \"root\r\"; exp_continue}\"*assword*\" {send \"root\r\";}} "done#--------------------------所有主机用同一套主机文件for i in {12..19}doscp -rp /etc/hosts root@10.0.0.$i:/etc/hostsdone#--------------------------设定主机名for i in master{1..3} node{1..2} ha{1..2} registerdossh root@$i "hostnamectl set-hostname $i"# ssh root@$i "hostname"done
2.禁用swap分区
1.关闭当前已启用的所有Swap设备:
swapoff -a
2.编辑/etc/fstab配置文件,注释用于挂载Swap设备的所有行。
方法一:手工编辑
vim /etc/fstab
# UUID=0a55fdb5-a9d8-4215-80f7-f42f75644f69 none swap sw 0 0
方法二:
sed -i 's/.*swap.*/#&/' /etc/fstab #替换后位置的&代表前面匹配的整行内容
注意:只需要注释掉自动挂载SWAP分区项即可,防止机子重启后swap启用
3.内核(禁用swap)参数
cat >> /etc/sysctl.d/k8s.conf << EOF
vm.swappiness=0
EOF
sysctl -p /etc/sysctl.d/k8s.conf
3.开启内核转发供能
1.配置iptables参数,使得流经网桥的流量也经过iptables/netfilter防火墙
cat >> /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
2.配置生效
modprobe br_netfilter
modprobe overlay
sysctl -p /etc/sysctl.d/k8s.conf
#脚本执行
for i in 10.0.0.{12..19};do {
scp 02-k8s-base_env.sh $i:/root/
ssh $i "/root/02-k8s-base_env.sh"
}
done
4.安装docker,定制启动方式Cgroupfs—->systemd)
1.编辑软件安装脚本 docker_install.sh
#!/bin/bash
apt-get update
apt-get install apt-transport-https ca-certificates curl gnupg lsb-release -y
curl -fsSL https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
echo \
"deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list >/dev/null
apt-get update
apt-get -y install docker-ce docker-ce-cli containerd.io # 安装软件
echo '{"registry-mirrors": ["http://74f21445.m.daocloud.io"], "insecureregistries": ["10.0.0.19:80"]}' > /etc/docker/daemon.json # 加速器配置
systemctl restart docker;systemctl enable docker # 重启服务
2.定制Docker的启动方式
vim /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd --exec-opt native.cgroupdriver=systemd -H fd:// --containerd=/run/containerd/containerd.sock
或者
vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
systemctl daemon-reload;systemctl restart docker
检查:docker info | grep Cgroup
for i in 10.0.0.{12..16};do
> scp 03-docker_install.sh $i:/root/
> ssh $i "bash /root/03-docker_install.sh"
> done
5.kubeadm软件源配置及安装
1.kubeadm软件源的配置
apt-get update && apt-get install -y apt-transport-https
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
cat >/etc/apt/sources.list.d/kubernetes.list <<EOF
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
apt-get update
apt-cache madison kubeadm #查看支持的软件版本
2.软件的安装
主节点:nftables,kubelet, kubeadm, kubectl
从节点:nftables,kubelet, kubeadm
kubeadm 主要是对k8s集群来进行管理的,所以在master角色主机上安装
kubelet 是以服务的方式来进行启动,主要用于收集节点主机的信息
kubectl 主要是用来对集群中的资源对象进行管控,一半情况下,node角色的节点是不需要安装的
镜像的获取脚本
#!/bin/bash
# 从新的地址下载所需镜像
images=$(kubeadm config images list --kubernetes-version=v1.22.1 | awk -F "/" '{print $2}')
for i in ${images}
do
docker pull registry.aliyuncs.com/google_containers/$i
docker tag registry.aliyuncs.com/google_containers/$i k8s.gcr.io/$i
docker rmi registry.aliyuncs.com/google_containers/$i
done
🔣部署单主分布式集群
部署主节点master
apt install -y kubelet=1.22.1-00 kubeadm=1.22.1-00 kubectl=1.22.1-00
1.配置kubelet的cgroups
DOCKER_CGROUPS=$(docker info | grep 'Cgroup Driver' | cut -d ' ' -f4)
echo $DOCKER_CGROUPS
systemctl enable kubelet
2.查看所需镜像,并拉取。上传至harbor供其他节点使用
kubeadm config images list --kubernetes-version=v1.22.1
3.启动一个主节点
kubeadm init --kubernetes-version=1.22.1 \
--apiserver-advertise-address=10.0.0.12 \
--image-repository 10.0.0.19:80/google_containers \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16 \
--ignore-preflight-errors=Swap
mkdir -p $HOME/.kube #根据提示配置环境(3条命令)
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
export KUBECONFIG=/etc/kubernetes/admin.conf
4.kubectl get cs #默认的配置文件中对于端口的定制做了操作,注释掉port,停掉默认端口
grep -ni '#' /etc/kubernetes/manifests/kube-scheduler.yaml
5.kubectl get nodes #cni网络报错,需要配置一下网络,安装网络插件
cd ~ && mkdir flannel && cd flannel
docker pull quay.io/coreos/flannel:v0.14.0-amd64 #先下载好flannel:v0.14.0-amd64然后在来应用该文件
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yml(报错1)
kubectl get pod -n kube-system
kubectl get ns
kubectl describe nodes | grep -i taint #获取污点信息
kubeadm token list #查看token的实效
kubeadm token create --print-join-command
kubectl describe node master1 #获取节点的基本信息
部署节点node
部署异常中断,清理环境
rm -rf /etc/kubernetes/*
docker rm -f $(docker ps -a -q)
rm -rf /etc/cni/* # 清除容器的网络接口
apt-get install -y kubelet=1.22.1-00 kubeadm=1.22.1-00
systemctl enable kubelet
kubeadm config images list --kubernetes-version=v1.22.1 #拉取所需镜像
1.加入集群
kubeadm token create --print-join-command #重新生成加入集群的token
kubeadm join 10.0.0.12:6443 --token 8e6svw.58surb6luz2hoiw1 \
--discovery-token-ca-cert-hash sha256:a699ddf40e9b53d6815c22ebccda4dfb99fca75c0d8c5568e5843d84ce147a1f
2.kubectl get nodes(新增结点一直都是NoReady,那么就来查看新结点的kubelet服务)
mkdir -p /etc/cni/net.d/
cat > /etc/cni/net.d/10-flannel.conf <<EOF
{"name":"cbr0","type":"flannel","delegate": {"isDefaultGateway": true}}
EOF
mkdir /usr/share/oci-umount/oci-umount.d -p
mkdir /run/flannel/
cat > /run/flannel/subnet.env <<EOF
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.1.0/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
EOF
命令补全功能
kubectl completion bash
source <(kubectl completion bash)
echo "source <(kubectl completion bash)" >> ~/.bashrc
节点移除
1.在master节点上执行步骤:
kubectl drain node16 --delete-local-data --force --ignore-daemonsets
kubectl delete node node16
2.在node节点上移除历史记录文件
kubeadm reset
systemctl stop kubelet docker
rm -rf /etc/kubernetes/
ifconfig cni0 down
dashboard部署
1.获取官方的yaml文件,稍作修改
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.3.1/aio/deploy/recommended.yaml
ports:
- port: 443
targetPort: 8443
nodePort: 30443 #添加
type: NodePort #添加
docker pull kubernetesui/dashboard:v2.3.1 #依赖这两个镜像
docker pull kubernetesui/metrics-scraper:v1.0.6
kubectl apply -f recommended.yaml
2.kubectl get all -n kubernetes-dashboard
3.访问:https://10.0.0.12:30443/
kubeconfig 内部依赖于token功能,所以先来测试一下token的连接方式。生成访问token相关的信息
kubectl create serviceaccount dashboard-admin -n kube-system
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
kubectl -n kube-system get secret | grep dashboard-admin
kubectl describe secrets -n kube-system dashboard-admin-token-bpkxs
#复制token部分的代码,拷贝到浏览器里面的"输入token"部分,然后点击登录
🔣部署高可用分布式集群
对于生产的集群,原则上允许节点挂的数量需要遵循一个原则,剩余的节点数量要大于 n/2 个整数,其根本原因在于,所有节点的属性信息都保存在etcd中,而etcd是一个分布式的,一致的 keyvalue 存储,它遵循分布式一致性的基本节点要求
部署镜像仓库harbor
apt-get -y install docker-compose
mkdir /data/softs -p;cd /data/softs
wget https://github.com/goharbor/harbor/releases/download/v2.3.2/harbor-offline-installer-v2.3.2.tgz
tar -zxvf harbor-offline-installer-v2.3.2.tgz -C /usr/local/
cd /usr/local/harbor/
docker load < harbor.v2.3.2.tar.gz
cp harbor.yml.tmpl harbor.yml
vim harbor.yml
hostname: 10.0.0.19
http:
port: 80
#https: 注释ssl相关的部分
# port: 443
# certificate: /your/certificate/path
# private_key: /your/private/key/path
harbor_admin_password: 123456
data_volume: /data/harbor
./prepare #配置harbor
./install.sh #启动harbor
浏览器访问:10.0.0.19:80
创建工作账号:zhuyuany/Zhuyuany123
创建仓库:zhuyuany(公开)
vim /lib/systemd/system/harbor.service #通过service文件实现开机自启动
[Unit]
Description=Harbor
After=docker.service systemd-networkd.service systemd-resolved.service
Requires=docker.service
Documentation=http://github.com/vmware/harbor
[Service]
Type=simple
Restart=on-failure
RestartSec=5
ExecStart=/usr/bin/docker-compose -f /usr/local/harbor/docker-compose.yml up
ExecStop=/usr/bin/docker-compose -f /usr/local/harbor/docker-compose.yml down
[Install]
WantedBy=multi-user.target
systemctl daemon-reload;systemctl enable harbor
systemctl start harbor
systemctl status harbor
修改docker的不安全仓库
vim /etc/docker/daemon.json
{"registry-mirrors": ["http://74f21445.m.daocloud.io"], "insecure-registries":["10.0.0.19:80"]}
systemctl restart docker
docker info | grep -A1 Insecure #检查效果
登录仓库
docker login 10.0.0.19:80(用admin账号)
docker tag goharbor/nginx-photon:v2.3.2 10.0.0.19:80/zhuyuany/nginx-photon:v2.3.2
docker push 10.0.0.19:80/zhuyuany/nginx-photon:v2.3.2 #提交
docker images |tr -s ' '|awk -F' ' '/10.0.0.19.*/{print $1,$2}'|while read repo version; do docker push $repo:$version; done
因为默认情况下docker仓库是基于https方式来进行登录的,而我们的没有定制https所以,这里的仓库地址必须是 ip:port方式
docker pull 10.0.0.19:80/zhuyuany/nginx-photon:v2.3.2 #下载
部署高可用ha+ka
vim /etc/haproxy/haproxy.cfg #haproxy配置
...
listen stats
bind 10.0.0.200:9999
mode http
log global
stats enable
stats uri /haproxy-stats
stats auth haadmin:123456
listen k8s-api-6443
bind 10.0.0.200:6443
mode tcp
server master1 10.0.0.12:6443 check inter 3s fall 3 rise 5
server master2 10.0.0.13:6443 check inter 3s fall 3 rise 5
server master3 10.0.0.14:6443 check inter 3s fall 3 rise 5
haproxy -f /etc/haproxy/haproxy.cfg -c
systemctl enable --now haproxy;systemctl status haproxy
网页访问:http://haadmin:123456@10.0.0.200:9999/haproxy-stats
vim /etc/nginx/nginx.conf
server 10.0.0.12:6443 weight=1 fail_timeout=5s max_fails=3; #后端服务器状态监测
server 10.0.0.13:6443 weight=1 fail_timeout=5s max_fails=3;
server 10.0.0.14:6443 weight=1 fail_timeout=5s max_fails=3;
}
server {
listen 10.0.0.200:6443;
location /{
proxy_pass http://k8s-api-6443/;
}
}
apt install keepalived haproxy -y
vim /etc/keepalived/keepalived.conf #keepalived主配置文件
global_defs {
router_id 17
}
vrrp_script chk_haproxy {
script "/etc/keepalived/check_haproxy.sh"
interval 2
weight 2
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 78
priority 100
unicast_src_ip 10.0.0.17
unicast_peer {
10.0.0.18
}
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
chk_haproxy
}
virtual_ipaddress {
10.0.0.200
}
}
vim /etc/keepalived/keepalived.conf #keepalived从配置文件
global_defs {
router_id 18
}
vrrp_script chk_haproxy {
script "/etc/keepalived/check_haproxy.sh"
interval 2
weight 2
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 78
priority 80
unicast_src_ip 10.0.0.18
unicast_peer {
10.0.0.17
}
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
chk_haproxy
}
virtual_ipaddress {
10.0.0.200
}
}
vim /etc/keepalived/check_haproxy.sh #编写检测脚本
#!/bin/bash
haproxy_status=$(ps -C haproxy --no-header | wc -l)
if [ $haproxy_status -eq 0 ];then
systemctl start haproxy
sleep 3
if [ $(ps -C haproxy --no-header | wc -l) -eq 0 ];then
killall keepalived
fi
fi
chmod +x /etc/keepalived/check_haproxy.sh #一定要加执行权限
systemctl start keepalived;systemctl enable keepalived;systemctl status keepalived
部署主节点master
如果节点添加失败,则执行下面两条命令可以让环境还原
kubeadm reset
rm -rf /etc/kubernetes/*
rm -rf .kube
apt install -y kubelet=1.22.1-00 kubeadm=1.22.1-00 kubectl=1.22.1-00
kubeadm config images list --kubernetes-version=v1.22.1 #查看并拉取所需镜像
#镜像的获取脚本
#!/bin/bash
images=$(kubeadm config images list --kubernetes-version=v1.22.1 | awk -F "/" '{print $2}')
for i in ${images}
do
docker pull registry.aliyuncs.com/google_containers/$i
docker tag registry.aliyuncs.com/google_containers/$i k8s.gcr.io/$i
docker rmi registry.aliyuncs.com/google_containers/$i
done
1.master1节点集群初始化
kubeadm init --kubernetes-version=1.22.1 \
--apiserver-advertise-address=10.0.0.12 \
--control-plane-endpoint=10.0.0.200 \
--apiserver-bind-port=6443 \
--image-repository 10.0.0.19:80/google_containers \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16 \
--ignore-preflight-errors=Swap
mkdir -p $HOME/.kube #赋予权限
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
export KUBECONFIG=/etc/kubernetes/admin.conf
cd ~ && mkdir flannel && cd flannel #网络容器
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yml
2.添加节点,在集群初始化节点上生成通信认证的key:
kubeadm init phase upload-certs --upload-certs
kubeadm join 10.0.0.200:6443 --token p4roz0.3gdaemp992ecb0tu \
--discovery-token-ca-cert-hash sha256:79f2a6930ee227242e67f9e2aa8dd48fb286642351b5620bdc7e09e55a01161f \
--control-plane --certificate-key [认证key]
kubeadm join 10.0.0.200:6443 --token i2it5v.ef3f7wvdnx4s8kej \
--discovery-token-ca-cert-hash sha256:bc742029bd8515bf2e7228384a2cb0eed78bf4a4be5a6c5681464f6e69edd359 \
--control-plane --certificate-key 76b5b5f8d84a8903c82f2f56a0eb08287843bae40d48e018ee7b2ba91b90ca93
#如果是通过haproxy的方式来进行负载均衡的话,在环境初始化的时候,最好部署好一个master,添加一条负载记录。
mkdir -p $HOME/.kube #赋予权限
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
查看效果
kubectl get nodes
如果状态为NotReady
systemctl restart kubelet
移除master节点
移除普通master节点的方法与移除普通节点的方式很相像
kubectl drain master3 --delete-local-data --force --ignore-daemonsets
kubectl delete node master3
最后一个节点的环境清空
kubect reset
rm -rf /etc/kubernetes
部署节点node
apt-get install -y kubelet=1.22.1-00 kubeadm=1.22.1-00
systemctl enable kubelet
kubeadm join 10.0.0.200:6443 --token i2it5v.ef3f7wvdnx4s8kej \
--discovery-token-ca-cert-hash sha256:bc742029bd8515bf2e7228384a2cb0eed78bf4a4be5a6c5681464f6e69edd359
查看效果
kubectl get nodes
如果状态为NotReady,查看kubelet服务
mkdir -p /etc/cni/net.d/
cat > /etc/cni/net.d/10-flannel.conf <<EOF
{"name":"cbr0","type":"flannel","delegate": {"isDefaultGateway": true}}
EOF
mkdir /usr/share/oci-umount/oci-umount.d -p
mkdir /run/flannel/ #配置文件中未添加podSubnet,需要在/run/flannel/下定制pod的范围
cat > /run/flannel/subnet.env <<EOF
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.1.0/24
FLANNEL_MTU=1450
FLANNEL_IPMASQ=true
EOF
添加dashboard环境
2.启动dashboard任务(master任意节点)
kubectl apply -f recommended.yaml
2.haproxy编辑dashboard的监控
vim /etc/haproxy/haproxy.cfg
listen dashboard-api-30443
bind 10.0.0.200:30443
mode tcp
server master1 10.0.0.12:30443 check inter 3s fall 3 rise 5
server master2 10.0.0.13:30443 check inter 3s fall 3 rise 5
server master3 10.0.0.14:30443 check inter 3s fall 3 rise 5
systemctl restart haproxy.service
3.浏览器访问:https://10.0.0.200:30443
eyJhbGciOiJSUzI1NiIsImtpZCI6IlNYa0NtRU5fN0FodVdCaUEtLWZvSzZjbTB2VzRwblFiY0x0dTRaT0FzSXcifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tc2t0NGgiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiNWIyMmNlYTAtN2QxYi00Y2JlLWJiZDctNWVkYWFmMzYzMWJiIiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmUtc3lzdGVtOmRhc2hib2FyZC1hZG1pbiJ9.fD20Zvqf8b8xMaDId2I3kgCM8zDS9xcMykoygILl8bV6MGXT0tzL5uN4KTfbp0euwSsDdPOv4kL-WSmFwbykvws2RpZjvySslkGFoUQ4n12d4c4OtOrlGVkANd2mHf4SQbBsOBbuBiZHjzn99RVmI1wIydHITuUtCfIcpkrhOdlqg33GGj6chvpBav0xWDI-FX50XhbYhN5CjO5hXltM_dPSPHfMCkjAiCLti_wunwlEtaNcN34z4K-3Im3wf6QnZHJlwmmROuJ_IEWDwMrSTImmIrFldxw8EC1JihMOPGLLib7m_-ZIo9O-3Ph12KFBPlKeanhzcUTuxU-8SPLOKQ
🔣文件定制初始化集群
apt install -y kubelet=1.21.4-00 kubeadm=1.21.4-00 kubectl=1.21.4-00 --allow-downgrades
1.在集群初始化节点上生成通信认证的配置信息
kubeadm config print init-defaults > kubeadm-init.yml
vim kubeadm-init.yml
bootstrapTokens.groups.ttl #修改为48h或者更大
localAPIEndpoint.advertiseAddress #修改为当前主机的真实ip地址
controlPlanelEndpoint #如果涉及到haproxy的方式,需要额外添加基于VIP的Endpoint地址
imageRepository #修改为我们能够访问到镜像的仓库地址
kubernetesVersion #修改为当前的k8s的版本信息 !!!很重要
networking.serviceSubnet #改为自己的规划中的service地址信息,最好是大一点的私网地址段
2.初始化集群环境
① master节点初始化
kubeadm init --config kubeadm-init.yml
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
export KUBECONFIG=/etc/kubernetes/admin.conf
cd ~ && mkdir flannel && cd flannel
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yml
② 添加master节点
kubeadm init phase upload-certs --upload-certs #在集群初始化节点上生成通信认证的key
kubeadm join 10.0.0.200:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:340cc5484c78f388f42ea5ae466de69350df661795420fba78ddfc3b1f330fd2 \
--control-plane --certificate-key 5ef380f4ee9860a775478795b4b3114eaf1bc32f2d43d1c176b2bcd3216de51a
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
③ 添加node节点(多个节点要一个一个的加)
kubeadm join 10.0.0.200:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:340cc5484c78f388f42ea5ae466de69350df661795420fba78ddfc3b1f330fd2
集群版本更新
#master节点(交替更新)
apt-cache madison kubelet | kubeadm | kubectl
kubeadm upgrade plan #查看更新条件
1.高可用配置暂停待更新节点的服务功能
2.更新kubeadm相关软件 apt install kubelet=1.22.4-00 kubeadm=1.22.4-00 kubectl=1.22.4-00
3.确认可以更新的版本,根据提示命令更新到指定的软件版本 kubeadm upgrade apply v1.22.4
#按照相同的步骤依次更新后面的几个master,更新过程中,haproxy必须将要更新的点剔除出
版本升级后,之前的认证证书就不管用了,需要重新定制,暂时是无法执行kubectl get nodes 之类的命令
rm -rf ~/.kube
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
生产的集群,原则上允许节点挂的数量需要遵循一个原则,剩余的节点数量要大于 n/2 个整数节点。3个节点集群,只允许挂1个,5节点集群只允许挂2个。其根本原因在于,所有节点的属性信息都保存在etcd中,而etcd是一个分布式的,一致的 key/value 存储,它遵循分布式一致性的基本节点要求
#node节点
apt-cache madison kubelet | kubeadm
#更新最新版本的kubeadm、kubelet
kubeadm upgrade node #升级node节点
1.将node节点上的所有资源清理出去:kubectl cordon node1
2.驱逐当前节点上的资源:kubectl drain node2 --delete-emptydir-data --ignore-daemonsets --force
3.更新node节点软件:apt install kubelet=1.22.4-00 kubeadm=1.22.4-00
4.升级节点:kubeadm upgrade node
5.恢复node可以正常调度:kubectl uncordon node1
使用相同的步骤,升级其他节点
常见命令
1.创建一个应用
kubectl create deployment nginx --image=nginx
kubectl expose deployment nginx --port=80 --type=NodePort
kubectl get deployments.apps
kubectl get pod,svc
kubectl get pod,svc -o wide
2.查看资源的访问日志
kubectl logs nginx-6799fc88d8-gsxzk
3.查看资源的详情信息
kubectl describe pod nginx-6799fc88d8-gsxzk
4.进入容器查看信息
kubectl exec -it nginx-6799fc88d8-wgnjt -- /bin/bash #如果一个pod内部存在多个pod的话,通过-c 指定一个具体的容器
5.pod的扩容缩容
kubectl help scale #pod的容量扩充
kubectl scale --replicas=3
kubectl scale --replicas=3 deployment nginx
kubectl get deployment
kubectl get pod -o wide
kubectl scale --replicas=1 deployment nginx #pod的容量收缩
kubectl get deployment
6.pod的版本更新
kubectl help set image
kubectl set image deployment/nginx nginx='nginx:1.11.0' --record=true
kubectl get deployment
kubectl rollout status deployment nginx #查看版本更新状态和历史
kubectl rollout history deployment nginx
kubectl rollout undo deployment nginx #撤销更改
kubectl rollout history deployment nginx
kubectl rollout undo --to-revision=2 deployment nginx #回到指定版本
kubectl rollout history deployment nginx
7.删除资源
kubectl delete deployments nginx
kubectl delete svc nginx
kubectl delete 资源类型 资源1 资源2 ... 资源n (因为限制了资源类型,所以这种方法只能删除一种资源)
kubectl delete 资源类型/资源 (因为删除对象的时候,指定了资源类型,所以我们可以通过这种资源类型限制的方式同时删除多种类型资源)
dockers应用如何迁移到k8s
1 资源清单文件的创建
- deployment、service
2 调整k8s上的容器应用
- 反向代理
- 默认的nginx镜像无效
3 改造容器应用镜像
4 重新调整资源清单文件
5 合理的开放流量访问
获取nginx镜像
docker pull nginx
docker tag nginx 10.0.0.19:80/mykubernetes/nginx:1.21.3
构建tomcat镜像
mkdir tomcat-web;cd tomcat-web/
tar zcf ROOT.tar.gz ROOT/
docker build -t tomcat-web:v0.1
docker run --rm -it -P tomcat-web:v0.1
docker tag tomcat-web:v0.1 10.0.0.19:80/mykubernetes/tomcat-web:v0.1
登录仓库
docker login 10.0.0.19:80
docker push 10.0.0.19:80/mykubernetes/nginx:1.21.3
docker push 10.0.0.19:80/mykubernetes/tomcat-web:v0.1
编辑keepalived配置文件
10.0.0.201 dev ens33 label ens33:2
编辑haproxy配置
listen k8s-nginx-30086
bind 10.0.0.201:30086
mode tcp
server master1 10.0.0.12:30086 check inter 3s fall 3 rise 5
nginx项目定制
kubectl apply -f nginx-proxy.yml
测试:curl 10.0.0.12:30086
tomcat项目定制
kubectl apply -f tomcat-web.yml
测试:curl 10.0.0.12:30087
需求:
nginx需要实现反向代理的功能
tomcat应用不对外暴露端口
初始化流程
参考资料: https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadminit/#init-workflow
master节点启动:
1.当前环境检查,确保当前主机可以部署kubernetes
2.生成kubernetes对外提供服务所需要的各种私钥以及数字证书 ls /etc/kubernetes/pki/
3.生成kubernetes控制组件的kubeconfig文件及相关的启动配置文件 ls /etc/kubernetes/
4.生成kubernetes控制组件的pod对象需要的manifest文件 ls /etc/kubernetes/manifests
5.为集群控制节点添加相关的标识,不让主节点参与node角色工作
6.生成集群的统一认证的token信息,方便其他节点加入到当前的集群 kubeadm token list
7.进行基于TLS的安全引导相关的配置、角色策略、签名请求、自动配置策略 kubectl get csr
8.为集群安装DNS和kube-porxy插件 kubectl get pod -n kube-system | egrep 'proxy|core'
node节点加入
1.当前环境检查,读取相关集群配置信息
2.获取集群相关数据后启动kubelet服务 ls /var/lib/kubelet/
3.获取认证信息后,基于证书方式进行通信
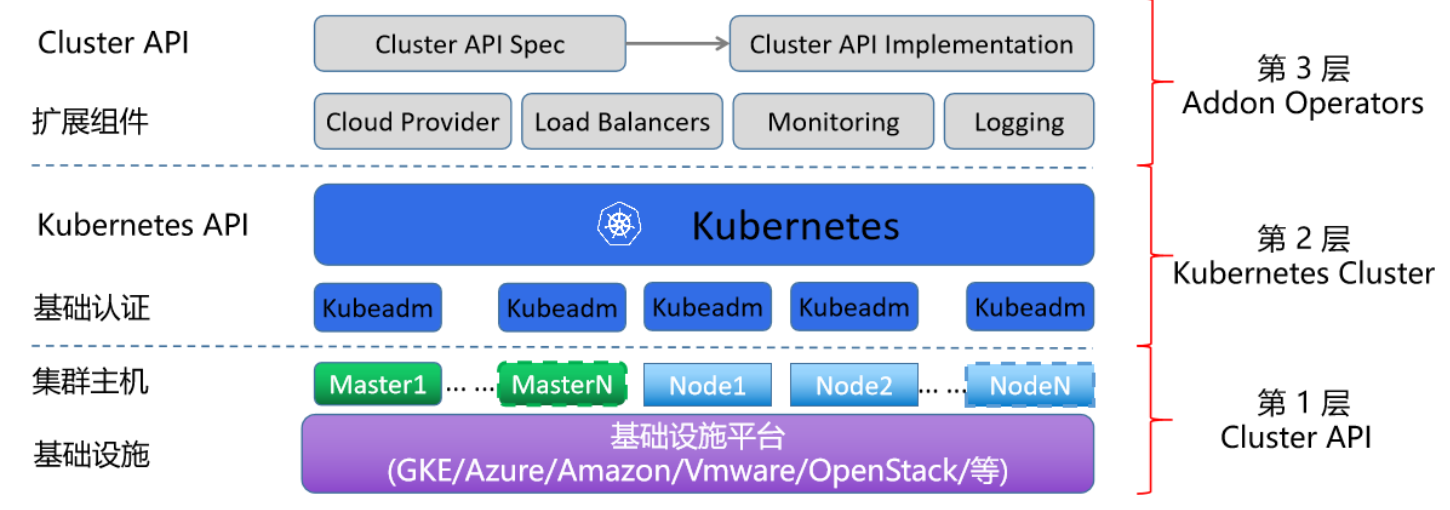
组件解析
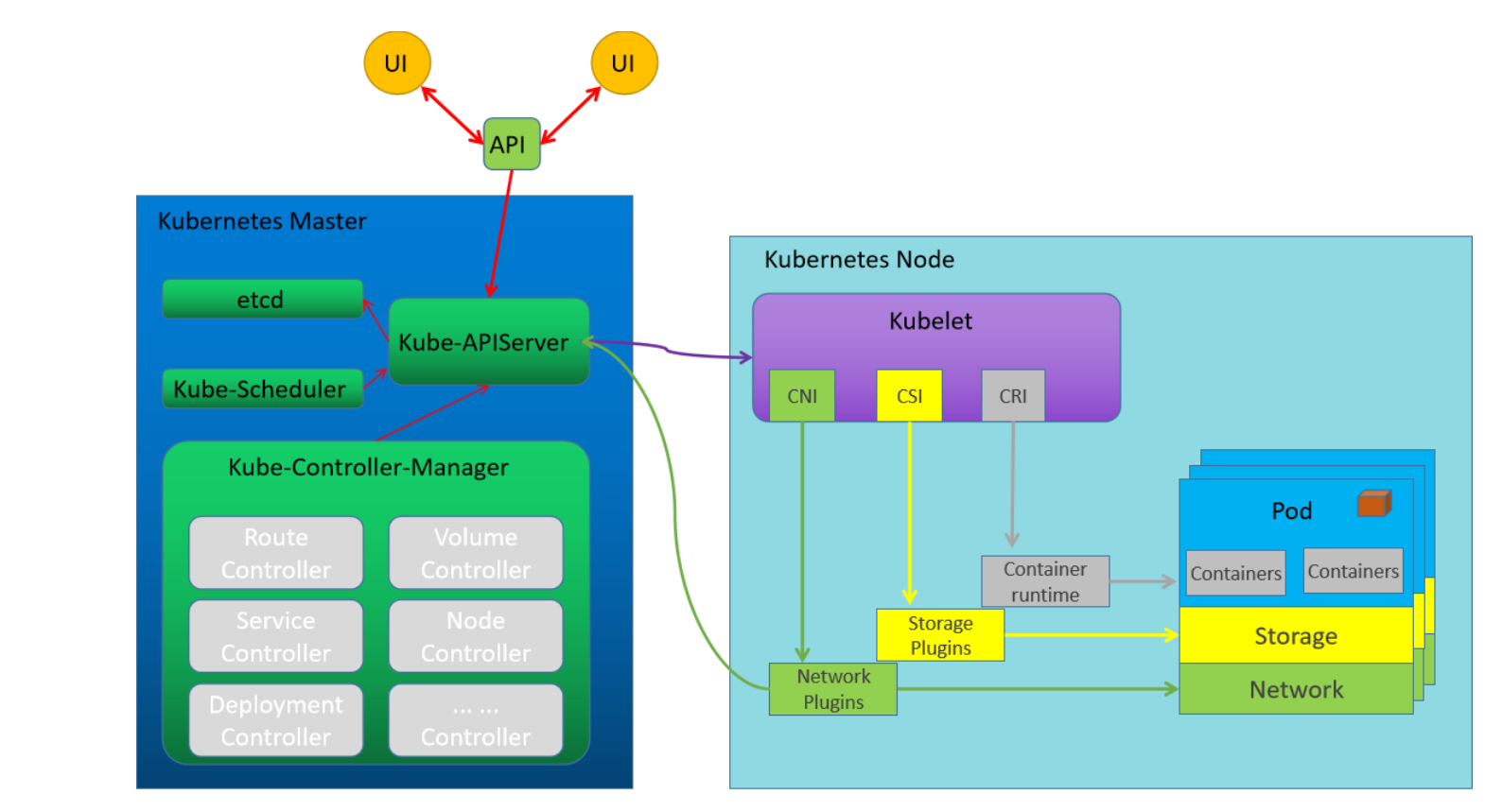
集群部署方式
1.传统方式
支撑性软件都是以服务的样式来进行运行,其他的组件以pod的方式来运行
2.pod方式
除了kubelet和容器环境基于服务的方式运行,其他的都以pod的方式来运行。
所有的pod都被kubelet以manifest(配置清单)的方式进行统一管理。
由于这种pod是基于节点指定目录下的配置文件统一管理的,所有我们将这些pod称为静态pod云方式
基础设施环境都提供了一种 KaaS的方式提供基准的k8s环境,我们直接在这些环境中,进行资源的管理
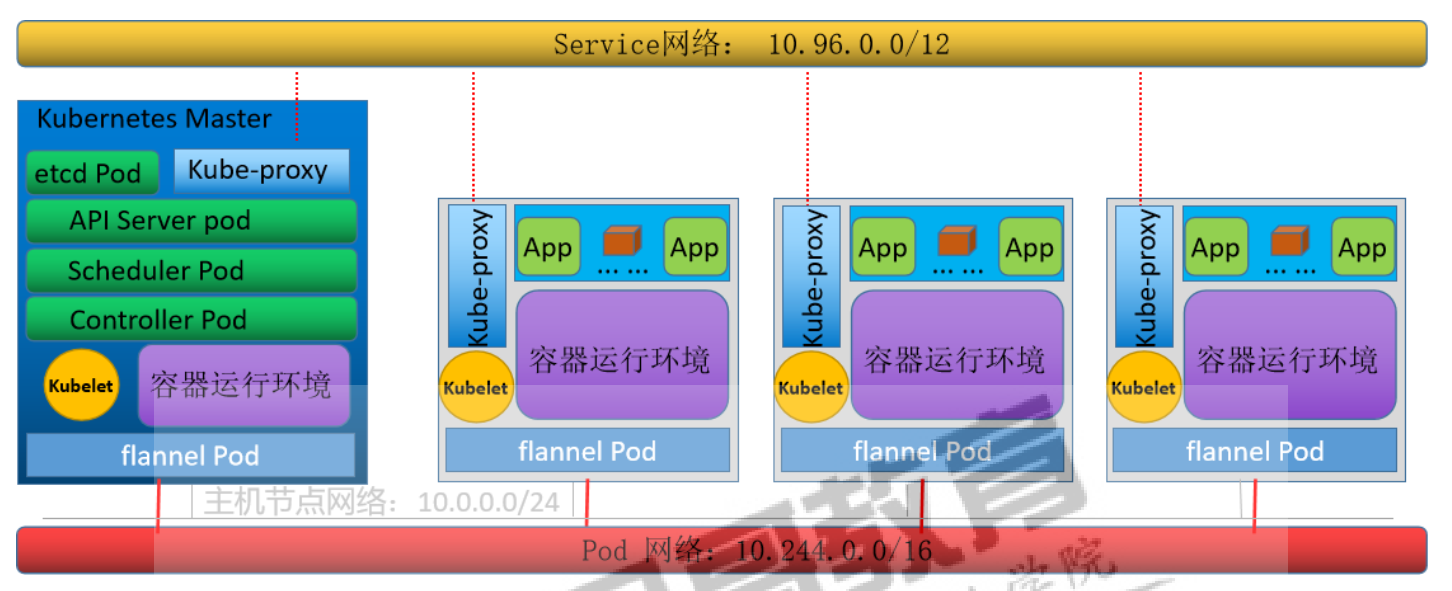
物理主机网络
k8s集群pod网络 --service-cidr=10.96.0.0/12
应用service网络 --pod-network-cidr=10.244.0.0/16
问题报错
1.Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
解决:21版本以上用下面这个命令
wget https://docs.projectcalico.org/v3.20/manifests/calico.yaml --no-check-certificate
kubectl apply -f calico.yaml
kubectl get nodes
2.kube-flannel-ds-d44mn 0/1 Init:ErrImagePull (kubectl get pod -n kube-system时)
报错3:向harbor导入镜像时报错:“denied: requested access to the resource is denied”
解决:因为没有指定仓库名和镜像的tag一致
4.集群init初始化时
"The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error"
解决:vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
Environment="KUBELET_SYSTEM_PODS_ARGS=--pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true --fail-swap-on=false"
systemctl daemon-reload
systemctl restart kubelet
“[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s”
解决:关闭Swap
5.集群init初始化时,加载超时问题
解决方法1:重新执行一下即可
解决方法2:kubeadm reset 之后,重新执行
6.加入node节点时"The connection to the server localhost:8080 was refused - did you specify the right host or port?"
原因:没有认证

若有收获,就点个赞吧
0 人点赞
