Java基础
String 和 StringBuffer,StringBuilder 的区别
1、String 是“字符串常量”,也就是不可改变的对象。 2、StringBuffer 与 StringBuilder,他们是字符串变量,是可改变的对象,每当我们用它们对字符串做操作时,实际上是在一个对象上操作的,不像 String 一样创建一些对象进行操作,所以速度就快了。 3、SringBuffer:线程安全的;StringBuilder:线程非安全的 4、使用场景
- 如果要操作少量的数据用 String
- 单线程操作字符串缓冲区下操作大量数据用 StringBuilder
- 多线程操作字符串缓冲区下操作大量数据 用 StringBuffer 。【在应用程序要求线程安全的情况下,则必须使用 StringBuffer 类】
另一种回答方式
看如何操作:
常量的声明,少量的变量运算,选String
频繁的字符串运算,如拼接,修改,删除等,选StringBuilder或StringBuffer
StringBuilder和StringBuffer如何选?
涉及线程安全,选StringBuffer
不涉及线程安全,选StringBuilder
StringBuilder的效率比StringBuffer的要高,所以更多的情况下使用的是StringBuilder
为什么这样选?
String:String 类是不可改变的,所以你一旦创建了 String 对象,那它的值就无法改变了
当两个字符串拼接时,会产生一个新的字符串去接收拼接的结果,但前两个字符串并没有销毁,当拼接操作变多以后,产生大量的String 临时类,消耗内存,增加对垃圾回收占用CPU的时间
StingBuilder和StringBuffer:StringBuffer 和 StringBuilder 类的对象能够被多次的修改,并且不产生新的未使用对象。
集合
Java集合都有哪些?
l Java集合分为Collection(List、Set)和Map两大类
l List:ArrayList、LinkedList、Vector、Stack
l Set:HashSet、LinkedHashSet、TreeSet
l Map:HashMap、LinkedHashMap、TreeMap、ConcurrentHashMap、Hashtable
几大集合存储特性以及区别?
List、Set、Map 的区别:
- List 是允许存重复关系,有序的,可以插入多个 null 元素
- Set 不允许重复对象,无序的,只允许一个 null 元素,没有索引
-
哪些集合类时线程安全的
l 线程安全:当多线程访问时,采用了加锁的机制;即当一个线程访问该类的某个数据时,会对这个数据进行保护,其他线程不能对其访问,直到该线程读取完之后,其他线程才可以使用。
l 线程不安全:多个线程能够同时操作某个数据,从而出现数据不一致
l 对于线程不安全的问题,一般会使用synchronized 关键字加锁同步控制。
l 线程安全:Vector、Stack、HashTable、ConcurrentHashMap。
l 非线程安全:ArrayList、HashMap、HashSet、TreeMap、TreeSet。List
ArrayList、LinkedList、Vector的区别:
ArrayList集合:底层是数组结构实现,查询快、增删慢;非线程安全,非同步的;默认容量是 10,扩容是 1.5 倍扩容;存放的是Object对象类型
- LinkedList集合:底层是双向链表结构实现,查询慢、增删快
- Vector中的方法由于添加了synchronized修饰,因此Vector是线程安全的容器,但性能上较ArrayList差,因此已经是较少使用。为了提高效率,Vector默认扩充为2倍
ArrayList为什么它查询快增删慢?
- 查询快
ArrayList底层是数组的结构,查询快是因为它是连续存放元素的,当我们找到第一个元素的首地址,再加上每个元素的占据的字节大小就能定位到对应的元素,不需要进行遍历。
- 增删慢(使用数组的弊端)
- 每当插入或删除操作时 都需要向前或向后的移动元素
- 当插入元素时 需要判定是否需要扩容操作
- 扩容操作:创建一个新数组 增加length 再将元素放入进去,较为繁琐
ArrayList有最大或者最小的容量吗?
有最大最小容量限制,默认初始容量为10,当超过数组的长度时,按照1.5倍进行扩容,最大容量为Integer.MAX_VALUE - 8,【为什么是减8,因为数组对象有一个额外的元数据,用于表示数组的大小。】
LinkedList为什么查询慢、增删快?
- 查询慢(双向链表的弊端)
双向链表的查询逻辑是他会根据index的大小判断是从前开始遍历还是从后开始遍历,如果index更靠前就从前遍历,更靠后就从后遍历,也就是在查询过程中,会一次次的移动指针直到获取到index的值。 - 增删快
只需要修改插入位置或删除位置左右数据的引用目标即可。
总结:如果查询修改比较多应该选用ArrayList,如果增加和删除操作比较多应该选择Linkedlist
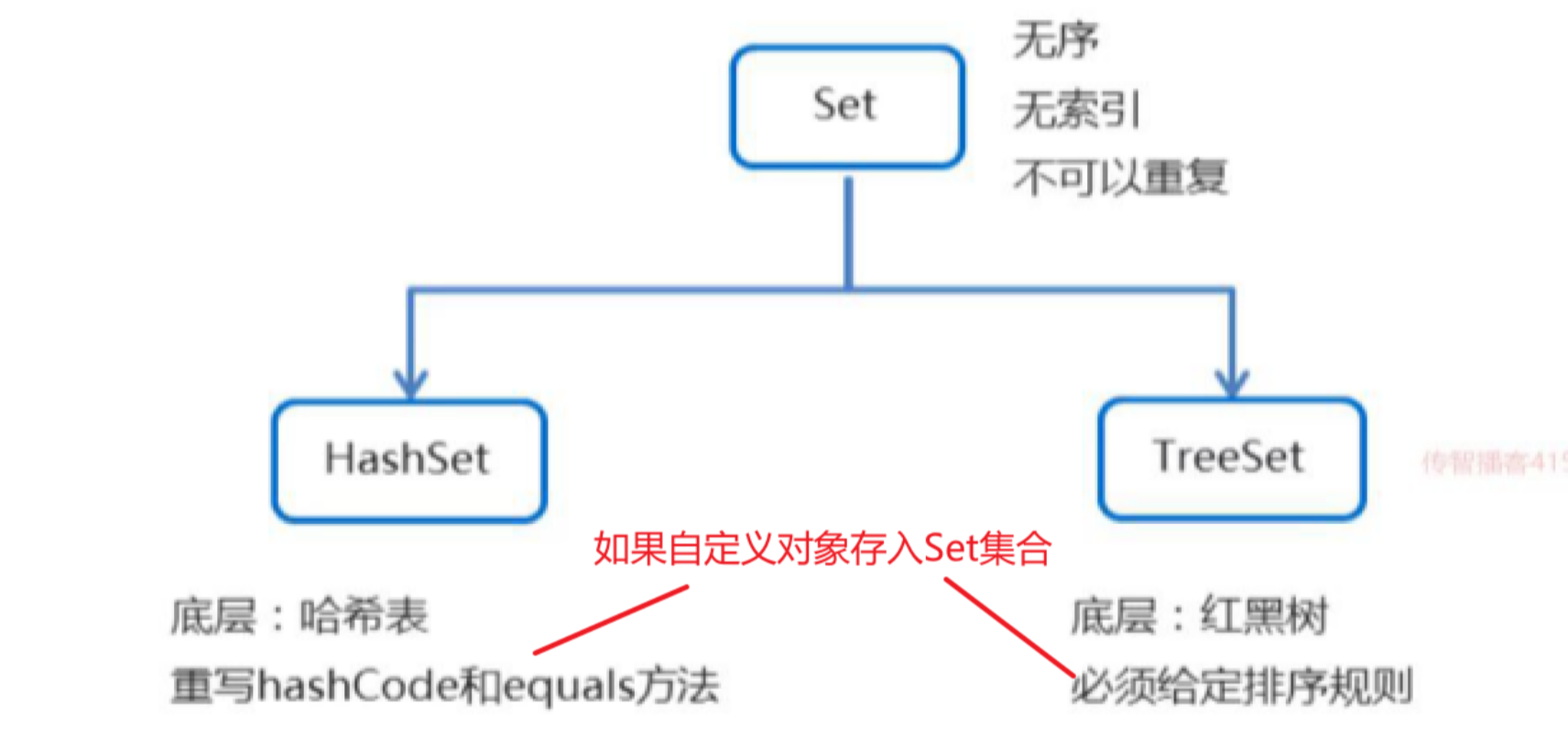
Set
Set集合概述和特点
- 不可以存储重复元素
- 存取顺序不一致
- 没有索引
TreeSet集合
排序规则
如果存储的是已存在的引用类型数据,比如Integer、String等,那么底层已经有实现自然排序。
如果存储的是自定义对象,那么必须实现自然排序或比较器排序,否则直接打印集合时会出现类转换异常
- 两种排序比较方式总结【理解】
- 自然排序: 自定义类实现Comparable接口,重写compareTo方法,根据返回值进行排序
- 比较器排序: 创建TreeSet对象的时候传递Comparator的实现类对象,重写compare方法,根据返回值进行排序
底层原理
底层是红黑树实现,遍历时,先获取左边,再获取中间,再获取右边
二叉树(任意一个节点的度要小于等于2)
二叉查找树(左节点上的值小于自己,右节点上的值大于自己)
平衡二叉树(二叉树左右两个子树的高度差不超过1、任意节点的左右两个子树都是一颗平衡二叉树)
红黑树的特点
- 平衡二叉B树
- 每一个节点可以是红或者黑
- 红黑树不是高度平衡的,它的平衡是通过”自己的红黑规则”进行实现的
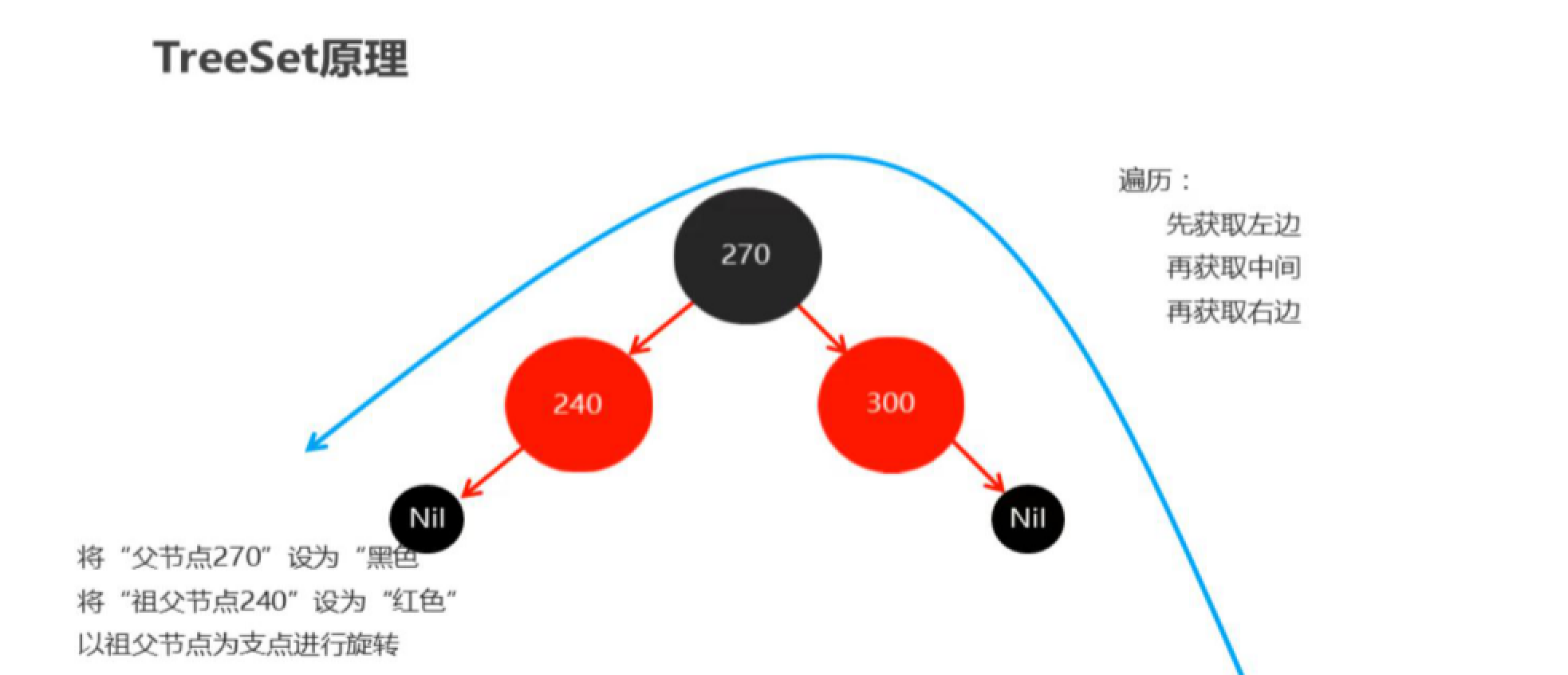
- 红黑树的红黑规则
- 每一个节点或是红色的,或者是黑色的
- 根节点必须是黑色
- 如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点,每个叶节点(Nil)是黑色的
- 如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连 的情况)
- 对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点
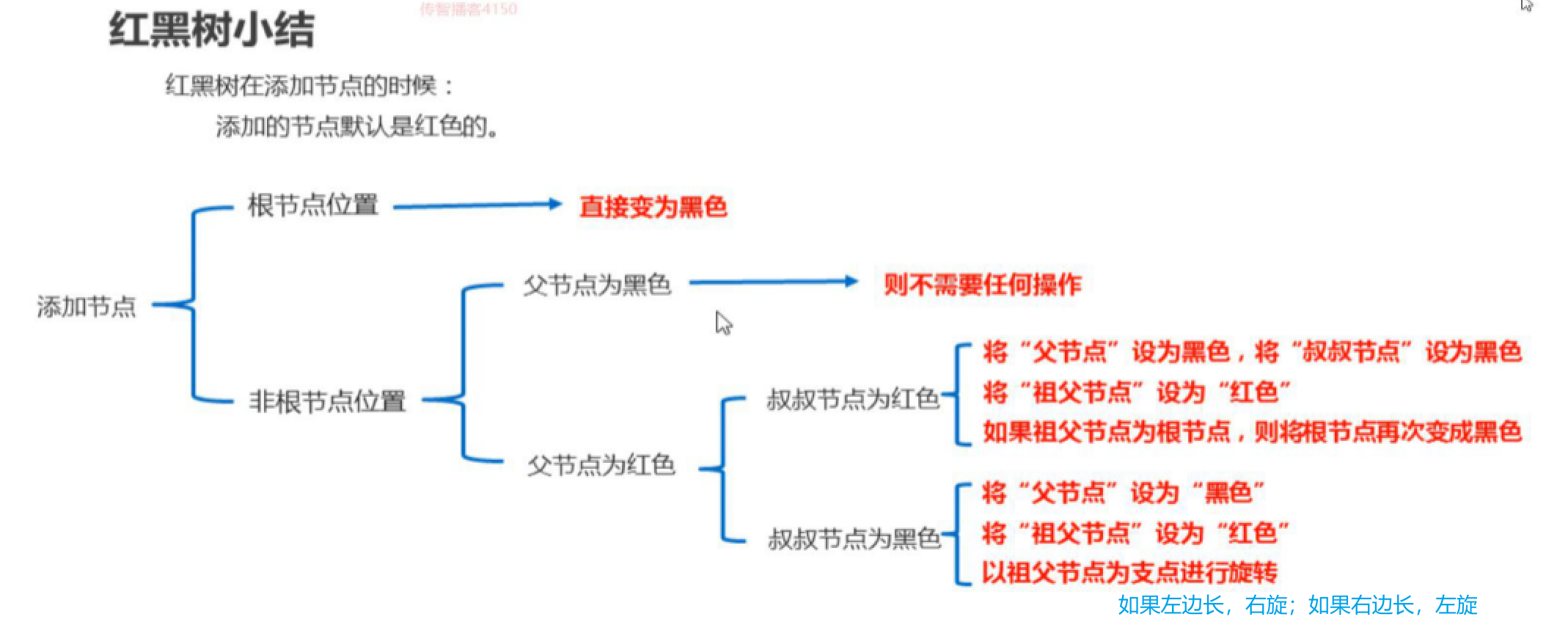
HashSet集合
底层数据结构是哈希表
哈希表结构
- JDK1.8以前(不包括JDK8),底层采用数组+链表实现。
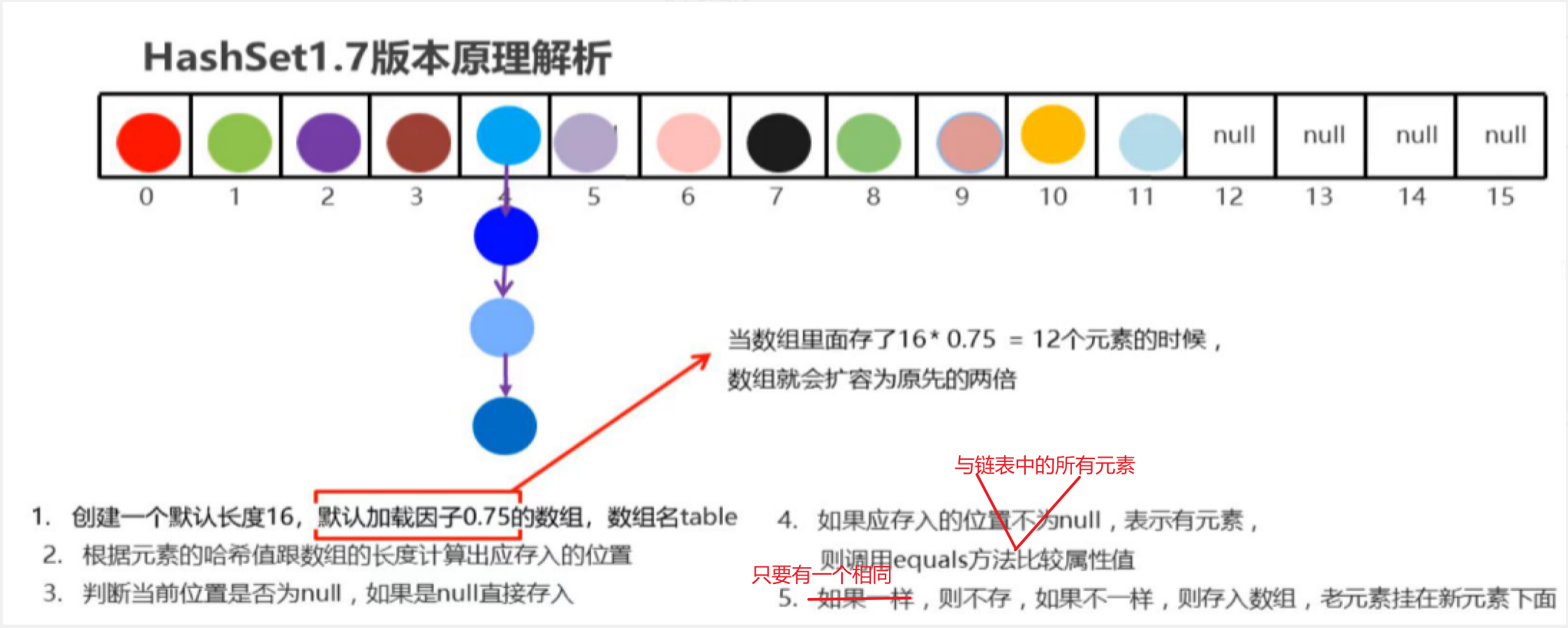
- JDK1.8以后,底层进行了优化。底层采用数组+链表+红黑树实现。
- 节点个数少于等于8个:数组 + 链表
- 当链表上的元素过多时,不利于添加,也不利于查询。
- 节点个数多于8个:数组 + 红黑树
treeSet与hashSet有什么区别
相同点:
两者中的值都不能重复,就如数据库中唯一约束
不同点:
1、TreeSet 是红黑树实现的,Treeset中的数据是自动排好序的,不允许放入null值
2、HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null
3、HashSet是通过HashMap实现的,TreeSet是通过TreeMap实现的,只不过Set用的只是Map的key
set为什么不能存储重复的元素?
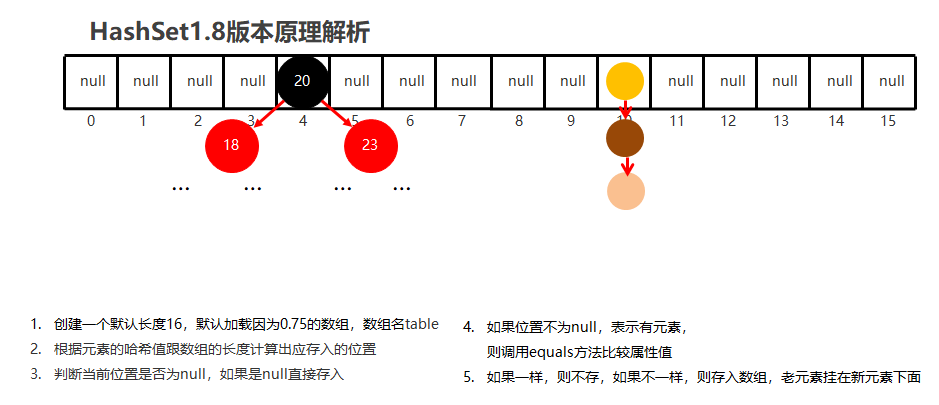
以hashSet为例,在添加元素到集合时,会使用hashCode()与equals()来判断存入的对象是否重复。
首先,计算存入元素的哈希值,如果在集合中不存在该哈希值,就把元素存储到集合中;如果存在(哈希冲突),会调用equals方法和哈希值相同的元素进行比较,根据equals方法返回的结果进行判断;
equals方法返回true;认定两个元素相同,就不会把元素存储到集合中;
equals方法返回false;认定两个元素不相同,就把元素存入集合中。
hashSet与hashMap 它们的区别?

Map
HashMap的特点
- HashMap底层是哈希表结构的
- 依赖hashCode方法和equals方法保证键的唯一
如果键要存储的是自定义对象,需要重写hashCode和equals方法
如果键存储的是Java已有引用数据类型对象,那么不需要重写hashCode和equals方法
HashMap 的底层数据结构?HashMap 的 put 方法是如何实现添加数据到 HashMap 集合中的?
1、 jdk1.7 之前 HashMap 底层数据结构是:哈希表数组+链表的数据结构。jdk1.8 之后底层数据结构是:哈
希表数组+链表+红黑树。
2、 当调用 put 方法时 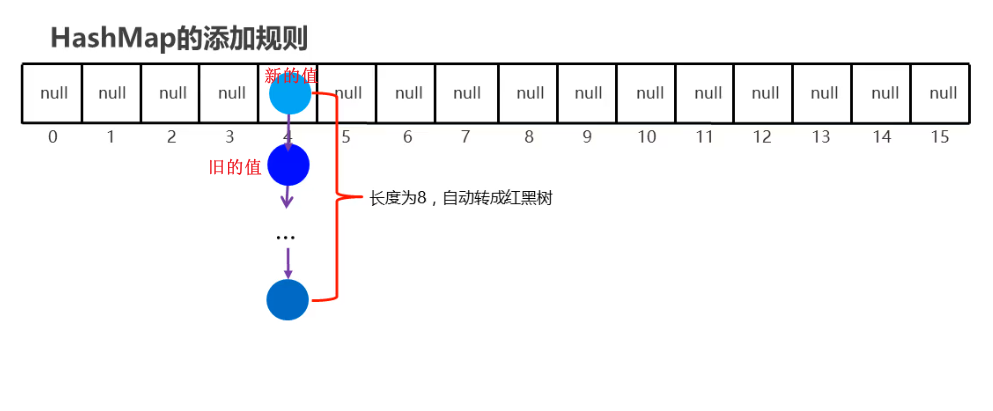
1) 对 Key 求 Hash 值,然后再计算出对应的数组索引。
2) 如果数组索引处的值为null,直接放在该数组位置上。
3) 如果不为null,则调用equals方法比较键的属性值,如果返回true,则覆盖替换旧值;如果返回false,则以链表的方式将新值放入到数组索引处,链接到旧值后面。
4) 如果链表长度超过阀值( TREEIFY THRESHOLD==8),就把链表转成红黑树
5) 如果数组满了(容量 16*加载因子 0.75),就需要 resize(扩容 2 倍后重排)。
3、 get 过程
当我们调用 get()方法,HashMap 会使用键对象的 hashcode 找到 bucket 位置,找到 bucket 位置之后, 会调用 keys.equals()方法去找到链表中正确的节点,最终找到要找的值对象。
TreeMap的特点
- TreeMap底层是红黑树结构的
- 依赖自然排序或者比较器排序,对键进行排序(只关心键,不关心值)
如果键存储的是自定义对象,需要实现Comparable接口或者在创建TreeMap对象时候给出比较器排序规则
map的分类,HashMap 与 HashTable 的区别
HashMap 是线程非安全的,非同步的;允许 null key 和 null value;HashMap 的初始容量是 16
- HashTable 是线程安全的,同步的,不允许 null key 和 null value; HashTable的初始容量是11,扩容策略是翻倍加1,即当前容量 capacity * 2 + 1,采取悲观锁synchronized的形式保证数据的安全性,只要有线程访问,会将整张表锁起来,效率低下(悲观锁)
- ConcurrentHashMap也是线程安全的,效率较高。 在JDK7和JDK8中,底层原理不一样。ConcurrentHashMap使用了分段锁技术来提高了并发度,不在同一段的数据互相不影响,多个线程对多个不同段的操作是不会相互影响的。每个段使用一把锁。所以在需要线程安全的业务场景下,推荐使用ConcurrentHashMap,而HashTable不建议在新的代码中使用
1、 HashMap:
- 底层数组+ 链表实现,可以存储 null 键和 null 值,线程不安全。
- 初始 size 为 16,扩容:newsize = oldsize*2,size 一定为 2 的 n 次幂。
- 扩容针对整个 M a p ,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入。
- 插入元素后才判断该不该扩容,有可能无效扩容(插入后如果扩容,如果没有再次插入,就会产生无效扩容)。
- 当 Map 中元素总数超过 Entry 数组的 75%,触发扩容操作,为了减少链表长度,元素分配更均匀。
- 计算 index 方法:index = hash & (tab.length – 1)。
- jdk1.8 之后加入了红黑树。
2、 ConcurrentHashMap:
- 底层采用分段的数组(长度16的大数组和长度2的小数组)+ 链表实现,线程安全。
- 通过把整个 Map 分为 N 个 Segment,可以提供相同的线程安全,但是效率提升 N 倍,默认提升 16 (支持16个线程同时访问)倍。(读操作不加锁,由于 HashEntry 的 value 变量是 volatile 的,也能保证读取到最新的值。)
- ConcurrentHashMap 允许多个修改操作并发进行,其关键在于使用了锁分离技术,有些方法需要跨段,比如 size()和 containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。
- 扩容:段内(长度为2的小数组)扩容(段内元素超过该段对应 Entry 数组长度的 75%触发扩容,不会对整个 Map 进行扩容),插入前检测需不需要扩容,有效避免无效扩容。
- jdk1.8 之后加入了红黑树。
多线程
ThreadLocal的作用是什么?线程池的状态有哪些?线程池的好处是什么?线程的实现方式有几种?哪一种比较好,为什么?sleep与wait的区别?有没有在项目中写过多线程,线程池?
进程与线程的区别
线程在项目中有写过吗?并发量多吗?数据量多吗?
有用到过多线程吗?
hashmap的底层原理有了解吗?知道它为什么线程不安全吗?因为hashmap有个自动扩容机制,在取值赋值删除值的时候,多个线程操作会引起死循环 会导致 Hashmap出现死循环是因为多线程会导致 Hashmape的Enty节点形成环链,这样当遍历集合时 Entry的next节点永远不为空,从而形成死循环
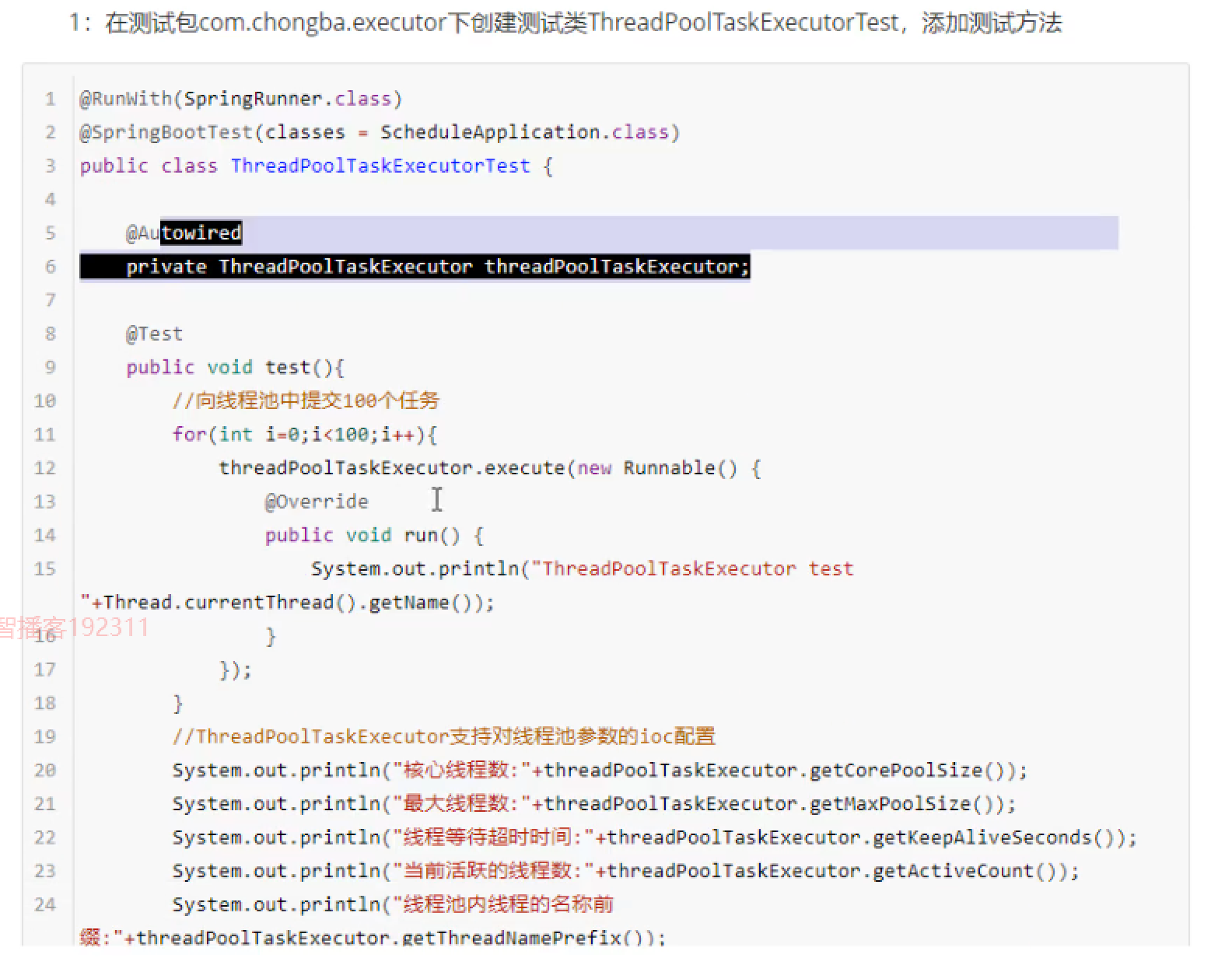
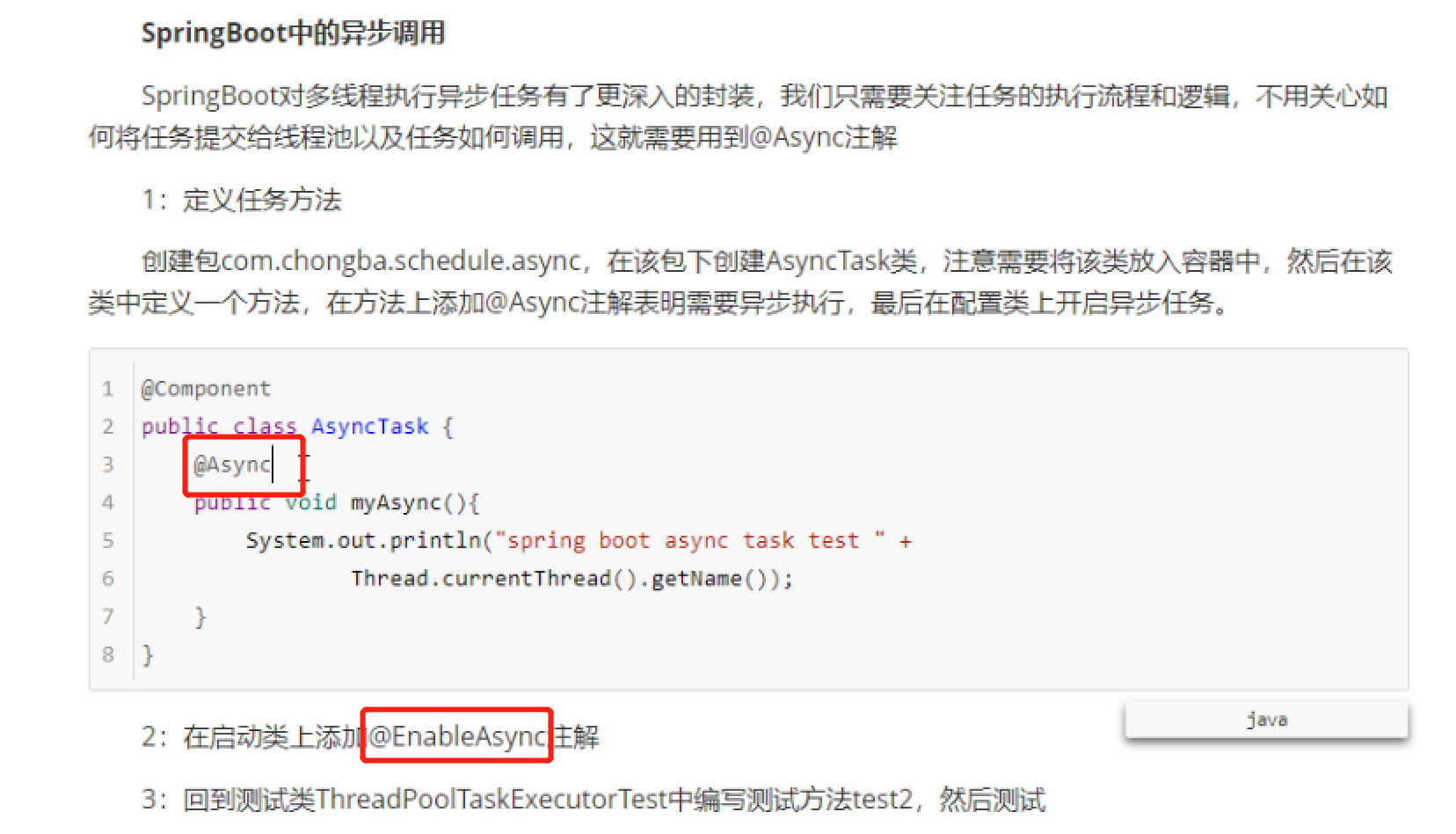
核心线程池ThreadPoolExecutor的参数和执行流程
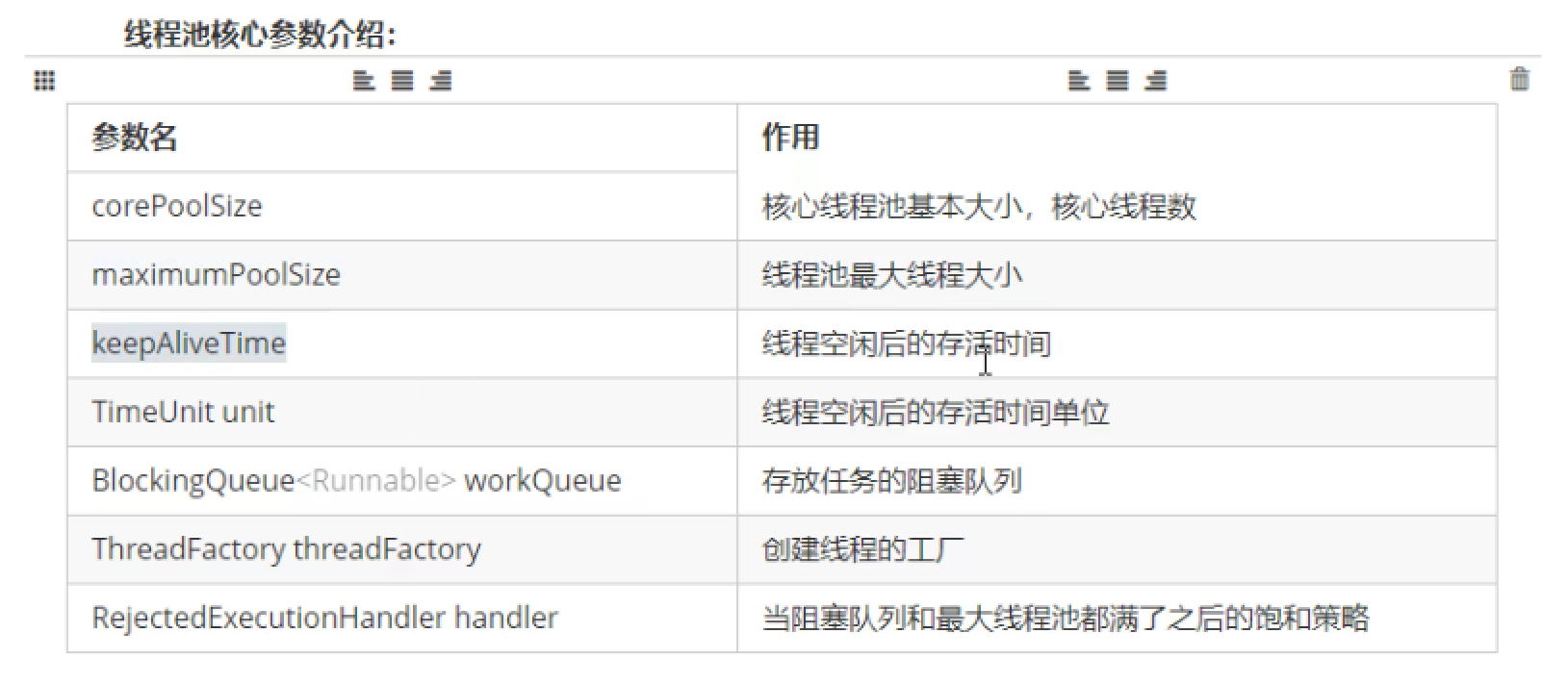

当阻塞队列任务完成后(没有任务要被处理),临时线程达到设置的空闲时间后就会被销毁

充吧项目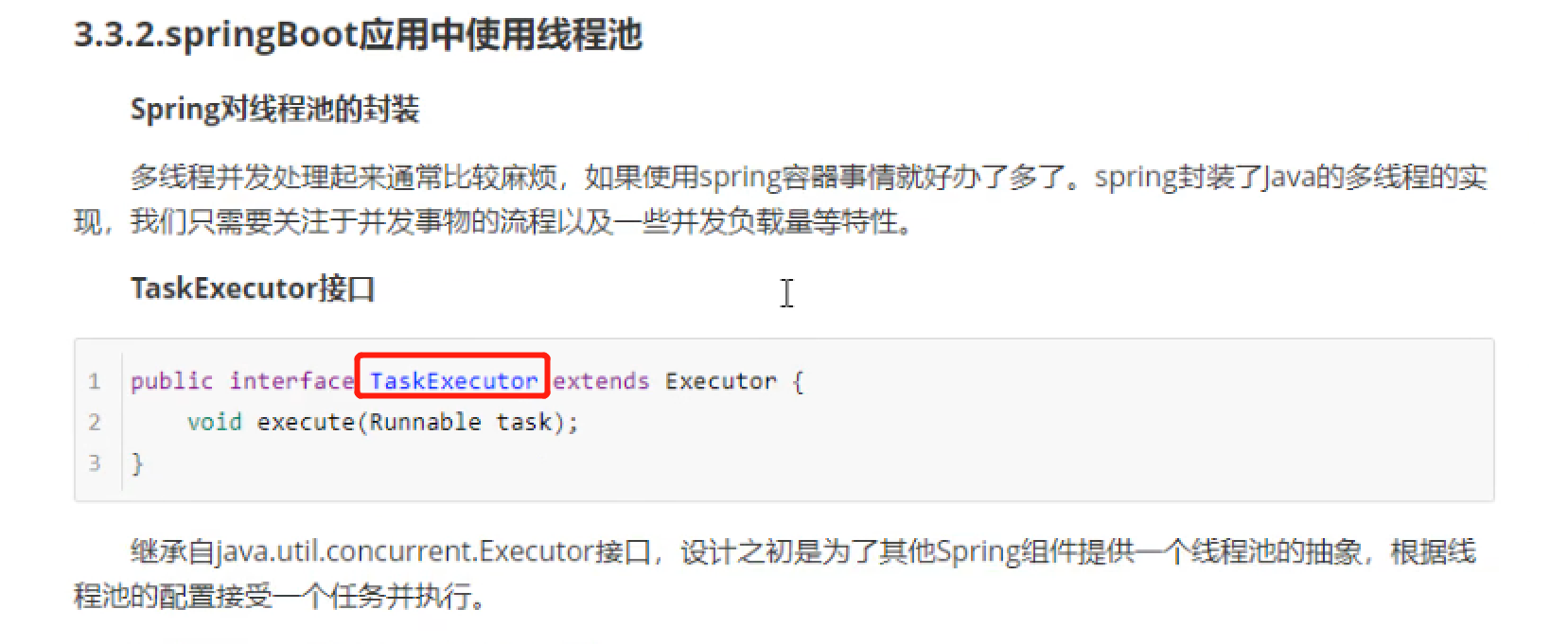

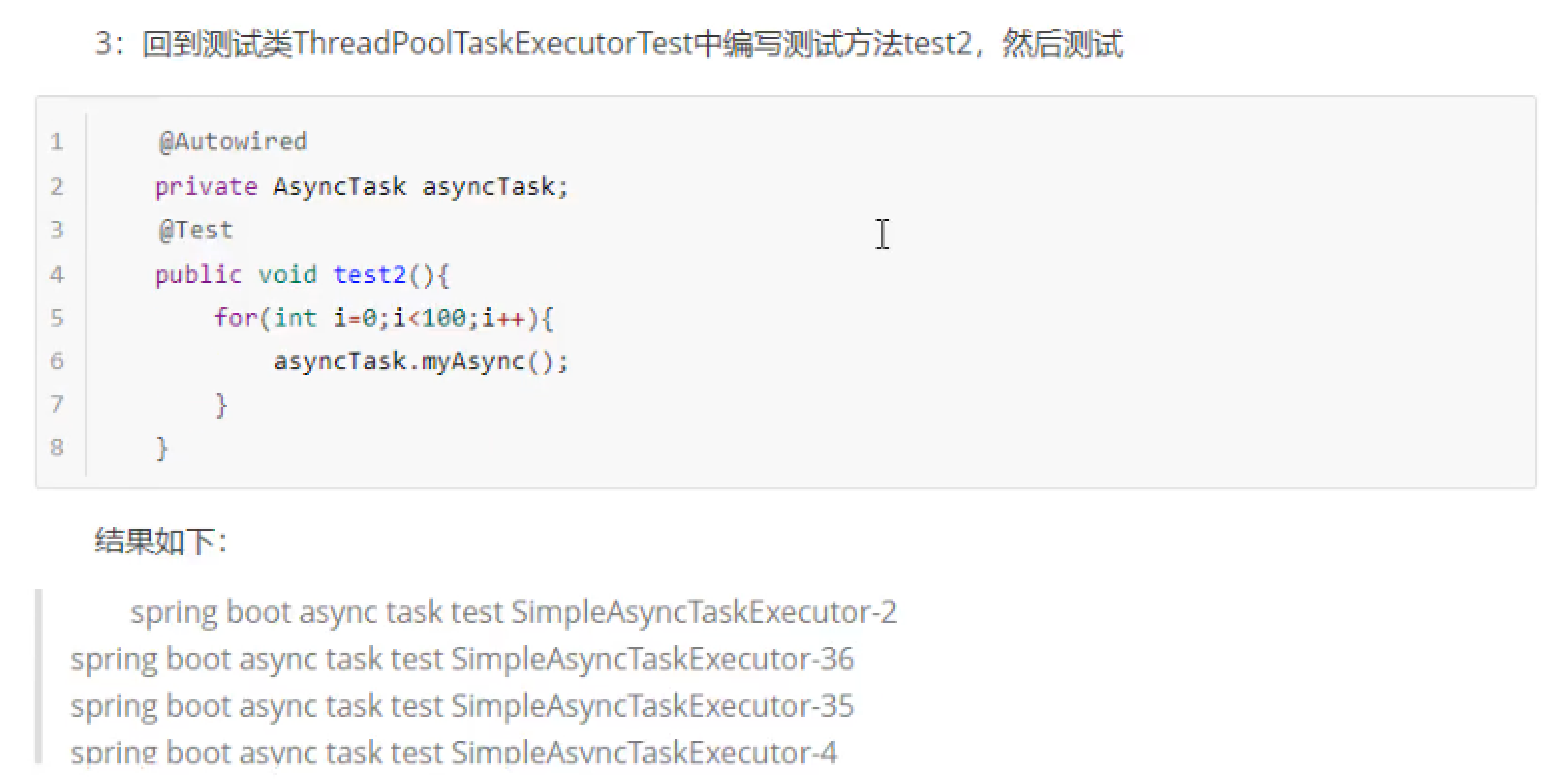
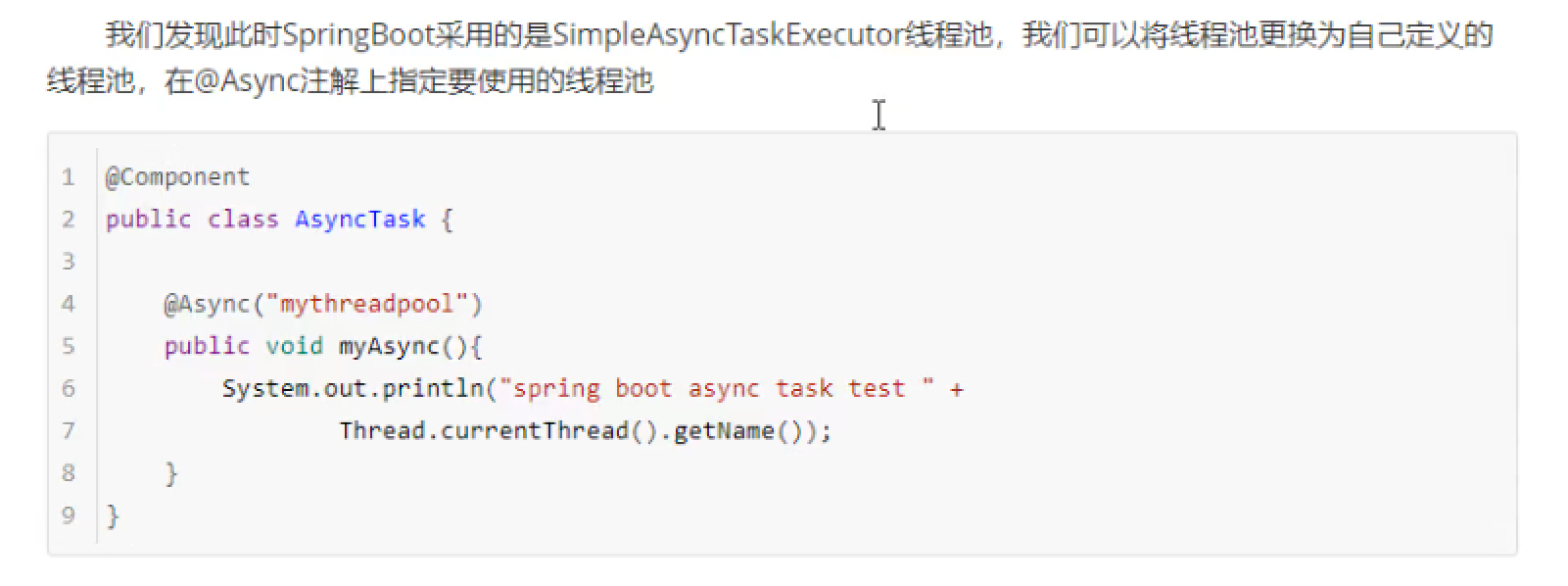
网络
redis
redis的应用场景?
redis的几种数据类型?
Redis 的持久化有哪几种方式?不同的持久化机制都有什么优缺点?
redis的定时清理垃圾图片是怎么实现的?redis的set存储什么数据?如果用户上传图片后,但是正在填写其他的信息,这时定时任务正好把图片删除要怎么处理?
——在清理图片的时候,判断图片的上传时间距现在多久,只清理上传时间超过半个小时以上、并且没有和套餐关联的图片
商品搜索引擎为什么要用elasticSearch、 购物车为什么就要用redis 他们的区别是什么
es专门做搜索服务的,支持分词搜索 购物车的数据是经常变动的,频繁进行更新,所以放到redis
redis如果挂了,那购物车信息不久丢失了?
redis的持久化有哪几种方式?哪种方式更好?
redis的几种基本类型? sorted set可以进行排序,那它怎么可以排序呢?List你认为它是一种什么样的结构呢
Redis中的List数据结构是链表型的,类似于LinkedList。所以它的插入效率非常高,时间复杂度为O(1)。它的查询效率较慢,时O(n)。
redis中的基本类型中,你用的比较多的是哪些?
redis的信息如果丢失了,你们是怎么处理的?
redis这一块有了解过部署吗?zsort类型有了解过吗?有用过分布式锁吗?
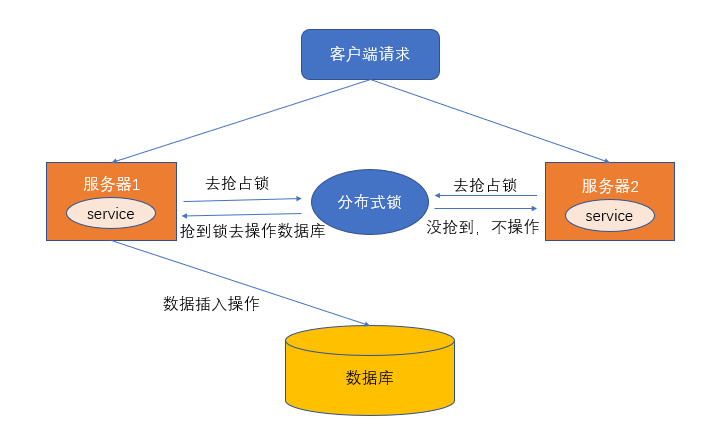
https://juejin.cn/post/6844903830442737671#heading-1 基于Redis的分布式锁实现 分布式锁,它是控制分布式系统之间互斥访问共享资源的一种方式。 分布式锁机制保证多个服务之间互斥的访问共享资源,如果一个服务抢占了分布式锁,其他服务没获取到锁,就不进行后续操作。
分布式锁的特点
分布式锁一般有如下的特点:
- 互斥性: 同一时刻只能有一个线程持有锁
- 可重入性: 同一节点上的同一个线程如果获取了锁之后能够再次获取锁
- 锁超时:和J.U.C中的锁一样支持锁超时,防止死锁
- 高性能和高可用: 加锁和解锁需要高效,同时也需要保证高可用,防止分布式锁失效
- 具备阻塞和非阻塞性:能够及时从阻塞状态中被唤醒
分布式锁的实现方式
使用Lua脚本(包含setnx和expire两条指令)
使用 set key value [EX seconds][PX milliseconds][NX|XX] 命令 (正确做法)
…….
Redis实现的分布式锁轮子(SpringBoot + Jedis + AOP)
数据库
如果有2张关联的表,数据非常庞大,现在让你去查询非常大的数据,你有什么调优方案吗? 如果发现sql查询比较慢,要怎么进行优化?(前提:不用es)
https://www.jianshu.com/p/ed877806888d
- sql优化(可以从业务以及技术上进行优化,根据你选择的引擎、表中数据的分布情况、索引情况等情况从整体进行优化,可以结合explain关键字来查看优化效果)
尽可能的使用 varchar/nvarchar 代替 char/nchar
对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。 应尽量避免在 where 子句中对字段进行 null 值判断
避免在 WHERE 子句中使用 in,not in,or 或者 having。可以使用 exist 和 not exist 代替 in 和 not in。
避免全表数据查询,少用select
尽量避免SELECT 而是一一罗列出所需要查询的字段
- 索引优化
- 缓存的配置(mysql支持缓存查询语句或者缓存查询数据,但当一个表格的更新数据表操作非常多的话,query cache是不会起到查询提升的性能,还会影响其他操作的性能。)
- slow_query_log分析
当你设置slow_query_log为on的时候,server端会对每次的查询进行记录,当超过你设置的慢查询时间 (long_query_time)的时候就把该条查询记录到日志。而你对性能进行优化的时候,就可以分析慢查询日志,对慢查询的查询语句进行有目的的优化。
- 子查询优化(在绝大多数情况下,服务器对join的查询优化要远远高于子查询优化。)
- 分库、分表(数据迁移、字段迁移)
- 用的最多的是左连接 查询速度最快
- 减少数据库的连接次数
- 批量插入 不要在for循环中 进行一次次的插入insert into() insert into()…..要使用insert into(),(),()
什么情况会式索引失效? 我只回答了一种情况 在不分库分表的情况下, 可以进行索引优化,添加索引后不走索引是什么情况?
类型不一致导致的索引失效(表字段类型是varchar,但是我查询的时候使用了数字类型,因为这个中间存在一个隐式的类型转换,所以就会导致索引失效)
在索引列进行运算或者使用函数导致索引失效;
在 sql 中使用 <> 、not in 、not exist、!=,or,like “%_” 百分号在前,where 后使用 IS NULL、IS NOT NULL 或者使用函数,会使索引失效
**
%like导致索引失效,但是又必须使用模糊查询来保证业务的话,有没有什么替代方案?
like %keyword 索引失效,使用全表扫描。
解决方案:使用索引覆盖解决。可以通过翻转函数+like前模糊查询+建立翻转函数索引=走翻转函数索引,不走全表扫描。如where reverse(code) like reverse(‘%Code2’)
https://blog.csdn.net/shadow_zed/article/details/89117125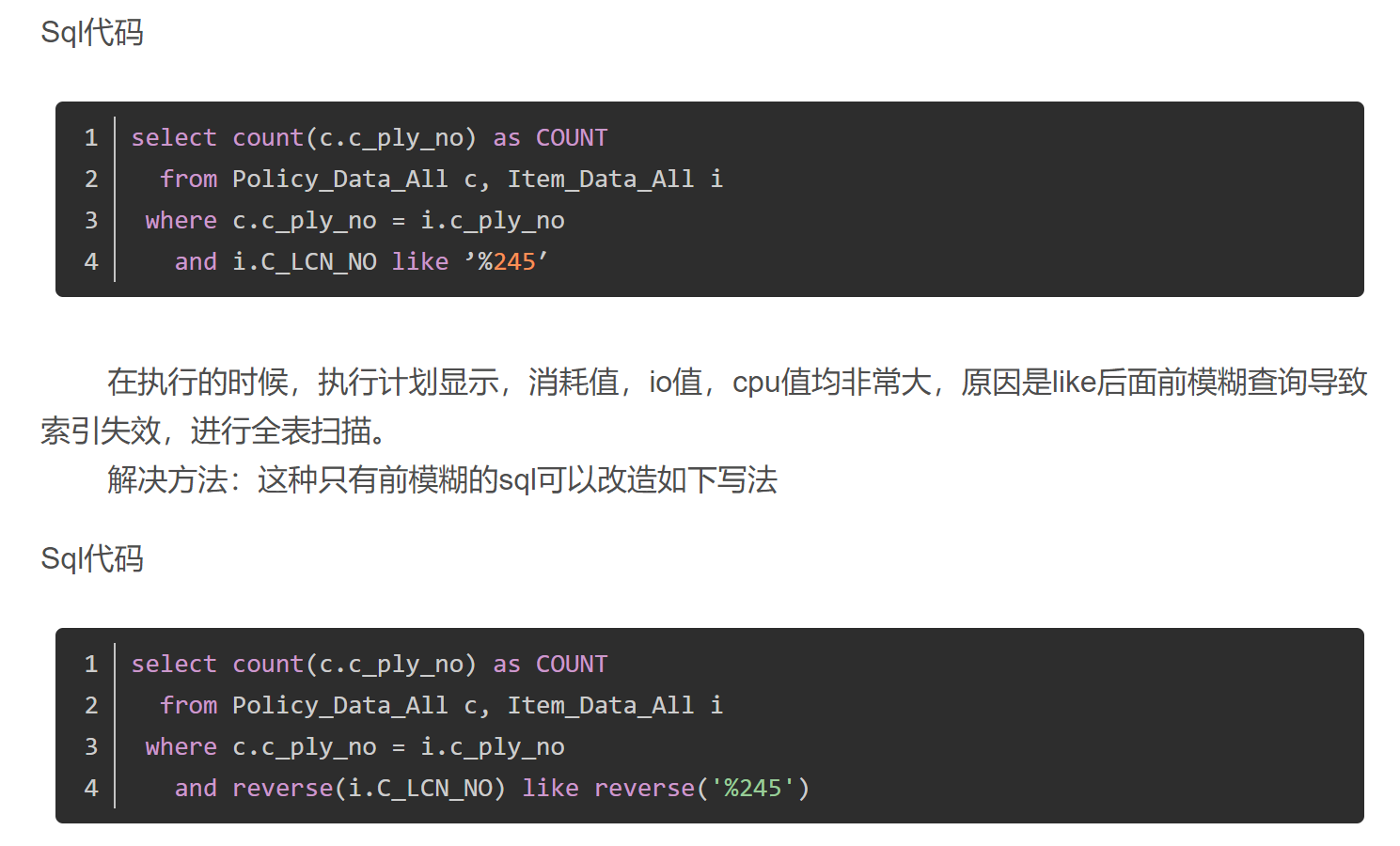
使用翻转函数+like前模糊查询+建立翻转函数索引=走翻转函数索引,不走全扫描。有效降低消耗值,io值,cpu值这三个指标,尤其是io值的降低。
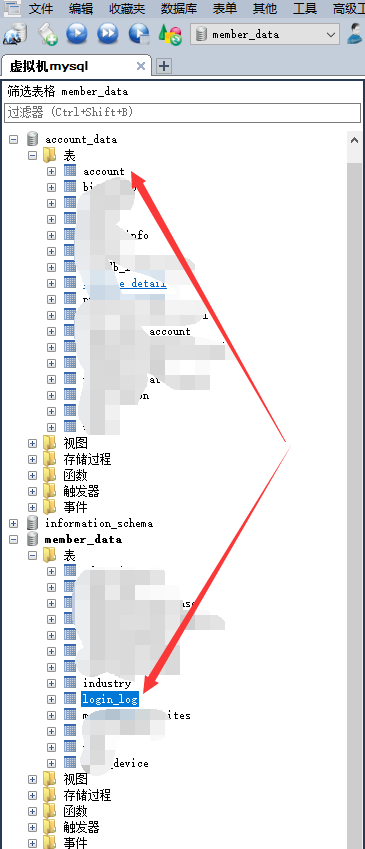
业务微服务是否有分库?跨库关联怎么实现?比如用户数据库与订单数据库,怎么进行关联查询查出用户名,以及该用户名对应的订单?后台管理要显示全部用户名、以及对应的订单
第一种:同一个MySQL实例下的跨库
可以通过带数据库名进行关联查询
EXPLAIN SELECT * FROM account_data.`account` a JOIN member_data.`login_log` b ON a.`account_id`=b.`user_id`;
第二种:不同MySQL实例下的跨库
业务场景:关联不同数据库中的表的查询
比如说,要关联的表是:机器A上的数据库A中的表A && 机器B上的数据库B中的表B。
解决方案:在机器A上的数据库A中建一个表B
基于MySQL的federated引擎的建表方式。
建表语句示例:CREATE TABLE table_name(……) ENGINE =FEDERATED CONNECTION=’mysql://[username]:[password]@[location]:[port]/[db-name]/[table-name]’
前提条件:你的mysql得支持federated引擎(执行show engines;可以看到是否支持)。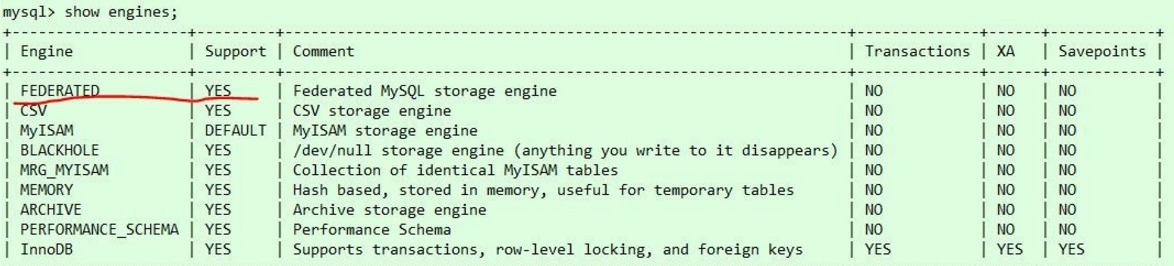
如果有FEDERATED引擎,但Support是NO,说明你的mysql安装了这个引擎,但没启用,去my.cnf文件末添加一行 federated ,重启mysql即可;
解释:通过FEDERATED引擎创建的表只是在本地有表定义文件,数据文件则存在于远程数据库中。就是说,这种建表方式只会在数据库A中创建一个表B的表结构文件,表的索引、数据等文件还是在机器B上的数据库B中,相当于只是在数据库A中创建了表B的一个快捷方式。
需要注意的几点:
1. 本地的表结构必须与远程的完全一样。
2.远程数据库目前仅限MySQL
3.不支持事务
4.不支持表结构修改
mysql优化的知识(视频讲解)
二八原则:80%都是在写查询语句
软优化: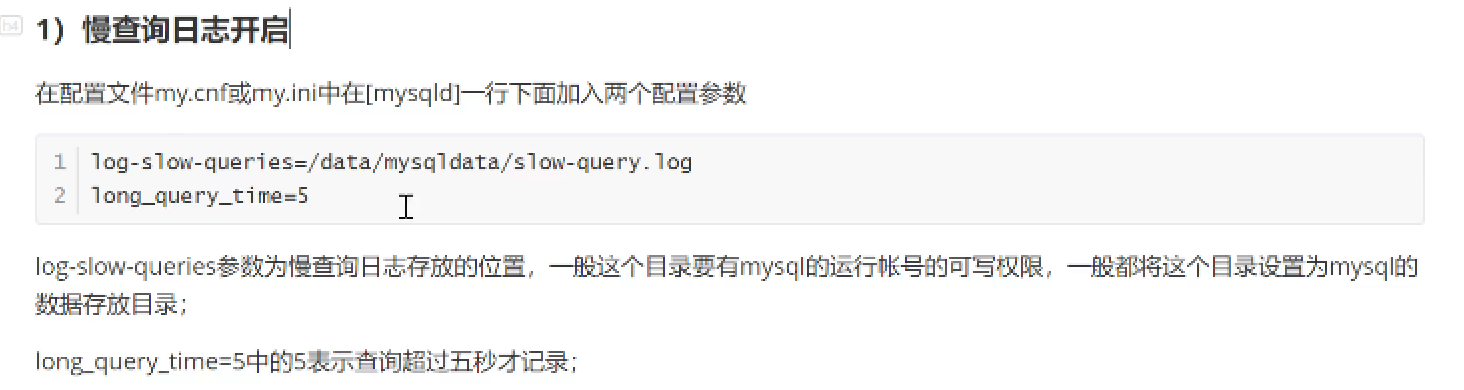
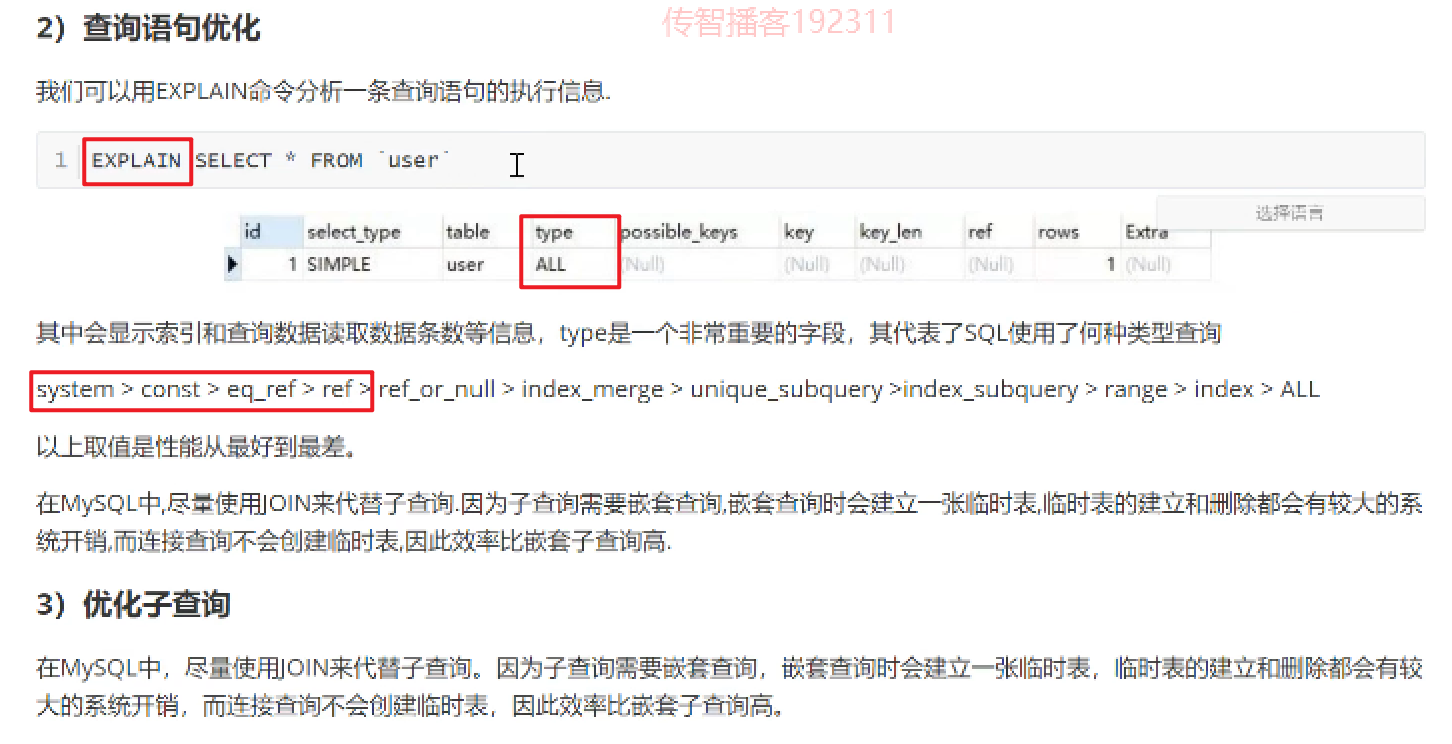

查单表比查询多表来得快很多。
硬优化:
mysql优化的知识(自己上网找的)
优化的目标是尽可能减少JOIN中Nested Loop的循环次数,以此保证:永远用小结果集驱动大结果(Important!)!: A JOIN B,A为驱动,A中每一行和B进行循环JOIN,看是否满足条件,所以当A为小结果集时,越快
查看sql是否用到索引:
我们只需要注意一个最重要的type 的信息,很明显的体现是否用到索引:
type结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般来说,得保证查询至少达到range级别,最好能达到ref,否则就可能会出现性能问题。
————————————————
分页查询的优化
数据量很大的情况下,对于分页查询你有什么优化方案吗?
分页查询方式会从数据库第一条记录开始扫描,所以越往后,查询速度越慢,而且查询的数据越多,也会拖慢总查询速度。
#1000000偏移量与100查询量 这2个数越大,那么速度也就越慢select * from orders_history where type=8 limit 1000000,100;
JVM
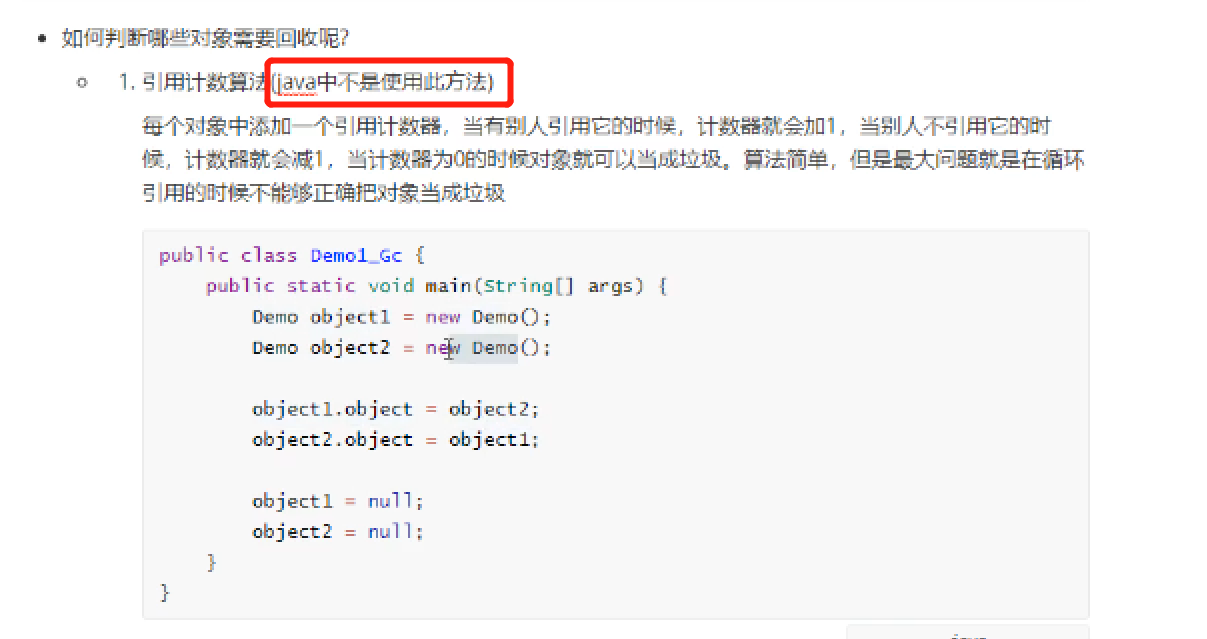
垃圾回收机制与垃圾回收算法
https://www.cnblogs.com/sunniest/p/4575144.html 垃圾回收机制与垃圾回收算法 https://blog.csdn.net/YHYR_YCY/article/details/52566105 Minor GC和Full GC触发条件 https://www.cnblogs.com/ityouknow/p/5610232.html 内存结构
内存模型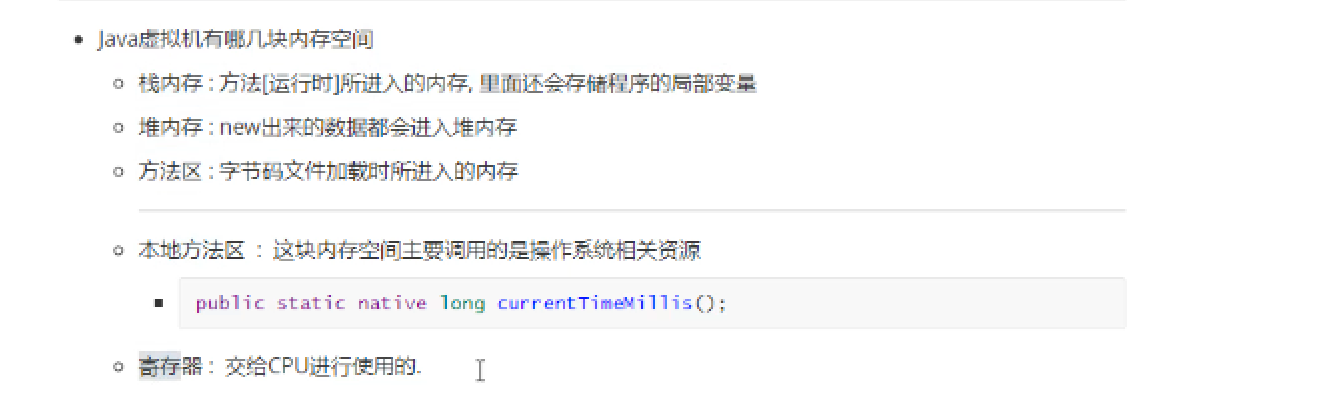
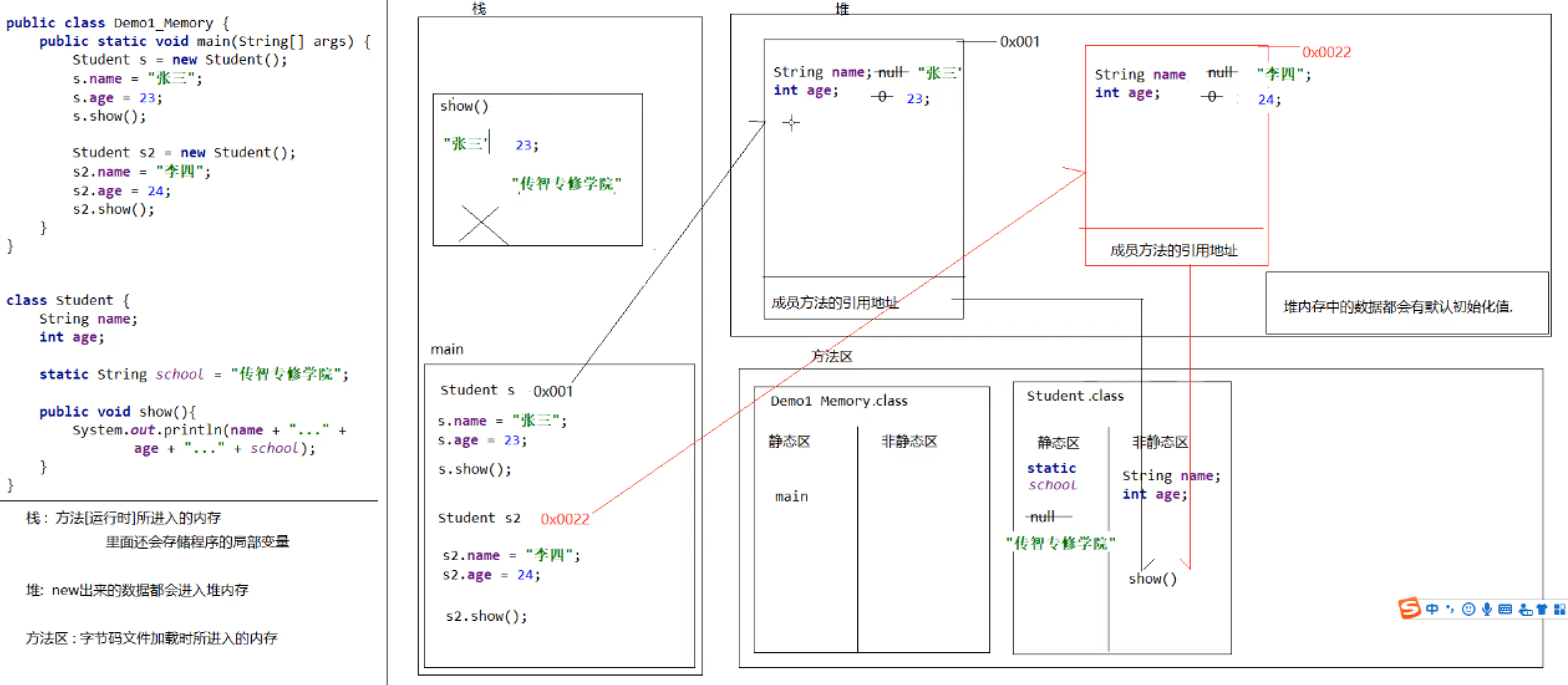
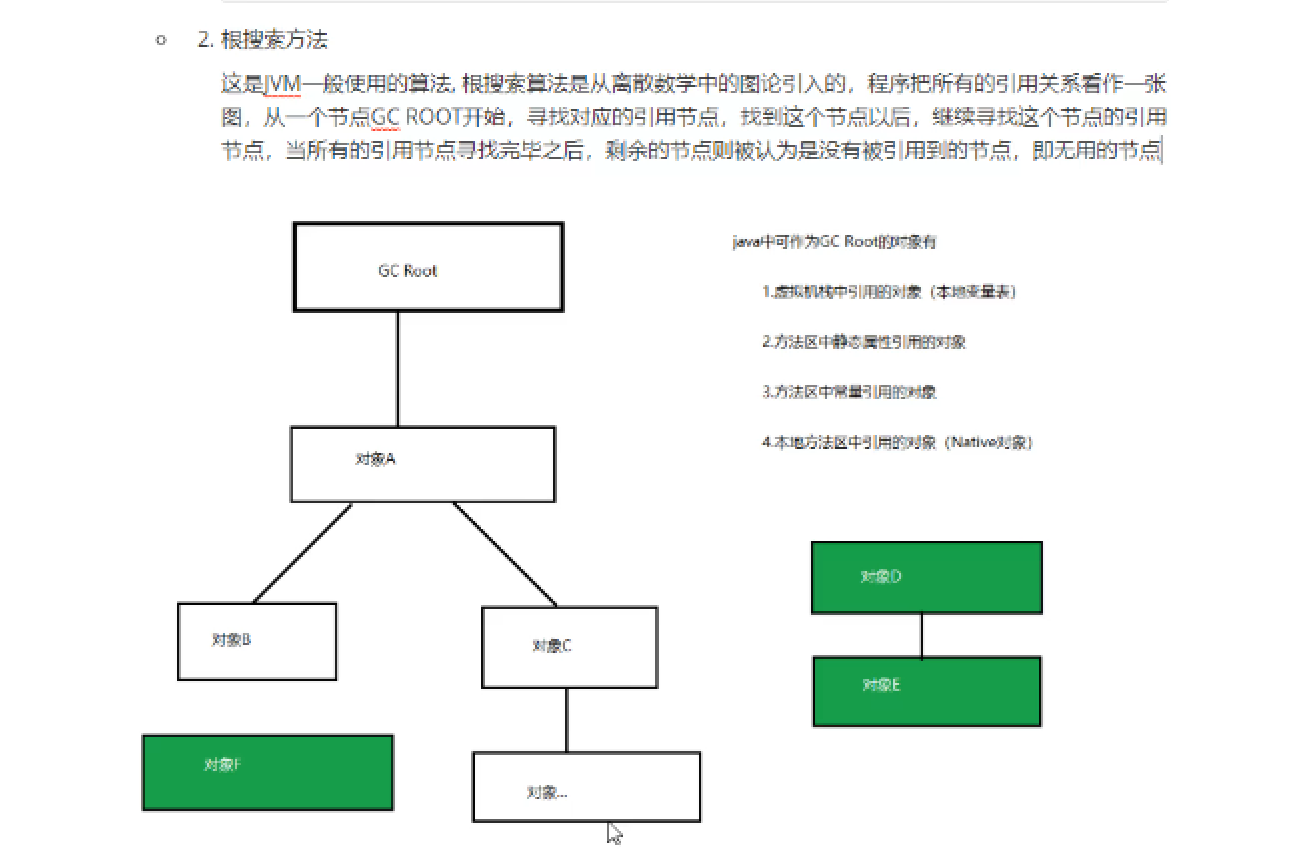
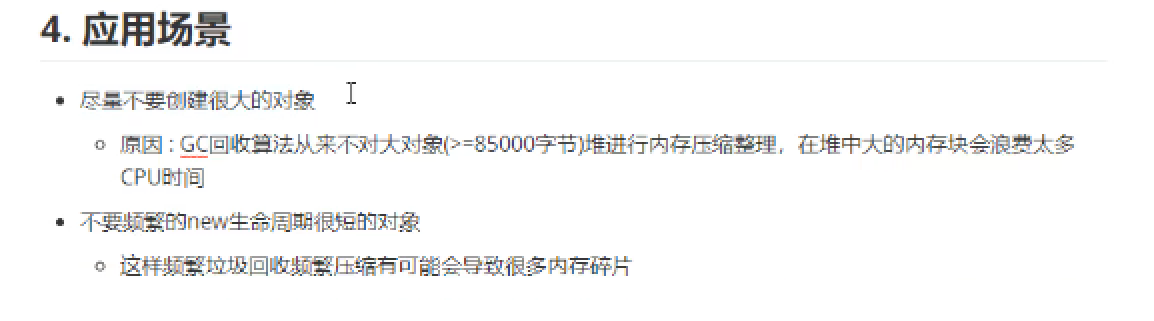
内存碎片(比如安卓手机很卡,你恢复出厂设置后不卡,其中就是清理了内存碎片)
多线程
spring
springCloud
RabbitMQ
rabbitMQ的工作模式你可以讲下吗?消费者是竞争关系 ,指的是绑定在一个队列上吗?*与#是有什么区别?
1、简单模式 HelloWorld 一个生产者、一个消费者,不需要设置交换机(使用默认的交换机 “”) routingKey:路由名称 同队列名称
2、工作队列模式 Work Queue(轮询) 一个生产者、多个消费者(竞争关系),不需要设置交换机(使用默认的交换机 “”) routingKey:路由名称 同队列名称 消费端:和上面的没有区别,只是多个消费者
上面两个: 不需要设置交换机(使用默认的交换机 “”)routingKey:路由名称 同队列名称 下面三个:创建交换机(exchangeDeclare) 和 绑定队列与交换机(queueBind)
3、发布订阅模式 Publish/subscribe(fanout) 需要设置类型为fanout的交换机,并且交换机和队列进行绑定,当发送消息到交换机后,交换机会将消息发送到绑定的队列 生产端: 创建交换机(exchangeDeclare) 和 绑定队列与交换机(queueBind) routingKey:路由名称 “”
4、路由模式 Routing(direct) 需要设置类型为direct的交换机,交换机和队列进行绑定,并且指定routing key,当发送消息到交换机后,交换机会根据routing key将消息发送到对应的队列 生产端: 创建交换机(exchangeDeclare) 和 绑定队列与交换机(queueBind) routingKey:路由名称 通过路由名称(queueBind basicPublish)匹配
5、通配符模式 Topic(更加强大 更加灵活)(topic) 需要设置类型为topic的交换机,交换机和队列进行绑定,并且指定通配符方式的routing key,当发送消息到交换机后,交换机会根据routing key将消息发送到对应的队列 生产端: 创建交换机(exchangeDeclare) 和 绑定队列与交换机(queueBind) routingKey:路由名称 通过路由名称(queueBind basicPublish)通配符 匹配
通配符规则:
:匹配一个或多个词
:匹配1个词 举例: item.#:能够匹配item.insert.abc 或者 item.insert item.:只能匹配item.insert
rabbitMQ的应用场景?
超时订单处理;支付成功后修改订单状态、新增订单日志;商品上/下架后导入/删除数据到索引库中
RabbitMQ中如何防止数据丢失?
MQ如果挂了怎么处理?可以进行持久化,你知道怎么进行持久化?
rabbitmq消息持久化存储包含以下三个方面: 1、exchange的持久化 在申明exchange的时候,有个参数:durable。当该参数为true,则对该exchange做持久化,重启rabbitmq服务器,该exchange不会消失。durable的默认值为true 2、queue的持久化 申明队列时也有个参数:durable。当该参数为true,则对该queue做持久化,重启rabbitmq服务器,该queue不会消失。durable的默认值为true 3、message的持久化 设置了BasicProperties的deliveryMode为2,做消息的持久化。
如何保证消息队列rabbitmq的幂等性/RabbitMQ如何避免消息重复消费?
幂等性:一个操作多次执行产生的结果与一次执行产生的结果一致 使用数据库的乐观锁来保证,(每个消息用一个唯一标识来区分,消费前先判断标识有没有被消费过,若已消费过,则直接ACK;没有消费过,就处理) 这个还得结合业务来思考,这里给几个思路。 ① 如果你拿个数据要写库,你先根据主键id查一下。如这数据都有了,你就别插入了。update一下。 ② 如果你拿个数据是要更新表里的字段,直接update就好,幂等的。 ③ 基于数据库的唯一性索引。因为有唯一性索引了。所以重复数据只会插入报错,不会导致数据库中出现重复的数据。 ④ 如果你是写redis,那没问题了。每次都是set,天然幂等。
如何保证rabbitMQ消息的可靠性?
可靠性就是保证消息不丢失,能够被消费。
- 丢消息的情况有3种情况
- 生产者丢
- rabbitmq丢
- 消费端弄丢
- 如何保证消息不丢失,就是分别避免每一个环节丢失
保证
生产者不丢消息——开启confirm(推荐) 保证rabbitmq不丢消息——开启RabbitMQ持久化(交换机、队列、消息) 保证消费端不丢消息——关闭RabbitMQ自动ack(改成手动)
- 保证生产者不丢消息,要确保说写rabbitmq的消息别丢,可以开启confirm模式。
- 每次写的消息都会分配一个唯一的id,如果写入了rabbitmq中,rabbitmq会给你回传一个
ack消息,告诉你说这个消息ok了。- 如果rabbitmq没能处理这个消息,会回调你一个
nack接口,告诉你这个消息接收失败,我们可以重试。- 保证rabbitmq不丢消息,开启rabbitmq的持久化(持久化queue和message)
- 消息写入之后会持久化到磁盘,假如rabbitmq挂了,恢复之后会自动读取之前存储的数据,一般数据不会丢。
- rabbitmq还没持久化,自己就挂了,可能导致少量数据会丢失的,但是这个概率较小。
持久化exchange,设置durable为true,表示交换机进行持久化持久化queue,在创建queue的时候将其设置为持久化的,这样就可以保证rabbitmq持久化queue的元数据,但是不会持久化queue里的数据;持久化Message,在发送消息的时候将消息的deliveryMode设置为2,就是将消息设置为持久化的,此时rabbitmq就会将消息持久化到磁盘上去。- 保证消费端不丢消息
- 依靠ack机制,简单来说,就是你
关闭rabbitmq自动ack,通过一个api来手动ack就行,就是每次你自己代码里确保处理完的时候,在程序里ack一下。
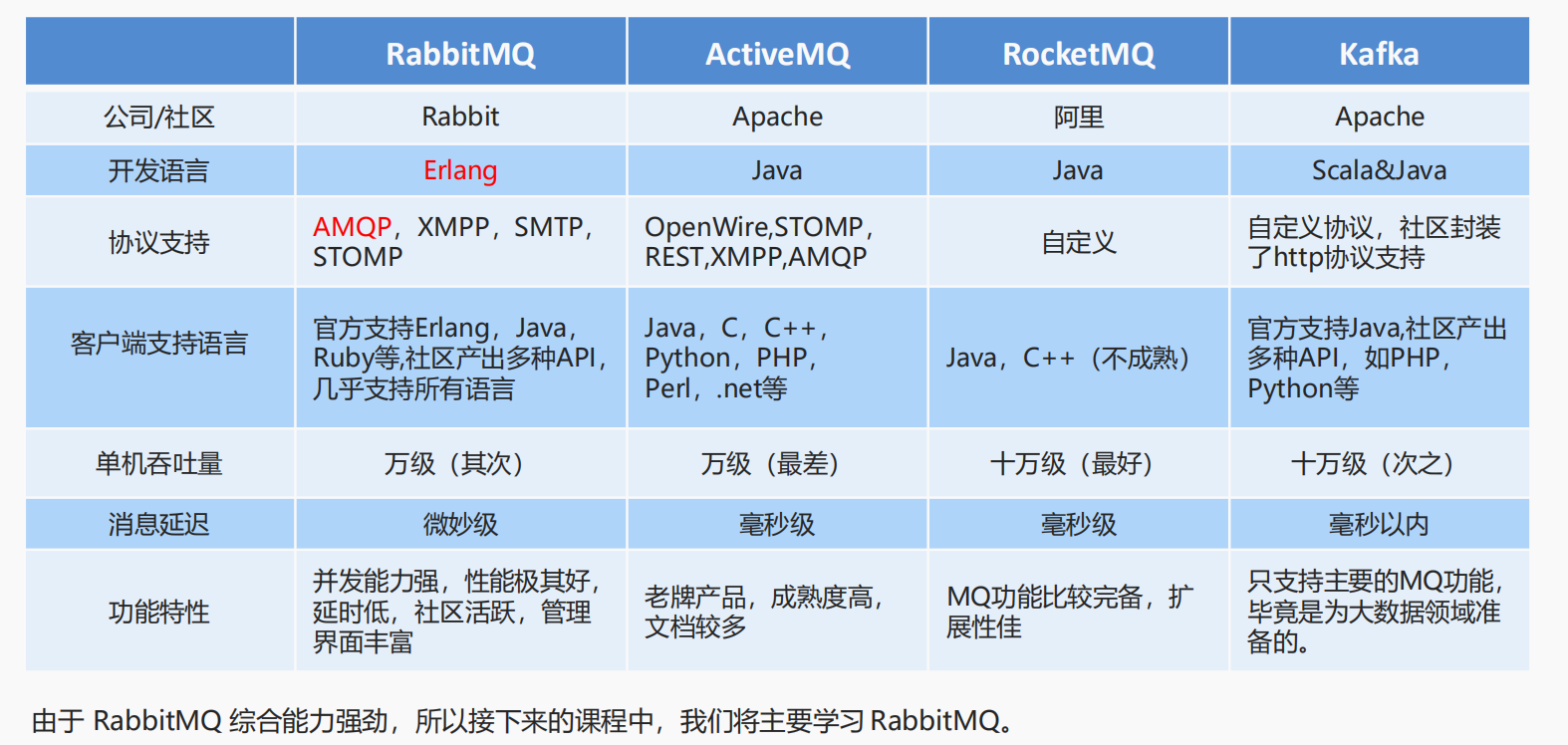
kafka用过吗?kafka与 rabbitMQ的区别?
没用过,不过我有了解到kafka单机支持的吞吐量更高,rabbitMQ支持的吞吐量为万级,而kafka支持的吞吐量为十万级,更适合大数据领域。 RabbitMQ:基于AMQP协议,erlang语言开发,稳定性好,消息延迟在微秒级 kafka:自定义协议,消息延迟在毫秒以内
谈谈rabbitmq中重试机制?
- 默认情况下,如果消费者程序出现异常情况, Rabbitmq 会自动实现补偿机制 也就是重试机制,会一直重试到不抛出异常为准
- 默认是5s重试一次,重试策略可以修改
- 最大重试次数(默认无数次)
- 重试间隔次数
- 可以设置应答模式,默认是自动应答,可以采取手动应答
1、修改重试策略
listener:simple:retry:####开启消费者重试enabled: true####最大重试次数(默认无数次)max-attempts: 5####重试间隔次数initial-interval: 3000
2、修改应答模式为手动,在application.yml中配置
acknowledge-mode: manual
RabbitMQ如何保证消息的顺序性?
RabbitMQ如何避免消息堆积?
- 为什么出现消息堆积?
- 消息堆积主要是生产者和消费者不平衡导致的
- 核心处理思路还是提高消费者的消费速率,保证消费者不出现消费故障。
- 哪些方式可以避免消息堆积呢?
- 足够的cpu和内存资源(硬件)
- 消费者数量足够多
- 避免消费者故障,举个例子,消费端每次消费之后要写MySQL,结果MySQL挂了,消费端卡那儿了,不动了。或者是消费端出了个什么叉子,导致消费速度极其慢。
elasticSearch
es跟传统数据库的区别
商品搜索引擎为什么要用elasticSearch、 购物车为什么就要用redis 他们的区别是什么
es脚本
es的数据类型
字符串:text(会分词)、keyword(不会分词) 数值:float、integer、double、byte…… 布尔:boolean 二进制:binary(不常用) 范围类型:integer_range, float_range, long_range, double_range, date_range 日期:date 复杂数据类型:数组:[ ](数组类型的JSON对象)、对象:{ }(单个JSON对象)
es能分词的是什么,不能分词的是什么
text:会分词,不支持聚合 keyword:不会分词,将全部内容作为一个词条,支持聚合
es倒排索引的原理?聚合有用过吗?
keyword类型的支持聚合
es中请对倒排索引下一个定义, 以及正排索引是什么?
es底层是如何实现分词?我提到2种分词,具体是哪2种
倒排索引 一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,对应一个包含它的文档id列表。
es中ik分词器,你们直接用默认的吗
es的内置分词器
standard对中文很不友好,处理方式为:一个字一个词 我们是有安装了开源的中文分词工具包IK分词器(IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包) IK分词器有两种分词模式:ik_max_word和ik_smart模式。 ik_max_word:会将文本做最细粒度的拆分,比如会将“乒乓球明年总冠军”拆分为“乒乓球、乒乓、球、明年、总冠军、冠军。 ik_smart:会做最粗粒度的拆分,比如会将“乒乓球明年总冠军”拆分为乒乓球、明年、总冠军。
你们项目中用的es版本号是多少 5.6.8
es用它做什么?es的分组查询有使用过吗?
Mybatis
mybatis什么时候要用$不要用#号
需要直接插入一个不做任何修改的字符串到SQL语句中。比如order by 后的排序字段,表名、列名 比如 order by column,这个时候务必要用${},因为如果你使用了#{},那么打印出来的将会是select * from table order by ‘name’ ,这样是没用的
mybatis的一级缓存和二级缓存
mybatis用来干嘛,sql在xml文件中多表查询语句复杂的时候怎么优化
- 考虑冗余几个字段采用单表的设计
- sql的优化,判断使用什么连接方式,是左连接还是内连接。可以结合explain
JPA是什么?JPA是spring底下的,他可以代替MyBatis
mybatis与hibernate的区别在哪?
JPA默认使用hibernate作为ORM实现 Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的orm框架,hibernate可以自动生成SQL语句,自动执行,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。 Spring Data JPA与MyBatis对比,起始也就是hibernate与MyBatis对比 Hibernate 属于全自动 ORM 映射工具,使用 Hibernate 查询关联对象或者关联集合对象 时,可以根据对象关系模型直接获取,所以它是全自动的。而 Mybatis 在查询关联对象或 关联集合对象时,需要手动编写 sql 来完成,所以,称之为半自动 ORM 映射工具。虽然Mybatis是半自动的,但是他给用户提供了更多更强大的sql操作,并且在很大程度上提高了执行效率。
两者的区别具体体现在: 1)Mybatis 和 hibernate 不同,它不完全是一个 ORM 框架,因为 MyBatis 需要程序员自己 编写 Sql 语句,不过 mybatis 可以通过 XML 或注解方式灵活配置要运行的 sql 语句,并将 java 对象和 sql 语句映射生成最终执行的 sql,最后将 sql 执行的结果再映射生成 java 对 象。 2)Mybatis 学习门槛低,简单易学,程序员直接编写原生态 sql,可严格控制 sql 执行性能,灵活度高,非常适合对关系数据模型要求不高的软件开发,例如互联网软件、企业运营类软件等,因为这类软件需求变化频繁,一但需求变化要求成果输出迅速。但是灵活的 前提是 mybatis 无法做到数据库无关性,如果需要实现支持多种数据库的软件则需要自定义多套 sql 映射文件,工作量大。 3)Hibernate 对象/关系映射能力强,数据库无关性好,对于关系模型要求高的软件(例如 需求固定的定制化软件)如果用 hibernate 开发可以节省很多代码,提高效率。但是 Hibernate 的缺点是学习门槛高,而且由于hibernate提供的方法只能对应一些简单的操作,一些复杂的操作是需要我们自己编写sql并完成映射的,所以hibernate要精通门槛更高.并且由于hibernate的封装,导致性能上和mybatis有一定差异,所以使用hibernate需要在性能和对象模型之间做权衡,所以想要用好 Hibernate 需要具有很强的经验和能力才行。
mybatis的查询语句有哪两种方式?哪种方法比较好?
xml和接口中
我回答了接口比较好,但面试官回答xml配置文件比较好,可以解耦,java代码与sql语句分开;可以减少在java中编写sql脚本,像是if…else
mybatis的常用注解?
常见的注解有增删改查四种 @SelectKey注解:插入后,获取id的值 @Result,@Results,@ResultMap是结果集映射的三大注解。 @one注解:用于一对一关系映射 @many注解:用于一对多关系映射 如果查询语句是包含select * from table where id in (…),可以用什么 面试者回答:foreach标签可以用来进行遍历的
@Select({"<script>","select","id, name, user_id","from label","where id in","<foreach collection='ids' item='id' open='(' separator=',' close=')'>","#{id}","</foreach>","</script>"})List<LabelDTO> getLabelsByIds(@Param("ids") List<Long> ids);
mybatis的分页查询?分页的原理? 它的底层是经历了什么查询语句?
面试官答:分页进行2次查询,一次limit,另一次查询总数
项目相关
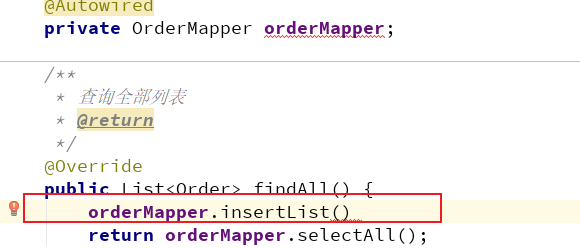
日志文件的管理 你们是怎么做的? (主要用到spring的AOP)
应用场景:后台管理中每次修改数据的动作都有必要记录,方便追踪数据的变化。
spring的AOP可以在不修改源代码的情况下,记录到这个方法相关的动作操作

log4J支持将日志输出到控制台、日志或者数据库中
ID如果使用uuid,对比雪花算法有什么缺点?结合BTree说说 面试官回答:uuid分列,雪花算法直接按顺序排放??
缺点: 1)没有排序,无法保证趋势递增。 2)UUID往往是使用字符串存储,查询的效率比较低。 3)存储空间比较大,如果是海量数据库,就需要考虑存储量的问题。 4)传输数据量大 UUID长且无序;主键应越短越好,无序会造成每一次UUID数据的插入都会对主键地址的B+Tree树进行很大的修改 在时间上,1)uuid由于占用的内存更大,所以查询、排序速度会相对较慢;2)在存储过程中,自增长id由于主键的值是顺序的,所以InnoDB把每一条记录都存储在上一条记录的后面。当达到页的最大填充因子时(innodb默认的最大填充因子为页大小的15/16,留出部分空间用于以后修改),下一条记录就会写入新的页面中。一旦数据按照这种方式加载,主键页就会被顺序的记录填满。而对于uuid,由于后面的值不一定比前面的值大,所以InnoDB并不能总是把新行插入到索引的后面,而是需要为新行寻找合适的位置(通常在已有行之间),并分配空间
分布式ID你有实现吗?有了解雪花算法?
分布式ID是由我们经理实现的一个工具类
开发中有遇到什么问题? 我讲到ID自增会重复,用到UUID,但不好排序,所以引入雪花算法。面试官对此回答不满意
当数据量庞大时,会考虑对数据库进行分库分表,那么分表后数据库自增id不能满足全局唯一id来标识数据;因为分表后每张表自增id是独立的,肯定会生成重复的ID
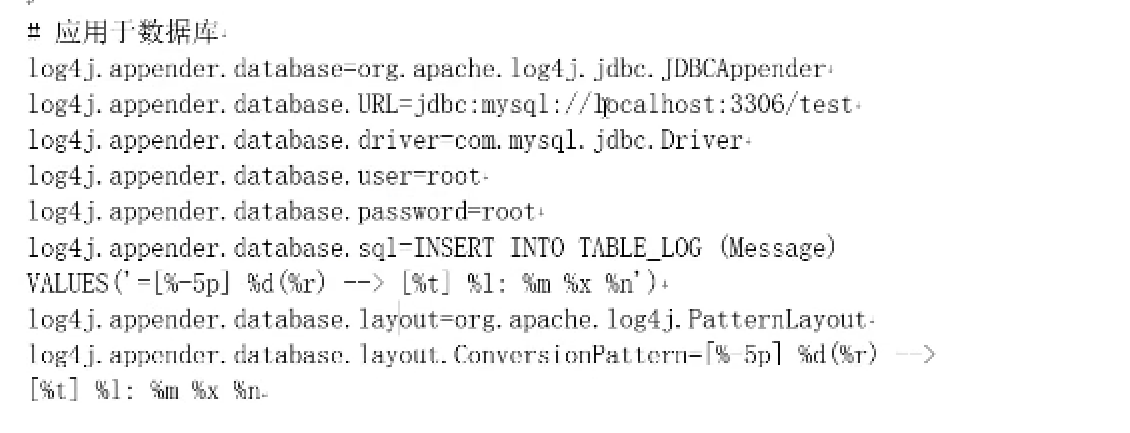
雪花算法: Twitter开源的、long型的ID 其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(需要开发人员指定,5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0
在项目中遇到的最大的问题是什么以及怎么解决的?
开发中有遇到什么问题? 我讲到ID自增会重复,用到UUID,但不好排序,所以引入雪花算法。面试官对此回答不满意
- maven刚开始用的时候因为不怎么会用经常出现环境问题,
遇到过:使用骨架构建工程失败 (阿里云镜像->中央仓库镜像)、插件报错(挨着执行一次插件,让他重新下载,如果下载失败,再进行阿里云镜像的注释尝试)、某个引入的坐标无法下载 (查找本地仓库,将坐标对应的文件夹删掉,然后重新导入坐标重新下载)
- 需要用到第三方报表技术时,因为没接触过,无从下手,后面查找资料,从官方入门案例学习入手
- 客观:需求变化快(产品经理或者客户频繁更新需求)
- 主观:前后端集成测试问题:集成的时候才发现,由于业务发生了变更修改了API接口,但是忘记更新文档

分布式事务Seata在项目中是怎么使用? 我回答:添加@GlobalTransactional,还需要添加唯一的ID,比如
- 基于Seata实现分布式事务(同步,是防止出现超卖的情况)
应用场景:下单扣减库存,如果订单保存失败,那么需要回滚库存数(涉及订单微服务、商品服务) 实际操作:
- 我们专门创建了一个Seata的分布式事务微服务,在这个微服务中导入依赖(fescar版本号为0.4.2)
涉及到的分布式事务管理的微服务需要导入这个微服务,以及在数据库中添加undolog日志(保存了事务发生之前的数据的一个版本,可以用于回滚)。然后在订单微服务的方法上加@GlobalTransactional(name = “order_add”) 【商品微服务的方法上加@Transactional,是对进行本地事务的控制】


若有收获,就点个赞吧
0 人点赞
