特征工程是推荐系统和机器学习项目中最重要的一个环节,它直接决定了模型的上限。
深度学习在特征生成方面有很大的贡献,允许通过多个处理层来学习具有抽象能力的数据表示,比如词嵌入表示模型。
随着网络层数的增加,激活函数的调节,神经网络非线性拟合能力不断提高。
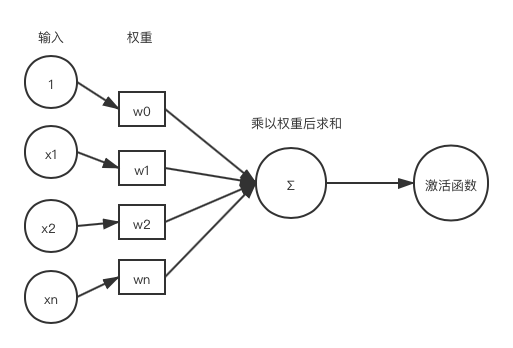
神经网络基础
感知器
梯度下降
梯度的反方向是函数在定点下降最快的方向。梯度下降的主要思想是通过迭代,每次定点沿着梯度相反的方向以一定的学习率逼近局部最低点,最终到达局部最小值。
批梯度下降
批梯度下降会获得全局最优解,下降路径很稳定,并且会逐渐逼近最优解。缺点是在更新每个参数的时候需要遍历所有的数据,计算量会很大,并且会有很多的冗余计算,导致的结果是当数据量大的时候,每个参数的更新都会很慢。
随机梯度下降
随机梯度每次选择一个样本更新权重,更新速度更快,会跳到新的和潜在的局部最优解,缺点是下降的路径很曲折,噪声样本可能会导致权重波动从而无法收敛到局部最优解,在最小值附近震荡。
小批量梯度下降
小批量梯度下降结合了批梯度下降和随机梯度下降的优点,每次更新的时候使用k个样本。减少了参数更新次数,可以达到更加稳定收敛的结果。
Momentum
参数更新时采用累计梯度来代替当前梯度。如果某些参数在连续时间内梯度方向不同的话,那么动量会变小。相反,如果在连续时间内梯度方向相同的话,那么动量会增大。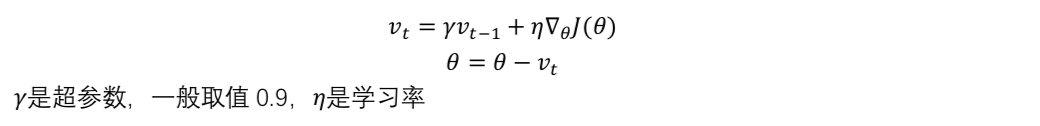
RMSprop
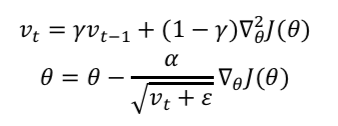
Adam
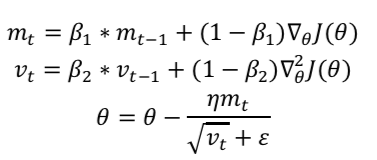
优化算法
参数初始化
参数初始化对高维非线性非凸函数非常重要。如果初始化参数太小,在网络的训练过程中前馈和反馈的信号可能会丢失,导致神经元之间没有区分(梯度消失)。如果初始化参数太大,可能会导致梯度失控爆炸的问题,影响模型的收敛性。
- 高斯分布初始化:参数服从固定的均值和方差的高斯分布进行随机初始化
- 均匀分布初始化:参数服从区间[-a, a]的均匀分布进行随机初始化
- Xavier初始化:尽量让输出的方差等于输出的方差
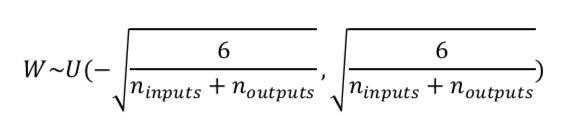
学习率的选择
自始至终保持同样的学习率其实不太合适。因为参数刚刚开始学习的时候,参数和最优解隔的比较远,需要保持一个较大的学习率尽快逼近最优解。但是学习到后面的时候,参数和最优解已经隔的比较近了,如果还保持最初的学习率,容易越过最优点,在最优点附近来回振荡。
- 反向衰减学习率
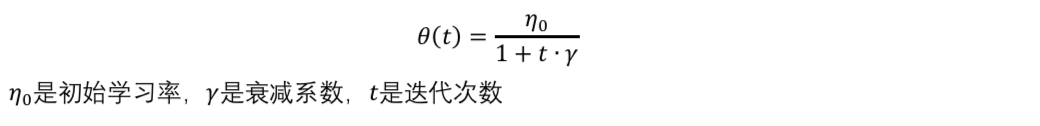
- 指数衰减学习率
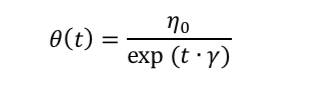
Batch Normalization
Batch Normalization是在数据传入激活函数之前做的标准化操作。
Batch Normalization在常规的标准化后面还有一个反向操作,将normalize后的数据再扩展和平移。这是为了让神经网络自己去学着和使用这两个参数gamma和beta,这样神经网络就可以自己琢磨出来之前的normalization有没有起到优化作用,如果没有,就用gamma和beta来抵消之前normalization的操作。
卷积神经网络
卷积神经网络的第l+1层神经元和l层神经元局部区域相连接,该区域执行卷积操作和非线性变换,生成第l+1层神经元。与标准神经网络相比,卷积神经网络具有更少的参数,从而可以训练非常深的构架。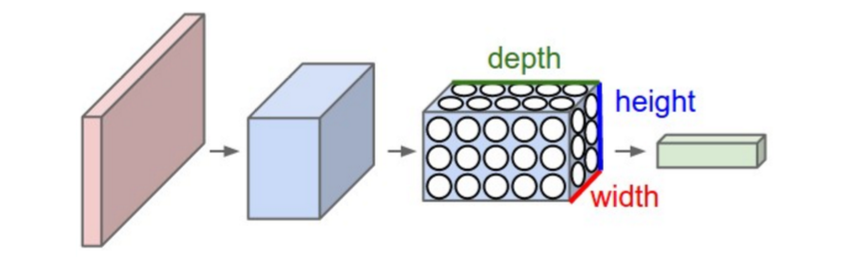
卷积层
卷积层有多个卷积核,局部区域与这些卷积核经过卷积运算生成不同的特征。同一层(same depth)的像素点共享参数,因此我们可以在不同的位置检测相同的特征。多个卷积核就可以检测多个特征。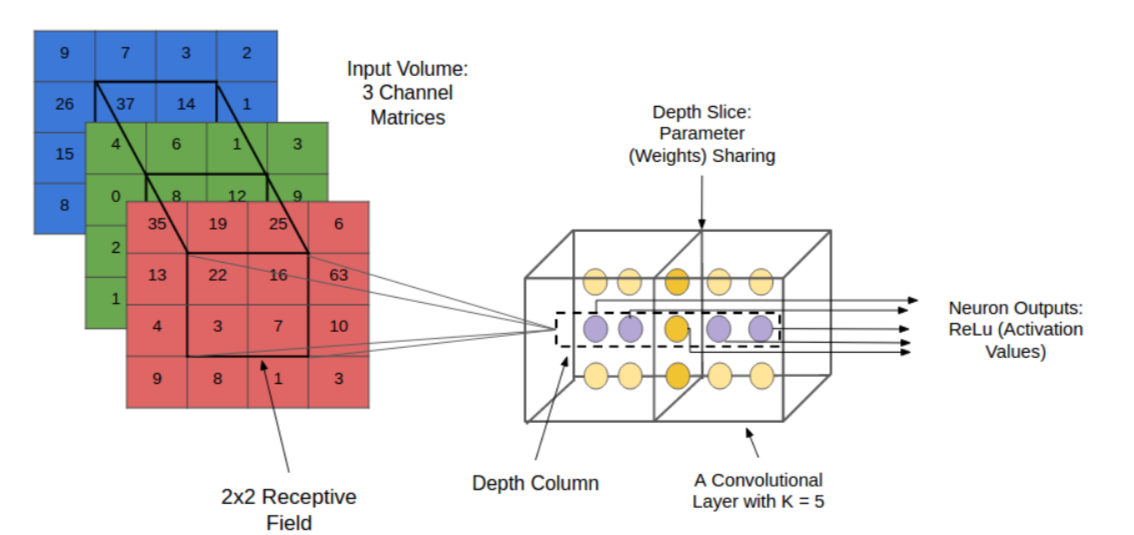
在坐标(i,j)处的卷积计算结果是: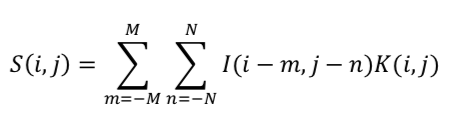
demo: http://cs231n.github.io/convolutional-networks/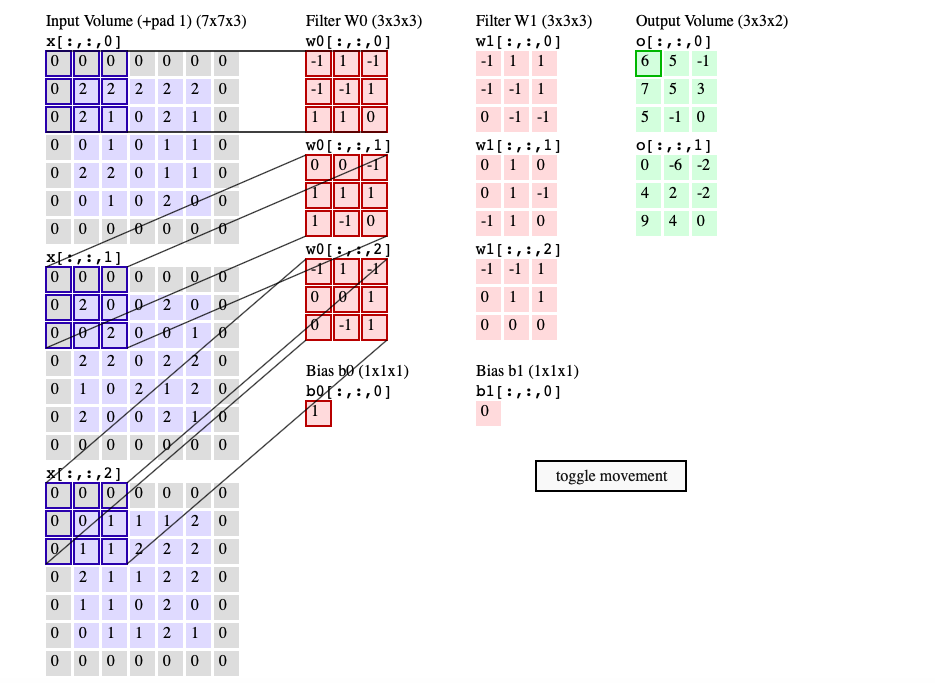
最后的结果需要经过一个非线性激活函数(Relu)
如果原始的体积是W1H1D1,需要4个参数:卷积核的个数K,卷积核的边长F,步长S,零填充的数量P。经过卷积之后的体积为W2H2D2,其中: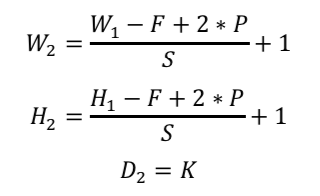
假设原始的图像是22722732,对于第一层卷积层,K=96,F=11,S=4,P=0:
W2=55,H2=55,D2=96
参数的数量为:(11113+1)96=34,944
如果替换为全连接神经网络,参数的数量为:(22722732+1)555596=44,892,355,200
池化层
池化层通常用于连续的卷积层之间,其主要作用是减少特征和参数的数量,减少网络的计算量,从而控制过拟合。
最大池化
(效果最佳)
在每个通道的n*m区域内计算保留神经元的最大值: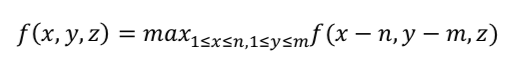
平均池化
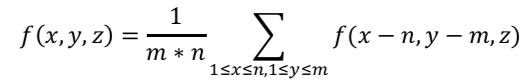
全连接层
全连接层神经元与上一层中所有的神经元完全连接在一起,通常被用于卷积神经网络的最后一层。在全连接层之后通常连接一个softmax函数计算图像属于每个类别的概率,softmax的损失值通过cross entropy计算得到。
常见的网络结构
AlexNet
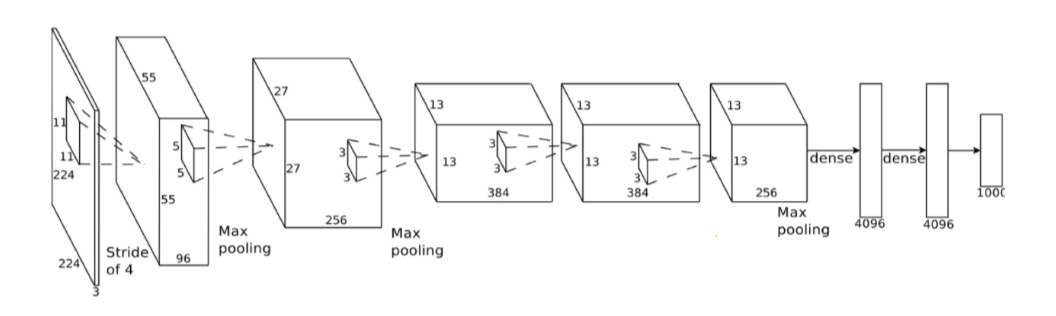
- 5个池化层跟着3个全连接层
- 大约有60M参数,且大多数参数来自全连接层
- 第一次使用Relu作为激活函数
- 引用数据增强技术增加标签数据集
- 采用dropout技术,dropout=0.5
- SGD momentum=0.9,learning rate=0.01,当验证集准确率停滞时,手动将学习率除以10
ResNet
常规的网络堆叠随着网络结构加深,效果越来越差。造成这样的现象的原因之一是网络越深,梯度很难传播回低层,梯度消失现象越明显。
为此引入了残差网络结构,在输入和输出之间引入了identity connection,而不是做简单的网络堆叠,可以解决由网络结构变深导致的梯度消失问题。
循环神经网络
标准RNN
RNN有一个输入序列x(t)和一个隐藏层序列h(t),每一时刻的h(t)取决有当前时刻的输入x(t)和前一时刻的h(t-1),即: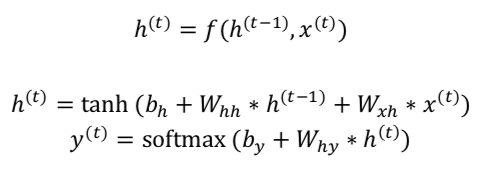
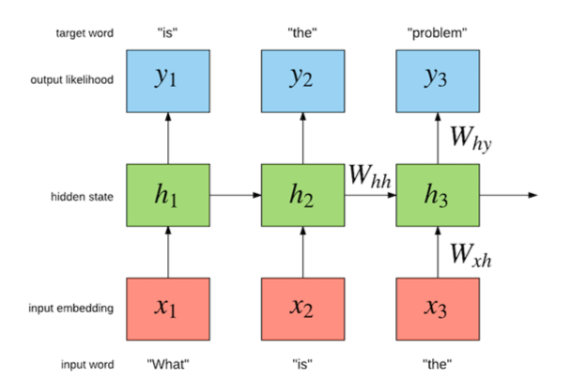
RNN的显著优点是:能够将之前时刻t的信息,利用到当前时刻所需要完成的任务上。
Challenge:当预测目标和上下文相关项距离很远的时候,RNN不能学习到长距离的依赖性,会出现梯度消失或者梯度爆炸的问题。
LSTM
同时引入了记忆单元和门机制,有效解决了梯度消失和梯度爆炸的问题。其中,内存单元c(t)是LSTM的核心单元,它对历史的隐藏状态h(t-1)和当前的输入x(t)进行编码,通过输入门、遗忘门和输出门控制网络内部的信息流传递。
门结构就是一个sigmoid层和一个点积操作的组合。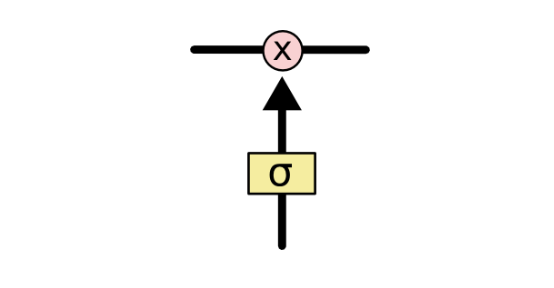
遗忘门
通过sigmoid确定对输入的cell state遗忘多少信息,减少之前无用的信息。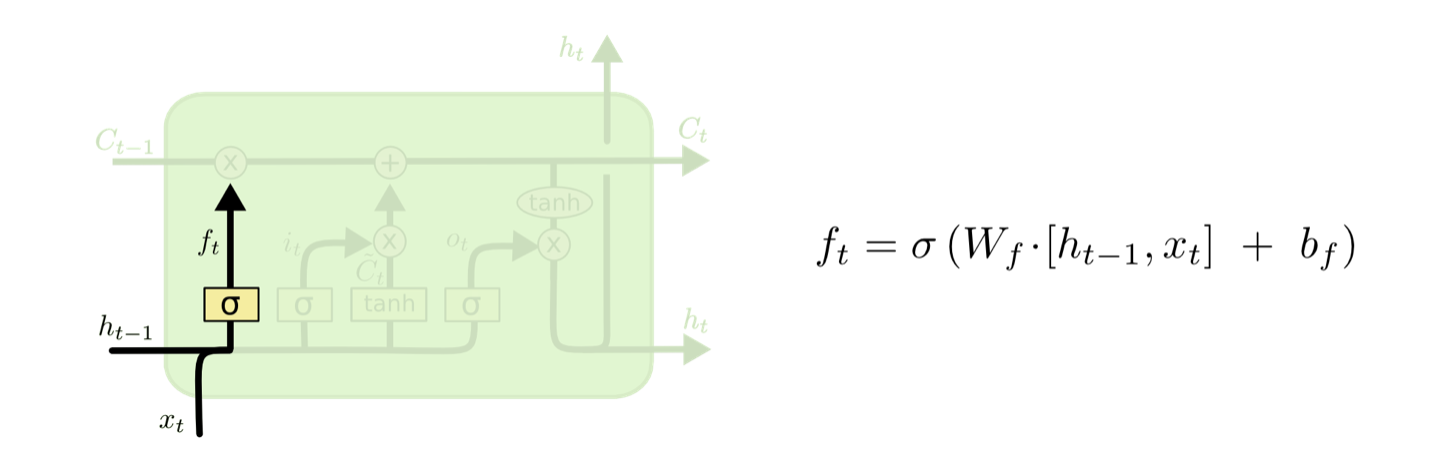
输入门
通过sigmoid决定保留多少信息,通过tanh得到新的候选cell state信息。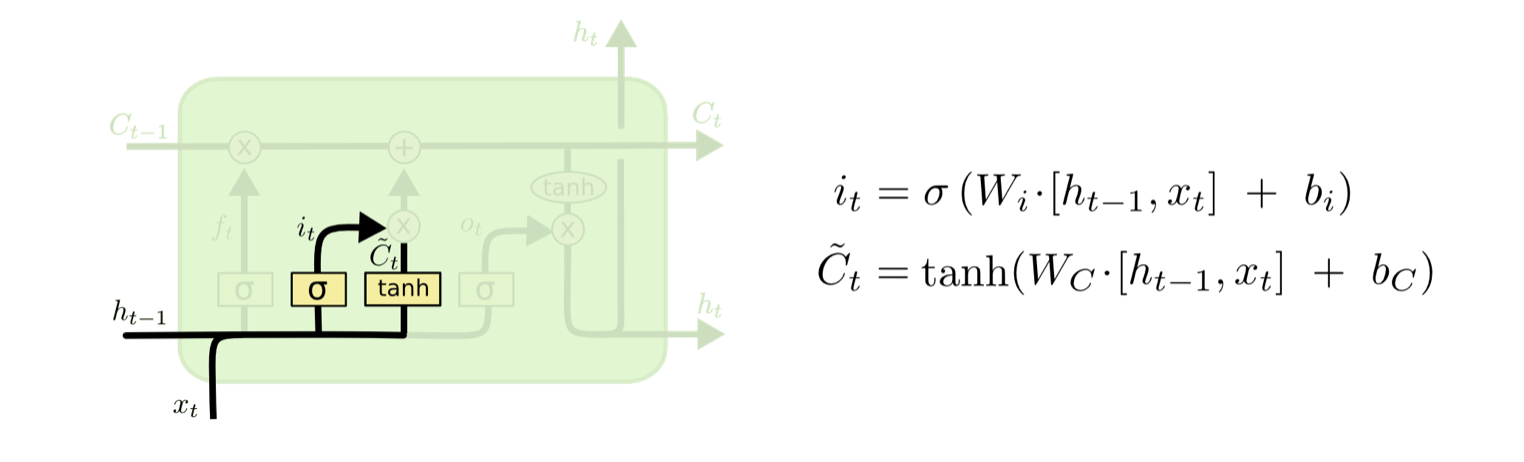
输出门
一个tanh从新的cell state中产生输出,一个sigmoid选择输出的信息量。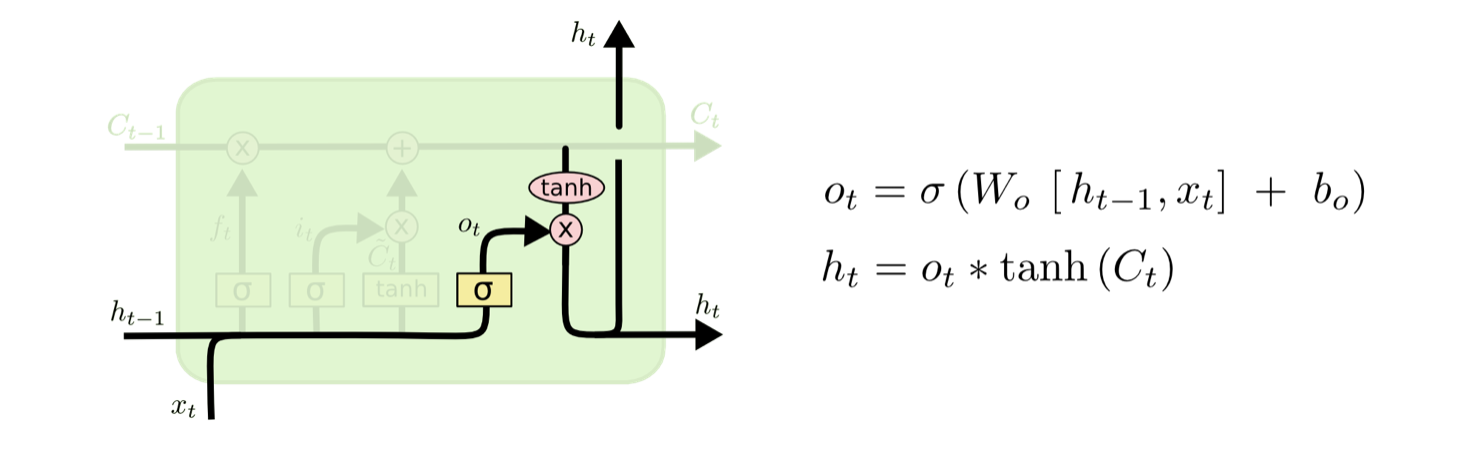
GRU
GRU将遗忘门和输入门合并成一个门,成为更新门,决定保留之间记忆的多少信息。此外,GRU还有一个重置门,决定了如何将新的信息和之前的信息结合。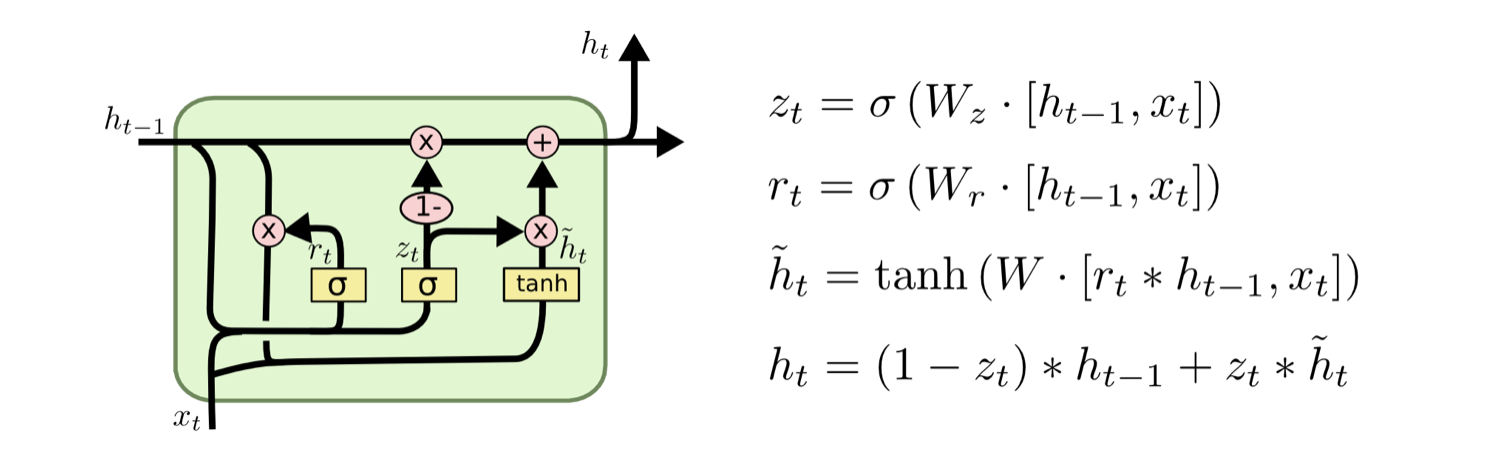

若有收获,就点个赞吧
0 人点赞
