社会化推荐对增加用户对广告的印象和购买意愿有非常强烈的作用。
获取社交网络数据的途径
- 电子邮件
- 用户注册信息
- 用户位置信息
- 论坛和讨论组
- 即时聊天工具
通过联系人列表和分组信息可以知道用户的社交网络关系,通过统计用户之间聊天的频繁程度可以度量出用户之间的熟悉程度。
- 社交网站
社会图谱/双方确认的社交网络:好友相互之间都是现实社会中认识的人,比如家人、朋友、同事等,且好友关系需要经过双方确认。
兴趣图谱/单向关注的社交网络:好友往往不是现实生活中认识的人,只是出于对对方的言论兴趣而建立好友关系,是单方关注的好友关系。
在社交网络中,用户的出度和入度都呈长尾分布。
基于社交网络的推荐
基于邻域的社会化推荐系统

熟悉度可以用用户之间的共同好友比例来度量: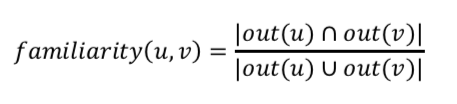
用户的兴趣相似度可以用他们喜欢的物品集合重合度来度量: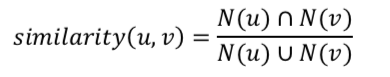
基于图的社会化推荐算法
结合社交网络图和用户物品二分图,定义用户与用户之间边的权重为a,用户和物品之间边的权重为b。
如果我们希望用户好友的行为对推荐结果产生较大的影响,那么就可以选择较大的a。相反,如果我们希望用户的历史行为对推荐结果产生较大的影响,就可以选择较大的b。
因此,需要找到合适的参数来融合用户的社交推荐和历史行为推荐结果。
社会化推荐系统和协同过滤推荐系统
社会化推荐的优势不在于增加预测准确率,而在于通过用户的好友增加用户对推荐系统的信任度,从而增加一些冷门推荐结果的点击率。
node2vec技术在社交网络中的应用
利用用户社交网络计算用户相似度的方法不适用于大规模的社交关系,node2vec可以用一个坐标/向量表示用户在社交网络中的位置。
node2vec整体思路分为两个步骤:
- random walk,即通过一定的规则随机抽取一些点的序列
将点序列输入word2vec模型从而得到每个点embedding向量
random walk
random walk 主要分为两步:
选择初始节点(以图中所有节点作为初始节点)
- 选择下一跳节点
给定一张图和一个初始节点S,标记初始节点位置为当前位置,随机选择当前位置节点的一个邻居并将当前位置移动到被选择的邻居的位置,重复以上步骤。
random walk 通过引入两个参数p和q来控制广度优先和深度优先的游走范围: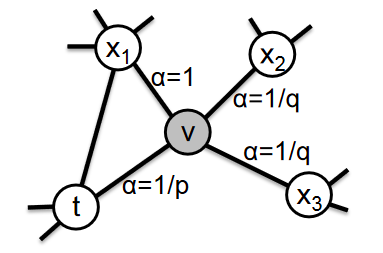
假设第一步是从节点t游走到节点v,在确定下一步的邻接节点时,需要计算每个邻接节点和上一节点t的距离d: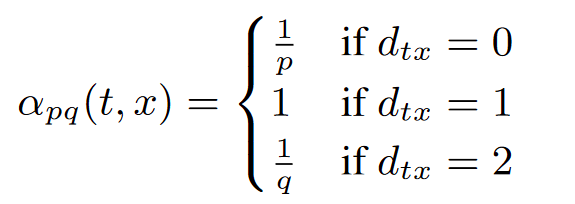
当下一节点选择为t的时候,即返回原节点,d=0;当下一节点为x1时,v、t和x1构成三角形,d=1;当下一节点为x2或x3时,d=2
这样,我们设置不同的p和q,就可以得到不同偏重的node sequence,在训练模型的时候,可以grid search 寻找最优的p和q,也可以根据场景的需要来选择合适的p和q
word2vec
word2vec时从大量文本语料中以无监督的方式学习语义知识的一种模型,被大量运用在NLP中。
word2vec的核心目标是通过一个嵌入空间将每个词映射到一个空间向量上,并且使得语义上相似的单词在该空间内距离很近。
当构建的神经网络训练好时,我们真正需要的是这个模型通过训练学到的参数,即隐藏层的权重矩阵。
Skip-Gram模型的训练输入是某一特定词的词向量(one-hot),输出是特定词对应的上下文词向量。
Skip-Gram模型示意图: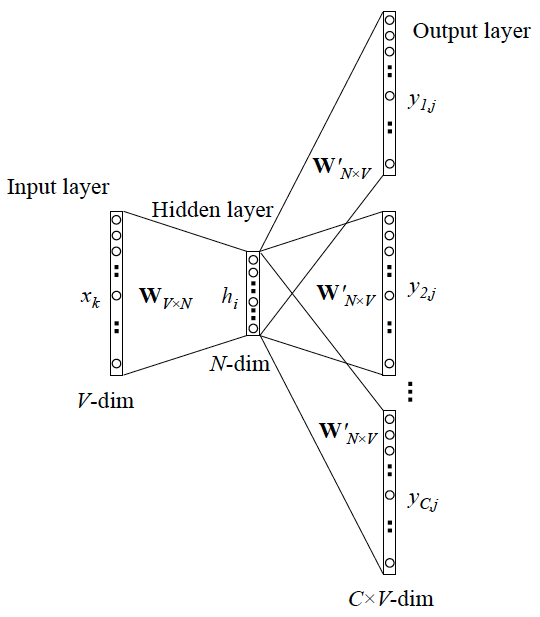
当模型训练完后,最后得到的其实是神经网络的权重,比如现在输入一个词的one-hot向量: [1,0,0,…,0],则在输入层到隐藏层的权重里,只有对应 1 这个位置的权重被激活,这些权重的个数,跟隐藏层节点数是一致的,从而这些权重组成一个向量 vx 来表示x,而因为每个词语的 one-hot encoder 里面 1 的位置是不同的,所以,这个向量 vx 就可以用来唯一表示 x。
CBOW模型的训练输入是某一特征词的上下文相关词对应的词向量(one-hot),输出是该词的词向量。
CBOW训练模型示意图: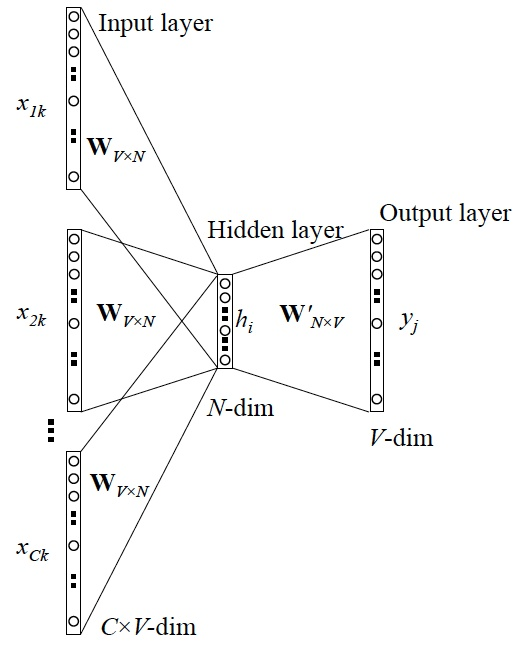
给用户推荐好友
根据用户现有的好友、用户行为记录给用户推荐新的好友,增加社交网络的稠密度和社交网站用户活跃度。

若有收获,就点个赞吧
0 人点赞
