在没有大量用户数据的情况下,设计个性化推荐系统就是冷启动问题。
主要分为用户冷启动、物品冷启动和系统冷启动三类问题。
提供非个性化推荐
先给用户推荐热门排行榜,等到用户数据收集到一定数量的时候,再切换为个性化推荐。
利用用户注册信息
利用用户注册时填写的人口统计学信息和兴趣描述信息等做粗粒度的个性化推荐。
选择合适的物品启动用户的兴趣
在新用户第一次访问推荐系统时,不立即给用户展示推荐结果,而是给用户提供一些物品,让用户反馈他们对这些物品的兴趣,然后根据用户的反馈提供个性化推荐。
利用物品的内容信息
声称关键词和关键词词向量,计算关键词词向量之间的相似度。(缺点是会丢失关键词之间的关系信息)
很多时候,内容过滤算法的精度远低于协同过滤算法。
如何建立文章、话题和关键词的关系是话题模型研究的重点,代表的话题模型有LDA。LDA有三种,即文档、话题和词语。LDA可以较好地对词进行聚类,找到每个词的相关词。
在使用LDA计算物品内容的相似度时,我们可以先计算出物品在话题上的分布,然后利用两个物品的话题分布计算物品的相似度。计算分布的相似度利用的是KL散度: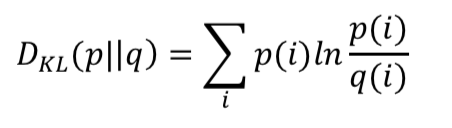
其中p和q是两个分布,KL散度越大说明分布的相似度越低。
发挥专家作用
标注数据在各个维度下的类别,然后计算相似度

若有收获,就点个赞吧
0 人点赞
