Node 节点
节点是一个 Elasticsearch 的实例,本质上就是一个 Java 进程,一台机器上可以运行多个 Elasticsearch 进程,但生产环境上一般建议一台机器上只运行一个实例。Elasticsearch 中,每个节点都有名字,允许通过配置文件配置,或者启动的时候配置指定。每一个节点在启动之后,会分配一个UID,可以通过 GET /_cluster/nodes?pretty 获取
node.name: node-1
bin/elasticsearch -E node.name=node-1
节点类型
| 节点类型 | 概述 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Master Node 主节点 |
Master Node 在一个集群中唯一仅有一台,维护了一个集群中的必要的信息:所有节点的信息;所有索引和其他相关的 Mapping 与 Setting 信息;分片的路由信息。虽然每个节点都保存了集群的必要信息,但是仅有 Master Node 节点能够修改集群的信息,保证集群内部的信息一致性。 | ||||||||
| Master-eligible nodes 合格主节点 |
每个节点启动后,默认就是一个 Master-eligible nodes 节点,节点允许参与选举流程,成为 Master Node,当第一个 Master-eligible nodes 启动时,会自动选举自己成为 Master Node。 | ||||||||
| Coordinating Node 协调节点 |
Coordinating Node 主要负责接收 Client 的请求,将请求分发到合适的节点,最终把各个节点反馈的结果汇聚到一起。 在生产环境中,建议为一些大的集群配置 Coordinating Only Nodes。扮演负载均衡器,降低 Master 和 Data Nodes 的负载;负责搜索结果的收集整理;有时候无法预知客户端会发送怎么样的请求,大量占用内存的结合操作,一个深度聚合可能会引发内存溢出。 |
||||||||
| Data Node 数据节点 |
Data Node 主要承担数据存储,保存分片数据。在数据扩展上起到了至关重要的作用,可以解决水平扩展和解决数据单点的问题。 | ||||||||
| Ingest Node 数据前置处理节点 |
Ingest 节点可以看作是数据前置转换的节点,支持 pipeline 管道设置,可以使用 ingest 对数据进行过滤、转换等操作。 | ||||||||
| Machine Learning Node 机器学习节点 |
负责跑机器学习Job,用来做异常检测 |
配置节点类型
开发环境中一个节点可以承担多种角色,但在生产环境中,应该设置单一的角色节点。
| 节点类型 | 配置参数 | 默认值 |
|---|---|---|
| Master-eligible nodes 合格主节点 |
node.master | true |
| Data Node 数据节点 |
node.data | true |
| Ingest Node 数据前置处理节点 |
node.ingest | true |
| Coordinating Only Node 仅协调节点 |
无 | 每个节点默认都是 coordinating 节点。设置其他类型全部为false则可关闭 |
| machine learning 机器学习节点 |
node.ml | true(需enable X-Pack) |
Cluster 集群
一个集群是多个节点的组合,Elasticsearch 的分布式架构基于去中心化概念实现。对于集群外部客户端看来,与集群内任意一个节点的通信和与整个 Elasticsearch 集群通信是等价的,接收请求的节点会将任务分发给其他节点协同完成,集群内部通信和存储对集群外部是透明的。
启动集群
静态启动
# 集群名称cluster.name: elasticsearch# 节点名称node.name: node0# 节点数据保存位置path.data: data/node0_data# 节点IPnetwork.host: 192.168.9.220# 节点对外端口http.port: 9200# 集群通信端口transport.tcp.port: 9300# 集群列表discovery.seed_hosts: ["192.168.9.220:9300"]
# 集群名称cluster.name: elasticsearch# 节点名称node.name: node1# 节点数据保存位置path.data: data/node1_data# 节点IPnetwork.host: 192.168.9.220# 节点对外端口http.port: 9201# 集群通信端口transport.tcp.port: 9301# 集群列表discovery.seed_hosts: ["192.168.9.220:9300"]
动态启动
/elasticsearch/bin/elasticsearch -E cluster.name=elasticsearch -E node.name=node0 -E path.data=data/node0_data -E network.host=192.168.9.220 -E http.port=9200 -E transport.tcp.port=9300 -E cluster.initial_master_nodes=node0
/elasticsearch/bin/elasticsearch -E cluster.name=elasticsearch -E node.name=node1 -E path.data=data/node1_data -E network.host=192.168.9.220 -E http.port=9201 -E transport.tcp.port=9301 -E discovery.seed_hosts=192.168.9.220:9300
脑裂问题
Split-Brain,分布式系统的经典网络问题,当出现网络问题,一个节点和其他节点无法连接。通过选举会产生两个 master,导致 2 个 master 维护不同的 Cluster state。当网络恢复时,无法正常恢复。
Elasticsearch 7.0 版本开始后,无需考虑该问题。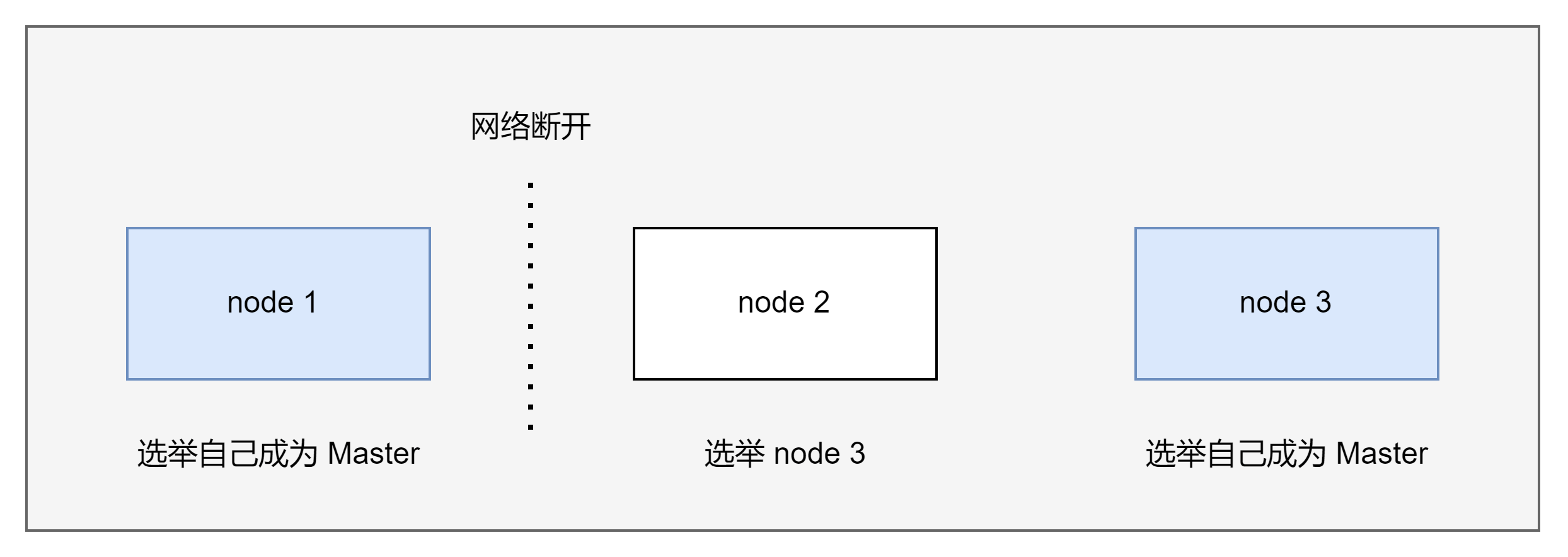
常见的集群部署
一个节点可以承担多种角色,但在生产环境中,基于单一职责的设计原则,应该设置单一的角色节点。每个节点仅承担一种角色。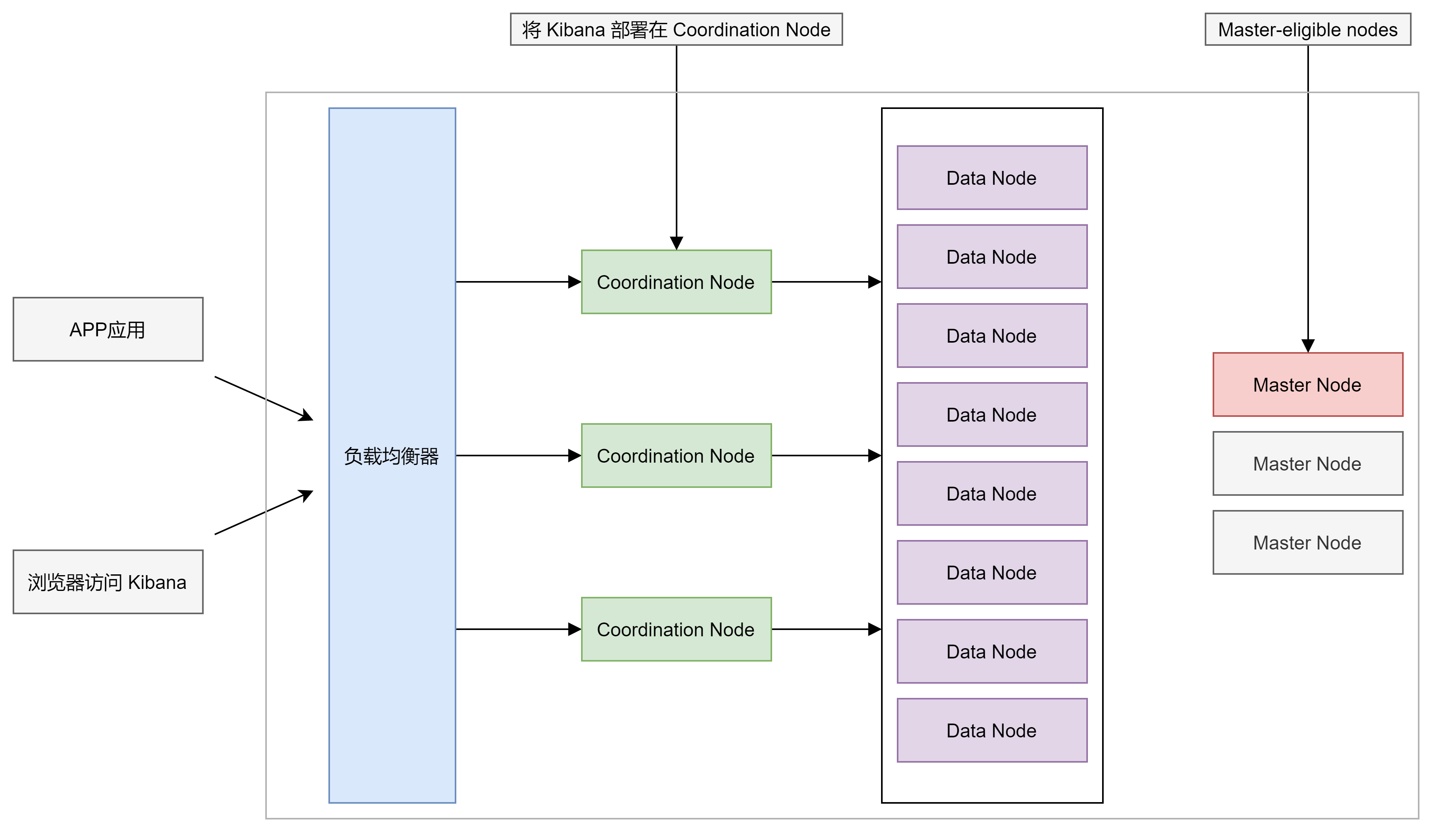
shards 分片
Primary Shard:主分片
Elasticsearch 可以把一个完整的索引进行水平切割,分布到集群内不同的节点上,构成分布式搜索,解决数据水平扩展的问题。一个分片是一个运行的 Lucene 的实例,主分片数量在创建时指定,后续不允许修改,除非 Reindex 重建索引。
Replica Shard:副本
索引副本,Elasticsearch 可以设置多个索引的副本,副本是主分片的拷贝,作用一是用于提高系统的容错性,当某个节点分片损坏或丢失时可以从副本中恢复;作用二是提高 Elasticsearch 的查询效率,Elasticsearch会对搜索请求进行负载均衡。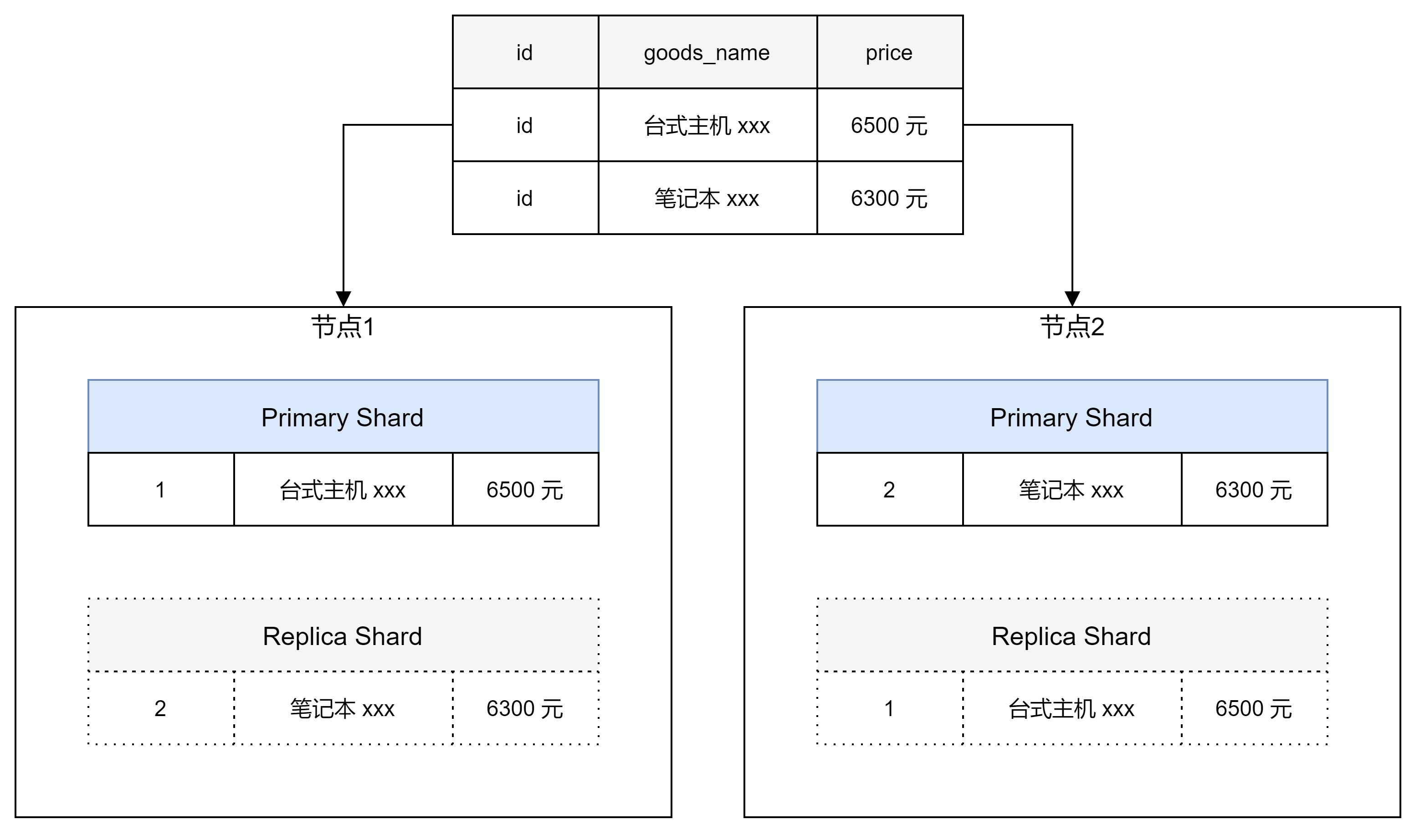
分片设置
# my_index: 索引名称PUT /my_index{"settings": {"number_of_shards": 3, #分片数"number_of_replicas": 1 #副本数}}
如何设计分片数
当分片数 大于 节点数时候,一旦集群中有新的数据节点加入,分片旧可以自动进行分配,分片在重新分配时候,系统不会有downtime(停机时间)。
一个索引如果分布在不同的节点,多个节点可以并行执行查询和写入。
但是一旦分片过多,会给系统带来一些潜在的问题,每个分片是一个 Lucene 的索引,会使用机器的资源。过多的分片会导致额外的性能开销。例如每次搜索的请求,需要从每个分片上获取数据;分片的 Meta 信息由 Master 节点维护,过多会增加管理的负担,经验值,控制分片总数在 10W 内比较合理。
如何确定主分片数量?
从存储的物理角度看。日志类引用,单个分片不要大于 50G,搜索类应用,单个分片不要超过 20G。
控制分片存储大小,能够提高 Update 的性能;Merge 时,减少所需的资源;节点丢失后,具备更快的恢复速度 、便于分片在集群内 Rebalancing (再平衡)。
如何确定副本分片数量?
副本分片是主分片的拷贝,用于提高系统可用性:响应查询请求,防止数据丢失,但需要占用和主分片一样的资源。同时,副本分片会降低数据的索引速度,有几份副本就会有几倍的CPU资源消耗在索引上;虽然会减缓对主分片的查询压力,但是会消耗同样的内存资源。
如果机器资源充分,提高副本数,可以提高整体的查询 QPS。
分片均衡分配
Elasticsearch 的分片策略会尽量保证节点上的分片数大致相同。但是调整分片总数后,扩容的新节点由于没有数据,就会导致新缩影集中在新节点上,热点数据过于集中,可能会产生性能问题。
动态设置允许您从每个节点允许的单个索引中指定对分片总数的硬限制:
# my_index: 索引名称PUT /my_index{"settings": {"number_of_shards": 2,"number_of_replicas": 0,"routing": {"allocation": {"total_shards_per_node": "1"}}}}
Elasticsearch 通过 Hash 算法确保文档均匀分片。默认 _routing 值是文档ID,可用自行制定 routing数值。
这也是为什么索引分片数不能修改的根本原因。hash算法是通过集群的分片数计算出文档均匀存放的,一旦分片数修改,必须要重建索引。
# my_index:索引名称# bigdata:自定义_routing值PUT my_index/_doc/100?routing=bigdata{"title": "Mastering Elasticsearch","body": "Let's Rock"}
分片的结构
- 在 Lucene 中,单个倒排索引文件被称为 Segment。Segment 是自包含的,不可变的。多个 Segments 汇聚在一起,被称为 Lucene 的 Index,对应 Elasticsearch 中的 Shard。
- 当由新文档写入时,会生成新Segment,查询时会同时查询所有 Segment,并且对结果进行汇总。Lucene 中有个文件,用来记录所有 Segments 信息,称为 Commit Point。
- 删除的文档被记录在 .del 文件中,查询时候用于过滤结果。
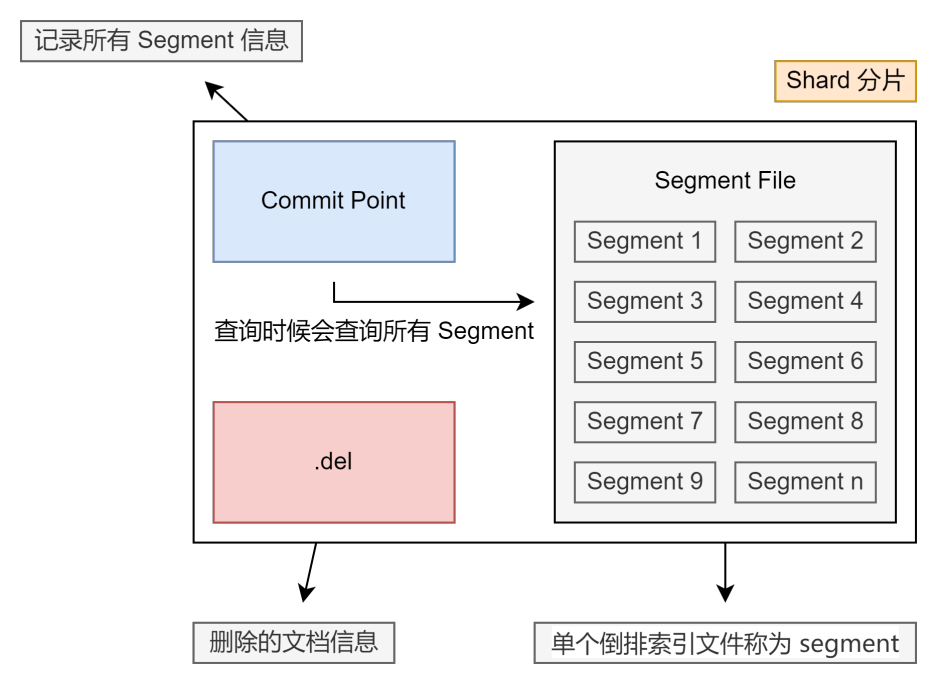
更新删除文档流程


分片的生命周期
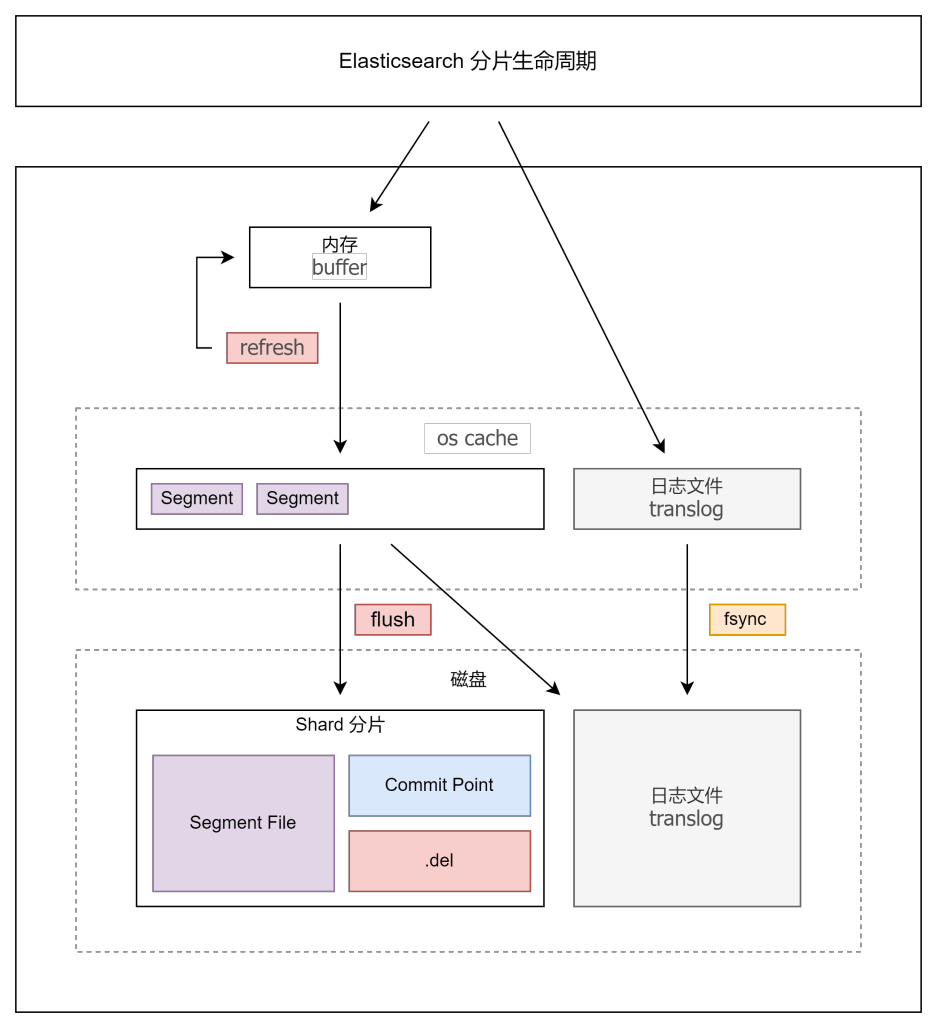
- 写入请求到达Shard后,先把数据写入到内存(buffer)中,同时会写入一条日志到translog日志文件中去。
- 首先写入的是 Lucene,创建索引,并未生成 Segment,Lucene 缓存数据是不可被检索的。
- 执行 refresh 操作:将 buffer 数据写入 os cache (操作系统缓存),产生一个 Segment,并清空 buffer。
- 写入 os cache 的同时,建立倒排索引,这个时候数据已经可以被客户端检索。
- 如果系统又大量的数据写入,那么就会产生很多的 Segment。
- 默认 refresh 操作间隔1秒(默认)执行一次。
- buffer 内存超过设定阈值(默认是 JVM 内存10%)也会触发 refresh。
- 可以通过 refresh api 手动触发 refresh。
- 执行 fsync 操作:translog会每隔5秒或者在一个变更请求完成之后,将translog从缓存刷入磁盘。
- translog 是存储在 os cache 中的,每个分片有一个,如果节点宕机,Elasticsearch 会在 translog 中恢复数据,最多导致 5 秒数据丢失。
- 系统默认设置每次写操作都必须直接 fsync 到硬盘,但性能会有所降低。
- transaction log 内容不会因 refresh 操作而被清空。
- 执行 Flush 操作:每30分钟或者当 tanslog 的大小达到 512M 时候,会触发 Flush 操作(commit操作)。
- 随着时间递增,磁盘上的 Segment File 会越来越多(每次 refresh 都会生成一个),需要定期进行合并。
- Elasticsearch 删除操作会首先记录在 .del 文件中,并不会删除 Segment File,需要定期进行物理删除。
- Elasticsearch 会定期自动进行 Merge 操作。
# my_index:索引名称POST my_index/_forcemerge
分片分配意识
当在同一物理服务器,多个机架上或跨多个感知区域上的多个虚拟机上运行节点时,同一物理服务器,同一机架中或相同感知区域中的两个节点更有可能会同时崩溃,而不是两个不相关的节点同时崩溃。
如果 Elasticsearch 了解硬件的物理配置,则可以确保主分片及其副本分片分布在不同的物理服务器,机架或区域之间,以尽可能减少丢失所有分片副本的风险。标记节点
标记一个 Hot 节点node.attr.my_node_type=hot
GET /_cat/nodeattrs?v
| 设置 | 分配索引到节点,节点的属性规则 | | —- | —- | |PUT logs-2019-06-27{"settings": {"number_of_shards": 2,"number_of_replicas": 0,"index.routing.allocation.require.my_node_type": "hot"}}
Index.routing.allocation.include.{attr}| 至少包含一个值 | |Index.routing.allocation.exclude.{attr}| 不能包含任何一个值 | |Index.routing.allocation.require.{attr}| 所有值都需要包含 |
index.routing.allocation 是一个索引级的 dynamis setting,可以通过 API 在后期进行设定
PUT logs-2019-06-27/_settings{"index.routing.allocation.require.my_node_type": "warm"}
Reck Awareness 机架感知意识
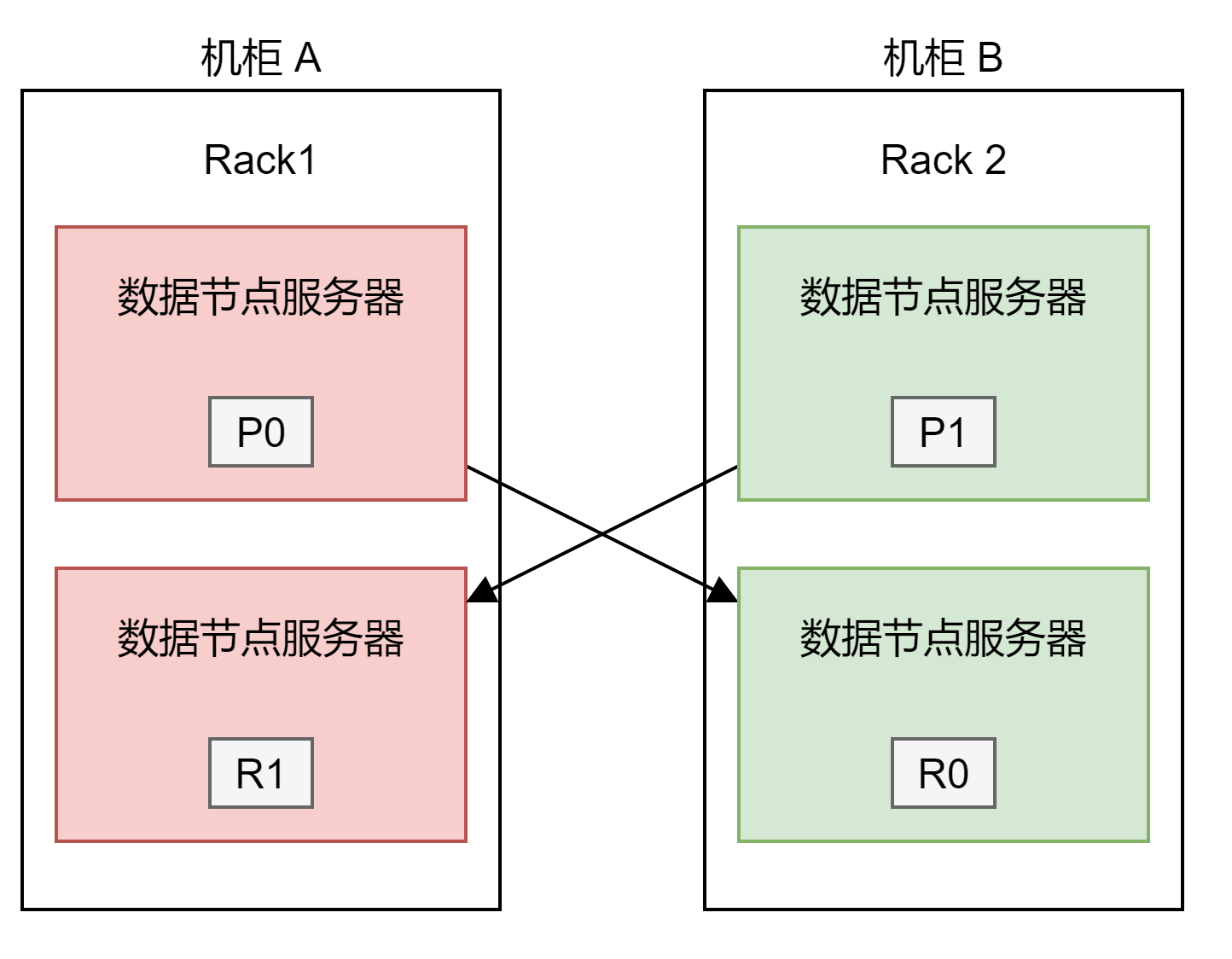
Elasticsearch 的节点可能分布在不同的机架上,当一个机架断电,可能会同时丢失几个节点,如果一个索引相同的主分片和副本分片,同时在这个机架上,就有可能导致数据的丢失。通过 Reck Awareness 的机制,旧可以尽可能避免将同一个索引的主副分片同时分配在一个机架的节点上。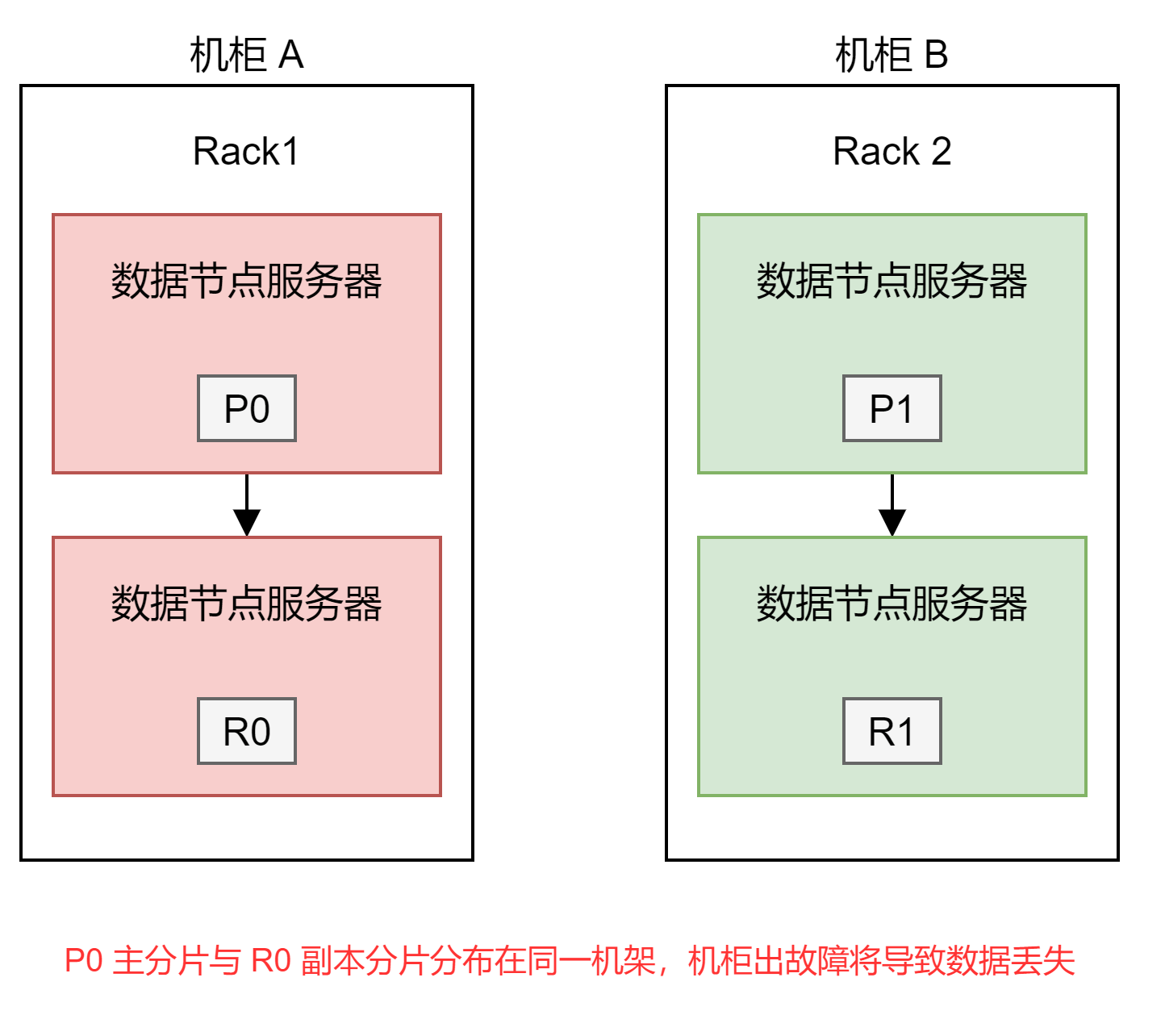
node.attr.rack_id=rack1
node.attr.rack_id=rack2
PUT _cluster/settings{"persistent": {"cluster.routing.allocation.awareness.attributes": "rack_id"}}
Forced Awareness 强迫意识
假设有两个机柜意识来托管主要和复制分片,通过机柜感知意识,主副分片能够分别在不同机柜存储,但是一旦其中一个机柜失去联系,Elasticsearch 会将所有的主分片和副本分片同时分配给同一个机柜,这个突然的额外负载就会导致机柜内的节点硬件过载。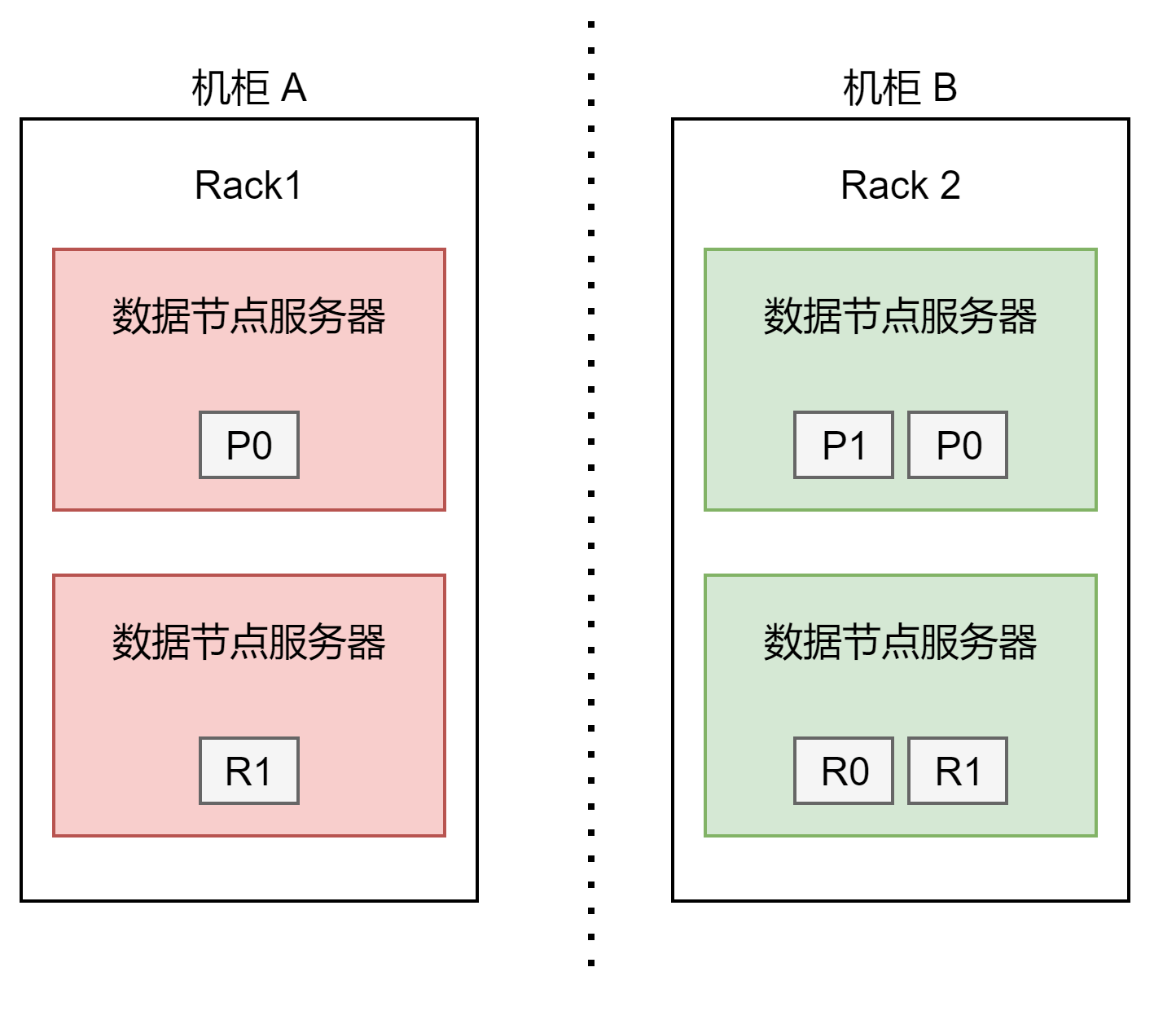
强制意思解决了这个问题,绝不允许将同一分片和副本分配到同一个区域。
PUT _cluster/settings{"persistent": {"cluster.routing.allocation.awareness.attributes": "rack_id","cluster.routing.allocation.awareness.force.rack_id.values": "rack1,rack2"}}
故障转移与集群健康状态
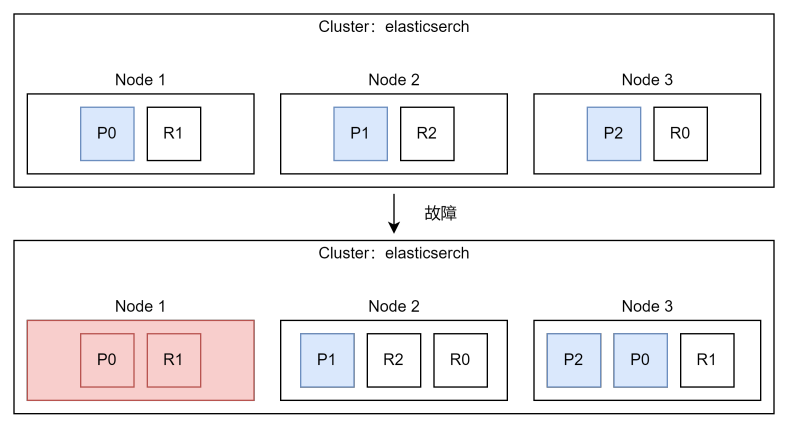
GET /_cluster/health
- Green:健康状态,所有主分片和副本分片都可用
- Yellow:亚健康,所有主分片可用,部分副本分片不可用
- Red:不健康状态,部分主分片不可用
监控 Elasticsearch 集群
GET _nodes/stats
GET _cluster/stats
GET <index_name>/stats
Health 相关的 API
| GET _cluster/health | 集群状态,检查节点数量 | | —- | —- | | GET _cluster/health?level=indices | 所有索引的监控状态,查看有问题的索引 | | GET _cluster/health/| 单个索引的健康状态 | | GET _cluster/health?level=shards | 分片级的索引 | | GET _cluster/allocation/explain | 返回第一个未分配Shard的原因 |
Throttles 限流
为 Relocation 和 Recovery 设置限流,避免过多任务对集群产生性能影响
PUT _cluster/settings{"persistent" : {# 允许在一个节点上发生多少并发传入分片恢复。 默认为2"cluster.routing.allocation.node_concurrent_incoming_recoveries":2,#允许在一个节点上发生多少并发传出分片恢复,默认为2"cluster.routing.allocation.node_concurrent_outgoing_recoveries":2,#为上面两个的统一简写"Cluster.routing.allocation.node_concurrent_recoveries": 2}}
PUT _cluster/settings{"persistent" : {# 允许集群内并发分片的rebalance数量,默认为2"Cluster.routing.allocation.cluster_concurrent_rebalance": 2}}
故障转移
PUT _cluster/settings{"transient": {"cluster.routing.allocation.node_concurrent_recoveries":5}}
PUT /_cluster/settings{"transient": {"indices.recovery.max_bytes_per_sec": "80mb"}}
PUT _cluster/settings{"transient": {"indices.recovery.concurrent_streams":6}}

若有收获,就点个赞吧
0 人点赞
