Logstash 概述
Logstash 是免费且开放的服务器端数据处理管道,能够从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。
Pipeline 概念
包含了 input (数据采集)、 filter(数据转换)、output(数据发送) 三个阶段的处理流程,目前支持 200+ 插件,支持队列管理。
数据在 Logstash 内部流转时的具体表现形式 被称之为 Logstash Event。数据在 input 阶段被转换为 Event,在 output 被转化成目标格式数据。Event 其实是一个 Java Object,在配置文件中,对 Event 进行增删改查。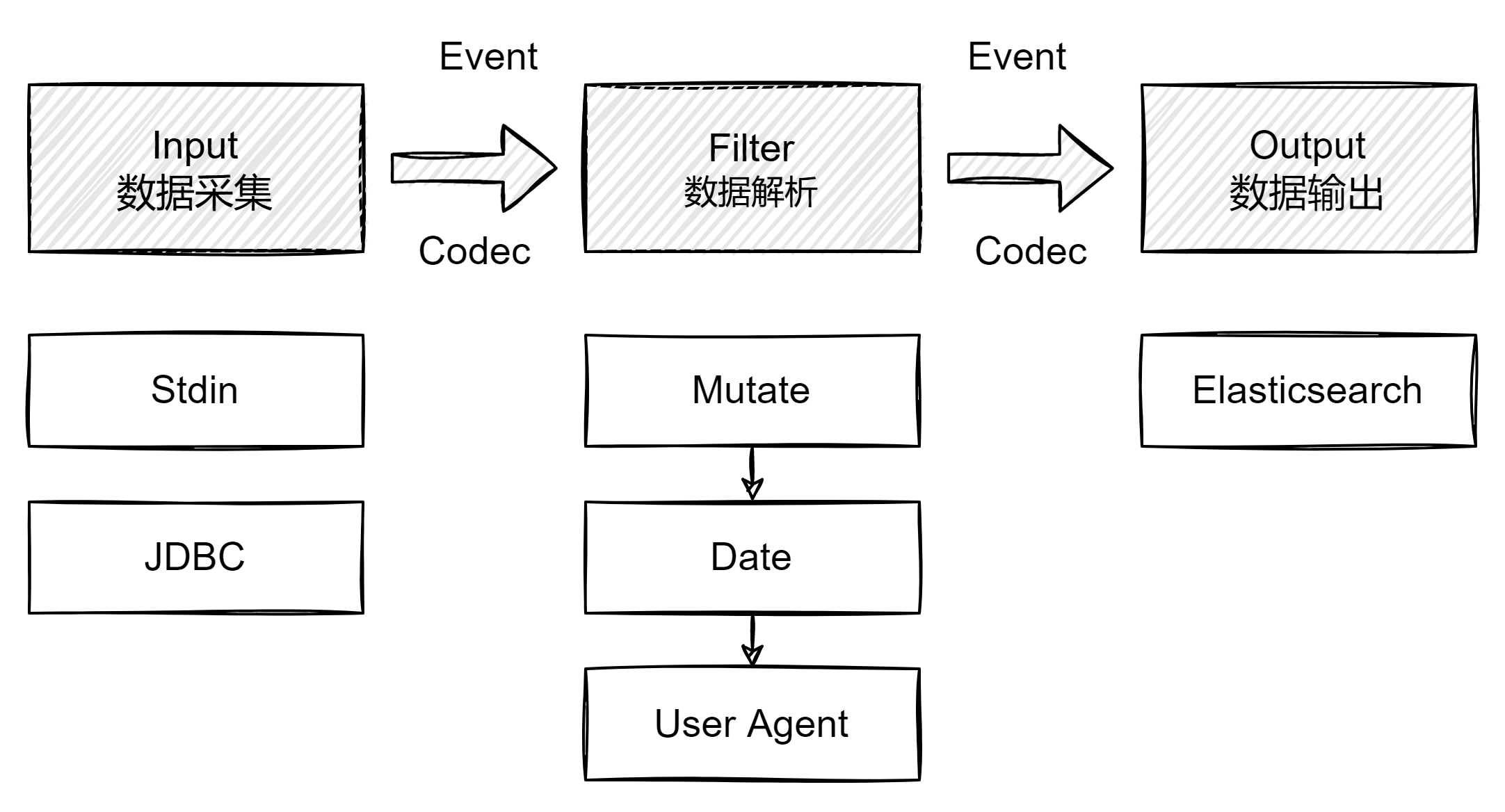
Input 插件
一个 Pipeline 可以由多个 input 插件
- Stdin 、 File
- Beats 、 Log4J 、Elasticsearch、JDBC、Kafka、Rabbitmq、Redis
- JMX、HTTP、Websocket、UDP、TCP
- Google Cloud Storage / S3
- Github / Twitter
Filter 插件
内置的 Filter Plugins(https://www.elastic.co/guide/en/logstash/7.1/filter-plugins.html)
- Mutate:操作 Event 的字段
- Metrics:Aggregate metrics
- Ruby:执行 Ruby 代码
Output 插件
常见的 Output Plugins:https://www.elastic.co/guide/en/logstash/7.1/output-plugins.html
- Elasticsearch
- Email 、 Pageduty
- Influxdb 、 Kafka 、Mongodb、Opentsdb、Zabbix
- Http、TCP、Websocket
Codec 插件
内置的 Codec Plugins:https://www.elastic.co/guide/en/logstash/7.1/codec-plugins.html
- Line、Multiline
- JSON 、Avro、Cef(ArcSight Common Event Format)
- Dots 、Rubydebu
Logstash 配置文件结构
```shell input {
}
filter {
}
output {
}
<a name="ILXx3"></a>## Logstash QueueIn Memory Queue:进程奔溃,机器宕机,都会引发数据的丢失。<br />Persistent Queue:机器宕机数据也不会丢失,数据保证会被消费,可以代替 Kafka 等消息队列缓冲区的作用。<a name="cukX7"></a># 同步数据库数据到 Elasticsearch> 需求:将数据库中的数据同步到 Elasticsearch- 需要把新增数据库信息同步到 Elasticsearch- 数据库信息 Update 后,需要能被更新到 Elasticsearch- 支持增量更新- 数据库信息被删除后,不能被 Elasticsearch 搜索到<a name="qYjUF"></a>## JDBC Input Plugin```shellinput {jdbc {# mysql 数据库链接,db_fengche为数据库名 ?tinyInt1isBit=false 禁止整型转换为booljdbc_connection_string => "jdbc:mysql://192.168.9.201/db_fengche?tinyInt1isBit=false"# 用户名和密码jdbc_user => "db_fengche"jdbc_password => "HbDZF63D5865BjjE"# 驱动jdbc_driver_library => "/logstash/logstash-core/lib/jars/mysql-connector-java-8.0.28.jar"# 驱动类名jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_paging_enabled => "true"jdbc_page_size => "50000"# 启动追踪,如果为true,则需要指定 tracking_columuse_column_value => true# 指定追踪的字段tracking_column => "last_update"# 追踪字段的类型,目前只有数字(numeric)和时间类型(timestamp),默认是 numerictracking_column_type => "numeric"# 记录最后一次运行的结果record_last_run => true# 上次运行结果的保存位置last_run_metadata_path => "/logstash/config/goods/jdbc-position.txt"# 执行的sql 文件路径+名称statement_filepath => "/logstash/config/goods/jdbc.sql"# 设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新schedule => "* * * * *"}}output {elasticsearch {# ES的IP地址及端口hosts => ["192.168.9.220:9200"]# 索引名称index => "goods"document_type => "_doc"# 自增ID 需要关联的数据库中有有一个id字段,对应索引的id号document_id => "%{goods_id}"}stdout {# JSON格式输出codec => json_lines}}
SELECT * FROM `fc_goods` where last_update > :sql_last_value
开启同步监控
/logstash/bin/logstash -f /logstash/config/goods/jdbc.conf

若有收获,就点个赞吧
0 人点赞
