Elasticsearch 除了支持海量数据的搜索以外,还提供了针对 Elasticsearch 数据进行统计分析的功能,具有海量数据高实时性的特点。
Aggregation 属于 Search 的一部分,一般情况下,建议将其 Size 指定为 0
聚合的分类
- Bucket Aggregation:一些列满足特定条件的文档的集合,类似于 Mysql 中的 GROUP BY 分组。
- Metric Aggregation:一些数学运算,可以对文档字段进行统计分析,类似于 Mysql 中的 count、sum等。
- Pipeline Aggregation:对一些其他的聚合结构进行二次聚合
- Matrix Aggregation:支持对多个字段的操作并提供一个结果矩阵
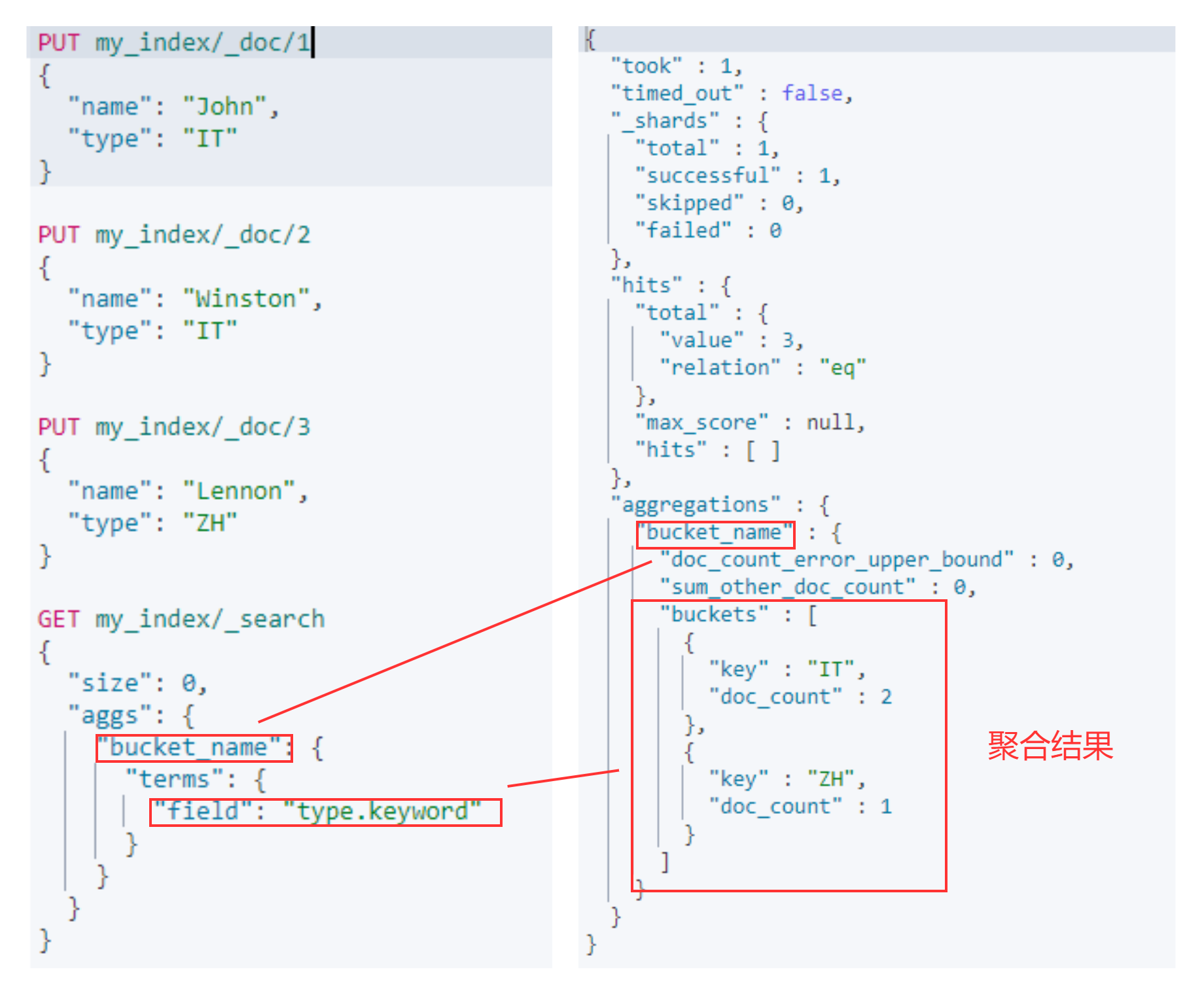
Bucket 分桶
Terms 分桶
```jsonmy_index:索引名称
bucket_name 聚合名称
type.keyword 聚合字段
GET my_index/_search { “size”: 0, “aggs”: { “bucket_name”: { “terms”: { “field”: “type.keyword” } } } }
<a name="S6ztX"></a>### Range 分桶```json# my_index:索引名称# price_ranges:聚合名称# price:聚合字段GET my_index/_search{"aggs": {"price_ranges": {"range": {"field": "price","ranges": [{ "key": "cheap", "to": 100 },{ "key": "average", "from": 100, "to": 200 },{ "key": "expensive", "from": 200 }]}}}}
Histogram 分桶
以某个数值为区间,对范围数据进行分桶
# products:索引名称# price_histogram:聚合名称# price:聚合字段POST /products/_search{"query": {"match_all": {}},"aggs": {"price_histogram": {"histogram": {"field": "price","interval": 1000,"extended_bounds": {"min": 0,"max": 10000}}}}}
Top Hits 分桶内容
找出指定数量的分桶信息
# my_index:索引名称# goods_name、price_order:聚合名称# goods_name、price:聚合字段POST /my_index/_search{"query": {"match_all": {}},"aggs": {"goods_name": {"terms": {"field": "goods_name.keyword"},"aggs": {"price_order": {"top_hits": {"from": 0,"size": 2,"sort": [{"price": {"order": "desc"}}]}}}}}}
Metric 计算
# my_index:索引名称# bucket_name 聚合名称# avg_price / max_price / min_price 聚合结果字段# deposit 聚合字段GET /my_index/_search{"size": 0,"aggs": {"avg_price":{"avg":{"field":"deposit"}},"max_price":{"max":{"field":"deposit"}},"min_price":{"min":{"field":"deposit"}}}}
| Metric 类型 | 含义 |
|---|---|
| count | 文档总数 |
| min | 文档最小值 |
| max | 文档最大值 |
| avg | 文档平均值 |
| sum | 文档数求和 |
| stats | count、min、max、avg、sum聚合 |
Pipeline 管道聚合
支持对聚合分析的结果,再次进行聚合分析。Pipeline 的分析结果会输出到原结果中,根据位置的不同,分为:
- Sibling - 结果和现有分析结果同级
- Max,Min,Avg & Sum Bucket
- Stats,Extended Status Bucket
- Percentiles Bucket
- Parent - 结果内嵌到现有的聚合分析结果中
POST /products/_search { “size”: 0, “query”: {“match_all”: {}}, “aggs”: { “name_bucket”: { “terms”: {“field”: “goods_name.keyword”}, “aggs”: { “avg_price”: { “avg”: {“field”: “price”} } } }, “min_goods”: { “min_bucket”: { “buckets_path”: “name_bucket>avg_price” } } } }
| Pipeline 类型 | 含义 || --- | --- || min_bucket | 文档最小值 || max_bucket | 文档最大值 || avg_bucket | 文档平均值 || stats_bucket | count、min、max、avg、sum聚合 || percentiles_bucket | 百分位 |```jsonPOST employees/_search{"size": 0,"aggs": {"age": {"histogram": {"field": "age","min_doc_count": 1,"interval": 1},"aggs": {"avg_salary": {"avg": {"field": "salary"}},"derivative_avg_salary":{"derivative": {"buckets_path": "avg_salary"}}}}}}
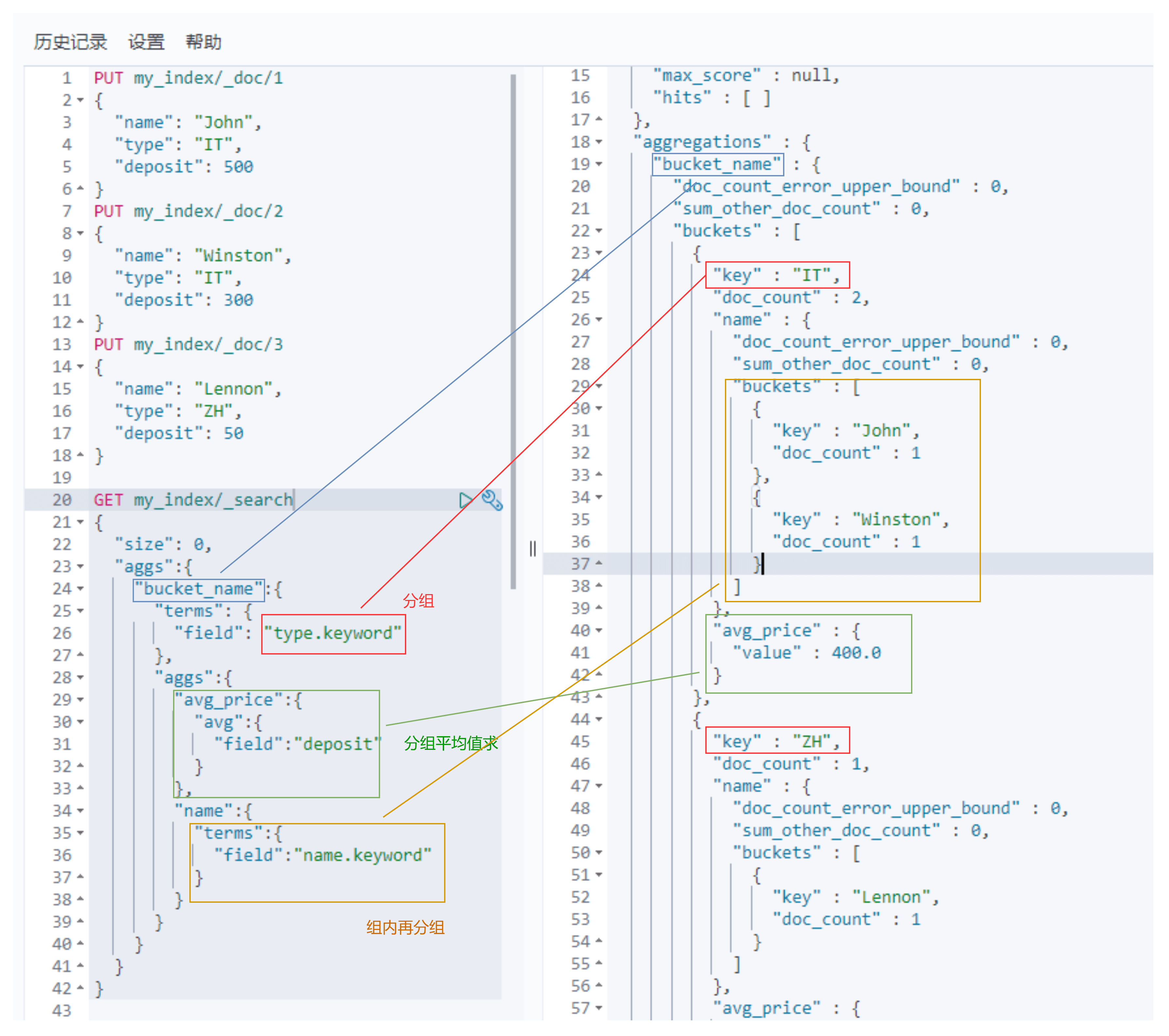
聚合嵌套
# my_index:索引名称# bucket_name 聚合名称# avg_price / max_price / min_price 聚合结果字段# deposit 聚合字段GET my_index/_search{"size": 0,"aggs":{"bucket_name":{"terms": {"field": "type.keyword"},"aggs":{"avg_price":{"avg":{"field":"deposit"}},"name":{"terms":{"field":"nams"}}}}}}
优化 Terms 聚合的性能
PUT index{"mappings": {"properties": {"foo": {"type": "keyword","eager_global_ordinals": true}}}}
聚合的作用范围
Elasticsearch 聚合分析的默认作用范围是 query 的查询集,同时还支持以下方式改变聚合的作用范围:
filter 前置过滤器
过滤查询结果,同时过滤聚合结果
POST /products/_search{"aggs": {"name_bucket": {"filter": {"term": {"goods_name": "php"}},"aggs": {"avg_price": {"avg": {"field": "price"}}}}}}
post_filter 后置过滤器
过滤查询结果,不过滤聚合查询
POST /products/_search{"size": 0,"aggs": {"avg_price": {"avg": {"field": "price"}}},"post_filter": {"match": {"goods_name.keyword": "php"}}}
global 全局作用范围
忽略 query 查询中的条件进行聚合
POST /products/_search{"query": {"term": {"goods_name": {"value": "php"}}},"aggs": {"all_price": {"global": {},"aggs": {"sum_price": {"sum": {"field": "price"}}}}}}
聚合排序
POST /products/_search{"size": 0,"aggs": {"name_bucket": {"terms": {"field": "goods_name.keyword","order": [{"_count": "asc"},{"_key": "desc"}]}}}}
POST /products/_search{"size": 0,"aggs": {"name_bucket": {"terms": {"field": "goods_name.keyword","order": [{"sum_price": "desc"}]},"aggs": {"sum_price": {"sum": {"field": "price"}}}}}}
聚合原理与聚合精准度

分桶原理与异常场景
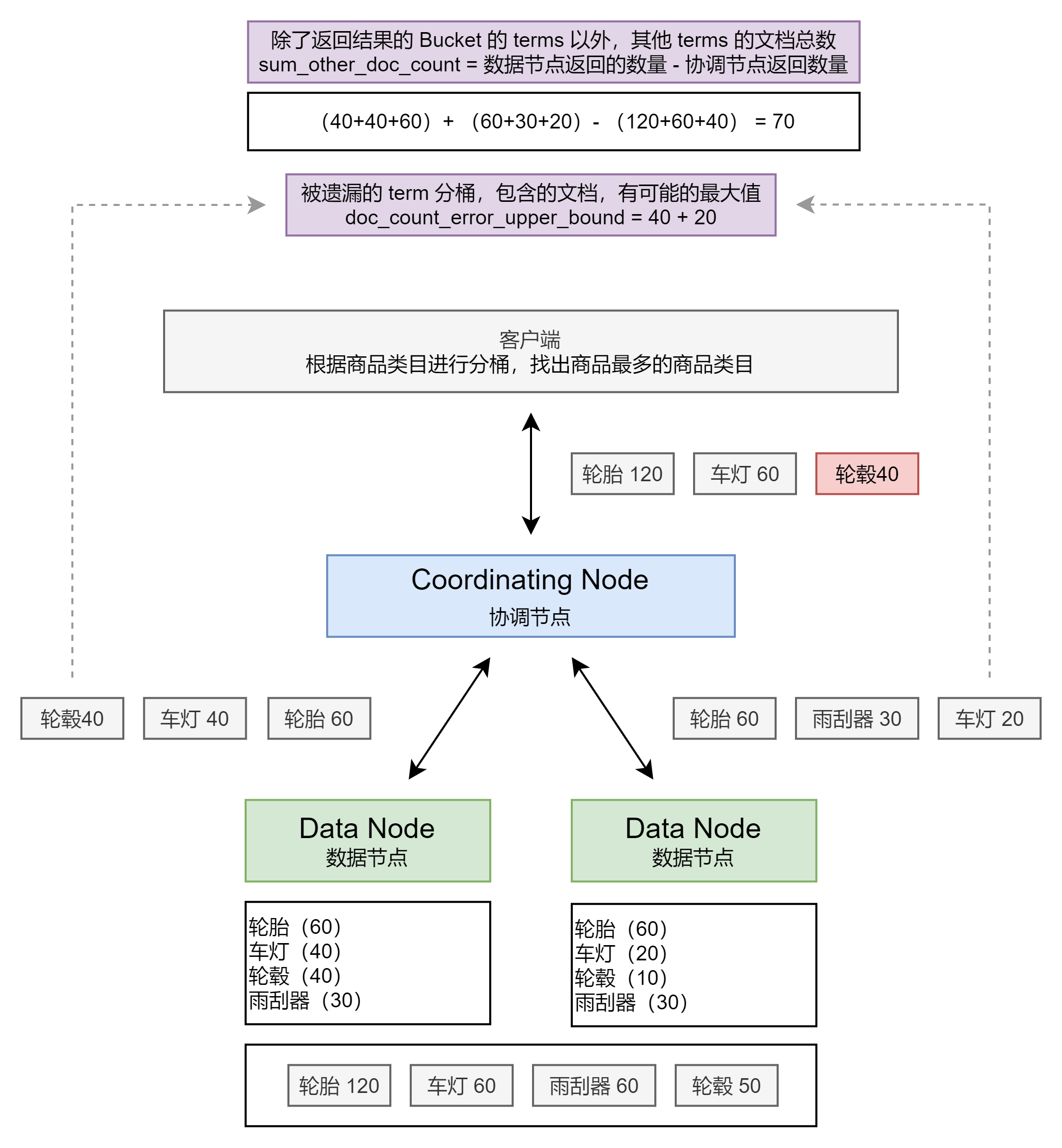
如何解决 Terms 不准的问题
- Terms 聚合分析不准的原因,数据分散再多个分片上,Coordinating Node 无法获取数据全貌。
- 解决方案1:当数据量不大时,设置 Primary Shard 为1;实现准确率。
- 解决方案2:在分布式数据上,设置 shard_size 参数,提高精准度。
- 原理:每次从 Shard 上额外多获取数据,提升准确率。
- 增加了整体的计算量,提高了准确度,但会降低相应时间。
- shard_size 默认大小设置等于 size * 1.5 + 10
POST /products/_search{"size": 0,"aggs": {"name_bucket": {"terms": {"field": "goods_type","size": 3,"shard_size": 4,"order": [{"_count": "desc"}]}}}}
打开 show_term_doc_count_error
打开该选项可以查看分桶文档是否正常POST /products/_search{"size": 0,"aggs": {"name_bucket": {"terms": {"field": "goods_type","size": 3,"show_term_doc_count_error": true}}}}

若有收获,就点个赞吧
0 人点赞
