正排索引和倒排索引
正排表是以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
倒排索引的核心组成部分
倒排索引包含两个部分:
- 单词词典(Term Dictionary),记录所有文档的单词,记录单词到倒排索引列表的关联关系;单词库一般比较大,可用通过B+树或者哈希拉链法实现,以满足高性能插入与查询。
- 倒排列表(Posting List),记录了单词对应的文档结合,由倒排索引项组成。其中倒排索引项包含:
- 文档ID
- 词频TF :该单词在文档中出现的次数,用于相关性算分
- 位置(Position):单词在文档中分词的位置,用于语句搜索(phrase query)
- 偏移(Offset):记录单词的开始结束位置,实现高亮显示

Elasticsearch 的倒排索引
Elasticsearch 的 JSON 文档中的每个字段,都有自己的倒排索引,并且 Elasticsearch 可用指定某些字段不做索引,这样做的优点是可用节省存储空间,缺点是该字段将无法被分词搜索。
文本分析与转换
Analysis 分词 与 Analyzer 分词器
Analysis 文本分析是把全文本转换成一系列单词(term/token)的过程,也称为分词,是 Elasticsearch 中的动词,需要通过 Analyzer 分析器来实现分词的过程。
Analyzer 作为 Elasticsearch 分词器,在索引过程中发挥着重要的作用。在 Elasticsearch 中我们可用使用内置的分词器或者按需求定制化分析器,用于实现倒排索引的建立。
Analyzer 分析器
分词器是专门处理分词的组件,Analyzer 由三部分组成。
| 阶段 | 描述 |
|---|---|
| Character Filters | 针对原始文本处理,例如去除html |
| Tokenizer | 按照规则切分为单词 |
| Token Filter | 将切分的单词进行加工,小写,删除停用词,增加同义词等 |

_analyzer API使用
Elasticsearch 提供了专用的REST API,_analyzer 作为其中的一个辅助API,它可以帮助你分析每一个field或者某个analyzer/tokenizer是如何分析和索引一段文字。针对不同的场景,有以下几种方式进行使用:
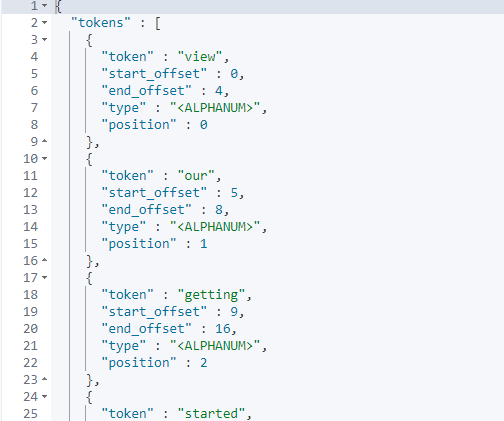
GET _analyze{"analyzer": "standard","text": "View our getting started page to get acquainted with the Elastic"}
POST index_name/_analyze{"field": "fieldName","text": "View our getting started page to get acquainted with the Elastic"}
POST _analyze{"tokenizer": "standard","filter": ["lowercase"],"text": "View our getting started page to get acquainted with the Elastic"}
内置分词器
| analyzer 分词器 | 描述 |
|---|---|
| standard | 默认分词器,按词切分(过滤符号;保留数字),小写处理 |
| simple | 按非字母切分(过滤符号和数字),小写处理 |
| stop | 按非字母切分(过滤符号和数字),小写处理,停用词过滤 |
| whitespace | 按空格切分(保留中划线和数字),不转小写 |
| keyword | 不分词 |
| pater | 正则表达式,默认\W+(非字母切分) |
| language | 提供了30多种常见语言的分词器(english,可以将英文双数转单数) |
GET _analyze{"analyzer": "standard","text": "View our getting started page to get acquainted with the Elastic"}
中文分词的难度与解决方案
- 中文句子中,词语间没有空格作为分隔,无法像英文一样通过空格作为规则进行分词
- 一句中文,在不同的上下文,有不同的理解,例如:
- 这个 苹果,不大好吃
- 这个 苹果,不大 好吃!
ICU Analyzer
提供了 Unicode 的支持,更好的支持亚洲语言。
/elasticsearch/bin/elasticsearch-plugin install analysis-icu
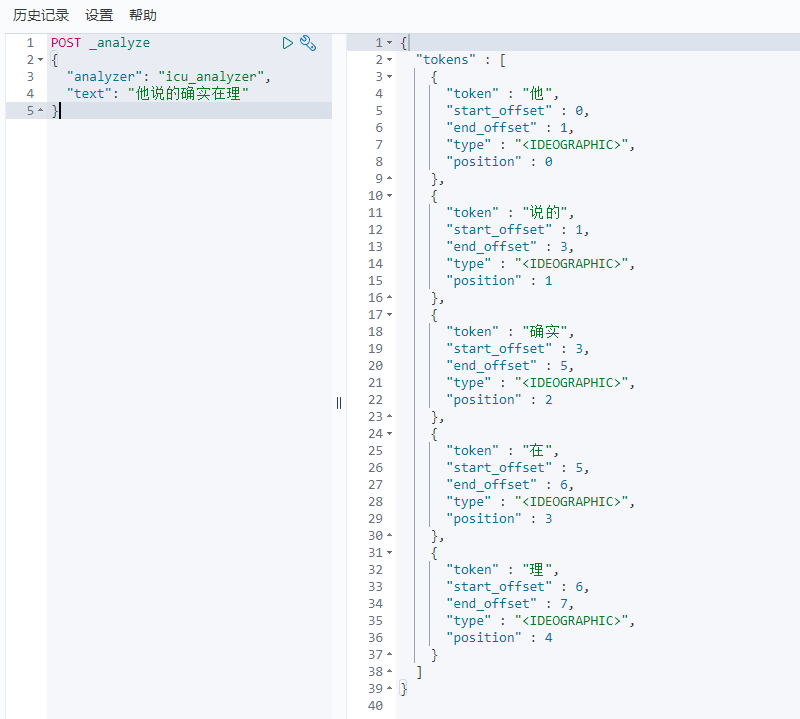
POST _analyze{"analyzer": "icu_analyzer","text": "他说的确实在理”"}
全文搜索API
使用方式
Elasticsearch 支持两种形式的全文搜索API
| URL Search | Request Body Search | |
|---|---|---|
| 使用方式 | 在 URL 中使用查询参数 | 基于 JSON 格式的更加完备的查询(DSL) |
| 实用性 | 差 | 优(包含高阶查询用法) |
| 请求方式 | GET | GET/POST |
指定查询索引
| 语法 | 范围 |
|---|---|
| /_search | 集群上所有的索引 |
| /index/_search | index索引 |
| /index1,index2/_search | index_name1索引和index_name2索引 |
| /index*/_search | 以index开头的索引 |
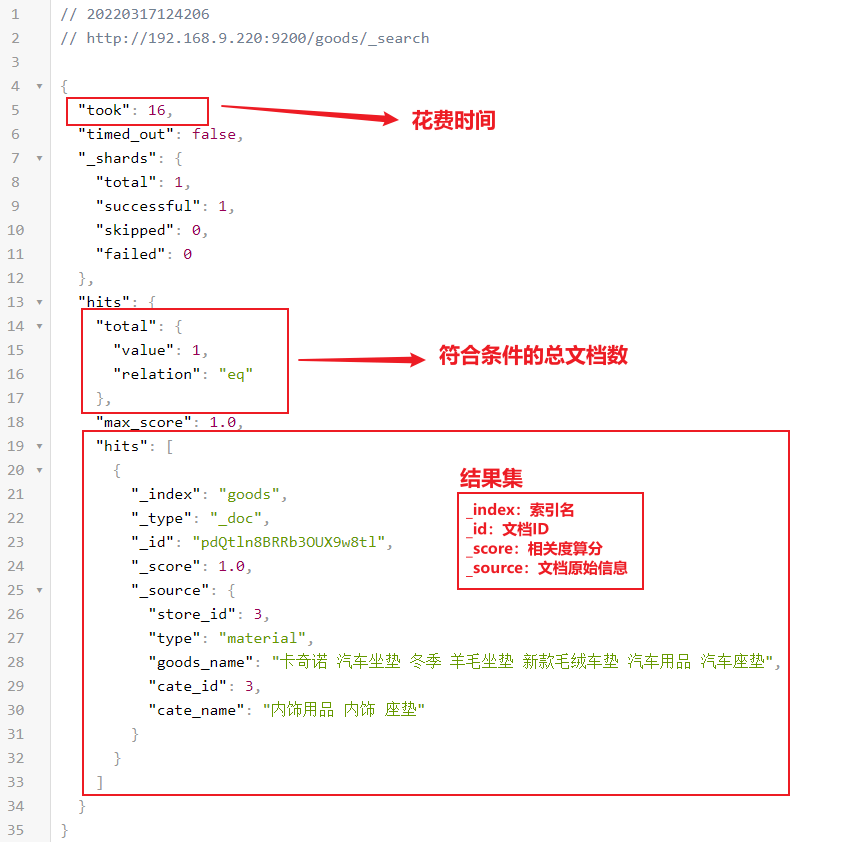
查询返回结果
URL Search
发送请求
curl -XGET"http://{ip}:9200/{索引名称}/_search?q={查询内容}"
curl -XGET"http://127.0.0.1:9200/index_name/_search?q=name:Eddie"
请求可选项
| 参数名 | 类型 | 描述 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| q | string | 指定查询语句,使用Query String Syntax | |||||||
| df | string | 默认字段,不指定时会对所有字段进行查询 | |||||||
| sort | string | 根据字段名排序 | |||||||
| from | int | 返回的索引匹配结果的开始值,默认为 0 | |||||||
| size | int | 搜索结果返回的条数,默认为 10 | |||||||
| timeout | int | 超时的时间设置 | |||||||
| fields | string | 只返回索引中指定的列,多个列中间用逗号分开 | |||||||
| analyzer | string | 当分析查询字符串的时候使用的分词器 | |||||||
| analyze_wildcard | bool | 通配符或者前缀查询是否被分析,默认为 false | |||||||
| explain | bool | 在每个返回结果中,将包含评分机制的解释 | |||||||
| _source | bool | 是否包含元数据,同时支持 _source_includes和 _source_excludes |
|||||||
| lenient | bool | 若设置为 true,字段类型转换失败的时候将被忽略,默认为 false | |||||||
| default_operator | string | 默认多个条件的关系,AND 或者 OR,默认为 OR | |||||||
| search_type | string | 搜索的类型,可以为 dfs_query_then_fetch或 query_then_fetch,默认为 query_then_fetch |
|||||||
| profile | bool | 打开性能分析 |
Query String Syntax
# 泛查询GET /{index_name}/_search?q=2022# 指定字段查询GET /{index_name}/_search?q=title:2022# 等于 beautiful OR mind,只要求其中一个词GET /{index_name}/_search?q=title:beautiful mind# 等于 beautiful AND mind,且要求顺序一致GET /{index_name}/_search?q=type:"beautiful mind"# 等于 beautiful AND mind,不要求顺序一致GET /{index_name}/_search?q=type:"beautiful mind"~2
# 等于 beautiful AND mind,但不要求顺序一致GET /{index_name}/_search?q=type:(beautiful AND mind)# OR / NOT / && / || / !GET /{index_name}/_search?q=type:(beautiful OR mind)GET /{index_name}/_search?q=type:(beautiful NOT mind)# 分组# + 表示 must 必须存在# - 表示 must_not 必须不存在GET /{index_name}/_search?q=type:(+beautiful -mind)
# 区间写法,闭区间用[],开区间用{}# 年 >= 2002 AND 年 <= 2022GET /{index_name}/_search?q=title:beautiful AND year:[2002 TO 2022]# 年 >= 2002 AND 年 < 2022GET /{index_name}/_search?q=title:beautiful AND year:[2002 TO 2022}# 年 >= 2002GET /{index_name}/_search?q=title:beautiful AND year:[2002 TO}# 年 <= 2022GET /{index_name}/_search?q=title:beautiful AND year:[* TO 2022]# 算术符号GET /{index_name}/_search?q=title:beautiful AND year:>2010GET /{index_name}/_search?q=title:beautiful AND year:(>2010 && <=2018)GET /{index_name}/_search?q=title:beautiful AND year:(+>2010 +<=2018)
# 通配符查询(效率低,占用内存大,不建议使用,特别是放置在最前)# 代表一个字符GET /{index_name}/_search?q=title:bea?tiful# 代表0或多个字符GET /{index_name}/_search?q=title:bea*
Request Body Search
发送请求
| 字段 | 描述 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| query | 查询体 | ||||||||
| from | 分页起始位 | ||||||||
| size | 分页页面大小 | ||||||||
| sort | 排序 | ||||||||
| _source | 获取字段 |
POST /{index_name}/_search{"_source": ["title", "year", "name*"]"sort": [{"recommend_sort": "desc"}]"from": 10,"size": 20,"query": {"match_all": {}}}
脚本字段
GET {index_name}/_search{"script_fields": {"{new_field}": {"script": {"lang": "expression","source": "doc['age'] * multiplier",}}}}
脚本字段使用场景:需要通过es计算汇率后输出、字符拼接等场景
Term查询-词项查询
term是表达语意的最小单位,搜索和统计语言模型进行自然语言处理都需要处理term。在 Elasticsearch 中,Term查询,将不会对输入分词,作为一个整体,在倒排缩影中查找准确的词项,并且使用相关度算分公司为每个包含该词项的文档进行相关度算分;同时也可以通过 Constant Score 将查询转换成一个 Filtering,避免算分,利用缓存提高性能。
虽然 Term 不会对语句进行一个分词处理,但是由于ES在简历倒排索引的时候会自动进行分词处理,所以在检索的时候,英文大写统一将变为小写,检索大写字母词语将无法检索到数据。这个时候我们可以通过字段的keyword值进行检索。
# my_index:索引名称# name:查询字段# "Harry":查询关键字POST /my_index/_search{"query": {"term": {"name": {"value": "Harry"}}}}
# my_index:索引名称# name:查询字段# "Harry":查询关键字POST /my_index/_search{"query": {"constant_score": {"filter": {"term": {"name.keyword": {"value": "Harry"}}}}}}
全文本查询
对搜索输入进行分词,查询字符串先传递到一个合适的分词器,然后生成一个供查询的词项列表;然后每个词项逐个进行底层的查询,最终将结果进行合并。并为每个文档生成一个算分。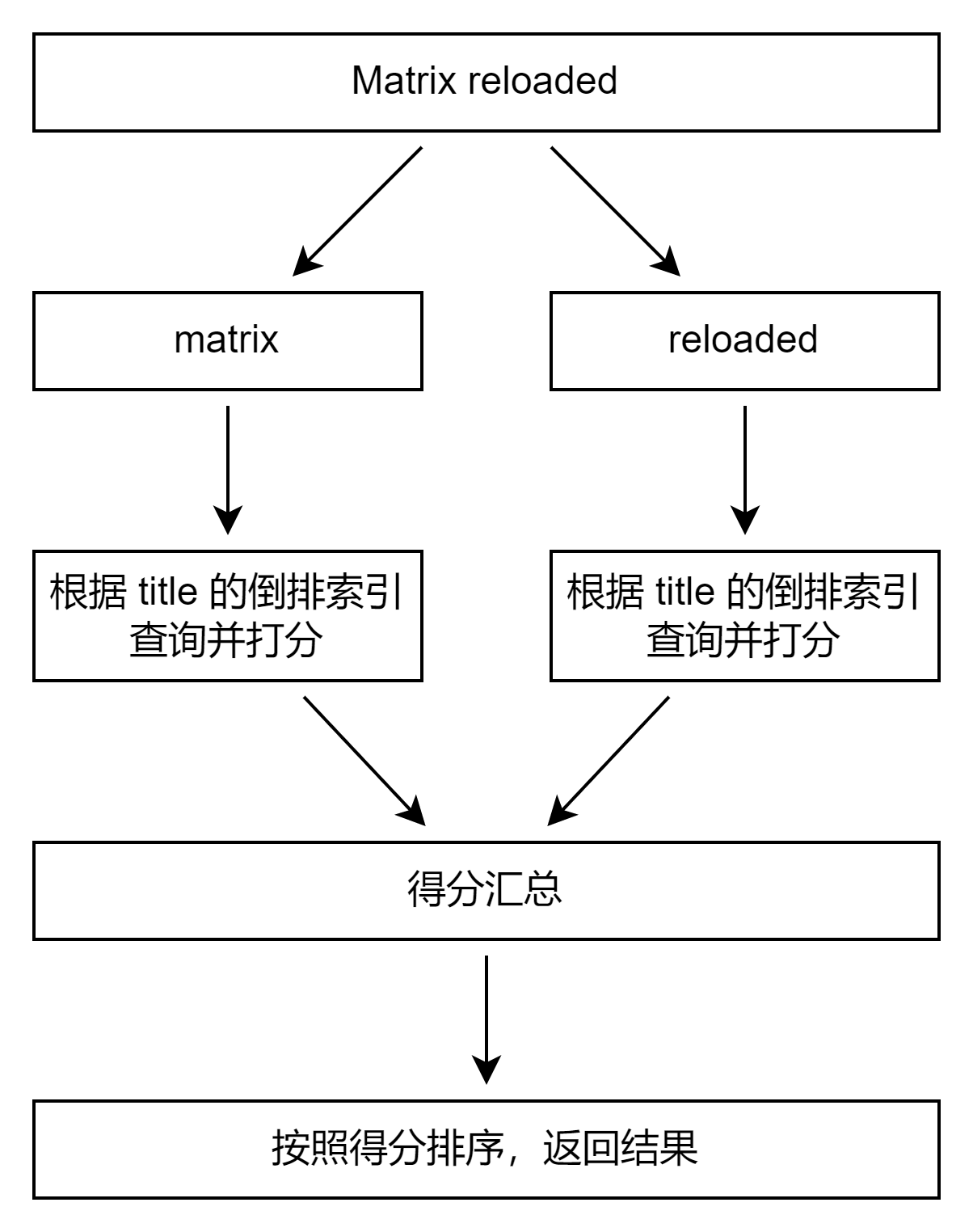
# 匹配查询,进行分词检索,默认进行OR查询;可以通过 operator 参数 来控制查询语句# my_index:索引名称# name:查询字段# "Harry":查询关键字GET /my_index/_doc/_search{"query": {"match": {"name": "Harry","operator": "AND"}}}
# 短语搜索,不进行分词检索,并且需要顺序一致。slop 代表词语之间允许插入字符和空格# my_index:索引名称# name:查询字段# "Harry":查询关键字GET /my_index/_doc/_search{"query": {"match_phrase": {"name": {"query": "Harry","slop": 1}}}}
# 字符查询,允许自由构建查询词条件# my_index:索引名称# query_string:查询字段# (Ruan AND Yiming) OR (Java AND Elasticsearch):查询语句GET /my_index/_doc/_search{"query": {"query_string": {"query": "(Ruan AND Yiming) OR (Java AND Elasticsearch)","fields": "{检索字段}"}}}
# 字符查询的简化版,不会进行异常检测和对查询语句分组查询等不支持# my_index:索引名称# query_string:查询字段POST /my_index/_search{"query": {"simple_query_string": {"fields": "query_string","query": "Ruan AND Yiming" // 不会将AND识别为查询条件语句,应该改写为以下写法}}}POST /my_index/_search{"query": {"simple_query_string": {"fields": "query_string","query": "Ruan Yiming","default_operator": "AND"}}}
- Simple Query String 查询类似于 Query String,但会忽略语法错误,同时只支持部分查询语法
- 不支持 AND OR NOT,在query内只会被当作字符串处理
- Term 之间默认的关系是 OR,可以通过指定 default_operator 调整查询
- 支持部分逻辑
- 代替 AND
- | 代替 OR
- 代替 NOT
结构化搜索
结构化数据是指日期,布尔类型和数字类型的相关数据,文本也是结构化数据的一种体现,结构化搜索的结构只有 “是” 和 “否” 两个值。根据不同的场景,可以决定结构化搜索是否需要打分。
在 Elasticsearch 中,结构化文本可以通过 Term 查询和 Prefix 前缀查询进行结构化查询;通过范围进行时间和数字类型的比较判断数组的大小。
也可以根据场景需要,决定结构化搜索是否需要打分。以下案例中均使用 constant_score filter关闭了结构化搜索的算分。
布尔数据查询
# my_index:索引名称# isVip:查询字段POST /my_index/_search{"query": {"constant_score": {"filter": {"term": {"isVip": true}}}}}
范围查询
范围查询允许纯数字,但是同时也支持字符串范围的查询,例如 a ~ b
但字符串却并非如此简单,要想对其使用范围过滤,Elasticsearch 实际上是在为范围内的每个词项都执行 term 过滤器,这会比日期或数字的范围过滤慢许多。
字符串范围在过滤 低基数(low cardinality) 字段(即只有少量唯一词项)时可以正常工作,但是唯一词项越多,字符串范围的计算会越慢。
# my_index:索引名称# age:查询字段POST /my_index/_search{"query": {"constant_score": {"filter": {"range": {"age": {"gte": 18,"lte": 35}}}}}}
| 关键字 | 翻译 | 描述 |
|---|---|---|
| gt | greater than | 大于 |
| lt | less than | 小于 |
| gte | greater than or equal to | 大于或等于 |
| lte | less than or equal to | 小于或等于 |
日期范围
# my_index:索引名称# year:查询字段# now-1y:当前时间减一天POST /my_index/_search{"query": {"constant_score": {"filter": {"range": {"year": {"gte": "now-1y"}}}}}}
| 日期标识 | 说明 |
|---|---|
| y | 年 |
| M | 月 |
| w | 周 |
| d | 天 |
| H/h | 小时 |
| m | 分钟 |
| s | 秒 |
多值字段查询
Elasticsearch 在多值字段处理上,term查询采用的是包含匹配,而不是相等匹配。
PUT my_index/_doc/1{"name": "John","type": "IT","deposit": 500,"work": ["php", "java"]}POST /my_index/_search{"query": {"constant_score": {"filter": {"term": {"work": "php"}}}}}
NULL 查询
# my_index:索引名称# car:查询字段POST /my_index/_search{"query": {"constant_score": {"filter": {"exists": {"field": "car"}}}}}
搜索相关度算分
相关性 Relevance
搜索的相关性算分,描述了一个文档和查询语句匹配程度,Elasticsearch 会对每个匹配查询条件的结果进行算分,体现在结果集中 _score。
算分的本质是排序,需要把最符合用户需求的文档排在最前面。ES5之前,默认相关性算分采用的是 TF-IDF,而目前版本采用 BM25。
词频 TF
Term Frequency,表示检索词在一片文档中出现的频率,检索词出现的次数除以文档的总字数。度量一条查询和结果文档相关度的最简单的方法:简单的将搜索中的每个词的TF进行相加即可。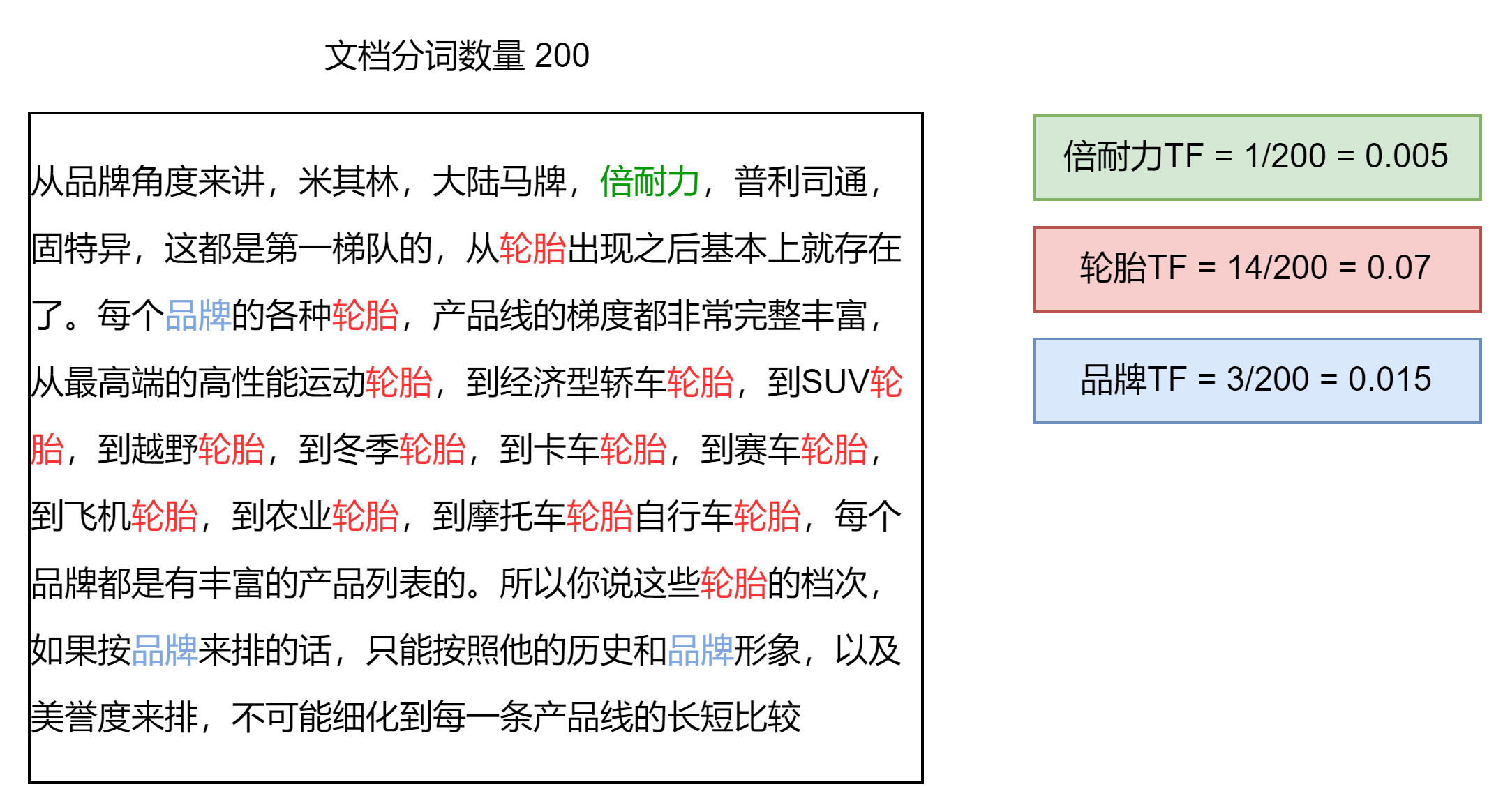
停用词
在一片文档中出现了很多次,但是对贡献相关度几乎没有任何用处,不应该考虑它们的词频的词。例如文档中的“的”、“是”、“和”。
IDF 逆文档频率与 TF-IDF
DF:就是检索词在所有文档中出现的频率
IDF:就是 Inerse Document Frequency,简单来说就是等于
| 出现的文档数量 | 总文档数量 | IDF | |
|---|---|---|---|
| 倍耐力 | 200万 | 10亿 | log(500) = 8.96 |
| 轮胎 | 10亿 | 10亿 | log(1) = 0 |
| 品牌 | 5亿 | 10亿 | log(2) = 1 |
本质上就是将 TF 求和变成了加权求和。被公认为是信息检索领域最重要的发明,除了在信息检索,在文献分类和其他相关领域都有着非常广泛的应用。现代搜索引擎,对 TF-IDF 进行了大量细微的优化。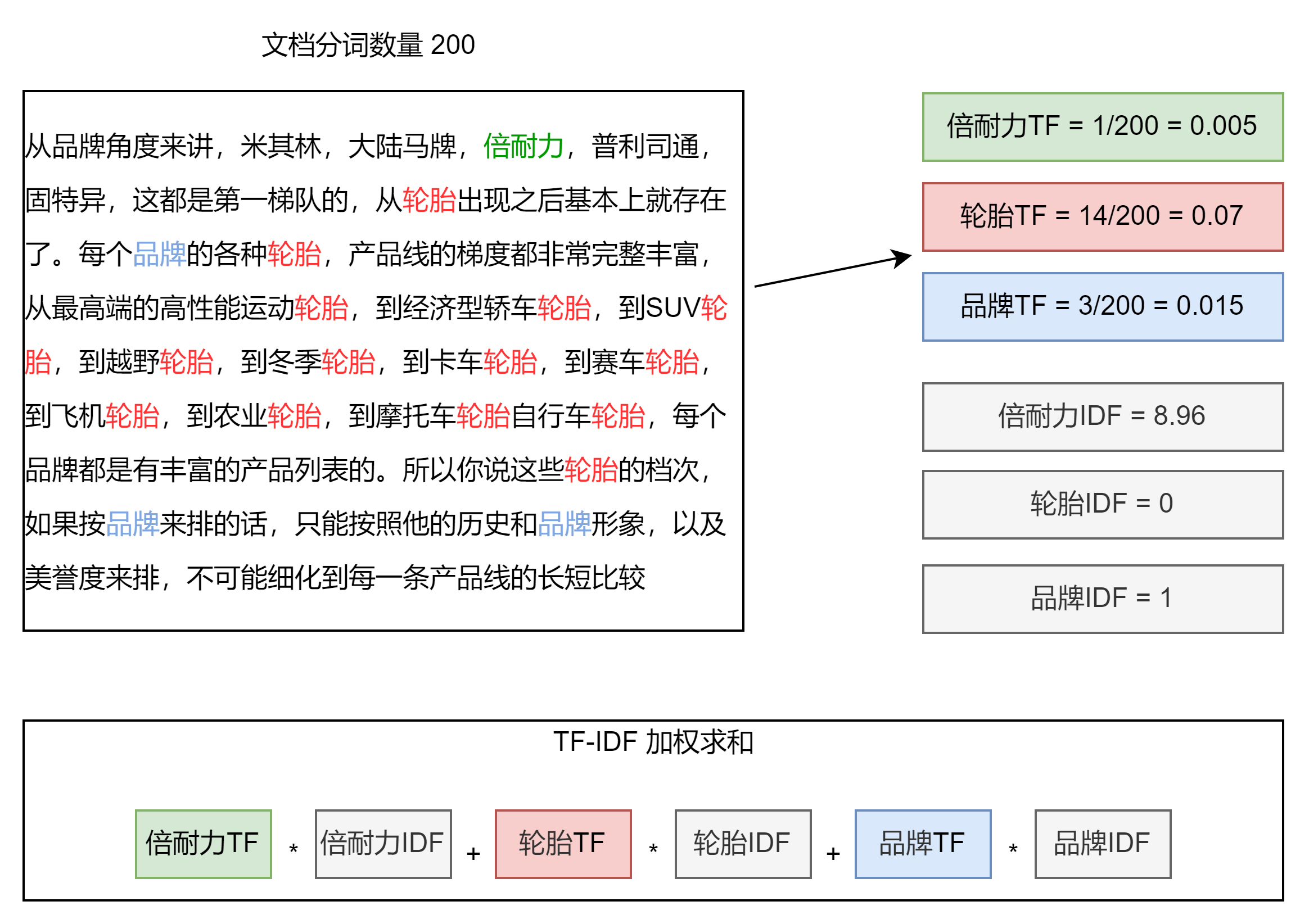
Lucene中的TF-IDF评分公式
相关性算分 BM25
从 Elasticsearch 5 开始,默认算法改为 BM25,和经典的TF-IDF相比,当TF无限增加时,BM25算分会趋于一个数值。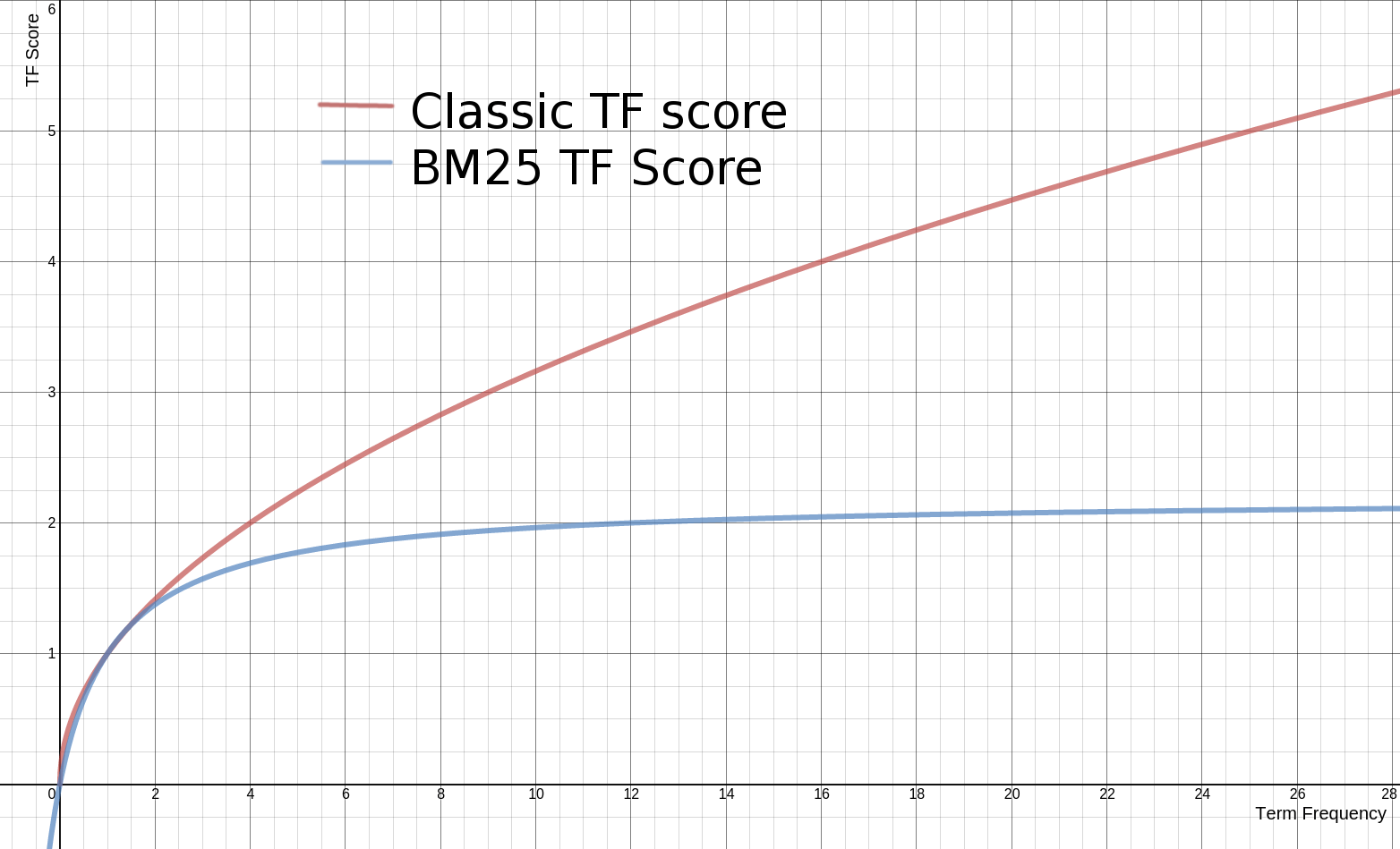
POST /my_index/_search{"explain": true,"query": {"term": {"work": "php"}}}
字段长度归一值
在 Elasticsearch 搜索相关性算法上,还存在字段长度归一值理论计算。即文档字段的长度越短,字段的权重越高,最终所得到相关性分将越高。
对于有些应用场景如日志,归一值不是很有用,要关心的只是字段是否包含特殊的错误码或者特定的浏览器唯一标识符。字段的长度对结果没有影响,禁用归一值可以节省大量内存空间。可以通过以下方式在构建Mapping中关闭字段长度归一值:
# my_index:索引名称# name:查询字段PUT /my_index{"mappings": {"properties": {"name": {"type": "string","norms": { "enabled": false }}}}}
权重控制
Boosting是控制相关度算分的一种技术手段
# my_index:索引名称# positive.term.content:查询字段# "elasticsearch":查询关键字# negative.term.content:查询字段# "like":控制权重关键字,存在关键字则会对文档产生影响# negative_boost:权重POST /my_index/_search{"query": {"boosting" : {"positive" : {"term" : {"content" : "elasticsearch"}},"negative" : {"term" : {"content" : "like"}},"negative_boost" : 0.2}}}
| 数值范围 | 描述 |
|---|---|
negative_boost> 1 |
对指定的字段搜索匹配将加权 |
negative_boost= 1 |
默认加权值 |
negative_boost< 1 && negative_boost> 0 |
对指定字段搜索匹配加权,但是低于默认权值 |
negative_boost< 0 |
对指定字段搜索匹配降权,匹配越多降权越重 |
排序
排序是针对字段原始内容进行的,倒排索引无法发挥作用,需要用到正排索引,通过文档 ID 和字段快速得到字段原始内容。
# posts:索引名称# platform,recommend_sort,_score:排序字段名称# asc:正序# desc:倒序POST /posts/_search{"query": {"match_all": {}},"sort": [{"platform": {"order": "asc"}},{"recommend_sort": {"order": "desc"}},{"_score": {"order": "desc"}}]}
# kibana_sample_data_ecommerce:索引名称# customer_full_name:字段名称PUT kibana_sample_data_ecommerce/_mapping{"properties": {"customer_full_name" : {"type" : "text","fielddata": true,"fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}
实现方式
| Doc Values | Field data | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 何时创建 | 索引时,和倒排索引一起创建 | 搜索时动态创建 | |||||||
| 创建位置 | 磁盘文件 | JVM Heap | |||||||
| 优点 | 避免大量内存占用 | 索引速度快,不占用额外磁盘空间 | |||||||
| 缺点 | 降低索引速度,占用额外磁盘空间 | 文档过多时,动态创建开销大,占用过多 JVM Heap | |||||||
| 缺省值 | ES 2.x 之后 | ES 1.x 及之前 |
关闭 Doc Values
# test_keyword:索引名称# user_name:字段名称PUT test_keyword/_mapping{"properties": {"user_name": {"type": "keyword","doc_values": false}}}
- Elasticsearch 默认启用 Doc Values,增加索引速度,减少磁盘空间,可以通过 Mapping 设置关闭。
- 如果重新打开,需要重建索引
- 什么时候关闭:明确不需要做排序及聚合分析

若有收获,就点个赞吧
0 人点赞
